
1.基础训练流程
1.1 什么是模型训练?
简单一句话:训练就是准备好数据集和模型,然后不断把数据集投喂给模型,让模型慢慢掌握预测的能力。
1.2 训练要关注什么?
📚 数据集: 数据集就是"投喂" 为模型的物料。
首先要搞清楚你的目标是想让模型预测什么?有没有现成的数据集? 如果有人已经做过这种数据集并且资料公开,那我们就可以直接拿来用。如果比较特殊,没有人做过,那我们就只能自己动手做一个数据集了。
📦 模型: 就是你要训练哪个模型。前一篇中看到 Ultralytics准备好了各种版本,各种大小。我们要做的就是选择一个模型来训练,或者别人训练好的拿过来改进,提升效果。
📌训练选项:在开始训练之前,有一些训练选项我们需要进行调整:
- 一共要投喂多少轮?
epochs=? - 图片缩放到多少?
imgsz=? - 每个批次打包多少张图片?
batch=? - 要不要缓存加速一下训练?
cache=? - 要不要多用几个进程加载数据集?
workers=?
2.尝试跑通最简单的YOLO训练
打开VS Code,SSH 连接到项目:
在项目根目录下创建一个文件 mytrain.py
python
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolov8n.pt')
# 开启训练
model.train(
data=r'coco8.yaml',
epochs=10, # 训练轮数
imgsz=640, # 训练图片大小
batch=2, # 训练批次
cache=False, # 是否缓存数据
workers=0, # 训练进程数
)执行后,会自动下载两个文件,我截取了部分日志:
latex
WARNING ⚠️ Dataset 'coco8.yaml' images not found, missing path '/home/qy/yolo/ultralytics-8.3.229/datasets/coco8/images/val'
Downloading https://ultralytics.com/assets/coco8.zip to '/home/qy/yolo/ultralytics-8.3.229/datasets/coco8.zip': 100% ━━━━━━━━━━━━ 432.8KB 402.5KB/s 1.1s
Unzipping /home/qy/yolo/ultralytics-8.3.229/datasets/coco8.zip to /home/qy/yolo/ultralytics-8.3.229/datasets/coco8...: 100% ━━━━━━━━━━━━ 25/25 2.0Kfiles/s 0.0s
Dataset download success ✅ (2.3s), saved to /home/qy/yolo/ultralytics-8.3.229/datasets第一个文件:在数据集目录下没有找到 coco8.yaml 这个配置文件,
于是开始到 https://ultralytics.com/assets/coco8.zip 下载,并保存到了
/home/qy/yolo/ultralytics-8.3.229/datasets/coco8.zip, 随后进行了解压如果下载失败了,就手动下载,然后放入到提示的对应的目录中。注意不要去解压缩文件,它会自动被解压缩
latex
Downloading https://ultralytics.com/assets/Arial.ttf to '/home/qy/.config/Ultralytics/Arial.ttf': 100% ━━━━━━━━━━━━ 755.1KB 99.9KB/s 7.6s第二个文件:下载了一个 字体文件,保存到了
/home/qy/.config/Ultralytics/Arial.ttf
然后看到类似的进度条,就表示已经开始训练了:
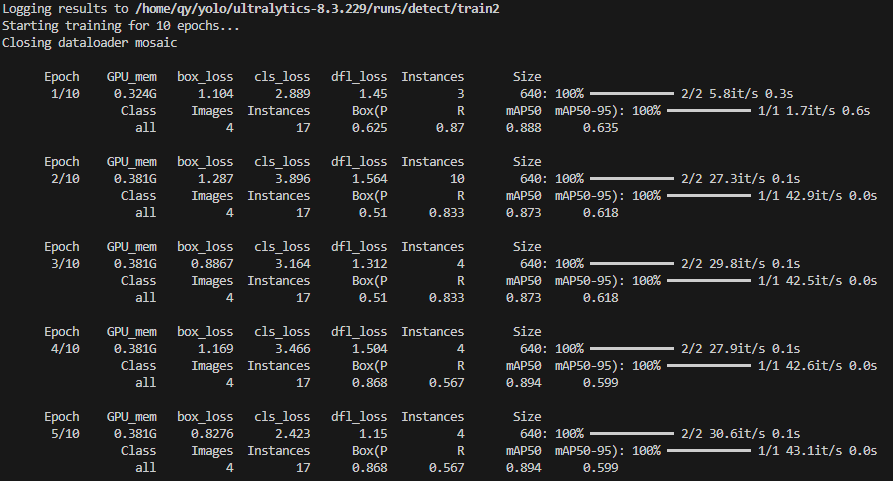
最前面的 Epoch ,可以清楚的看到这是第几轮训练。
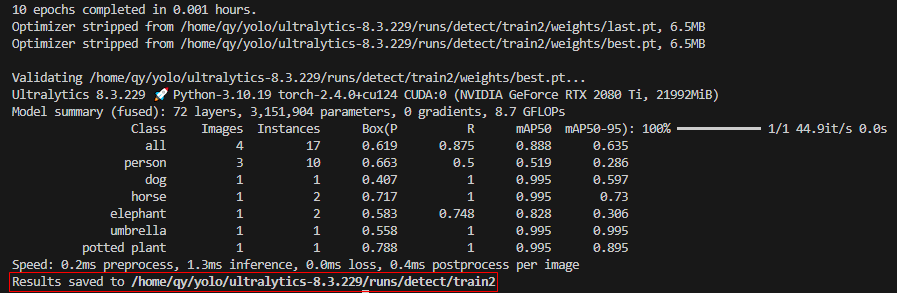
最终,训练完成之后,结果被保存到了 ......runs/detect/train2文件夹中了。
在weights文件夹中有两个.pt文件, best.pt就是我们通过训练后,得到的模型。其它还有一些图片,这些图片都是用来评价这次训练的,即给best.pt的各项指标打分。
3.理解数据集重要
3.1 YOLO需要什么样的数据集
关于训练,就是将一堆图片投喂给模型。那么对于这堆图片,数据集通常会按照一定比例进行划分为: 训练集(多的部分)和 验证集(少的部分)
3.2 训练集/验证集

每一轮训练就分为两个部分:
- 用训练集更新模型的参数, 这是真正意义上的训练
- 再使用验证集看看训练效果好不好
所以训练就是不断重复: 训练->验证 , 训练->验证 ... 的过程。
每一轮训练会看到两个进度条,第一个进度条是训练,第二个进度条是验证。

也可以跳过验证,只需要添加一个参数val=False即可,添加这个参数后,就会看到只有一个进度条了:
python
# 开启训练
model.train(
data=r'coco8.yaml',
epochs=10, # 训练轮数
imgsz=640, # 训练图片大小
batch=2, # 训练批次
cache=False, # 是否缓存数据
workers=0, # 训练进程数
val=False # 是否验证
)3.3 测试集
这堆图片除了被划分为 训练集和验证集,还会划分一部分出来作为测试集,比如按照 7:2:1进行划分:

每一轮都会用到 训练集和验证集,但是测试集不参与训练,它的作用是等到整场训练完毕后,用来评估模型的效果。就是看谁在测试集上取得更好的效果。其办法就是拿
测试集上的标签与预测结果进行对比,进行相似度计算,相似度(得分)高的取胜,其实就是一个量化的过程。不是每个数据集都提供测试集的,也就是说测试集不是必须的,你可以在实际用的过程中查看效果,这其实也是一种测试,只不过这个测试没有量化。
4.数据集
在训练程序中指定了一个参数:
python
data=r'coco8.yaml' # 可以是一个绝对路径可以看到这个文件其实是一个 yaml格式的配置文件,它的作用就是训练开始前用来告诉YOLO, 训练集/验证集图片/标签分别在按个文件夹。
4.1 数据集目录结构
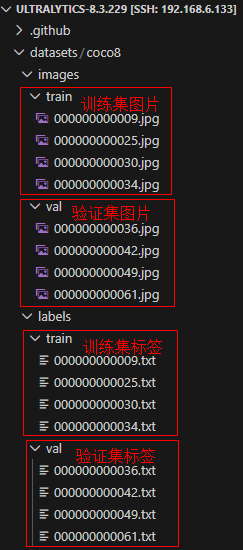
也就是说一个数据集文件夹是必须按照一定的目录结构来组织数据:
coco8.yaml文件的实际路径是:ultralytics/cfg/datasets/coco8.yaml数据集文件夹结构:
yaml
path: coco8 # 数据集在的路径,这里实际路径是 项目根目录/datasets/coco8, 也可以是一个绝对路径
# 对应的训练标签文件夹就是 labels/train
train: images/train # 训练集图片文件夹,
# 对应的验证标签文件夹就是 labels/val
val: images/val # 验证集图片文件夹
test: # 测试集图片文件夹[可选]
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
...
# Download script/URL (optional)
download: https://github.com/ultralytics/assets/releases/download/v0.0.0/coco8.zip4个文件夹,有任何一个文件夹找不到,训练程序就会报错
4.2 标签文件内容
每个训练文件图片都会对应一个标签文件,标签文件说的是图片中有什么东西,分别在什么地方:
如:
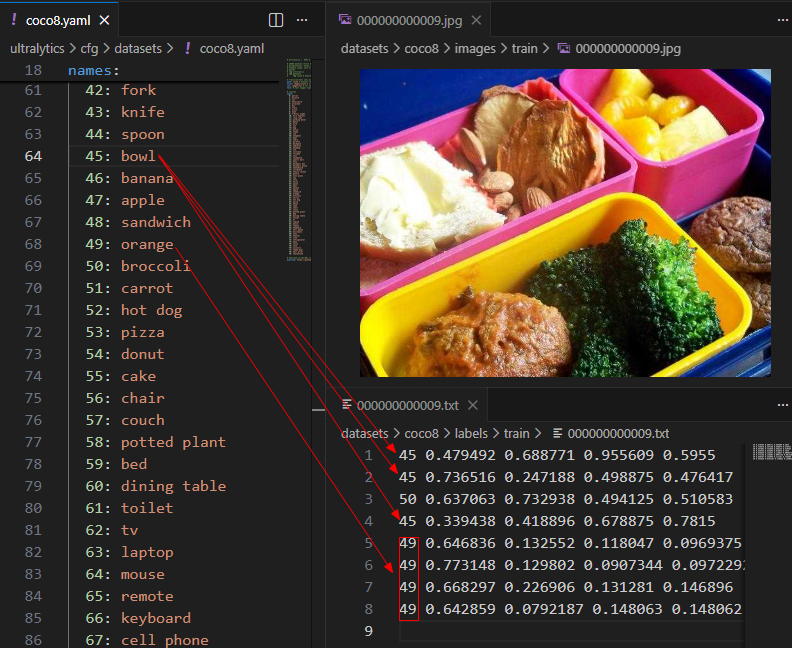
标签文件中(以第一行为例):(注意坐标系远点在图片的左上角)
- 第一列(类型):就是 配置文件中分类的编号,如
45它表示碗 - 第二列(cx):框中心点横坐标占用图片宽度的比例
- 第三列(cy) :框中心点纵坐标占图片高度的比例
- 第四列(w): 框的宽度占图片宽度的比例
- 第四列(h): 框的高度占图片高度的比例

标签可视化可以使用工具LabelImg来制作自己的数据集:
4.Labellmg
4.1安装
需要使用pip进行安装。因为它是用于标注的图形化软件,所以在windows上安装python环境,并安装conda虚拟环境:
shell
# 创建一个conda环境, Labellmg 兼容 python 3.9 环境
(base) conda create -n labelimg python=3.9
#激活虚拟环境
(base) conda activate labelimg
# 接下来会使用pip安装依赖,所以天添加国内加速
(labelimg) pip config set global.index-url https://mirrors.huaweicloud.com/repository/pypi/simple/
(labelimg) pip install labelimg
# 输入labelimg运行
labelimg
4.2 标记coco8数据集
由于labelimg 编辑器在windows上,而前面下载的 coco8 数据集在服务器上,所以要将服务器上的coco8 数据集下载到本地。
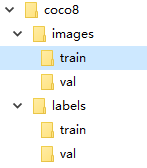
Labellmg 对数据集的要求除了标准数据集目录结构以外,还要求在
labels\train文件夹下有一个classes.txt文件,内容与coco8.yaml文件中的names节点一样,它要去掉前面的数字,即: 没有类型序号,只有类型名称
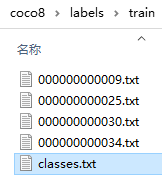
classes.txt内容如下(拷贝coco8.yamlnames节点内容,去掉前面的数字+冒号),下面是去掉后的部分内容:
latex
person
bicycle
car
motorcycle
airplane
bus
...
现在在运行labelimg命令的时候,需要为它添加
- 训练数据集文件夹绝对路径,如:
E:\coco8\images\train - 训练数据集标签文件夹绝对路径 ,如:
E:\coco8\labels\train - classes.txt 文件绝对路径, 如:
E:\coco8\labels\classes.txt
shell
labelimg E:\coco8\images\train E:\coco8\labels\train\classes.txt E:\coco8\labels\train现在就可以看到每个图片的标记内容了:
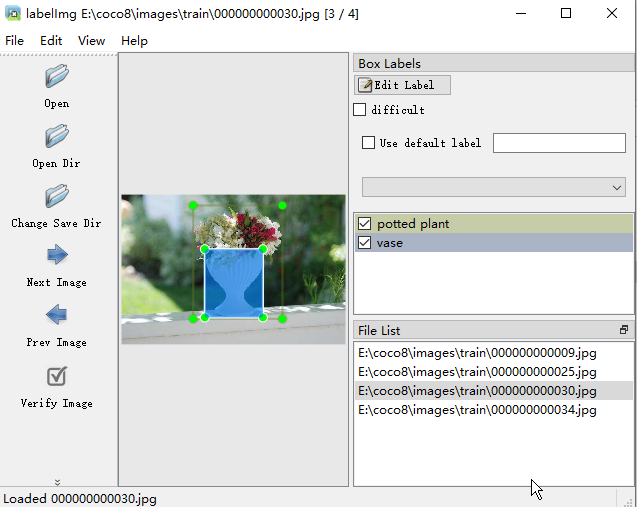
要想看到表面名称,需要打开:
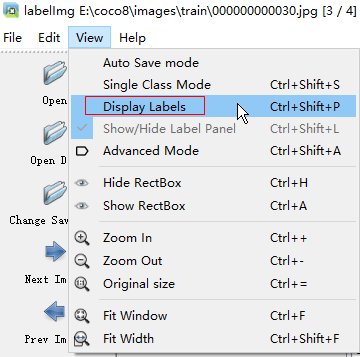
这样我们就可以自己来进行标注了。
5.怎么获取现成的数据集
在 ultralytics/cfg/datasets文件夹下可以看到还有很多内置的数据集。这些内置的数据集中都配置了下载地址。
步骤:
- 修改程序(
mytrain.py)中model.train的 data参数,指定要数据集配置文件名称 - 运行程序,程序会自动下载。如果自动下载出现问题,则手工下载后将文件放入到提示指定的地方。
- 在标签目录中添加
classes.txt文件,内容从数据集配置文件中拷贝,去掉分类序号,保留分类名称。