用机器学习给深度学习库"体检":大幅提升测试效率的新思路
论文信息
- 原标题:Improving Deep Learning Library Testing with Machine Learning
- 主要作者及机构
- Facundo Molina(马德里康普顿斯大学)
- M M Abid Naziri、Feiran Qin、Marcelo d'Amorim(北卡罗来纳州立大学)
- Alessandra Gorla(马德里IMDEA软件研究所)
- 引文格式(GB/T 7714) Molina F, Naziri M M A, Qin F, et al. Improving Deep Learning Library Testing with Machine LearningC//AST '26: Proceedings of the 2026 ACM SIGSOFT International Symposium on Software Testing and Analysis. Rio de Janeiro: ACM Press, 2026.
1. 一段话总结
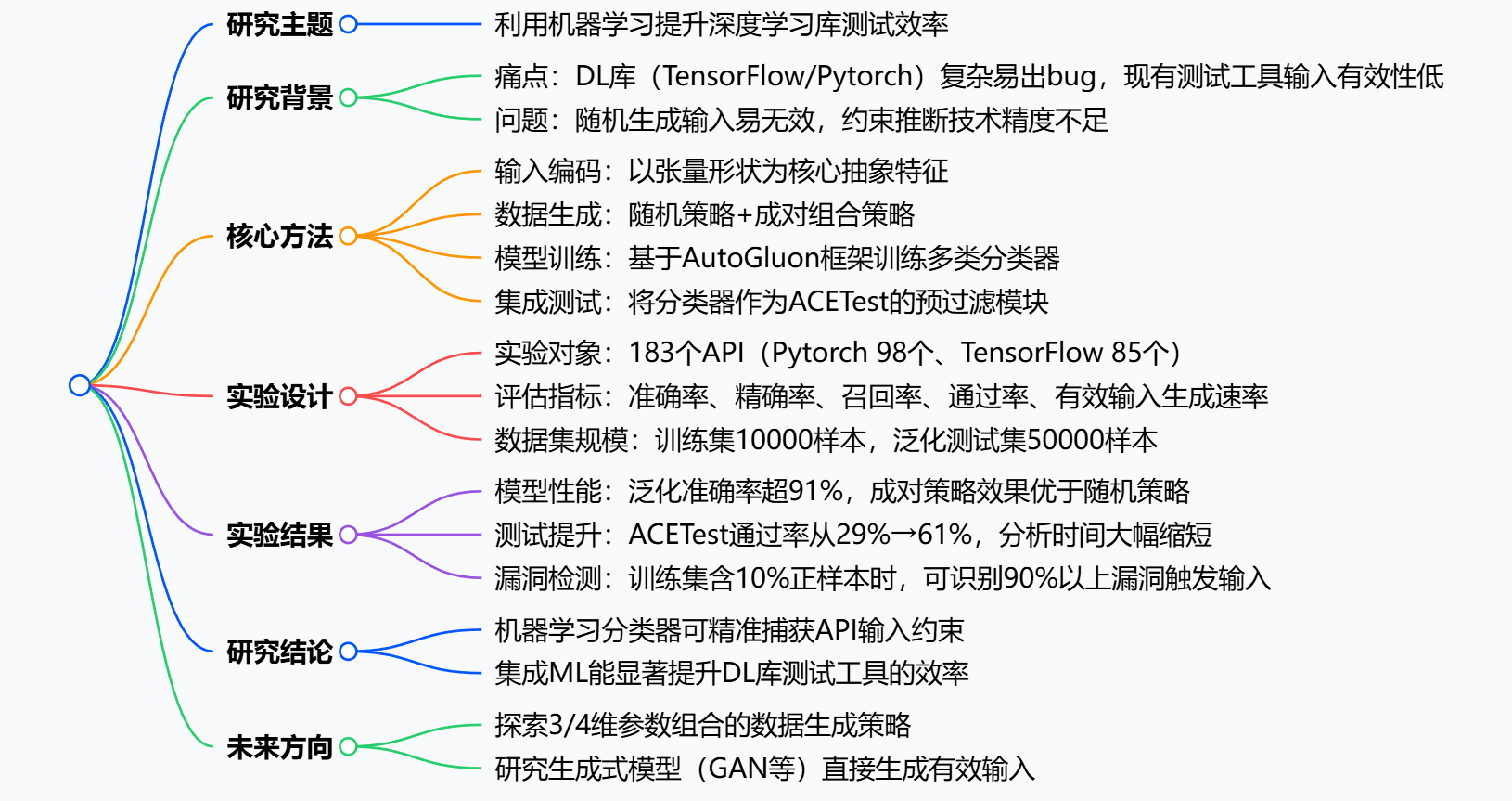
该研究提出利用机器学习分类器 ,以张量形状 为核心抽象特征来编码深度学习库API的输入数据,通过随机和成对两种策略生成标注数据集,借助AutoGluon训练分类器以判断输入有效性;实验针对TensorFlow和Pytorch的183个API 展开,结果显示分类器在未见过的数据上准确率超91% ,将其集成到先进的模糊测试工具ACETest后,有效输入通过率从约29%提升至61%,且对ACETest的漏洞检测能力影响极小,证明机器学习增强的输入分类技术能显著提升深度学习库测试的效率与有效性。
2. 思维导图
3. 详细总结
一、研究背景与动机
- 深度学习库的测试痛点
- TensorFlow、Pytorch等主流DL库因设计复杂存在较多bug,但现有模糊测试工具生成的输入常因违反API约束而无效。
- 先进测试工具ACETest 的有效输入通过率仅约29%,部分API(如TensorFlow的SigmoidGrad)通过率甚至低至5.4%,测试效率低下。
- 核心假设
- 以张量形状作为输入抽象特征,既能精准捕获API输入约束,又能大幅降低问题维度,便于机器学习模型训练。
- 批量推理技术可快速筛选大量输入,提升测试效率。
二、核心方法与实验设计
- 训练数据生成
- 策略1:随机生成:为每个API参数随机生成10000组取值,通过运行时结果标注有效/无效输入。
- 策略2:成对组合:基于成对组合测试方法,覆盖所有参数对的取值组合,确保样本分布更均匀。
- 参数取值范围:张量维度最大为6,维度长度范围0,10;整数参数范围-100,100;字符串参数取自API文档预定义集合。
- 模型训练与特征编码
- 特征处理:张量参数仅保留形状信息,整数/浮点数直接使用原值,字符串映射为整数,布尔值编码为0/1。
- 训练框架:采用AutoGluon自动机器学习框架,训练包括CatBoost、LightGBM、XGBoost在内的多类分类器。
- 训练配置:数据集按8:2划分训练集与测试集,每个API重复训练10次以消除随机误差。
- 集成测试流程
- 将训练好的分类器集成到ACETest中,作为预过滤模块:ACETest生成输入后,先由分类器预测有效性,仅执行预测有效的输入。
- 对比指标:测试通过率、分析总时间、有效输入生成速率(个/秒)。
三、实验结果与关键数据
- 模型性能评估(RQ1)
- 两类策略下模型的精确率与召回率表现如下表:
| DL库 | API数量 | 训练策略 | 平均正样本数 | 平均负样本数 | 平均精确率 | 平均召回率 |
|------|---------|----------|--------------|--------------|------------|------------|
| Pytorch | 98 | 随机 | 1633 | 8291 | 87% | 79% |
| Pytorch | 98 | 成对 | 1633 | 8263 | 88% | 82% |
| TensorFlow | 85 | 随机 | 1699 | 8300 | 90% | 78% |
| TensorFlow | 85 | 成对 | 1529 | 8470 | 91% | 80% | - 最优模型:梯度提升类模型(CatBoost、LightGBM、XGBoost)表现最佳,占比达77%,其中CatBoost在47.1%的API中取得最优性能。
- 两类策略下模型的精确率与召回率表现如下表:
- 模型泛化能力评估(RQ2)
- 在50000个未见过的输入样本上,91%的API对应的分类器准确率超过90%。
- 仅20%的API出现精确率下降,且下降幅度小;仅12%的API出现召回率下降,整体泛化能力优异。
- 测试效率提升评估(RQ3)
- 通过率提升 :ACETest的平均通过率从29.1%提升至60.7%,提升幅度达108.5%;对于原通过率低于40%的"难测API",通过率从11.8%提升至51%。
- 效率提升:测试总时间从54.8s缩短至21.4s;批量推理使分析时间减少约49%。
- 漏洞检测能力 :当训练集正样本比例≥10%时,分类器可正确识别91%以上的漏洞触发输入,对ACETest的漏洞检测能力影响极小。
四、研究结论与局限性
- 核心结论
- 基于张量形状的机器学习分类器可精准捕获DL库API的输入约束,泛化能力强。
- 将分类器集成到模糊测试工具中,能显著提升有效输入比例与测试效率。
- 局限性
- 部分复杂API(如torch.bmm)因训练集正样本过少(平均仅4个),导致模型性能极差。
- 现有数据生成策略无法覆盖所有参数组合,可能遗漏有效输入。
4. 关键问题与答案
问题1(方法侧重) :该研究选择张量形状作为输入抽象特征的核心原因是什么?
答案 :一是张量形状能精准编码DL库API的核心输入约束,例如torch.bmm要求两个输入均为3维张量且维度匹配,形状信息可直接反映该约束;二是仅保留形状信息可大幅降低输入数据的维度,避免因张量元素值过多导致的维度灾难,提升机器学习模型的训练效率与泛化能力;三是形状信息可统一编码为整数元组,能直接适配表格型数据的分类模型训练,无需复杂的特征工程。
问题2(结果侧重):将机器学习分类器集成到ACETest后,测试效率提升的具体表现有哪些?
答案 :一是有效输入通过率大幅提升 ,从原本的29.1%提升至60.7%,对于原通过率低于40%的难测API,提升效果更为显著;二是测试时间显著缩短 ,整体分析时间从54.8s减少到21.4s,批量推理技术使输入筛选效率提升近一倍;三是无效输入执行成本降低,分类器作为预过滤模块,可提前丢弃约90%的无效输入,避免不必要的API执行开销,例如在SigmoidGrad API测试中,无效输入从5000个减少到332个,执行时间从31s缩短至7.4s。
问题3(应用侧重):该研究提出的方法在实际应用于DL库测试时,需要满足哪些条件才能保证效果?
答案 :一是训练集需包含足够比例的正样本 ,当训练集正样本比例≥10%时,分类器对漏洞触发输入的识别率可达91%以上,否则易因数据不平衡导致模型失效;二是需采用批量推理模式 ,若逐个输入进行预测,会导致推理时间大幅增加(如5000个输入的推理时间从0.1s增至195s),反而降低测试效率;三是需结合具体API的约束特点选择数据生成策略,对于参数组合复杂的API,成对组合策略比随机策略更能生成均匀的样本分布,提升模型的精确率与召回率。
研究背景
深度学习的火爆离不开TensorFlow、PyTorch这些"神兵利器",它们帮开发者封装了复杂的底层计算,让大家不用从零造轮子。但这些库本身的代码极其复杂,藏着不少bug,一不小心就会让开发者的模型训练半路翻车。
为了揪出这些bug,研究者们常用模糊测试 ------随机生成大量输入数据喂给库的API,看会不会触发异常。但这里有个大痛点:很多API对输入有严格约束 ,比如PyTorch的torch.bmm函数,要求两个输入必须是3维张量,而且维度要匹配。随机生成的输入大部分都不符合要求,直接在运行时报错,相当于做了大量无用功。
举个例子,当时的先进测试工具ACETest,生成的输入平均只有29%是有效的;更夸张的是TensorFlow的SigmoidGrad API,有效率才5.4%。这就像你想筛选出合格的苹果,结果90%都是烂的,又费时间又费力气。
大家也试过用规则推断来过滤无效输入,但效果都不好------要么规则太粗糙,要么计算成本太高。于是研究者们开始思考:能不能用机器学习来"精准预判"输入是否有效?
创新点
这篇论文的核心创新点就三个,简单又实用:
- 选对了"特征" :用张量形状代替完整的张量数据来训练模型。张量形状是API输入约束的核心(比如维度数量、各维度大小),而且能大幅降低数据维度,让模型训练又快又准。
- 高效的"数据生成策略":提出随机生成+成对组合两种策略,快速构建带标签的训练集(有效输入标为正例,无效标为负例),不用人工标注。
- 巧妙的"集成方案":把训练好的ML分类器当成"前置过滤器",集成到ACETest工具里,先筛掉无效输入再执行测试,直接提升有效率。
研究方法和思路
整个研究过程可以拆解成4个步骤,就像搭积木一样清晰:
步骤1:确定研究对象和数据范围
- 选了PyTorch 2.2.2和TensorFlow 2.16.2两个主流库,共183个有输入约束的API(PyTorch 98个,TensorFlow 85个)。
- 限定输入参数的范围:张量维度最多6维,每个维度大小在0-10之间;整数参数在-100到100之间,保证生成的数据不会太离谱。
步骤2:生成带标签的训练数据
用两种策略生成10000组输入,然后运行API,根据是否报错标注正负例:
- 随机策略:直接随机生成参数值,简单粗暴。
- 成对策略:确保每对参数的组合都被覆盖,样本分布更均匀,能更好地捕捉参数间的约束关系。
步骤3:训练ML分类器
- 特征编码 :整数/浮点数直接用原值,字符串转成数字,布尔值用0/1表示,张量只保留形状信息(比如一个3×4的张量就编码成(3,4))。
- 模型训练:用AutoGluon自动机器学习框架,自动训练和对比多种模型(CatBoost、LightGBM、XGBoost等),选出每个API的最佳模型。
- 评估指标:用精确率(预测有效里真有效的比例)和召回率(真有效里被预测出来的比例)来衡量模型性能。
步骤4:集成到测试工具并验证
把训练好的分类器集成到ACETest中,流程变成:ACETest生成输入 → 分类器预判有效性 → 只执行预判有效的输入。然后对比集成前后的测试效率和有效率。
主要成果和贡献
这篇论文的成果可以用"效果炸裂"来形容,核心贡献有三个:
1. 模型性能:又准又通用
- 对183个API,训练出的分类器在未见过的5万组输入上,准确率超过91%。
- 成对策略比随机策略效果更好:比如PyTorch API的平均召回率从79%提升到82%,能更少地漏掉有效输入。
- 最优模型是梯度提升类(CatBoost、LightGBM、XGBoost),占了77%的最佳案例,其中CatBoost表现最突出,在47.1%的API上都是最优。
2. 测试效率:通过率翻倍,时间大减
把分类器集成到ACETest后,效果立竿见影,具体对比如下表:
| 评估维度 | ACETest(原工具) | ACETest+ML(集成后) | 提升幅度 |
|---|---|---|---|
| 平均通过率 | 29.1% | 60.7% | +108.5% |
| 平均测试时间 | 54.8s | 21.4s | 减少61% |
| 无效输入数 | 3542.9 | 354 | 减少90% |
尤其对那些原本通过率低于40%的"难测API",提升更明显------有效率从11.8%涨到51%,直接从"几乎没用"变成"能用"。
3. 不影响漏洞检测能力
大家可能会担心:过滤输入会不会漏掉能触发bug的有效输入?结果证明完全不会:
- 当训练集里的有效输入占比≥10%时,模型能正确识别91%以上的bug触发输入。
- 集成后工具的漏洞检测能力几乎没损失,还能节省大量无效测试的时间。
开源资源
论文的复现包已公开:https://sites.google.com/view/ml4dllconstraints
总结
这篇论文提出了一个简单却极具实用性的方案:用张量形状做特征,训练机器学习分类器,作为深度学习库模糊测试的前置过滤器。实验证明,这个方案能把测试工具的有效输入通过率从29%提升到61%,同时大幅减少测试时间,而且完全不影响漏洞检测能力。
这个方法的意义在于,它给深度学习库的测试提供了一条新路径------不用再靠复杂的规则推断,而是让机器自己学约束,既高效又通用。未来研究者还打算探索更复杂的参数组合策略,以及用生成式模型直接生成有效输入,进一步提升测试效率。