图表图片由阿里巴巴提供本文作者的观点:QwQ-32B 作为小型开源 AI 模型,在数学、编程等任务上表现接近甚至超越 DeepSeek-R1 671B模型,同时计算资源占用大幅降低,使其更易部署和使用。然而,在逻辑推理等方面仍存在推理不一致和语言混杂等问题,有待优化。作者总体认可 QwQ-32B 的实力,并认为它代表了 AI 发展向"小而高效"方向演进的趋势,可能冲击 OpenAI 等收费模式的市场格局。
DeepSeek R-1 才刚刚发布两个月,我当时真的很兴奋,因为 AI 社区终于有了一个能与 OpenAI 的强大 o1 模型抗衡的开源模型。
然而就在昨天,阿里巴巴发布了另一个开源模型,功能与 DeepSeek R-1 相当,但体量却小了 20 倍。
这家中国科技巨头推出的新推理模型 QwQ-32B 仅使用 320 亿参数,而 DeepSeek 的参数量为 6710 亿,在推理过程中有 370 亿参数被实际调用。
自 2023 年推出首个大型语言模型以来,阿里巴巴大幅增加了对 AI 的投资。其云智能部门已成为主要增长动力,在 12 月季度对阿里巴巴的利润增长贡献显著。
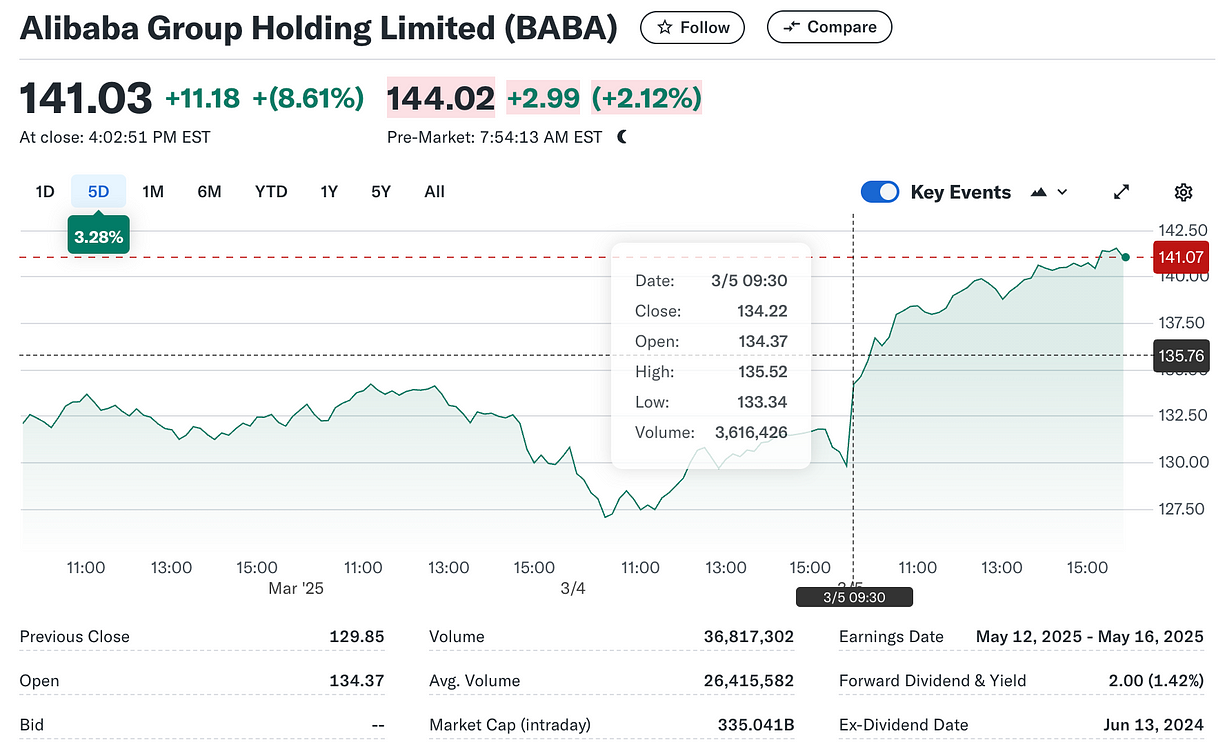
阿里巴巴集团控股有限公司 2025 年 3 月 5 日市值"展望未来,由 AI 驱动的云智能集团收入增长将持续加速。" 阿里巴巴 CEO 吴泳铭最近表示。AI 发展潜力带来的乐观情绪得到了投资者的积极响应,QwQ-32B 发布后,阿里巴巴股价明显上涨。
QwQ-32B 的关键特性
QwQ-32B 采用强化学习(RL),即通过试错学习,而非传统的监督训练方式。这样做的主要优势是,它所需的资源远远少于 DeepSeek-R1(QwQ-32B 仅 320 亿参数,而 DeepSeek-R1 拥有 6710 亿参数,其中约 370 亿实际参与推理)。
尽管体量更小,QwQ-32B 在某些任务上却能达到甚至略微超越更大模型的表现。
以下是其关键特性概览:
• 类型:因果语言模型
• 训练阶段:预训练 & 后训练(监督微调和强化学习)
• 架构:采用 RoPE、SwiGLU、RMSNorm 和 Attention QKV 偏置的 Transformer
• 参数数量:325 亿
• 非嵌入参数数量:310 亿
• 层数:64
• 注意力头数(GQA):Q 40,KV 8
• 上下文长度:完整 131,072 令牌
强化学习(RL)为何重要
阿里巴巴选择 RL 训练 QwQ-32B 的决定至关重要。RL 让模型能直接从现实世界的反馈中学习,提高准确性和适应性。阿里巴巴在两个阶段中实施了这一方法:
• 初期专注于数学和编程:第一阶段,QwQ-32B 通过直接测试数学问题和编程任务学习,并通过实际计算和代码执行验证结果。
• 扩展至通用能力:在掌握特定技能后,阿里巴巴扩大训练范围,使模型在遵循指令、优化用户交互等方面表现更好。
这种强化学习方法显著提升了模型的效率,同时没有牺牲性能。
性能测试结果
在多个基准测试中,QwQ-32B 取得了出色表现:
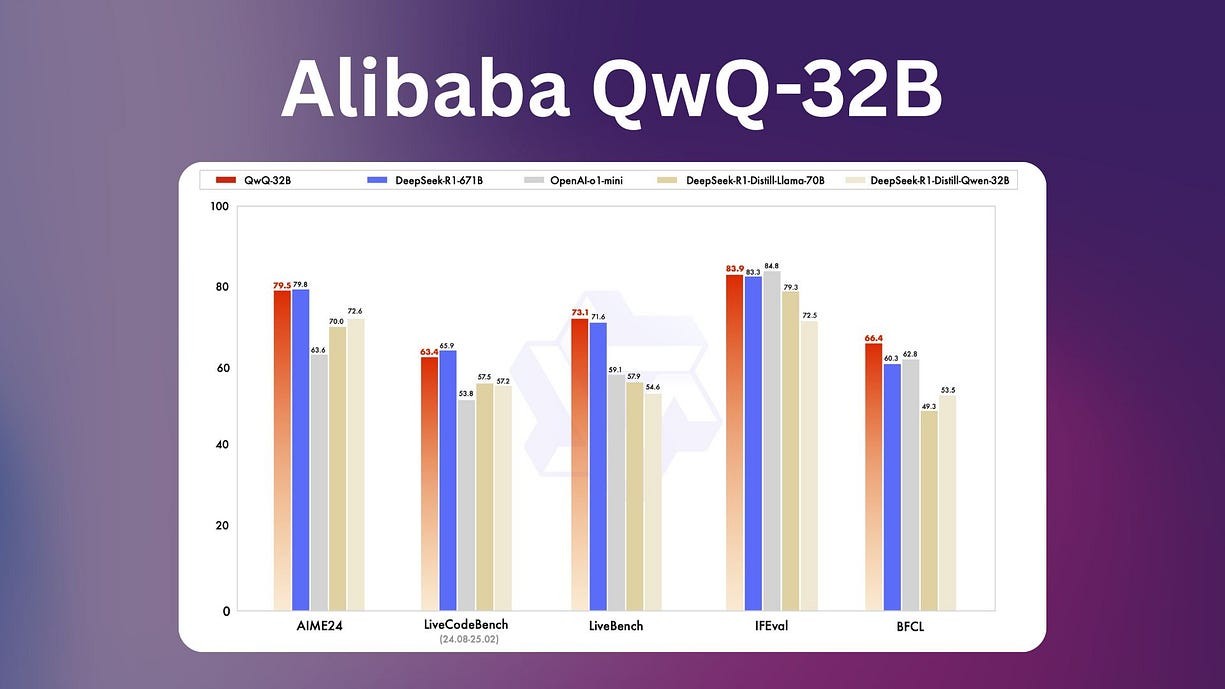
• 数学任务:在 AIME24 等高难度数学测试中表现与 DeepSeek-R1 持平。
• 编程任务:在 LiveCodeBench 等代码基准测试中,QwQ-32B 取得了与 DeepSeek-R1 相近的分数。
• 通用任务:在指令跟随和工具使用测试中,QwQ-32B 略微优于 DeepSeek-R1。
下方是 QwQ-32B 与其他领先模型(包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 以及原版 DeepSeek-R1)的对比表现。
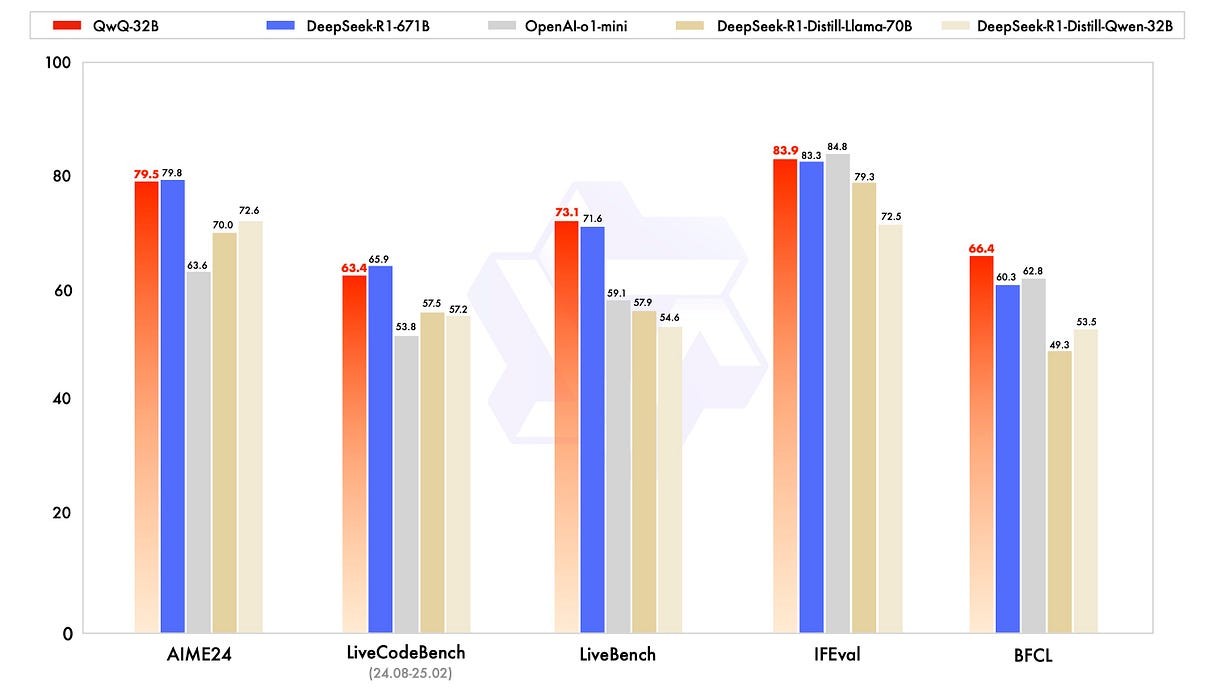
QwQ-32B 与其他模型的对比,包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 和原版 DeepSeek-R1这些基准测试显示,该模型在实际应用中的可行性,适用于多种真实场景。
但它在现实世界中表现如何?
人工智能与数据专家 Ana Rojo Echeburúa(应用数学博士)对 QwQ-32B 进行了数学、编程和逻辑推理测试。
草莓测试
提示:"'strawberry' 这个单词中字母 'r' 出现了几次?"
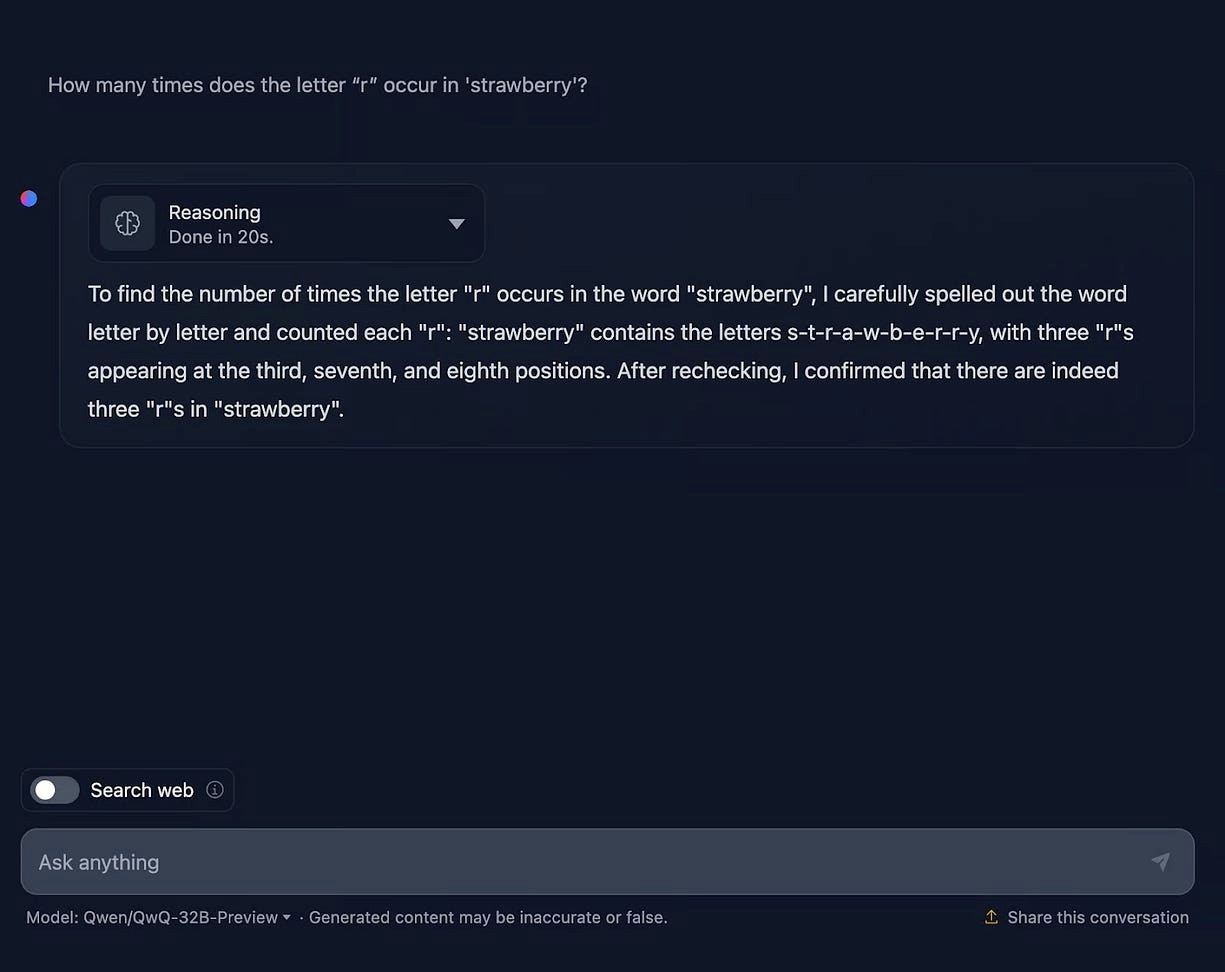
QwQ-32B 回答尽管 QwQ-32B 准确计算出了字母的数量,但它错误地指出了字母的位置,尽管题目并未明确要求这一点。这突显了该模型偶尔会提供不必要的细节,并在推理上存在一定的不准确性。
数学推理测试
提示:"边长为 3、4、5 的三角形面积是多少?"
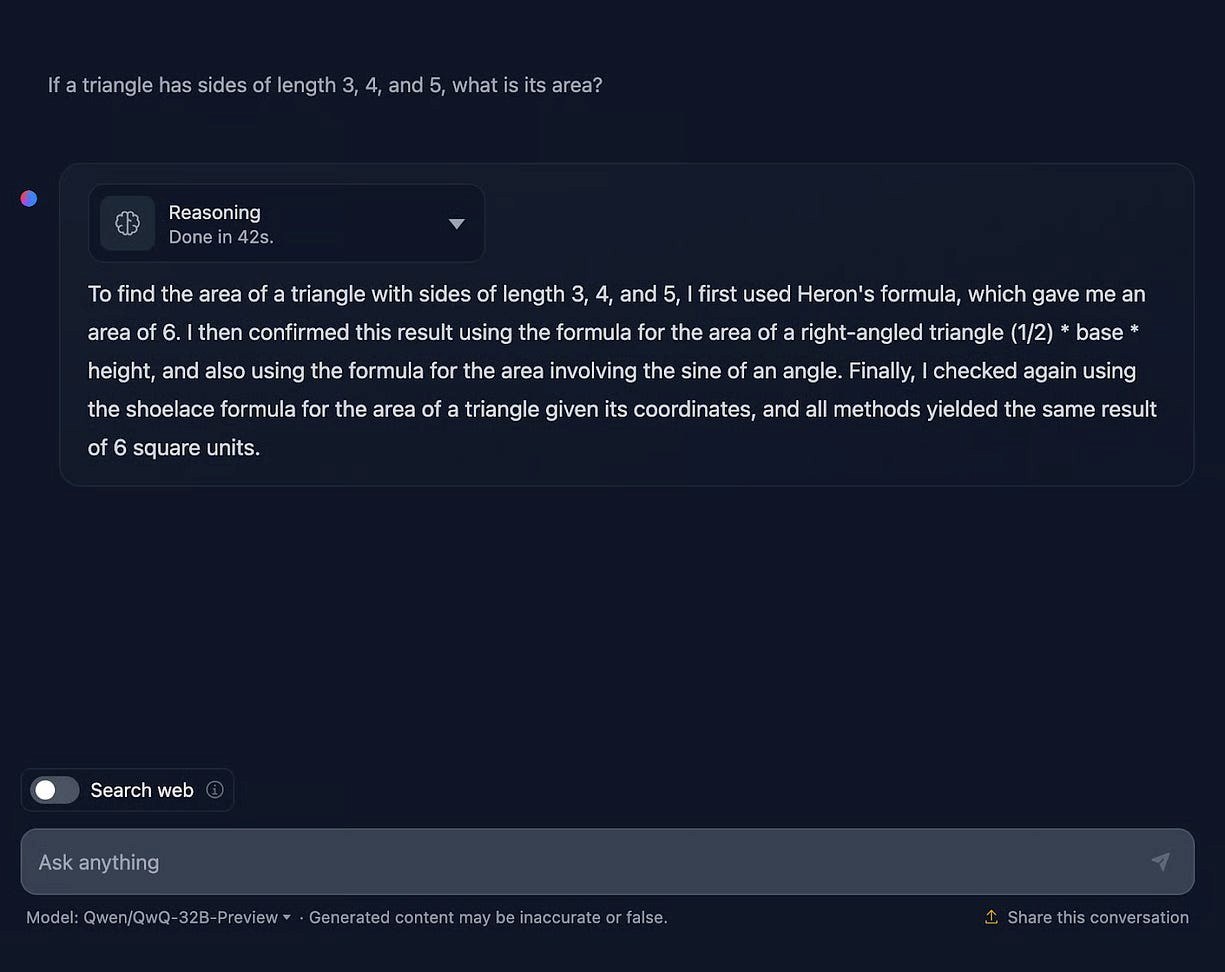
QwQ-32B 回答该模型正确回答出面积为 6,并清晰地解释了多种求解方法,展现了清晰且直接的推理过程。然而,它在格式和公式呈现上存在一些不一致之处。
逻辑推理测试
经典"狼、山羊和白菜"问题
提示:"一个人要带着狼、山羊和白菜过河。船每次只能载一个物品。如果单独留下,狼会吃山羊,山羊会吃白菜。请问他如何安全地把它们带过河?"
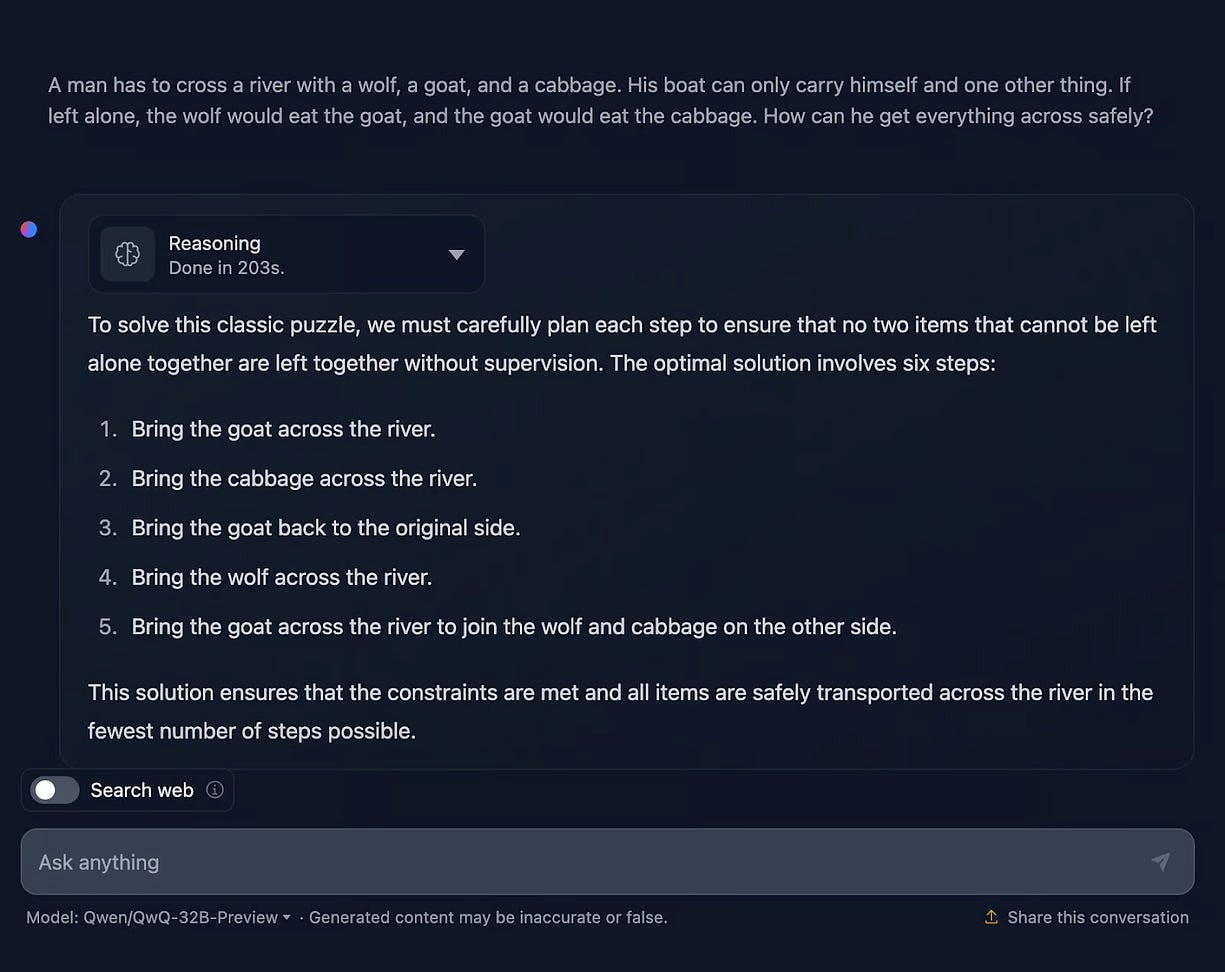
QwQ-32B 回答QwQ-32B 提供了一个大体正确的解决方案,但令人困惑的是,它声称需要六个步骤,而实际只列出了五个。其推理过程较为详细,但也出现了一些问题,包括语言混杂------英文推理中夹杂了中文文本,使部分内容难以理解。有趣的是,推理部分包含了一套完整且准确的逐步解决方案,但与最终总结的答案并不匹配。
对开发者和企业的实际影响
QwQ-32B 的高效性让先进 AI 技术更容易普及。相比 DeepSeek-R1 需要高达 1600GB 的 GPU 显存,QwQ-32B 仅需 24GB,使企业无需庞大的计算基础设施即可部署强大 AI 工具。
此外,该模型采用 Apache 2.0 许可证开源,企业可以自由修改和使用,适用于自动化、软件开发、数据分析等多个场景。
AI 社区对 QwQ-32B 的初步反应总体积极,特别是开发者们称赞其高效性和易部署性。例如,来自 Hugging Face 的 Vaibhav Srivastav 赞扬了 QwQ-32B 的速度和易用性。
如何访问 QwQ-32B
目前有多种方式可访问和测试 QwQ-32B:
• 专用演示应用:Hugging Face Demo
• 直接下载模型:开发者和研究人员可从 Hugging Face 仓库下载 QwQ-32B 进行深入研究。
• 在线界面:阿里巴巴通过官方 Qwen Chat 提供交互平台。
Qwen 官方网站界面截图Hugging Face 界面截图
此外,预计 OIlama 等工具很快也会支持 QwQ-32B,让开发者能够更方便地使用本地化部署方式。
最终感想
我真的对 QwQ-32B 这样的开源 AI 模型出现的速度感到震撼------甚至有点不知所措。这一发展表明 OpenAI 采用的高价订阅模式可能很快会过时,因为高质量的开源替代方案正变得越来越普及。
像 QwQ-32B 这样的模型展示了 AGI(通用人工智能)发展的包容性,使 AI 不再只是少数人能负担得起的昂贵工具。
当然,仍有许多方面值得探索,特别是这些小型但强大的模型在实际环境中的表现如何。我计划在搭载 M3 芯片的 MacBook 上测试 QwQ-32B,并在后续文章中分享详细结果。
QwQ-32B 预览版的优势令人印象深刻,但推理和最终答案的矛盾性仍有待改进。总体而言,这可能预示着 AI 领域向更小、更高效模型转型的新趋势。
你试用过这个新模型了吗?如果有,我很想听听你的想法。