目录
- 部署组件
- 方案概述
- 部署高可用组件
- 集群部署
- 集群初始化
- 安装NIC插件
- 添加Worker节点
- Helm部署
- Metrics部署
- [Nginx ingress部署](#Nginx ingress部署)
- Dashboard部署
- Longhorn存储部署
- kube-Prometheus部署
- [kubesphere 部署](#kubesphere 部署)
- 扩展:集群扩容及缩容
部署组件
该 Kubernetes 部署过程中,对于部署环节,涉及多个组件,主要有 kubeadm 、kubelet 、kubectl。
kubeadm介绍
Kubeadm 为构建 Kubernetes 提供了便捷、高效的"最佳实践" ,该工具提供了初始化完整 Kubernetes 过程所需的组件,其主要命令及功能有:
- kubeadm init:用于搭建 Kubernetes 控制平面节点;
- kubeadm join:用于搭建 Kubernetes 工作节点并将其加入到集群中;
- kubeadm upgrade:用于升级 Kubernetes 集群到新版本;
- kubeadm token:用于管理 kubeadm join 使用的 token;
- kubeadm reset:用于恢复(重置)通过 kubeadm init 或者 kubeadm join 命令对节点进行的任何变更;
- kubeadm certs:用于管理 Kubernetes 证书;
- kubeadm kubeconfig:用于管理 kubeconfig 文件;
- kubeadm version:用于显示(查询)kubeadm 的版本信息;
- kubeadm alpha:用于预览当前从社区收集到的反馈中的 kubeadm 特性。
更多参考:Kubeadm介绍
kubelet介绍
kubelet 是 Kubernetes 集群中用于操作 Docker 、containerd 等容器运行时的核心组件,需要在每个节点运行。通常该操作是基于 CRI 实现,kubelet 和 CRI 交互,以便于实现对 Kubernetes 的管控。
kubelet 主要用于配置容器网络、管理容器数据卷等容器全生命周期,对于 kubelet 而言,其主要的功能核心有:
- Pod 更新事件;
- Pod 生命周期管理;
- 上报 Node 节点信息。
更多参考:kubelet介绍
kubectl介绍
kubectl 控制 Kubernetes 集群管理器,是作为 Kubernetes 的命令行工具,用于与 apiserver 进行通信,使用 kubectl 工具在 Kubernetes 上部署和管理应用程序。
使用 kubectl,可以检查群集资源的创建、删除和更新组件。
同时集成了大量子命令,可更便捷的管理 Kubernetes 集群,主要命令如下:
- Kubetcl -h:显示子命令;
- kubectl option:查看全局选项;
- kubectl <command> --help:查看子命令帮助信息;
- kubelet command PARAMS -o=<format>:设置输出格式,如json、yaml等;
- Kubetcl explain RESOURCE:查看资源的定义。
更多参考:kubectl介绍
方案概述
方案介绍
本方案基于 kubeadm 部署工具实现完整生产环境可用的 Kubernetes 高可用集群,同时提供相关 Kubernetes 周边组件。
其主要信息如下:
- 版本:Kubernetes 1.32.3 版本;
- kubeadm:采用 kubeadm 部署 Kubernetes ;
- OS:Ubuntu Server 24.04 LTS;
- etcd:采用融合方式;
- HAProxy:以系统systemd形式运行,提供反向代理至3个master 6443端口;
- KeepAlived:用于实现 apiserver 的高可用;
- KubeSphere:是基于 Kubernetes 内核的分布式多租户商用云原生操作系统。在开源能力的基础上,在多云集群管理、微服务治理、应用管理等多个核心业务场景进行功能延伸。
- Prometheus+Grafana:用于集群监控;
- 其他主要部署组件包括:
- Metrics:度量组件,用于提供相关监控指标;
- Dashboard:Kubernetes 集群的前端图形界面;
- Helm:Kubernetes Helm 包管理器工具,用于后续使用 helm 整合包快速部署应用;
- Ingress:Kubernetes 服务暴露应用,用于提供7层的负载均衡,类似 Nginx,可建立外部和内部的多个映射规则;
- containerd:Kubernetes 底层容器时;
- Longhorn:Kubernetes 动态存储组件,用于提供 Kubernetes 的持久存储。
提示:本方案部署所使用脚本均由本人提供,可能不定期更新。
部署规划
节点规划
| 节点主机名 | IP | 类型 | 可运行服务/组件 |
|---|---|---|---|
| master01 | 172.24.8.181 | Kubernetes master节点 | kubeadm、kubelet、kubectl、KeepAlived、containerd etcd、kube-apiserver、kube-scheduler、kube-controller-manager、calico dashboard、metrics、ingress、Longhorn ui节点、Prometheus+Grafana节点 KubeSphere节点 |
| master02 | 172.24.8.182 | Kubernetes master节点 | kubeadm、kubelet、kubectl、KeepAlived、containerd etcd、kube-apiserver、kube-scheduler、kube-controller-manager、calico dashboard、metrics、ingress、Longhorn ui节点、Prometheus+Grafana节点 KubeSphere节点 |
| master03 | 172.24.8.183 | Kubernetes master节点 | kubeadm、kubelet、kubectl、KeepAlived、containerd etcd、kube-apiserver、kube-scheduler、kube-controller-manager、calico dashboard、metrics、ingress、Longhorn ui节点、Prometheus+Grafana节点 KubeSphere节点 |
| worker01 | 172.24.8.184 | Kubernetes worker节点 | kubelet、containerd、calico、metrics、Longhorn driver节点 Prometheus+Grafana节点、KubeSphere节点 |
| worker02 | 172.24.8.185 | Kubernetes worker节点 | kubelet、containerd、calico、metrics、Longhorn driver节点 Prometheus+Grafana节点、KubeSphere节点 |
| worker03 | 172.24.8.186 | Kubernetes worker节点 | kubelet、containerd、calico、metrics、Longhorn driver节点 Prometheus+Grafana节点、KubeSphere节点 |
Kubernetes集群高可用主要指的是控制平面的高可用,多个Master节点组件(通常为奇数)和Etcd组件的高可用,worker节点通过前端负载均衡VIP( 172.24.8.180 )连接到Master。

Kubernetes高可用架构中etcd与Master节点组件混合部署方式特点:
- 所需服务器节点资源少,具备超融合架构特点
- 部署简单,利于管理
- 容易进行横向扩展
- etcd复用Kubernetes的高可用
- 存在一定风险,如一台master主机挂了,master和etcd都少了一个节点,集群冗余度受到一定影响
提示:本实验使用Keepalived+HAProxy架构实现Kubernetes的高可用。
主机名配置
需要对所有节点主机名进行相应配置。
shell
root@localhost:~# hostnamectl set-hostname master01 #其他节点依次修改提示:如上需要在所有节点修改对应的主机名。\
生产环境通常建议在内网部署dns服务器,使用dns服务器进行解析,本指南采用本地hosts文件名进行解析。
如下hosts文件修改仅需在master01执行,后续使用批量分发至其他所有节点。
shell
root@master01:~# cat >> /etc/hosts << EOF
172.24.8.181 master01
172.24.8.182 master02
172.24.8.183 master03
172.24.8.184 worker01
172.24.8.185 worker02
172.24.8.186 worker03
EOF提示:如上仅需在master01节点上操作。\
变量准备
为实现自动化部署,自动化分发相关文件,提前定义相关主机名、IP组、变量等。
shell
root@master01:~# wget http://down.linuxsb.com/mydeploy/k8s/v1.32.3/environment.sh
root@master01:~# vi environment.sh #确认相关主机名和IP
#!/bin/bash
#***************************************************************#
# ScriptName: environment.sh
# Author: xhy
# Create Date: 2025-02-22 01:44
# Modify Author: xhy
# Modify Date: 2025-02-22 01:44
# Version: v1
#***************************************************************#
# 集群 MASTER 机器 IP 数组
export MASTER_IPS=(172.24.8.181 172.24.8.182 172.24.8.183)
# 集群 MASTER IP 对应的主机名数组
export MASTER_NAMES=(master01 master02 master03)
# 集群 NODE 机器 IP 数组
export NODE_IPS=(172.24.8.184 172.24.8.185 172.24.8.186)
# 集群 NODE IP 对应的主机名数组
export NODE_NAMES=(worker01 worker02 worker03)
# 集群所有机器 IP 数组
export ALL_IPS=(172.24.8.181 172.24.8.182 172.24.8.183 172.24.8.184 172.24.8.185 172.24.8.186)
# 集群所有IP 对应的主机名数组
export ALL_NAMES=(master01 master02 master03 worker01 worker02 worker03)提示:如上仅需在master01节点上操作。\
互信配置
为了方便远程分发文件和执行命令,本方案配置master01节点到其它节点的 ssh信任关系,即免秘钥管理所有其他节点。
shell
root@master01:~# source environment.sh #载入变量
root@master01:~# ssh-keygen -f ~/.ssh/id_rsa -N ''
root@master01:~# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh-copy-id -i ~/.ssh/id_rsa.pub root@${all_ip}
done
root@master01:~# for all_name in ${ALL_NAMES[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_name}...\033[0m"
ssh-copy-id -i ~/.ssh/id_rsa.pub root@${all_name}
done提示:如上仅需在master01节点上操作。\
环境预配置
kubeadm本身仅用于部署Kubernetes集群,在正式使用kubeadm部署Kubernetes集群之前需要对操作系统环境进行准备,即环境预配置。
环境的预配置本方案使用脚本自动完成。
使用如下脚本对基础环境进行初始化,主要功能包括:
- 安装containerd,Kubernetes平台底层的容器组件
- 关闭SELinux及防火墙
- 优化相关内核参数,针对生产环境Kubernetes集群的基础系统调优配置
- 关闭swap
- 设置相关模块,主要为转发模块
- 配置相关基础软件,部署Kubernetes集群所需要的基础依赖包
- 创建container所使用的独立目录
- 配置crictl和运行时的连接,便于后期使用crictl命令
提示:后续ctr命令下载镜像的时候,若需要使用containerd的加速,必须带上--hosts-dir,ctr当前环境所管理的镜像都属于k8s.io,因此创建一个别名。
shell
root@master01:~# wget http://down.linuxsb.com/mydeploy/k8s/v1.32.3/uk8spreconfig.sh
root@master01:~# vim uk8spreconfig.sh
#!/bin/bash
#***************************************************************#
# ScriptName: uk8spreconfig.sh
# Author: xhy
# Create Date: 2025-03-29 12:30
# Modify Author: xhy
# Modify Date: 2025-03-29 21:06
# Version: v1
#***************************************************************#
# Initialize the machine. This needs to be executed on every machine.
apt update && apt upgrade -y && apt autoremove -y
# Install package
sudo apt -y install conntrack ntpdate ntp ipvsadm ipset jq iptables sysstat wget
# Add Docker's official GPG key
sudo apt -y install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
# Install and config containerd
apt-cache madison containerd
sudo apt -y install containerd.io
sleep 3s
mkdir -p /etc/containerd/certs.d/docker.io
mkdir -p /data/containerd
cat > /etc/containerd/config.toml <<EOF
disabled_plugins = ["io.containerd.internal.v1.restart"]
root = "/data/containerd"
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
# sandbox_image = "registry.k8s.io/pause:3.10"
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.10"
[plugins."io.containerd.grpc.v1.cri".containerd]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
[plugins."io.containerd.runtime.v1.linux"]
shim_debug = true
EOF
cat > /etc/containerd/certs.d/docker.io/hosts.toml <<EOF
server = "https://registry-1.docker.io"
[host."https://docker.1ms.run"]
capabilities = ["pull", "resolve", "push"]
[host."https://dbzucv6w.mirror.aliyuncs.com"]
capabilities = ["pull", "resolve", "push"]
[host."https://docker.xuanyuan.me"]
capabilities = ["pull", "resolve", "push"]
EOF
# config crictl & containerd
cat > /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
echo 'alias ctrpull="ctr -n k8s.io images pull --hosts-dir /etc/containerd/certs.d"' >> /etc/profile.d/custom_bash.sh
systemctl restart containerd
systemctl enable containerd --now
# Turn off and disable the firewalld.
systemctl disable ufw --now || true
# Modify related kernel parameters & Disable the swap.
cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.tcp_tw_recycle = 0
vm.swappiness = 0
vm.overcommit_memory = 1
vm.panic_on_oom = 0
net.ipv6.conf.all.disable_ipv6 = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf >&/dev/null
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
modprobe br_netfilter
modprobe overlay
sysctl --system
# Add ipvs modules
cat > /etc/modules-load.d/ipvs.conf <<EOF
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
br_netfilter
overlay
EOF
systemctl restart systemd-modules-load.service提示:containerd 镜像加速配置更多可参考:
containerd配置镜像加速器 containerd官方加速配置
提示:如上仅需在master01节点上操作,建议初始化完后进行重启。\
shell
root@master01:~# source environment.sh
root@master01:~# chmod +x *.sh
root@master01:~# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
sleep 2
scp -rp /etc/hosts root@${all_ip}:/etc/hosts
scp -rp uk8spreconfig.sh root@${all_ip}:/root/
ssh root@${all_ip} "bash /root/uk8spreconfig.sh"
done提示:如上仅需在master01节点上操作。\
部署高可用组件
HAProxy安装
HAProxy是可提供高可用性、负载均衡以及基于TCP(从而可以反向代理kubeapiserver等应用)和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种高可用解决方案。
shell
root@master01:~# HAVERSION=3.1.6
root@master01:~# LHAVERSION=$(echo ${HAVERSION} | cut -d. -f1,2)
root@master01:~# wget https://mirrors.huaweicloud.com/haproxy/${LHAVERSION}/src/haproxy-${HAVERSION}.tar.gz
root@master01:~# for master_ip in "${MASTER_IPS[@]}"
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
sleep 2
ssh root@${master_ip} "apt-get -y install binutils gcc make wget openssh-client libssl-dev libpcre2-dev zlib1g-dev"
scp -rp haproxy-${HAVERSION}.tar.gz root@${master_ip}:/root/
ssh root@${master_ip} "tar -zxvf haproxy-${HAVERSION}.tar.gz"
ssh root@${master_ip} "cd haproxy-${HAVERSION}/ && make USE_OPENSSL=1 TARGET=linux-glibc USE_PCRE2=1 USE_ZLIB=1 PREFIX=/usr/local/haprpxy && make install PREFIX=/usr/local/haproxy"
ssh root@${master_ip} "cp /usr/local/haproxy/sbin/haproxy /usr/sbin/"
ssh root@${master_ip} "useradd -r haproxy && usermod -G haproxy haproxy"
ssh root@${master_ip} "mkdir -p /etc/haproxy && mkdir -p /etc/haproxy/conf.d && cp -r /root/haproxy-${HAVERSION}/examples/errorfiles/ /usr/local/haproxy/"
done提示:如上仅需在master01节点上操作,,在ubuntu 24.04上需要明确指定 USE_PCRE2 ,使用 libssl-dev 和 libpcre2-dev 相关库文件。\
提示:Haproxy官方参考: https://docs.haproxy.org/ 。
KeepAlived安装
KeepAlived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题。
本方案3台master节点均部署并运行Keepalived,一台为主服务器(MASTER),另外两台为备份服务器(BACKUP)。
Master集群外表现为一个VIP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
shell
root@master01:~# KPVERSION=2.3.2
root@master01:~# LKPVERSION=$(echo ${HAVERSION} | cut -d. -f1,2)
root@master01:~# wget https://www.keepalived.org/software/keepalived-${KPVERSION}.tar.gz
root@master01:~# for master_ip in "${MASTER_IPS[@]}"
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
sleep 2
ssh root@${master_ip} "apt-get -y install curl gcc make libnl-3-dev libnl-genl-3-dev
"
scp -rp keepalived-${KPVERSION}.tar.gz root@${master_ip}:/root/
ssh root@${master_ip} "tar -zxvf keepalived-${KPVERSION}.tar.gz"
ssh root@${master_ip} "cd keepalived-${KPVERSION}/ && ./configure --sysconf=/etc --prefix=/usr/local/keepalived && make && make install"
ssh root@${master_ip} "cd keepalived-${KPVERSION}/ && cp -a keepalived/keepalived.service /usr/lib/systemd/system/"
ssh root@${master_ip} "systemctl daemon-reload && systemctl enable keepalived"
done提示:如上仅需在master01节点上操作。\
提示:KeepAlive官方参考: https://www.keepalived.org/manpage.html 。
创建配置文件
创建集群部署所需的相关组件配置,采用脚本自动化创建相关配置文件。
shell
root@master01:~# wget http://down.linuxsb.com/mydeploy/k8s/v1.32.3/uk8sconfig.sh #拉取自动部署脚本
root@master01:~# vim uk8sconfig.sh
#!/bin/bash
#***************************************************************#
# ScriptName: uk8sconfig.sh
# Author: xhy
# Create Date: 2025-03-29 13:01
# Modify Author: xhy
# Modify Date: 2025-03-29 21:32
# Version: v1
#***************************************************************#
#######################################
# 全局变量配置区
#######################################
echo -e "\n\033[33m[INFO] 开始定义全局参数...\033[0m"
sleep 1
declare -A NODES=(
[master01]="172.24.8.181"
[master02]="172.24.8.182"
[master03]="172.24.8.183"
)
# 公共参数
K8SHA_VERSION=v1.32.3
K8SHA_VIP="172.24.8.180"
K8SHA_PORT="6443"
K8SHA_AUTH="ilovek8s"
K8SHA_PODCIDR="10.10.0.0/16"
K8SHA_SVCCIDR="10.20.0.0/16"
K8SHA_DNSIP="10.20.0.10"
K8SHA_NETINF="eth0"
echo -e "\n\033[32m[SUCCESS] 全局参数定义已完成...\033[0m"
set -euo pipefail # 启用严格模式
#######################################
# 函数定义区
#######################################
# 创建目录结构
init_dirs() {
echo -e "\n\033[33m[INFO] 开始创建目录结构...\033[0m"
sleep 1
for node in "${!NODES[@]}"; do
mkdir -p k8sdir/${node}/{keepalived,haproxy}
done
mkdir -p k8sdir/{keepalived,haproxy,init}
echo -e "\n\033[32m[SUCCESS] 目录结构创建已完成...\033[0m"
}
# 下载基础配置文件
download_templates() {
echo -e "\n\033[33m[INFO] 开始下载模板文件...\033[0m"
sleep 1
# Keepalived模板
wget -qcP k8sdir/keepalived/ http://down.linuxsb.com/mydeploy/k8s/common/{uk8s-keepalived.conf.tpl,uk8s-check-apiserver.sh}
# HAProxy模板
wget -qcP k8sdir/haproxy/ http://down.linuxsb.com/mydeploy/k8s/common/{uk8s-haproxy.cfg.tpl,k8s-haproxy.service}
# k8s配置模板
wget -qcP k8sdir/init/ http://down.linuxsb.com/mydeploy/k8s/${K8SHA_VERSION}/ukubeadm-config.yaml.tpl
echo -e "\n\033[32m[SUCCESS] 模板文件下载已完成...\033[0m"
}
# 生成HAProxy配置
gen_haproxy_conf() {
echo -e "\n\033[33m[INFO] 生成 HAProxy 配置...\033[0m"
sleep 1
local backend_servers=""
for node_ip in "${NODES[@]}"; do
backend_servers+=" server ${node_ip} ${node_ip}:${K8SHA_PORT} check\n"
done
# 使用临时文件处理多行替换
local tmpfile=$(mktemp)
echo -e "$backend_servers" > "$tmpfile"
# 替换模板中的占位符
sed -e "/BACKSERVER/ {
r $tmpfile
d
}" "k8sdir/haproxy/uk8s-haproxy.cfg.tpl" > "k8sdir/haproxy/haproxy.cfg"
rm -f "$tmpfile"
echo -e "\n\033[32m[SUCCESS] HAProxy 配置已完成...\033[0m"
}
# 生成Keepalived配置
gen_keepalived_conf() {
echo -e "\n\033[33m[INFO] 开始生成 KeepAlived 配置...\033[0m"
sleep 1
local priority=120
for node in "${!NODES[@]}"; do
sed -e "
s/K8SHA_KA_STATE/BACKUP/g
s/K8SHA_KA_INTF/${K8SHA_NETINF}/g
s/K8SHA_IPLOCAL/${NODES[$node]}/g
s/K8SHA_KA_PRIO/$((priority++))/g
s/K8SHA_VIP/${K8SHA_VIP}/g
s/K8SHA_KA_AUTH/${K8SHA_AUTH}/g
" k8sdir/keepalived/uk8s-keepalived.conf.tpl > "k8sdir/${node}/keepalived/keepalived.conf"
cp k8sdir/keepalived/uk8s-check-apiserver.sh "k8sdir/${node}/keepalived/check_apiserver.sh"
done
echo -e "\n\033[32m[SUCCESS] KeepAlived 配置已完成...\033[0m"
}
# 生成k8s配置文件
gen_k8s_config() {
echo -e "\n\033[33m[INFO] 开始生成 K8S 配置...\033[0m"
sleep 1
# 生成动态 SAN 条目到临时文件
tmp_sans=$(mktemp)
{
# 添加所有节点名称和 IP
for node in "${!NODES[@]}"; do
echo " - $node"
echo " - ${NODES[$node]}"
done
} > "$tmp_sans" # 生成动态 SAN 条目到临时文件
for node in "${!NODES[@]}"; do
sed -e "
s|K8SHA_SVCCIDR|${K8SHA_SVCCIDR}|g
s|K8SHA_PODCIDR|${K8SHA_PODCIDR}|g
s|K8SHA_VERSION|${K8SHA_VERSION}|g
s|K8SHA_VIP|${K8SHA_VIP}|g
/#DYNAMIC_SANS#/ {
r $tmp_sans
d
}
" k8sdir/init/ukubeadm-config.yaml.tpl > "k8sdir/init/kubeadm-config.yaml"
done
rm -rf ${tmp_sans}
echo -e "\n\033[32m[SUCCESS] K8S 配置已完成...\033[0m"
}
# 分发配置文件
distribute_files() {
echo -e "\n\033[33m[INFO] 分发配置文件...\033[0m"
sleep 1
for node in "${!NODES[@]}"; do
echo "正在处理节点: $node"
# HAProxy配置
cp k8sdir/haproxy/haproxy.cfg k8sdir/${node}/haproxy/
scp -qp k8sdir/haproxy/haproxy.cfg root@$node:/etc/haproxy/haproxy.cfg
cp k8sdir/haproxy/k8s-haproxy.service k8sdir/${node}/haproxy/
scp -qp k8sdir/haproxy/k8s-haproxy.service root@$node:/usr/lib/systemd/system/haproxy.service
# Keepalived配置
scp -qp k8sdir/$node/keepalived/* root@$node:/etc/keepalived/
done
echo -e "\n\033[32m[SUCCESS] 配置分发已完成...\033[0m"
}
#######################################
# 主执行流程
#######################################
main() {
init_dirs
download_templates
gen_keepalived_conf
gen_k8s_config
gen_haproxy_conf
distribute_files
# 设置执行权限
chmod u+x *.sh
echo -e "\n\033[32m[SUCCESS] 所有配置已完成...\033[0m"
sleep 1
}
main "$@"root@master01:~# bash uk8sconfig.sh解释:如上操作仅需Master01上执行,执行uk8sconfig.sh脚本后会生产如下配置文件清单:
- kubeadm-config.yaml:kubeadm初始化配置文件,位于kubeadm/目录,可参考 kubeadm 配置
- keepalived:keepalived配置文件,位于各个master节点的/etc/keepalived目录
- haproxy:haproxy的配置文件,位于各个master节点的/etc/haproxy/目录
- calico.yaml:calico网络组件部署文件,位于kubeadm/calico/目录
启动服务
启动keepalive和HAProxy服务,从而构建master节点的高可用。
- 检查服务配置
确认所有Master节点相关keepalive配置文件和keepalive监测脚本文件。
shell
root@master01:~# source environment.sh
root@master01:~# for master_ip in ${MASTER_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
ssh root@${master_ip} "cat /etc/keepalived/keepalived.conf"
ssh root@${master_ip} "cat /etc/keepalived/check_apiserver.sh"
done- 启动高可用服务
shell
root@master01:~# source environment.sh
root@master01:~# for master_ip in ${MASTER_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
ssh root@${master_ip} "systemctl enable haproxy.service --now && systemctl restart haproxy.service"
ssh root@${master_ip} "systemctl enable keepalived.service --now && systemctl restart keepalived.service"
ssh root@${master_ip} "systemctl status keepalived.service | grep Active"
ssh root@${master_ip} "systemctl status haproxy.service | grep Active"
done
root@master01:~# for all_ip in ${ALL_IPS[@]}
do
sleep 2
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh root@${all_ip} "ping -c1 172.24.8.180"
done提示:如上仅需Master01节点操作,从而实现所有节点自动启动服务。
集群部署
相关组件包
需要在每台机器上都安装以下的软件包:
- kubeadm: 用来初始化集群的指令;
- kubelet: 在集群中的每个节点上用来启动 pod 和 container 等;
- kubectl: 用来与集群通信的命令行工具。
kubeadm不能安装或管理 kubelet 或 kubectl ,因此在初始化集群之前必须完成kubelet和kubectl的安装,且能保证他们满足通过 kubeadm 安装的 Kubernetes控制层对版本的要求。
如果版本没有满足匹配要求,可能导致一些意外错误或问题。
具体相关组件安装见;附001.kubectl介绍及使用书
提示:Kubernetes 1.32.2 版本所有兼容相应组件的版本参考:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.32.md 。
正式安装
快速安装所有节点的kubeadm、kubelet、kubectl组件。
shell
root@master01:~# for all_ip in ${ALL_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh root@${all_ip} "curl -fsSL https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg"
ssh root@${all_ip} "cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/deb/ /
EOF"
ssh root@${all_ip} "sudo apt update && \
sudo apt -y install kubelet=1.32.3-1.1 kubectl=1.32.3-1.1 kubeadm=1.32.3-1.1 --allow-downgrades"
ssh root@${all_ip} "systemctl enable kubelet"
done
root@master01:~# apt-cache madison kubelet #查看相应版本 提示:如上仅需Master01节点操作,从而实现所有节点自动化安装,同时此时不需要启动kubelet,初始化的过程中会自动启动的,如果此时启动了会出现报错,忽略即可。
说明:同时安装了cri-tools, kubernetes-cni依赖:
cri-tools:即CRI(Container Runtime Interface)容器运行时接口的命令行工具。
集群初始化
预配置检查
使用 uk8sconfig 创建配置的时候会创建主要如下配置文件,集群初始化之前建议再次检查和确认集群配置文件。
- kubeadm-config.yaml:kubeadm初始化配置文件,位于kubeadm/目录,设置了Kubernetes版本、Pod IP段、SVC IP段、nodeport端口范围等,可参考 kubeadm 配置
- keepalived:keepalived配置文件,位于各个master节点的/etc/keepalived目录
- haproxy:haproxy的配置文件,位于各个master节点的/etc/haproxy/目录
shell
root@master01:~# cat k8sdir/init/kubeadm-config.yaml #检查集群初始化配置
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
etcd:
local:
dataDir: "/data/etcd"
networking:
serviceSubnet: "10.20.0.0/16" #设置svc网段
podSubnet: "10.10.0.0/16" #设置Pod网段
dnsDomain: "cluster.local"
kubernetesVersion: "v1.32.3" #设置安装版本
controlPlaneEndpoint: "172.24.8.180:16443" #设置相关API VIP地址
imageRepository: registry.aliyuncs.com/google_containers #设置国内镜像站点
apiServer:
certSANs:
- localhost
- 127.0.0.1
- 172.24.8.180
- master03
- 172.24.8.183
- master02
- 172.24.8.182
- master01
- 172.24.8.181
extraArgs:
service-node-port-range: "80-65535"
default-not-ready-toleration-seconds: "180" #简单not-ready时间优化
default-unreachable-toleration-seconds: "180" #简单unreachable时间优化
controllerManager:
extraArgs:
node-monitor-period: "3s"
node-monitor-grace-period: "30s"
certificatesDir: "/etc/kubernetes/pki"
#clusterName: "example-cluster"
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
mageGCHighThresholdPercent: 95
imageGCLowThresholdPercent: 90
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvsKubernetes默认的端口范围为30000-32767,为便于后期大量的应用,建议做端口扩展,如ingress的80、443端口,然后开放80-65535端口号。
同时开放更多端口范围后,使用的时候需要注意外部应用端口和Kubernetes使用的nodeport端口冲突的情况。
提示:更多config文件参考:kubeadm 配置 (v1beta4)
默认kubeadm配置可使用kubeadm config print init-defaults > config.yaml生成。
Master01上初始化
Master01节点上执行初始化,即完成单节点的Kubernetes,其他节点采用添加的方式部署。
提示:kubeadm init过程会执行系统预检查,预检查通过则继续init,也可以提前执行如下命令进行预检查操作: kubeadm init phase preflight
shell
root@master01:~# kubeadm init --config=k8sdir/init/kubeadm-config.yaml --upload-certs #保留如下命令用于后续节点添加
[init] Using Kubernetes version: v1.32.3
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
......
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes running the following command on each as root:
kubeadm join 172.24.8.180:16443 --token da9vsn.ygkqe0bvvdmdea5s \
--discovery-token-ca-cert-hash sha256:8b67aa30b925fbc8ed3105ec416eb27da87bc06e6bd0cc7814ec83a3e25915a8 \
--control-plane --certificate-key 7003c90eb58c6cf22f954b0727dc1b5f016f2c7dd824877f47e7de4b9a21ca50
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.24.8.180:16443 --token da9vsn.ygkqe0bvvdmdea5s \
--discovery-token-ca-cert-hash sha256:8b67aa30b925fbc8ed3105ec416eb27da87bc06e6bd0cc7814ec83a3e25915a8注意:如上token具有默认24小时的有效期,token和hash值可通过如下方式获取:
kubeadm token list
如果 Token 过期以后,可以输入以下命令,生成新的 Token:
shell
kubeadm token create
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'附加:初始化过程大致步骤如下:
- certs:生成相关的各种证书
- control-plane:创建Kubernetes控制节点的静态Pod
- etcd:创建ETCD的静态Pod
- kubelet-start:生成kubelet的配置文件"/var/lib/kubelet/config.yaml"
- kubeconfig:生成相关的kubeconfig文件
- bootstraptoken:生成token记录下来,后续使用kubeadm join往集群中添加节点时会用到
- addons:附带的相关插件
提示:初始化仅需要在master01上执行,若初始化异常可通过kubeadm reset -f k8sdir/init/kubeadm-config.yaml && rm -rf $HOME/.kube /etc/cni/ /etc/kubernetes/ && ipvsadm --clear重置。
添加Master节点
采用 kubeadm join 将其他Master节点添加至集群。
shell
root@master01:~# JOINS_IP=(172.24.8.182 172.24.8.183)
root@master01:~# for join_ip in "${JOINS_IP[@]}"; do
echo -e "\n\033[33m[INFO] Joining ${join_ip}...\033[0m"
ssh root@${join_ip} "kubeadm join 172.24.8.180:16443 --token da9vsn.ygkqe0bvvdmdea5s \
--discovery-token-ca-cert-hash sha256:8b67aa30b925fbc8ed3105ec416eb27da87bc06e6bd0cc7814ec83a3e25915a8 \
--control-plane --certificate-key 7003c90eb58c6cf22f954b0727dc1b5f016f2c7dd824877f47e7de4b9a21ca50"
done提示:如上仅需Master01节点操作,通过循环将master02和master03添加至当前集群的controlplane。
添加kubectl环境
给所有master节点创建相关Kubernetes集群配置文件保存目录,以及相关登录凭证,kubectl命令补全等。
shell
root@master01:~# source environment.sh
root@master01:~# for master_ip in "${MASTER_IPS[@]}"; do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
ssh -T root@${master_ip} << 'EOF'
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
cat << EOB > /etc/profile.d/custom_kubectl.sh
export KUBECONFIG=\$HOME/.kube/config
source <(kubectl completion bash)
EOB
chmod 644 /etc/profile.d/custom_kubectl.sh
EOF
done
root@master01:~# source /etc/profile安装NIC插件
NIC插件介绍
- Calico 是一个安全的 L3 网络和网络策略提供者。
- Canal 结合 Flannel 和 Calico, 提供网络和网络策略。
- Cilium 是一个 L3 网络和网络策略插件, 能够透明的实施 HTTP/API/L7 策略。 同时支持路由(routing)和叠加/封装( overlay/encapsulation)模式。
- Contiv 为多种用例提供可配置网络(使用 BGP 的原生 L3,使用 vxlan 的 overlay,经典 L2 和 Cisco-SDN/ACI)和丰富的策略框架。Contiv 项目完全开源。安装工具同时提供基于和不基于 kubeadm 的安装选项。
- Flannel 是一个可以用于 Kubernetes 的 overlay 网络提供者。
- Romana 是一个 pod 网络的层 3 解决方案,并且支持 NetworkPolicy API。Kubeadm add-on 安装细节可以在这里找到。
- Weave Net 提供了在网络分组两端参与工作的网络和网络策略,并且不需要额外的数据库。
- CNI-Genie 使 Kubernetes 无缝连接到一种 CNI 插件,例如:Flannel、Calico、Canal、Romana 或者 Weave。
提示:本方案使用Calico插件。
部署calico
确认相关配置,如MTU,网卡接口,Pod的IP地址段。
calico支持operator和manifests方式部署,本方案operator部署,对于manifests也也可参考:https://raw.githubusercontent.com/projectcalico/calico/v3.29.3/manifests/calico.yaml
| 维度 | Operator 模式 | Manifest 模式 |
|---|---|---|
| 管理方式 | 通过 Kubernetes Operator 动态管理 Calico 生命周期 | 通过静态 YAML 文件直接部署资源 |
| 适用场景 | 生产环境、需要自动化运维和高级功能(如自动升级、配置热更新) | 快速部署、测试环境、需要完全手动控制配置的场合 |
| 复杂度 | 较高(需理解 CRD 和 Operator 逻辑) | 较低(直接应用 YAML) |
| 灵活性 | 高(通过 CRD 动态调整配置) | 中(需手动修改 YAML 并重新部署) |
| 升级维护 | 自动化升级(Operator 负责版本迁移) | 手动升级(需下载新版本 Manifest 并重新应用) |
| 监控与自愈 | 内置健康检查和故障恢复机制 | 依赖 Kubernetes 原生机制(如 livenessProbe) |
Operator相对Manifest有如下优势:
- 自动证书轮换
- 配置热更新
- 多版本兼容管理
- 细粒度组件监控指标
- 一键式集群扩展
shell
root@master01:~# kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.29.3/manifests/tigera-operator.yaml
root@master01:~# wget https://raw.githubusercontent.com/projectcalico/calico/v3.29.3/manifests/custom-resources.yaml
root@master01:~# vim custom-resources.yaml
#......
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
mtu: 1450 #根据实际情况配置mtu
nodeAddressAutodetectionV4:
interface: "eth0" #建议指定网卡
ipPools:
- name: default-ipv4-ippool
blockSize: 26
cidr: 10.10.0.0/16 #配置网段,kubeadm匹配
root@master01:~# kubectl create -f custom-resources.yaml提示:其他配置建议保持默认,MTU建议为网卡当前MTU减去50。\
shell
root@master01:~# kubectl get pods --all-namespaces -o wide #查看部署的所有Pod
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-apiserver calico-apiserver-68db9dc44f-28h9g 1/1 Running 0 31m 10.10.235.4 master03 <none> <none>
calico-apiserver calico-apiserver-68db9dc44f-knmlb 1/1 Running 0 34m 10.10.59.200 master02 <none> <none>
calico-system calico-kube-controllers-6948974b95-x5v7c 1/1 Running 0 33m 10.10.59.204 master02 <none> <none>
calico-system calico-node-2bwxb 1/1 Running 0 33m 172.24.8.181 master01 <none> <none>
calico-system calico-node-6rt9p 1/1 Running 0 33m 172.24.8.183 master03 <none> <none>
calico-system calico-node-8n8nk 1/1 Running 0 33m 172.24.8.182 master02 <none> <none>
calico-system calico-typha-798b656c89-5pdqb 1/1 Running 0 33m 172.24.8.183 master03 <none> <none>
calico-system calico-typha-798b656c89-vcwc9 1/1 Running 0 33m 172.24.8.182 master02 <none> <none>
calico-system csi-node-driver-7lgf5 2/2 Running 0 34m 10.10.59.203 master02 <none> <none>
calico-system csi-node-driver-c4kzv 2/2 Running 0 14m 10.10.241.65 master01 <none> <none>
calico-system csi-node-driver-l7xht 2/2 Running 0 34m 10.10.235.3 master03 <none> <none>
kube-system coredns-6766b7b6bb-7znzk 1/1 Running 0 73m 10.10.59.201 master02 <none> <none>
kube-system coredns-6766b7b6bb-h2q9x 1/1 Running 0 73m 10.10.59.202 master02 <none> <none>
kube-system etcd-master01 1/1 Running 0 73m 172.24.8.181 master01 <none> <none>
kube-system etcd-master02 1/1 Running 0 70m 172.24.8.182 master02 <none> <none>
kube-system etcd-master03 1/1 Running 0 70m 172.24.8.183 master03 <none> <none>
kube-system kube-apiserver-master01 1/1 Running 0 73m 172.24.8.181 master01 <none> <none>
kube-system kube-apiserver-master02 1/1 Running 0 70m 172.24.8.182 master02 <none> <none>
kube-system kube-apiserver-master03 1/1 Running 0 70m 172.24.8.183 master03 <none> <none>
kube-system kube-controller-manager-master01 1/1 Running 0 73m 172.24.8.181 master01 <none> <none>
kube-system kube-controller-manager-master02 1/1 Running 0 70m 172.24.8.182 master02 <none> <none>
kube-system kube-controller-manager-master03 1/1 Running 0 70m 172.24.8.183 master03 <none> <none>
kube-system kube-proxy-cj5h9 1/1 Running 0 70m 172.24.8.182 master02 <none> <none>
kube-system kube-proxy-dvqx7 1/1 Running 0 73m 172.24.8.181 master01 <none> <none>
kube-system kube-proxy-xz4s2 1/1 Running 0 70m 172.24.8.183 master03 <none> <none>
kube-system kube-scheduler-master01 1/1 Running 0 73m 172.24.8.181 master01 <none> <none>
kube-system kube-scheduler-master02 1/1 Running 0 70m 172.24.8.182 master02 <none> <none>
kube-system kube-scheduler-master03 1/1 Running 0 70m 172.24.8.183 master03 <none> <none>
tigera-operator tigera-operator-789496d6f5-hmrbz 1/1 Running 0 35m 172.24.8.182 master02 <none> <none>
root@master01:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane 75m v1.32.3
master02 Ready control-plane 72m v1.32.3
master03 Ready control-plane 72m v1.32.3提示:官方calico参考:https://docs.projectcalico.org/manifests/calico.yaml
添加Worker节点
添加Worker节点
shell
root@master01:~# source environment.sh
root@master01:~# for node_ip in ${NODE_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${node_ip}...\033[0m"
ssh root@${node_ip} "kubeadm join 172.24.8.180:16443 --token da9vsn.ygkqe0bvvdmdea5s \
--discovery-token-ca-cert-hash sha256:8b67aa30b925fbc8ed3105ec416eb27da87bc06e6bd0cc7814ec83a3e25915a8"
ssh root@${node_ip} "systemctl enable kubelet.service"
done提示:如上仅需Master01节点操作,从而实现所有Worker节点添加至集群,若添加异常可通过如下方式重置:
shell
root@worker01:~# kubeadm reset
root@worker01:~# ifconfig kube-ipvs0 down
root@worker01:~# ip link delete kube-ipvs0
root@worker01:~# ifconfig tunl0@NONE down
root@worker01:~# ip link delete tunl0@NONE
root@worker01:~# rm -rf /var/lib/cni/确认验证
shell
rroot@master01:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane 79m v1.32.3
master02 Ready control-plane 77m v1.32.3
master03 Ready control-plane 76m v1.32.3
worker01 Ready <none> 3m52s v1.32.3
worker02 Ready <none> 3m49s v1.32.3
worker03 Ready <none> 3m46s v1.32.3
root@master01:~# kubectl get serviceaccount
NAME SECRETS AGE
default 0 79m
root@master01:~# kubectl cluster-info
Kubernetes control plane is running at https://172.24.8.180:16443
CoreDNS is running at https://172.24.8.180:16443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
root@master01:~# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-6766b7b6bb-7znzk 1/1 Running 0 79m 10.10.59.201 master02 <none> <none>
coredns-6766b7b6bb-h2q9x 1/1 Running 0 79m 10.10.59.202 master02 <none> <none>
etcd-master01 1/1 Running 0 79m 172.24.8.181 master01 <none> <none>
etcd-master02 1/1 Running 0 77m 172.24.8.182 master02 <none> <none>
etcd-master03 1/1 Running 0 76m 172.24.8.183 master03 <none> <none>
kube-apiserver-master01 1/1 Running 0 79m 172.24.8.181 master01 <none> <none>
kube-apiserver-master02 1/1 Running 0 77m 172.24.8.182 master02 <none> <none>
kube-apiserver-master03 1/1 Running 0 76m 172.24.8.183 master03 <none> <none>
kube-controller-manager-master01 1/1 Running 0 79m 172.24.8.181 master01 <none> <none>
kube-controller-manager-master02 1/1 Running 0 77m 172.24.8.182 master02 <none> <none>
kube-controller-manager-master03 1/1 Running 0 76m 172.24.8.183 master03 <none> <none>
kube-proxy-74hhh 1/1 Running 0 4m13s 172.24.8.184 worker01 <none> <none>
kube-proxy-cj5h9 1/1 Running 0 77m 172.24.8.182 master02 <none> <none>
kube-proxy-dvqx7 1/1 Running 0 79m 172.24.8.181 master01 <none> <none>
kube-proxy-kpxj5 1/1 Running 0 4m7s 172.24.8.186 worker03 <none> <none>
kube-proxy-mb9qg 1/1 Running 0 4m10s 172.24.8.185 worker02 <none> <none>
kube-proxy-xz4s2 1/1 Running 0 76m 172.24.8.183 master03 <none> <none>
kube-scheduler-master01 1/1 Running 0 79m 172.24.8.181 master01 <none> <none>
kube-scheduler-master02 1/1 Running 0 77m 172.24.8.182 master02 <none> <none>
kube-scheduler-master03 1/1 Running 0 76m 172.24.8.183 master03 <none> <none>提示:更多Kubetcl使用参考:https://kubernetes.io/docs/reference/kubectl/kubectl/
https://kubernetes.io/docs/reference/kubectl/overview/
更多kubeadm使用参考:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
Helm部署
helm介绍
Helm 是 Kubernetes 的软件包管理工具。包管理器类似 Ubuntu 中使用的apt、Centos中使用的yum 或者Python中的 pip 一样,能快速查找、下载和安装软件包。通常每个包称为一个Chart,一个Chart是一个目录(一般情况下会将目录进行打包压缩,形成name-version.tgz格式的单一文件,方便传输和存储)。
Helm 由客户端组件 helm 和服务端组件 Tiller 组成, 能够将一组K8S资源打包统一管理, 是查找、共享和使用为Kubernetes构建的软件的最佳方式。
Helm优势
在 Kubernetes中部署一个可以使用的应用,需要涉及到很多的 Kubernetes 资源的共同协作。
如安装一个 WordPress 博客,用到了一些 Kubernetes 的一些资源对象。包括 Deployment 用于部署应用、Service 提供服务发现、Secret 配置 WordPress 的用户名和密码,可能还需要 pv 和 pvc 来提供持久化服务。并且 WordPress 数据是存储在mariadb里面的,所以需要 mariadb 启动就绪后才能启动 WordPress。这些 k8s 资源过于分散,不方便进行管理。
基于如上场景,在 k8s 中部署一个应用,通常面临以下几个问题:
如何统一管理、配置和更新这些分散的 k8s 的应用资源文件;
如何分发和复用一套应用模板;
如何将应用的一系列资源当做一个软件包管理。
对于应用发布者而言,可以通过 Helm 打包应用、管理应用依赖关系、管理应用版本并发布应用到软件仓库。
对于使用者而言,使用 Helm 后不用需要编写复杂的应用部署文件,可以以简单的方式在 Kubernetes 上查找、安装、升级、回滚、卸载应用程序。
前置准备
Helm 将使用 kubectl 在已配置的集群上部署 Kubernetes 资源,因此需要如下前置准备:
- 正在运行的 Kubernetes 集群;
- 预配置的 kubectl 客户端和 Kubernetes 集群正确交互。
二进制安装Helm
建议采用二进制安装helm。
shell
root@master01:~# source environment.sh
root@master01:~# mkdir helm
root@master01:~# cd helm/
root@master01 helm# HELMVERSION=v3.17.2
root@master01 helm# wget https://repo.huaweicloud.com/helm/${HELMVERSION}/helm-${HELMVERSION}-linux-amd64.tar.gz
root@master01 helm# tar -zxvf helm-${HELMVERSION}-linux-amd64.tar.gz
root@master01:~# for master_ip in "${MASTER_IPS[@]}"
do
echo -e "\n\n\033[33m[INFO] >>> ${master_ip}...\033[0m"
sleep 1
scp -rp linux-amd64/helm root@${master_ip}:/usr/local/bin/
ssh root@${master_ip} "echo 'source <(helm completion bash)' >> /etc/profile.d/custom_helm.sh"
done
root@master01 helm# source /etc/profile
root@master01 helm# helm version #查看安装版本提示:更多安装方式参考官方手册:https://helm.sh/docs/intro/install/ 。
Helm操作
查找chart
helm search:可以用于搜索两种不同类型的源。
helm search hub:搜索 Helm Hub,该源包含来自许多不同仓库的Helm chart。
helm search repo:搜索已添加到本地头helm客户端(带有helm repo add)的仓库,该搜索是通过本地数据完成的,不需要连接公网。
shell
root@master01:~# helm search hub #可搜索全部可用chart
root@master01:~# helm search hub wordpress添加repo
类似CentOS添加yum源,可以给helm仓库添加相关源。
shell
root@master01:~# helm repo list #查看repo
root@master01:~# helm repo add azure https://mirror.azure.cn/kubernetes/charts
root@master01:~# helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
root@master01:~# helm repo add bitnami https://charts.bitnami.com/bitnami
root@master01:~# helm search repo azure
root@master01:~# helm search repo aliyun
root@master01:~# helm search repo bitnami #搜索repo中的chart
root@master01:~# helm repo update #更新repo的chart提示:bitnami chart更多信息参考:Kubernetes Bitnami chart
提示:更多helm知识可参考: Kubernetes集群管理-Helm部署及使用 。
Metrics部署
Metrics介绍
在Kubernetes新的监控体系中,Metrics Server用于提供核心指标(Core Metrics),包括Node、Pod的CPU和内存使用指标,对其他自定义指标(Custom Metrics)的监控则由Prometheus等组件来完成。
Metrics Server是一个可扩展的、高效的容器资源度量,通常可用于Kubernetes内置的自动伸缩,即自动伸缩可依据metrics的度量指标。
Metrics Server从Kubelets收集资源指标,并通过Metrics API将它们暴露在Kubernetes apisserver中,供Pod水平或垂直自动伸缩使用。
kubectl top也可以访问Metrics API,可查看相关对象资源使用情况。
提示:当前官方建议Metrics Server仅用于自动伸缩,不要使用它来当做对Kubernetes的监控解决方案,或者监控解决方案的上游来源,对于完整的Kubernetes监控方案,可直接从Kubelet的/metrics/resource endpoint收集指标。
Metrics Server建议场景
- 使用Metrics Server的场景:
- 基于CPU/内存的水平快速自动缩放;
- 自动调整/建议容器所需的资源。
Metrics Server不建议场景
不建议使用Metrics Server的场景:
- 非Kubernetes集群;
- 集群资源对象资源消耗的准确依据;
- 基于CPU/内存以外的其他资源的水平自动缩放。
对于整个集群的准备监控,可参考 Prometheus 。
Metrics特点
Metrics Server主要特点:
- 在大多数集群上可以以单Pod工作;
- 快速自动伸缩,且每15秒收集一次指标;
- 资源消耗极低,在集群中每个节点上仅需1分片CPU和2 MB内存;
- 可扩展支持最多5000个节点集群。
Metrics需求
Metrics Server对集群和网络配置有特定的需求依赖,这些需求依赖并不是所有集群默认开启的。
在使用Metrics Server之前,需要确保集群支持这些需求:
- kube-apiserver必须启用聚合层(aggregation layer);
- 节点必须启用Webhook身份验证和授权;
- Kubelet证书需要由集群证书颁发机构签名(或者通过向Metrics Server传递--kubelet-insecure-tls禁用证书验证);
- 容器运行时必须实现容器度量rpc(或有cAdvisor支持);
- 网络应支持以下通信:
- 控制平面到Metrics Server通信要求:控制平面节点需要到达Metrics Server的pod IP和端口10250(如果hostNetwork开启,则可以是自定义的node IP和对应的自定义端口,保持通信即可);
- Metrics Server到所有节点的Kubelete通信要求:Metrics Server需要到达node节点地址和Kubelet端口。地址和端口在Kubelet中配置,并作为Node对象的一部分发布。.status.address和.status.daemonEndpoints.kubeletEndpoint.port定义地址和端口(默认10250)。Metrics Server将根据kubelet-preferred-address-types命令行标志提供的列表选择第一个节点地址(默认InternalIP,ExternalIP,Hostname)。
开启聚合层
有关聚合层知识参考:https://blog.csdn.net/liukuan73/article/details/81352637
kubeadm方式部署默认已开启。
获取部署文件
根据实际生产环境,对Metrics Server的部署进行个性化修改,其他保持默认即可。
主要涉及:部署副本数为3,追加--kubelet-insecure-tls配置。
本文使用helm部署metrics,manifest方式可参考:Kubernetes集群管理-集群监控Metrics 。
bash
root@master01:~# mkdir metrics
root@master01:~# cd metrics/
root@master01:~/metrics# helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
root@master01:~/metrics# helm repo list | grep metrics-server
metrics-server https://kubernetes-sigs.github.io/metrics-server/
root@master01:~/metrics# helm search repo metrics-server
NAME CHART VERSION APP VERSION DESCRIPTION
azure/metrics-server 2.11.4 0.3.6 DEPRECATED - Metrics Server is a cluster-wide a...
bitnami/metrics-server 7.4.1 0.7.2 Metrics Server aggregates resource usage data, ...
metrics-server/metrics-server 3.12.2 0.7.2 Metrics Server is a scalable, efficient source ...创建自定义配置
shell
root@master01:~/metrics# helm show values metrics-server/metrics-server > defaults-values.yaml #查看默认配置
root@master01:~/metrics# vim myvalues.yaml
image:
repository: registry.aliyuncs.com/google_containers/metrics-server #修改为阿里云镜像
containerPort: 10300 #修改端口
hostNetwork:
enabled: true #追加此行
replicas: 3 #根据集群规模调整副本数
args:
- --secure-port=10300
- --kubelet-insecure-tls #自签名证书场景必须追加此行提示:当开启hostNetwork的时候,metrics-server d是会使用宿主机网络栈,该pod默认的10250会和kubelet默认端口10250冲突,因此建议修改端口。
kubelet各端口作用可参考: Kubelet 各个端口作用 10250
正式部署
shell
root@master01:~/metrics# helm upgrade --install metrics-server metrics-server/metrics-server -f myvalues.yaml
root@master01:~/metrics# kubectl -n kube-system get pods -l app.kubernetes.io/name=metrics-server -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
metrics-server-b46fcc76f-st5qk 1/1 Running 0 2m10s 172.24.8.185 worker02 <none> <none>
metrics-server-b46fcc76f-t46lg 1/1 Running 0 2m10s 172.24.8.186 worker03 <none> <none>
metrics-server-b46fcc76f-v2v6f 1/1 Running 0 2m10s 172.24.8.184 worker01 <none> <none>查看资源监控
可使用kubectl top查看相关监控项。
shell
root@master01:~# kubectl top nodes
root@master01:~# kubectl top pods --all-namespaces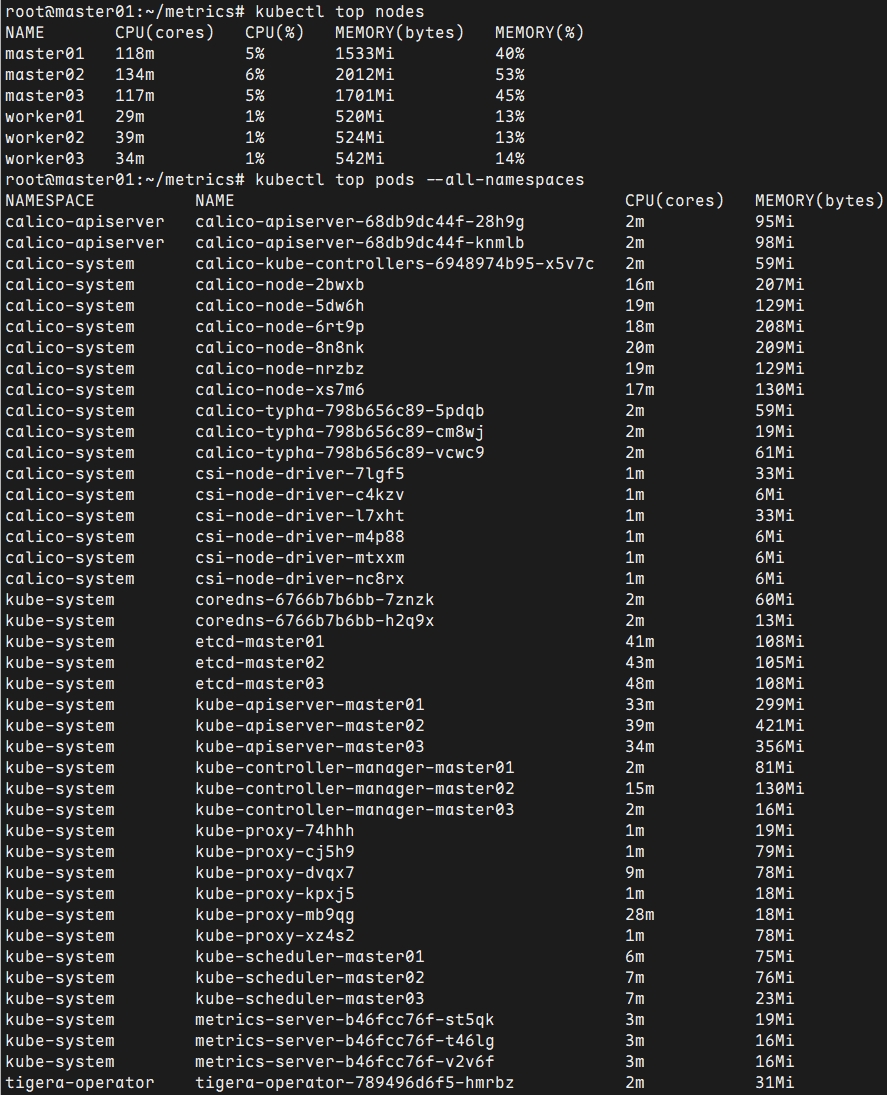
提示:Metrics Server提供的数据也可以供HPA控制器使用,以实现基于CPU使用率或内存使用值的Pod自动扩缩容功能。
有关metrics更多部署参考:
https://kubernetes.io/docs/tasks/debug-application-cluster/resource-metrics-pipeline/
开启开启API Aggregation参考:
https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/apiserver-aggregation/
API Aggregation介绍参考:
https://kubernetes.io/docs/tasks/access-kubernetes-api/configure-aggregation-layer/
Nginx ingress部署
ingress介绍
Kubernetes中的应用通常以Service对外暴露,而Service的表现形式为IP:Port,即工作在TCP/IP层。
对于基于HTTP的服务来说,不同的URL地址经常对应到不同的后端服务(RS)或者虚拟服务器(Virtual Host),这些应用层的转发机制仅通过Kubernetes的Service机制是无法实现的。
从Kubernetes 1.1版本开始新增Ingress资源对象,用于将不同URL的访问请求转发到后端不同的Service,以实现HTTP层的业务路由机制。
Kubernetes使用了一个Ingress策略规则和一个具体的Ingress Controller,两者结合实现了一个完整的Ingress负载均衡器。
使用Ingress进行负载分发时,Ingress Controller基于Ingress策略规则将客户端请求直接转发到Service对应的后端Endpoint(Pod)上,从而跳过kube-proxy的转发功能,kube-proxy不再起作用。
简单的理解就是:ingress使用DaemonSet或Deployment在相应Node上监听80或443,然后配合相应规则,因为Nginx外面绑定了宿主机80端口(就像 NodePort),本身又在集群内,那么向后直接转发到相应ServiceIP即可实现相应需求。
ingress controller + ingress 策略规则 ----> services。
同时当Ingress Controller提供的是对外服务,则实际上实现的是边缘路由器的功能。
典型的HTTP层路由的架构:

设置标签
建议对于非业务相关的应用,构建集群所需的应用(如Ingress),部署在master节点,从而复用master节点的高可用。
采用标签,结合部署的yaml中的tolerations,实现ingress部署在master节点的配置。
shell
root@master01:~# kubectl label nodes master0{1,2,3} ingress=enable获取部署文件
获取部署所需的yaml资源。
shell
root@master01:~# mkdir ingress
root@master01:~# cd ingress/
root@master01:~/ingress# helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx/
root@master01:~/ingress# helm repo list | grep ingress-nginx
ingress-nginx https://kubernetes.github.io/ingress-nginx/
root@master01:~/ingress# helm search repo ingress-nginx
NAME CHART VERSION APP VERSION DESCRIPTION
ingress-nginx/ingress-nginx 4.12.1 1.12.1 Ingress controller for Kubernetes using NGINX a...
root@master01:~/ingress# helm show values ingress-nginx --repo https://kubernetes.github.io/ingress-nginx > defaults-values.yaml #查看默认配置提示:ingress官方参考:https://github.com/kubernetes/ingress-nginx
https://kubernetes.github.io/ingress-nginx/deploy/
创建自定义配置
为方便后续管理和排障,对相关Nginx ingress挂载时区,以便使Pod时间正确,从而相关记录日志能具有时效性。
同时对ingress做了简单配置,如日志格式,副本数等。
自定义配置可参考默认helm values进行修改。
shell
root@master01:~/ingress# vim myvalues.yaml
global:
image:
registry: registry.cn-hangzhou.aliyuncs.com
controller:
image:
image: google_containers/nginx-ingress-controller
digest: ""
config:
allow-snippet-annotations: "true"
client-header-buffer-size: "512k"
large-client-header-buffers: "4 512k"
client-body-buffer-size: "128k"
proxy-buffer-size: "256k"
proxy-body-size: "50m"
server-name-hash-bucket-size: "128"
map-hash-bucket-size: "128"
## SSL 配置
ssl-ciphers: "ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA"
ssl-protocols: "TLSv1 TLSv1.1 TLSv1.2"
## 日志格式
log-format-upstream: '{"time": "$time_iso8601", "remote_addr": "$proxy_protocol_addr", "x-forward-for": "$proxy_add_x_forwarded_for", "request_id": "$req_id","remote_user": "$remote_user", "bytes_sent": $bytes_sent, "request_time": $request_time, "status": $status, "vhost": "$host", "request_proto": "$server_protocol", "path": "$uri", "request_query": "$args", "request_length": $request_length, "duration": $request_time,"method": "$request_method", "http_referrer": "$http_referer", "http_user_agent": "$http_user_agent" }'
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
nodeSelector:
kubernetes.io/os: linux
ingress: enable
service:
type: NodePort
externalTrafficPolicy: "Local"
nodePorts:
http: "80"
https: "443"
extraVolumeMounts:
- name: timeconfig
mountPath: /etc/localtime
readOnly: true
extraVolumes:
- name: timeconfig
hostPath:
path: /etc/localtime
type: File
admissionWebhooks:
patch:
image:
image: google_containers/kube-webhook-certgen
digest: ""
replicaCount: 3提示:添加默认backend需要等待default-backend创建完成controllers才能成功部署,新版本ingress不再推荐添加default backend。
正式部署
通常对于国外的包有可能直接安装会失败,可提前wget或者pull至本地,然后进行安装。
bash
root@master01:~/ingress# helm pull ingress-nginx/ingress-nginx
root@master01:~/ingress# ll
total 112K
-rw-r--r-- 1 root root 48K Mar 30 20:03 defaults-values.yaml
-rw-r--r-- 1 root root 57K Mar 30 22:48 ingress-nginx-4.12.1.tgz
-rw-r--r-- 1 root root 2.4K Mar 30 22:37 myvalues.yaml
root@master01:~/ingress# helm upgrade --install ingress-nginx ./ingress-nginx-4.12.1.tgz --namespace ingress-nginx --create-namespace -f myvalues.yaml提示:如上本地安装命令等效于:
shell
root@master01:~/ingress# helm upgrade --install ingress-nginx ingress-nginx/ingress-nginx --namespace ingress-nginx --create-namespace -f myvalues.yaml确认验证
查看Pod部署进度,是否成功完成。
shell
root@master01 ingress# kubectl get pods -n ingress-nginx -o wide
root@master01 ingress# kubectl get svc -n ingress-nginx -o wide
提示:参考文档: https://github.com/kubernetes/ingress-nginx/blob/master/docs/deploy/index.md 。
提示:其他更多ingress学习知识可参考此博客: Ingress-Nginx使用指南上篇 。
Dashboard部署
dashboard介绍
dashboard是基于Web的Kubernetes用户界面,即WebUI。
可以使用dashboard将容器化应用程序部署到Kubernetes集群,对容器化应用程序进行故障排除,以及管理集群资源。
可以使用dashboard来查看群集上运行的应用程序,以及创建或修改单个Kubernetes资源(例如部署、任务、守护进程等)。
可以使用部署向导扩展部署,启动滚动更新,重新启动Pod或部署新应用程序。
dashboard还提供有关群集中Kubernetes资源状态以及可能发生的任何错误的信息。
通常生产环境中建议部署dashboard,以便于图形化来完成基础运维。
从7.0.0版本开始,社区已放弃了对基于manifest安装的支持,现在只支持基于helm的安装。 由于多容器设置和对Kong网关API代理的严重依赖,原有基于yaml清单安装的方式已不可行。
同时基于helm的安装,部署速度更快,并且可以更好地控制Dashboard运行所需的所有依赖项。并且已经改变了版本控制方案,并从Helm chart中删除了appVersion。
因为,使用多容器设置,每个模块现在都是单独的版本,Helm chart版本现在可以被视为应用版本。
设置标签
基于最佳实践,非业务应用,或集群自身的应用都部署在Master节点。
shell
root@master01:~# kubectl label nodes master0{1,2,3} dashboard=enable提示:建议对于Kubernetes自身相关的应用(如dashboard),此类非业务应用部署在master节点。
创建证书
默认dashboard会自动创建证书,同时使用对应证书创建secret。生产环境可以启用相应的域名进行部署dashboard,因此需要为对应的域名制作TLS证书。
证书可通过如下任意一种方式获取。
- 方式一:脚本快速自签名
基于实验目的,采用自签名证书。
shell
root@master01:~# mkdir -p /root/dashboard/certs
root@master01:~# cd /root/dashboard/
root@master01:~/dashboard# vim signcert.sh
#!/bin/sh
#***************************************************************#
# ScriptName: signcert.sh
# Author: xhy
# Create Date: 2025-02-25 21:49
# Modify Author: xhy
# Modify Date: 2025-03-31 00:00
# Version: v1
#***************************************************************#
# 配置参数
#PARENT_DOMAIN="linuxsb.com" # 父级域名
#SUB_DOMAINS=("minio" "rminio" "kas") # 子域名列表,可选配置
PARENT_DOMAIN="linuxsb.com"
SUB_DOMAINS=("web")
#...... #其他保持默认
root@master01:~/dashboard# bash signcert.sh
root@master01:~/dashboard# mv certs/linuxsb.com.crt certs/tls.crt
root@master01:~/dashboard# mv certs/linuxsb.com.key certs/tls.key
root@master01:~/dashboard# ll certs/tls.*
-rw-r--r-- 1 root root 1208 Mar 31 00:01 certs/tls.crt
-rw------- 1 root root 1704 Mar 31 00:01 certs/tls.key- 方式二:命令快速自签名
shell
root@master01:~# cd /root/dashboard/certs
root@master01:~/dashboard/certs# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/C=CN/ST=ZheJiang/L=HangZhou/O=Xianghy/OU=Xianghy/CN=webui.linuxsb.com"
root@master01:~/dashboard/certs# ll tls.*- 方式三:申请免费证书
多个渠道可获取免费90天的证书,免费证书获取可参考:https://freessl.cn 。或者腾讯云 SSL证书 板块。
将已获取的证书上传至对应目录。
手动创建secret
自定义证书的场景,建议提前使用对应的证书创建secret。
shell
root@master01:~/dashboard/certs# cd /root/dashboard/
root@master01:~/dashboard# kubectl create ns kubernetes-dashboard #v3版本dashboard独立ns
root@master01:~/dashboard# kubectl -n kubernetes-dashboard create secret tls kubernetes-dashboard-certs \
--cert=/root/dashboard/certs/tls.crt \
--key=/root/dashboard/certs/tls.key
root@master01:~/dashboard# kubectl -n kubernetes-dashboard get secret kubernetes-dashboard-certs -o yaml #查看证书信息获取部署文件
添加kubernetes-dashboard的repo仓库。
shell
root@master01:~# helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
root@master01:~# helm repo list
NAME URL
......
kubernetes-dashboard https://kubernetes.github.io/dashboard/ 创建自定义配置
根据实际情况修改默认的chart values,未配置的项表示使用默认值。
如下yaml主要做了几项自定义配置:
- 指定dashboard部署在master节点,将其归属为集群自有应用,而非业务应用;
- 指定了使用自有的TLS证书,及https的ingress域名;
- 指定了污点能接受master节点;
- 指定了Pod挂载本地时间文件,使Pod时钟正确。
kubernetes-dashboard默认的values值参考 Kubernetes dashboard chart values ,没有自定义的参数将自动沿用默认配置。
shell
root@master01:~# cd /root/dashboard/
root@master01:~/dashboard# helm show values kubernetes-dashboard/kubernetes-dashboard > defaults-values.yaml #查看默认配置
root@master01:~/dashboard# vim myvalues.yaml
app:
scheduling:
nodeSelector: {"dashboard": "enable"}
ingress:
enabled: true
hosts:
# - localhost
- web.linuxsb.com
ingressClassName: nginx
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true"
tls:
enabled: true
secretName: "kubernetes-dashboard-certs"
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
auth:
nodeSelector: {"dashboard": "enable"}
# API deployment configuration
api:
scaling:
replicas: 3
containers:
volumeMounts:
- mountPath: /tmp
name: tmp-volume
- mountPath: /etc/localtime
name: timeconfig
volumes:
- name: tmp-volume
emptyDir: {}
- name: timeconfig
hostPath:
path: /etc/localtime
nodeSelector: {"dashboard": "enable"}
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: "Exists"
effect: "NoSchedule"
# WEB UI deployment configuration
web:
scaling:
replicas: 3
containers:
volumeMounts:
- mountPath: /tmp
name: tmp-volume
- mountPath: /etc/localtime
name: timeconfig
volumes:
- name: tmp-volume
emptyDir: {}
- name: timeconfig
hostPath:
path: /etc/localtime
nodeSelector: {"dashboard": "enable"}
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: "Exists"
effect: "NoSchedule"
# Metrics Scraper
metricsScraper:
scaling:
replicas: 3
containers:
volumeMounts:
- mountPath: /tmp
name: tmp-volume
- mountPath: /etc/localtime
name: timeconfig
volumes:
- name: tmp-volume
emptyDir: {}
- name: timeconfig
hostPath:
path: /etc/localtime
nodeSelector: {"dashboard": "enable"}
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: "Exists"
effect: "NoSchedule"
kong:
nodeSelector: {"dashboard": "enable"}
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: "Exists"
effect: "NoSchedule"正式部署
根据生产环境最佳实践进行调优,调优完成后开始部署。
shel
root@master01:~/dashboard# helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard -f myvalues.yaml提示:对于国内环境,可能如上直接部署会由于网络原因失败,可单独将dashboard包下载至本地,然后通过命令部署。
shell
root@master01:~/dashboard# helm pull kubernetes-dashboard/kubernetes-dashboard
root@master01:~/dashboard# helm upgrade --install kubernetes-dashboard ./kubernetes-dashboard-7.11.1.tgz \
--create-namespace --namespace kubernetes-dashboard \
-f myvalues.yaml
shell
root@master01:~/dashboard# helm -n kubernetes-dashboard list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kubernetes-dashboard kubernetes-dashboard 1 2025-03-31 00:10:33.070211851 +0800 CST deployed kubernetes-dashboard-7.11.1
root@master01:~/dashboard# kubectl -n kubernetes-dashboard get all
root@master01:~/dashboard# kubectl -n kubernetes-dashboard get ingress -o wide
NAME CLASS HOSTS ADDRESS PORTS AGE
kubernetes-dashboard nginx web.linuxsb.com 10.20.199.82 80, 443 5m28s
默认配置中,会自动为dashboard创建ingress规则,部署ingress之后可直接如上图所示存在dashboard的ingress对象。
创建管理员账户
建议创建管理员账户,dashboard默认没有创建具有管理员权限的账户,同时v7版本登录只支持token方式。
因此建议创建管理员权限的用户,然后创建此用户的token,然后使用此token进行登录。
shell
root@master01:~/dashboard# cat <<EOF > dashboard-admin.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin
namespace: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
type: kubernetes.io/service-account-token
metadata:
name: admin
namespace: kubernetes-dashboard
annotations:
kubernetes.io/service-account.name: "admin"
EOF
root@master01:~/dashboard# kubectl apply -f dashboard-admin.yaml查看token
最新版dashboard只支持token的方式访问dashboard。
shell
root@master01:~/dashboard# ADMIN_SECRET=$(kubectl -n kubernetes-dashboard get secret | grep admin | awk '{print $1}')
root@master01:~/dashboard# DASHBOARD_LOGIN_TOKEN=$(kubectl describe secret -n kubernetes-dashboard ${ADMIN_SECRET} | grep -E '^token' | awk '{print $2}')
root@master01:~/dashboard# echo ${DASHBOARD_LOGIN_TOKEN}提示:也可通过如下方式获取name为admin的secret的token。
kubectl -n kubernetes-dashboard get secret admin -o jsonpath={".data.token"} | base64 -d
将web.linuxsb.com.crt证书文件导入,以便于浏览器使用该文件登录。
导入证书
将web.linuxsb.com.crt证书导入浏览器,并设置为信任,可规避证书不受信任的弹出。
测试访问dashboard
本实验采用ingress所暴露的域名: https://web.linuxsb.com
使用对应admin用户的token进行访问。
登录后默认进入的是default命名空间,可切换至其他对应的namespace,对整个Kubernetes进行管理和查看。

提示:更多dashboard访问方式及认证可参考附004.Kubernetes Dashboard简介及使用。
dashboard登录整个流程可参考:https://www.cnadn.net/post/2613.html
Longhorn存储部署
Longhorn概述
Longhorn是用于Kubernetes的开源分布式块存储系统。
当前Kubernetes 1.32.3 版本建议使用Longhorn 1.8.1 。
提示:更多介绍参考:https://github.com/longhorn/longhorn 。
安装要求
安装 Longhorn 的 Kubernetes 集群中的每个节点都必须满足以下要求:
- 与 Kubernetes 兼容的容器运行时,如Docker v1.13+、containerd v1.3.7+ ;
- Kubernetes >= v1.25;
- open-iscsi已安装,并且iscsid守护程序在所有节点上运行,此为必要条件,Longhorn 依赖 iscsiadm 主机为 Kubernetes 提供持久卷;
- RWX 支持要求每个节点都安装 NFSv4 客户端;
- 有关安装 NFSv4 客户端;
- 主机文件系统支持file extents存储数据的功能,当前支持:ext4、xfs;
- 其他必要命令工具:bash、curl、findmnt、grep、awk、blkid、lsblk;
- 为了正确部署和运行 Longhorn,Longhorn 工作负载必须能够以 root 身份运行。
本指南旨在使用longhorn给Kubernetes提供持久化存储,通常由Kubernetes的应用操作Longhorn,Longhorn也支持直接通过longhornctl命令操作存储。
longhornctl命令更多使用参考:longhornctl命令工具 。
shell
curl -sSfL -o /usr/local/bin/longhornctl https://github.com/longhorn/cli/releases/download/v1.8.1/longhornctl-linux-amd64
chmod +x /usr/local/bin/longhornctlroot权限说明可参考: Root和特权权限说明
安装准备
- 脚本检查
最新版官方已提供完整的环境检查脚本。
shell
root@master01:~# curl -sSfL https://raw.githubusercontent.com/longhorn/longhorn/v1.8.1/scripts/environment_check.sh | bash- 环境准备
后续业务应用可能运行在任意节点位置,挂载操作需要在任何节点可正常执行。
所有节点均需要安装基础以来软件。
shell
root@master01:~# source environment.sh
root@master01:~# for all_ip in "${ALL_IPS[@]}"
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
ssh root@${all_ip} "cat /boot/config-`uname -r`| grep CONFIG_NFS_V4 || true"
ssh root@${all_ip} "apt-get -y install open-iscsi nfs-common &"
ssh root@${all_ip} "cat > /etc/modules-load.d/iscsid.conf <<EOF
iscsi_tcp
nfs
nfsv4
EOF
"
ssh root@${all_ip} "systemctl restart systemd-modules-load.service"
ssh root@${all_ip} "systemctl enable iscsid --now"
done提示:如上仅需Master01节点操作,从而实现所有Worker节点的组件安装。
设置标签
本实验规划master用于 Longhorn UI 部署,worker用于提供真实的存储。
在Master节点上部署 Longhorn UI 。
在worker节点上部署 Longhorn Manager 和 Longhorn Driver 。
shell
root@master01:~# kubectl label nodes master0{1,2,3} longhorn-ui=enabled
root@master01:~# kubectl label nodes worker0{1,2,3} longhorn-storage=enabled提示:ui图形界面可复用master高可用,因此部署在master节点。
准备磁盘
Longhorn的分布式存储,建议独立磁盘设备专门作为存储卷,可提前挂载。
longhorn默认使用/var/lib/longhorn/作为设备路径,可提前挂载/dev/nvme0n2设备。
不同环境下裸磁盘的设备名不一样,且根据启动时识别的顺序可能设备名不一样,因此建议采用UUID挂载设备,保持挂载一致性。
shell
root@worker01:~# fdisk -l #判断新增的独立磁盘
root@master01:~# source environment.sh
root@worker01:~# for node_ip in "${NODE_IPS[@]}"
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkfs.xfs -f /dev/sdb && mkdir -p /var/lib/longhorn/ && echo '/dev/sdb /var/lib/longhorn xfs defaults 0 0' >> /etc/fstab && mount -a"
done提示:如上操作需要在所有worker节点根据相应的UUID进行挂载操作。\
shell
root@master01:~# source environment.sh
root@master01:~# for node_ip in ${NODE_IPS[@]}
do
echo -e "\n\n\033[33m[INFO] >>> ${node_ip}...\033[0m"
ssh root@${node_ip} "systemctl daemon-reload"
ssh root@${node_ip} "mount -a"
echo -e "\n\n\033[34m[WARN] >>> ${node_ip} check result...\033[0m"
sleep 1
ssh root@${node_ip} "df -hT | grep longhorn"
done获取部署文件
根据实际生产环境,对Longhorn进行优化配置。
存储节点使用worker01、worker02、worker03,图形界面可部署在master节点,复用Kubernetes的高可用。
提示:也可使用kubectl进行安装,kubectl安装参考官方: Install with Kubectl
kubectl和helm安装时均可自定义相关配置,更多自定义配置可参考官方:Longhorn自定义配置
shell
root@master01:~# mkdir longhorn
root@master01:~# cd longhorn/
root@master01:~/longhorn# helm repo add longhorn https://charts.longhorn.io
root@master01:~/longhorn# helm repo list | grep longhorn
longhorn https://charts.longhorn.io
root@master01:~/longhorn# helm search repo longhorn
NAME CHART VERSION APP VERSION DESCRIPTION
longhorn/longhorn 1.8.1 v1.8.1 Longhorn is a distributed block storage system ...创建自定义配置
shell
root@master01:~/longhorn# helm show values longhorn --repo https://charts.longhorn.io > defaults-values.yaml #查看默认配置
root@master01:~/longhorn# vim myvalues.yaml
longhornManager:
nodeSelector:
longhorn-storage: enabled
extraVolumeMounts:
- name: timeconfig
mountPath: /etc/localtime
readOnly: true
extraVolumes:
- name: timeconfig
hostPath:
path: /etc/localtime
longhornDriver:
nodeSelector:
longhorn-storage: enabled
longhornUI:
replicas: 3
nodeSelector:
longhorn-ui: enabled
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
extraVolumeMounts:
- name: timeconfig
mountPath: /etc/localtime
readOnly: true
extraVolumes:
- name: timeconfig
hostPath:
path: /etc/localtime
ingress:
enabled: true
ingressClassName: "nginx"
host: "longhorn.linuxsb.com"
path: /
pathType: Prefix
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: longhorn-basic-auth
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required'
nginx.ingress.kubernetes.io/proxy-body-size: 50m
nginx.ingress.kubernetes.io/ssl-redirect: "false"对于longhorn-ui的svc不建议直接通过nodeport暴露,保持默认的ClusterIP,然后通过ingress对外暴露。
创建Longhorn UI密码
使用已部署完成的ingress将Longhorn UI暴露,以便于使用URL形式访问Longhorn图形界面进行Longhorn的基础管理。
使用helm部署Longhorn中,可直接在自定义 values中直接配置ingress,若开启认证,则需要提前创建好用户密码。
shell
root@master01:~/longhorn# apt-get -y install apache2-utils
root@master01:~/longhorn# htpasswd -c auth admin #创建用户名和密码
New password: [输入密码]
Re-type new password: [输入密码]提示:也可通过如下命令创建用户名和密码:
USER=admin; PASSWORD=admin1234; echo "${USER}:$(openssl passwd -stdin -apr1 <<< ${PASSWORD})" >> auth
创建secret。
shell
root@master01:~/longhorn# kubectl create namespace longhorn-system
root@master01:~/longhorn# kubectl -n longhorn-system create secret generic longhorn-basic-auth --from-file=auth正式部署
基于自定义的 helm values 进行部署。
shell
root@master01:~/longhorn# helm upgrade --install longhorn longhorn/longhorn --create-namespace --namespace longhorn-system -f myvalues.yaml
root@master01:~/longhorn# kubectl -n longhorn-system get pods -o wide #查看所有已部署的Pod
root@master01:~/longhorn# kubectl -n longhorn-system get svc -o wide
root@master01:~/longhorn# kubectl -n longhorn-system get svc longhorn-frontend
root@master01:~/longhorn# kubectl -n longhorn-system get ingress longhorn-ingress
root@master01:~/longhorn# kubectl -n longhorn-system describe svc longhorn-frontend
root@master01:~/longhorn# kubectl -n longhorn-system describe ingress longhorn-ingress 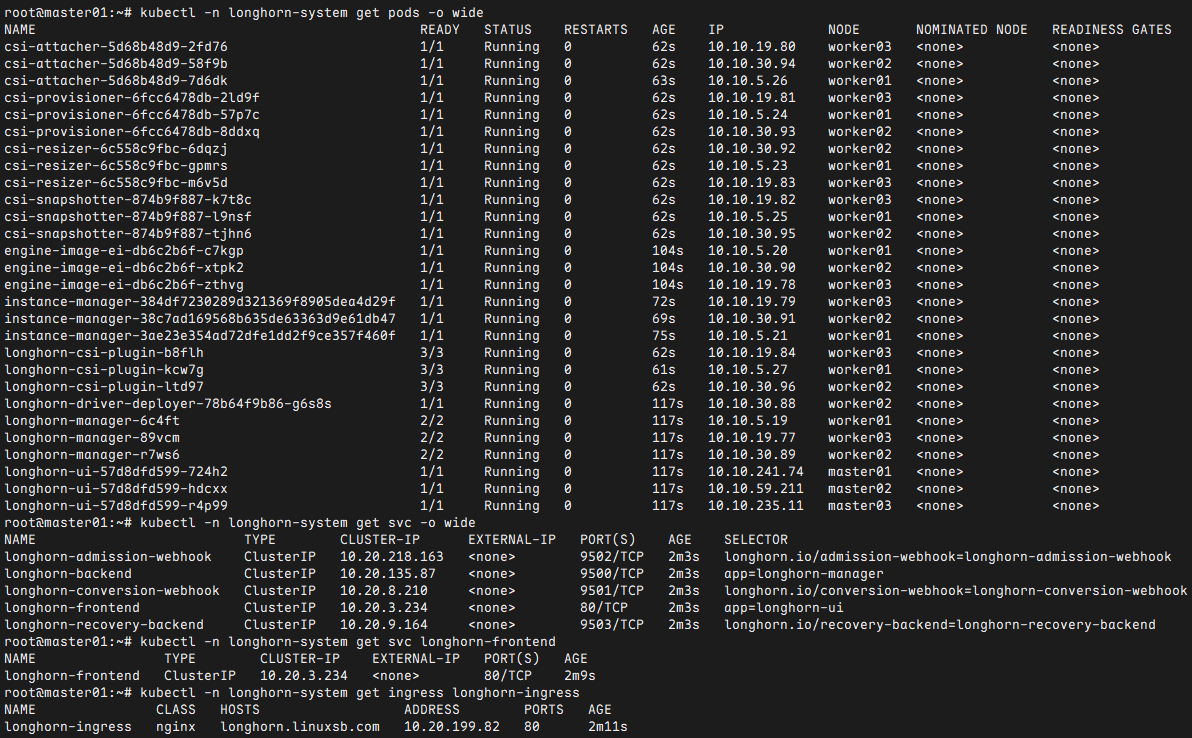
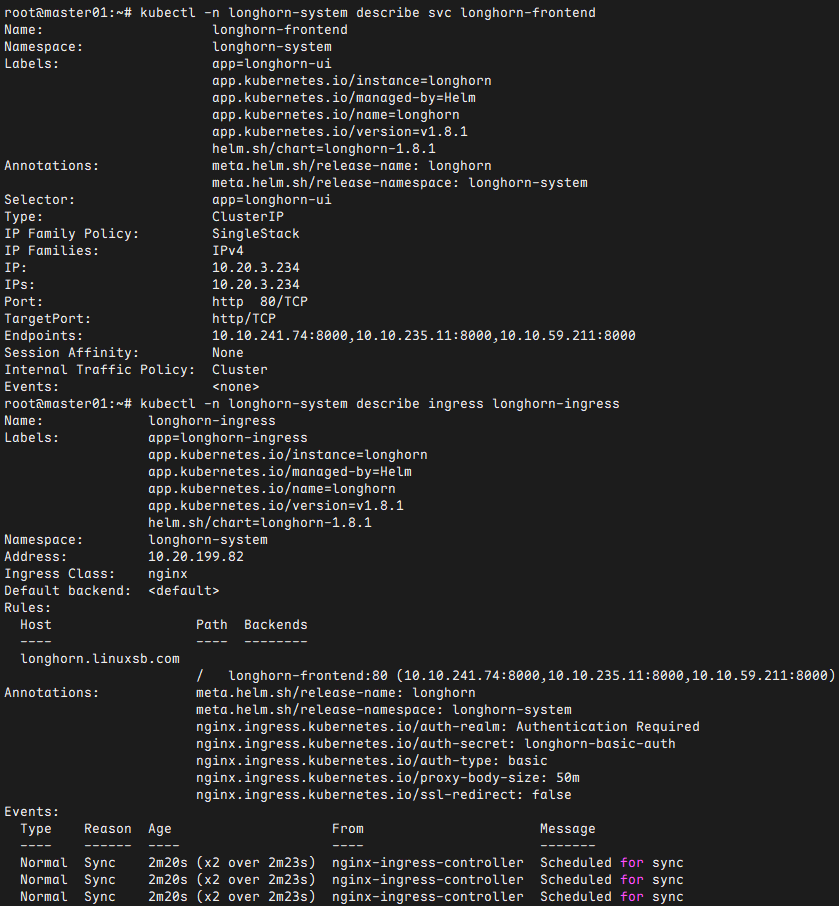
提示:若部署异常可删除重建,若出现无法删除namespace,可通过如下操作进行删除:
方式一:
shell
root@master01:~/longhorn# helm -n longhorn-system uninstall longhorn
root@master01:~/longhorn# kubectl -n longhorn-system edit settings.longhorn.io deleting-confirmation-flag
#......
value: "true"方式二:
shell
wget https://github.com/longhorn/longhorn/blob/master/uninstall/uninstall.yaml
kubectl apply -f uninstall.yaml
kubectl get job/longhorn-uninstall -n longhorn-system -w
kubectl delete -f uninstall.yaml #等待任务完成再次执行delete
rm -rf /var/lib/longhorn/*动态sc创建
部署Longhorn后,默认已创建一个名为longhorn的sc。
shell
root@master01:~/longhorn# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 16m
longhorn-static driver.longhorn.io Delete Immediate true 16m也可以通过如下方式创建一个新的sc,测试Longhorn部署结果。
shell
root@master01:~/longhorn# cat <<EOF > longhornpsc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-test
provisioner: driver.longhorn.io
allowVolumeExpansion: true
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880" # 48 hours in minutes
fromBackup: ""
fsType: "ext4"
EOF
root@master01:~/longhorn# kubectl apply -f longhornpsc.yaml测试PV及PVC
使用常见的Nginx Pod进行测试,模拟生产环境常见的Web类应用的持久性存储卷。
shell
root@master01:~/longhorn# cat <<EOF > longhornpvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 50Mi
EOF #创建PVC
root@master01:~/longhorn# cat <<EOF > longhornpod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: longhorn-pod
namespace: default
spec:
containers:
- name: volume-test
image: nginx:stable-alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- name: volv
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: volv
persistentVolumeClaim:
claimName: longhorn-pvc
EOF #创建Pod
root@master01:~/longhorn# kubectl apply -f longhornpvc.yaml -f longhornpod.yaml
root@master01:~/longhorn# kubectl get pods -o wide
root@master01:~/longhorn# kubectl get pvc -o wide
root@master01:~/longhorn# kubectl get pv -o wide
确认验证
浏览器访问:longhorn.linuxsb.com ,并输入设置的账号和密码。

使用admin/密码登录查看。

kube-Prometheus部署
获取资源
root@master01:~# git clone https://github.com/prometheus-operator/kube-prometheus.git拉取镜像
由于Prometheus所需镜像仓库国外,建议提前拉取至本地,如上 docker_pull_lists_images.sh 脚本为个人使用脚本,把国外镜像先同步国内至仓库,然后从国内仓库下载,再修改tag为yaml中默认的国外tag。
shell
root@master01:~# cd kube-prometheus/
root@master01:~/kube-prometheus# grep -rn "image:" manifests/ | awk '{print $3}' | grep -v ^$ | sort | uniq > images.list #查看manifests部署所需镜像
root@master01:~/kube-prometheus# cat images.list
ghcr.io/jimmidyson/configmap-reload:v0.14.0
grafana/grafana:11.5.2
quay.io/brancz/kube-rbac-proxy:v0.19.0
quay.io/prometheus/alertmanager:v0.28.1
quay.io/prometheus/blackbox-exporter:v0.26.0
quay.io/prometheus/node-exporter:v1.9.0
quay.io/prometheus-operator/prometheus-operator:v0.81.0
quay.io/prometheus/prometheus:v3.2.1
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.15.0
registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0
root@master01:~/kube-prometheus# wget http://down.linuxsb.com/myshell/docker_pull_lists_images.sh
root@master01:~/kube-prometheus# for all_ip in "${ALL_IPS[@]}"
do
echo -e "\n\n\033[33m[INFO] >>> ${all_ip}...\033[0m"
sleep 2
scp -rp /root/ctr_*.sh root@${all_ip}:/root/
ssh root@${all_ip} "bash ctr_pull_lists_images.sh"
done创建prometheus持久卷
prometheus 默认是通过 emptyDir 进行挂载的,emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,为了实现数据持久化,本方案建议提前生成持久卷。
prometheus是一种 StatefulSet 有状态集的部署模式,可直接将 StorageClass 配置到如下yaml 中。
本环境已创建动态存储longhorn,longhorn部署参考《附034.Kubernetes_v1.21.0高可用部署架构二》。
[root@master01 ~]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn driver.longhorn.io Delete Immediate true 12d
[root@master01 ~]# cd kube-prometheus/manifests/
[root@master01 manifests]# vim prometheus-prometheus.yaml #追加如下持久化配置
......
storage:
volumeClaimTemplate:
spec:
storageClassName: longhorn
resources:
requests:
storage: 1Gi创建grafana持久卷
Grafana 是部署模式为 Deployment,所以我们提前为其创建一个 grafana-pvc.yaml 文件,加入下面 PVC 配置。
[root@master01 manifests]# vim grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-storage
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 1Gi
[root@master01 manifests]# vim grafana-deployment.yaml
......
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
readOnly: false
......
serviceAccountName: grafana
volumes:
- name: grafana-storage
persistentVolumeClaim: #修改为预创建的pvc
claimName: grafana-storage
......修改暴露服务端口
需要修改的是alertmanager-main,grafana,prometheus-k8s。
[root@master01 manifests]# vim alertmanager-service.yaml
apiVersion: v1
kind: Service
#......
spec:
type: NodePort #SVC暴露模式设为NodePort
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30010 #指定nodePort
#......
[root@master01 manifests]# vim grafana-service.yaml
apiVersion: v1
kind: Service
#......
spec:
type: NodePort #SVC暴露模式设为NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30011 #指定nodePort
#......
[root@master01 manifests]# vim prometheus-service.yaml
apiVersion: v1
kind: Service
#......
spec:
type: NodePort #SVC暴露模式设为NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30012 #指定nodePort
#......部署operator
[root@master01 manifests]# kubectl apply --server-side -f ./setup #创建monitoring命名空间和CRD模板
[root@master01 manifests]# kubectl apply -f .提示:如上操作会创建monitoring 的命名空间,以及相关的 Prometheus Operator 控制器。
创建 Operator 后,可以创建自定义资源清单(CRD),若需要自定义资源对象生效就需要安装对应的 Operator 控制器,因此如上创建operator需要在创建CRD之前。
提示:kube-Prometheus安装和使用完全教程 中提到了给Prometheus提权,可参考。
确认验证
[root@master01 manifests]# kubectl -n monitoring get pods -o wide
[root@master01 manifests]# kubectl -n monitoring get svc -o wide
若要使用端口访问,由于kube-Prometheus默认会创建networkpolicy,因此在不适用规则的情况下,可删除相应的策略。
shell
[root@master01 manifests]# kubectl delete -f alertmanager-networkPolicy.yaml
[root@master01 manifests]# kubectl delete -f grafana-networkPolicy.yaml
[root@master01 manifests]# kubectl delete -f prometheus-networkPolicy.yaml访问alertmanager-main,http://172.24.8.180:30010/ 。
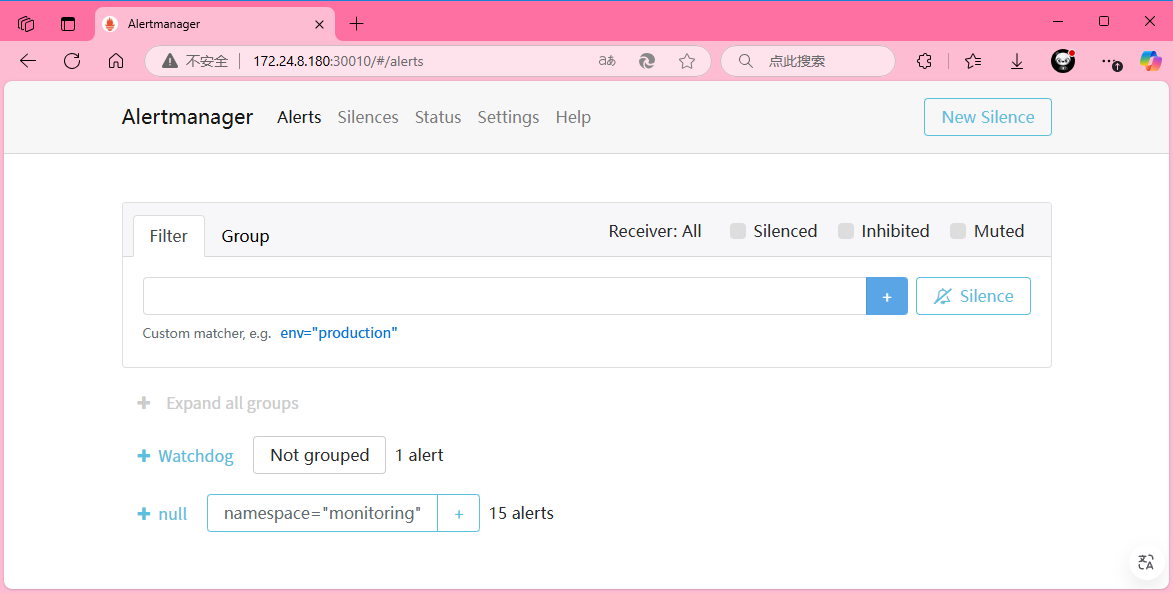
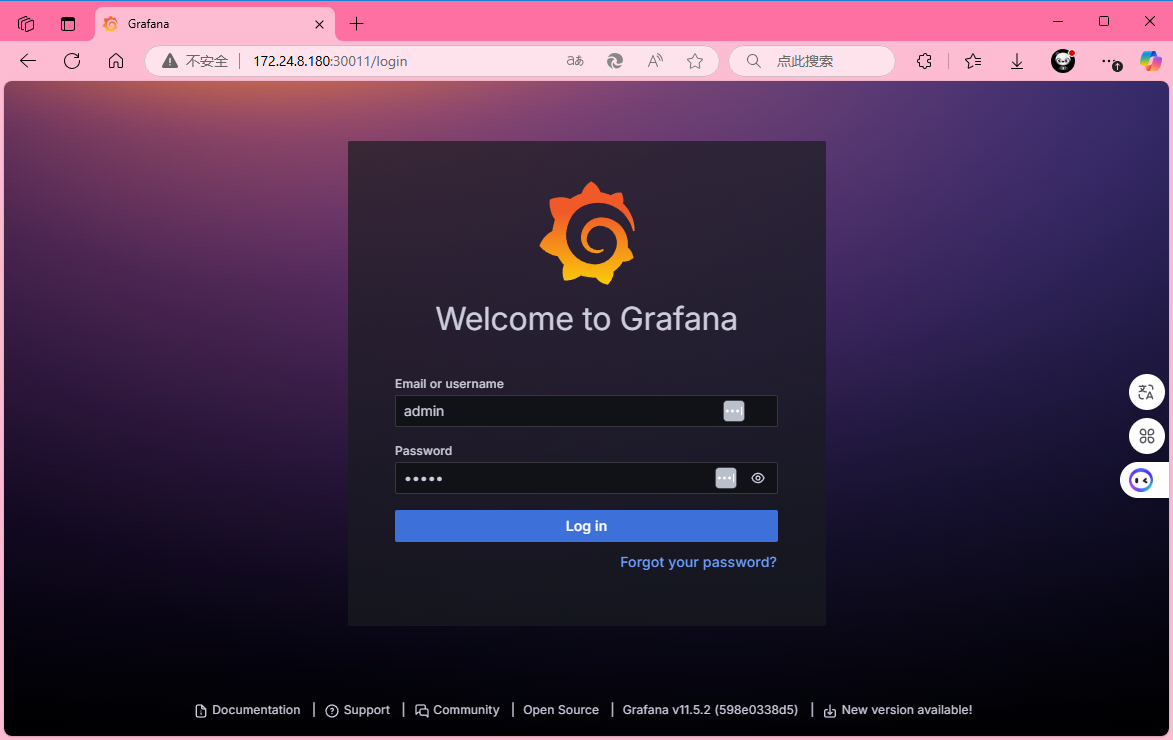
访问grafana,http://172.24.8.180:30011/ ,默认用户名密码都为admin。
访问prometheus-k8s,http://172.24.8.180:30012/ 。

ingress暴露alertmanager
[root@master01 manifests]# vim alertmanager-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: alertmanager-ingress
namespace: monitoring
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: alertmanager
spec:
ingressClassName: "nginx"
rules:
- host: alertmanager.linuxsb.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
[root@master01 manifests]# kubectl apply -f alertmanager-ingress.yamlingress暴露prometheus
[root@master01 manifests]# vim prometheus-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-ingress
namespace: monitoring
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: prometheus
spec:
ingressClassName: "nginx"
rules:
- host: prometheus.linuxsb.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
[root@master01 manifests]# kubectl apply -f prometheus-ingress.yamlingress暴露grafana
[root@master01 manifests]# vim grafana-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana-ingress
namespace: monitoring
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: grafana
spec:
ingressClassName: "nginx"
rules:
- host: grafana.linuxsb.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
[root@master01 manifests]# kubectl apply -f grafana-ingress.yaml确认验证
访问grafana,http://alertmanager.linuxsb.com 。
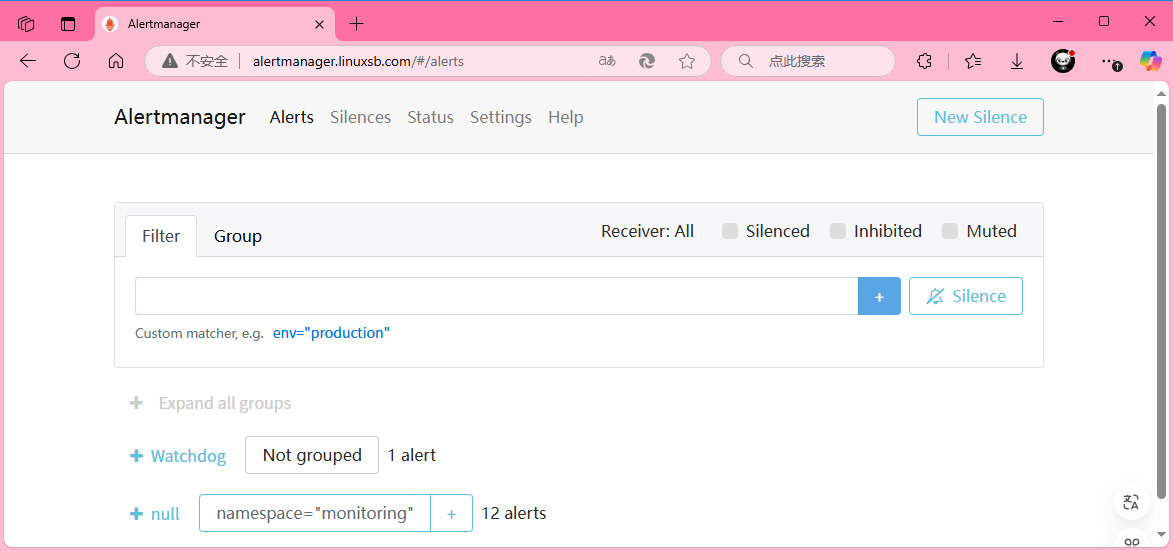
访问grafana,http://prometheus.linuxsb.com 。
访问grafana,http://grafana.linuxsb.com 。

配置grafana
配置源数据
浏览器访问:http://grafana.linuxsb.com ,Connections ----> Data Sources。
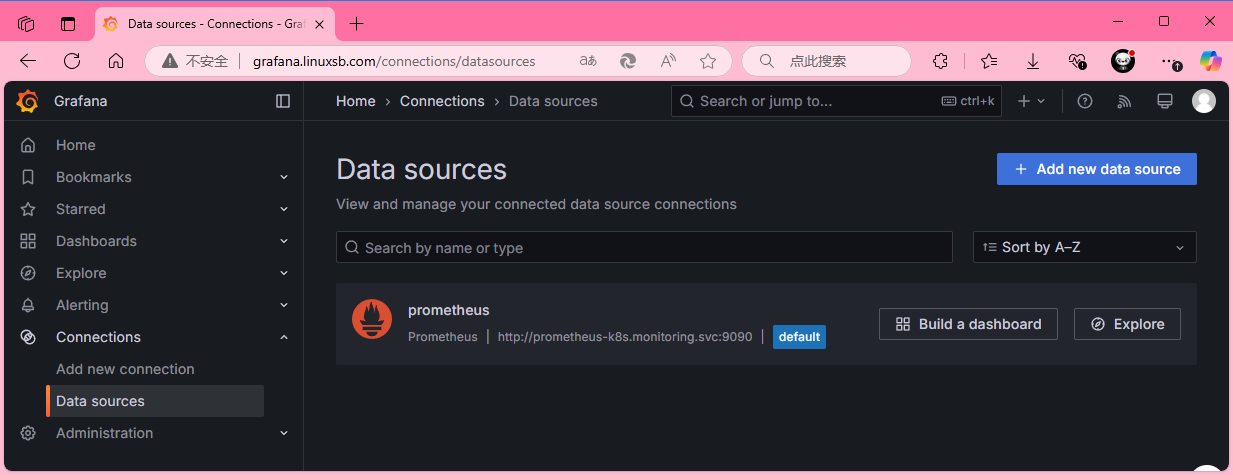
本项目grafana默认已经添加了Prometheus数据源,可以直接使用。
配置Grafana
配置dashboard,新增dashboard。

导入dashboard,本实验使用315号模板,此Dashboard 模板来展示 Kubernetes 集群的监控信息。


设置导入后的dashboard名称,以及使用的监控数据源。

查看Kubernetes监控信息。
Grafana其他配置
建议配置对应的时区。
查看Kubernetes监控

提示:本文参考:https://blog.csdn.net/zuozewei/article/details/108358460
kubesphere 部署
kubesphere 介绍
KubeSphere,是基于 Kubernetes 内核的分布式多租户商用云原生操作系统。在开源能力的基础上,在多云集群管理、微服务治理、应用管理等多个核心业务场景进行功能延伸。
商用扩展中心实现高度模块化,满足不同场景业务需求。以强大的企业级云原生底座,完善的专家级解决方案和服务支持,赋能企业数字化转型和规模化运营。
自 KubeSphere v4.0 起,引入扩展机制,推出了全新的 KubeSphere 架构:KubeSphere LuBan,它构建在 Kubernetes 之上,支持高度可配置和可扩展。KubeSphere LuBan,是一个分布式的云原生可扩展开放架构,为扩展组件提供一个可热插拔的微内核。自此,KubeSphere 所有功能组件及第三方组件都会基于 KubeSphere LuBan,以扩展组件的方式无缝融入到 KubeSphere 控制台中,并独立维护版本,真正实现即插即用的应用级云原生操作系统。
提示:更多 KubeSphere 参考KubeSphere产品简介 。
创建证书
使用自定义域名访问 kubesphere ,因此需要为对应的域名制作TLS证书。
证书可通过如下任意一种方式获取。
- 方式一:脚本快速自签名
基于实验目的,采用自签名证书。
shell
root@master01:~# mkdir -p /root/kubesphere/certs
root@master01:~# cd /root/kubesphere/
root@master01:~/kubesphere# vim signcert.sh
#!/bin/sh
#***************************************************************#
# ScriptName: signcert.sh
# Author: xhy
# Create Date: 2025-02-25 21:49
# Modify Author: xhy
# Modify Date: 2025-03-31 00:00
# Version: v1
#***************************************************************#
# 配置参数
#PARENT_DOMAIN="linuxsb.com" # 父级域名
#SUB_DOMAINS=("kubesphere") # 子域名列表,可选配置
PARENT_DOMAIN="linuxsb.com"
SUB_DOMAINS=("web")
#...... #其他保持默认
root@master01:~/kubesphere# bash signcert.sh
root@master01:~/kubesphere# mv certs/linuxsb.com.crt certs/tls.crt
root@master01:~/kubesphere# mv certs/linuxsb.com.key certs/tls.key
root@master01:~/kubesphere# ll certs/tls.*
-rw-r--r-- 1 root root 1208 Mar 31 00:01 certs/tls.crt
-rw------- 1 root root 1704 Mar 31 00:01 certs/tls.key- 方式二:命令快速自签名
shell
root@master01:~# cd /root/kubesphere/
root@master01:~/kubesphere/certs# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/C=CN/ST=ZheJiang/L=HangZhou/O=Xianghy/OU=Xianghy/CN=webui.linuxsb.com"
root@master01:~/kubesphere/certs# ll tls.*- 方式三:申请免费证书
多个渠道可获取免费90天的证书,免费证书获取可参考:https://freessl.cn 。或者腾讯云 SSL证书 板块。
将已获取的证书上传至对应目录。
手动创建secret
自定义证书的场景,建议提前使用对应的证书创建secret。
shell
root@master01:~# cd /root/kubesphere/
root@master01:~/kubesphere# kubectl create ns kubesphere-system
root@master01:~/kubesphere# kubectl -n kubesphere-system create secret tls tls-ks-core-ingress \
--cert=/root/kubesphere/certs/tls.crt \
--key=/root/kubesphere/certs/tls.key
root@master01:~/kubesphere# kubectl -n kubesphere-system get secret tls-ks-core-ingress -o yaml #查看证书信息获取部署文件
通过helm方式获取官方kubesphere资源。
shell
root@master01:~# mkdir kubesphere
root@master01:~# cd kubesphere/
root@master01:~/kubesphere# helm repo add kubesphere https://charts.kubesphere.com.cn/main/
root@master01:~/kubesphere# helm repo list | grep kubesphere
kubesphere https://charts.kubesphere.com.cn/main/
root@master01:~/kubesphere# helm search repo kubesphere
NAME CHART VERSION APP VERSION DESCRIPTION
kubesphere/apisix 0.7.2 2.10.0 A Helm chart for Apache APISIX
kubesphere/apisix-dashboard 0.3.0 2.9.0 A Helm chart for Apache APISIX Dashboard
kubesphere/apisix-ingress-controller 0.8.0 1.3.0 Apache APISIX Ingress Controller for Kubernetes
kubesphere/elasticsearch-exporter 3.4.0 1.1.0 Elasticsearch stats exporter for Prometheus
kubesphere/fluentbit-operator 0.1.0 0.9.0 A Helm chart for Kubernetes
kubesphere/gitlab 4.2.3 13.2.2 Web-based Git-repository manager with wiki and ...
kubesphere/harbor 1.9.3 2.5.3 An open source trusted cloud native registry th...
kubesphere/ks-core 1.1.4 v4.1.3 A Helm chart for KubeSphere Core components
kubesphere/ks-installer 0.3.1 3.2.1 The helm chart of KubeSphere, supports installi...
kubesphere/memcached 3.2.5 1.5.20 Free & open source, high-performance, distribut...
kubesphere/minio 6.0.5 RELEASE.2020-08-08T04-50-06Z High Performance, Kubernetes Native Object Storage
kubesphere/mysql 1.6.8 5.7.31 Fast, reliable, scalable, and easy to use open-...
kubesphere/mysql-exporter 0.5.6 v0.11.0 A Helm chart for prometheus mysql exporter with...
kubesphere/nfs-client-provisioner 4.0.11 4.0.2 nfs-client is an automatic provisioner that use...
kubesphere/nginx 1.3.5 1.18.0 nginx is an HTTP and reverse proxy server, a ma...
kubesphere/pvc-autoresizer 0.1.0 v0.1 Auto-resize PersistentVolumeClaim objects based...
kubesphere/redis-exporter 3.4.6 1.3.4 Prometheus exporter for Redis metrics
kubesphere/sonarqube 6.7.0 8.9-community SonarQube is an open sourced code quality scann...
kubesphere/storageclass-accessor 0.1.0 v0.1.1 The storageclass-accessor webhook is an HTTP ca...
kubesphere/tomcat 0.4.3 8.5.41 Deploy a basic tomcat application server with s...创建自定义配置
根据需求创建自定义配置:
- 设置kubesphere访问域名;
- 启用https;
- 设置正确的时钟服务器;
- 数据持久化。
shell
root@master01:~/kubesphere# helm show values kubesphere/ks-core > defaults-values.yaml #查看默认配置
root@master01:~/kubesphere# vim myvalues.yaml
global:
imageRegistry: swr.cn-southwest-2.myhuaweicloud.com/ks
portal:
hostname: "kubesphere.linuxsb.com"
https:
port: 443
ingress:
enabled: true
ingressClassName: "nginx"
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true" # 强制HTTPS重定向
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
tls:
enabled: true
source: importation
secretName: "tls-ks-core-ingress"
apiserver:
extraVolumeMounts:
- name: timeconfig
mountPath: /etc/localtime
readOnly: true
extraVolumes:
- name: timeconfig
hostPath:
path: /etc/localtime
console:
extraVolumeMounts:
- name: timeconfig
mountPath: /etc/localtime
readOnly: true
extraVolumes:
- name: timeconfig
hostPath:
path: /etc/localtime
controller:
extraVolumeMounts:
- name: timeconfig
mountPath: /etc/localtime
readOnly: true
extraVolumes:
- name: timeconfig
hostPath:
path: /etc/localtime
redis:
persistentVolume:
enabled: true
storageClassName: "longhorn"
size: 2Gi正式部署
使用helm正式部署。
shell
root@master01:~/kubesphere# helm upgrade --install ks-core https://charts.kubesphere.com.cn/main/ks-core-1.1.4.tgz --create-namespace --namespace kubesphere-system -f myvalues.yaml --debug --wait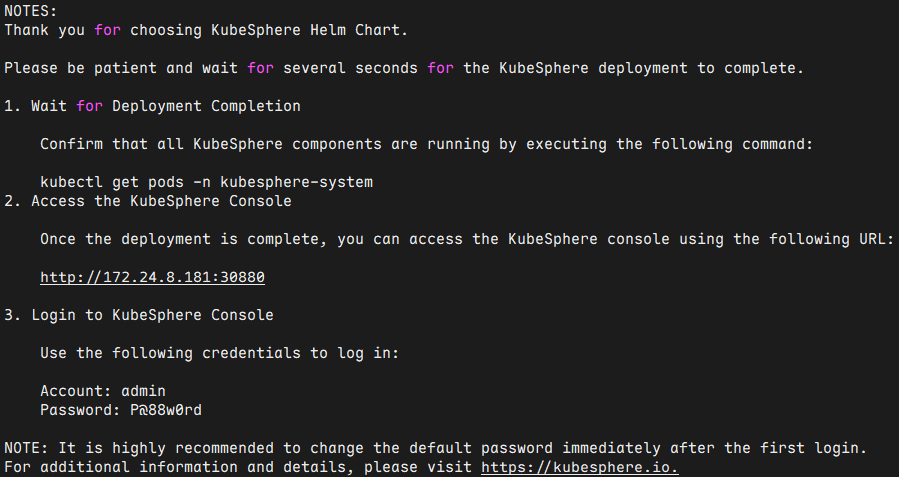
确认验证
shell
root@master01:~/kubesphere# kubectl -n kubesphere-system get all -o wide
浏览器访问 https://kubesphere.linuxsb.com/ ,使用部署后的初始账号和密码登录。
重置密码。
登录主页。
简单管理
可通过kubesphere对集群进行基础管理。
本方案与上一个版本做了大量更新,主要更新如下:
1:底层操作系统从 CentOS 更新为 Ubuntu Server 24.04 ;
2:环境预配置同步迭代为在 Ubuntu Server 上执行;
3:创建配置文件脚本彻底重构,实现多节点的动态支持;
4:Metrics、Ingress、Longhorn、kubesphere均更新为helm部署的方式;
5:Longhorn做了图形界面UI组件和真正提供存储的driver组件分离;
6:新增了kube-Prometheus+grafana组件,并做了数据持久化,提供集群监控;
7:新增了一个快速生成自签名证书的脚本。
提示:更多kubesphere使用参考官方doc:KubeSphere 。
扩展:集群扩容及缩容
集群扩容
- master节点扩容
参考:添加Master节点 步骤 - worker节点扩容
参考:添加Worker节点 步骤
集群缩容
- master节点缩容
Master节点缩容的时候会自动将Pod迁移至其他节点。
shell
root@master01:~# kubectl drain master03 --delete-emptydir-data --force --ignore-daemonsets
root@master01:~# kubectl delete node master03
root@master03:~# kubeadm reset -f && rm -rf $HOME/.kube- worker节点缩容
Worker节点缩容的时候会自动将Pod迁移至其他节点。
shell
root@master01:~# kubectl drain worker04 --delete-emptydir-data --force --ignore-daemonsets
root@master01:~# kubectl delete node worker04
root@worker04:~# kubeadm reset -f
root@worker04:~# rm -rf /etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf