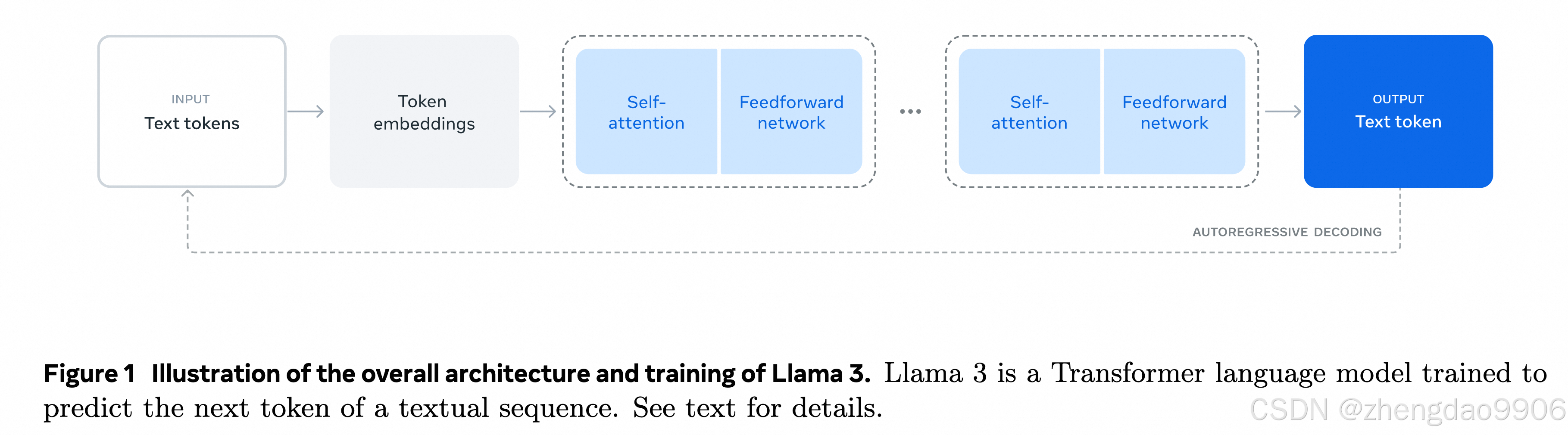
Llama 3中的顶级模型是一个拥有4050亿参数的密集Transformer模型,并且它的上下文窗口长度可以达到128,000个tokens。这意味着它能够处理非常长的文本,记住和理解更多的信息。Llama 3.1的论文长达92页,详细描述了模型的开发阶段、优化策略、模型架构、性能比较、新功能等。

pre-train(预训练阶段)
训练的两个阶段,第一个阶段是预训练做词语预测或者文章总结;第二个阶段是后训练用来做模型的微调,或者是人类偏好对齐。
pre-train(预训练阶段)
模型的预训练分多阶段,第一个阶段是初始化的预训练,第二阶段是长上下文预训练,第三阶段是退火模拟。
初始化
● 模型在训练的初始阶段,学习率从一个较低的值逐渐增加(称为线性预热)
● 为了提高训练的稳定性,在训练初期使用较小的批次大小。在训练过程中,为了提高效率,逐步增大批次大小。
● 增加非英语数据、数学数据、网络数据减少了那些在训练过程中被识别为低质量的数据子集(交叉熵自动计算&人工标注网站)。
长序列训练
● 目标:最终的预训练目标是让模型能够处理长达128K(128,000)个tokens的上下文序列。
● 逐步增加上下文长度:为了让模型逐渐适应更长的上下文长度,预训练过程中按阶段逐步增加序列长度。每个阶段会先让模型在新的序列长度下进行预训练,直到模型适应这个新的长度。
● 成功适应的评估:模型能够完美解决在这个长度下的"needle in a haystack"(大海捞针)任务。这种任务是指在很长的文本中找到特定的信息或答案。
● 最后阶段的长序列预训练使用了大约8000亿(800B)个训练tokens。
模拟退火
● 预训练过程的最后阶段:在预训练的最后阶段,使用了 4000 万个文本标记(tokens)来训练模型。
● 学习率(模型在每次迭代中调整其参数的速度)被线性下降到 0。也就是说,训练开始时学习率较高,然后逐渐降低,直到最后完全停止调整。
● 模型检查点的平均:在学习率逐渐降低的过程中,使用了一种叫做"Polyak 平均"的方法(根据 Polyak 在 1991 年提出的方法)。这意味着,取了多个时间点的模型参数的平均值,来得到一个更稳定、性能更好的最终模型。(模型)
post-train(后训练阶段)
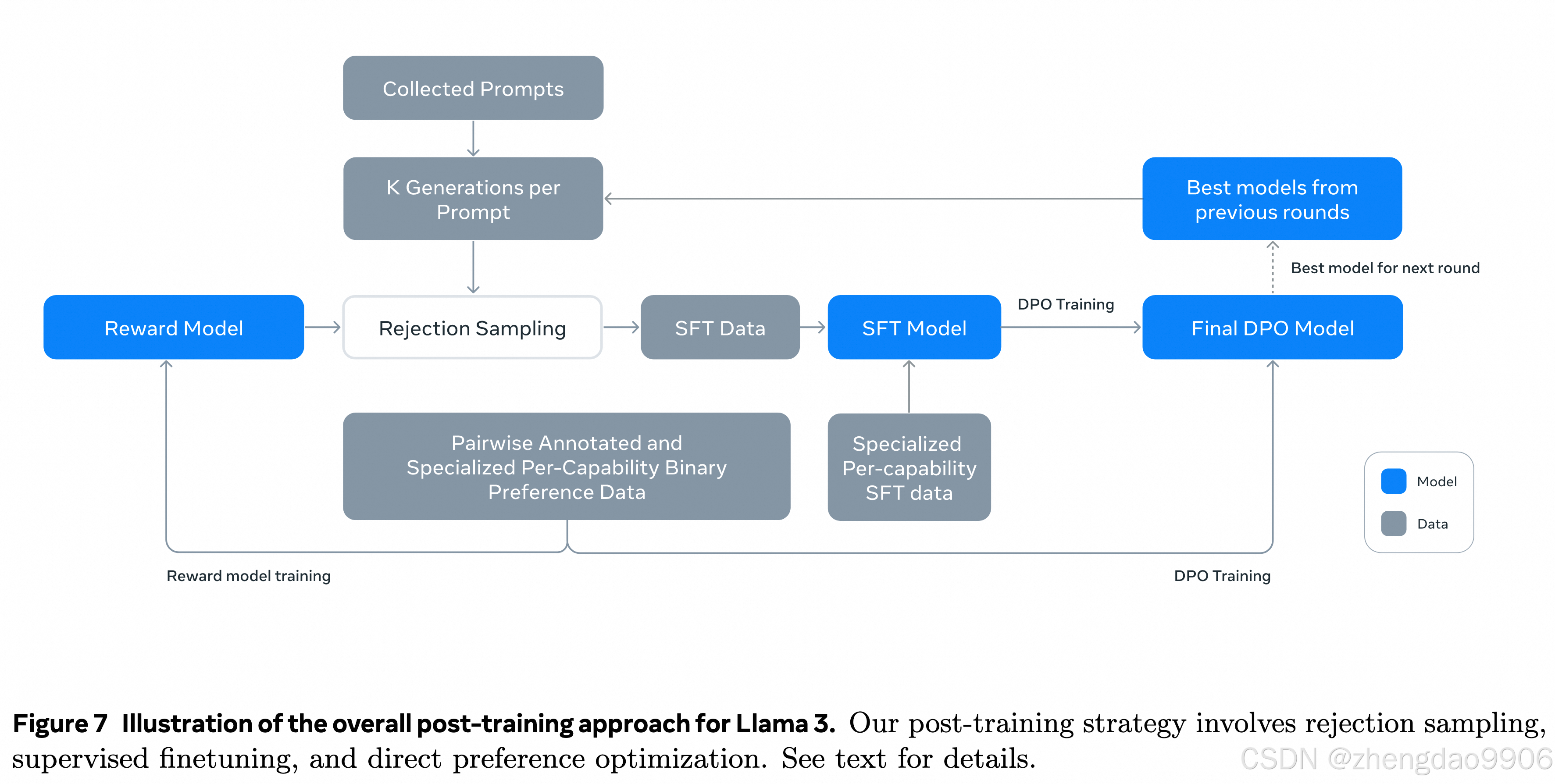
核心策略是奖励模型和语言模型。
奖励模型:这个模型的目的是帮助评估生成的文本是否符合人类的偏好。它基于预训练好的模型,使用人类注释的偏好数据进行训练。
● 训练奖励模型:在预训练好的模型基础上,使用人类注释的偏好数据来训练奖励模型。人类注释的偏好数据是指人类标记哪些生成的文本更符合他们的期望或喜好。
● 有监督微调(SFT):接下来,对预训练好的模型进行有监督微调(SFT),这是利用具体任务的标注数据来进一步训练模型,使其在特定任务上表现更好。Tricks:使用奖励模型进行拒绝采样,提高用于微调的数据质量。
● 直接偏好优化(DPO):最后,使用直接偏好优化(DPO)进一步调整模型。DPO方法通过奖励模型的反馈,直接优化模型生成的文本,使其更符合人类的偏好。
聊天对话协议
● 定义聊天对话协议:为了让模型理解人类的指令并执行对话任务,需要定义一个聊天对话协议。
● 工具使用:与前一代模型相比,Llama 3 拥有新功能,例如工具使用,这可能需要在一个对话轮次内生成多个消息并发送到不同的地方(例如,用户、ipython)。
奖励模型
● 奖励模型的训练:在预训练好的模型基础上训练一个奖励模型,这个模型用于评估和提升模型的各项能力。
● 使用偏好数据:使用所有的偏好数据来训练奖励模型,但会过滤掉那些回应相似的样本。
● 偏好数据的处理:除了标准的偏好对(即chosen, rejected),还为一些提示创建了第三种"edited",这些回应是在选中回应的基础上、人工进一步改进的。因此,每个偏好排序样本会有两到三种回应,且有明确的排序(edited > 即chosen > rejected)。
监督训练
● 使用奖励模型进行拒绝采样:使用之前训练的奖励模型对人工标注的数据进行拒绝采样。这意味着会根据奖励模型的评分来筛选出高质量的回应。
● 监督微调阶段:这一阶段称为监督微调(SFT),尽管很多训练目标是模型生成的。这意味着用高质量的训练数据对模型进行进一步调整,使其性能更好。
直接偏好优化
● DPO:一种优化算法,用于调整模型以更好地符合人类偏好。相比其他算法(如PPO),DPO在大规模模型上的计算需求更少,性能更好,尤其是在遵循指令的基准测试上表现出色。
● 训练数据:使用最新收集的偏好数据,这些数据来自于之前优化轮次中表现最好的模型。这样,训练数据更符合正在优化的策略模型的分布。
实验结果
改进了一些具体的能力,以提升模型的整体表现。
● 代码能力:提升模型理解和生成代码的能力。
● 多语言能力(:让模型能够处理多种语言,而不仅限于一种语言。
● 数学和推理能力:提高模型进行数学计算和逻辑推理的准确性和能力。
● 长上下文处理能力:增强模型处理长文本的能力,使其在面对长篇文章时表现更好。
● 工具使用能力:提升模型使用各种工具和接口的能力。
● 事实性:确保模型提供的信息准确且基于事实。
● 可引导性:增强模型按照用户指令进行操作和回答的能力。
参考文献
arxiv-pdf:https://arxiv.org/pdf/2407.21783v3
llama官方主页:https://llama.meta.com/