一、打开li视频在抓包工具中可以找到对应的视频链接,但是页面源代码却不行
这是因为页面源代码是 "服务器返回的初始模板",抓包工具里的 "源代码" 是 "包含动态渲染 + 所有依赖资源" 的完整集合 。因为视频数据是JS 通过异步接口动态加载的
过程是:
-
浏览器加载 视频页的 "页面源代码"(只有页面的 HTML 框架,没有具体视频数据);
-
页面中的 JS 执行,发送异步请求(比如
https://www.pearvideo.com/videoStatus.jspcontId=1802157&mrd=0.6347927921664064)到服务器; -
服务器返回视频数据(JSON 格式);
-
JS 把 JSON 数据解析后,插入到 DOM 结构中(Elements 面板能看到插入后的视频链接标签)。
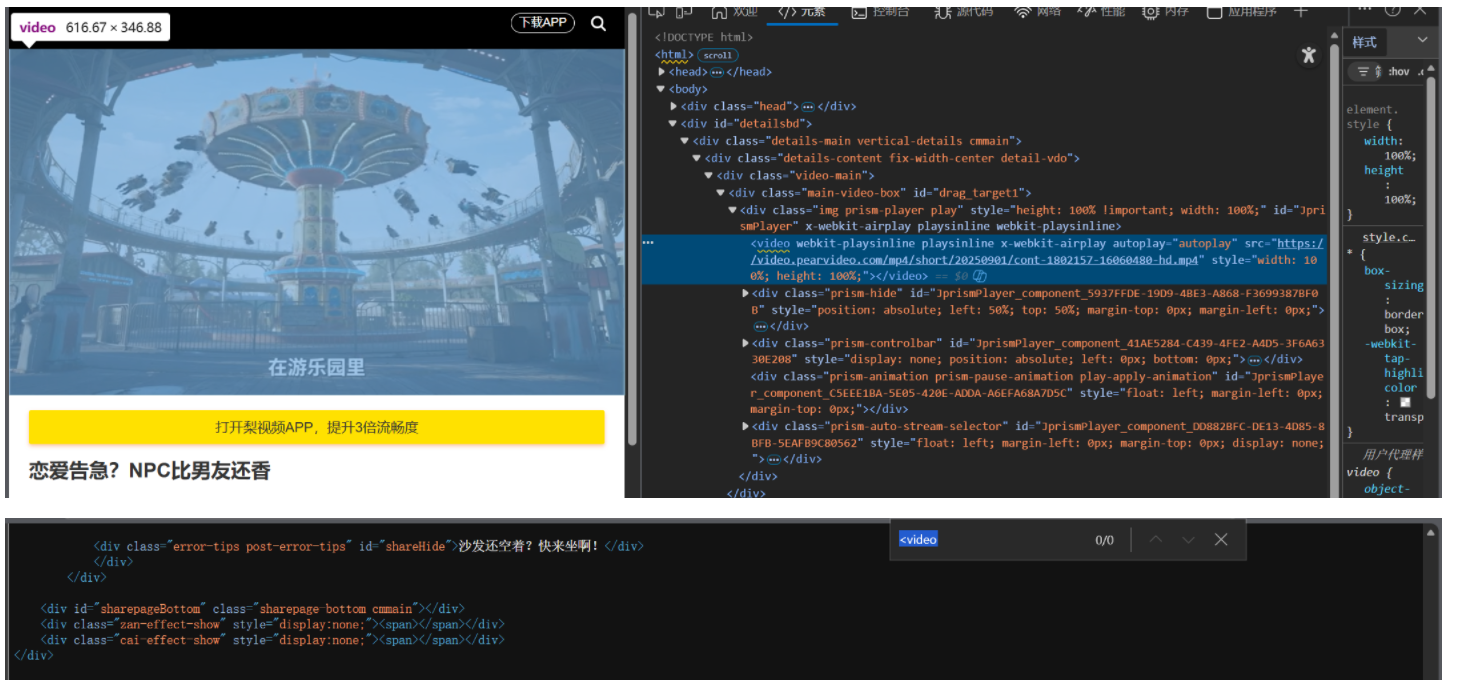

二、通过抓包工具找到js异步接口
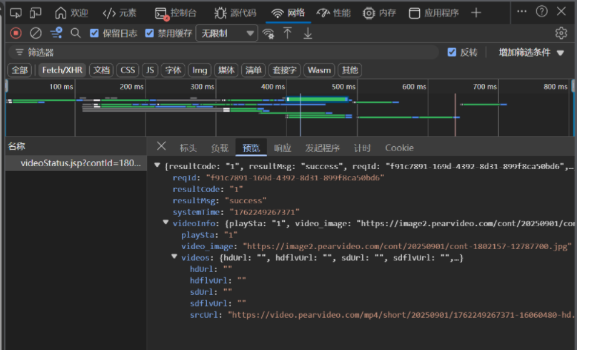 其中的video_image是视频的封面图片地址,而最后的strurl则是视频的链接地址,但是我们可以发现,这个地址是被修改过的,正确的地址应该是video.pearvideo.com/mp4/short/20250901/cont-1802157-16060480-hd.mp4,这是因为服务器接口返回的是 "不完整的视频 URL 片段",需要前端 JavaScript(JS)结合页面中的 "视频 ID"(contId)进行动态拼接,才能生成最终可播放的完整 URL------ 这是视频网站常见的 "反爬 + URL 动态生成" 机制,目的是防止直接通过接口抓取完整视频地址。
其中的video_image是视频的封面图片地址,而最后的strurl则是视频的链接地址,但是我们可以发现,这个地址是被修改过的,正确的地址应该是video.pearvideo.com/mp4/short/20250901/cont-1802157-16060480-hd.mp4,这是因为服务器接口返回的是 "不完整的视频 URL 片段",需要前端 JavaScript(JS)结合页面中的 "视频 ID"(contId)进行动态拼接,才能生成最终可播放的完整 URL------ 这是视频网站常见的 "反爬 + URL 动态生成" 机制,目的是防止直接通过接口抓取完整视频地址。
import requests
#因为li视频的视频地址是动态的,需要根据contID来构造
url="https://www.pearvideo.com/video_1802157"
contID=url.split("_")[-1]
videourl=f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=0.6347927921664064"三、通过js异步接口爬取视频链接的 "核心逻辑代码"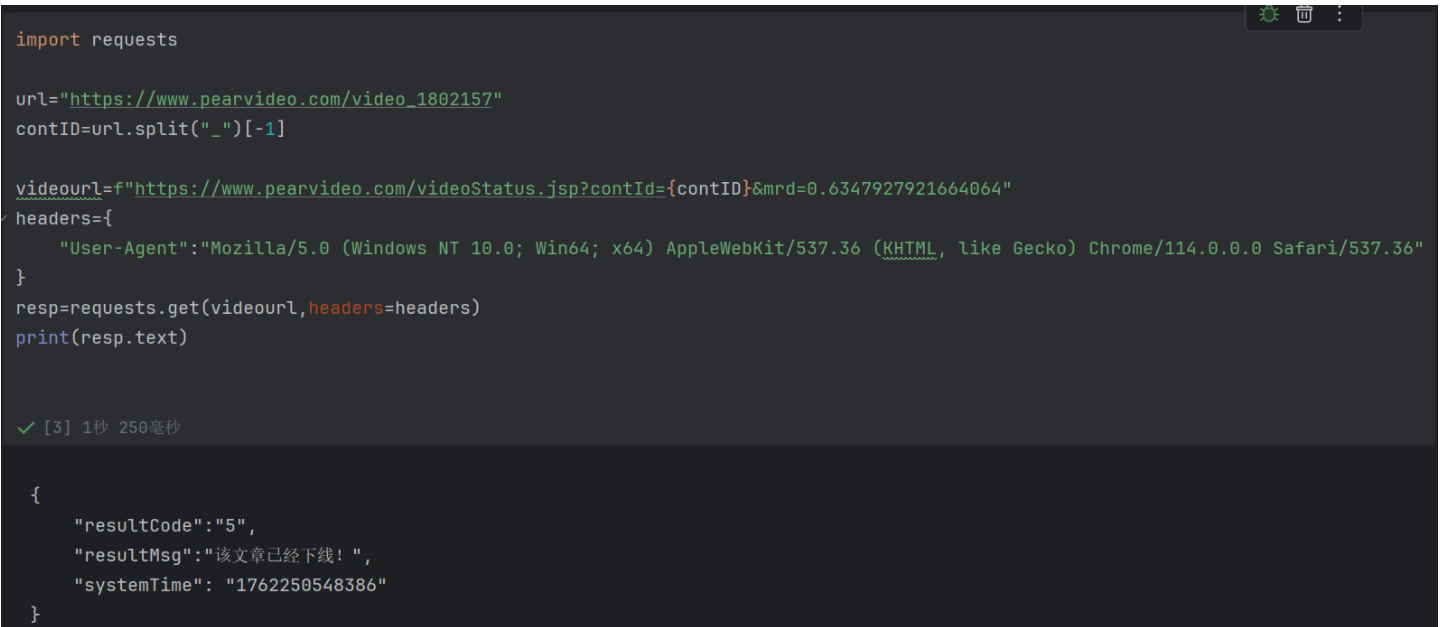
但因为缺少关键请求头(Referer),目前被服务器的防盗链机制拦截了。所以需要结合防盗链机制 和Referer 的验证作用来分析。
li视频的 videoStatus.jsp 接口(用于获取视频真实地址)设置了Referer 校验 ,属于 "防盗链" 的一种变形 ------防止外部爬虫 / 网站直接调用该接口,仅允许 "从li视频自身页面发起的请求" 访问。
-
当你不添加
Referer时,服务器会认为这个请求是 "外部非法调用"(比如来自爬虫脚本、其他网站的接口请求),于是返回 "该文章已经下线" 的虚假提示(实际是反爬拦截); -
当你添加
Referer并设置为视频的原始页面(https://www.pearvideo.com/video_1802157)时,服务器会认为这个请求是 "用户从li视频页面正常点击发起的",从而返回真实的视频信息。
Referer 在这里的 "角色":
Referer 是请求头的核心字段之一,作用是告诉服务器 "当前请求是从哪个页面跳转 / 发起的"。
在这个案例中,li视频通过 Referer 做了以下验证:
-
服务器检查请求的
Referer是否以https://www.pearvideo.com/开头(即请求是否来自li视频自身的页面); -
只有通过这个校验,才会返回真实的视频数据;否则直接拦截(返回虚假的 "文章下线" 提示)。
这里的机制属于接口级别的防盗链(防止接口被外部盗用),和之前讲的 "资源防盗链"(防止图片 / 视频被外部引用)逻辑一致,只是保护的对象从 "静态资源" 变成了 "接口数据"。
-
防盗链的目的:限制只有 "合法来源"(自己的页面 / 域名)才能访问资源 / 接口;
-
Referer 的作用 :作为 "合法来源" 的验证凭证,让服务器判断请求是否来自允许的页面。
这样修改后,服务器会认为请求是 "从li视频自身页面发起的",从而返回真实的视频信息,绕过接口的防盗链拦截。
四、添加referer请求头,告诉服务器 "当前请求是从哪个页面跳转 / 发起的",就可以爬取视频链接所在异步接口的内容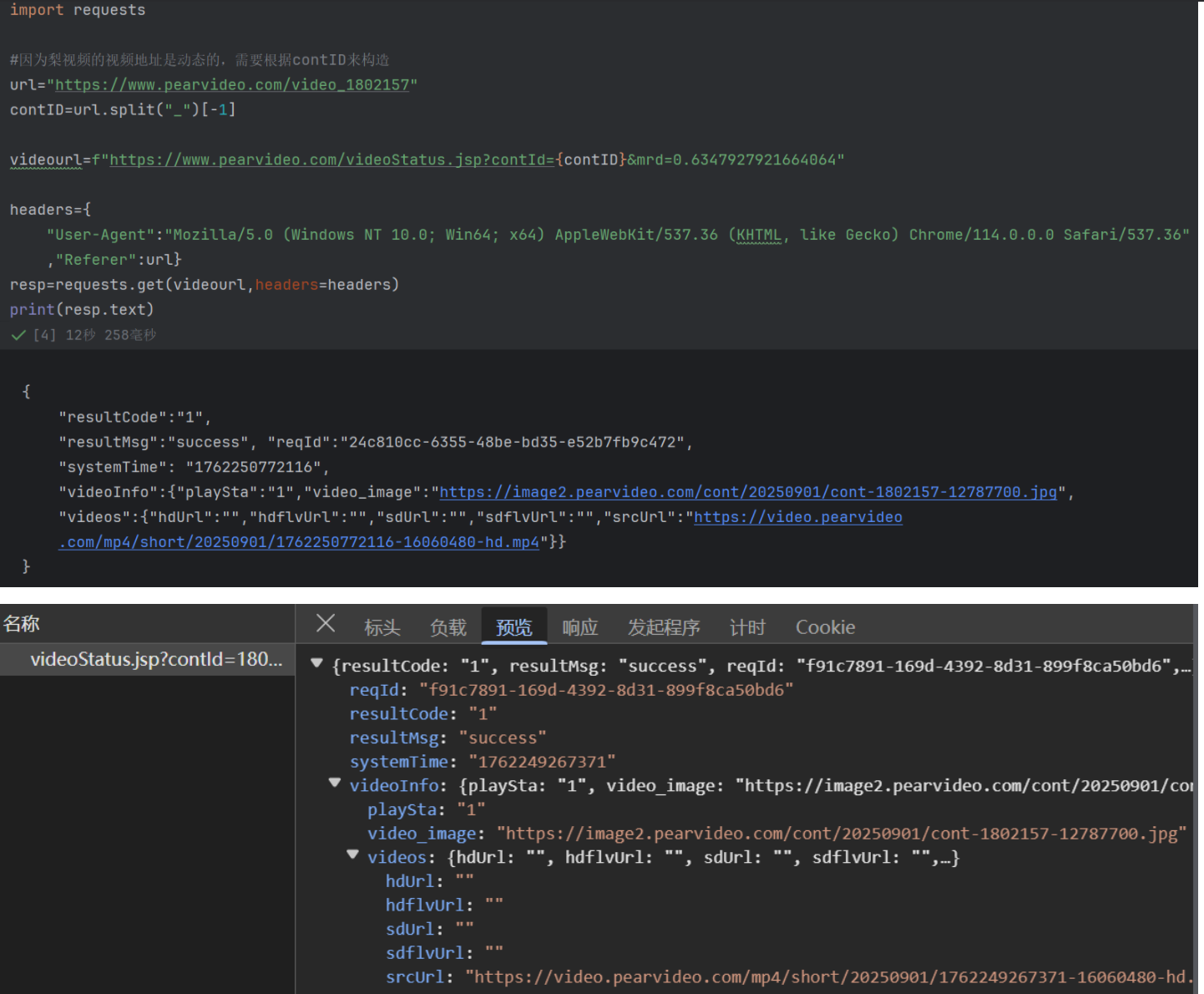
其中,Referer 大多数情况下确实是 "上一级链接的网址"(即发起当前请求的 "来源页面 URL")
五、替换 "不完整的视频 URL 片段",前端 JavaScript(JS)结合页面中的 "视频 ID"(contId)进行动态拼接,生成最终完整 URL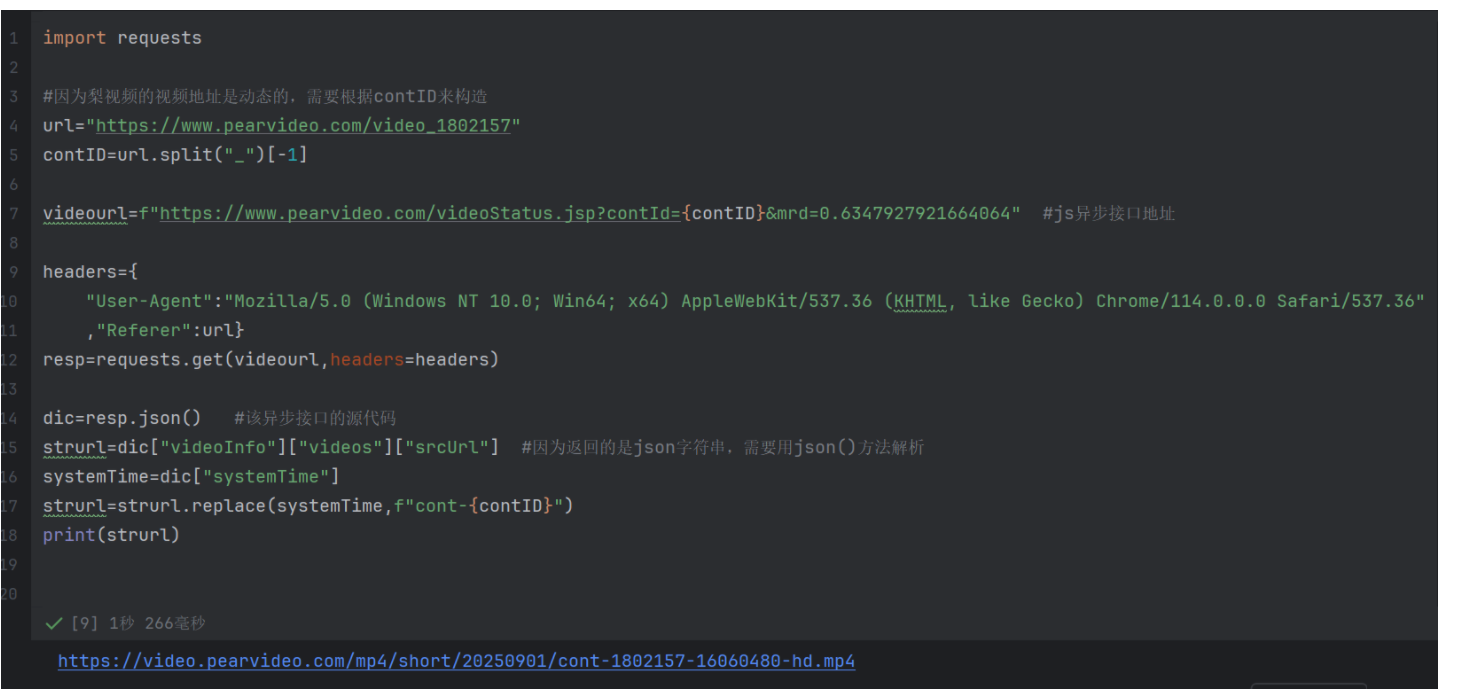
所以最后的video.pearvideo.com/mp4/short/20250901/cont-1802157-16060480-hd.mp4便是完整的URL
六、下载视频
最后也是爬取成功
七:总结
整体过程可以概况成下面步骤:
一、找到需要爬取的视频,发现是动态渲染,刷新页面,在抓包工具网络XHR中找到视频加载的js异步接口
二、通过这个异步工具的网址来爬取这个接口的源代码(还需添加referer来绕过防盗链拦截),在其中找到被替换的"虚假URL",使用contID来替换便是真正的URL
三、找到真正的视频URL后,便可以下载视频了
完整代码:
import requests
#因为;li视频的视频地址是动态的,需要根据contID来构造
url="https://www.pearvideo.com/video_1802157"
contID=url.split("_")[-1]
videourl=f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=0.6347927921664064" #js异步接口地址
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
,"Referer":url} #添加referer来绕过防盗链拦截,告诉服务器 “当前请求是从哪个页面跳转 / 发起的”
resp=requests.get(videourl,headers=headers) #发送get请求,获取异步接口的源代码
dic=resp.json() #该异步接口的源代码
strurl=dic["videoInfo"]["videos"]["srcUrl"] #因为返回的是json字符串,需要用json()方法解析
systemTime=dic["systemTime"]
strurl=strurl.replace(systemTime,f"cont-{contID}")
#下载视频
with open("video.mp4","wb") as f: #wb表示二进制写入模式,因为视频是二进制数据,所以需要用二进制写入模式
f.write(requests.get(strurl,headers=headers).content) #content属性表示响应的二进制数据,需要用content属性来获取二进制数据