FFCA-YOLO for Small Object Detection in Remote Sensing Images
FFCA-YOLO遥感图像小目标检测

0.论文摘要
摘要------特征表征不足、背景干扰等问题使得遥感图像中的小目标检测任务极具挑战性。尤其在算法需部署于星载设备进行实时处理时,需在有限计算资源下对精度与速度进行深度优化。为此,本文提出一种名为特征增强-融合与上下文感知YOLO(FFCA-YOLO)的高效检测器。该模型包含三个轻量化即插即用模块:特征增强模块(FEM)、特征融合模块(FFM)和空间上下文感知模块(SCAM),分别用于提升网络局部区域感知、多尺度特征融合以及跨通道与空间的全局关联能力,同时尽可能避免增加复杂度,从而增强小目标的弱特征表征并抑制混淆性背景干扰。通过VEDAI和AI-TOD两个公开遥感小目标数据集及自建数据集USOD验证表明,FFCA-YOLO的mAP50指标分别达到0.748、0.617和0.909,超越多个基准模型与前沿方法。在不同模拟退化条件下的测试也验证了其鲁棒性。此外,为在保证效能的同时进一步降低计算资源消耗,基于部分卷积(PConv)重构主干网络与颈部结构,优化出轻量版L-FFCA-YOLO。相比原模型,该版本在精度损失极小的情况下实现了更快的速度、更少的参数量与更低算力需求。
索引术语---上下文信息、特征融合、轻量级网络、遥感图像、小目标检测。
1.引言
近年来,随着光学遥感技术的快速发展,小目标检测研究在交通监管、搜救、安防、军事等应用领域取得了显著进展1-6。遥感图像通常具有大视场特性,非常适合广域监测。但由于分辨率相对较低、成像质量较差,目标往往呈现尺寸微小(小于32×32像素7、57)、特征微弱、对比度低、信息不足等特点,这给检测任务带来了额外困难8、9。同时,遥感系统面临观测条件不可控、成像链路干扰因素多等问题,如平台运动、大气扰动及复杂场景等,导致目标与背景严重混叠,使得小目标难以辨识。另一方面,随着相机波段和分辨率的持续提升,星上成像数据量激增10。以WorldView-4为例,其每日采集数据覆盖面积达68万平方公里11,给下行数据传输带来巨大压力。传统的地面事后处理模式难以满足军事侦察、应急救援等高时效性应用需求。星上实时处理能显著缓解成像数据传输压力,缩短从信息获取到战略决策的延时,成为解决这一问题的潜在途径。欧洲航天局(ESA)等权威机构已前瞻性地将星上处理技术列为重点研究方向12。然而星载设备严格的功耗、重量、体积等资源约束,对处理算法的可靠性、速度及规模提出了更高要求。
总体而言,遥感应用中小目标检测的主要挑战可归纳为三点:特征表示不足、背景干扰以及在有限硬件条件下速度与精度的优化。
本研究旨在设计一种高精度的小目标检测器,未来有望应用于机载实时处理。解决特征表征不足与背景干扰问题的关键在于特征增强与融合。在特征增强方面,充分利用局部与全局上下文信息13、14、15能有效提升网络对小目标的感知能力。我们提出特征增强模块(FEM)和空间上下文感知模块(SCAM),分别用于丰富局部与全局上下文特征:FEM通过多分支空洞卷积扩展骨干网络感受野,SCAM通过构建全局上下文关系建立小目标与全局区域的关联。在特征融合方面,提出特征融合模块(FFM)改进融合策略,该模块能基于通道信息对特征图进行重加权且不增加计算复杂度。将这三个模块嵌入YOLO框架后,我们构建出新模型------特征增强、融合与上下文感知YOLO(FFCA-YOLO)。最后,为在保证效能的同时进一步降低计算资源消耗,基于部分卷积(PConv)重构FFCA-YOLO的骨干网络与颈部结构,优化得到轻量版L-FFCA-YOLO。
本文的主要贡献如下。
- 针对遥感应用设计了一款高效的小目标检测器FFCA-YOLO及其轻量版L-FFCA-YOLO。相较于多种基准模型与前沿方法,FFCA-YOLO在小目标检测任务中展现出优越性能,并具备未来星载实时应用的潜力。
- 提出了三个创新性轻量化即插即用模块:FEM、FFM和SCAM。这三个模块分别增强了网络对局部区域的感知能力、多尺度特征融合能力以及跨通道与空间的全局关联能力,可作为通用模块嵌入任何检测网络,以增强小目标的弱特征表征并抑制易混淆背景。
- 基于航空遥感影像构建了新型小目标数据集USOD,其中小于32×32像素的小目标占比超过99.9%,且包含大量低照度与阴影遮挡样本。该数据集还设有图像模糊、高斯噪声、条带噪声和雾化等不同模拟退化条件下的多组测试集,可作为遥感小目标检测的基准数据集。
本文剩余部分组织结构如下:第二节介绍小目标检测相关研究工作后,第三节详细阐述了提出的FFCA-YOLO和L-FFCA-YOLO架构。第四节简要说明实验细节,重点对比了所提方法与若干基准模型及前沿算法的性能表现,同时验证了FFCA-YOLO的鲁棒性和轻量化特性。第五节对全文进行总结,并指出遥感小目标检测领域的未来研究方向。
2.相关工作
本节简要回顾与本文工作相关的文献,包括YOLO在遥感检测中的应用、小目标特征提取方法、全局上下文特征表示以及网络轻量化框架。
A. YOLO在遥感领域的应用
深度学习的发展使得目标检测器能够通过端到端学习框架自适应地提取图像特征并定位物体。目前,检测方法可分为两类:两阶段检测器1617与单阶段检测器18192021。相较于两阶段检测器,单阶段检测器具有更快的运算速度和较低的精度损失,这使其在车载应用领域更具潜力。作为典型的单阶段目标检测算法,YOLO系列算法181920在小目标检测方面具有实现理想性能的优势。目前针对遥感图像目标检测已涌现出若干改进的YOLO算法,例如TPH-YOLO22、FE-YOLO23和CA-YOLO24。
TPH-YOLO22在骨干网络中引入Transformer编码器模块,以获取丰富的全局上下文信息,提升目标特征表征质量。FE-YOLO23采用可变形卷积实现YOLO颈部高低层特征图融合,旨在消除自上而下连接导致的语义鸿沟对目标检测的影响。这两种方法虽效果显著,但参数量激增。CA-YOLO24将坐标注意力模块嵌入浅层特征提取网络,通过建立像素间长程依赖关系抑制冗余背景并增强目标特征表达。综上所述,YOLO系列算法兼具可扩展性和高效性优势,非常适合遥感检测任务应用。
因此,我们选择YOLO作为基础框架,并针对小目标特征表征与背景抑制专门设计了新增模块。
B. 小目标检测的特征增强与融合方法
基于深度学习的目标检测方法依赖主干网络获取高维特征。然而在遥感图像中,小目标提取的特征在输出特征图上可能仅占据单个像素,此时需要利用多尺度特征进行更有效的表征。受手工设计特征金字塔结构的启发,Lin等人25提出了特征金字塔网络(FPN),该网络能够将高分辨率的低级特征与低分辨率的高级特征进行聚合。此后,PANet26、NAS-FPN27、ASFF28和BiFPN29相继被提出,并在目标检测任务中取得良好效果。Guo等人30引入AugFPN来解决特征图中细节信息与语义信息的不一致问题,通过在特征融合阶段采用一次性监督方法缩小信息差距。Liu等人31提出高分辨率目标检测网络(HRDNet)用于检测小型车辆目标,该网络采用多深度图像金字塔与多尺度FPN相结合的方式深化特征。这些方法表明,加强多尺度特征融合的质量能在一定程度上有效提升小目标检测性能。此外,在特征融合前进行特征增强可进一步提升网络的语义表征能力。Cheng等人32采用双重注意力机制在融合前增强特征,使网络聚焦于目标的显著特征。Zhang与Shen33提出的特征增强模块与Cheng的方法类似,同样利用空间和通道维度的注意力机制进行特征增强。除注意力机制外,通过多分支卷积8和Transformer编码器34、35扩大感受野也是两种常用的特征增强方式。
为获得更大的感受野,本文设计了一种新型轻量化FEM模块,通过包含标准卷积与空洞卷积的多分支结构来获取更丰富的局部上下文信息。此外,通过改进多尺度融合策略并几乎不引入额外参数,提出了一种新型FFM模块。
C. 全局上下文特征表示
经过FEM和FFM处理后,小目标的特征表征得到了一定程度的增强。在此阶段建模小目标与背景的全局关系,相比在骨干网络中更为有效。
根据36、37和38的研究成果,获取全局感受野和上下文信息对于小目标定位至关重要。非局部神经网络(NLNet)13通过计算空间像素间的成对相关性来聚合全局上下文信息。此后,GCNet14和SCP38通过简化查询向量与键向量的乘积运算,解决了NLNet计算量过大的问题。SCP在GCNet基础上增加了额外路径以学习每个像素的信息。该路径采用1×1卷积聚合不同通道间的空间信息,但仍可能引入部分无效的背景特征。
基于上述方法,结合文献39和40的思想,本文提出了一种新的SCAM模块。该模块通过全局平均池化(GAP)和全局最大池化(GMP)引导像素学习空间与通道间的关联关系,从而能够实现跨通道与跨空间的上下文特征交互。
D. 轻量级模型框架
轻量化是衡量检测器性能的重要指标,尤其针对未来车载部署场景,需在有限计算资源下平衡精度与速度。实现网络轻量化主要有两种方式:一是以剪枝为代表的模型压缩技术41424344,其本质是通过设计过滤算法删除低于阈值的冗余参数,任何模型均可通过剪枝减少参数量;二是采用轻量化卷积网络优化模型结构,核心思想是设计更高效的计算方式。MobileNet45、ShuffleNet46和GhostNet47采用深度可分离卷积(DWConv)和/或分组卷积提取空间特征,DWConv能有效降低参数量和浮点运算量。遥感目标检测领域的若干网络结构48、49、50基于上述方法实现了轻量化设计。Chen等51证实DWConv的低浮点运算量主要源于算子频繁的内存访问,因此提出PConv通过减少冗余计算和内存访问来更高效提取空间特征。基于PConv思想,本文在第四-E节重构网络结构,提出轻量化版本L-FFCA-YOLO,在保持精度小幅降低的同时实现更快推理速度。
3.方法
A.概述
我们选择YOLOv5作为基准框架,因其相较于最新的YOLOv8参数量更少,且在小目标检测任务中能保持一定精度。FFCA-YOLO的整体架构如图1所示:首先,与原始YOLOv5不同,FFCA-YOLO仅采用四次卷积下采样操作作为特征提取主干;其次,在YOLOv5的颈部添加了三个特殊设计的模块------提出轻量化FEM模块以增强网络局部区域感知能力,FFM模块用于提升多尺度特征融合能力,SCAM模块则用于强化跨通道与跨空间的全局关联能力;最后基于PConv重构FFCA-YOLO,在精度损失极小的情况下得到轻量化版本L-FFCAYOLO。具体实现细节详见第三-B节至第三-E节。
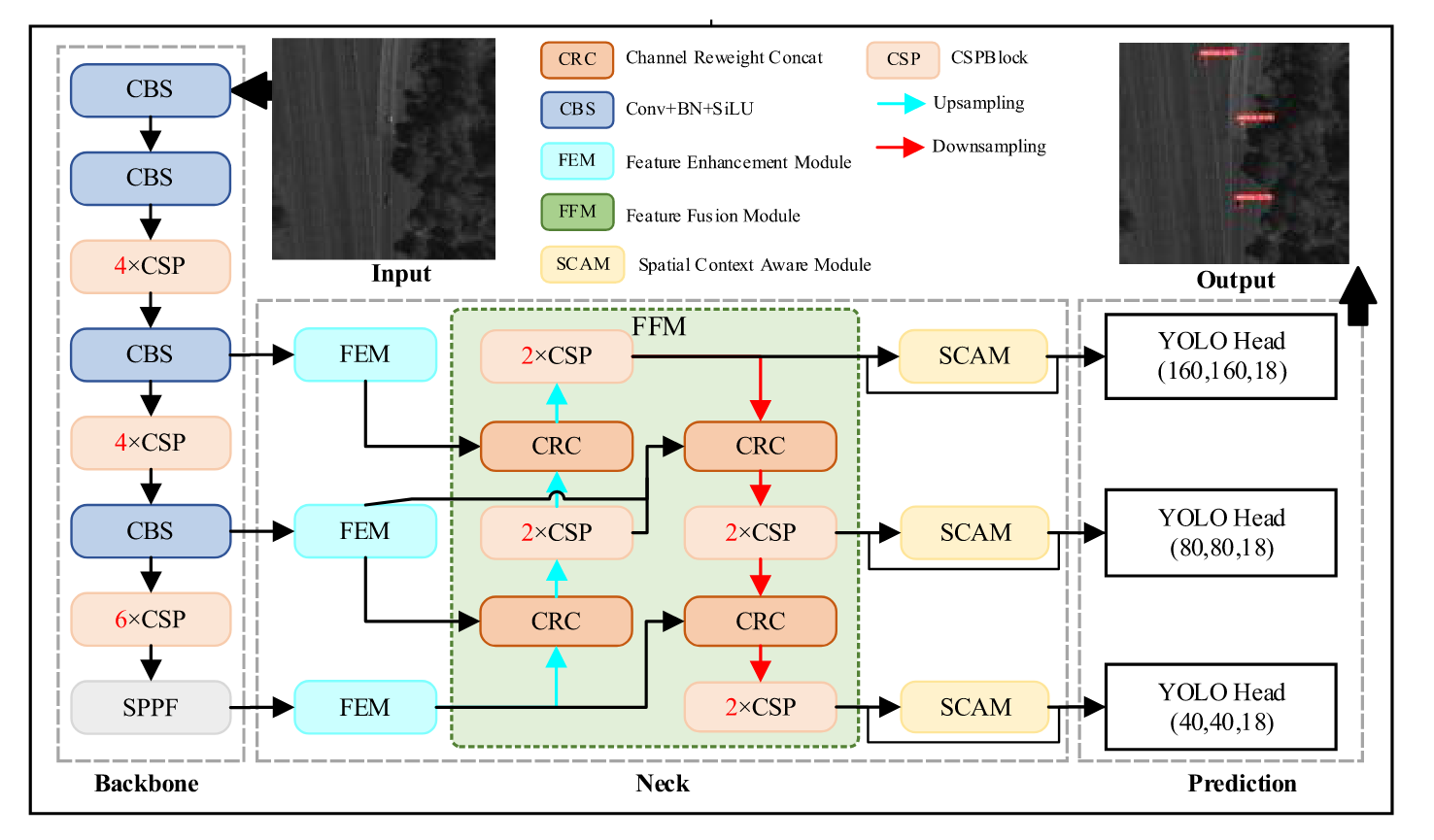
图1. FFCA-YOLO的整体框架。
B. 特征增强模块(FEM)
由于遥感图像的复杂性,在小目标检测任务中容易出现具有相似特征的虚警现象。然而主干网络的提取能力有限,当前阶段提取的特征包含的语义信息较少且感受野较窄,导致难以将小目标与背景区分。为此,本文提出的特征增强模块(FEM)从两个维度提升小目标特征:在增加特征丰富性方面,采用多分支卷积结构提取多重判别性语义信息;在扩大感受野方面,运用空洞卷积获取更丰富的局部上下文信息。如图2所示,FEM的整体结构受RFB-s52启发,其区别在于仅包含两个采用空洞卷积的分支。每个分支先对输入特征图执行1×1卷积以初步调整通道数,便于后续处理。第一分支采用残差结构形成等效映射,用于保留小目标的关键特征信息;其余三个分支分别执行核尺寸为1×3、3×1和3×3的级联标准卷积操作,并在中间两个分支中额外添加空洞卷积层,使提取的特征图能保留更多上下文信息。
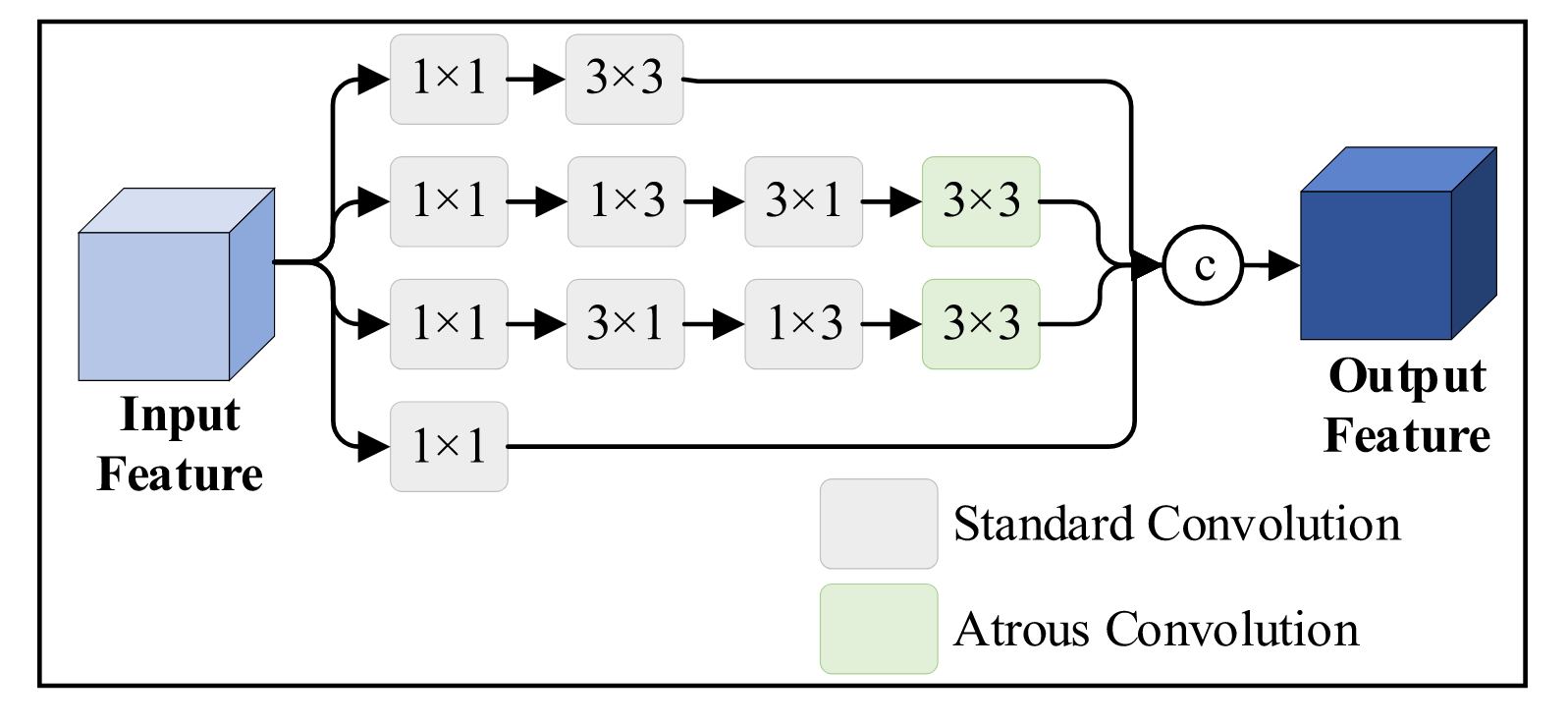
图2. FEM结构。
FEM的数学表达式可表述如下:

其中 f c o n v 1 × 1 f^{1×1}{conv} fconv1×1、 f c o n v 1 × 3 f^{1×3}{conv} fconv1×3、 f c o n v 3 × 1 f^{3×1}{conv} fconv3×1和 f c o n v 3 × 3 f^{3×3}{conv} fconv3×3分别表示核尺寸为 1 × 1 1×1 1×1、 1 × 3 1×3 1×3、 3 × 1 3×1 3×1和 3 × 3 3×3 3×3的标准卷积运算。 f d i c o n v 3 × 3 f^{3×3}_{diconv} fdiconv3×3表示膨胀率为5的空洞卷积运算。 C a t ( ⋅ ) Cat(·) Cat(⋅)为特征图拼接操作。 ⊕ ⊕ ⊕表示特征图的逐元素相加运算。 F F F为输入特征图。 W 1 W_1 W1、 W 2 W_2 W2和 W 3 W_3 W3分别表示前三个分支经过标准卷积和空洞卷积后的输出特征图。 Y Y Y是FEM模块的输出特征图。
与RFB-s相比,FEM结构更为轻量化,其通过多分支空洞卷积使模型能够学习更丰富的局部上下文特征,从而提升对小目标的特征表征能力。
C. 特征融合模块(FFM)
高层与低层特征图蕴含不同的语义信息。通过聚合多尺度特征图中的特征,可以增强小目标的语义表征能力。本文提出的FFM采用基于BiFPN的颈部结构,不同于BiFPN之处在于:FFM改进了名为CRC的重加权策略,并调整原始BiFPN结构以适配三个检测头。FFM结构如图3所示,其输入包含经FEM处理后的低层特征图 X 2 X_2 X2(160×160)和 X 3 X_3 X3(80×80),以及经SPPF处理后的高层特征图 X 4 X_4 X4(40×40)。

图3. FFM结构。
FFM的自顶向下策略如下:首先对 X 4 X_4 X4使用CSPBlock得到 X 4 ′ X'_4 X4′,随后将 X 4 ′ X'_4 X4′上采样至与 X 3 X_3 X3相同尺度,通过CRC模块进行特征融合。融合后的特征图经CSPBlock处理得到 X 3 ′ X'_3 X3′。对 X 3 ′ X'_3 X3′重复上述操作生成新特征图 X 2 ′ X'_2 X2′。 X 2 ′ X'_2 X2′、 X 3 ′ X'_3 X3′和 X 4 ′ X'_4 X4′实现了语义信息由深层向浅层的流动。自底向上过程与自顶向下类似,主要区别在于采用步长为2的卷积进行下采样。通过 X 3 X_3 X3、 X 3 ′ X'_3 X3′与 X 2 ′ X'_2 X2′的CRC融合得到 X 3 ′ ′ X''_3 X3′′。该操作能在不显著增加计算成本的前提下融合更多特征。FFM的输出结果 X 2 ′ X'_2 X2′、 X 3 ′ ′ X''_3 X3′′和 X 4 ′ ′ X''_4 X4′′将被输入SCAM模块进行上下文信息提取。FFM的计算过程可表述为:

其中 f u p 2 ↑ f^{2↑}_{up} fup2↑表示上采样操作。CBS指包含批归一化和SiLU激活函数的3×3卷积。
与BiFPN相比,FFM通过引入通道重加权机制改进了多尺度特征图的融合策略。BiFPN29的特征融合是在特征图之间进行的,这导致不同通道具有相同权重。为了增强多尺度特征对小目标的表征能力并充分利用不同通道的特征,本文提出的CRC模块对特征图通道进行重加权处理,如图3下半部分所示。
我们设计了三种通道重加权策略。第一种策略采用类似SENet39或ECANet53的通道注意力机制,如公式(8)所示对通道进行重加权。该策略虽然可行,但会显著增加计算成本和参数量。第二种策略先对特征图进行拼接,然后与通道总数相同维度的归一化可训练权重相乘,如公式(9)所示。第三种策略进一步考虑了不同特征图间的语义差异,先对每个特征图内部通道进行重加权,再对不同特征图进行整体重加权,如公式(10)所示。
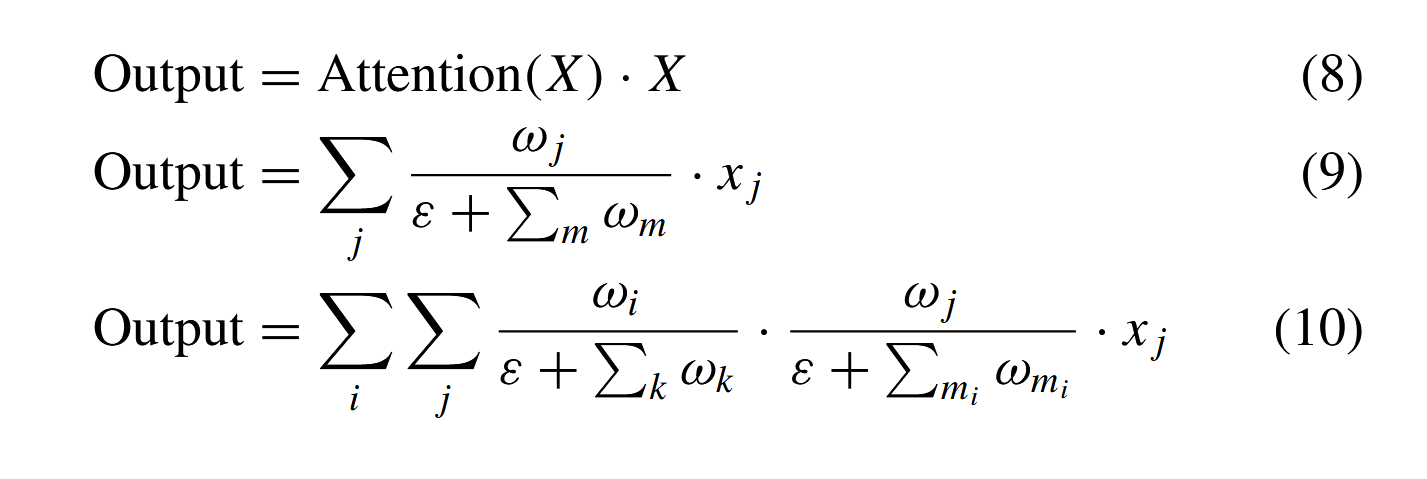
其中Attention(·)表示通道注意力机制,例如SENet或ECANet。 ω i ω_i ωi代表第 i i i个特征图中的可训练权重, ω j ω_j ωj代表第 j j j个通道中的可训练权重。 m i m_i mi是第 i i i个特征图的通道数, m m m表示拼接后的总通道数。 ε ε ε设为0.0001以避免数值不稳定。根据第四部分D节的消融实验结果,三种策略均能提升性能,但第二种与第三种策略差异不显著。因此我们在FFM中选择第二种策略进行特征重加权。FFM的结构及其通道重加权策略优化了多尺度语义信息对小目标的融合过程,为后续全局上下文建模提供了更有效的特征图。
D. 空间上下文感知模块(SCAM)
经过FEM和FFM处理后,特征图已包含局部上下文信息,能充分表征小目标特征。在此阶段建模小目标与背景的全局关系比在骨干网络中更有效。全局上下文信息可用于表征跨空间像素间的关系,从而抑制无用背景并增强目标与背景的区分度。受GCNet14和SCP38启发,SCAM由三个分支构成:第一分支通过全局平均池化(GAP)和全局最大池化(GMP)整合全局信息;第二分支采用1×1卷积生成特征图的线性变换结果(图4中称为Value54);第三分支使用1×1卷积简化query与key的乘积运算(图4中标记为QK)。随后,第一分支和第三分支分别与第二分支进行矩阵相乘,得到的两个分支分别表征跨通道和跨空间的上下文信息。最终通过广播哈达玛积运算这两个分支,得到SCAM的输出。其结构如图4所示。每层中像素级空间上下文可表示为:

图4. GCBlock、SCP和SCAM的结构。

其中, P j i P_j^i Pji 和 Q j i Q_j^i Qji 分别表示第 i i i层特征图中第 j j j个像素的输入与输出, N i N_i Ni 代表像素总数。 ω q k ω_{qk} ωqk 和 ω v ω_v ωv 是通过 1 × 1 1×1 1×1卷积简化的特征图线性变换矩阵。 a v g ( ⋅ ) avg(·) avg(⋅) 和 m a x ( ⋅ ) max(·) max(⋅) 分别执行全局平均池化(GAP)与全局最大池化(GMP)。GAP和GMP能引导特征图筛选具有显著信息的通道,使SCAM能够学习通道维度的上下文信息。
E. Lite-FFCA-YOLO(轻量级FFCA-YOLO)
合格的轻量级模型需要在参数量、速度和精度之间取得平衡。FasterNet发现DWConv的FLOPs较低的主要原因在于其频繁的内存冗余访问,这实际上导致了速度下降。为了缓解这一现象,FasterNet采用了PConv,该方法考虑了特征图中的冗余性51,仅对部分输入通道应用标准卷积。FFCA-YOLO中的CSPBlock通过结合FasterNet中的FasterBlock进行了重构,命名为CSPFasterBlock,如图5所示。

图5. L-FFCA-YOLO的主干网络结构。
根据51的研究结果,在CSPFasterBlock中采用1×1卷积的通道数M被设定为总通道数的3/4。在PConv之后设置了两个具有通道缩放比例的标准卷积。第四节E部分展示了不同缩放比例下的实验结果。FasterNet指出,直接用PConv替换标准卷积会导致精度显著下降。因此我们仅在CSPBlock中将瓶颈结构替换为FasterBlock,这能确保不同层次的特征信息流经所有通道的同时,仅产生微小精度损失。表I列出了FFCA-YOLO与L-FFCA-YOLO主干网络的参数量对比,数据显示L-FFCA-YOLO主干网络的参数量比FFCA-YOLO减少了30%。

4.实验
本文中将小目标定义为尺寸小于32×32像素的物体。基准测试在两个公开的小目标数据集VEDAI54和AI-TOD55、56以及自建的小目标检测专用数据集USOD上进行。实验选择YOLOv5作为基准框架,该框架按网络宽度和深度递增可分为五种模型:YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。其中YOLOv5m在YOLOv5系列算法中实现了速度与精度的最佳平衡,因此我们以YOLOv5m作为基础模型进行改进优化。
A. 实验数据集描述
-
VEDAI数据集:车辆航空图像检测(VEDAI)数据集55由从犹他州自动地理参考中心(AGRC)大型数据集中裁剪的图像组成。AGRC中每张图像约16000×16000像素,采集自同一高度,分辨率约为每像素12.5×12.5厘米。每幅场景图像包含RGB和红外两种模式。我们仅对RGB版本进行实验,并按照官方给定方法划分训练集和测试集。我们不考虑实例数量少于50的类别(如飞机、摩托车和巴士)。检测任务与YOLO-fine62和SuperYOLO63相同,共包含八类不同目标。
-
AI-TOD数据集:AI-TOD56、57是面向航拍图像微小目标检测的数据集。相较于现有遥感目标检测数据集,AI-TOD中目标的平均尺寸仅约12.8像素,远小于其他公开数据集。该数据集包含28,036张航拍图像,共计700,621个目标实例,涵盖飞机、桥梁、储油罐等八类目标。我们采用官方提供的11,214张训练集图像和2,804张验证集图像(合计14,018张)进行训练,并在14,018张测试集上评估模型性能。
-
USOD数据集:现有公开数据集58、59包含大量中大型目标,难以验证检测器对小目标的特征提取性能。为此,我们基于UNICORN200860构建了UNICORN小目标数据集(USOD)以进一步验证FFCA-YOLO的检测能力。UNICORN2008提供的光电传感器成像数据空间分辨率约为0.4米,我们通过筛选、分割及人工标注小尺寸车辆目标,利用其可见光数据构建了USOD,如图6所示。此外,UNICORN2008部分SAR图像可与可见光图像配准,未来我们将把SAR图像纳入USOD,构建多模态版本数据集。

图6. UNICORN2008与USOD数据集中的真实标注对比。红色边界框为UNICORN2008原始标注实例,带绿色角点的边界框是为USOD补充的人工标注。(a)原始标注,(b)人工标注,©原始标注,(d)人工标注。
USOD数据集共包含3000张图像,涵盖43 378个车辆实例,训练集与测试集的比例为7:3。如图7所示,尺寸小于16×16像素的物体占比达96.3%,小于32×32像素的物体占比达99.9%。图8展示了训练集中小目标数量的分布情况,可见小目标分布较为均匀。综上所述,USOD具备以下特征,可作为遥感小目标检测领域的基准数据集。

- USOD中小目标的比例(99.9%)高于其他小目标数据集,如AI-TOD(97.9%)。
- USOD中包含大量低光照和阴影遮挡条件下的车辆实例,能更有效验证模型检测小目标的性能。
- USOD提供了一系列测试集用于验证模型鲁棒性,涵盖图像退化因素,包括模糊、高斯噪声、条纹噪声和雾化。
- USOD未来有望成为多模态数据集。其数据源UNICORN2008已注册可见光数据与SAR数据的配准图像。
B. 模型训练与评估指标
所提模型基于PyTorch框架实现,部署于配备NVIDIA 4090 GPU的工作站。采用随机梯度下降(SGD)优化器进行参数学习,初始学习率为0.01,动量为0.937,权重衰减为0.0005。训练过程中批量大小设为32。在YOLOv5的损失函数中引入归一化Wasserstein距离(NWD)57损失作为边界框损失的补充------该损失通过Wasserstein距离建模边界框间距,有效降低了IOU对小目标的敏感性。针对CIOU损失与NWD损失设置了0.5的调节权重。采用平均精度均值(mAP)作为标准评估指标,根据IOU阈值差异可分为mAP50、mAP75、mAP50:95等不同指标,本文主要采用mAP50和mAP50:95作为核心评估指标。此外,为体现模型对小目标的检测性能,额外引入mAPs作为专项评估指标。
C. 与现有方法的对比
FFCA-YOLO与L-FFCAYOLO的实验结果在VEDAI、AI-TOD和USOD三个数据集上呈现。在VEDAI和AI-TOD数据集中,我们将模型与当前先进方法及SOTA方法进行了对比。图9展示了FFCA-YOLO在不同数据集典型场景下的检测结果。在USOD数据集中,我们将其与其他YOLO模型及若干经典目标检测算法进行了性能比较。

图9. FFCA-YOLO算法在USOD、VEDAI和AI-TOD数据集中对港口、高速公路、建筑物等典型场景的检测结果。(a)USOD数据集检测结果 (b)VEDAI数据集检测结果 ©AI-TOD数据集检测结果
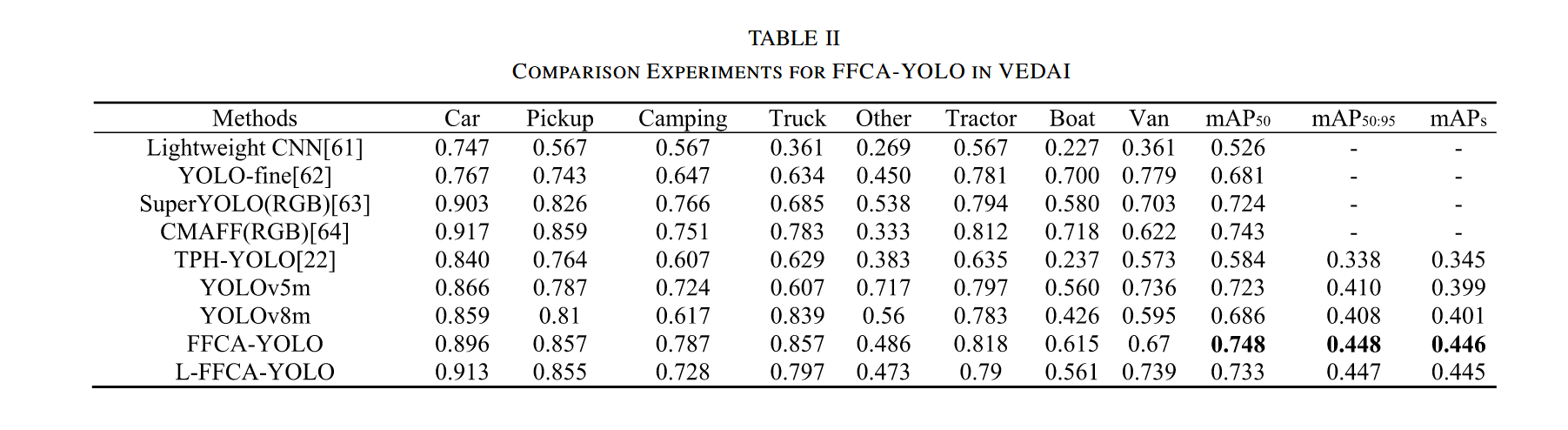
- VEDAI数据集:我们使用512×512分辨率的数据进行训练和验证。对比了轻量化CNN61、YOLO-fine62、SuperYOLO63和CMAFF64的结果。原始CMAFF和SuperYOLO均采用多模态数据训练,我们仅引用其在RGB数据训练下的结果以保持与训练集的一致性。表II显示,相比CMAFF,FFCA-YOLO在mAP50指标上提升0.005;相较于YOLOv5m,FFCA-YOLO在mAP50、mAP50:95和mAPs三个指标上分别提升0.025、0.038和0.047。值得注意的是,FFCA-YOLO在mAPs上的提升幅度显著高于mAP50和mAP50:95,这表明该网络在遥感小目标检测领域较基准网络具有显著优势。
- AI-TOD数据集:该数据集中小目标占比更高,能更好反映网络在微小目标检测上的能力。其评估指标与其他数据集不同,采用mAPvt、mAPt和mAPs三个指标,分别对应8×8像素以下、8×8至16×16像素、16×16至32×32像素尺寸目标的平均精度。表III显示,相较于现有最优方法(SOTA),FFCA-YOLO和LFFCA-YOLO均取得最佳性能。在测试集上,FFCA-YOLO的mAP50达到0.617,较当前最优模型HANet68提升0.08;mAP50:95、mAPvt、mAPt和mAPs分别提升0.056、0.015、0.027和0.045。结果表明FFCA-YOLO在遥感小目标检测中具有卓越性能。

- USOD数据集:表IV展示了DSSD69、RefineDet70、YOLOv319、YOLOv471、YOLOv5m、YOLOv8m、TPH-YOLO22以及本文方法在USOD数据集上的性能表现。可以看出,在相同训练超参数下,FFCA-YOLO相比基准方法具有更少的参数量和更高的性能。L-FFCA-YOLO将参数量较FFCA-YOLO减少了约30%(从7.12M降至5.04M),但精度指标未见明显下降。图10展示了YOLOv5m、TPH-YOLO和FFCA-YOLO在低照度与阴影遮挡场景下的检测结果。在低照度场景中,目标与背景的灰度值相近,导致YOLOv5m和TPH-YOLO出现漏检;在遮挡场景中,一个小目标位于树荫下,致使YOLOv5m发生漏检。


图10. YOLOv5m、TPH-YOLO与FFCA-YOLO在低照度及阴影遮挡场景下的检测结果。红色边界框代表模型输出的检测框,黄色圆圈标注区域为漏检目标。
D. 消融实验结果
为分析FFCAYOLO中各组件的贡献度,我们在基线模型中逐步应用FEM、FFM和SCAM模块以验证其有效性。消融实验在USOD数据集上进行。表V展示了各模块增减对评估指标的影响,其中√表示使用该模块,×表示不使用该模块。

-
特征增强模块(FEM):如表V所示,加入FEM后所有评估指标均显著提升,其中精确率(从0.9提升至0.926)和mAP值(从0.303提升至0.335)改善尤为明显。这证实FEM能有效帮助模型区分小目标与背景。为验证该结论,我们在图11中可视化对比了FEM处理前后的特征图,亮度越高表示模型对该区域关注度越高。由于FEM增强了局部上下文特征,网络对复杂背景表现出良好的抑制效果。
-
特征融合模块(FFM):如表V所示,引入FFM能全面提升各项评估指标,其中召回率提升尤为显著(从0.826增至0.837)。此外,我们针对第III-C节所述的不同颈部结构和多尺度特征图融合策略进行了实验研究,结果如表VI所示。CRC_1、CRC_2和CRC_3分别对应公式(8)-(10)中的不同通道重加权策略。可以看出,CRC_2和CRC_3在各项指标上均显著优于双向特征金字塔网络(BiFPN),且两者性能差异较小(CRC_2的mAP50:95仅比CRC_3高0.003)。因此最终选择CRC_2作为FFM中的通道重加权策略。

- SCAM模块:表V展示了引入SCAM带来的性能提升。该模块能全面改善所有评估指标。表VII对比了SCAM与典型基线方法,可见SCAM在所有指标上均取得更优表现。图11呈现了SCAM对特征图的影响------相较于FEM输出的特征图,SCAM同层级特征图进一步强化了小目标的特征表征,同时有效抑制背景干扰。通过上述消融实验分析可得出结论:本文提出的FEM、FFM和SCAM模块均能稳定提升FFCA-YOLO模型的性能,且彼此之间不存在冲突。



图11. FEM和SCAM对特征提取的影响。颜色越亮表示模型对该区域的关注度越高。
E. 鲁棒性实验
遥感数据在成像过程中往往存在各种退化、噪声效应或变异性,这可能导致目标物体与背景的混叠现象,尤其当目标较小时更为明显。为验证FFCA-YOLO在图像退化条件下的鲁棒性,我们基于文献73的研究,构建了模拟遥感图像退化的系列测试集。每个测试集采用相同的原始图像,但施加了不同的退化条件。考虑的退化类型包括图像模糊、高斯噪声、条纹噪声以及雾化效果。其中模糊因子w、高斯噪声方差σ²和条纹振幅系数r的设定参考了文献73;雾化图像的生成则采用文献74的模型,并设置不同的大气光参数A。图12展示了退化效果,可见图像退化会显著破坏小目标的特征。我们采用峰值信噪比(PSNR)来评估退化图像的质量。

图12. USOD中的模拟退化图像。
我们选择FFCA-YOLO和YOLOv5m进行鲁棒性测试。实验结果表明,FFCA-YOLO和YOLOv5m对图像模糊和雾化均具有一定程度的鲁棒性,其中FFCA-YOLO效果略优于YOLOv5m(详见表VIII)。遗憾的是,两种模型对高斯噪声和条纹噪声的抵抗能力较差,这些噪声会严重破坏小目标的特征。为缓解该问题,我们在数据增强过程中加入噪声模拟并重新训练模型。经重新训练后,FFCA-YOLO的抗噪能力显著提升,但仍无法有效处理强噪声图像。因此建议在检测小目标前,先采用图像去噪、非均匀性校正等方法抑制噪声。

F. 轻量级对比实验
为验证L-FFCA-YOLO的轻量化效果,将CSPFasterBlock与GhostBlock和ShuffleBlock进行对比,结果如表IX所示。可以看出,CSPFasterBlock在mAP50指标上表现突出,但计算量(GFLOPs)相对较大。这是因为GhostNet和ShuffleBlock存在更多计算冗余与内存访问。在相近GFLOPs条件下,CSPFasterBlock具有更快的推理速度,能更有效地平衡速度、精度和内存需求。此外,为获得CSPFasterBlock的最优结构,表IX还分析了不同通道缩放比例的影响。可以发现:当比例降低时,mAP50和参数量会同步下降;当比例等于2时,其性能与FFCA-YOLO最为接近。

!\[局部截取_20250329_175612.png]
5.结论
本文设计了一种名为FFCA-YOLO的高效检测器用于遥感小目标检测。具体提出了三个轻量级即插即用模块(FEM、FFM和SCAM):FEM采用多分支结构获取不同感受野,融合小目标的局部上下文信息;FFM设计新型特征融合策略以降低背景干扰;SCAM通过全局池化引导全局上下文学习,建立通道间相关性并重构像素间关联,实现跨通道与空间的全局上下文信息获取。此外还推出轻量化版本L-FFCA-YOLO,采用PConv重构主干网络和颈部结构,在保持精度的同时具有更快的速度、更小的参数量及更低算力需求。实验结果表明,在小目标检测数据集VEDAI(RGB)和AITOD上,FFCA-YOLO以0.748和0.617的mAP50精度超越现有SOTA模型。本文还构建了包含更高小目标占比、更多低光照场景及目标遮挡的新数据集USOD,FFCA-YOLO在该数据集各类退化条件下的测试中取得0.909的mAP50,显著优于YOLOv5m(0.873)等基准模型。尽管FFCA-YOLO在小目标检测任务中表现优异且具备未来星上实时处理的潜力,但仍存在一定局限性。
- 在硬件部署前,需进一步优化运行速度和内存利用率。
- 目前所提方法仅在航空数据集上得到验证。对于天基遥感而言,图像通常分辨率更低、质量更差且退化特征更复杂,因此本方法的有效性仍有待进一步研究和验证。
在研究过程中,我们发现现有深度学习网络仅依靠单一模态数据源时,其小目标检测能力存在瓶颈。我们认为,多源数据融合可使检测器获取更有效的小目标特征表征。因此,多平台协同检测或单平台多波段检测可能成为小目标检测应用的未来发展方向。
6.引用文献
- 1 K. Tong, Y. Wu, and F. Zhou, "Recent advances in small object detection based on deep learning: A review," Image Vis. Comput., vol. 97, May 2020, Art. no. 103910.
- 2 M. Shimoni, R. Haelterman, and C. Perneel, "Hypersectral imaging for military and security applications: Combining myriad processing and sensing techniques," IEEE Geosci. Remote Sens. Mag., vol. 7, no. 2, pp. 101--117, Jun. 2019.
- 3 V. Gagliardi et al., "Satellite remote sensing and non-destructive testing methods for transport infrastructure monitoring: Advances, challenges and perspectives," Remote Sens., vol. 15, no. 2, p. 418, Jan. 2023.
- 4 X. Sun et al., "RingMo: A remote sensing foundation model with masked image modeling," IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1--22, 2023, Art. no. 5612822, doi: 10.1109/TGRS.2022.3194732.
- 5 Q. He, X. Sun, Z. Yan, B. Li, and K. Fu, "Multi-object tracking in satellite videos with graph-based multitask modeling," IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1--13, 2022, Art. no. 5619513, doi: 10.1109/TGRS.2022.3152250.
- 6 F. Zhang, X. Wang, S. Zhou, Y. Wang, and Y. Hou, "Arbitraryoriented ship detection through center-head point extraction," IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1--14, 2022, Art. no. 5612414, doi: 10.1109/TGRS.2021.3120411.
- 7 T. Shi et al., "Feature-enhanced CenterNet for small object detection in remote sensing images," Remote Sens., vol. 14, no. 21, p. 5488, Oct. 2022.
- 8 H. Ruan, W. Qian, Z. Zheng, and Y. Peng, "A decoupled semanticdetail learning network for remote sensing object detection in complex backgrounds," Electronics, vol. 12, no. 14, p. 3201, Jul. 2023.
- 9 Q. Ran, Q. Wang, B. Zhao, Y. Wu, S. Pu, and Z. Li, "Lightweight oriented object detection using multiscale context and enhanced channel attention in remote sensing images," IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 5786--5795, 2021.
- 10 B. Zhang et al., "Progress and challenges in intelligent remote sensing satellite systems," IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 15, pp. 1814--1822, 2022.
- 11 B. Vajsova, A. Walczynska, S. Bärisch, P. J. Åstrand, and S. Hain, "New sensors benchmark report on WorldView-4," Publications Office Eur. Union, Luxembourg, U.K., Tech. Rep. EUR 28761 EN, 2017.
- 12 R. Trautner and R. Vitulli, "Ongoing developments of future payload data processing platforms at ESA," in Proc. On-Board Payload Data Compress. Workshop (OBPDC), 2010.
- 13 X. Wang, R. Girshick, A. Gupta, and K. He, "Non-local neural networks," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 7794--7803.
- 14 Y. Cao, J. Xu, S. Lin, F. Wei, and H. Hu, "GCNet: Non-local networks meet squeeze-excitation networks and beyond," in Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshop (ICCVW), Oct. 2019, pp. 1971--1980.
- 15 Y. Cao, J. Xu, S. Lin, F. Wei, and H. Hu, "Global context networks," IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 6, pp. 6881--6895, Jun. 2023.
- 16 S. Q. Ren et al., "Faster R-CNN: Towards real-time object detection with region proposal networks," IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1137--1149, 2017, doi: 10.1109/TPAMI.2016.2577031.
- 17 K. He, G. Gkioxari, P. Dollár, and R. Girshick, "Mask R-CNN," in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2961--2969.
- 18 J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, "You only look once: Unified, real-time object detection," in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 779--788.
- 19 J. Redmon and A. Farhadi, "YOLOv3: An incremental improvement," 2018, arXiv:1804.02767.
- 20 C.-Y. Wang, A. Bochkovskiy, and H.-Y.-M. Liao, "YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2023, pp. 7464--7475.
- 21 W. Liu et al., "SSD: Single shot MultiBox detector," in Proc. Eur. Conf. Comput. Vis. Cham, Switzerland: Springer, 2016, pp. 21--37.
- 22 X. Zhu, S. Lyu, X. Wang, and Q. Zhao, "TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios," in Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshops (ICCVW), Oct. 2021, pp. 2778--2788.
- 23 M. Wang et al., "FE-YOLOv5: Feature enhancement network based on YOLOv5 for small object detection," J. Vis. Commun. Image Represent., vol. 90, Feb. 2023, Art. no. 103752.
- 24 L. Shen, B. Lang, and Z. Song, "CA-YOLO: Model optimization for remote sensing image object detection," IEEE Access, vol. 11, pp. 64769--64781, 2023.
- 25 T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, "Feature pyramid networks for object detection," in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 2117--2125.
- 26 S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, "Path aggregation network for instance segmentation," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 8759--8768.
- 27 G. Ghiasi, T.-Y. Lin, and Q. V. Le, "NAS-FPN: Learning scalable feature pyramid architecture for object detection," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 7036--7045.
- 28 S. Liu, D. Huang, and Y. Wang, "Learning spatial fusion for single-shot object detection," 2019, arXiv:1911.09516.
- 29 M. Tan, R. Pang, and Q. V. Le, "EfficientDet: Scalable and efficient object detection," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 10781--10790.
- 30 C. Guo, B. Fan, Q. Zhang, S. Xiang, and C. Pan, "AugFPN: Improving multi-scale feature learning for object detection," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 12595--12604.
- 31 Z. Liu, G. Gao, L. Sun, and Z. Fang, "HRDNet: High-resolution detection network for small objects," in Proc. IEEE Int. Conf. Multimedia Expo (ICME), Jul. 2021, pp. 1--6.
- 32 G. Cheng et al., "Feature enhancement network for object detection in optical remote sensing images," J. Remote Sens., vol. 1, p. 14, 2021, doi: 10.34133/2021/9805389.
- 33 K. Zhang and H. Shen, "Multi-stage feature enhancement pyramid network for detecting objects in optical remote sensing images," Remote Sens., vol. 14, no. 3, p. 579, Jan. 2022.
- 34 R. Liu et al., "RAANet: A residual ASPP with attention framework for semantic segmentation of high-resolution remote sensing images," Remote Sens., vol. 14, no. 13, p. 3109, Jun. 2022.
- 35 Y. Li, Z. Cheng, C. Wang, J. Zhao, and L. Huang, "RCCT-ASPPNet: Dual-encoder remote image segmentation based on transformer and ASPP," Remote Sens., vol. 15, no. 2, p. 379, Jan. 2023.
- 36 W. Chen, S. Ouyang, W. Tong, X. Li, X. Zheng, and L. Wang, "GCSANet: A global context spatial attention deep learning network for remote sensing scene classification," IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 15, pp. 1150--1162, 2022.
- 37 Y. Zhou et al., "BOMSC-Net: Boundary optimization and multi-scale context awareness based building extraction from high-resolution remote sensing imagery," IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1--17, 2022, Art. no. 5618617, doi: 10.1109/TGRS.2022.3152575.
- 38 Y. Liu, H. Li, C. Hu, S. Luo, Y. Luo, and C. Wen Chen, "Learning to aggregate multi-scale context for instance segmentation in remote sensing images," 2021, arXiv:2111.11057.
- 39 J. Hu, L. Shen, and G. Sun, "Squeeze-and-excitation networks," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 7132--7141.
- 40 S. Woo, J. Park, J. Y. Lee, and I. S. Kweon, "CBAM: Convolutional block attention module," in Proc. Eur. Conf. Comput. Vis. (ECCV)., 2018, pp. 3--19.
- 41 Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, and C. Zhang, "Learning efficient convolutional networks through network slimming," in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2736--2744.
- 42 Y. He, X. Zhang, and J. Sun, "Channel pruning for accelerating very deep neural networks," in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 1389--1397.
- 43 S. Guo, Y. Wang, Q. Li, and J. Yan, "DMCP: Differentiable Markov channel pruning for neural networks," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 1536--1544.
- 44 J. Chang, Y. Lu, P. Xue, Y. Xu, and Z. Wei, "Automatic channel pruning via clustering and swarm intelligence optimization for CNN," Appl. Intell., vol. 52, pp. 17751--17771, Apr. 2022.
- 45 A. G. Howard et al., "MobileNets: Efficient convolutional neural networks for mobile vision applications," 2017, arXiv:1704.04861.
- 46 X. Zhang, X. Zhou, M. Lin, and J. Sun, "ShuffleNet: An extremely efficient convolutional neural network for mobile devices," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 6848--6856.
- 47 K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, and C. Xu, "GhostNet: More features from cheap operations," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 1580--1589.
- 48 L. Huyan et al., "A lightweight object detection framework for remote sensing images," Remote Sens., vol. 13, no. 4, p. 683, Feb. 2021.
- 49 J. Yi, Z. Shen, F. Chen, Y. Zhao, S. Xiao, and W. Zhou, "A lightweight multiscale feature fusion network for remote sensing object counting," IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1--13, 2023, Art. no. 5902113, doi: 10.1109/TGRS.2023.3238185.
- 50 J. Liu, R. Liu, K. Ren, X. Li, J. Xiang, and S. Qiu, "High-performance object detection for optical remote sensing images with lightweight convolutional neural networks," in Proc. IEEE 22nd Int. Conf. High Perform. Comput. Commun., IEEE 18th Int. Conf. Smart City, IEEE 6th Int. Conf. Data Sci. Syst. (HPCC/SmartCity/DSS), Dec. 2020, pp. 585--592.
- 51 J. Chen et al., "Run, don't walk: Chasing higher FLOPS for faster neural networks," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2023, pp. 12021--12031.
- 52 S. Liu and D. Huang, "Receptive field block net for accurate and fast object detection," in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 385--400.
- 53 Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, and Q. Hu, "ECA-Net: Efficient channel attention for deep convolutional neural networks," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 11534--11542.
- 54 A. Vaswani et al., "Attention is all you need," in Proc. Adv. Neural Inf. Process. Syst., vol. 30, 2017, pp. 5998--6008.
- 55 S. Razakarivony and F. Jurie, "Vehicle detection in aerial imagery: A small target detection benchmark," J. Vis. Commun. Image Represent., vol. 34, pp. 187--203, Jan. 2016.
- 56 J. Wang, W. Yang, H. Guo, R. Zhang, and G.-S. Xia, "Tiny object detection in aerial images," in Proc. 25th Int. Conf. Pattern Recognit. (ICPR), Jan. 2021, pp. 3791--3798.
- 57 J. Wang, C. Xu, W. Yang, and L. Yu, "A normalized Gaussian Wasserstein distance for tiny object detection," 2021, arXiv:2110.13389.
- 58 T.-Y. Lin et al., "Microsoft COCO: Common objects in context," in Proc. Eur. Conf. Comput. Vis. Cham, Switzerland: Springer, 2014, pp. 740--755.
- 59 G.-S. Xia et al., "DOTA: A large-scale dataset for object detection in aerial images," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 3974--3983.
- 60 L. Colin et al. (2019). Unified Coincident Optical and Radar for Recognition (UNICORN) 2008 Dataset. Online. Available: https://github.com/AFRL-RY/data-unicorn-2008
- 61 M. A. Momin, M. H. Junos, A. S. M. Khairuddin, and M. S. A. Talip, "Lightweight CNN model: Automated vehicle detection in aerial images," Signal, Image Video Process., vol. 17, no. 4, pp. 1209--1217, Jun. 2023.
- 62 M.-T. Pham, L. Courtrai, C. Friguet, S. Lefèvre, and A. Baussard, "YOLO-Fine: One-stage detector of small objects under various backgrounds in remote sensing images," Remote Sens., vol. 12, no. 15, p. 2501, Aug. 2020.
- 63 J. Zhang, J. Lei, W. Xie, Z. Fang, Y. Li, and Q. Du, "SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery," IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1--15, 2023, Art. no. 5605415, doi: 10.1109/TGRS.2023.3258666.
- 64 F. Qingyun and W. Zhaokui, "Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery," Pattern Recognit., vol. 130, Oct. 2022, Art. no. 108786.
- 65 Z. Cai and N. Vasconcelos, "Cascade R-CNN: Delving into high quality object detection," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 6154--6162.
- 66 S. Qiao, L.-C. Chen, and A. Yuille, "DetectoRS: Detecting objects with recursive feature pyramid and switchable atrous convolution," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2021, pp. 10213--10224.
- 67 M. Ma and H. Pang, "SP-YOLOv8s: An improved YOLOv8s model for remote sensing image tiny object detection," Appl. Sci., vol. 13, no. 14, p. 8161, Jul. 2023.
- 68 G. Guo, P. Chen, X. Yu, Z. Han, Q. Ye, and S. Gao, "Save the tiny, save the all: Hierarchical activation network for tiny object detection," IEEE Trans. Circuits Syst. Video Technol., vol. 34, no. 1, pp. 221--234, Jan. 2024, doi: 10.1109/TCSVT.2023.3284161.
- 69 C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg, "DSSD : Deconvolutional single shot detector," 2017, arXiv:1701.06659.
- 70 S. Zhang, L. Wen, X. Bian, Z. Lei, and S. Z. Li, "Single-shot refinement neural network for object detection," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 4203--4212.
- 71 A. Bochkovskiy, C.-Y. Wang, and H.-Y. Mark Liao, "YOLOv4: Optimal speed and accuracy of object detection," 2020, arXiv:2004.10934.
- 72 G. Yang, J. Lei, Z. Zhu, S. Cheng, Z. Feng, and R. Liang, "AFPN: Asymptotic feature pyramid network for object detection," 2023, arXiv:2306.15988.
- 73 C. Li, Z. Li, X. Liu, and S. Li, "The influence of image degradation on hyperspectral image classification," Remote Sens., vol. 14, no. 20, p. 5199, Oct. 2022.
- 74 K. He, J. Sun, and X. Tang, "Single image haze removal using dark channel prior," IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 12, pp. 2341--2353, Dec. 2010.