Easy-Es介绍
Easy-Es(简称EE)是一款基于ElasticSearch(简称Es)官方提供的RestHighLevelClient打造的ORM开发框架,在 RestHighLevelClient 的基础上,只做增强不做改变,为简化开发、提高效率而生。

引入ES相关依赖

我是新创建了一个空的Springboot工程,所以要想使用 easy-es 就必须添加他需要用到的依赖才可以。如果es和kibana的环境还没有搭建好,可以参考我之前的文章。

在pom中引入
XML
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.dromara.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>2.0.0-beta7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
添加easy-es配置
这个地址就是自己es的访问地址,我的安装在了我的Linux虚拟机中。
easy-es:
address: 192.168.200.128:9200
global-config:
process-index-mode:
# username: #es用户名,若无则删去此行配置
# password: #es密码,若无则删去此行配置
在启动类添加注解
在 Spring Boot 启动类中添加 @EsMapperScan 注解,扫描 有关 es 的 Mapper 文件夹。这个路径是根据自己项目中,关于es的mapper 所在位置来写的。
java
@EsMapperScan("com.sde.mapper.es")
@SpringBootApplication
public class EasyEsDemoApplication {
public static void main(String[] args) {
SpringApplication.run(EasyEsDemoApplication.class, args);
}
}
启动项目测试

可以看到项目正常启动了
引入MP相关依赖
就是引入mybatis-plus相关的依赖,便于我们查询数据,然后同步到es中。
在pom中引入
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.23</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.26</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
添加mp配置
这个就是我们肯定要连接我们自己的MySQL数据库,来进行crud的操作。当然里面配置的环境地址也要替换成自己的。
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.128:3306/sde_item?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
druid:
initial-size: 5
min-idle: 5
max-active: 20
max-wait: 60000
mybatis-plus:
mapper-locations: classpath:mapper/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
fastJson相关配置
java
jackson:
serialization:
write-dates-as-timestamps: false #禁用将日期序列化为时间戳
date-format: yyyy-MM-dd HH:mm:ss #日期格式
time-zone: GMT+8 #时区
启动项目测试

项目也是正常启动的
先测试mp是否可用
创建item表对应的实体
在 com.sde.entity.mp 包下面,创建Item实体类。
java
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@TableName("item")
public class Item implements Serializable {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private Integer price;
private Integer stock;
private String image;
private String category;
private String brand;
private String spec;
private Integer sold;
private Integer commentCount;
@TableField("isAD")
private Boolean isAD;
private Integer status;
private LocalDateTime createTime;
private LocalDateTime updateTime;
private Long creater;
private Long updater;
}
创建ItemMapper接口
在 com.sde.mapper.mp 包里面,创建一个名为 ItemMapper的接口,然后继承 BaseMapper
java
@Mapper
public interface ItemMapper extends BaseMapper<Item> {
}
测试mp是否可用
在测试类里面,使用 ItemMapper 进行测试。
java
@SpringBootTest
public class MpTest {
@Autowired
private ItemMapper itemMapper;
@Test
@DisplayName(("测试根据id查询"))
void testSelectById() {
Item item = itemMapper.selectById(317578L);
System.out.println(item);
}
}
可以看到是能查到数据的,到此开始编写es相关的代码,前置已经准备好了。
Easy-Es 配置
基础配置
使用 easy-es 的必要配置,如果缺失这些配置可能会导致项目无法启动,但是账号密码,如果我们没有设置的话,可以不用添加上去。
easy-es:
address : 127.0.0.1:9200 # es连接地址+端口 格式必须为ip:port,如果是集群则可用逗号隔开
username: sde #如果无账号密码则可不配置此行
password: 111 #如果无账号密码则可不配置此行 扩展配置
可缺省,不影响项目启动,为了提高生产环境性能,建议您按需配置
创建Es索引
Es的索引就类似于MySQL的数据表。我们先根据我们的 Item实体,创建es索引。
特别注意:如果您开启了索引托管-平滑模式(默认开启),并且您需要迁移的数据量很大,可以调大socketTimeout,否则迁移可能会超时异常 单位是毫秒,默认为1分钟,我们经过测试发现迁移1万条数据大约需要5秒左右,当然该数值需要综合考虑您的服务器硬件负载等因素,因此建议 您按需配置。
easy-es:
keep-alive-millis: 30000 # 心跳策略时间 单位:ms
connect-timeout: 5000 # 连接超时时间 单位:ms
socket-timeout: 600000 # 通信超时时间 单位:ms
request-timeout: 5000 # 请求超时时间 单位:ms
connection-request-timeout: 5000 # 连接请求超时时间 单位:ms
max-conn-total: 100 # 最大连接数 单位:个
max-conn-per-route: 100 # 最大连接路由数 单位:个全局配置
可缺省,不影响项目启动,若缺省则为默认值
easy-es:
enable: true # 是否开启EE自动配置 默认开启,可缺省
schema: http # 默认值为http 可缺省 也支持https免ssl方式 配置此值为 https 即可
banner: true # 默认为true 打印banner 若您不期望打印banner,可配置为false
global-config:
i-kun-mode: false # 是否开启小黑子模式,默认关闭, 开启后日志将更有趣,提升编码乐趣,仅供娱乐,切勿用于其它任何用途
process-index-mode: manual #索引处理模式,smoothly:平滑模式, not_smoothly:非平滑模式, manual:手动模式,,默认开启此模式
print-dsl: true # 开启控制台打印通过本框架生成的DSL语句,默认为开启,测试稳定后的生产环境建议关闭,以提升少量性能
distributed: false # 当前项目是否分布式项目,默认为true,在非手动托管索引模式下,若为分布式项目则会获取分布式锁,非分布式项目只需synchronized锁.
reindexTimeOutHours: 72 # 重建索引超时时间 单位小时,默认72H 可根据ES中存储的数据量调整
async-process-index-blocking: true # 异步处理索引是否阻塞主线程 默认阻塞 数据量过大时调整为非阻塞异步进行 项目启动更快
active-release-index-max-retry: 4320 # 分布式环境下,平滑模式,当前客户端激活最新索引最大重试次数,若数据量过大,重建索引数据迁移时间超过4320/60=72H,可调大此参数值,此参数值决定最大重试次数,超出此次数后仍未成功,则终止重试并记录异常日志
active-release-index-fixed-delay: 60 # 分布式环境下,平滑模式,当前客户端激活最新索引最大重试次数 分布式环境下,平滑模式,当前客户端激活最新索引重试时间间隔 若您期望最终一致性的时效性更高,可调小此值,但会牺牲一些性能
db-config:
map-underscore-to-camel-case: false # 是否开启下划线转驼峰 默认为false
index-prefix: daily_ # 索引前缀,可用于区分环境 默认为空 用法和MP的tablePrefix一样的作用和用法
id-type: customize # id生成策略 customize为自定义,id值由用户生成,比如取MySQL中的数据id,如缺省此项配置,则id默认策略为es自动生成
field-strategy: not_empty # 字段更新策略 默认为not_null
enable-track-total-hits: true # 默认开启,开启后查询所有匹配数据,若不开启,会导致无法获取数据总条数,其它功能不受影响,若查询数量突破1W条时,需要同步调整@IndexName注解中的maxResultWindow也大于1w,并重建索引后方可在后续查询中生效(不推荐,建议分页查询).
refresh-policy: immediate # 数据刷新策略,默认为不刷新,若对数据时效性要求比较高,可以调整为immediate,但性能损耗高,也可以调整为折中的wait_until
batch-update-threshold: 10000 # 批量更新接口的阈值 默认值为1万,突破此值需要同步调整enable-track-total-hits=true,@IndexName.maxResultWindow > 1w,并重建索引.
smartAddKeywordSuffix: true # 是否智能为字段添加.keyword后缀 默认开启,开启后会根据当前字段的索引类型及当前查询类型自动推断本次查询是否需要拼接.keyword后缀其他配置
logging:
level:
tracer: trace # 开启trace级别日志,在开发时可以开启此配置,则控制台可以打印es全部请求信息及DSL语句,为了避免重复,开启此项配置后,可以将EE的print-dsl设置为false.Easy-Es 配置
@EsMapperScan
描述:mapper 扫描注解,功能跟mp的@MapperScan 一致
使用位置:Springboot 启动类
java
@EsMapperScan("com.sde.mapper.es")
@SpringBootApplication
public class Application{
}|-------|------------|------|-----|----------------------------------|
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
| value | String\[\] | 是 | "" | 自定义mapper所在包全路径,2.1.0 + 版本支持多包扫描 |
注意:由于EE和MP对Mapper的扫描都是采用Springboot的doScan,而且两套系统互相独立,所以在扫描的时候没有办法互相隔离,因此如果您的项目同时有用到EE和MP,您需要将EE的Mapper和MP的Mapper放在不同的包下,否则项目将无法正常启动。
@Settings
描述:索引Settings信息注解,可设置ES索引中的Settings信息
使用位置:实体类
java
@Settings(shardsNum = 3, replicasNum = 2, settingsProvider = MySettingsProvider.class)
public class ItemDoc {
// 其它字段省略
}|------------------|--------|------|------------------|--------------------------------------------------------------------------------------------|
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
| shardsNum | int | 否 | 1 | 索引分片数,默认值为1 |
| shardsNum | int | 否 | 1 | 索引副本数,默认值为1 |
| maxResultWindow | int | 否 | 10000 | 默认最大返回数 |
| refreshInterval | String | 否 | "" | 索引的刷新间隔 es默认值为1s ms:表示毫秒 s:表示秒 m:表示分钟 |
| settingsProvider | Class | 否 | settingsProvider | 自定义settings提供类 默认为DefaultSettingsProvider空实现 如需自定义,可继承此类并覆写getSettings方法 将settings信息以Map返回 |
注意:maxResultWindow:默认最大返回数,默认值为10000,超过此值推荐使用searchAfter或滚动查询等方式,性能更好,详见拓展功能章节. 当此值调整至大于1W后,需要更新索引并同步开启配置文件中的enable-track-total-hits=true方可生效
settingsProvider:自定义settings提供类,当小部分场景下,框架内置的这些参数不足以满足您对索引Settings的设置时,您可以自定义类并继承DefaultSettingsProvider,覆写其中的getSettings方法,将您自定义的settings信息以Map返回,通过此方式可以支持所有ES能够支持的Settings
@IndexName
描述:索引名注解,标识实体类对应的索引 对应MP的@TableName注解,在v0.9.40之前此注解为@TableName
使用位置:实体类
java
@IndexName
public class ItemDoc {
// 其它字段省略
}|------------------|---------|------|-------|-------------------------------------------------|
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
| value | String | 否 | "" | 索引名,可简单理解为MySQL表名 |
| aliasName | String | 否 | "" | 索引别名 |
| keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值,与MP用法一致 |
| refreshPolicy | Enum | 否 | NONE | 索引数据刷新策略,默认为不刷新,其取值参考RefreshPolicy枚举类,一共有3种刷新策略 |
@IndexId
描述:ES主键注解
使用位置:实体类中被作为ES主键的字段, 对应MP的@TableId注解
java
public class ItemDoc {
@IndexId
private String id;
}|------|------|------|-------------|--------|
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
注意:Id 的生成类型支持以下几种
IdType.NONE: 由ES自动生成,是默认缺省时的配置,无需您额外配置 推荐
IdType.UUID: 系统生成UUID,然后插入ES (不推荐)
IdType.CUSTOMIZE: 由用户自定义,用户自己对id值进行set,如果用户指定的id在es中不存在,则在insert时就会新增一条记录,如果用户指定的id在es中已存在记录,则自动更新该id对应的记录
@IndexField
描述:ES字段注解, 对应MP的@TableField注解
使用位置:实体类中被作为ES索引字段的字段
使用示例:
java
public class ItemDoc {
// 场景一:标记es中不存在的字段
@IndexField(exist = false)
private String notExistsField;
// 场景二:更新时,此字段为非空字符串才会被更新
@IndexField(strategy = FieldStrategy.NOT_EMPTY)
private String creator;
// 场景三: 指定fieldData
@IndexField(fieldType = FieldType.TEXT, fieldData = true)
private String filedData;
// 场景四:自定义字段名
@IndexField("wu-la")
private String ula;
// 场景五:支持日期字段在es索引中的format类型
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private String gmtCreate;
// 场景六:支持指定字段在es索引中的分词器类型
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
private String content;
// 场景七:支持指定字段在es的索引中忽略大小写,以便在term查询时不区分大小写,仅对keyword类型字段生效,es的规则,并非框架限制.
@IndexField(fieldType = FieldType.KEYWORD, ignoreCase = true)
private String caseTest;
// 场景八:支持稠密向量类型 稠密向量类型,dims必须同时指定,非负 最大为2048
@IndexField(fieldType = FieldType.DENSE_VECTOR, dims = 3)
private double[] vector;
// 场景九:支持复制字段,复制当前字段至指定字段,支持将多个字段值复制到同一字段,与原生用法一致
@IndexField(copyTo = "creator")
private String copiedField;
}|----------------|------------|------|--------------------------|------------------------|
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
| value | String | 否 | "" | 字段名 |
| exist | boolean | 否 | true | 字段是否存在 |
| fieldType | Enum | 否 | FieldType.NONE | 字段在es索引中的类型 |
| fieldData | boolean | 否 | false | text类型字段是否支持聚合 |
| analyzer | String | 否 | Analyzer.NONE | 索引文档时用的分词器 |
| searchAnalyzer | String | 否 | Analyzer.NONE | 查询分词器 |
| strategy | Enum | 否 | FieldStrategy.DEFAULT | 字段验证策略 |
| dateFormat | String | 否 | "" | es索引中的日期格式,如yyyy-MM-dd |
| nestedClass | Class | 否 | DefaultNestedClass.class | 嵌套类 |
| parentName | String | 否 | "" | 父子文档-父名称 |
| childName | String | 否 | "" | 父子文档-子名称 |
| joinFieldClass | Class | 否 | JoinField.class | 父子文档-父子类型关系字段类 |
| ignoreCase | boolean | 否 | false | keyword类型字段是否忽略大小写 |
| ignoreAbove | int | 否 | 256 | 字符串将被索引或存储的最大长度 |
| copyTo | String\[\] | 否 | {} | 复制字段,可将当前字段复制到多个指定字段 |
注意:
更新策略一共有3种
NOT_NULL: 非Null判断,字段值为非Null时,才会被更新
NOT_EMPTY: 非空判断,字段值为非空字符串时才会被更新
IGNORE: 忽略判断,无论字段值为什么,都会被更新
针对BigDecimal类型字段,其scalingFactor若用户未指定,则系统默认值为100
ES索引CRUD
创建ItemDoc索引
并不需要把全部的,Item实体都加进去,我们es的索引主要是为了查询,可以存入一些页面上比较常见的属性。
java
@Data
@IndexName
public class ItemDoc implements Serializable {
@IndexId(type = IdType.CUSTOMIZE)
private String id;
@IndexField(fieldType = FieldType.TEXT,analyzer = Analyzer.IK_SMART,searchAnalyzer = Analyzer.IK_MAX_WORD)
private String name;
@IndexField(fieldType = FieldType.INTEGER)
private Integer price;
@IndexField(fieldType = FieldType.INTEGER)
private String stock;
@IndexField(fieldType = FieldType.KEYWORD)
private String image;
@IndexField(fieldType = FieldType.KEYWORD)
private String category;
@IndexField(fieldType = FieldType.KEYWORD)
private String brand;
@IndexField(fieldType = FieldType.KEYWORD)
private String spec;
@IndexField(fieldType = FieldType.KEYWORD)
private Integer sold;
@IndexField(fieldType = FieldType.KEYWORD)
private String commentCount;
@IndexField(fieldType = FieldType.BOOLEAN)
private Boolean isAD;
@IndexField(fieldType = FieldType.DATE,dateFormat = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime createTime;
@IndexField(fieldType = FieldType.DATE,dateFormat = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime updateTime;
}创建ItemDocMapper
其实和mp的模式差不多。创建好 ItemDocMapper 之后,继承 BaseEsMapper
java
/**
* @Author SDE
* @Classname: ItemDocMapper
* @Date 2025-03-27 17:43
* @Package com.sde.mapper.es
*/
public interface ItemDocMapper extends BaseEsMapper<ItemDoc> {
}
测试创建索引
我编写了一个测试类,来创建es索引。
java
@SpringBootTest
public class EsTest {
@Autowired
private ItemDocMapper itemDocMapper;
@Test
@DisplayName("创建Es索引")
void testCreateEsIndex(){
Boolean aBoolean = itemDocMapper.createIndex();
System.out.println("创建索引是否成功:" + aBoolean);
}
}看结果,索引创建成功了。

在kibana查看
我们一般会在 kibana 的控制台来查看
访问地址:你的 IP + 端口
****
使用 Easy-Es 创建索引的时候,我们会在类名的上面添加 @IndexName 来指定索引名称,如果只是加了注解没有指定名字,默认就是你的类名小写。
因为我的是 ItemDoc ,所以我的索引名是 itemdoc
java
# 查看索引
GET /itemdoc
在执行一次看看会出现什么?

索引已经存在了,在创建就报错了。
测试删除索引
java
@Test
@DisplayName("删除Es索引")
void testDeleteEsIndex(){
//要删除那个索引
String indexName = ItemDoc.class.getSimpleName().toLowerCase();
System.out.println("要删除的索引:" + indexName);
Boolean aBoolean = itemDocMapper.deleteIndex(indexName);
System.out.println("删除索引是否成功:" + aBoolean);
}
看控制台效果

测试查询索引
索引是否存在
java
@Test
@DisplayName("测试索引是否存在")
void testExistIndex(){
String indexName = ItemDoc.class.getSimpleName().toLowerCase();
Boolean aBoolean = itemDocMapper.existsIndex(indexName);
System.out.println("索引是否存在:" + aBoolean);
}
我先执行一下删除索引的操作,再来看下测试结果。可以看到这次的就是false了

当前mapper对应的索引信息
java
@Test
@DisplayName("获取当前mapper对应的索引信息")
void testMapperIndexInfo(){
GetIndexResponse indexResponse = itemDocMapper.getIndex();
indexResponse.getMappings().forEach((k, v) -> System.out.println(v.getSourceAsMap()));
}
详细结果
{properties={image={type=keyword},
sold={type=keyword},
createTime={format=yyyy-MM-dd HH:mm:ss, type=date},
price={type=integer},
name={search_analyzer=ik_max_word,
analyzer=ik_smart, type=text},
updateTime={format=yyyy-MM-dd HH:mm:ss, type=date},
category={type=keyword},
isAD={type=boolean},
stock={type=integer},
brand={type=keyword},
spec={type=keyword},
commentCount={type=keyword}}}测试更新索引
刷新获取索引分片数
java
@Test
@DisplayName("测试索引更新")
void testUpdateIndex(){
Integer refresh = itemDocMapper.refresh();
System.out.println("返回刷新成功分片数:" + refresh);
}控制台结果

更新索引结构
es索引创建好了之后,不能直接更新某个索引字段,我们测试的更新就是,新增加一个es索引字段。
我现在 ItemDoc中新增了一个属性
java
// 新增一个字段
private Long creater;
java
@Test
@DisplayName("测试索引更新索引结构")
void UpdateIndex(){
LambdaEsIndexWrapper<ItemDoc> esWrapper = new LambdaEsIndexWrapper<>();
String indexName = ItemDoc.class.getSimpleName().toLowerCase();
//指定更新那个索引
esWrapper.indexName(indexName);
esWrapper.mapping(ItemDoc::getCreater, FieldType.LONG);
//更新索引
Boolean aBoolean = itemDocMapper.updateIndex(esWrapper);
System.out.println("更新索引是否成功:" + aBoolean);
}控制台结果

在kibana查看下

Es文档CRUD
新增单个es文档
上面已经完成了使用easy-es,快速的完成对 es索引的 crud操作。下面就开始往里面存储数据了。
java
@Test
@DisplayName("向es索引种新增文档")
void testCreateDoc(){
//根据id查询一条数据库里面的数据
Item item = itemMapper.selectById("317578L");
//转换成itemDoc对象
ItemDoc itemDoc = BeanUtil.toBean(item, ItemDoc.class);
//向索引中新增一条数据
Integer rows = itemDocMapper.insert(itemDoc);
System.out.println("新增文档成功,受影响的行数:" + rows);
}
在kibana看下
java
# 查看文档
GET /itemdoc/_doc/317578
批量新增es文档
可以一次新增多条数据到es索引中
java
@Test
@DisplayName("批量新增es文档")
void testBatchInsertDoc(){
//查询数据库中类目是硬盘的商品数据
LambdaQueryWrapper<Item> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Item::getCategory, "硬盘");
List<Item> itemList = itemMapper.selectList(wrapper);
System.out.println("查询到类目为 硬盘的数据量:" + itemList.size() + "条");
//批量转换为itemDoc对象
List<ItemDoc> itemDocList = BeanUtil.copyToList(itemList, ItemDoc.class);
//批量新增es文档
Integer rows = itemDocMapper.insertBatch(itemDocList);
System.out.println("向es索引中新增了 " + rows + " 条数据");
}查看下控制台

在kibana中查看下

删除单个es文档
可以新增es文档,当然我们也就可以删除es文档。
java
@Test
@DisplayName("根据id删除es索引中的文档")
void testDeleteDoc(){
Integer rows = itemDocMapper.deleteById("317578");
System.out.println(rows > 0 ? "删除成功 删除了" + rows +"条" : "删除失败");
}控制台

在kibana查询下

批量删除es文档
我们可以一个一个的删除索引中的文档,当然也可以进行删除多个的操作,就是批量删除。
java
@Test
@DisplayName("批量删除es索引中的文档")
void testBatchDeleteDoc(){
//查询数据库中类目是硬盘的商品数据,只查询100条
IPage<Item> page = new Page<>(1, 100);
LambdaQueryWrapper<Item> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Item::getCategory, "硬盘");
IPage<Item> itemIPage = itemMapper.selectPage(page, wrapper);
System.out.println("查询到类目为 硬盘的数据量:" + itemIPage.getSize() + "条");
//提取里面的id,转换成集合。
List<Long> itemIdList = itemIPage.getRecords().stream().map(Item::getId).collect(Collectors.toList());
//批量删除
Integer rows = itemDocMapper.deleteBatchIds(itemIdList);
System.out.println("删除了 " + rows + " 条数据");
}控制台

kibana中查看,现在数据为 198条了。

查询单个es文档
java
@Test
@DisplayName("根据id查询es索引中的文档")
void testSelectDocById(){
ItemDoc itemDoc = itemDocMapper.selectById("317578");
System.out.println(itemDoc);
}
批量查询es文档
所谓的批量查询其实就是按照条件查询,这俩我就演示一种,后面根据 LambdaEsQueryWrapper 构造条件查询的时候,在过多的说下。
java
@Test
@DisplayName("批量查询es文档")
void testBatchSelectDoc(){
//查询数据库中类目是硬盘的商品数据,只查询100条
IPage<Item> page = new Page<>(1, 100);
LambdaQueryWrapper<Item> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Item::getCategory, "硬盘");
IPage<Item> itemIPage = itemMapper.selectPage(page, wrapper);
System.out.println("查询到类目为 硬盘的数据量:" + itemIPage.getSize() + "条");
//转换成id集合
List<Long> idList = itemIPage.getRecords().stream().map(Item::getId).collect(Collectors.toList());
//批量查询
List<ItemDoc> itemDocList = itemDocMapper.selectBatchIds(idList);
System.out.println("查询到es索引中文档的数据量:" + itemDocList.size());
}控制台

修改单个es文档
java
@Test
@DisplayName("根据id更新es索引中的文档")
void testUpdateDoc(){
//查询现有的数据
ItemDoc itemDoc = itemDocMapper.selectById("317578");
//在现有数据基础上更改一些值
itemDoc.setBrand("SDE品牌");
itemDoc.setCreateTime(LocalDateTime.now());
//发送更新请求
Integer rows = itemDocMapper.updateById(itemDoc);
System.out.println(rows > 0 ? "更新成功" : "更新失败");
}
在kibana控制台查看

批量修改es文档
java
@Test
@DisplayName("批量修改es文档")
void testBatchUpdateDoc(){
//查询数据库中类目是硬盘的商品数据,只查询100条
IPage<Item> page = new Page<>(1, 100);
LambdaQueryWrapper<Item> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Item::getCategory, "硬盘");
IPage<Item> itemIPage = itemMapper.selectPage(page, wrapper);
System.out.println("查询到类目为 硬盘的数据量:" + itemIPage.getSize() + "条");
List<Item> itemList = itemIPage.getRecords();
//这里把这100条数据的name从 0 加到了 99
for (int i = 0; i < itemIPage.getSize(); i++) {
itemList.get(i).setName(itemList.get(i).getName()+">=" + i);
}
//转换成itemDoc对象
List<ItemDoc> itemDocList = BeanUtil.copyToList(itemList, ItemDoc.class);
//批量修改
Integer rows = itemDocMapper.updateBatchByIds(itemDocList);
System.out.println("修改了 " + rows + " 条数据");
}控制台效果

在kibana中查看下

数据同步
就比如我们在进行数据迁移的时候,想把MySQL数据库里面的数据,同步到es中。但是MySQL数据库中的数据也有很多,我们不能一次insert太多数据吧,就要分批次的同步数据到es中。
java
@Test
@DisplayName("分批次同步数据")
void testBatchSyncData(){
Integer pageNum = 1;
Integer pageSize = 2000;
Integer total = 0;
//构建分页条件
IPage<Item> page = new Page<>(pageNum, pageSize);
long startTime = System.currentTimeMillis();
while (true){
//分页查询
IPage<Item> itemIPage = itemMapper.selectPage(page, null);
//如果查询不到数据就终止循环
if (CollUtil.isEmpty(itemIPage.getRecords())){
break;
}
//转换成itemDoc对象
List<ItemDoc> itemDocList = BeanUtil.copyToList(itemIPage.getRecords(), ItemDoc.class);
//批量新增es文档
itemDocMapper.insertBatch(itemDocList);
total += itemIPage.getRecords().size();
//下一页
pageNum++;
//更新Page对象的页码
page.setCurrent(pageNum);
}
long endTime = System.currentTimeMillis();
System.out.println("数据同步到Es索引成功!同步了 " + total + " 条数据。" + "执行耗时:" + (endTime - startTime) / 1000 + "秒" );
}控制台查看下

在kibana中查看下

查询条件构造器
LambdaEsQueryWrapper 此条件构造器主要用于查询时对条件的封装,其使用和mp类似。
allEq
顾名思义就是要符合全部的条件
方法说明
java
allEq(Map<R, V> params)params:key为数据库(es索引字段)字段名,value为字段值。
java
@Test
@DisplayName("测试查询条件的allEq")
public void testAllEq() {
// 查询类目(category)是牛奶 并且品牌(brand)是德亚 的商品
Map<String, Object> params = new HashMap<>();
params.put("category", "牛奶");
params.put("brand", "欧德堡");
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper.allEq(params);
//查询数据
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类名是:" + params.get("category") + "品牌是:" + params.get("brand") +"的商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台输出

kibana控制台
java
# 查询类目是牛奶,品牌是 欧德堡 德商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "牛奶"
}
}
},
{
"term": {
"brand": {
"value": "欧德堡"
}
}
}
]
}
}
}
Eq
等于 =
例: eq("name","sde") ---> name = 'sde'
语法
java
eq(R column, Object val)
eq(boolean condition, R column, Object val)示例
java
@Test
@DisplayName("测试查询条件的eq")
public void testEq() {
//查询类目是牛奶 并且品牌是德亚 的商品
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper.eq(ItemDoc::getCategory,"牛奶");
esWrapper.eq(ItemDoc::getBrand,"德亚");
//查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类名是:牛奶 品牌是:德亚 的商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是牛奶,品牌是 德亚 德商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "牛奶"
}
}
},
{
"term": {
"brand": {
"value": "德亚"
}
}
}
]
}
}
}
gt
大于 >
例:gt("age",18) ---> age > 18
语法
java
gt(R column, Object val)
gt(boolean condition, R column, Object val)示例
java
@Test
@DisplayName("测试查询条件的gt")
public void testGt() {
//查询类目是 拉杆箱 品牌是 莎米特 价格 大于 200元的 商品
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"拉杆箱")
.eq(ItemDoc::getBrand,"莎米特")
.gt(ItemDoc::getPrice,20000); //因为存储在es的单位是 (分),所以需要转换一下 就是 2万分
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类名是:拉杆箱 品牌是:莎米特 价格 大于 200元的 商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana控制台
java
# 查询类目是拉杆箱,品牌是 莎米特价格大于 200元 德商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "拉杆箱"
}
}
},
{
"term": {
"brand": {
"value": "莎米特"
}
}
},
{
"range": {
"price": {
"gt": 20000
}
}
}
]
}
}
}
ge
大于等于 >=
例:ge("age",18) ---> age >= 18
语法
java
gt(R column, Object val)
gt(boolean condition, R column, Object val)示例
java
@Test
@DisplayName("测试查询条件的ge")
public void testGe() {
//查询类目是 拉杆箱 品牌是 莎米特 价格 大于等于 140元的 商品
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"拉杆箱")
.eq(ItemDoc::getBrand,"莎米特")
.ge(ItemDoc::getPrice,14000);
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类名是:拉杆箱 品牌是:莎米特 价格 大于等于 140元的 商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是拉杆箱,品牌是 莎米特价格大于 140元 德商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "拉杆箱"
}
}
},
{
"term": {
"brand": {
"value": "莎米特"
}
}
},
{
"range": {
"price": {
"gte": 14000
}
}
}
]
}
}
}同样也是查到了 211 条数据


lt
小于 <
例:lt("age",18) ---> age < 18
语法
java
lt(R column, Object val)
lt(boolean condition, R column, Object val)示例
java
@Test
@DisplayName("测试查询条件的lt")
public void testLt() {
//查询类目是手机 品牌是 Apple 价格小于 5000元的 商品
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","手机");
params.put("brand","Apple");
esWrapper.allEq(params)
.lt(ItemDoc::getPrice,500000);
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目名是:"+params.get("category")+" 品牌是:"+params.get("brand")+" 价格小于 5000元的 商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是手机,品牌是 Apple 价格小于 5000元 的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "手机"
}
}
},
{
"term": {
"brand": {
"value": "Apple"
}
}
},
{
"range": {
"price": {
"lt": 500000
}
}
}
]
}
}
}
le
小于等于 <=
例:le("age",18) ---> age <= 18
语法
java
le(R column, Object val)
le(boolean condition, R column, Object val)示例
java
@Test
@DisplayName("测试查询条件的le")
public void testLe() {
// 查询类目是手机 品牌是 Apple 价格小于等于 6531元的 商品
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","手机");
params.put("brand","Apple");
esWrapper.allEq(params)
.le(ItemDoc::getPrice,653100);
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目名是:"+params.get("category")+" 品牌是:"+params.get("brand")+" 价格小于等于 6531元的 商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是手机,品牌是 Apple 价格小于 628900元 的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "手机"
}
}
},
{
"term": {
"brand": {
"value": "Apple"
}
}
},
{
"range": {
"price": {
"lte": 628900
}
}
}
]
}
}
}
between
between 值1 and 值2
例:between("age",18,28) ---> age between 18 and 28
语法
java
between(R column, Object val1, Object val2)
between(boolean condition, R column, Object val1, Object val2)示例
java
@Test
@DisplayName("测试查询条件的between")
public void testBetween() {
//查询类目是 牛奶 品牌是欧德堡 价格在 30 到 300 之间的商品
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","牛奶");
params.put("brand","欧德堡");
esWrapper.allEq(params)
.between(ItemDoc::getPrice,4000,30000);
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目名是:"+params.get("category")+" 品牌是:"+params.get("brand")+" 价格在 50 到 100 之间的商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是牛奶,品牌是 欧德堡 价格在 40 到 300元 的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "牛奶"
}
}
},
{
"term": {
"brand": {
"value": "欧德堡"
}
}
},
{
"range": {
"price": {
"gte": 4000,
"lte": 30000
}
}
}
]
}
}
}
like
like '%值%'
例:like("name","德亚") ---> name like '%德亚%'
语法
java
between(R column, Object val1, Object val2)
between(boolean condition, R column, Object val1, Object val2)示例
java
@Test
@DisplayName("测试查询条件的like")
public void testLike() {
//查询类目是 牛奶 品牌是 德亚 ,sku名称中包含 脱脂 的商品
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","牛奶");
params.put("brand","德亚");
esWrapper.allEq(params)
.like(ItemDoc::getName,"脱脂");
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目名是:"+params.get("category")+" 品牌是:"+params.get("brand")+" sku名称中包含 脱脂 的商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是牛奶,品牌是 亚德 sku名称包含 脱脂 的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "牛奶"
}
}
},
{
"term": {
"brand": {
"value": "德亚"
}
}
},
{
"match": {
"name": "脱脂"
}
}
]
}
}
}
likeLeft
like '%值'
例:likeLeft("name","减") ---> name like "%减"
语法
java
likeLeft(R column, Object val)
likeLeft(boolean condition, R column, Object val)示例
java
@Test
@DisplayName("测试查询条件的likeLeft")
public void testLikeLeft() {
//查询类目是 牛奶 品牌是 德亚 ,sku名称中以 减 开头的商品
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","牛奶");
params.put("brand","德亚");
esWrapper.allEq(params)
.likeLeft(ItemDoc::getName,"减");
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目名是:"+params.get("category")+" 品牌是:"+params.get("brand")+" sku名称中以 减 开头的商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是牛奶,品牌是 亚德 sku名称以 减 开头的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "牛奶"
}
}
},
{
"term": {
"brand": {
"value": "德亚"
}
}
},
{
"prefix": {
"name": "减"
}
}
]
}
}
}
likeRight
like '值%'
例:likeRight("name","低")
语法
java
likeRight(R column, Object val)
likeRight(boolean condition, R column, Object val)示例
java
@Test
@DisplayName("测试查询条件的likeRight")
public void testLikeRight() {
//查询类目是 牛奶 品牌是 德亚 ,sku名称中以 低 结尾的商品
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","牛奶");
params.put("brand","德亚");
esWrapper.allEq(params)
.likeRight(ItemDoc::getName,"低");
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目名是:"+params.get("category")+" 品牌是:"+params.get("brand")+" sku名称中以 低 结尾的商品,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是牛奶,品牌是 亚德 sku名称以 低 结尾的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "牛奶"
}
}
},
{
"term": {
"brand": {
"value": "德亚"
}
}
},
{
"regexp": {
"name": "低"
}
}
]
}
}
}
isNotNull
字段 is not null 就是字段的值 不为 null
例:isNotNull("ItemDoc::getName") ---> name is not null
语法
java
isNotNull(R column)
isNotNull(boolean condition, R column)示例
java
@Test
@DisplayName("测试查询条件的is not null")
public void testIsNotNull() {
//查询类目是 牛奶 品牌是 德亚 商品名称 不为null的商品信息
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","牛奶");
params.put("brand","德亚");
esWrapper.allEq(params)
.isNotNull(ItemDoc::getName);
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目名是:"+params.get("category")+" 品牌是:"+params.get("brand")+" 商品名称 不为null的商品信息,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是牛奶,品牌是 亚德 商品名称 不为null的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "牛奶"
}
}
},
{
"term": {
"brand": {
"value": "德亚"
}
}
},
{
"exists": {
"field": "name"
}
}
]
}
}
}
exists
功能和 is not null 一样
语法
java
exists(R column)
exists(boolean condition, R column)示例
java
@Test
@DisplayName("测试查询条件的exists")
public void testExists() {
//查询类目是 牛奶 品牌是 德亚 商品名称 不为null的商品信息
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","牛奶");
params.put("brand","德亚");
esWrapper
.allEq(params)
.exists("name");
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目名是:"+params.get("category")+" 品牌是:"+params.get("brand")+" 商品名称 不为null的商品信息,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是牛奶,品牌是 亚德 商品名称 不为null的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "牛奶"
}
}
},
{
"term": {
"brand": {
"value": "德亚"
}
}
},
{
"exists": {
"field": "name"
}
}
]
}
}
}
in
字段 in (value.get(0),value.get(1),...)
例:in("age",1,2,3) ---> age in(1,2,3)
语法
java
in(R column, Collection<?> value)
in(boolean condition, R column, Collection<?> value)示例
java
@Test
@DisplayName("测试查询条件的in")
public void testIn() {
//查询类目是 拉杆箱 品牌是 旅行之家 和 宾豪 的商品信息
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"拉杆箱")
.in(ItemDoc::getBrand,"旅行之家","宾豪");
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
System.out.println("类目是 拉杆箱 品牌是 旅行之家 和 宾豪 的商品信息,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是拉杆箱,品牌是 旅行之家 和 宾豪 的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": "拉杆箱"
}
},
{
"terms": {
"brand": [
"旅行之家",
"宾豪"
]
}
}
]
}
}
}
groupBy
分组:group by 字段、...
例:groupBy(ItemDoc::getCategory,ItemDoc::getBrand) ---> group by category,brand
java
@Test
@DisplayName("测试查询条件的group by")
public void testGroupBy() {
// 查询类目是 拉杆箱,品牌是 旅行之家 和 宾豪 的商品信息,根据品牌分组
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"拉杆箱")
.in(ItemDoc::getBrand,"旅行之家","宾豪")
.groupBy(ItemDoc::getBrand);
// 执行查询
Long count = itemDocMapper.selectCount(esWrapper);
System.out.println("根据品牌分组,查询到了 " + count + " 条数据");
}控制台

kibana
java
# 查询类目是拉杆箱,品牌是 旅行之家 和 宾豪 根据品牌分组
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": "拉杆箱"
}
},
{
"terms": {
"brand": [
"旅行之家",
"宾豪"
]
}
}
]
}
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
}
}
},
"size": 0
} 
orderByDesc
排序:order by 字段,... desc
例: orderByDesc(Document::getId,Document::getTitle)--->order by id DESC,title DESC
语法
java
orderByDesc(R... columns)
orderByDesc(boolean condition, R... columns)示例
java
@Test
@DisplayName("测试查询条件的orderByDesc")
public void testOrderByDesc() {
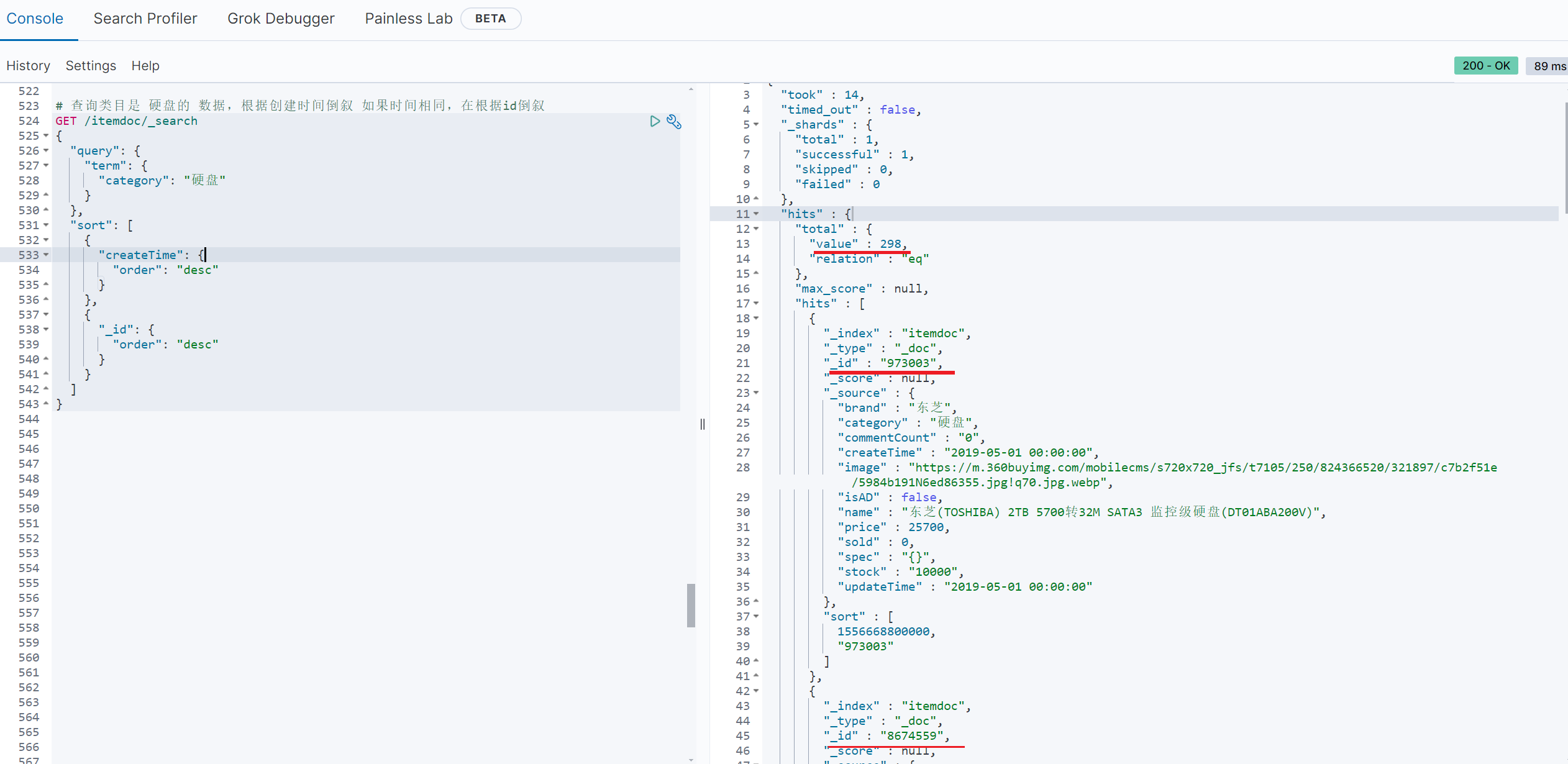
//查询类目是 硬盘的 数据,根据创建时间倒叙 如果时间相同,在根据id倒叙
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"硬盘")
.orderByDesc(ItemDoc::getCreateTime)
.orderByDesc(ItemDoc::getId);
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
//我们就取前5条看看是不是根据创建时间倒叙
for (int i = 0; i < 5; i++) {
System.out.println("第 " + (i+1) + " 条数据:ID是" +itemDocList.get(i).getId() + ",创建时间:"+itemDocList.get(i).getCreateTime());
}
System.out.println("类目是 硬盘的 数据,根据创建时间倒叙,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是 硬盘的 数据,根据创建时间倒叙 如果时间相同,在根据id倒叙
GET /itemdoc/_search
{
"query": {
"term": {
"category": "硬盘"
}
},
"sort": [
{
"createTime": {
"order": "desc"
}
},
{
"_id": {
"order": "desc"
}
}
]
}
from
从第几条数据开始查询,相当于MySQL中limit (m,n)中的m.
例: from(10)--->从第10条数据开始查询
语法
java
from(Integer from)示例
java
@Test
@DisplayName("测试查询条件的from")
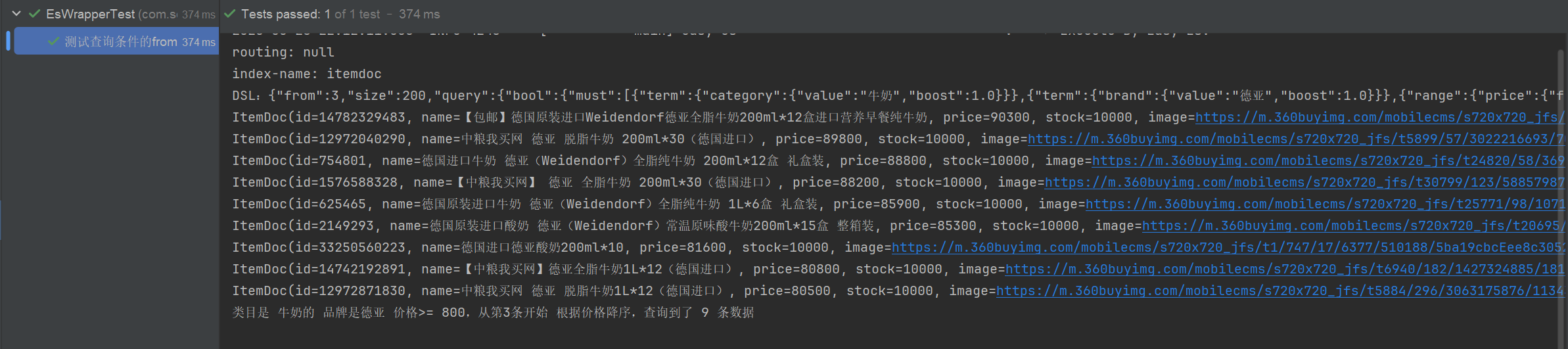
public void testFrom() {
//查询类目是 牛奶的 品牌是德亚 价格>= 800,从第3条开始 根据价格降序
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","牛奶");
params.put("brand","德亚");
esWrapper
.allEq(params)
.ge(ItemDoc::getPrice,80000)
.from(3)
.size(200)
.orderByDesc(ItemDoc::getPrice);
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("类目是 牛奶的 品牌是德亚 价格>= 800,从第3条开始 根据价格降序,查询到了 " + itemDocList.size() + " 条数据");
}控制台
kibana
java
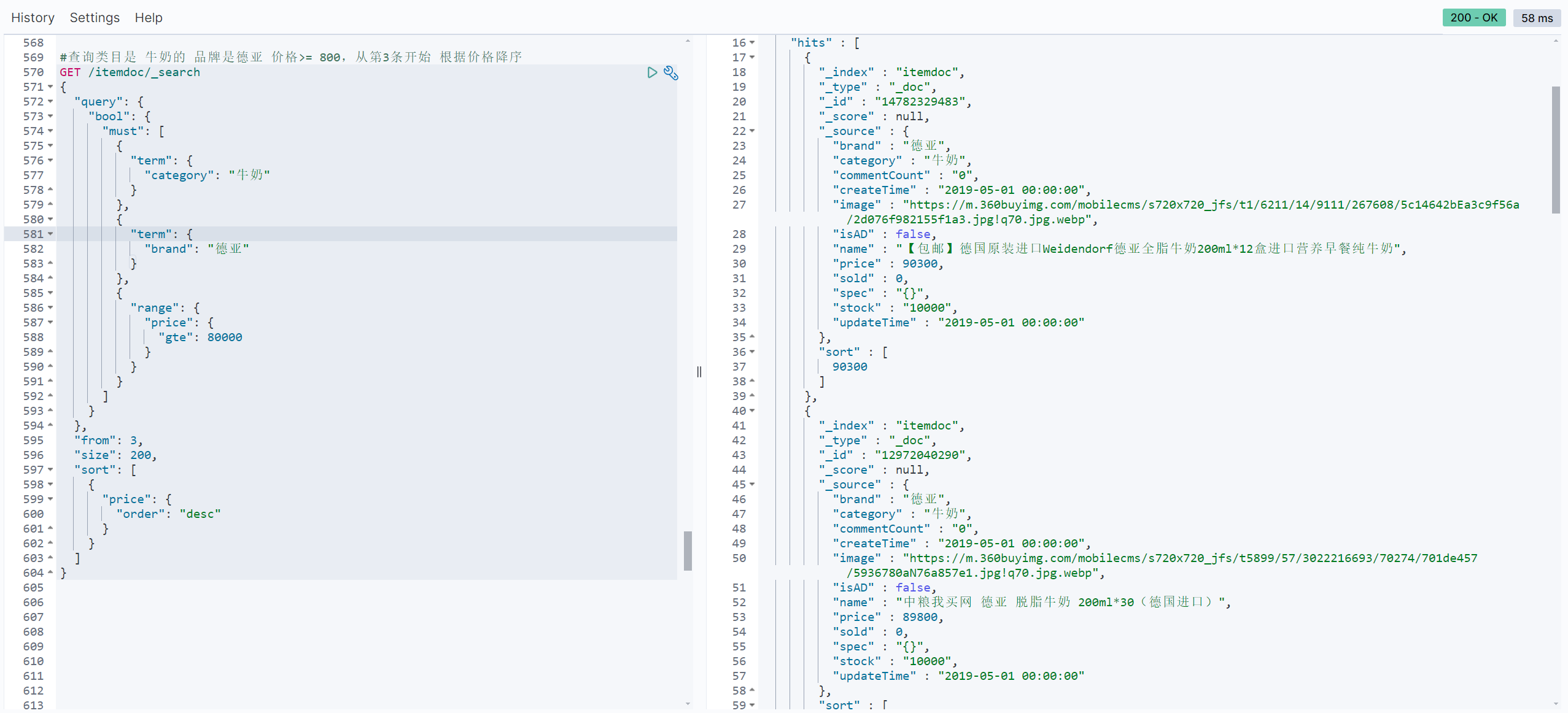
#查询类目是 牛奶的 品牌是德亚 价格>= 800,从第3条开始 根据价格降序
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": "牛奶"
}
},
{
"term": {
"brand": "德亚"
}
},
{
"range": {
"price": {
"gte": 80000
}
}
}
]
}
},
"from": 3,
"size": 200,
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
size
最多返回多少条数据,相当于MySQL中limit (m,n)中的n 或limit n 中的n
例: size(10)--->最多只返回10条数据
语法
java
size(Integer size)示例
java
@Test
@DisplayName("测试查询条件的size")
public void testSize() {
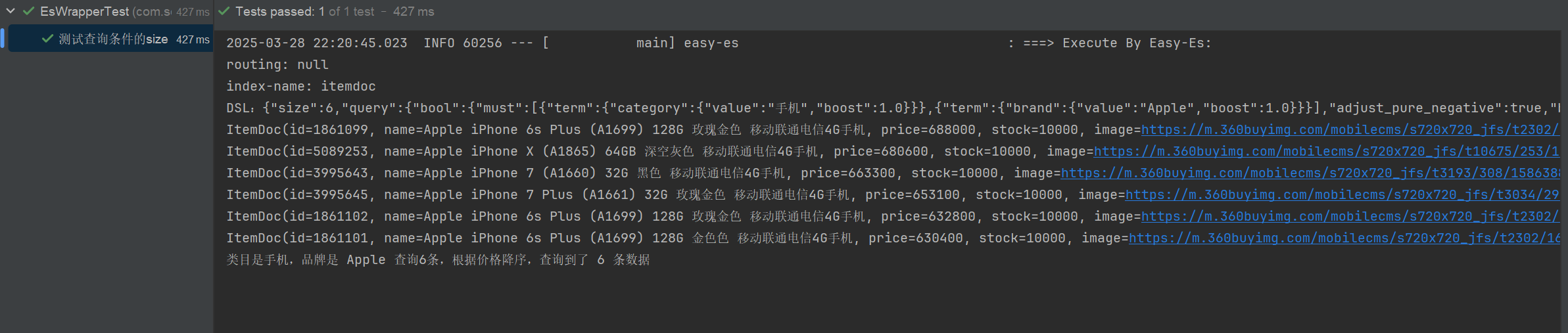
//查询类目是手机,品牌是 Apple 查询6条,根据价格降序
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"手机")
.eq(ItemDoc::getBrand,"Apple")
.size(6)
.orderByDesc(ItemDoc::getPrice);
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("类目是手机,品牌是 Apple 查询6条,根据价格降序,查询到了 " + itemDocList.size() + " 条数据");
}控制台
kibana
java
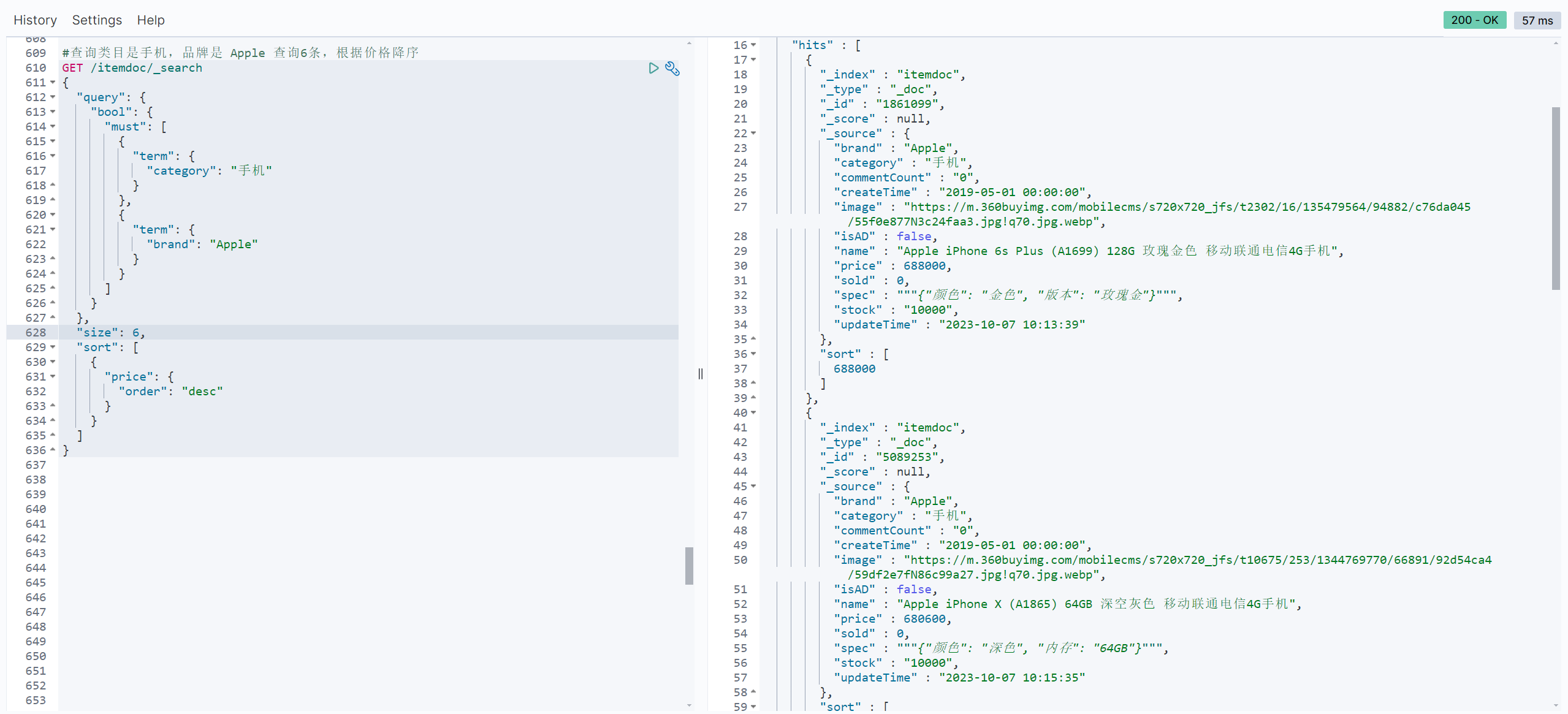
#查询类目是手机,品牌是 Apple 查询6条,根据价格降序
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": "手机"
}
},
{
"term": {
"brand": "Apple"
}
}
]
}
},
"size": 6,
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
limit
limit n 最多返回多少条数据,相等于mysql中的 limit n 中的 n,用法一样。
limit m,n 跳过m条数据,最多返回n条数据,相当于MySQL中的limit m,n 或 offset m limit n
例: limit(10)--->最多只返回10条数据
例: limit(2,5)--->跳过前2条数据,从第3条开始查询,总共查询5条数据
注意:n参数若不指定,则其默认值是10000 如果你单次查询超过1W条,建议采用分页(参考后面分页章节),万不得已非要在这里指定超过1w,比如指定2w,需要在查询的实体类上加上注解@IndexName(maxResultWindow=20000) 指定其maxResultWindow,并重建索引,否则es会报错,这是es的规则,它作此限制应该是为了保护你的内存防止溢出. 如果你单次查询,不想要太多得分较低的数据,需要手动指定n去做限制. 另外此参数作用与Es中的size,from一致,只是为了兼容MySQL语法而引入,使用者可以根据自身习惯二选一,当两种都用时,只有一种会生效,后指定的会覆盖先指定的。
语法
java
limit(Integer n);
limit(Integer m, Integer n);示例
java
@Test
@DisplayName("测试查询条件的limit")
public void testLimit() {
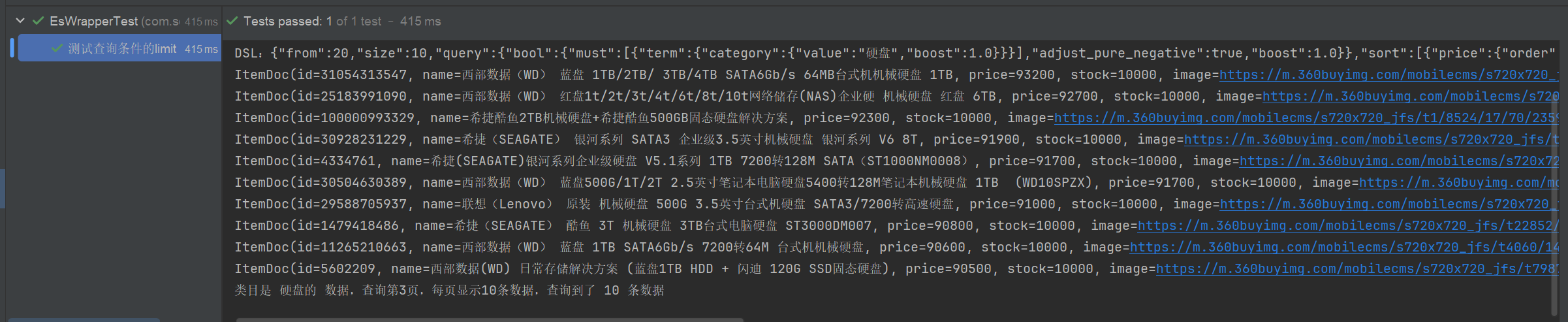
//查询类目是 硬盘的 数据,查询第3页,每页显示10条数据。
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"硬盘")
.limit(20,10)
.orderByDesc(ItemDoc::getPrice);
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("类目是 硬盘的 数据,查询第3页,每页显示10条数据,查询到了 " + itemDocList.size() + " 条数据");
}控制台
kibana
java
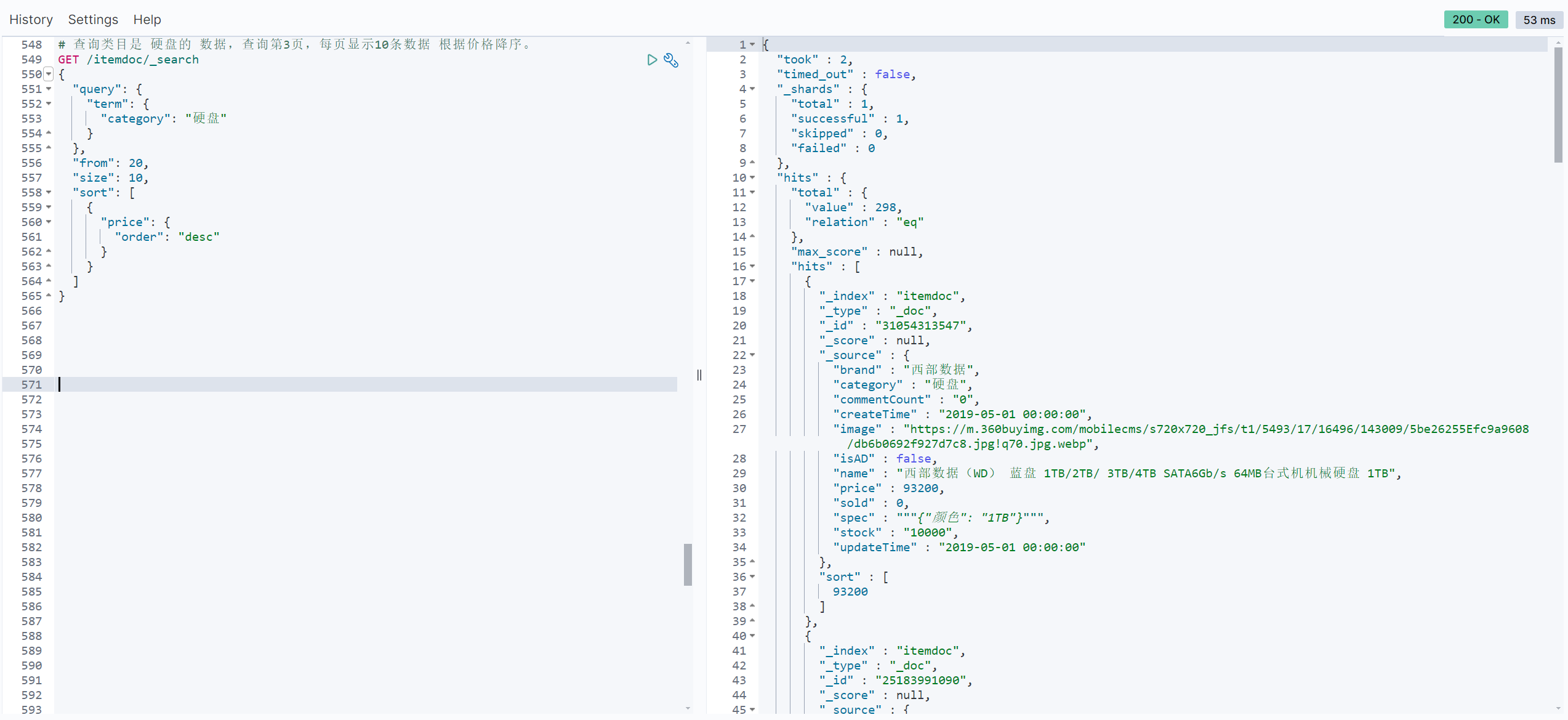
# 查询类目是 硬盘的 数据,查询第3页,每页显示10条数据 根据价格降序。
GET /itemdoc/_search
{
"query": {
"term": {
"category": "硬盘"
}
},
"from": 20,
"size": 10,
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
minScore
查询得分不低于score的数据,如果得分低于此值,则不被命中
语法
java
minScore(Float score)示例
java
@Test
@DisplayName("测试查询条件的minScore")
public void testMinScore() {
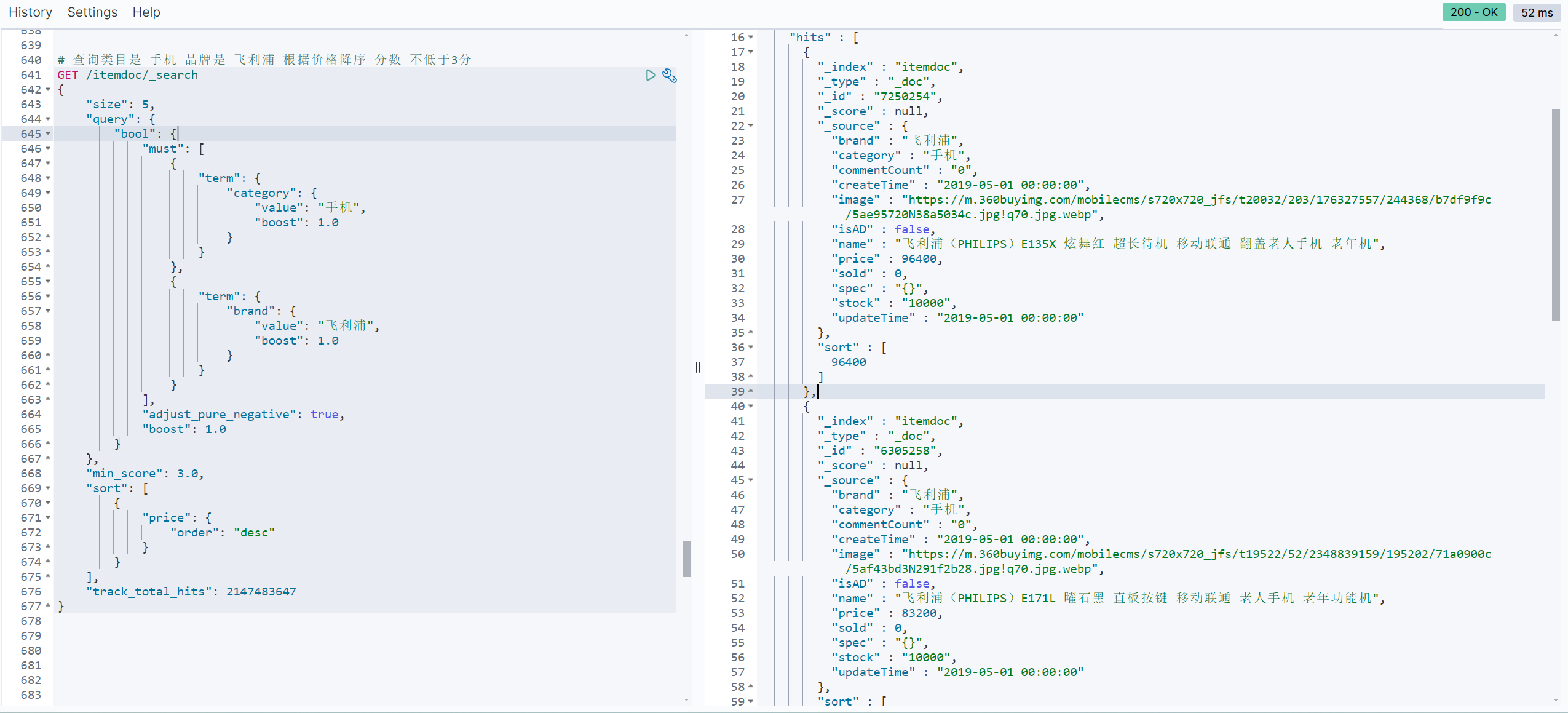
//查询类目是 手机 品牌是 飞利浦 根据价格降序 分数 不低于3分
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"手机")
.eq(ItemDoc::getBrand,"飞利浦")
.orderByDesc(ItemDoc::getPrice)
.limit(5)
.minScore(3.0F);
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("类目是 手机 品牌是 飞利浦 根据价格降序 分数 不低于3分,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是 手机 品牌是 飞利浦 根据价格降序 分数 不低于3分
GET /itemdoc/_search
{
"size": 5,
"query": {
"bool": {
"must": [
{
"term": {
"category": {
"value": "手机",
"boost": 1.0
}
}
},
{
"term": {
"brand": {
"value": "飞利浦",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"min_score": 3.0,
"sort": [
{
"price": {
"order": "desc"
}
}
],
"track_total_hits": 2147483647
}
and
AND
例: and(i -> i.eq(Document::getTitle, "Hello").eq(Document::getCreator, "Guy"))--->and (title ='Hello' and creator = 'Guy' )
语法
java
and(Consumer<Param> consumer)
and(boolean condition, Consumer<Param> consumer)示例
java
@Test
@DisplayName("测试查询条件的and")
public void testAnd() {
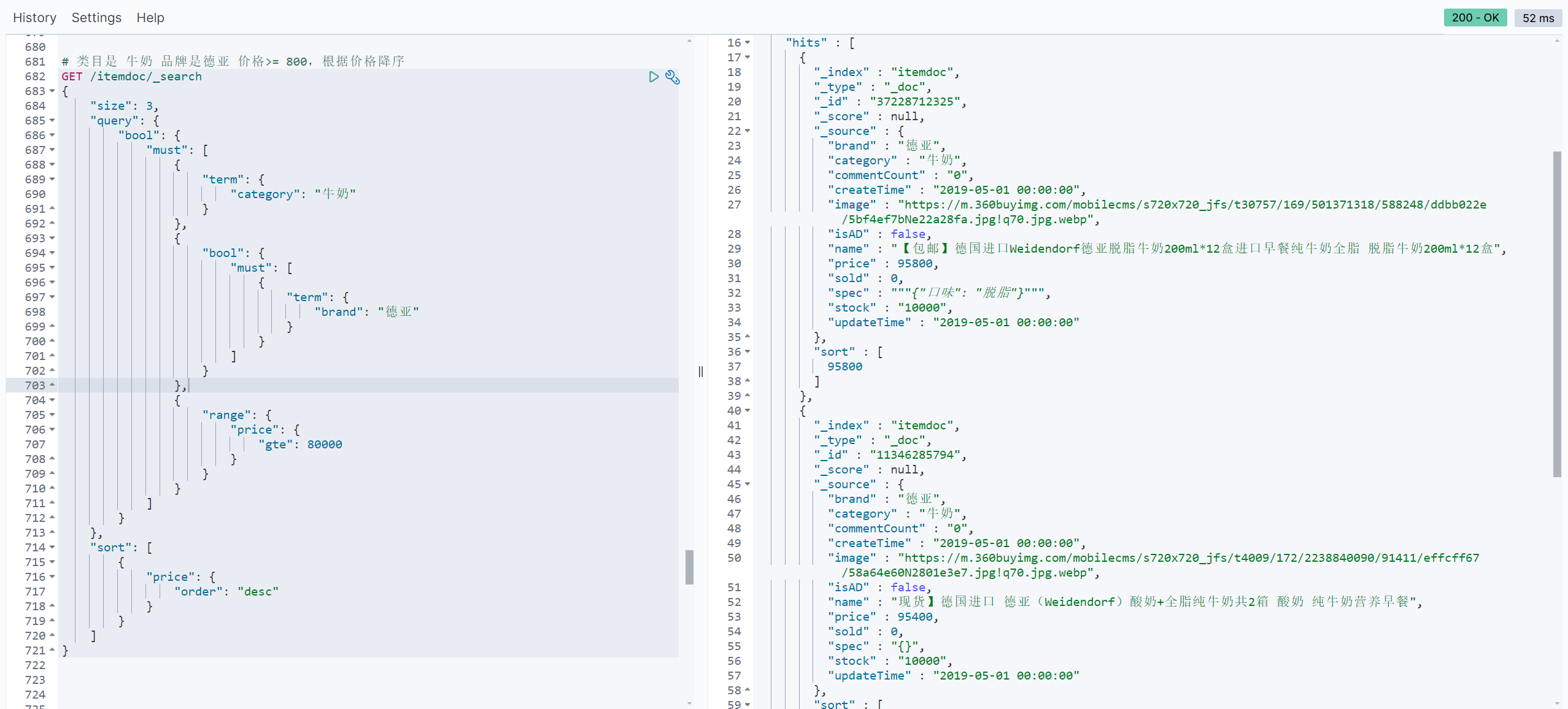
//类目是 牛奶 品牌是德亚 价格>= 800,根据价格降序
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper.eq(ItemDoc::getCategory,"牛奶")
.and(wrapper -> wrapper.eq(ItemDoc::getBrand,"德亚"))
.ge(ItemDoc::getPrice,80000)
.limit(3)
.orderByDesc(ItemDoc::getPrice);
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("类目是 牛奶 品牌是德亚 价格>= 800,根据价格降序,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 类目是 牛奶 品牌是德亚 价格>= 800,根据价格降序
GET /itemdoc/_search
{
"size": 3,
"query": {
"bool": {
"must": [
{
"term": {
"category": "牛奶"
}
},
{
"bool": {
"must": [
{
"term": {
"brand": "德亚"
}
}
]
}
},
{
"range": {
"price": {
"gte": 80000
}
}
}
]
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
or
拼接 OR 注意事项: 主动调用or表示紧接着下一个方法不是用and连接!(不调用or则默认为使用and连接)
例: eq("Document::getId",1).or().eq(Document::getTitle,"Hello")--->id = 1 or title ='Hello'
语法
java
or()
or(boolean condition)示例
java
@Test
@DisplayName("测试查询条件的or")
public void testOr() {
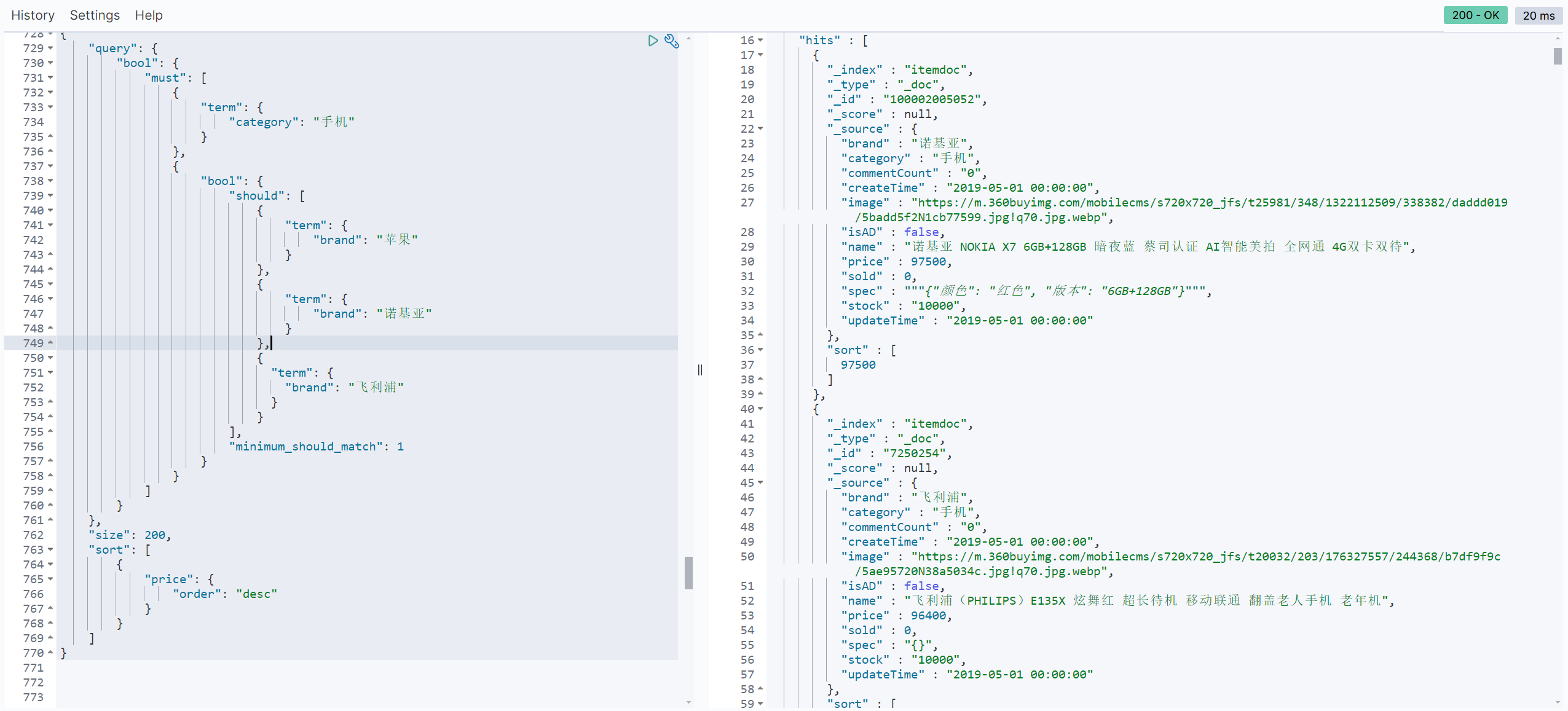
//类目是手机 品牌是 Apple 或者 诺基亚 或者 飞利浦 根据价格降序
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"手机")
.and(
i -> i.eq(ItemDoc::getBrand,"飞利浦")
.or()
.eq(ItemDoc::getBrand,"Apple")
.or()
.eq(ItemDoc::getBrand,"诺基亚")
)
.size(200)
.orderByDesc(ItemDoc::getPrice);
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("类目是手机 品牌是 Apple 或者 诺基亚 或者 飞利浦 根据价格降序,查询到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
#类目是手机 品牌是 Apple 或者 诺基亚 或者 飞利浦 根据价格降序
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": "手机"
}
},
{
"bool": {
"should": [
{
"term": {
"brand": "苹果"
}
},
{
"term": {
"brand": "诺基亚"
}
},
{
"term": {
"brand": "飞利浦"
}
}
],
"minimum_should_match": 1
}
}
]
}
},
"size": 200,
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
更新条件构造器
LambdaEsUpdateWrapper
此条件构造器主要用于更新数据时所需要更新字段及其值或者查询条件的封装。
其中查询条件的封装与LambdaEsQueryWrapper 中提供的方法一致,不一样的只有set方法。
set
SQL SET 字段
例: set("name", "老李头")
例: set("name", "")--->数据库字段值变为空字符串
例: set("name", null)--->数据库字段值变为null
语法
java
set(String column,Object val)
set(boolean condition,String column,Object val)示例1
java
@Test
@DisplayName("测试根据条件更新和实体对象更新")
public void testUpdate1() {
// 更新类目是拉杆箱 品牌是 RIMOWA 价格等于 289元的商品信息
LambdaEsUpdateWrapper<ItemDoc> esWrapper = new LambdaEsUpdateWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"拉杆箱")
.eq(ItemDoc::getBrand,"RIMOWA")
.eq(ItemDoc::getPrice,28900);
//创建ItemDoc对象,设置更新内容
ItemDoc itemDoc = new ItemDoc();
itemDoc.setName("RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4 更新数据");
itemDoc.setStock("9999");
//执行更新
int result = itemDocMapper.update(itemDoc, esWrapper);
System.out.println(result > 0 ? "更新成功" : "更新失败");
//查询更新后的商品
ItemDoc NewitemDoc = itemDocMapper.selectOne(esWrapper);
System.out.println("更新后:" + NewitemDoc);
}控制台

kibana
java
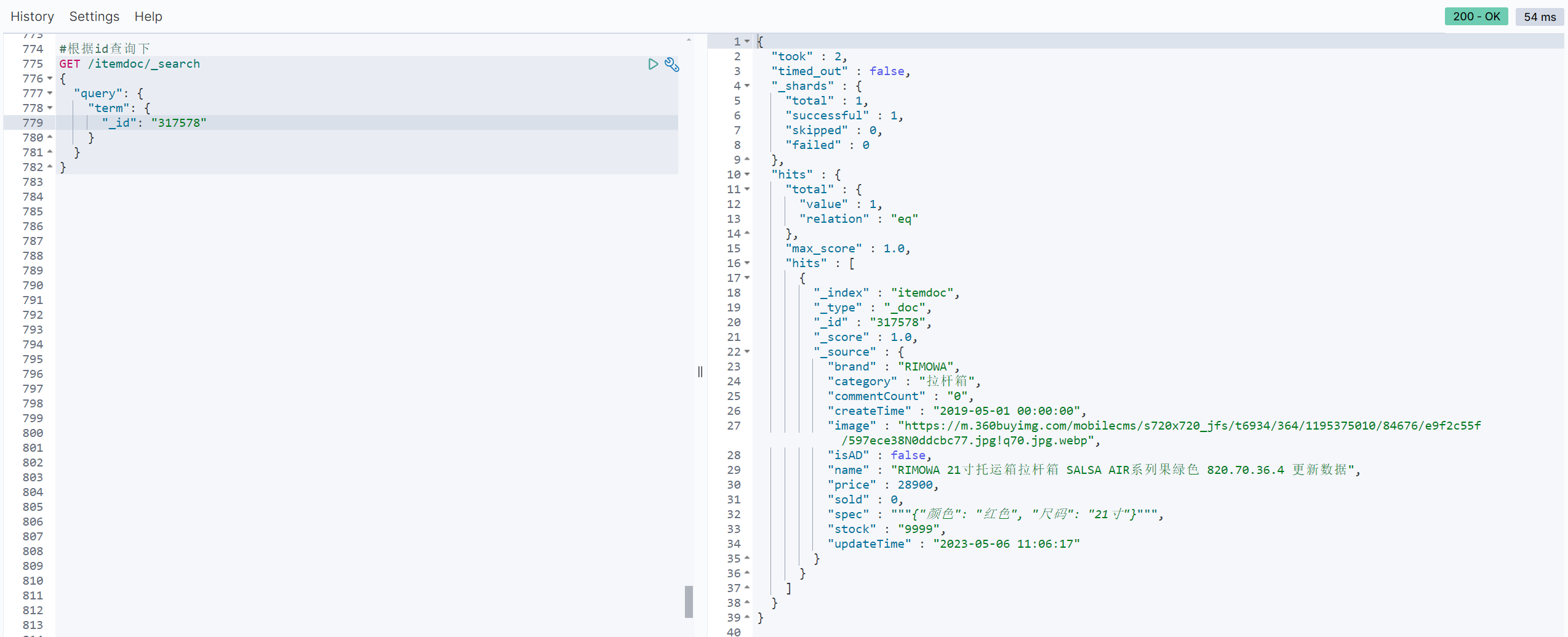
#根据id查询下
GET /itemdoc/_search
{
"query": {
"term": {
"_id": "317578"
}
}
}
示例2
java
@Test
@DisplayName("测试省略实体的简单写法")
public void testUpdate2() {
//更新类目是 拉拉裤 品牌是 花王 价格是 389元的商品信息
//构建更新条件
LambdaEsUpdateWrapper<ItemDoc> esWrapper = new LambdaEsUpdateWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("category","拉拉裤");
params.put("brand","花王");
params.put("price",38900);
esWrapper
.allEq(params)
.set(ItemDoc::getName,"花王拉拉裤(Merries)拉拉裤 M58片 中号尿不湿(6-11kg)(日本原装进口)测试更新")
.set(ItemDoc::getStock,"9999");
List<ItemDoc> itemDocs = itemDocMapper.selectList(esWrapper);
System.out.println("更新前:" + itemDocs);
//执行更新
int result = itemDocMapper.update(null,esWrapper);
System.out.println(result > 0 ? "更新成功" : "更新失败");
}控制台

kibana
java
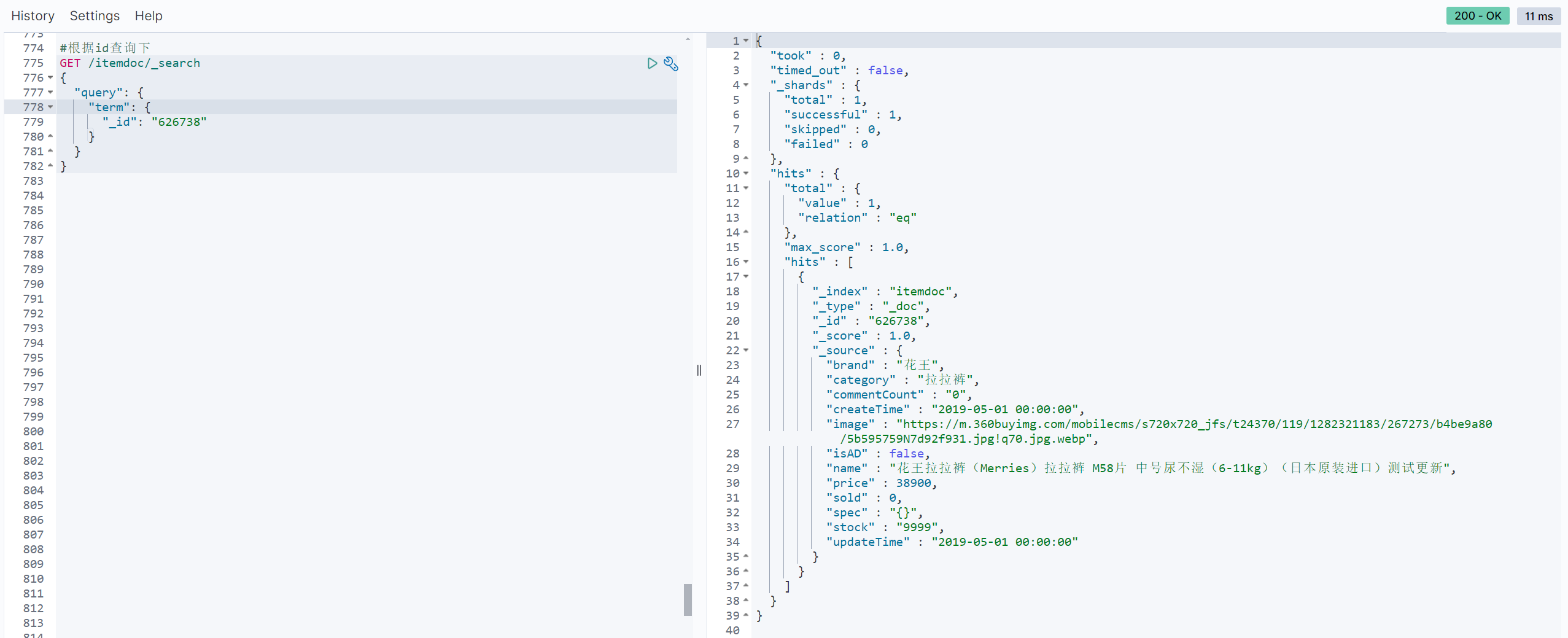
#根据id查询下
GET /itemdoc/_search
{
"query": {
"term": {
"_id": "626738"
}
}
}
四大嵌套查询
Es四大嵌套查询
|--------|---------------|----------|------------------|
| MySQL | Mybatis-Plus | ES | Easy-Es |
| and 嵌套 | and(Consumer) | must | and(Consumer) |
| or 嵌套 | or(Consumer) | should | or(Consumer) |
| 无 | 无 | filter | filter(Consumer) |
| 无 | 无 | must_not | not(Consumer) |
Es四大拼接查询
|-------|--------------|----------|----------|
| MySQL | Myabtis-Plus | ES | Easy-Es |
| and拼接 | 默认 | must | 默认 |
| or拼接 | or() | should | or() |
| 无 | 无 | filter | filter() |
| 无 | 无 | must_not | not() |
注意:如果您有用过MP,理解上面的差异就比较简单,如果您尚未用过MP也没关系,咱只需要搞清楚嵌套类型与拼接类型的差异即可。
另外关于must和filter的选择,它们在功能上类似,都是表示必须满足的条件,不同之处在于filter不计算得分,性能表现更好,但不支持根据得分排序。
嵌套和拼接如何理解并使用
简单来说,嵌套就是有括号的,拼接就是无括号的,或者说嵌套就是里面有东西的,拼接是里面没东西的,怎么理解这段话呢?以大家熟悉的MySQL中的一段SQL为例:
java
#这里的 or 就是拼接
where category = '手机' or category = '牛奶';
#用mp或者ee来写
wrapper.eq(category,"手机").or().eq(category,"牛奶);
#这里的 or 就是嵌套
where category = '手机' or (price = 500 and brand = '鸭梨牌');
# 用mp或者ee来写
wrapper.eq(category,"手机").or(i->i.eq(price,500).eq(brand,"鸭梨牌));通过上面的例子大家应该很好理解拼接和嵌套的差异了,对应到es中,嵌套就是把嵌套中的所有查询条件封装进一个新创建的boolQuery中,然后拼接至根boolQuery,而拼接则是把查询条件直接拼接进根boolQuery中. 在EE中条件与条件直接默认的拼接方式是以and拼接,由于95%的使用场景都是and拼接,所以直接省略了and这种拼接,这点和MP一样。
java
# sql写法
where category = '手机' and brand = 'Apple';
用mp或者ee写法
wrapper.eq(category,"手机).eq(brand,"Apple");如果你需要改写默认的拼接方式只需要加上对应的拼接类型即可,例如:
java
# SQL
where category = '手机' or brand = 'Apple';
#用ee或者mp
wrapper.eq(category,"手机").or().eq(brand,"Apple");
#SQL
where category = '手机' and brand != 'Apple';
#用ee写
wrapper.eq(category,"手机).not().eq(brand,"Apple");
# 所有的表 '非' 的条件都可以用 not() 来拼接
wrapper.eq(category,"手机).not().eq(brand,"Apple").not().match(price,5000);场景示例
嵌套and使用
java
@Test
@DisplayName("测试嵌套and使用")
void testAnd() {
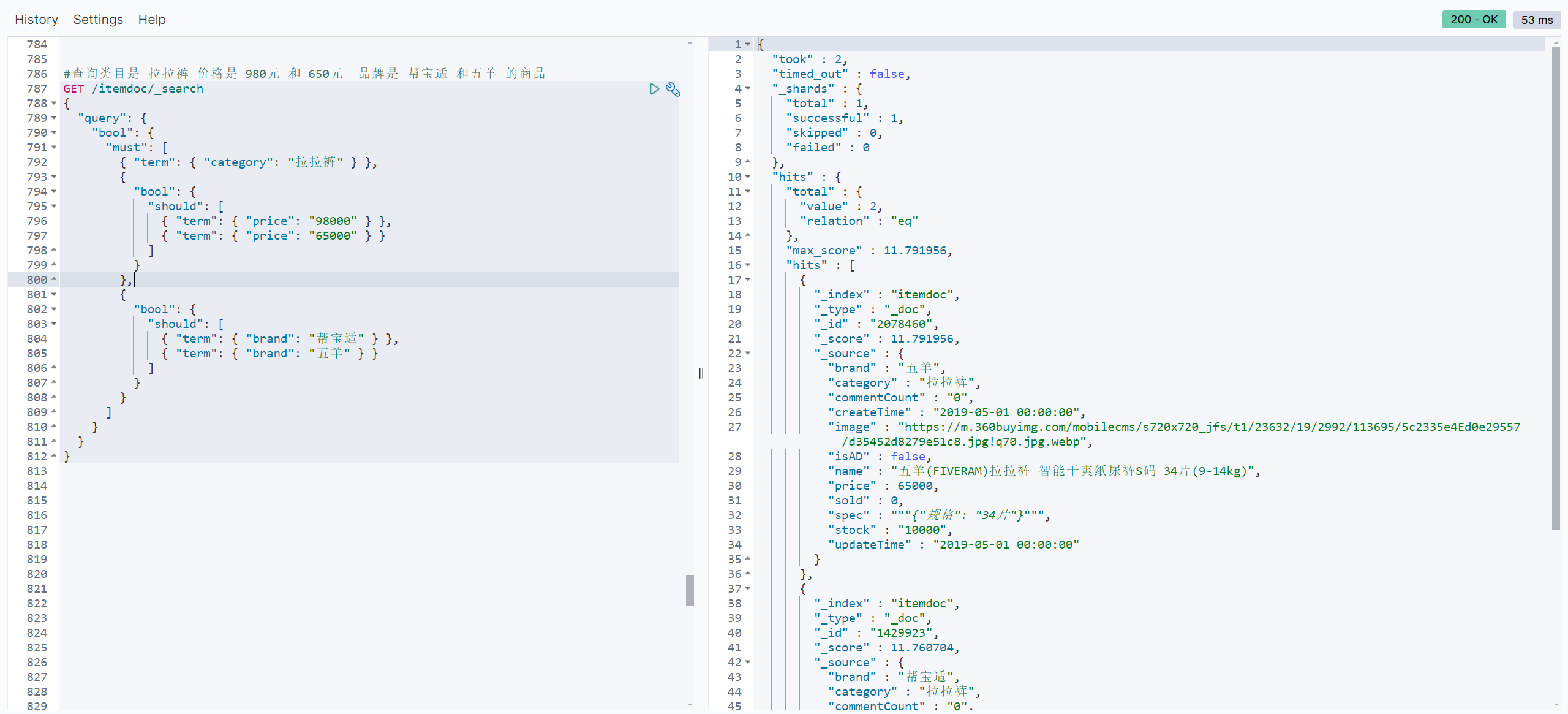
// 查询类目是 拉拉裤 价格是 980元 和 650元 品牌是 帮宝适 和五羊 的商品
// sql: select * from item where category = '拉拉裤' and (price = '98000' or price = '65000') and (brand = '帮宝适' or brand = '五羊');
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper.eq(ItemDoc::getCategory, "拉拉裤")
.and(i->i.eq(ItemDoc::getPrice,98000).or().eq(ItemDoc::getPrice,65000))
.and(i->i.eq(ItemDoc::getBrand,"帮宝适").or().eq(ItemDoc::getBrand,"五羊"));
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("查到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
#查询类目是 拉拉裤 价格是 980元 和 650元 品牌是 帮宝适 和五羊 的商品
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{ "term": { "category": "拉拉裤" } },
{
"bool": {
"should": [
{ "term": { "price": "98000" } },
{ "term": { "price": "65000" } }
]
}
},
{
"bool": {
"should": [
{ "term": { "brand": "帮宝适" } },
{ "term": { "brand": "五羊" } }
]
}
}
]
}
}
}
拼接 and的使用
java
@Test
@DisplayName("测试拼接and的使用")
void testAnd2() {
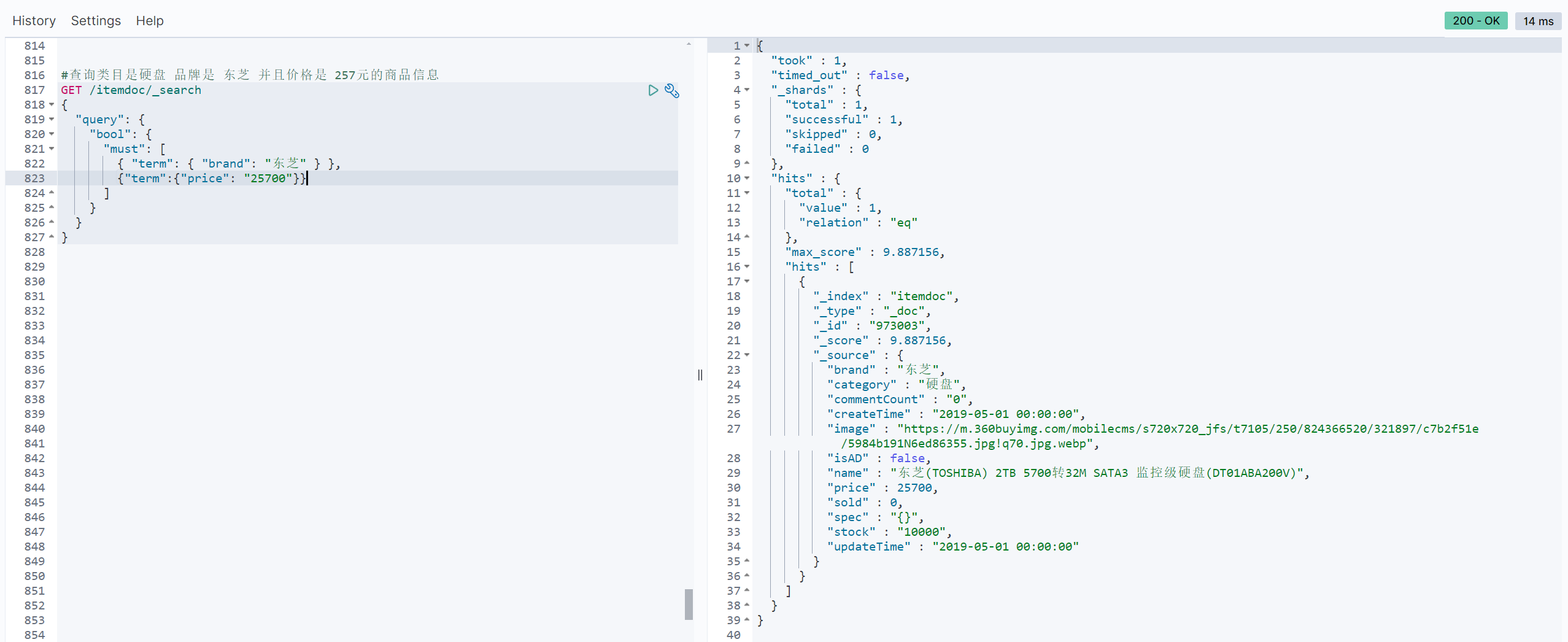
// 查询类目是硬盘 品牌是 东芝 并且价格是 257元的商品信息
// sql: select * from item where brand = '东芝' and price = '25700';
//构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getBrand,"东芝")
.match(ItemDoc::getPrice,"25700");
//执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("查到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
#查询类目是硬盘 品牌是 东芝 并且价格是 257元的商品信息
GET /itemdoc/_search
{
"query": {
"bool": {
"must": [
{ "term": { "brand": "东芝" } },
{"term":{"price": "25700"}}
]
}
}
}
嵌套or的使用
java
@Test
@DisplayName("测试嵌套or使用")
void testOr() {
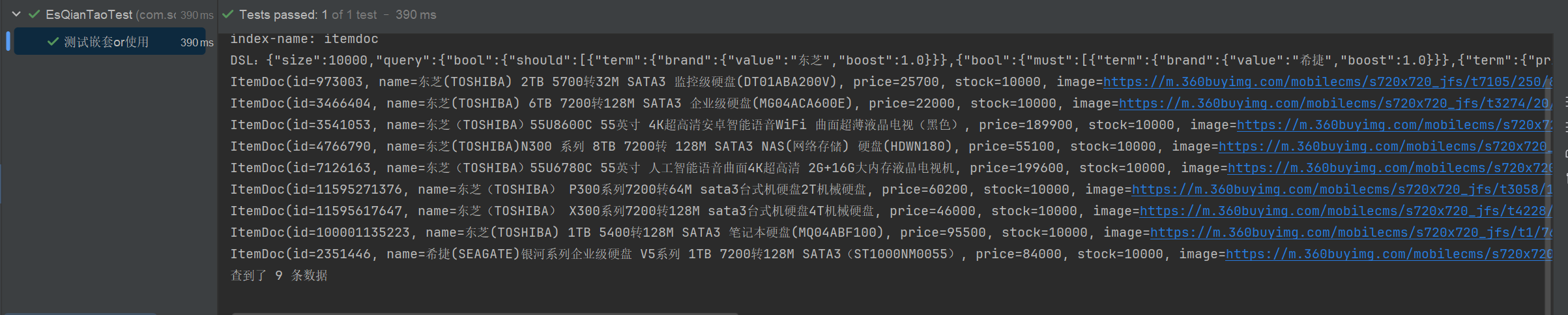
// 查询 品牌是 东芝 或者(品牌是希捷并且价格是840元)的商品信息
// sql: select * from item where brand = '西部数据' or (brand = '希捷' and price = '84000');
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper.eq(ItemDoc::getBrand,"东芝")
.or()
.and(i->i.eq(ItemDoc::getBrand,"希捷").eq(ItemDoc::getPrice,"84000"));
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("查到了 " + itemDocList.size() + " 条数据");
}控制台
kibana
java
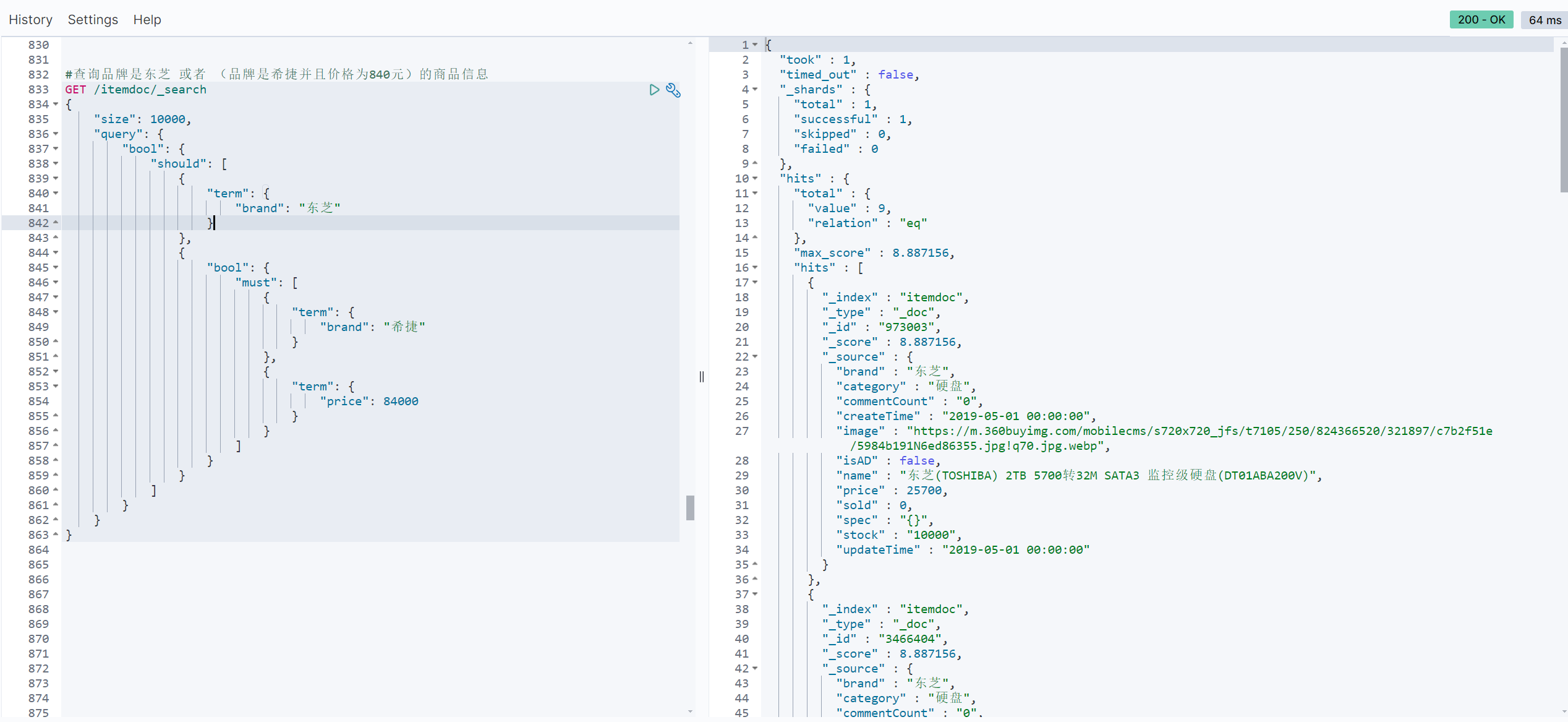
#查询品牌是东芝 或者 (品牌是希捷并且价格为840元)的商品信息
GET /itemdoc/_search
{
"size": 10000,
"query": {
"bool": {
"should": [
{
"term": {
"brand": "东芝"
}
},
{
"bool": {
"must": [
{
"term": {
"brand": "希捷"
}
},
{
"term": {
"price": 84000
}
}
]
}
}
]
}
}
} 
拼接or的使用
java
@Test
@DisplayName("测试拼接or使用")
void testOr2() {
// 查询品牌是 希捷或者是 东芝的商品
// sql: select * from item where brand = '希捷' or brand = '东芝';
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper.eq(ItemDoc::getBrand,"希捷").or().eq(ItemDoc::getBrand,"东芝");
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("查到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
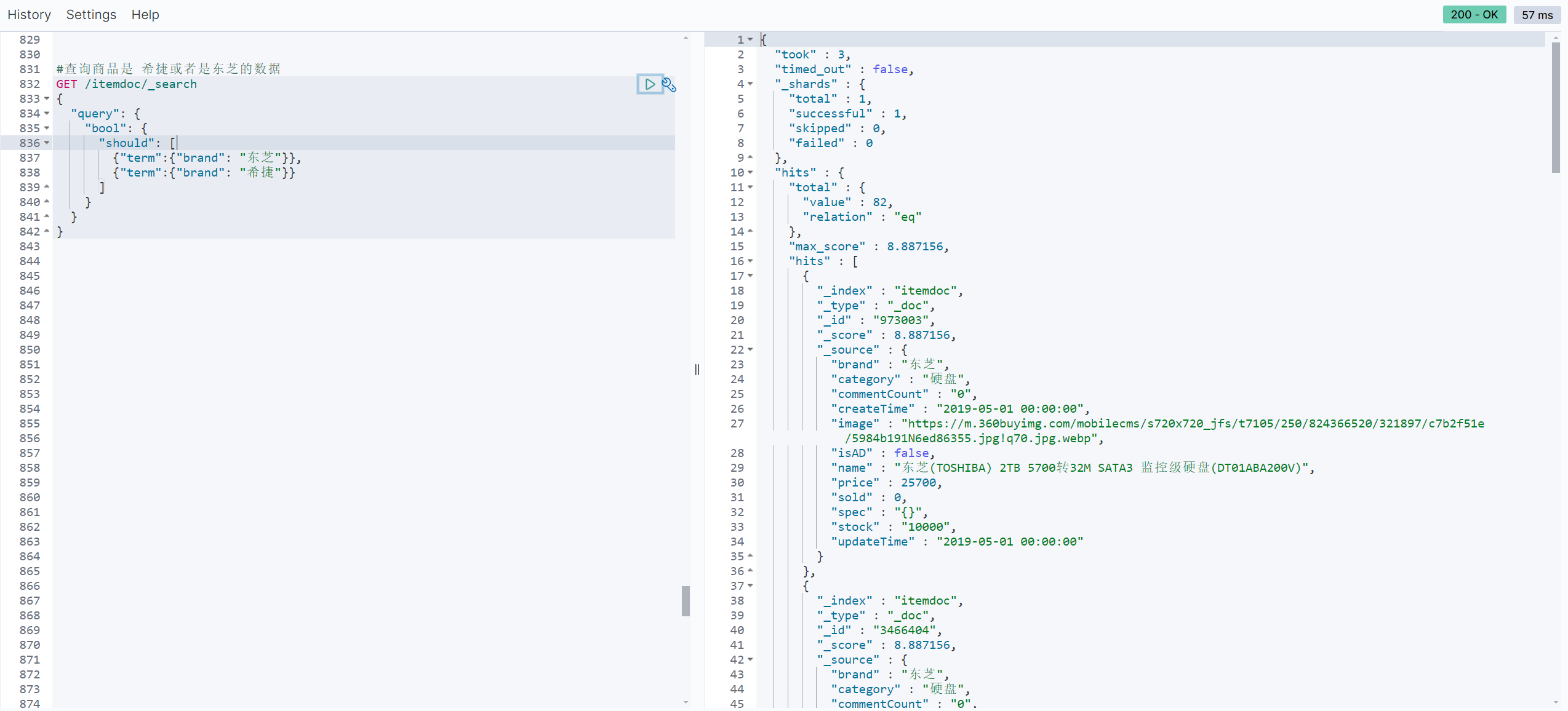
#查询商品是 希捷或者是东芝的数据
GET /itemdoc/_search
{
"query": {
"bool": {
"should": [
{"term":{"brand": "东芝"}},
{"term":{"brand": "希捷"}}
]
}
}
}
嵌套filter的使用
java
@Test
@DisplayName("测试嵌套filter的使用")
void testFilter() {
// 查询价格是 289元和286元 并且类目是 拉杆箱 或者name中包含 绿色 的商品信息
// sql: select * from item where price in(289,286) and (category = '拉杆箱' or name like '%绿色%');
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.in(ItemDoc::getPrice,28900,28600)
.filter(i->i.eq(ItemDoc::getCategory,"拉杆箱").or().like(ItemDoc::getName,"绿色"));
// 执行查询
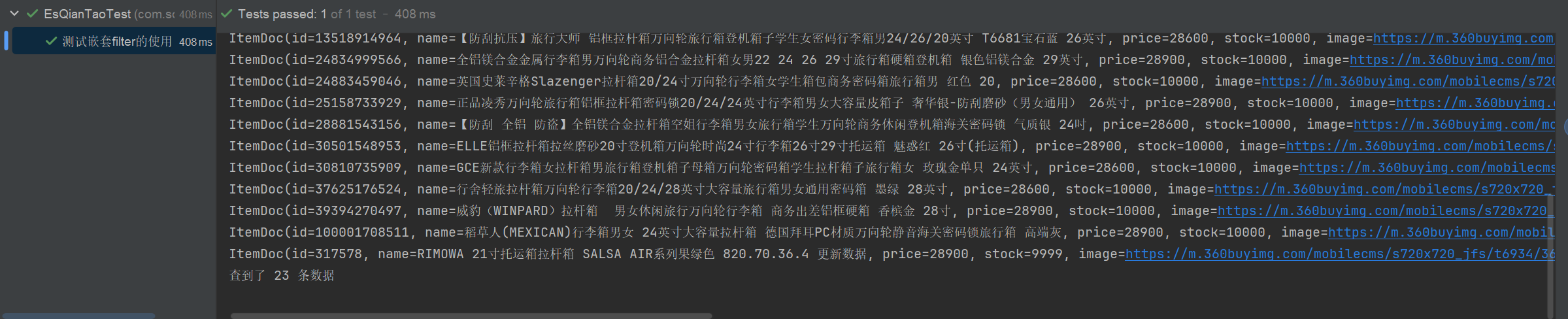
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("查到了 " + itemDocList.size() + " 条数据");
}控制台
kibana
java
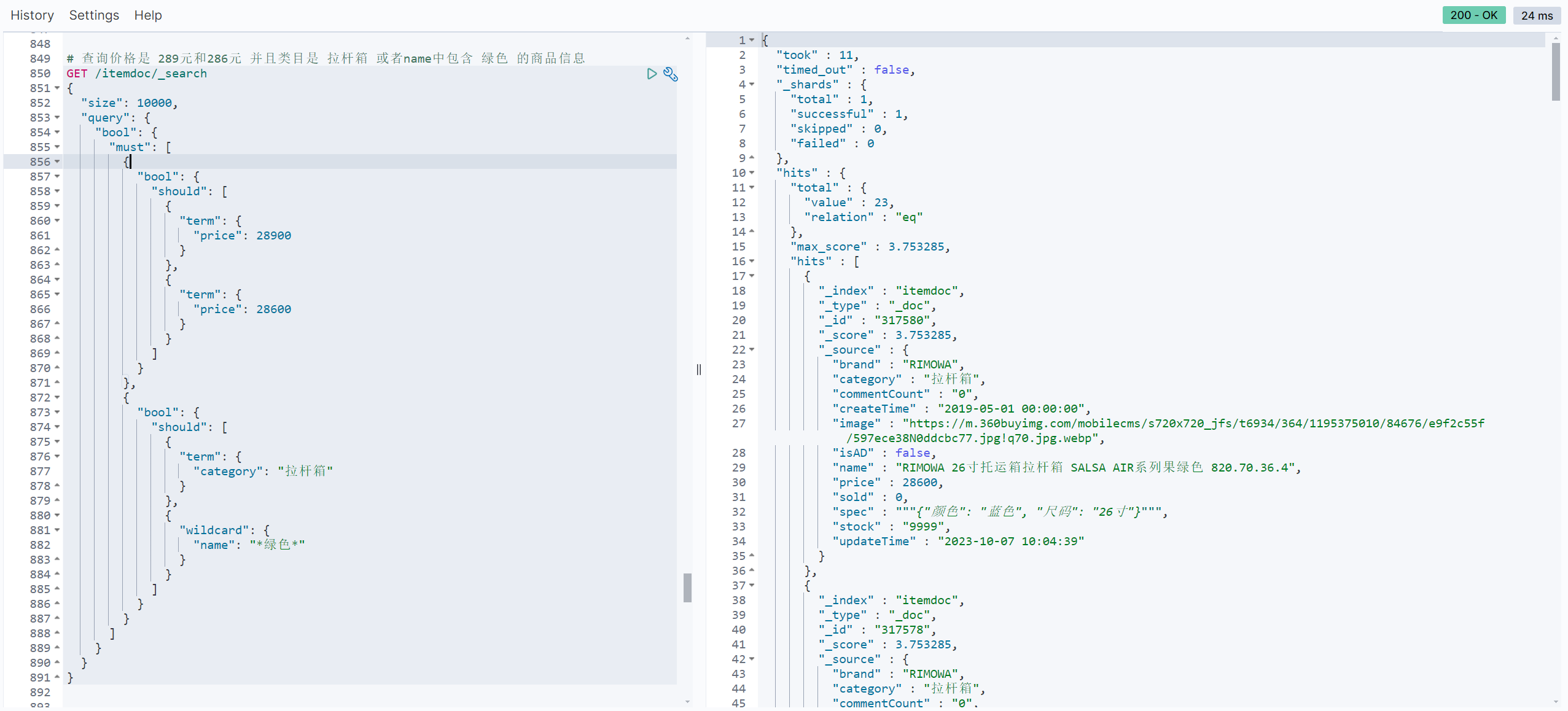
# 查询价格是 289元和286元 并且类目是 拉杆箱 或者name中包含 绿色 的商品信息
GET /itemdoc/_search
{
"size": 10000,
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"term": {
"price": 28900
}
},
{
"term": {
"price": 28600
}
}
]
}
},
{
"bool": {
"should": [
{
"term": {
"category": "拉杆箱"
}
},
{
"wildcard": {
"name": "*绿色*"
}
}
]
}
}
]
}
}
}
拼接filter的使用
java
@Test
@DisplayName("测试拼接filter的使用")
void testFilter2() {
//查询品牌是 希捷的
// sql: select * from item where brand = '希捷';
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper.filter().eq(ItemDoc::getBrand,"希捷");
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("查到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
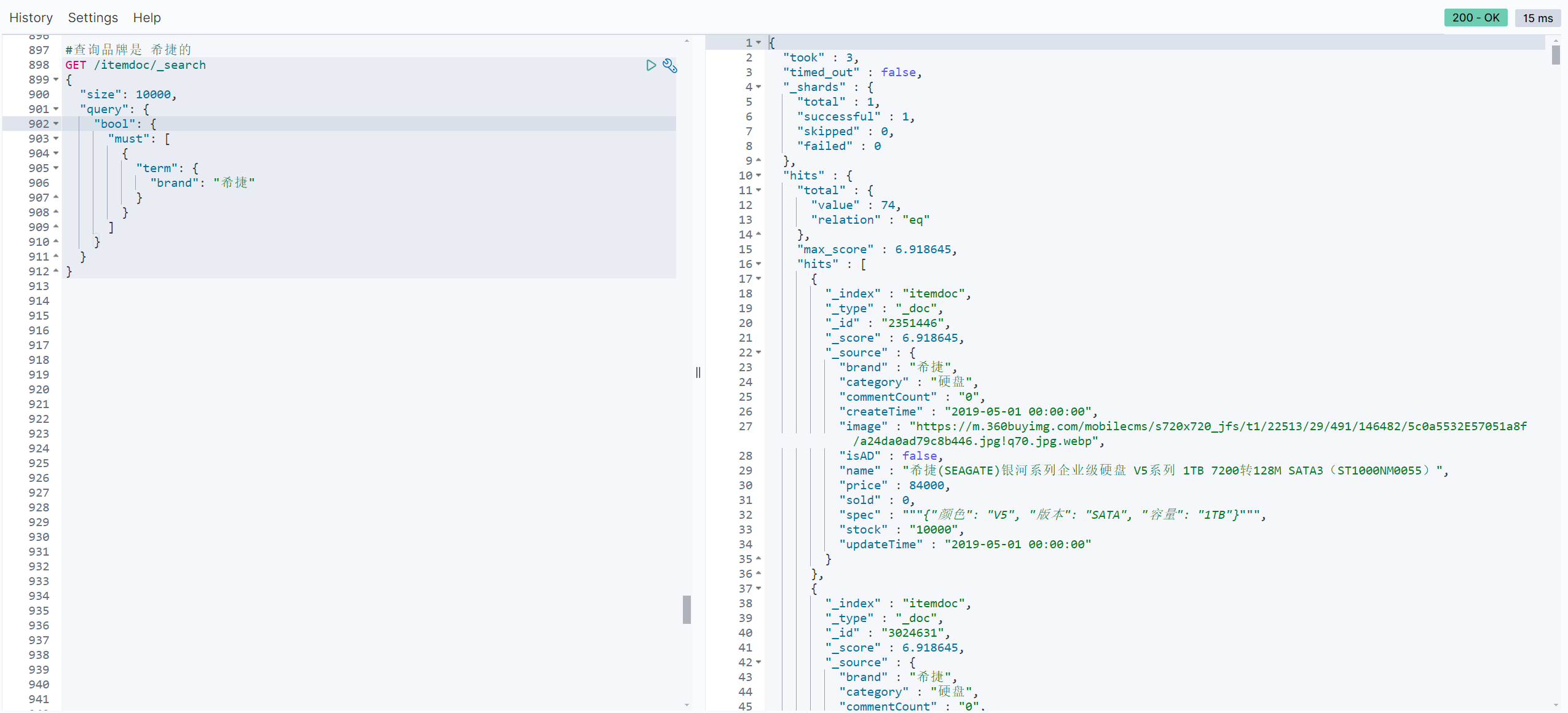
#查询品牌是 希捷的
GET /itemdoc/_search
{
"size": 10000,
"query": {
"bool": {
"must": [
{
"term": {
"brand": "希捷"
}
}
]
}
}
}
嵌套mustnot的使用
java
@Test
@DisplayName("测试嵌套mustnot的使用")
void testMustNot() {
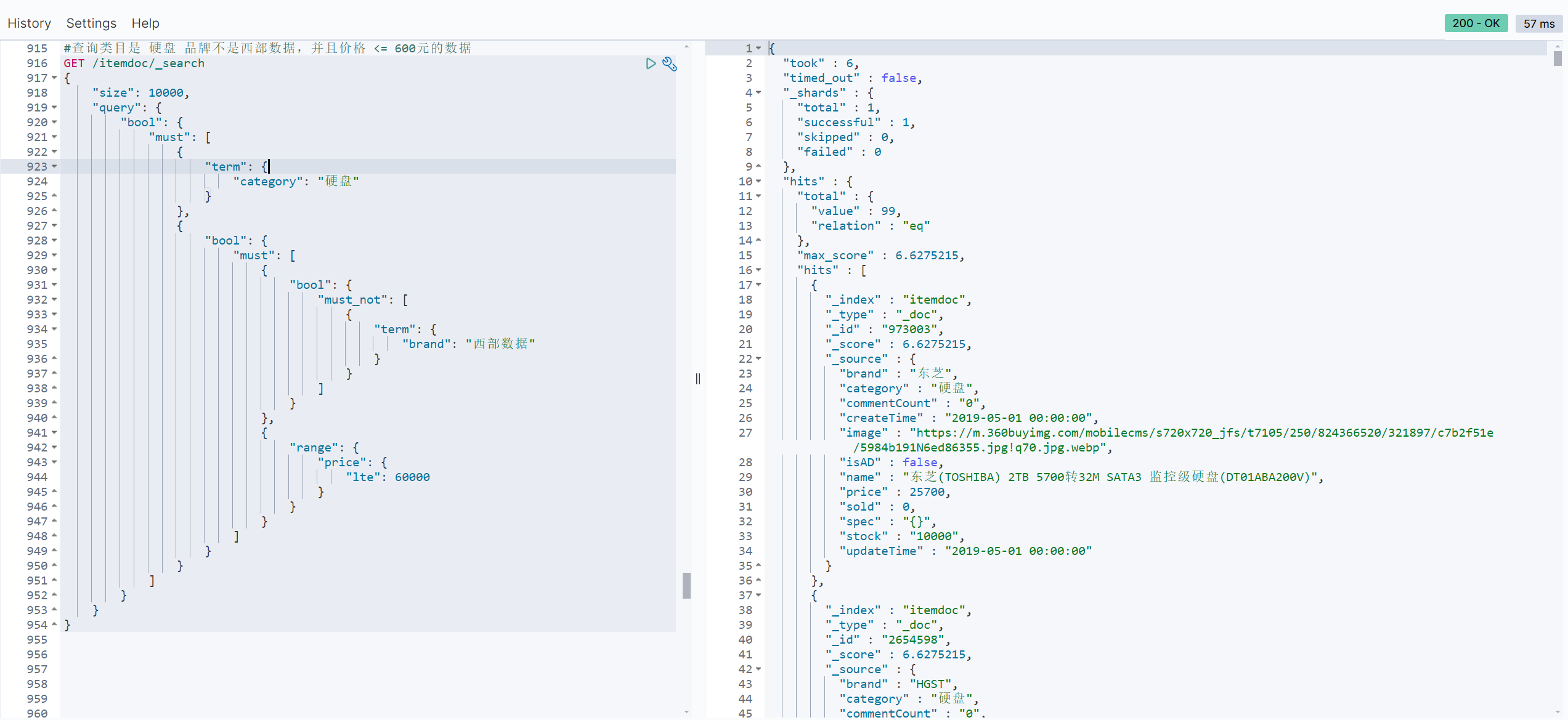
//查询类目是 硬盘 品牌不是西部数据,并且价格 <= 600元的数据
// sql: select * from item where category = '硬盘' and (brand != '西部数据' and price <= '60000');
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"硬盘")
.and(i->i.not().eq(ItemDoc::getBrand,"西部数据").le(ItemDoc::getPrice,60000));
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("查到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
#查询类目是 硬盘 品牌不是西部数据,并且价格 <= 600元的数据
GET /itemdoc/_search
{
"size": 10000,
"query": {
"bool": {
"must": [
{
"term": {
"category": "硬盘"
}
},
{
"bool": {
"must": [
{
"bool": {
"must_not": [
{
"term": {
"brand": "西部数据"
}
}
]
}
},
{
"range": {
"price": {
"lte": 60000
}
}
}
]
}
}
]
}
}
}
拼接not使用
java
@Test
@DisplayName("测试拼接not的使用")
void testMustNot2() {
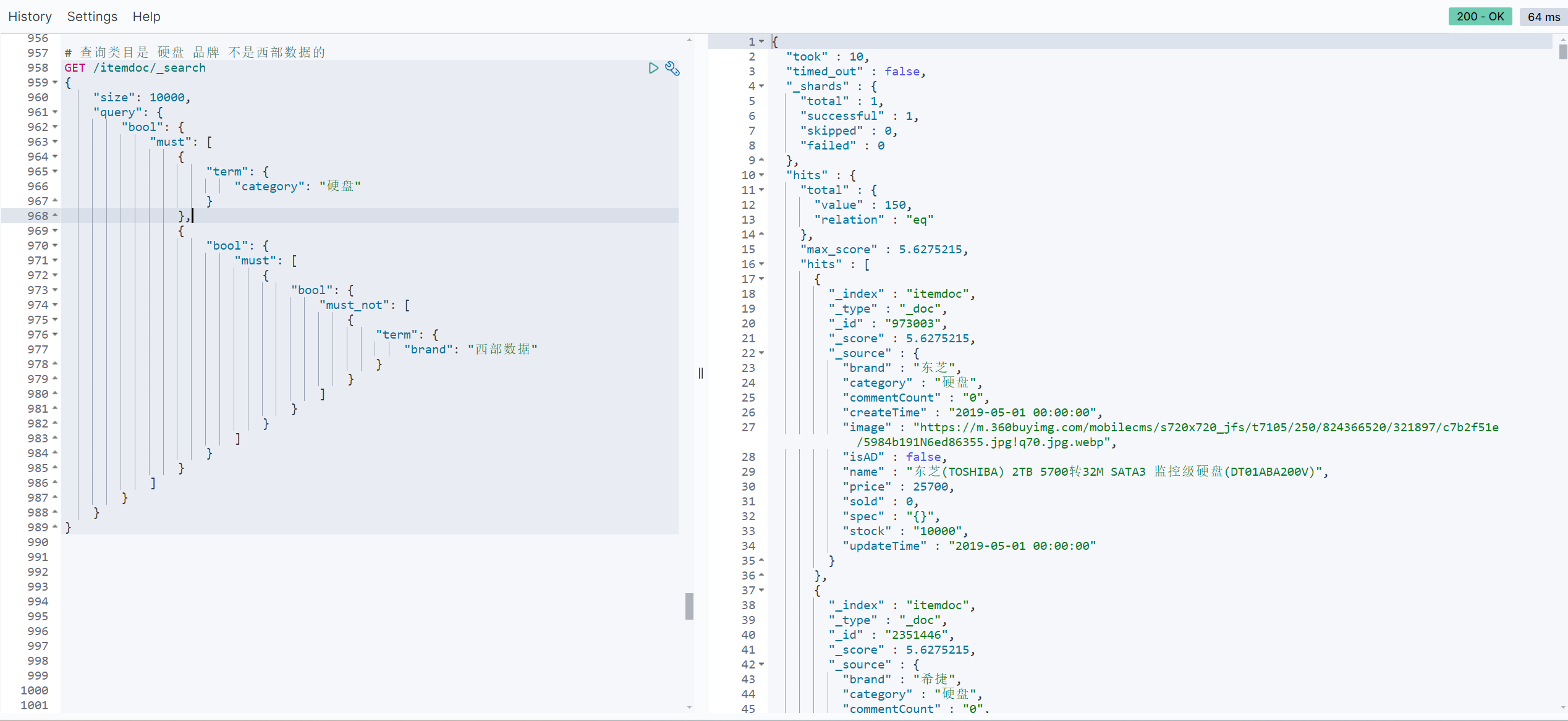
//查询类目是 硬盘 品牌 不是西部数据的
// sql: select * from item where category = '硬盘' and brand != '西部数据';
// 构建查询条件
LambdaEsQueryWrapper<ItemDoc> esWrapper = new LambdaEsQueryWrapper<>();
esWrapper
.eq(ItemDoc::getCategory,"硬盘")
.not()
.eq(ItemDoc::getBrand,"西部数据");
// 执行查询
List<ItemDoc> itemDocList = itemDocMapper.selectList(esWrapper);
itemDocList.forEach(System.out::println);
System.out.println("查到了 " + itemDocList.size() + " 条数据");
}控制台

kibana
java
# 查询类目是 硬盘 品牌 不是西部数据的
GET /itemdoc/_search
{
"size": 10000,
"query": {
"bool": {
"must": [
{
"term": {
"category": "硬盘"
}
},
{
"bool": {
"must": [
{
"bool": {
"must_not": [
{
"term": {
"brand": "西部数据"
}
}
]
}
}
]
}
}
]
}
}
}