一、引言
在动态复杂的城市环境中部署网联自动驾驶汽车(CAVs),安全高效的多智能体协同是核心挑战。多智能体强化学习(MARL)虽在多机器人路径规划等领域展现出潜力,但应用于自动驾驶时,面临非平稳性、部分可观测性以及人类驾驶行为不确定性等多重难题。传统协同 MARL 方法仅通过共享编码状态观测来提升协同能力,在安全关键场景中表现不足。
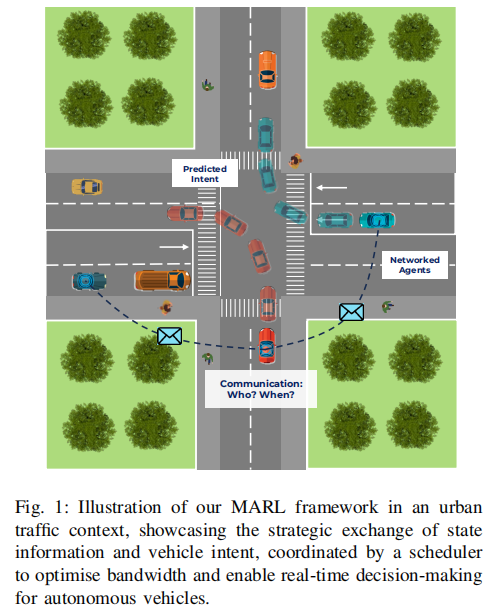
为此,来自帝国理工学院的研究团队提出了 IntNet 框架,将车辆意图传输与自适应通信调度融入端到端学习范式,通过联合优化所有组件实现安全协同。其核心创新在于观测预测模块,使智能体能够预测后续策略输出并通过车联网共享,结合图注意力网络(GAT)处理消息与调度器优化通信图,在复杂城市场景中实现了协同性能提升、碰撞率降低以及通信开销减少 60% 的显著成效。
代码链接:暂无
沐小含持续分享前沿算法论文,欢迎关注...
二、相关工作
2.1 自动驾驶中的多智能体强化学习
MARL 在自动驾驶领域的应用已涵盖交叉口管理、交通流优化、协同路径规划等多个方向。已有研究通过 MARL 解决了双合并问题、混合交通流中的协同变道、高速公路匝道汇入等复杂场景问题,并尝试利用图卷积神经网络(GCN)提升操控安全性,或在紧急车辆避让、遮挡场景等挑战性场景中应用 MARL。
然而,动态城市环境中的安全与协同问题仍未得到充分解决。现有方法虽能提升交通效率,但在面对高维观测数据(如摄像头、激光雷达数据)和复杂交通动态时,难以保证关键场景下的绝对安全,这为 IntNet 框架的提出提供了切入点。
2.2 多智能体通信强化学习
通信式多智能体强化学习(MACRL)的核心是通过高效通信提升协作能力并节省带宽。早期研究提出了 MARL 智能体通过学习通信实现群体决策的概念,后续逐步引入门控机制实现选择性通信、注意力机制实现聚焦通信,并通过通信图管理带宽。
意图共享作为提升协同的关键思路,已有研究通过共享动作或策略输出来减少系统非平稳性,或利用观测与动作预测模块结合注意力机制优化协同,但这些方法多局限于网格环境,难以应对自动驾驶中的高维观测和带宽约束。IntNet 在此基础上,针对自动驾驶场景特性,融合 GAT 与消息调度机制,实现了更高效的意图共享与通信优化。
三、方法论
3.1 基于通信的多智能体强化学习建模
论文将 MACRL 建模为去中心化部分可观测马尔可夫决策过程(Dec-POMDP),其形式化定义为元组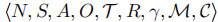 ,各组件含义如下:
,各组件含义如下:
:智能体数量集合;
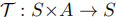 :状态转移函数,定义智能体动作对环境状态的影响;
:状态转移函数,定义智能体动作对环境状态的影响;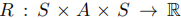 :奖励函数,计算即时奖励;
:奖励函数,计算即时奖励;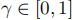 :折扣因子,平衡当前与未来奖励;
:折扣因子,平衡当前与未来奖励;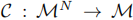 :通信协议,定义消息聚合方式。
:通信协议,定义消息聚合方式。
该模型的目标是为每个智能体找到最优策略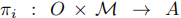 ,最大化期望累积奖励:
,最大化期望累积奖励:
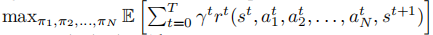
其中为时刻
的即时奖励,由奖励函数
定义。
3.2 意图共享 MARL 框架
IntNet 的核心是两步通信机制,结合观测编码、意图预测、通信调度与图注意力处理,实现智能体间的高效协同。框架结构如图 2 所示:
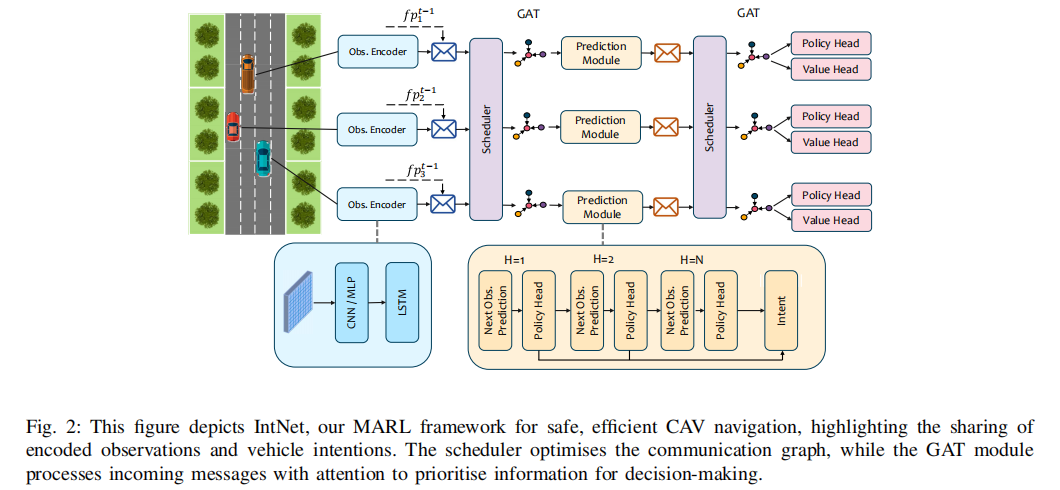
3.2.1 观测编码与策略指纹共享
第一步通信中,每个智能体 通过编码函数
将时刻t的局部观测
编码为消息
,同时广播上一时刻的策略指纹
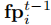 。策略指纹总结了智能体近期的决策上下文,定义为动作空间上的概率分布:
。策略指纹总结了智能体近期的决策上下文,定义为动作空间上的概率分布:
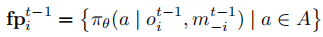
其中 为智能体
在
时刻的局部观测,
为其他智能体在
时刻发送的消息。通过共享观测编码与策略指纹,智能体建立初步的协同决策基础。
3.2.2 意图预测与共享
第二步通信聚焦于未来意图的交换,智能体预测未来 个时间步的策略指纹序列
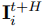 ,即意图集合:
,即意图集合:
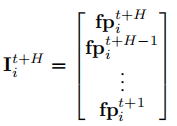
其中每个未来策略指纹 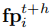 (h=1,2,...,H)的计算依赖于预测观测
(h=1,2,...,H)的计算依赖于预测观测 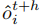 :
:
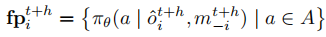
预测观测 通过观测预测模块 递归生成:
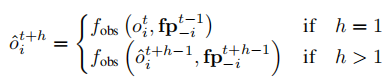
当 时,利用当前观测
与其他智能体上一时刻的策略指纹
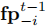 ;当
;当 时,基于前一步预测观测与对应时刻的策略指纹递归更新。这种递归机制能够捕捉环境动态与智能体意图的相互作用,使智能体形成前瞻性的决策依据。
3.2.3 通信调度与图注意力处理
考虑到自动驾驶场景的带宽限制与高维状态空间,IntNet 为每个通信步骤设计了调度器,通过构建邻接矩阵 确定智能体间的通信链路。矩阵元素
表示智能体
在时刻
与智能体
通信,否则为 0,以此减少不必要的数据传输,提升带宽效率。
智能体采用图注意力网络(GAT)处理接收的消息,通过注意力机制动态权衡消息重要性。对于节点 及其邻居
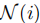 ,注意力系数
,注意力系数 计算如下:
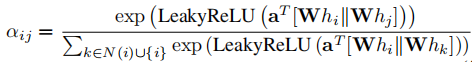
其中 表示拼接操作,
为节点特征权重矩阵,a为注意力权重向量,LeakyReLU 为非线性激活函数。注意力系数经 softmax 归一化后,节点
的更新特征表示为邻居特征的加权和:
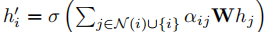
其中σ为可选激活函数。GAT 能够自适应优先处理关键信息,为高维、带宽受限环境下的有效决策提供支持。
3.3 训练方法
IntNet 采用并发训练策略,无需预训练观测预测模块,直接利用 episode 滚动过程中收集的数据同时训练预测模块与策略。
3.3.1 观测预测模块训练
基于滚动过程生成的转移样本 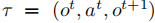 构建监督数据集,以
构建监督数据集,以 和
为输入,
为目标,采用均方误差(MSE)损失训练:
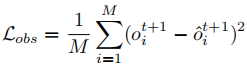
其中 为样本总数,
为真实下一时刻观测,
为预测观测。
3.3.2 策略训练
采用演员 - 评论家(Actor-Critic)损失函数训练策略,同时优化演员(策略)和评论家(价值):
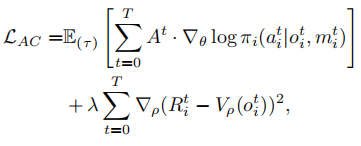
其中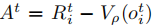 为优势函数,
为优势函数,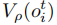 为价值函数,
为价值函数, 为价值损失权重系数。这种并发训练方式使观测预测模块与策略相互促进,实时提升对环境动态的理解。
3.4 环境设置
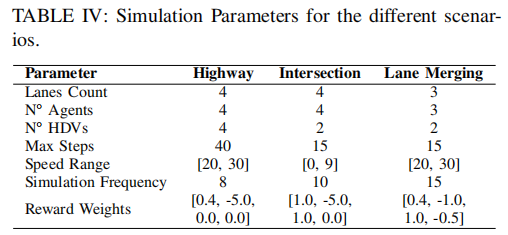
实验基于修改后的 Highway-env 模拟器,适配多智能体城市导航场景,智能体需避免碰撞并到达目的地以最大化奖励。环境关键配置如下:
- 智能体:CAVs 具有有限视野,可通过车联网交换消息;
- 观测:采用类激光雷达的射线投射方法,在 360° 范围内检测 80 米内的其他车辆,使用 64 条射线,每时间步更新一次;
- 动作:离散元动作包括加速、减速、保持速度、左变道、右变道;
- 奖励函数:协作式奖励设计,包含速度奖励(rspeed)、避撞奖励(rcol)、到达奖励(rarr)和协同变道奖励(rmerge),通过网格搜索优化权重,优先保障安全,并根据场景特性调整各组件权重。
场景具体参数如表 IV 所示:
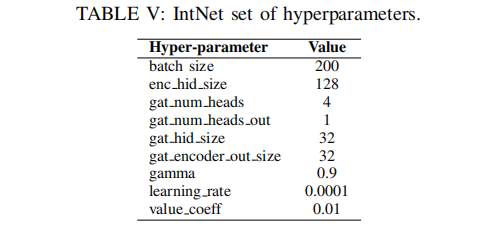
IntNet 的超参数设置如表 V 所示:
四、实验验证
论文通过三组核心实验验证 IntNet 的性能,包括与基线方法的对比、 scalability 分析以及通信效率评估,实验场景涵盖高速公路、四向交叉口和车道合并(如图 3 所示):
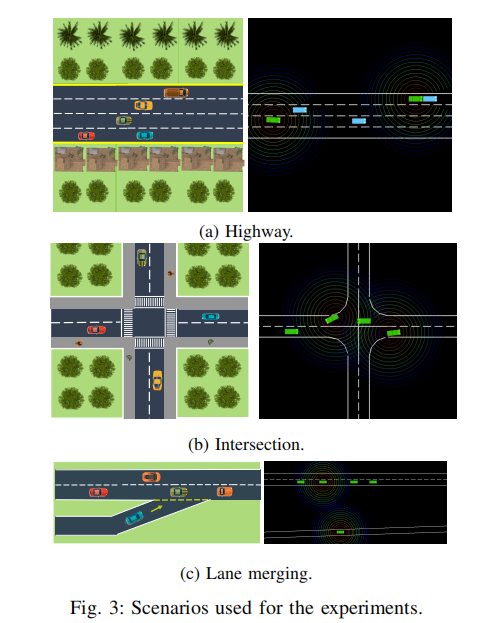
其中高速公路和车道合并场景包含 CAVs 与人类驾驶车辆(HDVs),交叉口场景仅含 CAVs,HDVs 采用 IDM/MOBIL 跟驰模型模拟人类驾驶行为。主要评估指标为平均到达率(成功到达目的地的 episode 百分比)、碰撞率(发生碰撞的 episode 百分比)和团队累积奖励,所有实验采用 3 个独立随机种子,基于 100 个测试 episode 验证结果,预测 horizon H=2(经预实验确定,H>2时性能下降且方差增大)。
4.1 基线方法对比
选取四种代表性基线方法进行对比:无通信(No Communication)、CommNet、IC3Net 和 MAGIC,前三种为传统状态 / 特征共享方法,MAGIC 为动态通信调整方法。
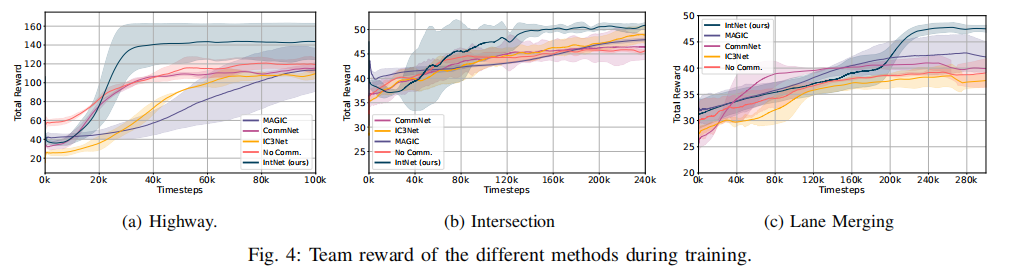
4.1.1 团队奖励与到达率
训练过程中的团队奖励变化如图 4 所示,IntNet 在所有场景中均展现出更高的奖励累积速度和最终奖励值:
到达率(成功 rate)的训练曲线如图 5 所示,IntNet 的成功到达率显著高于基线方法:
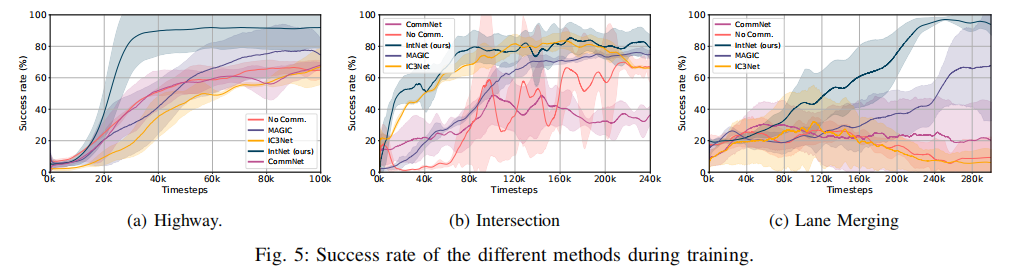
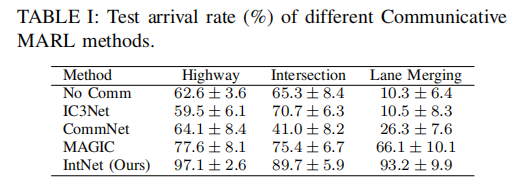
表 I 详细列出了各方法在 100 个测试 episode 中的到达率:
关键发现:
- 高速公路场景:IntNet 仅需 100k 训练 episode 即可达到高成功率,而基线方法需约 200k episode;
- 交叉口场景:IC3Net 的成功率与 IntNet 接近,但 IntNet 的学习曲线更平稳快速;
- 车道合并场景:所有基线方法表现不佳,因该场景对协同要求最高,基线方法易为追求速度牺牲安全,而 IntNet 通过意图共享实现了 93.2% 的高到达率。
4.1.2 碰撞率对比
车道合并场景中,基线方法因协同不足导致碰撞率较高,而 IntNet 通过提前共享未来意图,使智能体能够预判冲突并调整动作,显著降低碰撞风险。高速公路场景中,IntNet 在高车速下仍能维持极低碰撞率,体现了意图共享对安全的提升作用。
4.2 扩展性分析
在交叉口场景中逐步增加智能体数量,评估 IntNet 与 IC3Net 的碰撞率变化,结果如图 6 和表 II 所示:
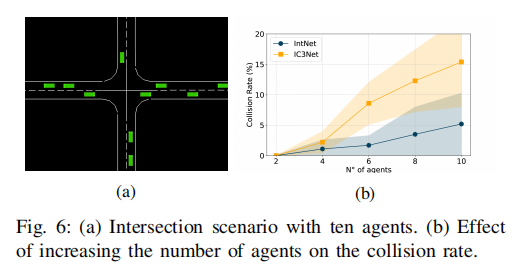
表 II 不同智能体数量下的测试碰撞率(%)
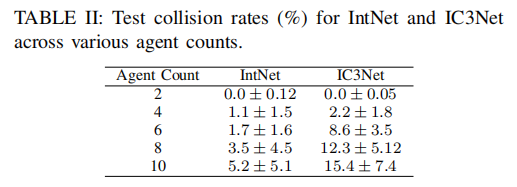
随着智能体数量增加,环境复杂度提升,两种方法的碰撞率均有所上升,但 IntNet 的碰撞率始终显著低于 IC3Net。当智能体数量达到 10 时,IC3Net 的碰撞率高达 15.4%,而 IntNet 仅为 5.2%,证明其在拥挤场景中具有更强的扩展性,能够通过高效通信与意图共享维持协同安全性。
4.3 通信效率评估
在仅含 CAVs 的交叉口场景中,对比有无调度器时的通信性能。无调度器时采用全连接通信网络,所有范围内的智能体均通信;有调度器时,智能体仅在安全导航的关键时刻与必要的智能体通信。
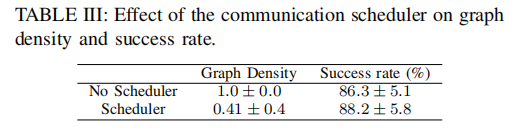
结果表明,调度器使每个智能体的平均通信对象减少一半以上,图密度从 1.0 降至 0.41,同时成功率略有提升。图 7 展示了交叉口场景中两个关键时刻的通信图:
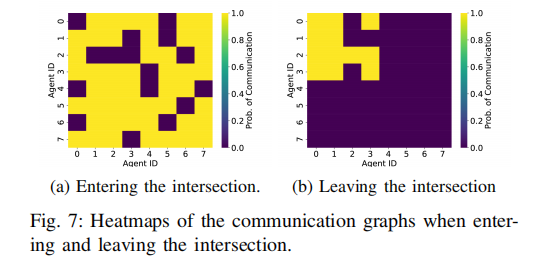
图 7a 为智能体进入交叉口时的通信图,智能体间通信链路密集,以协调冲突;图 7b 为多数智能体驶出交叉口时的通信图,仅剩余在交叉口内的智能体(ID 0-3)保持通信。这种动态通信调度既保证了关键场景的协同需求,又最大化降低了通信开销,通信努力减少高达 60%。
五、结论与未来工作
5.1 核心贡献
- 提出了一种新型意图共享 MARL 框架,融合 GAT 处理共享消息与调度机制优化通信,提升安全关键场景的协同性并降低不确定性;
- 开发了无需预训练的多智能体观测预测模块,支持智能体递归规划未来动作;
- 突破了传统网格环境的局限,融入高维观测与真实车辆运动学,为自动驾驶场景的通信式 MARL 提供了更具代表性的评估方案。
5.2 关键发现
IntNet 通过意图共享与自适应通信调度,在复杂城市场景中实现了三大提升:
- 安全性:碰撞率显著降低,车道合并等强协同场景的到达率提升至 90% 以上;
- 学习效率:收敛速度更快,所需训练 episode 仅为基线方法的一半;
- 通信效率:通信开销减少 60%,图密度降至 0.41,同时维持甚至提升了协同性能。
5.3 未来工作
- 扩展方法的适用范围,覆盖更多样化的城市场景(如环岛、施工区域);
- 探索不同预测 horizon H 的影响,优化长短期意图的平衡;
- 考虑实际通信延迟与数据包丢失问题,增强框架的鲁棒性;
- 融合更多传感器数据(如视觉图像),进一步提升观测建模的准确性。
六、技术总结
IntNet 的核心创新在于将 "意图共享" 与 "自适应通信" 深度融入 MARL 框架,针对自动驾驶的高维观测、带宽约束和安全需求,提出了端到端的协同解决方案。其技术路径可总结为:
- 两步通信机制:先共享当前观测与策略指纹,再交换未来意图,构建全方位协同基础;
- 递归观测预测:无需预训练,通过环境交互数据实时优化预测模块,捕捉动态环境与智能体意图的相互作用;
- 调度与 GAT 结合:通过调度器优化通信拓扑,GAT 动态权衡消息重要性,实现高效低耗的通信处理。
该框架为协同自动驾驶提供了新的技术思路,其意图共享与通信优化的设计理念,也可迁移至其他安全关键型多智能体系统(如多机器人协同救援、无人机编队飞行等),具有广泛的应用前景。