读论文笔记-ALIGN:利用有噪声数据集扩大视觉和视觉-语言表示
Problems
本文拟解决NLP的表示学习可以直接利用原始文本,而视觉和视觉-语言表示学习仍然依赖于大量昂贵和需要专业知识精心设计的数据集的问题。
Motivations
- 昂贵的数据处理过程限制了数据集的规模进而限制训练模型的规模,使得模型性能受限:制作视觉任务的预训练数据集需要数据收集、采样、人工标注等复杂的工作,对于视觉语言任务则需要更复杂的人工标注、语义解析、清洗和平衡工作,所以数据量很小。预训练数据集对迁移学习中下游任务的性能提升十分关键。
- 现有的利用文本描述来学习视觉表示的模型并没产生vision-language representation用于跨模态检索任务。
Methods
Overview :为了实现视觉和视觉-语言表示学习,作者先构造了一个1.8billion的有噪声的图文对数据集,使用的文本是alt-text文本(alt-text是HTML中描述图像的一段文本),且只用了基于频率的过滤方法。在成对的噪声数据上预训练ALIGN模型,再在匹配和检索、视觉分类任务上进行了评估。通过消融实验、基于text queries和image+text queries的图像检索的可视化、多语种模型训练证明了研究的可用性、模型的优越性。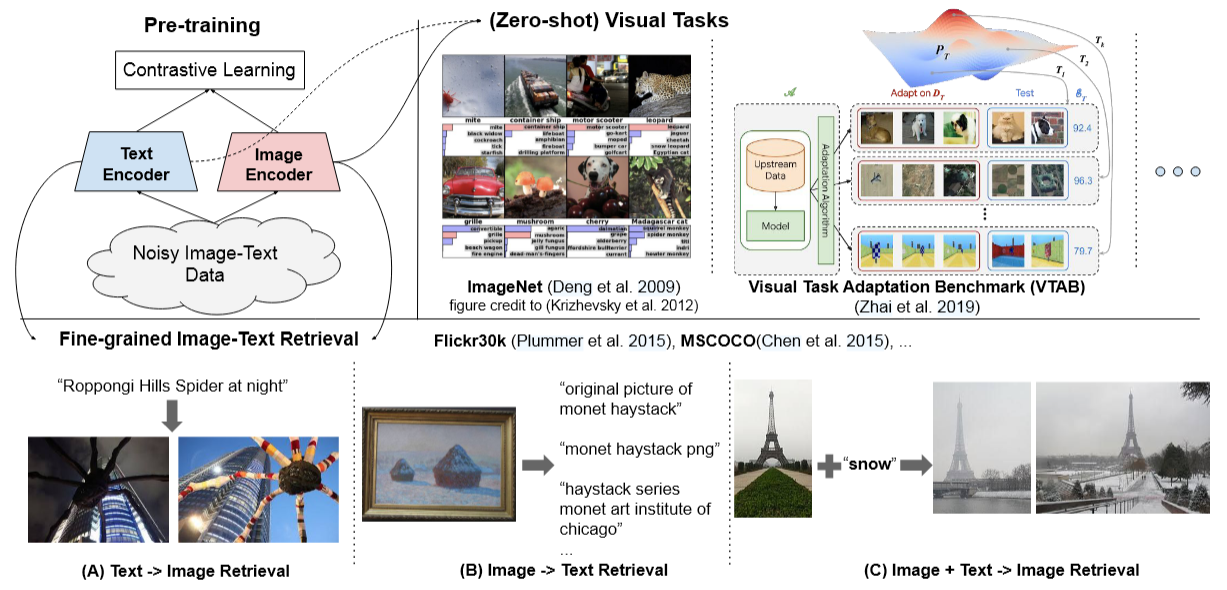
-
数据集过滤:对于图像,删除了色情的图像、有超过1000个关联的alt-text的图像、删除下游与验证验证数据集重复或相似的图像,保留最短尺寸大于200像素和长宽比小于3的图像。对于文本,删除与超过10张图像共享的alt-text、过长或过短的alt-text、包含太多稀有(超出100million个常用unigrams或bigrams的)token的alt-text。
-
ALIGN模型预训练:使用双编码器结构,包括文本编码器和图像编码器,最后用余弦相似度结合起来。视觉编码器是去除分类头添加全局池化层的EfficientNet,文本编码器是包含CLS token embedding的BERT并在其上加入了线性激活层以统一到视觉特征的尺度,两者都是从头预训练的。对比学习的任务来训练,损失函数是归一化的softmax loss (归一化是指embedding都通过了L2-normalized,再使用对比损失softmax loss)。
L i 2 t = − 1 N ∑ i N l o g e x p ( x i T y i / σ ) ∑ j = 1 N e x p ( x i T y j / σ ) L_{i2t}=-\frac{1}{N}\sum_i^Nlog\frac{exp(x_i^Ty_i/\sigma)}{\sum_{j=1}^Nexp(x_i^Ty_j/\sigma)} Li2t=−N1i∑Nlog∑j=1Nexp(xiTyj/σ)exp(xiTyi/σ)
L t 2 i = − 1 N ∑ i N l o g e x p ( y i T x i / σ ) ∑ j = 1 N e x p ( y i T x j / σ ) L_{t2i}=-\frac{1}{N}\sum_i^Nlog\frac{exp(y_i^Tx_i/\sigma)}{\sum_{j=1}^Nexp(y_i^Tx_j/\sigma)} Lt2i=−N1i∑Nlog∑j=1Nexp(yiTxj/σ)exp(yiTxi/σ)
x i x_i xi, y i y_i yi就是归一化后的embedding。在对比学习时,一般在一个batch里面就有正样本对和负样本对。正样本对就是来源于数据集,对于N个成对的,负样本对就是对每一个图像就可以匹配N-1个文本,文本也同理。所以可以有大量的负样本对。L-2归一化:L2-normalized是把向量通过除以其L2范数调整到单位长度为1的操作。对于向量 x x 1 , x 2 , . . . , x d xx_1,x_2,...,x_d xx1,x2,...,xd,L2范数就是 ( x 1 2 + x 2 2 + . . . ) \sqrt{(x_1^2+x_2^2+...)} (x12+x22+...) ,对于归一化后的 x i x_i xi就是 v i ∣ ∣ v ∣ ∣ 2 \frac{v_i}{||v||_2} ∣∣v∣∣2vi。本文使用这个的原因可能是为了统一向量尺寸方便进行余弦相似度的计算,为了训练稳定。
-
迁移到下游任务:1)图文匹配和检索任务:在img2text和text2img的检索任务上进行了微调或不微调的迁移。benchmarks是COCO\Flickr30K\CxC。2)视觉分类:在ImageNet ILSVRC-2012\ImageNet-R\ImageNet-A\ImageNetV2上做ALIGN的零样本迁移。用ImageNet和一些细粒度的小型分类数据集在Image Encoder上做分类,对于ImageNet上的验证使用了只微调分类层和全部微调的配置,对于其他小型数据集则使用全部微调的配置。还是用了VTAB来验证模型的鲁棒性。
Experiments
预训练配置 :图像分辨率固定为289*289(先统一到 346 ∗ 346 346*346 346∗346尺寸再在训练时随机裁剪,在验证时进行中心裁剪),对文本使用最大64个tokens,输入文本不长于20unigrams。softmax loss的温度值初始化为1,标签平滑参数为0.1。优化器为LAMB,warmup+linear decay。
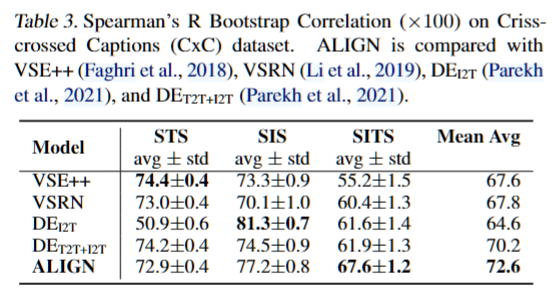
下游检索和匹配任务 :微调场景下,损失函数和预训练一样。结果:在3个数据集的所有场景(跨模态和同模态检索)下达到了全面的SOTA,但在语义相似性任务上只有在SITS这个跨模态任务上表现出了SOTA甚至在单模态上的表现弱于其他模型(可能是因为预训练目标只有跨模态匹配而忽略了模态内的)。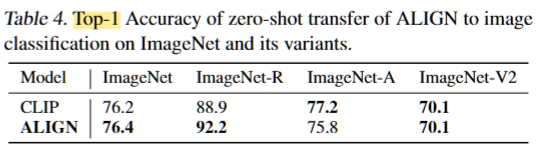
ALIGN的零样本视觉分类 :1)如果直接使用classnames作为text输入给encoder在4种数据集上都达到了良好的效果,表明了模型的鲁棒性。2)使用和CLIP相同的提示词,在ImageNet上实现了TOP-1指标的提升。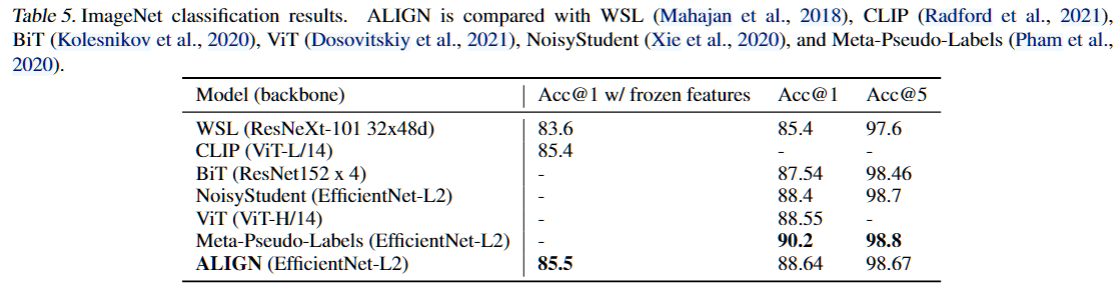
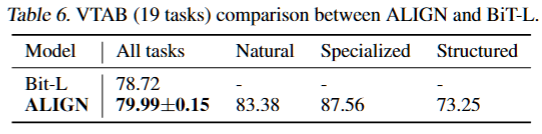
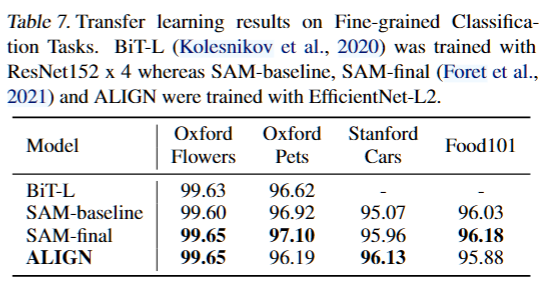
ImageEncoder的视觉分类 :1)finetuning on ImageNet,使用全部和局部2种微调方式,微调时使用随机裁剪和水平翻转。前者达到了SOTA,后者与多个模型competitive。2)VTAB验证,在每个任务上做50次实验寻找超参数,最终验证结果表示在相同的超参数搜索方法下性能超过了BiT-L。3)细粒度数据集分类:使用和ImageNet同样的数据增强和优化器,也用2种微调方法。最终达到了competitive的效果。
消融实验:在MSCOCO的零样本检索和ImageNet KNN任务上进行评估,因为有代表性且和预训练数据有相似性。1)使用不同规模的EfficientNet和BERT的组合,结论是在视觉任务上Image encoder的能力起到了更重要的作用,在视觉语言检索任务上,两者能力同等重要。2)探究主结构的超参数设置影响,结论是embedding的维度越大越好,softmax loss的in-batch negatives多一点更好,对于温度参数手选比模型学习更好。3)对于预训练数据集:为了验证不同大小数据集对模型性能的影响,使用2种模型在3类数据集上先预训练后再实验。结果表明在本文的模型结构上,用更大的模型才会有更好的效果。为了验证模型大小是怎么赢过噪声的影响的,作者对原始的训练集随机采样了3种大小并于CC3M比较,结果表明在同等数据量大小下,ALIGN数据预训练的模型确实比CC3M的差,但数据量变大后模型性能也有飞跃的提升。