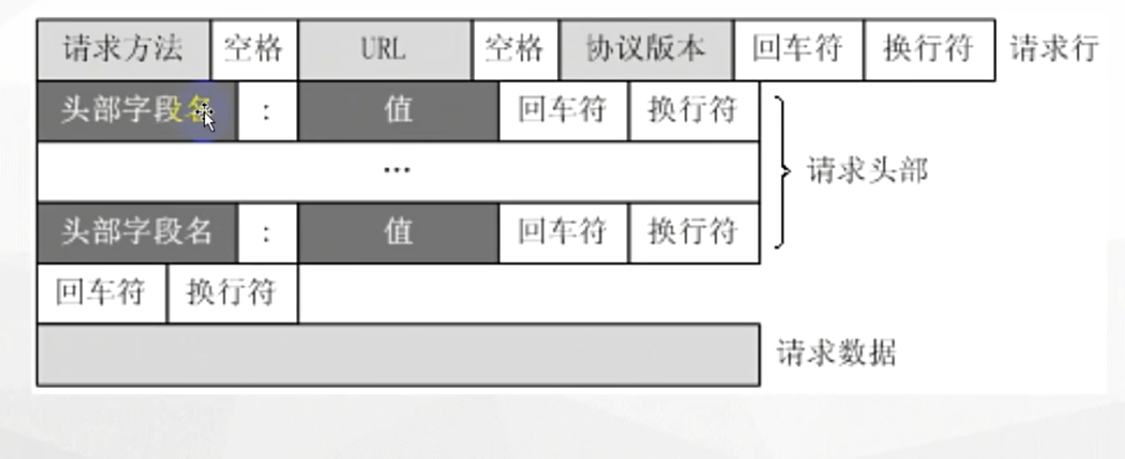
 请求方式:get(向服务器要资源)和post(提交资源)
请求方式:get(向服务器要资源)和post(提交资源)
 user-agent:模拟正常用户的一种方式
user-agent:模拟正常用户的一种方式
cookie:登陆保持
referer:表示当前这一次请求是由哪个请求过来的
抓取数据包得到的内容才是判断依据elements中的源码是渲染之后的不能作为判断标准
requests模块:

import requests
url="https://www.baidu.com"
response=requests.get(url)
#print(response.text)#响应内容有乱码,requests模块会自动寻求一种解码方式去解码
print(response.content.decode())使用requests库保存图片:
*确定url 发送请求,获取响应 保存响应
import requests
url='https://ts1.tc.mm.bing.net/th/id/R-C.f1e812793db01f91d2f3c3ba3170e9b2?rik=wWVRN0nDp7vIYw&riu=http%3a%2f%2fpic.bizhi360.com%2fbbpic%2f72%2f6572.jpg&ehk=Jofon8hSdAuGUWZlfcJuSvncnsYZsKv0KdGjxHD%2b2eg%3d&risl=&pid=ImgRaw&r=0'
response=requests.get(url)
#print(response.text)#响应内容有乱码,requests模块会自动寻求一种解码方式去解码
with open('1.png','wb')as f:
f.write(response.content)response.text和response.content的区别:
text:str类型,requests模块自动根据http头部对响应和编码做出的推测,返回文本数据
content:bytes类型,可以通过decode()解码,返回二进制数据(图片,视频等)
将编码设置为utf-8:
response.encoding='utf-8'#指定编码
