前言
智能体(Agent)是人工智能中的核心概念之一,它广泛应用于游戏AI、机器人、自动驾驶、智能客服等领域。本篇博客将从智能体的基本概念、核心架构、开发工具,以及简单的智能体实现入手,为想要入门智能体开发的读者提供清晰的指导。
1. 什么是智能体?
1.1 智能体的定义
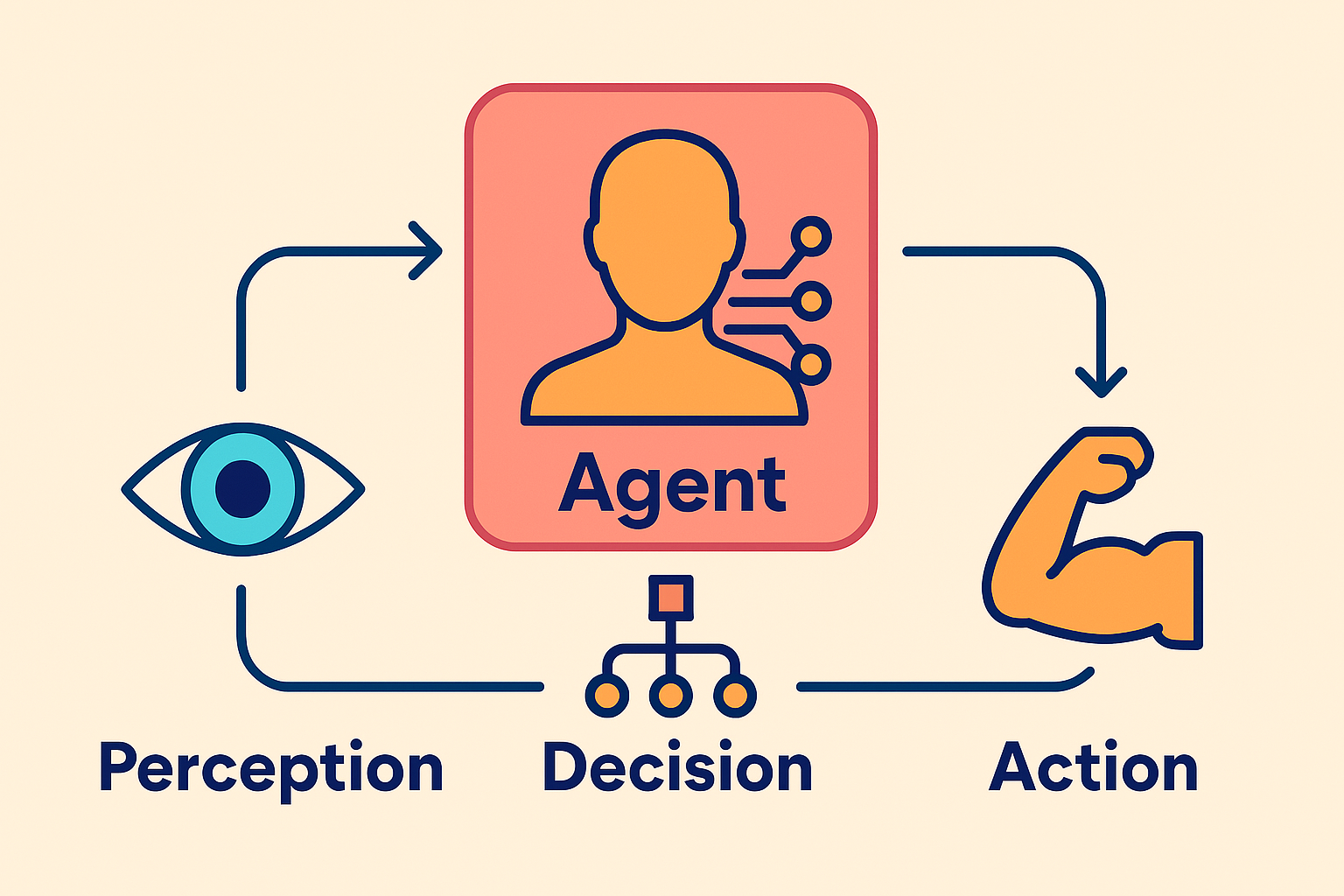
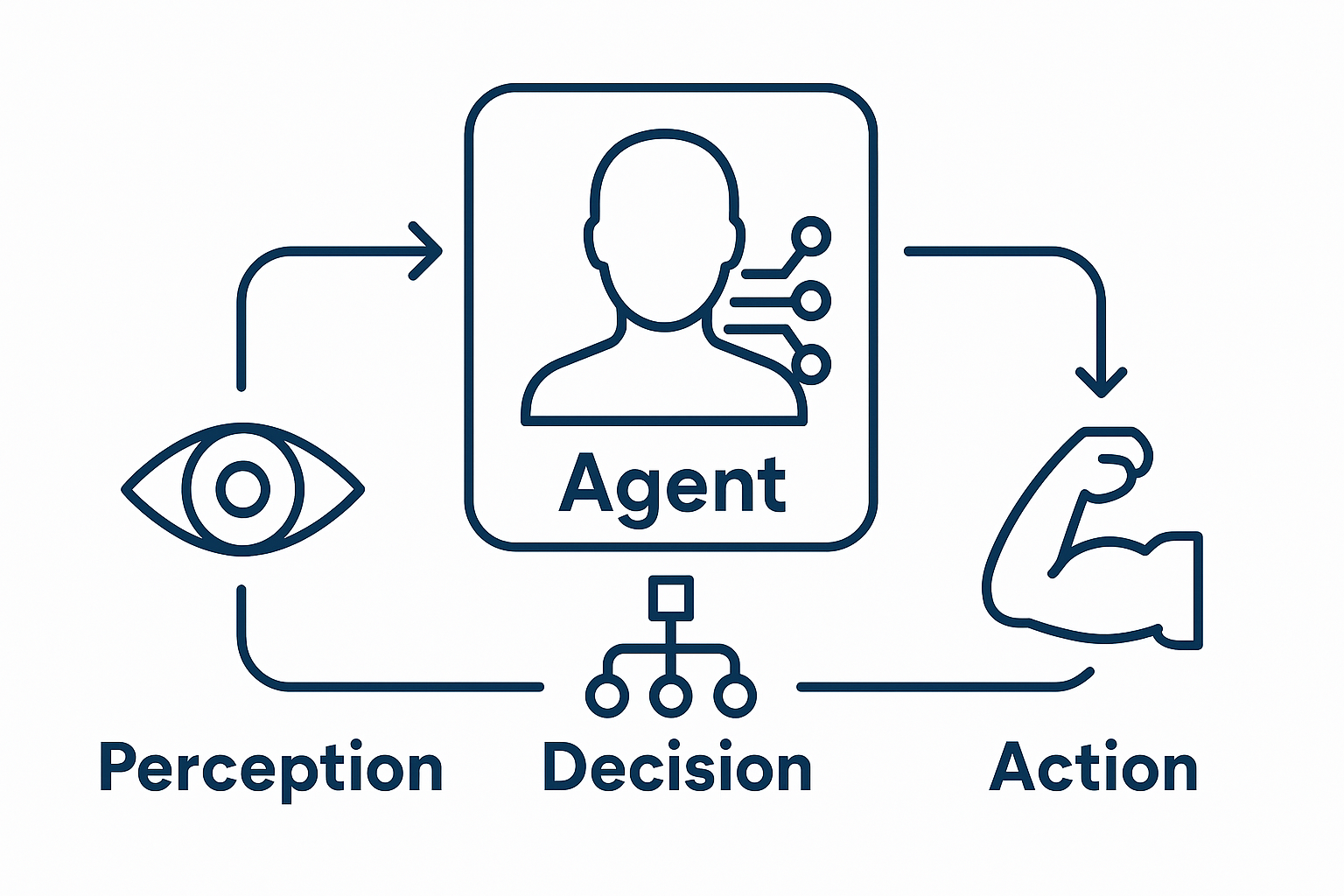
智能体(Agent)是一个能够感知环境(Perception)、做出决策(Decision),并执行动作(Action)以影响环境的自主系统。一个智能体通常具有以下特性:
-
自主性(Autonomy):能够独立感知和决策,而不需要外部干预。
-
交互性(Interactivity):可以与环境或其他智能体进行交互。
-
目标导向性(Goal-Oriented):通常围绕某个任务或目标进行行为优化。
-
适应性(Adaptability):能够根据环境变化调整自身行为。
1.2 智能体的分类
智能体可以按照不同的维度进行分类:
-
按决策方式分类
-
基于规则的智能体(Rule-Based Agent):按照预定义的规则执行任务,例如状态机(FSM)。
-
基于学习的智能体(Learning-Based Agent):利用机器学习或强化学习来优化自身策略,如DQN、PPO等。
-
自主智能体(Autonomous Agent):能够独立学习并适应复杂环境,如自动驾驶智能体。
-
-
按智能程度分类
-
反应型智能体(Reactive Agent):仅根据当前感知信息做决策,如游戏中的简单NPC。
-
带有记忆的智能体(Deliberative Agent):能够记住过去的信息,并基于历史数据做出更复杂的决策。
-
混合型智能体(Hybrid Agent):结合反应型和记忆型智能体的优点,常用于高级AI系统。
-
-
按环境交互方式分类
-
单智能体(Single-Agent):独立运行的智能体,如自动化交易系统。
-
多智能体系统(Multi-Agent System, MAS):多个智能体协同或竞争,如无人机编队、游戏AI对抗。
-
2. 智能体的基本架构
智能体开发涉及感知-决策-执行(Perception-Decision-Action)循环,核心架构可以分为以下几类:
2.1 感知-行动(Perception-Action)架构
-
直接将感知到的环境状态映射到行动,不进行复杂的决策过程。
-
适用于简单任务,如基于传感器的机器人控制。
示例:
python
class SimpleAgent:
def __init__(self):
self.state = "searching"
def perceive(self, environment):
return environment.get_state()
def act(self, perception):
if perception == "food_found":
return "eat"
return "search"
environment = {"state": "food_found"}
agent = SimpleAgent()
action = agent.act(agent.perceive(environment))
print(action) # 输出: "eat"2.2 基于规则的智能体(Rule-Based Agent)
-
通过固定规则进行决策,通常使用"如果-那么(IF-THEN)"逻辑。
-
适用于确定性较强的环境,如专家系统或策略游戏AI。
示例:
python
class RuleBasedAgent:
def act(self, perception):
rules = {
"enemy_near": "attack",
"low_health": "retreat",
"ally_near": "support"
}
return rules.get(perception, "patrol")
agent = RuleBasedAgent()
print(agent.act("enemy_near")) # 输出: "attack"2.3 基于模型的智能体(Model-Based Agent)
-
智能体会维护一个内部模型,用于预测环境的未来状态。
-
适用于自动驾驶、机器人导航等复杂决策任务。
2.4 机器学习驱动的智能体(Learning-Based Agent)
-
通过强化学习、监督学习等方法,使智能体能够自主优化决策策略。
-
适用于复杂环境,如游戏AI、金融智能体。
示例(强化学习智能体框架):
python
import random
class RLAgent:
def __init__(self):
self.q_table = {} # 状态-动作值函数
def choose_action(self, state):
return random.choice(["move_left", "move_right", "jump"]) # 随机选择动作
def learn(self, state, action, reward):
self.q_table[(state, action)] = reward # 简单Q-learning示例
agent = RLAgent()
print(agent.choose_action("on_ground")) # 随机输出: "move_left" 或 "move_right" 或 "jump"3. 智能体开发工具和框架
智能体的开发通常依赖于一些强大的工具和框架,以下是几个常用的智能体开发框架:
3.1 OpenAI Gym
-
用于训练和测试强化学习智能体的标准环境库。
-
提供各种环境,如CartPole(平衡杆)、Atari游戏、机器人控制等。
3.2 Unity ML-Agents
-
适用于游戏AI、3D环境下的智能体训练。
-
支持强化学习、监督学习等多种训练方式。
3.3 ROS(机器人操作系统)
- 适用于机器人智能体开发,如无人车、自主无人机等。
3.4 TensorFlow/PyTorch
- 用于构建和训练神经网络驱动的智能体。
4. 轻量级智能体示例
我们使用 OpenAI Gym 来构建一个简单的强化学习智能体:
python
import gym
env = gym.make("CartPole-v1") # 选择环境
state = env.reset()
for _ in range(1000):
env.render() # 渲染环境
action = env.action_space.sample() # 随机选择动作
state, reward, done, _, _ = env.step(action)
if done:
break
env.close()在这个示例中,智能体在 CartPole 环境中随机选择动作,并尝试保持平衡。进一步优化可以使用强化学习算法(如DQN)。
5. 结论
智能体开发是人工智能的重要组成部分,涉及 感知-决策-执行 机制。根据不同需求,可以选择 基于规则、基于模型、基于学习 的方法来开发智能体。掌握 OpenAI Gym、Unity ML-Agents、强化学习算法 等工具,可以帮助开发更高级的智能体。
下一步学习方向
-
进一步探索 强化学习(RL),如DQN、PPO等算法。
-
学习 多智能体系统(MAS),如智能体协作与竞争。
-
研究 大模型(LLM)驱动的智能体,如基于GPT的对话智能体。