文章目录
[1. 内积](#1. 内积)
[2. 感知机](#2. 感知机)
[3. 权重向量的更新表达式](#3. 权重向量的更新表达式)
[4. 线性可分](#4. 线性可分)
[三、 逻辑回归](#三、 逻辑回归)
[1)sigmoid 函数](#1)sigmoid 函数)
一、引入案例
根据尺寸把图像分类为纵向图像和横向图像
训练数据如下表所示:


如果用一条线将图中白色的点和黑色的点分开,该怎么画?

分类的目的就是找到这条线
二、准备知识
1. 内积
刚才**画的那条线,是使权重向量成为法线向量的直线。**设权重向量为w,那么那条直线的表达式就是这样的,代表两个向量的内积。(垂直所以值为0)

权重向量就是我们想要知道的未知参数,w是权重一词的英文------weight的首字母。
内积计算公式:

现在只考虑的是有宽和高的二维情况,那么公式写成:

比如我们设权重向量为 w=(1,1),那么刚才的内积表达式会变成:

移项变形之后,表达式变成x2=−x1了。这就是斜率为−1的直线

画上权重向量,再来理解下这句话 "使权重向量成为法线向量的直线"

总结:通过训练找到权重向量,然后才能得到与这个向量垂直的直线,最后根据这条直线就可以对数据进行分类了。
2. 感知机
在介绍如何求出权重向量之前,先了解下感知机的概念。
感知机是接受多个输入后将每个值与各自的权重相乘,最后输出总和的模型。

感知机是非常简单的模型,基本不会应用在实际问题中,但它是神经网络和深度学习的基础模型。
更新上面训练数据的表格,设表示宽的轴为x1、表示高的轴为x2,用y来表示图像是横向还是纵向的,横向的值为1、纵向的值为−1

接下来,根据参数向量x来判断图像是横向还是纵向的函数,即返回1或者−1的函数fw(x)的定义如下。这个函数被称为判别函数。

根据内积的符号来给出不同返回值的函数,这样就可以判断图像是横向还是纵向的了。
利用这个包含cos的表达式来思考:

cosθ 的图是这样的:

在90度<θ<270度的时候cosθ为负。
与权重向量w之间的夹角为θ,在90度<θ<270度范围内的所有向量都符合条件,所以在这条直线下面、与权重向量方向相反的这个区域。同样使内积为正的向量在另一半(θ在0-90度范围内)。


内积是衡量向量之间相似程度的指标。结果为正,说明二者相似;为0则二者垂直;为负则说明二者不相似。------这也是为什么用向量内积来进行分类的原因
3. 权重向量的更新表达式
我们先来看下权重向量的更新表达式:

只有在判别函数分类失败的时候才会更新参数值,否则权重向量w保持不变。
来看下分类失败时更新表达式的含义
首先在图上随意画一个权重向量和直线,
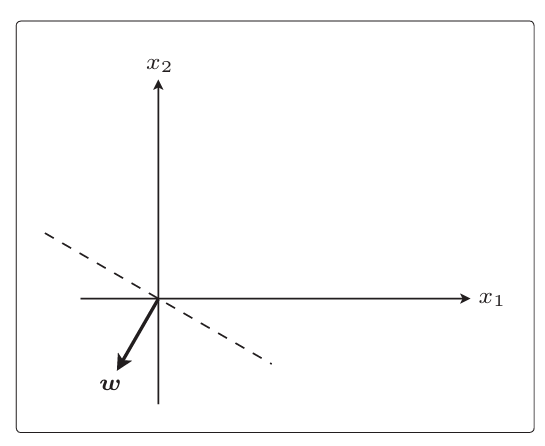
假设第一个训练数据是x(1)=(125,30),就用它来更新参数

现在权重向量w和训练数据的向量x(1)二者的方向几乎相 反,w和x(1)之间的夹角θ的范围是90度<θ<270度,内积为负。 也就是说,判别函数fw(x(1))的分类结果为−1,而训练数据x(1)的标签y(1)是1,所以fw(x(1))与y(1)不相等,说明分类失败。
这里应用刚才的更新表达式。现在y(1)=1,所以更新表达式是这样的,其实就是向量的加法:


这个w+x(1)就是下一个新的w,画一条与新的权重向量垂直的直线,相当于把原来的线旋转了一下
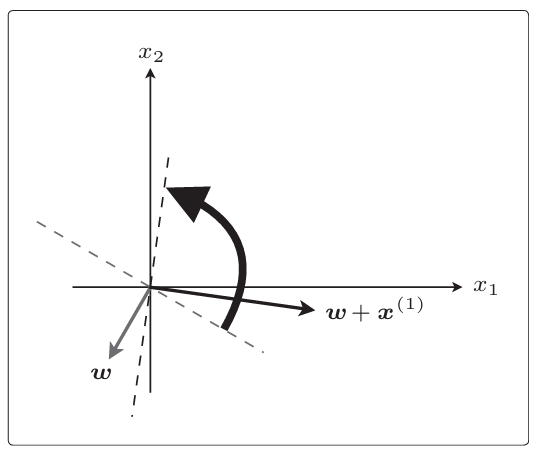
刚才x(1)与权重向量分居直线两侧,现在它们在同一侧了,这次θ<90◦,所以内积为正,判别函数fw(x)的分类结果为1。而且x(1)的标签也为1,说明分类成功了。

刚才处理的是标签值y=1的情况,而对于y=−1的情况,只是更新表达式的向量加法变成了减法而已,做的事情是一样的,都是在分类失败时更新权重向量,使得直线旋转相应的角度。像这样重复更新所有的参数,就是感知机的学习方法。
4. 线性可分
感知机最大的缺点就是它只能解决线性可分的问题。那什么是线性可分呢?
线性可分指的就是能够使用直线分类的情况,类似于上面提到的案例
像下图所示就是不能用直线分类的就不是线性可分:

三、 逻辑回归
在引入能应用于线性不可分问题的算法之前,我们先介绍逻辑回归算法 ,与感知机的不同之处在于,它是把分类作为概率来考虑的。
还是用刚才按横向和纵向对图像进行分类的例子来介绍。比如图像为纵向的概率是80%、为横向的概率是20%。
1)sigmoid 函数
这里需要能够将未知数据分类为某个类别的判别函数fθ(x),作用和感知机的判别函数fw(x)类似
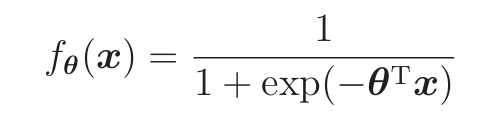

这个函数的名字叫sigmoid函数 ,设为横轴,
为纵轴,那么它的图形是这样的:

因为sigmoid函数的取值范围是0<<1,所以它可以作为概率来使用
2)决策边界
把未知数据x是横向图像的概率作为****。其表达式是这样的:

条件概率,在给出x数据时y=1,即图像为横向的概率。假如fθ(x)的计算结果是0.8,意思是图像为横向的概率是80%,就可以把x分类为横向了。
以0.5为阈值,然后把fθ(x)的结果与它相比较, 从而分类横向或纵向

从上图中可以看出在**)⩾0.5时,
⩾0,
**<0.5时,
<0
所以表达式改写为:
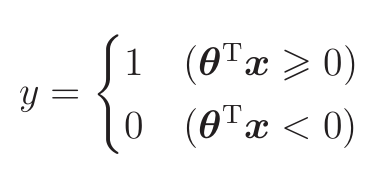
下面像学习感知机时那样,设横轴为图像的宽(x1)、纵轴为图像的高(x2),并且画出图来考虑,同样像学习回归时那样,先随便确定θ再具体地去考虑。 比如当θ是如下的向量时,画一下⩾0的图像

就有:

也就是说,我们将这条直线作为边界线,就可以把这条线两侧的数据分类为横向和纵向了


也就是说,将这条直线作为边界线,就可以把这条线两侧的数据分类为横向和纵向了。这样用于数据分类的直线称为决策边界。
为了求得正确的参数θ而定义目标函数,进行微分,然后求出参数的更新表达式,这种算法就称为逻辑回归。
3)似然函数
在构建目标函数前我们先来看下训练数据的标签y和fθ(x)的关系:
● y =1的时候,我们希望概率P(y=1|x)是最大的
● y =0的时候,我们希望概率P(y=0|x)是最大的
对于一开始列举的那6个训练数据,我们期待的最大概率是这样的:

假定所有的训练数据都是互不影响、独立发生的,这种情况下整体的概率就可以用下面的联合概率来表示:

一般化的写法如下:(也就是目标函数)


首先向指数代入1:

然后当代入0时:

这里的目标函数L(θ)也被称为似然,函数的名字L取自似然的英文单词Likelihood的首字母,接下来考虑使这个目标函数最大化的参数θ。
4)对数似然函数
直接对似然函数进行微分有点困难,首先它是联合概率,概率都是1以下的数,所以像联合概率这种概率乘法的值会越来越小,如果值太小,编程时会出现精度问题。另外还有一个,那就是乘法。与加法相比,乘法的计算量要大得多。
对应办法:取似然函数的对数

因为log是单调递增函数,如下图所示:

所以我们现在考察的似然函数也是在L(θ1)<L(θ2)时,有logL(θ1) < logL(θ2)成立。也就是说,使L(θ) 最大化等价于使logL(θ) 最大化。
把对数似然函数进行变形:

总结一下就是逻辑回归将这个对数似然函数用作目标函数:

接下来,对各个参数θj求微分:

和回归的时候一样,把似然函数也换成这样的复合函数,然后依次求微分



化简后:

v对的微分:

设z=,然后再一次使用复合函数的微分

v对z微分的部分也就是sigmoid函数的微分:

z 对θj的微分:

最后结果:

最后代入各个结果,然后通过展开、约分,化简得到:

得到参数更新表达式,最大化时要与微分结果的符号同向移动:

为了与回归时的符号保持一致,也可以将表达式调整为下面这样:

5)线性不可分
以上对于分类图像是纵向图像还是横向图像的案例是线性可分的情况,对于之前提到的一个例子来说,虽然用直线不能分类,但是用曲线就可以分类。

像学习多项式回归时那样,去增加次数,向训练数据中加入这样的数据

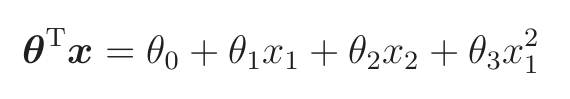
假设θ是这样的向量,那么⩾0的图形是什么样的呢?


移项后最终得到的表达式是x2⩾

之前的决策边界是直线,现在则是曲线了(由于参数θ是随便定的,所以数据没有被正确地分类)
之后通过随意地增加次数,就可以得到复杂形状的决策边界了。 比如在之外再增加一个
,就会有圆形的决策边界。然后采用随机梯度下降法求出参数更新表达式。