第一课时
一、导入
前面的课程我们搭建了hadoop集群,并成功启动了它,接下来我们看看如何去使用集群。
测试的内容包括:1.上传文件,2.下载文件,3.运行程序
二、授新
( 一 ) 配置 运行任务的 历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。这个历史服务器需要消耗的资源比较小,你可以选择把它配置在集群中的任意一台节点上。但是,请注意,在哪一台上配置了,就应该在哪一台上去启动。
我们这把它配置在nn节点(hadoop100)上。具体配置步骤如下:
1.配置mapred-site.xml
在hadoop的安装目录下,打开mapred-site.xml,并在该文件里面增加如下两条配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop100:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop100:19888</value>
</property>2.分发配置
把这个配置同步到其他的节点中。这里直接使用我们之前封装好的命令xsync来同步。具体如下:
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
3.启动历史服务器
请注意,你在配置的时候指定哪个节点是历史服务器,就在哪里启动,请不要搞错了。
对应的命令是: mapred --daemon start historyserver
4.检查历史服务器是否启动
通过jps命令来查看历史服务器是否已经成功启动了。
root@hadoop100 hadoop$jps
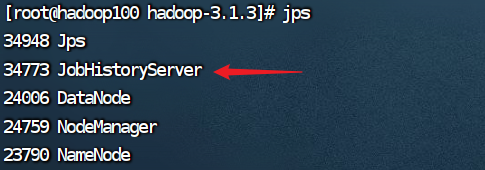
5.查看JobHistory
方式1:直接去看所有的历史记录 href="http://hadoop100:19888/jobhistory" ++++http://hadoop100:19888/jobhistory++++
方式2:重新启动yarn服务。再从具体的history链接进行跳转。
(二) 配置 运行任务的 日志
与历史命令相配套的还有对应的执行的日志。

它的入口在上面的位置。点击之后,我们去查看:

发现看不了。接下来我们就去配置一下,让它能够访问。
这个操作叫日志聚集。由于任务是在具体的节点上运行的,所以运行日志也是产生在具体的节点上,但是我们希望应用完成以后,将程序运行日志信息上传到HDFS系统上,这样就可以方便的查看到程序运行详情,方便开发调试。
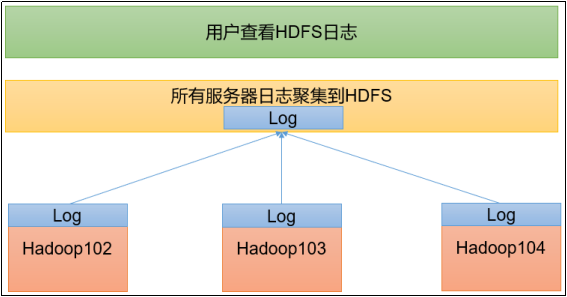
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
(1) 配置yarn-site.xml
打开yarn-site.xml文件,我们添加如下的配置。在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>(2)分发配置
和之前的配置一样,我们需要把这个更新之后的yarn-site.xml文件同步到其他的机器。这里还是使用脚本xsync。具体如下:
xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
(3)重启ResourceManager和HistoryServer
进入到我们安装yarn的主机,通过命令来关闭掉yarn和historyServer,然后再重启。
root@hadoop103 hadoop-3.1.3$ sbin/stop-yarn.sh
root@hadoop103 hadoop-3.1.3$mapred --daemon stop historyserver
启动ResourceManage和HistoryServer
mapred --daemon start historyserver
(三)测试运行任务的 日志
前面我们已经完成了任务日记的聚集,下面我们来看看是不是配置正确了。我们需要重新运行wordcount应用,然后再去看看是不是正确生成了日志。
- 重新 执行WordCount程序
命令如下:
root@hadoop100 hadoop-3.1.3$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
- 查看日志
如果一切正常,我们打开历史服务器地址http://hadoop101:19888/jobhistory 可以看到历史任务列表,如下:
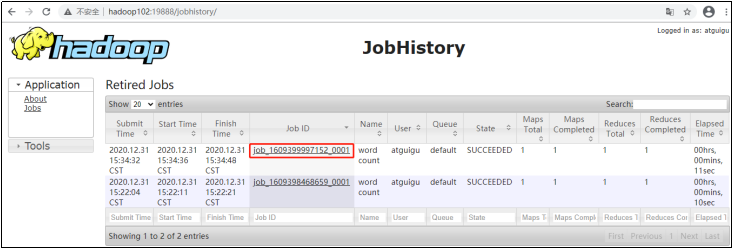
点击对应的JobID,就可以进一步查看任务运行日志
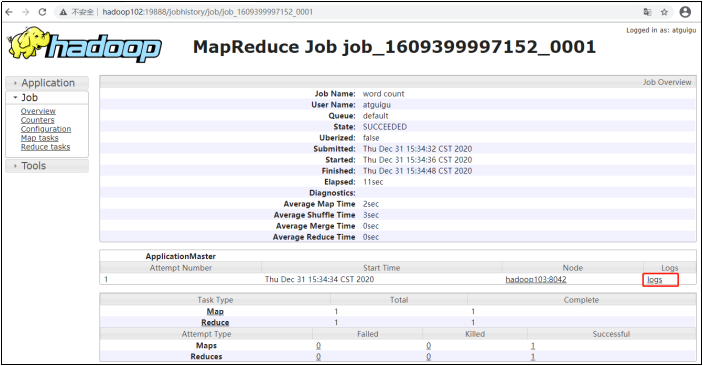
然后在点击logs,就可以查看运行日志的详情了。

第二课时
我们基本上完成了hadoop集群的所有配置了,涉及到的服务也非常多。下面我们看看在启动和关闭集群和相关的服务的细节。
( 四 ) 集群启动/停止方式 命令小 结
我们配置了多台服务器,并且每台服务器上运行的任务都不太相同,我们可以使用jps命令来查看每台设备上的运行任务。

具体说明如下:
- DataNode,它是hdfs的模块之一,每台服务器都有。
- NameNode, hdfs的核心服务,只有一个。
- SecondaryNameNode,hdfs的核心服务,是NameNode的备份。
- RourceManager, Yarn的核心服务,只有一个。
- NodeManager,Yarn的核心模块,每台服务器都有。
我们可以通过这些关键进程的名称来判断当前集群是否正常运转。
1.各个模块分开启动/停止
(1) 整体启动/停止HDFS:start-dfs.sh/stop-dfs.sh
(2) 整体启动/停止YARN: start-yarn.sh/stop-yarn.sh
2.各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN组件
yarn --daemon start/stop resourcemanager/nodemanager/historyserver
( 五 )编写Hadoop集群 启停 脚本
启动的命令(HDFS,Yarn,Historyserver)比较多,在启动的时候,还要分别进入不同的服务器写不同的命令,比较麻烦。我们可以准备一个自定义的shell脚本,更加方便地完成整体启动和停止。
具体操作有四步:
- 建立新文件,编写脚本程序
- 分配执行权限
- 分发脚本
- 测试执行
下面分别介绍。
1.我们在hadoop100中操作,在/root/bin下新建文件:myhadoop,输入如下内容:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop100 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop100 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop100 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop100 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac2.保存后退出,然后赋予脚本执行权限
chmod +x myhadoop
3.分发**/home/root/bin**目录,保证自定义脚本在三台机器上都可以使用。使用的命令如下
root@hadoop100 \~$ cd
4.测试执行
我们在hadoop100中,运行 myhadoop start 启动集群
在hadoop102中,运行myhadoop stop 停止集群
(六)查看三台服务器Java进程脚本:jpsall
同理,我们去/root/bin下创建一个新的脚本文件:jpsall,输入如下内容
#!/bin/bash
for host in hadoop100 hadoop101 hadoop102
do
echo =============== $host ===============
ssh $host jps
done保存后退出,然后赋予脚本执行权限
root@hadoop100 bin$chmod +x jpsall
3)分发/home/root/bin目录,保证自定义脚本在三台机器上都可以使用
root@hadoop100 \~$ xsync /home/root/bin/
( 七 ) 常用端口号说明
最后,补充总结一点关于我们用到的端口号的内容:
-
8020/9000/9820: NameNode内部通信端口
-
9870:NameNode HTTP UI
-
8088: MapReduce查看执行任务端口
-
19888:历史服务器通信端口
三、课堂小结
通过本堂课的学习,我们学习了配置历史任务的功能和查看运行日志的功能,并且编写了一个用来启动和停止集群的脚本。至此,所有的配置相关的内容全部结束。