前言
最近在看一本《ChatGLM3大模型本地化部署、应用开发和微调》,本文就是讨论ChatGLM3在本地的初步布设。(模型文件来自魔塔社区)
1、建立Pycharm工程
采用的Python版本为3.11
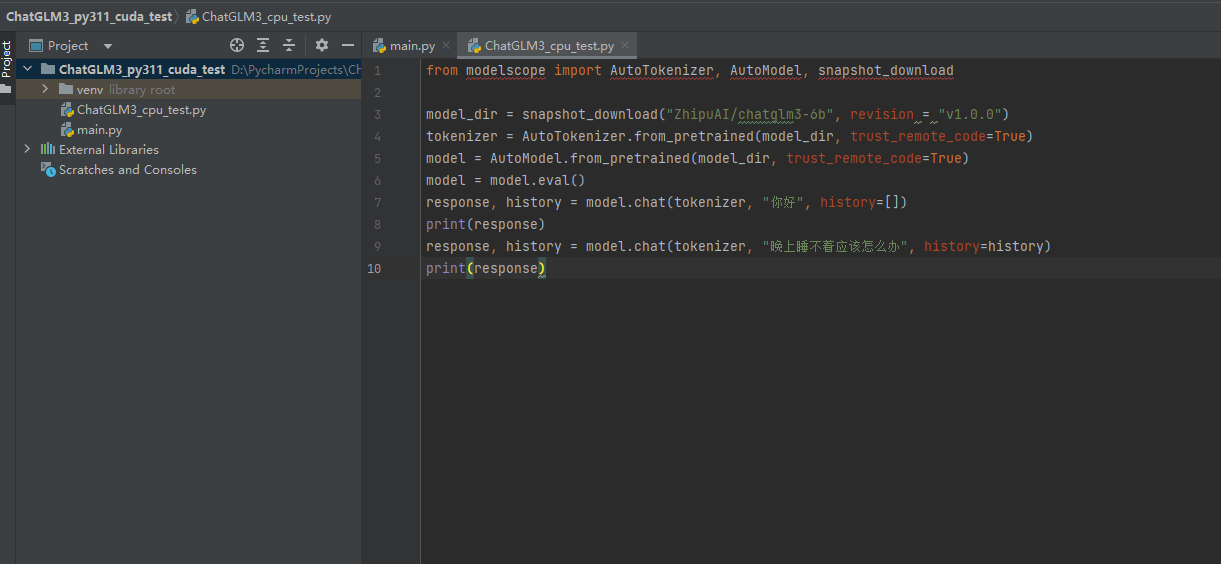
2、安装对应的包
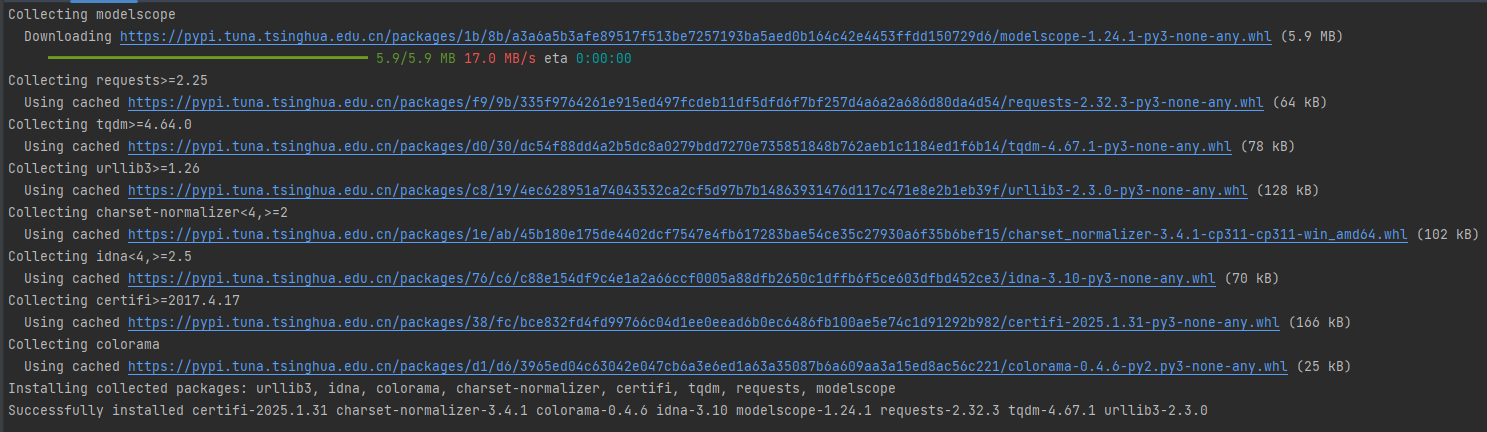
2.1、安装modelscope包
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
如下图:
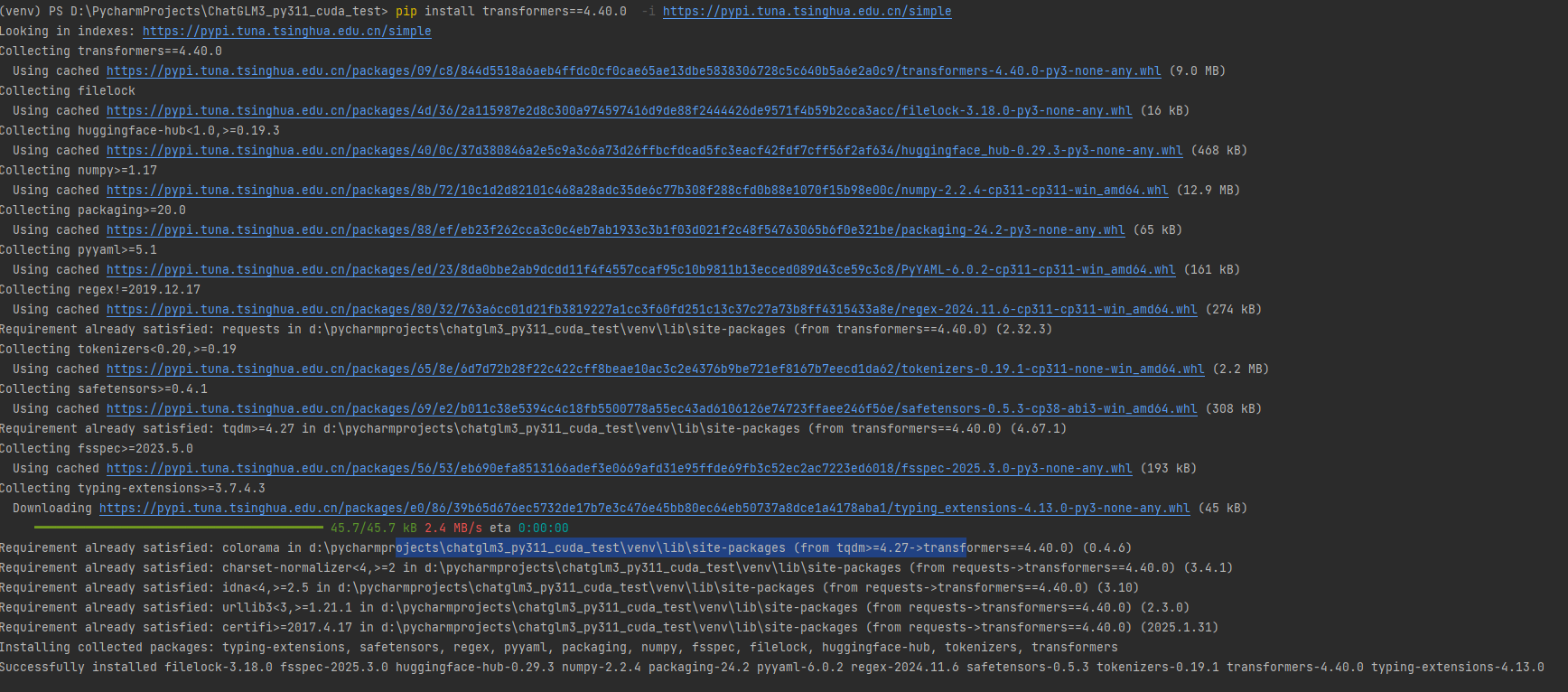
2.2、安装transformers包
pip install transformers==4.40.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
如下图:
2.3、安装cuda版本的Pytorch
可以参照我的另外一篇博客:
https://quickrubber.blog.csdn.net/article/details/145824058
包的安装顺序:
pip install sympy==1.13.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install networkx==3.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mkl==2021.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "f:\pytorch_\torch-2.3.1+cu121-cp311-cp311-win_amd64.whl"
pip install sentencepiece -i https://pypi.tuna.tsinghua.edu.cn/simple
2.4、包安装完毕后的版本截图

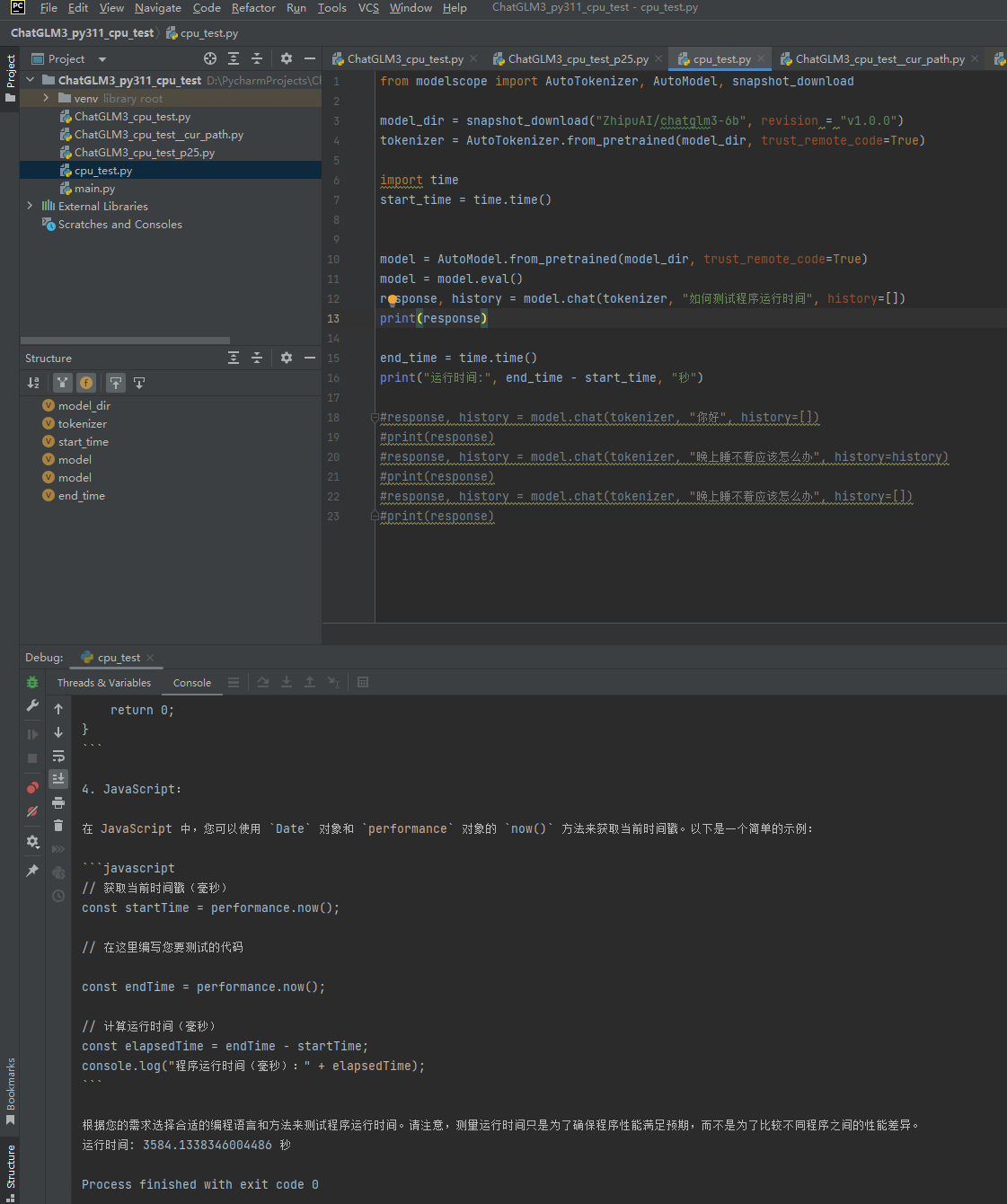
3、Cpu版本和Cuda版本程序的运行比较
3.1、cpu版本的程序运行
3.2、cuda版本的程序运行

可见相同的情况之下,二者的速度差距还是有点大的。Cuda大概是cpu的14倍左右。
本机使用的配置是cpu是intel i9-9900K,显卡Nvidia Gerforce2080。