1 MySQL InnoDB对隔离级别的支持
|---------------------------|---------|---------|----------------|
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 未提交读 (Read Uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read Committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable Read) | 不可能 | 不可能 | 对InnoDB不可能 |
| 串行化(Serialiable) | 不可能 | 不可能 | 不可能 |
InnoDB支持的四个隔离级别和SQL92定义的完全一致,隔离级别越高,事务的并发度越低。唯一的区别就在于,InnoDB在PR的级别就解决了幻读的问题。
也就是说,不需要使用串行化的隔离级别去解决所有问题,既保证了数据的一致性,又支持了越高的并发度。这个就是InnnoDB默认使用的RP作为事务隔离级别的原因。
2 两大实现方案
如果要解决读一致性的问题,也就是保证在一个事务中两次读取数据的结果要保持一致,实现数据的隔离;对于这个一种是基于锁来控制数据的修改、另一个基于MVCC快照读的方式保证读一致性
2.1 LBCC
第一种,既然要保证前后两次读取数据一致,那么在读数据的时候,要锁定当前需要操作的数据,不允许其他的事务的修改就行了。这种方案我们叫做基于锁的并发控制Lock Based Concurrency Control (LBCC)。
如果仅仅是基于锁来实现事务隔离级别,一个事务读取的时候不需要其他事务的修改,那就意味着不支持并发的读写操作,而我们的大多数应用都是读多写少的,这样会极大地影响操作数据的效率。
2.2 MVCC
如果一个事务前后两次读取到额数据保持一致,那么我们可以在修改数据之前给它建立一个备份或者叫快照,后面再来读取这个快照就行。这种方案我们叫做多版本并发控制(Multi Version Concurrency Control MVCC)。
MVCC的原则:
一个事务能看到的数据版本:
1、第一次查询之前已经提交的事务的修改
2、本事务的修改
一个事务部能看见的数据版本:
1、在本事务第一次查询之后创建的事务(事务ID比我的事务ID大)
2、活跃的(未提交)事务的修改
MVCC的效果:我们可以查询到这个事务开始之前已经存在的数据,即使它在后面被修改或者删除了,而在我这个事务时候新增的数据,我们是查不到的。
所以我们才把这种叫做快照,不管别的事务做任何增删改查的操作,它只能看到第一次查询时看到的数据版本。
问题: 这个快照是怎么实现的?会不会占用额外存储空间?
InnoDB的事务是有编号的,而且会不断递增,InnoDB为每行记录都实现了两个隐藏字段:
DB_TRX_ID :6字节:事务ID ,表明数据是在哪个事务插入或者修改为新数据的,就记录为当前事务ID。
DB_ROLL_PTR ,7字节:回滚指针 (我们可以把它理解为删除版本号,数据被删除或记录为旧数据的时候,记录当前事务ID,没有修改或者删除的时候是空)
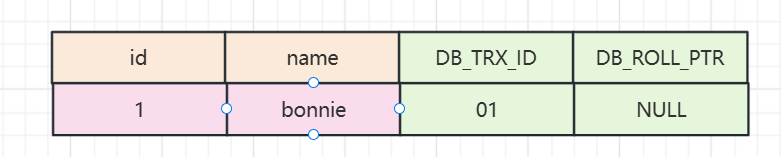
第一次初始化数据:
Transaction1:
begin;
insert into mvcctest values(NULL, 'bonnie');
insert into mvcctest values(NULL, 'hello');
commit;此时的数据,创建版本是当前事务ID,假设事务编号是1, 删除版本为空

第二个事务,执行第1次查询,读取到两条原始数据,这个时候事务ID是2:
Transaction 2:
begin;
select * from mvcctest;第三个事务插入数据:
begin;
insert into mvcctest values(NULL, 'world');
commit;这个时候数据库的数据大致如下:
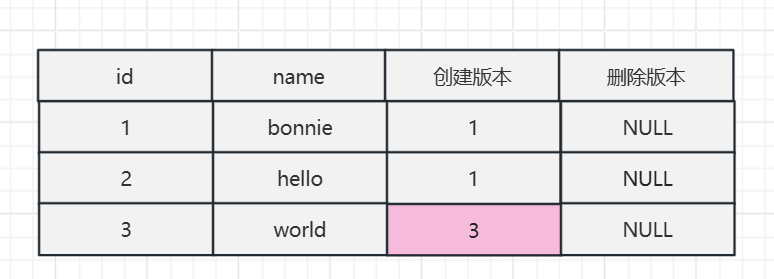
第二个事务,执行第2次查询:
begin;
select * from mvcctest;MVCC的查找规则:只能查找到创建时间小于等于当前事务ID的数据,和删除时间大于当前事务ID的行(或未删除)。
也就是不能查到在我的事务开始之后插入的数据,world的创建ID大于2,所以还是只能查到两条数据。
第四个事务,删除数据,删除了id=2 hello这条数据
begin;
delete from mvcctest where id=2;此时的数据,hello的删除版本被记录为当前事务ID, 4,其他数据不变
在第二个事务中,执行第3次查询: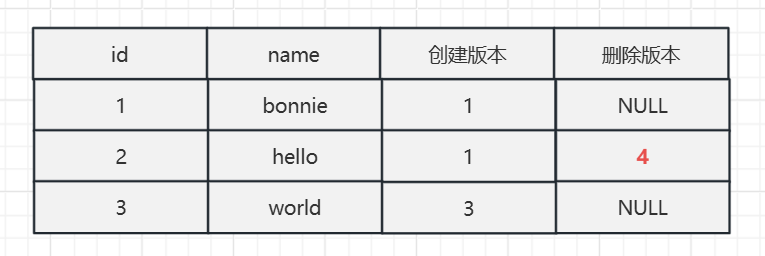
begin;
select * from mvcctest;查找规则:只能查找创建时间小于等于当前事务ID的数据,和删除时间大于等于当前事务ID的行(或未删除)
也就是,在事务开始之后删除的数据,所以hello依然可以查出来,所以还是这两条数据。
第5个事务,执行更新操作,这个事务ID是5:
begin;
update mvcctest set name="bonnie_1215" where id =1;
commit;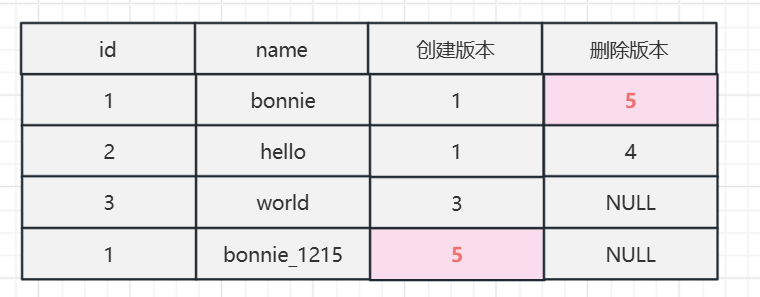
第二个事务,第4次执行:
begin;
select * from mvcctest;查找规则: 只能查找创建时间小于等于当前事务ID的数据,和删除时间大于当前事务ID的行(或未删除)。
因为更新后的数据bonnie_1215创建版本大于2,代表是在事务时候增加的,查不出来。
而旧数据bonnie的删除版本大于2,代表是在事务时候删除的,可以查出来。
通过上面的案例,我们能看到通过版本号的控制,无论其他事务是插入、修改、删除第一个事务查询到的数据都没有变化。
这个是MVVV的效果,当然,这里是一个简化的模型。
假设一条数据修改了3次,两次提交了一次未提交。每次修改之后都有开启一个事务去查询,那么事务2、4、6查到的数据会不一样。
|--------|-------------------------------------------------------------|
| trx_id | SQL |
| trx1 | update mvcctest set name='bonnie' where id = 1; commit; |
| trx2 | select * from mvcctest where id=1; |
| trx3 | update mvcctest set name='bonnie1215' where id = 1; commit; |
| trx4 | select * from mvcctest where id=1; |
| trx5 | update mvcctest set name='bonnie1215-151' where id = 1; 未提交 |
| trx6 | select * from mvcctest where id=1; |
| | trx2 4 6各查一次 |
InnoDB 中,一条数据的旧版本,是存放在哪里的呢?undolog。因为修改了多次,这些 undo log 会形成一个链条,叫做 undo log 链,现在 undo log 里面有刘德华、吴彦祖、盆鱼宴。
所以前面我们说的 DB ROLL PTR,它其实就是指向 undo log 链的指针。
第二个问题,事务 2、4、6最后再査一次,它们去 undo log 链找数据的时候,拿到的数据是不一样的。在这个 undo log 链里面,一个事务怎么判断哪个版本的数据是它应该读取的呢?
回想一下 MVCC 规则:
一个事务能看到的数据版本:
1、第一次查询之前已经提交的事务的修改
2、本事务的修改
一个事务不能看见的数据版本:
1、在本事务第一次查询之后创建的事务(事务 ID 比我的事务 ID 大)
2、活跃的(未提交的)事务的修改
所以,我们必须要有一个数据结构,把本事务ID、活跃事务ID、当前系统最大事务ID 存起来,这样才能实现判断。这个数据结构就叫 Read View(可见性视图),每个事务都维护一个自己的Read View.
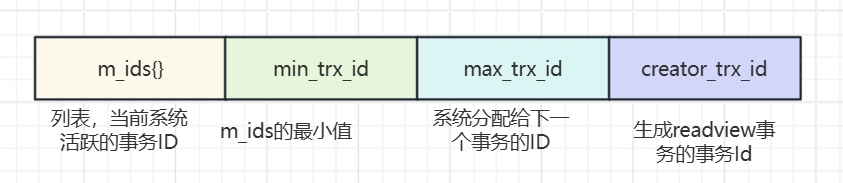 m_ids: 表示在生成 ReadView 时当前系统中活跃的读写事务的事务 id 列表。
m_ids: 表示在生成 ReadView 时当前系统中活跃的读写事务的事务 id 列表。
min_trx _id: 表示在生成 ReadView 时当前系统中活跃的读写事务中最小的事务 id也就是 m_ids 中的最小值。
max_trx_id: 表示生成 ReadView 时系统中应该分配给下一个事务的 id 值。
creator_trx_id: 表示生成该 ReadView 的事务的事务 id。有了这个数据结构以后,事务判断可见性的规则是这样的:
0、从数据的最早版本开始判断(undolog)
1、数据版本的 trx_id =creator_trx_id,本事务修改,可以访问
2、数据版本的 trx_id<min_trx_id(未提交事务的最小ID),说明这个版本在生成 ReadView 已经提交,可以访问
3、数据版本的 trx_id >max_trx_id(下一个事务ID),这个版本是生成 ReadView之后才开启的事务建立的,不能访问
4、数据版本的 trx_id 在 min_trx_ id 和 max_trx_id 之间,看看是否在 m_ids 中。
如果在,不可以。如果不在,可以。
5、如果当前版本不可见,就找 undo log 链中的下一个版本。
RR 中 Read View 是事务第一次査询的时候建立的。RC的 Read View 是事务每次查询的时候建立的。