虚拟索引技术(virtual index,也称为 hypothetical index)在数据库系统的查询优化、索引推荐等场景中扮演着关键角色。简单来说,虚拟索引可以理解为数据库的'沙盘推演'系统------无需真实构建索引,仅基于统计信息即可精准模拟不同索引方案对查询计划的优化效果。由于虚拟索引的创建/删除代价极低,使用者可以大量创建和删除索引、反复推演,确定最有效的索引方案。在AI 时代,基于机器学习模型 的NDV 、Cardinality估计算法层出不穷,但是在MySQL落地往往遇到很大挑战:无法注入机器学习模型的预测值,变无法得到MySQL索引推荐结果。
业界许多数据库已经以官方或第三方的方式提供了虚拟索引功能,例如 Postgres(https://github.com/HypoPG/hypopg )、Oracle(https://oracle-base.com/articles/misc/virtual-indexes )和 IBM DB2(https://www.ibm.com/docs/en/db2-for-zos/12?topic=tables-dsn-virtual-indexes )。大量数据库领域的研究都围绕虚拟索引技术展开。遗憾的是,MySQL 长期缺乏这一能力,导致其在复杂场景下的优化效果始终受限。
经过长期的生产验证,字节跳动正式开源了 MySQL 虚拟索引项目 VIDEX(Vi rtual Index ),让 MySQL 也有了自己的虚拟索引机制 🎉
VIDEX 开源地址:https://github.com/bytedance/videx
VIDEX 已经部署在了字节跳动大规模生产系统中,每天为数千用户、数十万慢 SQL 提供优化服务。VIDEX 的实用价值、工业级部署设计等特点,引来 Daniel Black(MariaDB Foundation 首席创新官)和Federico Razzoli (Founder of Vettabase) 等业界知名专家的点赞与认可。


VIDEX 提供开箱即用的虚拟索引能力,可无缝集成至现有 MySQL 生态;对于数据库研究者,VIDEX 模块化设计允许新算法(如 NDV 估计、Cardinality估计等等)在 MySQL 上快速验证,推动前沿技术落地。
具体来说,VIDEX 的贡献如下:
-
弥补 MySQL 虚拟索引空白:尽管业界已经有多种数据库支持了虚拟索引功能( Postgres、Oracle、 IBM DB2),也有一些论文和博客提到了 MySQL 的虚拟索引技术 1,2,但据我们所知,VIDEX 是首个开源的、可拓展、支持多形态部署的 MySQL 虚拟索引解决方案。
-
高精度地拟合 MySQL :我们已经在
TPC-H、TPC-H-Skew和JOB等复杂分析基准测试上对 VIDEX 进行了测试。给定准确的独立值估计(ndv) 和基数估计(Cardinality) 信息,VIDEX 可以 100% 模拟 MySQL InnoDB 的查询计划。 -
基于分离架构的多形态部署:VIDEX 实现了数据库实例-VIDEX优化器插件-VIDEX算法服务的模块分离。既支持作为插件无缝集成到现有MySQL实例,也可作为独立服务构建虚拟库环境,实现生产环境零干扰的索引验证;额外地,将 VIDEX优化器插件和VIDEX算法服务也做了分离,便于 AI 算法服务的集成和热更新。
-
可拓展的实验平台 :准确地模拟MySQL查询代价依赖于对独立值(ndv)和基数(Cardinality)的准确估计------这正是**AI****+**数据库研究中最火热的方向之一 3。VIDEX 给出了标准化、清晰易懂的接口设计,屏蔽了复杂的系统细节。研究者可以自由地用各种语言来重写 VIDEX 的算法模型,甚至只需要改动一个 JSON 文件,就能将自己的新算法应用于 MySQL查询优化器!
多形态部署:从实验平台到生产环境
由于 VIDEX 将真实数据库实例、虚拟数据库实例、算法服务器三个部分解耦了,因此可以灵活应用于各种适用场景,从个人研究到生产环境部署:
VIDEX-Optimizer 的两种形态
-
作为插件安装到真实数据库:将 VIDEX 作为插件安装到真实数据库实例,这样只需要一台 MySQL实例,即可体验基于虚拟索引的各种 what-if 分析。适合于个人实验和分析。
-
以独立实例启动:独立启动 VIDEX 示例,同步统计信息,然后开始分析。此模式可以完全避免影响在线运行实例的稳定性,在工业环境中很实用。
VIDEX 算法服务器的两种形态
-
与 VIDEX-Optimizer 配套启动:最经典的方式,无须额外设置,VIDEX-Optimizer 会自动寻找本地启动的VIDEX算法服务器。
-
独立启动算法服务器 :只要设置一下 SQL 环境变量(
SET @``VIDEX_STATISTIC_SERVER``='ip:port'),VIDEX-Optimizer 会将算法请求转发到指定的算法服务器上。对于研究者来说,可以自由实现算法、启动自定义的算法服务;对于云原生场景,可以将大量 MySQL 实例的算法请求发往中心式的算法服务,便于运维和快速更新。
VIDEX 任务的两种形态
-
非任务模式:默认情况下,用户不需要关注 "task_id" ------ 只需要指定目标库、指定虚拟库,同步数据即可;
-
任务模式:在大规模分析任务中(例如大规模索引推荐任务),各种用户往往会对同一个生产库的不同表、或不同实例的同名表发起多次分析。这种情况下,用户可以指定任务 id(
SET @VIDEX_OPTIONS={'task_id': 'abc'}),让多个任务彼此互不影响。
算法试验场:把算法模型接入 MySQL 优化器
MySQL 采用了分离式的架构,上层的查询优化器会向下层存储引擎请求各种信息,包括元数据信息(table_rows、data_length 等等)、独立值(ndv)、基数(cardinality)、索引内存加载率等等。其中基数估计和独立值估计是 AI for DB 研究领域的热点方向。现已有大量 data-driven 或者 query-driven 的算法被提出,但这些算法往往只能以 PostgreSQL 作为试验场。
VIDEX 让用户不必与 MySQL 查询优化器做交互、也屏蔽了 MySQL 对库表元数据信息(table_rows、deta_length)的请求。由此,用户可以专注于一些重点的算法问题,例如 NDV 估计和 Cardinality 估计。
方法 1:在 VIDEX-Statistic-Server 中添加一种新方法
考虑到许多研究者习惯于用 Python 研究各种 AI 与 DB 结合的算法,因此,我们用Python 实现了 VIDEX-Statistic。
用户可以继承并修改 VidexModelInnoDB。VidexModelInnoDB 为用户屏蔽了系统变量、索引元数据格式等复杂细节,并提供了一个基于独立、均匀分布假设的 ndv 和 cardinality 算法。这样用户可以聚焦于 cardinality 和 ndv 这两个研究热点:
class VidexModelBase(ABC):
"""
Abstract cost model class. VIDEX-Statistic-Server receives requests from VIDEX-Optimizer for Cardinality
and NDV estimates, parses them into structured data for ease use of developers.
Implement these methods to inject Cardinality and NDV algorithms into MySQL.
"""
@abstractmethod
def cardinality(self, idx_range_cond: IndexRangeCond) -> int:
"""
Estimates the cardinality (number of rows matching a criteria) for a given index range condition.
Parameters:
idx_range_cond (IndexRangeCond): Condition object representing the index range.
Returns:
int: Estimated number of rows that match the condition.
Example:
where c1 = 3 and c2 < 3 and c2 > 1, ranges = [RangeCond(c1 = 3), RangeCond(c2 < 3 and c2 > 1)]
"""
pass
@abstractmethod
def ndv(self, index_name: str, table_name: str, column_list: List[str]) -> int:
"""
Estimates the number of distinct values (NDV) for specified fields within an index.
Parameters:
index_name (str): Name of the index.
table_name (str): Table Name
column_list (List[str]): List of columns(aka. fields) for which NDV is to be estimated.
Returns:
int: Estimated number of distinct values.
Example:
index_name = 'idx_videx_c1c2', table_name= 't1', field_list = ['c1', 'c2']
"""
raise NotImplementedError()假设用户用 VidexModelExample 重载了 VidexModelInnoDB ,可以指定模然后启动 VIDEX-Statistic-Server(详见代码启动脚本)。
startup_videx_server(VidexModelClass=VidexModelExample)方法 2: 全新实现 VIDEX-Statistic-Server
用户可以用任何编程语言实现 HTTP 响应、并在任意位置启动 VIDEX-Statistic。
使用时,只需要指定环境变量(SET @VIDEX_STATISTIC_SERVER='ip:port'),VIDEX-Optimizer 就会将所有请求转发到指定服务上。
两步玩转 VIDEX,在TPC-H 上看看效果
步骤 1: Docker 启动 VIDEX
最简单的情况下,用户可以用 Docker 启动一个安装好 VIDEX-Optimizer 和 VIDEX-Statistic 的容器。用户也可以参考文档说明,尝试其他启动方式。
为简化部署,我们提供了预编译的 Docker 镜像,包含:
-
VIDEX-Optimizer: 基于 Percona-MySQL 8.0.34-26
(https://github.com/percona/percona-server/tree/release-8.0.34-26),并集成了 VIDEX 插件
-
VIDEX-Statistic: ndv 和 cardinality 算法服务
如果您尚未安装 Docker:
Docker Desktop for Windows/Mac(https://www.docker.com/products/docker-desktop/)
Linux: 参考官方安装指南(https://docs.docker.com/engine/install/)
docker run -d -p 13308:13308 -p 5001:5001 --name videx kangrongme/videx:0.0.2步骤 2: VIDEX 数据准备
VIDEX 需要 Python 3.9 环境,执行元数据采集等任务。我们推荐使用 Anaconda/Miniconda 创建独立的 Python 环境来安装,详见 README 文档的 Quick Start 章节(https://github.com/bytedance/videx?tab=readme-ov-file#2-quick-start):
git clone git@github.com:bytedance/videx.git videx_statistic
cd videx_statistic
python3.9 -m pip install -e . --use-pep517指定原库和 VIDEX 库地址,用脚本一键式同步数据(以 tpch 为例):
python src/sub_platforms/sql_opt/videx/scripts/videx_build_env.py \
--target 127.0.0.1:13308:tpch_tiny:videx:password \
--videx 127.0.0.1:13308:videx_tpch_tiny:videx:password效果展示:以 TPC-H 为例
本示例使用 TPC-H 数据集演示 VIDEX 的完整使用流程。
假设用户已经准备好了 TPCH 数据。篇幅限制,我们将更详细的步骤说明放到了 README 文档的 Example 章节(https://github.com/bytedance/videx?tab=readme-ov-file#3-examples)。
为了展示 VIDEX 的有效性,我们对比了 TPC-H Q21 的 EXPLAIN 细节,这是一个包含四表连接的复杂查询,涉及 WHERE、聚合、ORDER BY、GROUP BY、EXISTS 和 SELF-JOIN 等多种部分。初始情况下,MySQL 可以选择的索引有 11 个,分布在 4 个表上。
EXPLAIN FORMAT = JSON
SELECT s_name, count(*) AS numwait
FROM supplier,
lineitem l1,
orders,
nation
WHERE s_suppkey = l1.l_suppkey
AND o_orderkey = l1.l_orderkey
AND o_orderstatus = 'F'
AND l1.l_receiptdate > l1.l_commitdate
AND EXISTS (SELECT *
FROM lineitem l2
WHERE l2.l_orderkey = l1.l_orderkey
AND l2.l_suppkey <> l1.l_suppkey)
AND NOT EXISTS (SELECT *
FROM lineitem l3
WHERE l3.l_orderkey = l1.l_orderkey
AND l3.l_suppkey <> l1.l_suppkey
AND l3.l_receiptdate > l3.l_commitdate)
AND s_nationkey = n_nationkey
AND n_name = 'IRAQ'
GROUP BY s_name
ORDER BY numwait DESC, s_name;让我们来对比 VIDEX 和 InnoDB 的估计效果。我们使用 EXPLAIN FORMAT=JSON,这是一种更加严格的格式。
我们不仅比较表连接顺序和索引选择,还包括查询计划的每一个细节(例如每一步的行数和代价)。
如下图所示,VIDEX(左图)能生成一个与 InnoDB(右图)几乎 100% 相同的查询计划。
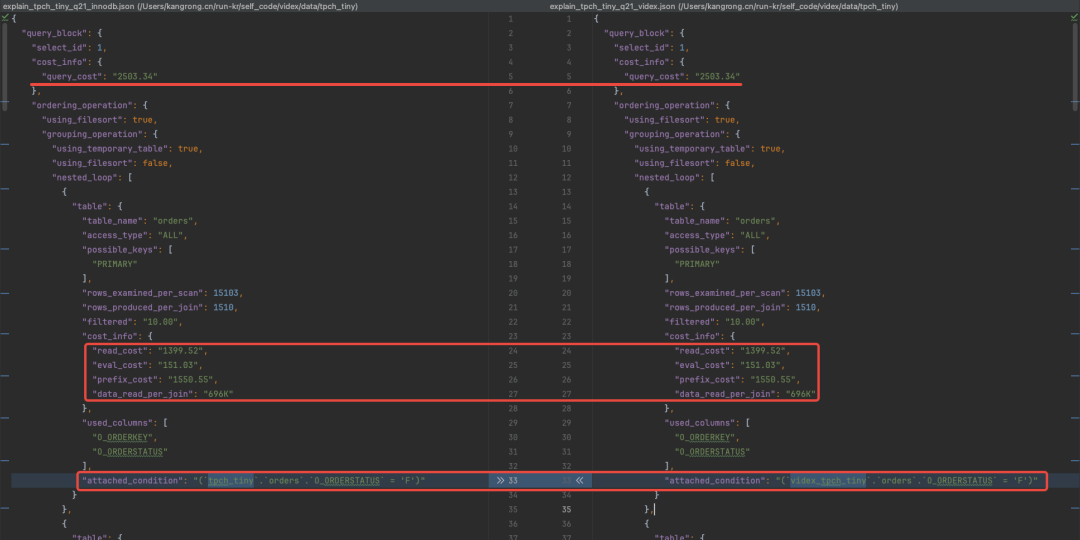
VIDEX 的一个重要作用是模拟索引代价。我们额外新增一个索引。VIDEX 增加索引的代价是 O(1) ,因为他并不需要在真实数据上创建索引:
-- 为 innodb 库创建索引
ALTER TABLE tpch_tiny.orders ADD INDEX idx_o_orderstatus (o_orderstatus);
-- 为 videx 创建索引
ALTER TABLE videx_tpch_tiny.orders ADD INDEX idx_o_orderstatus (o_orderstatus);再次执行 EXPLAIN,我们看到 MySQL-InnoDB 和 VIDEX 的查询计划发产生了相同的变化,两个查询计划均采纳了新索引,并且查询计划的细节也非常接近。

VIDEX 的行数估计 (7404) 与 MySQL-InnoDB (7362) 相差约为
0.56%,这个误差来自于基数估计算法的误差。
深入解析 VIDEX 架构

如图展现了 VIDEX 的架构。总体来说,VIDEX 包含两个模块:
-
VIDEX-Optimizer-Plugin(简称 VIDEX-Optimizer):VIDEX 的"前端"。可以作为插件安装到现有数据库,或者以一个独立的新实例启动。这一部分实现了 MySQL 查询优化器接口,并将其中一部分复杂的请求转发到 VIDEX-Statistic-Server。我们全面梳理了 MySQL handler 的超过90个接口函数,并实现与索引(Index)相关的接口。
-
VIDEX-Statistic-Server (简称 VIDEX-Statistic):VIDEX 的"后端"。基于收集到的统计信息(表行数、表大小、直方图等等)和集成的算法或模型,计算独立值(NDV) 和基数(Cardinality),并将结果返回给 VIDEX-Optimizer。
当用户指定了要分析(what-if analysis)的真实数据库之后,VIDEX 会在 VIDEX-Optimizer 上创建一个虚拟数据库。虚拟数据库与真实数据库的关系表结构完全一致,只是将 Engine 从 InnoDB 更换为 VIDEX。为了准确模拟目标数据库的查询代价,VIDEX 会调用脚本,从真实数据库采集必要的统计信息。上述过程都可以用我们提供好的脚本一键式完成。
用户也可以自定义地提供一份元数据文件、让脚本直接导入。元数据文件是 json 格式,包含了库表结构信息、统计信息(table_rows、单列 ndv等等)、直方图信息,非常容易理解。
VIDEX-Statistic-Server 是 VIDEX 的算法服务器。我们已经提供了基于独立均匀假设的 ndv 和 cardinality 算法。研究者可以自由地使用 Python、或者其他语言来实现算法,我们已经封装好了清晰明了的接口。
上述环节完成后,你就可以在虚拟数据库上自由的创建和删除索引,然后使用 EXPLAIN 来获取"贴近真实"的查询计划了 🚀
作者团队
我们来自字节跳动的 ByteBrain 团队,我们致力于用 AI 技术,为各种基础架构与系统(数据库、云原生、大数据)优化降本、提质增效。
如果您有任何疑问,请随时通过电子邮件联系我们:
-
Rong Kang: kangrong.cn@bytedance.com, kr11thss@gmail.com
-
Tieying Zhang: tieying.zhang@bytedance.com
参考资料
-
Meta: Yadav, Ritwik, Satyanarayana R. Valluri, and Mohamed Zaït. "AIM: A practical approach to automated index management for SQL databases." 2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, 2023.
-
Meituan: Slow Query Optimized Ddvice Driven by Cost Model:https://tech.meituan.com/2022/04/21/slow-query-optimized-advice-driven-by-cost-model.html
-
Kossmann, J., Halfpap, S., Jankrift, M., & Schlosser, R. (2020). Magic mirror in my hand, which is the best in the land? an experimental evaluation of index selection algorithms. Proceedings of the VLDB Endowment , 13(12), 2382-2395.
相关链接
项目地址: