我正在开发的一个.net sql拼写工具,当然也可以算是ORM
本工具的作用就是帮忙码农拼写sql,对标开源项目SqlKata。
本工具最大的特点就是性能好,省内存,拼接sql从头到尾只使用一个StringBuilder。
支持多种数据库,也可以自定义数据库方言,支持net7.0;net8.0;net9.0;netstandard2.0;netstandard2.1,支持跨平台。
本工具最适合搭配Dapper使用,所以附带了一个Dapper扩展。当然直接搭配ado.net也是可以的。
sql操作用的最多也是最复杂的是查询,本工具包含两套查询模式:sql模式和逻辑模式。
一、先介绍sql查询模式
1、支持按原生sql进行查询,示例如下:
var query = db.From("Users")
.ToSqlQuery()
.Where("Id=@Id", "Status=@Status");2、支持按逻辑查询
var query = new UserTable()
.ToSqlQuery()
.Where(Id.EqualValue(100));3、支持GroupBy
var table = db.From("Users");
var groupBy = table.ToSqlQuery()
.ColumnEqualValue("Age", 20)
.GroupBy("CityId")
.Having(g => g.Aggregate("MAX", "Level").GreaterValue(9));4、支持联表
var employees = db.From("Employees");
var departments = db.From("Departments");
var joinOn = employees.SqlJoin(departments)
.On(static (t1, t2) => t1.Field("DepartmentId").Equal(t2.Field("Id")));
var joinTable = joinOn.Root
.Where(join => join.From("t2").Field("Manager").EqualValue("CEO"));二、逻辑模式
以上功能逻辑模式都支持,逻辑模式是按And、Or来查询的。没有where、having、on等关键字
逻辑模式一般执行速度更快、内存消耗更少
1、单表查询
var query = db.From("Users")
.ToQuery()
.And(_id.Equal())
.And(_status.Equal("Status")); var query = db.From("Users")
.ToOrQuery()
.Or(_id.Equal())
.Or(_status.Equal("Status"));2、GroupBy
var groupBy = table.ToQuery()
.And(Age.EqualValue(20))
.GroupBy("CityId")
.And(Level.Max().GreaterValue(9));3、联表
CommentTable c = new("c");
PostTable p = new("p");
var joinOn = c.Join(p)
.And(c.PostId.Equal(p.Id));
var query = joinOn.Root
.And(c.Pick.Equal())
.And(p.Author.Equal())篇幅有限,还有很多功能没法在这里一一列举,欢迎大家去探索。
三、两种模式与SqlKata对比速度都更快,消耗内存也更少
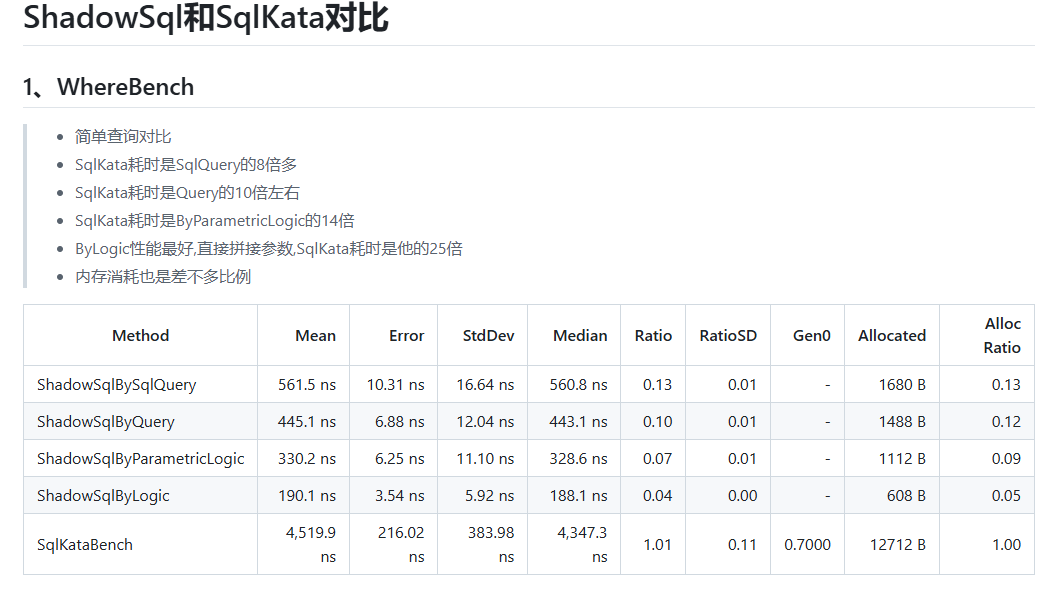
更多信息可以到github上查询,或下载代码自己测试一下
四、源码托管在github上
仓库地址: https://github.com/donetsoftwork/Shadow
如果大家喜欢请动动您发财的小手手帮忙点一下Star。
有什么建议也可以反馈给我,该项目还在开发中,还可能会增加更多有趣的功能。
而且我还计划为这个工具再开发一个精简版本,以求更好的性能。