在机器学习的流程中,数据集的合理划分是模型训练与评估的关键前提。
恰当的划分方式不仅能有效利用数据资源,还能确保模型评估结果的可靠性,为模型的泛化能力提供有力保障。
本文将深入介绍3种常见的数据集划分方法:留出法、交叉验证法和自助法,并配以scikit-learn的代码示例来说明如何使用这些方法。
1. 概述
在机器学习算法中,我们通常将原始数据集划分为两个部分:
- 训练集:用于训练模型,让模型学习数据中的特征和规律。
- 测试集:用于最终评估模型的性能,模拟实际应用场景。
数据集划分时需根据具体的数据量、任务目标和模型特性综合考量,
以确定每种数据集的数据量和数据种类。
2. 数据集划分方法
2.1. 留出法(Hold-out)
留出法是数据集划分的"基础款",其操作简洁明了。
具体而言,就是将整个数据集随机拆分为两个互不相交的子集:测试集和训练集。
通常情况下,测试集所占比例较小,例如常见的 20% 或 30%,而剩余的大部分数据则构成训练集,用于模型的训练过程。
这种划分方式的优势在于简单高效,只需一次划分即可完成数据集的分配。
下面的代码通过使用train_test_split函数演示如何划分数据集。
python
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 使用留出法划分数据集,测试集占20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("训练集特征形状:", X_train.shape)
print("测试集特征形状:", X_test.shape)
print("训练集标签形状:", y_train.shape)
print("测试集标签形状:", y_test.shape)
# 输出结果:
'''
训练集特征形状: (120, 4)
测试集特征形状: (30, 4)
训练集标签形状: (120,)
测试集标签形状: (30,)
'''留出法适用于数据量相对充足且希望快速得到模型初步评估结果的场景。
比如在探索性数据分析阶段,或者当数据集规模较大时,通过留出法可以高效地完成模型训练与初步性能评估,帮助我们快速验证模型的基本可行性,为进一步优化模型提供方向指引。
2.2. 交叉验证法(Cross-Validation)
交叉验证法堪称数据集划分的"进阶利器",尤其在数据量有限的情况下大显身手。
它将数据集划分为 K 个大小相近、互不重叠的子集。
接下来,模型训练与评估过程会进行 K 轮,在每一轮中,依次将其中一个子集作为测试集,其余 K-1 个子集合并作为训练集。
如此一来,每个子集都有机会担任测试集的角色,最终综合 K 轮的评估结果,得到更为稳定、可靠的模型性能指标。
这种方法充分利用了有限的数据资源,通过多次训练与评估,有效降低了模型评估结果的方差,增强了结果的可信度。
使用scikit-learn的代码示例如下:
python
from sklearn.model_selection import KFold
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
digits = load_digits()
X, y = digits.data, digits.target
# 初始化K折交叉验证,K=5
kf = KFold(n_splits=5, shuffle=True, random_state=42)
accuracies = []
# 进行交叉验证
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 初始化并训练模型
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 预测并计算准确率
y_pred = model.predict(X_test)
accuracies.append(accuracy_score(y_test, y_pred))
print("每轮交叉验证的准确率:", accuracies)
print("平均准确率:", sum(accuracies)/len(accuracies))
# 输出结果:
'''
每轮交叉验证的准确率: [
0.975,
0.9805555555555555,
0.9637883008356546,
0.9749303621169917,
0.9832869080779945
]
平均准确率: 0.9755122253172391
'''当数据集规模较小,担心留出法可能导致评估结果不稳定时,交叉验证法无疑是更优的选择。
例如在一些医学图像分类任务中,由于获取数据的成本较高,数据量有限,采用交叉验证法可以充分挖掘数据的价值,
使模型在有限的数据上得到更全面的训练与评估,提升模型的泛化能力,确保模型在实际应用中表现更佳。
2.3. 自助法(Bootstrapping)
自助法在数据集划分领域有着独特的魅力,其核心思想是从原始数据集中通过有放回地随机抽取样本,构建出新的训练集。
具体来说,假设原始数据集有N个样本,自助法会进行N次随机抽取,每次抽取一个样本记录后,将其放回原始数据集,使得下次抽取时该样本仍有可能被选中。
这样构建的训练集大约包含63.2%的原始样本,而剩下的未被选中的样本则构成测试集。
因为每次抽取独立,某个样本不被选中的概率为 (1-1/N)\^N ,当 N 很大时趋近于 1/e≈36.8% ,所以被选中的概率约为 63.2%。
这种划分方式使得训练集和测试集之间存在一定的重叠,为模型评估提供了不同的视角。
python
import numpy as np
from sklearn.datasets import load_wine
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
# 加载数据集
wine = load_wine()
X, y = wine.data, wine.target
# 自助法采样
n_samples = X.shape[0]
bootstrap_indices = np.random.choice(n_samples, size=n_samples, replace=True)
X_train, y_train = X[bootstrap_indices], y[bootstrap_indices]
# 找出测试集样本(未被选中的样本)
mask = np.zeros(n_samples, dtype=bool)
mask[bootstrap_indices] = True
X_test, y_test = X[~mask], y[~mask]
print("训练集特征形状:", X_train.shape)
print("测试集特征形状:", X_test.shape)
# 训练模型并评估
model = GradientBoostingClassifier(random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("分类报告:\n", classification_report(y_test, y_pred))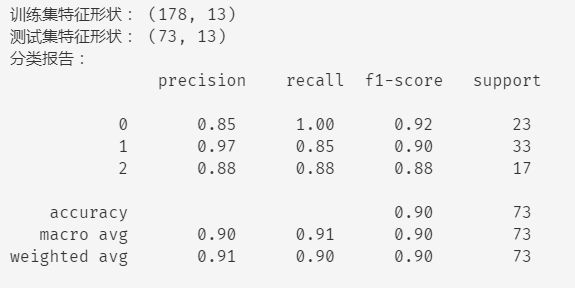
自助法常用于统计模型的性能评估以及模型稳定性分析。
例如在评估模型参数的稳定性时,通过多次自助采样,可以观察模型参数在不同训练集下的变化情况,进而判断模型对数据的敏感程度。
此外,在一些集成学习算法中,自助法也被用于生成多样化的训练集,提升模型的泛化能力和鲁棒性,如随机森林算法中就采用了自助法来构建多个决策树的训练集。
3. 总结
这三种划分数据集的方法各有优缺点和使用场景,熟练掌握这三种方法及其 scikit-learn 实现,
将使我们在机器学习的征程中更加从容地应对各种数据挑战,构建出性能优异、泛化能力强的模型。
它们之间的对比如下表:
| 方法 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
| 留出法 | 计算高效 | 结果不稳定 | 快速验证 / 大规模数据 |
| 交叉验证 | 评估稳定 | 计算成本高 | 中等数据量 / 模型调参 |
| 自助法 | 保留更多数据 | 数据分布改变 | 小数据集 / 特殊分布需求 |