文章目录
前言
上一篇文章我们学习了感知机,因为它和神经网络有很多共同点,所以这一篇正式进入神经网络一定也会很顺畅。
一个神经网络的例子
通过下面的神经网络图形,我们学习几个基础的术语:
- 输入层:最左边的一列,每个神经元代表一个输入特征,负责接收外部数据;
- 隐藏层/中间层 :中间的一列,负责数据的特征提取、模式识别和非线性变换,它是神经网络能学习复杂关系的关键部分;每个神经元都进行计算,并使用激活函数引入非线性;
- 输出层:最后一列,复杂将隐藏层提取的特征转换为最终的预测结果;
- 神经元层数:下图有3层;
- 权重层数:下图有2层;
- 网络层数 :我们用权重层数来表示,因此是2层。

激活函数登场
上面在介绍隐藏层的时候提到了激活函数,下图明确展示了激活函数的计算过程。首先输入通过权重和偏置计算得到 a = w 1 x 1 + w 2 x 2 + b a = w_1x_1+w_2x_2+b a=w1x1+w2x2+b, h h h函数就是激活函数,将 a a a激活转换成 y y y,即 y = h ( x ) y=h(x) y=h(x)。

激活函数的常见形式包括:

图像如下:

一般朴素感知机 是指激活函数使用了阶跃函数 的模型,而神经网络 则是激活函数使用了sigmoid等平滑函数的多层网络。
3层神经网络的实现
矩阵运算
回忆一个矩阵计算的规则:矩阵A的第一维元素个数(列数)必须等于矩阵B的第0维元素的个数(行数)。

实现神经网络时,要特别注意x的维度和w的维度是否一致

3层神经网络示意图

符号定义

第一层信号传递
以 a 1 ( 1 ) a_{1}^{(1)} a1(1)的计算为例:
a 1 ( 1 ) = w 11 ( 1 ) x 1 + w 12 ( 1 ) x 2 + b 1 ( 1 ) a_{1}^{(1)}=w_{11}^{(1)}x_1+w_{12}^{(1)}x_2+b_{1}^{(1)}\\ a1(1)=w11(1)x1+w12(1)x2+b1(1)

用矩阵的运算符号可以将第一层的计算表示为:
A ( 1 ) = X W ( 1 ) + B ( 1 ) A^{(1)}=XW^{(1)}+B^{(1)} A(1)=XW(1)+B(1)
其中:
A ( 1 ) = ( a 1 ( 1 ) , a 2 ( 1 ) , a 3 ( 1 ) ) A^{(1)}=(a_{1}^{(1)}, a_{2}^{(1)}, a_{3}^{(1)}) A(1)=(a1(1),a2(1),a3(1))
X = ( x 1 , x 2 ) X=(x_1, x_2) X=(x1,x2)
W ( 1 ) = ( w 11 ( 1 ) w 21 ( 1 ) w 31 ( 1 ) w 12 ( 1 ) w 22 ( 1 ) w 32 ( 1 ) ) \mathbf{W}^{(1)} = \begin{pmatrix} w_{11}^{(1)} & w_{21}^{(1)} & w_{31}^{(1)} \\ w_{12}^{(1)} & w_{22}^{(1)} & w_{32}^{(1)} \end{pmatrix} \ W(1)=(w11(1)w12(1)w21(1)w22(1)w31(1)w32(1))
激活函数的计算示意图如下:
Z 1 = s i g m o i d ( A 1 ) Z_1 = sigmoid(A_1) Z1=sigmoid(A1)

第二层信号传递

第三层信号传递
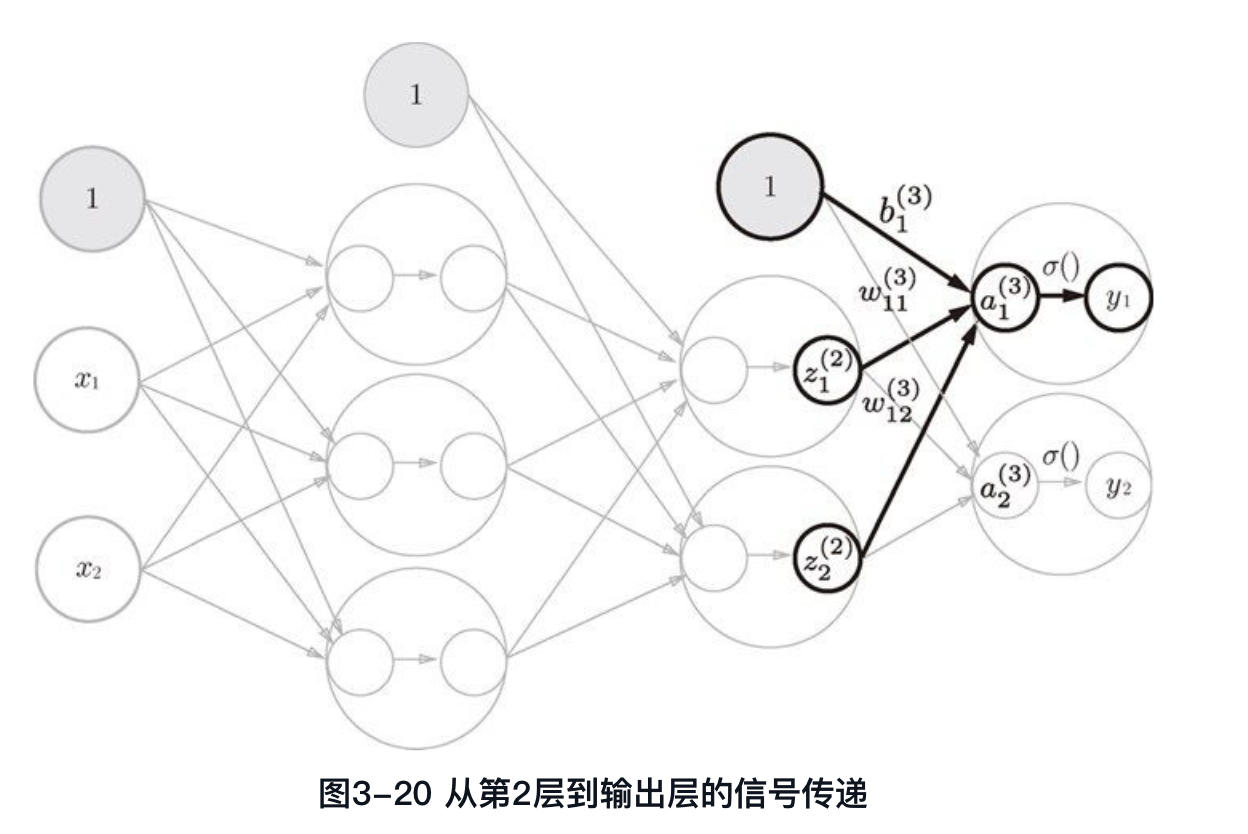
代码实现
python
def sigmoid(x):
"""
计算输入 x 的 Sigmoid 值。
:param x: 标量或 NumPy 数组
:return: Sigmoid 变换后的值
"""
return 1 / (1 + np.exp(-x))
def identify_function(x):
"""恒等函数"""
return x
def init_network():
"""initialize weight and biases"""
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5],[0.2, 0.4, 0.6])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4],[0.2, 0.5],[0.3, 0.6])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3],[0.2, 0.4])
network['b3'] = np.array([0.1, 0.2])
return
def forward():
"""transfer input to output"""
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a1 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identify_function(a3)
return y实践:手写数字识别
上面我们代码里的forward函数也称为神经网络的推理 过程或前向传播。完整的机器学习过程分为学习过程和推理过程两部分,神经网络也是如此。接下来我们假设使用数据学习权重和偏置的过程已经结束,现在只需根据学习到的参数,进行推理。
python
import sys, os
sys.path.append(os.pardir) # 为了导入父目录中的文件而进行的设定
from dataset.mnist import load_mnist
def get_data():
(x_train, t_train), (x_test, t_test) = \
load_mnist(normalize=True, flatten=True, one_hot_label=False) # normalize将输入归一到0~1之间的数值
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))通过上面的代码学习几个术语:
- 正规化:将数据限定到某个范围内的处理;
- 预处理:对神经网络的输入进行某种特定的转换;
- 数据白化:将数据整体的分布形状均匀化;
- 批处理:
上例中,拿到一张图片进行推理时,输入层是784(图像大小28*28)个神经元,输出层是10(数字0-9共10个类别)个神经元,数组形状变化如下:

设想如果我们想一次推理100张图片呢?数组形状变化就会变成下图所示:

这种打包式的输入称为"批"。批处理一次性计算大型数组要比分开逐步计算各个小型数组速度更快。批处理的代码如下:
python
x, t = get_data()
network = init_network()
batch_size = 100 # 批数量
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])参考资料
1 斋藤康毅. (2018). 深度学习入门:基于Python的理论与实践. 人民邮电出版社.