目录
3.1.2.测试解析网页title,content,url是否正确?
四、测试总结
一、项目背景
1、互联网信息爆炸的时代背景
随着互联网技术的飞速发展,全球范围内的信息量呈现出爆炸式增长。网络已成为人们获取信息的主要渠道,每天有海量的网页被创建和更新,涵盖了新闻、学术、商业、娱乐等各个领域。然而,面对如此庞大的信息海洋,用户如何高效、准确地找到所需信息成为了一个巨大的挑战。
2、搜索引擎的应运而生
为了应对这一挑战,搜索引擎应运而生。搜索引擎是一种能够根据用户输入的关键词,在海量信息中快速检索并返回相关结果的技术和系统。它的出现极大地提高了信息检索的效率,使得用户能够轻松找到所需信息,节省了大量的时间和精力。
3、搜索引擎的市场需求和竞争态势
在当今社会,搜索引擎已成为人们日常生活中不可或缺的一部分。无论是学术研究、商业决策还是日常信息获取,搜索引擎都发挥着至关重要的作用。随着移动互联网的普及和智能设备的广泛应用,用户对搜索引擎的需求也在不断变化和升级。同时,搜索引擎市场也呈现出激烈的竞争态势。各大搜索引擎公司纷纷加大研发投入,提升技术实力,以争夺更多的市场份额和用户资源。
4、搜索引擎项目的意义
在这样的背景下,开展搜索引擎项目具有重要意义。通过研发具有自主知识产权的搜索引擎技术,不仅可以满足用户日益增长的信息检索需求,提升用户体验,还可以推动相关产业的发展和进步。同时,搜索引擎项目也是一项具有创新性和挑战性的任务,能够锻炼和提升团队的技术研发能力和创新能力。
二、项目功能
1、基础搜索功能
- 关键词搜索:用户输入关键词或短语,搜索引擎能够快速在索引的数据库中查找与关键词相关的信息,并按一定顺序和格式展示给用户。
- 结果排序:根据网页的相关性、质量、权威性等因素,对搜索结果进行排序,优先展示最符合用户需求的网页。
2、用户交互与体验功能
- 用户界面友好:提供简洁明了的用户界面,方便用户输入查询、浏览结果和进行交互操作。
- 搜索建议与自动补全:在用户输入查询时,提供搜索建议和自动补全功能,提高搜索效率。
- 结果摘要与预览:为搜索结果提供摘要信息或预览图,帮助用户快速了解网页内容,决定是否点击查看。
3、数据索引与爬取功能
- 数据爬取:使用网络爬虫等自动化工具,从互联网上抓取网页数据,为搜索引擎提供数据支持。
- 数据索引:对抓取到的数据进行预处理和整理,构建倒排索引等数据结构,提高搜索效率。
三、测试报告
测试用例:

3.1.功能测试

3.1.1.输入测试:
下面是等价类的划分
- 有效等价类:英文字符,数字字符,英文和数字混杂字符
- 无效等价类:中文字符,停用词字符,其他特殊字符
测试输入数据:
|------------------|------------|
| 测试用例 | 期望结果 |
| arr(有效) | 能被查找到并正确显示 |
| string(有效) | 能被查找到并正确显示 |
| 1234(有效) | 能被查找到并正确显示 |
| ke123(有效) | 能被查找到并正确显示 |
| 你好(无效) | 查找不到结果 |
| ,;X(无效) | 查找不到结果 |
| 3=**&&~(无效) | 查找不到结果 |
| 空格(无效) | 查找不到结果 |
测试截图:
有效等价类:
输入字母:

预期结果:搜索成功,显示与字母相关的结果.
实际结果:搜索成功,显示带有字母的结果.
输入数字:

预期结果:搜索成功,显示与数字相关的结果.
实际结果:搜索成功,显示带有数字的结果.
无效等价类:
输入汉字:

预期结果:搜索失败,查找不到结果
实际结果:搜索失败,查找不到结果
输入特殊字符

预期结果:搜索失败,查找不到结果
实际结果:搜索失败,查找不到结果
3.1.2.测试解析网页title,content,url是否正确?
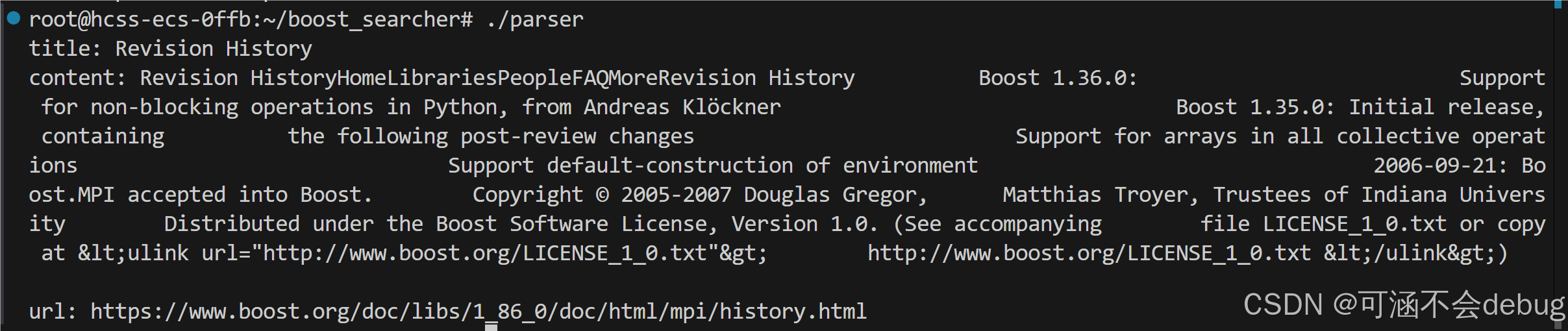
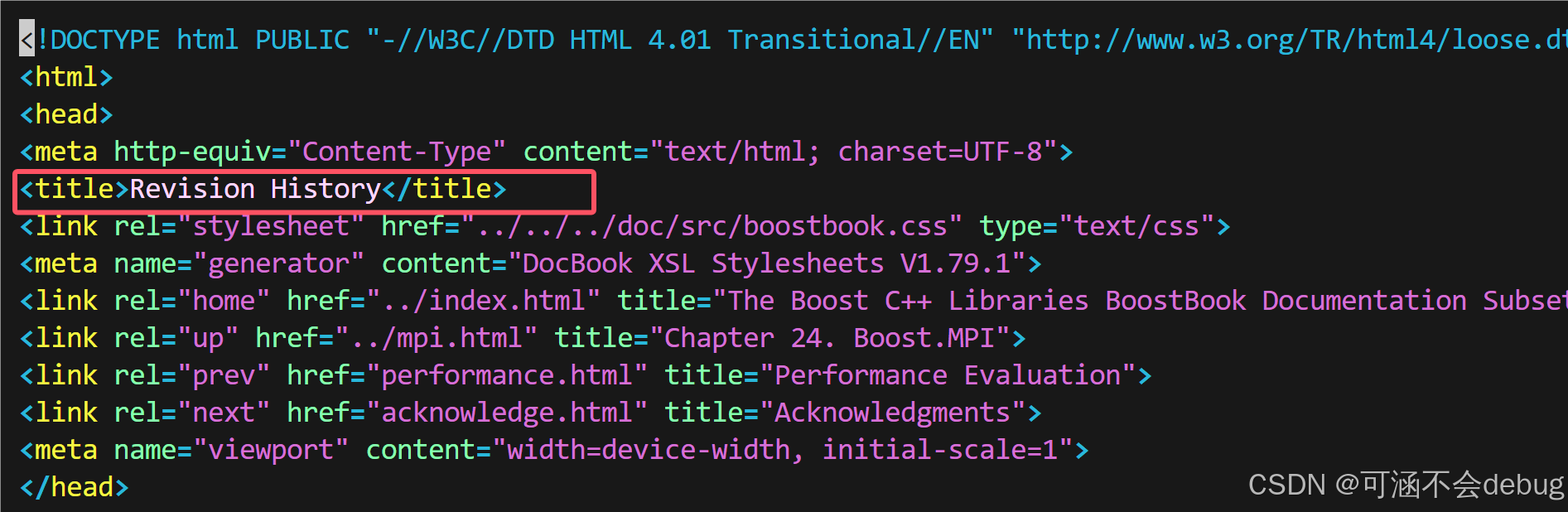
vim data/input/mpi/history.html
在自己下载的文件里面进行验证,发现正确,没问题!
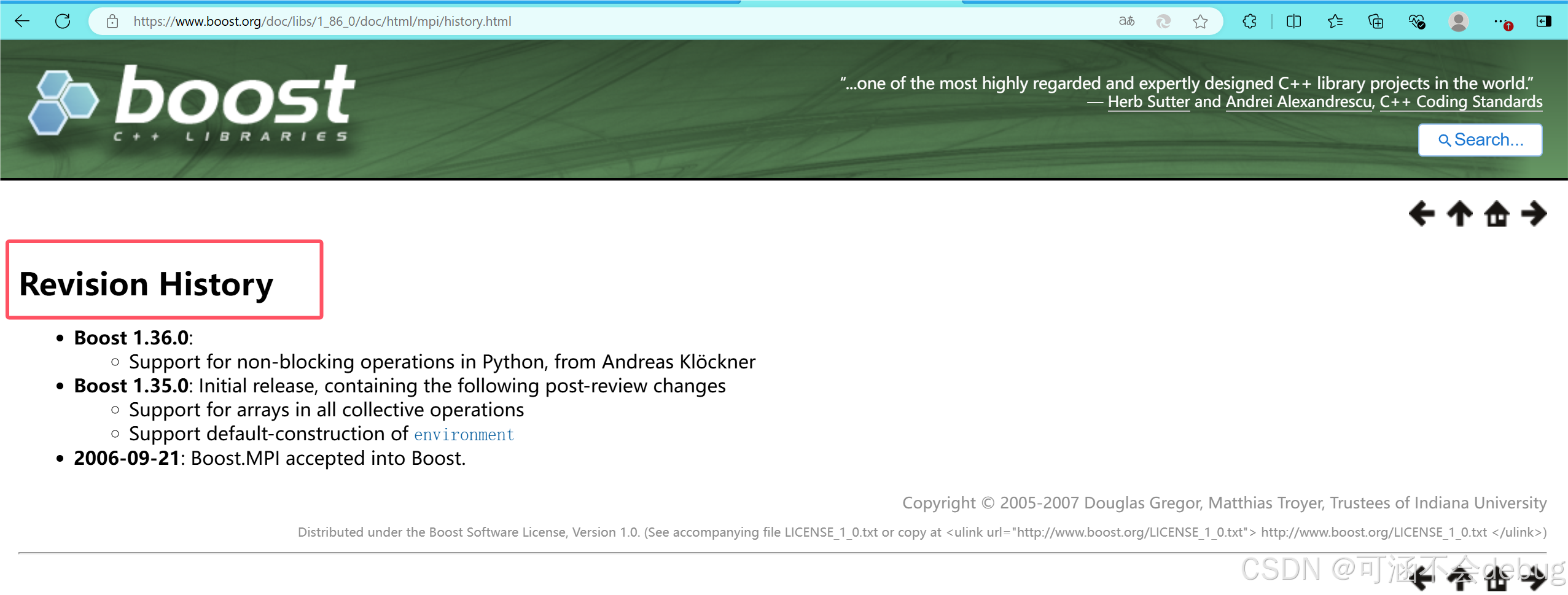
在网站中验证,也没问题!
3.2.界面测试


搜索框和按钮正常显示。

标题、描述、URL是否正确显示
如图,可以看到三者正确显示。
3.3.性能测试

3.4.自动化测试
3.4.1.工具类的实现:
python
import os
import sys
import datetime
from selenium import webdriver
from selenium.webdriver.ie.service import Service
from webdriver_manager.chrome import ChromeDriverManager
#创建一个浏览器对象
class Driver:
driver = ""
def __init__(self):
options = webdriver.ChromeOptions()
self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options)
def getScreeShot(self):
# 创建屏幕截图
# 图片文件名称:./2024-05-08-173456.png
dirname = datetime.datetime.now().strftime("%Y-%m-%d")
# 判断dirname文件夹是否已经存在,若不存在则创建文件夹
# ../images/2024-05-08
if not os.path.exists("../images/" + dirname):
os.mkdir("../images/" + dirname)
# 2024-05-08-173456.png
# 图片路径:../images/调用方法-2024-05-08/2024-05-08-173456.png
# 图片路径:../images/LoginSucTest-2024-05-08/2024-05-08-173456.png
# 图片路径:../images/LoginFailTest-2024-05-08/2024-05-08-173456.png
filename = sys._getframe().f_back.f_code.co_name + "-" + datetime.datetime.now().strftime(
"%Y-%m-%d-%H%M%S") + ".png"
self.driver.save_screenshot("../images/" + dirname + "/" + filename)
BlogDriver = Driver()3.4.2.主体测试代码的实现:
python
#测试搜索引擎主页界面
import time
from selenium.webdriver.common.by import By
from common.Utils import BlogDriver
class SearchHomePage:
url = ''
driver = ''
def __init__(self):
self.url = 'http://123.249.125.60:8085/'
self.driver = BlogDriver.driver
self.driver.get(self.url)
#搜索无效等价类
def InvaildTest(self):
#测试中文
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > input[type=text]').send_keys('你好')
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > button').click()
time.sleep(8)
#清空搜索框内容
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > input[type=text]').clear()
#测试特殊字符
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > input[type=text]').send_keys('****')
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > button').click()
#清空搜索框内容
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > input[type=text]').clear()
#搜索有效等价类
def VaildTest(self):
#测试字符串类型
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > input[type=text]').send_keys('string')
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > button').click()
time.sleep(3)
#每次搜索完毕之后,都要清空搜索框的内容,便于下次测试
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > input[type=text]').clear()
#测试数字类型
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > input[type=text]').send_keys('123')
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.search > button').click()
time.sleep(3)
#点击任意一条内容,看能否跳转
self.driver.find_element(By.CSS_SELECTOR,'body > div > div.result > div:nth-child(1) > a').click()
time.sleep(3)
_search = SearchHomePage()
_search.InvaildTest()
_search.VaildTest()测试结果:

3.5.兼容测试

在Windows11环境下:
联想浏览器:正常运行

在Windows11环境下:
谷歌浏览器:正常运行

在Windows11环境下:
Edge浏览器:正常运行

oppo Android手机环境:
手机QQ浏览器:正常运行
四、测试总结
4.1.功能测试
在功能测试环节,我们主要对搜索引擎的输入功能进行了详细测试。通过等价类划分,我们设计了有效等价类和无效等价类测试用例,以确保搜索引擎能够正确处理各种输入情况。
- 有效等价类测试 :
- 测试用例包括英文字符、数字字符、英文和数字混杂字符等,这些输入均能被搜索引擎正确查找并显示相关结果。
- 实际测试结果与预期结果一致,搜索引擎能够准确返回与输入内容相关的搜索结果。
- 无效等价类测试 :
- 测试用例包括中文字符、停用词字符、其他特殊字符以及空格等,这些输入均被搜索引擎判定为无效,无法查找到相关结果。
- 实际测试结果同样与预期结果一致,搜索引擎能够正确识别并处理这些无效输入。
4.2.界面测试
在界面测试环节,我们主要对搜索引擎的搜索框、按钮以及搜索结果展示界面进行了测试。
- 搜索框和按钮测试 :
- 搜索框和搜索按钮均能够正常显示,且点击按钮后能够触发搜索功能。
- 搜索结果展示界面布局合理,能够清晰展示搜索到的相关内容。
- 标题、描述、URL显示测试 :
- 搜索结果中的标题、描述和URL均能够正确显示,且与实际搜索结果相符。
4.3.自动化测试
在自动化测试环节,我们利用Selenium自动化测试工具编写了测试代码,对搜索引擎的搜索功能进行了自动化测试。
- 工具类实现 :
- 我们创建了一个
Driver类,用于初始化Selenium WebDriver并实现截图功能。 - 通过
ChromeDriverManager自动管理ChromeDriver的安装和更新。
- 我们创建了一个
- 主体测试代码实现 :
- 我们编写了
SearchHomePage类,用于测试搜索引擎主页的搜索功能。 - 通过CSS选择器定位搜索框和搜索按钮,并模拟用户输入和点击操作。
- 对有效等价类和无效等价类分别进行了测试,并验证了搜索结果和页面跳转功能。
- 我们编写了
- 测试结果 :
- 自动化测试代码运行顺利,测试结果与预期一致,搜索引擎能够正确处理各种输入并返回相关搜索结果。
4.4.兼容测试
在兼容测试环节,我们测试了搜索引擎在不同操作系统和浏览器环境下的运行情况。
- Windows11环境测试 :
- 在联想浏览器、谷歌浏览器和Edge浏览器下,搜索引擎均能正常运行,搜索结果准确且页面布局合理。
- Android手机环境测试 :
- 在oppo Android手机的QQ浏览器下,搜索引擎同样能够正常运行,搜索结果准确且页面适应手机屏幕大小。
总结:
通过本次测试,我们验证了搜索引擎项目的功能完整性、界面合理性、自动化测试可行性以及跨平台兼容性。测试结果表明,搜索引擎能够正确处理各种输入情况,界面布局合理且易于使用,自动化测试代码运行稳定且准确,同时在不同操作系统和浏览器环境下均能正常运行。因此,我们可以认为该搜索引擎项目已经具备了上线运行的基本条件。