Advances and Challenges in Foundation Agents--Memory调研
https://arxiv.org/pdf/2310.08560
https://github.com/letta-ai/letta
https://www.doubao.com/chat/15882792894090498
9.4k Star!MemGPT:伯克利大学最新开源、将LLM作为操作系统、无限上下文记忆、服务化部署自定义Agent
MemGPT - 一个智能的大模型记忆管理系统,提供大量的上下文长度信息支持
MemGPT学习资源汇总 - 打造具有长期记忆和自定义工具的LLM代理
【AI大模型应用开发】MemGPT原理与快速上手:这可能是目前管理大模型记忆的最专业的框架和思路
MemGPT:将LLMs视为操作系统------以达无限Context
论文翻译
MemGPT:迈向作为操作系统的大型语言模型
摘要
大型语言模型(LLMs)彻底改变了人工智能,但受限于有限的上下文窗口,这阻碍了它们在扩展对话和文档分析等任务中的实用性。为了能够使用超出有限上下文窗口的上下文,我们提出了虚拟上下文管理技术,该技术从传统操作系统中的分层内存系统汲取灵感,通过在物理内存和磁盘之间进行分页,提供了扩展虚拟内存的错觉。利用这种技术,我们引入了MemGPT(MemoryGPT),这是一个智能管理不同存储层级的系统,以便在大型语言模型有限的上下文窗口内有效地提供扩展的上下文。我们在两个领域评估了这种受操作系统启发的设计,在这两个领域中,现代大型语言模型有限的上下文窗口严重限制了它们的性能:一是文档分析,MemGPT能够分析远超底层大型语言模型上下文窗口的大型文档;二是多会话聊天,MemGPT可以创建会话代理,这些代理通过与用户的长期交互能够进行记忆、反思并动态进化。我们在https://research.memgpt.ai上发布了MemGPT的代码和实验数据。
1. 引言
近年来,大型语言模型(LLMs)及其底层的Transformer架构(Vaswani等人,2017;Devlin等人,2018;Brown等人,2020;Ouyang等人,2022)已成为会话人工智能的基石,并催生了大量的消费级和企业级应用。
尽管取得了这些进展,但大型语言模型所使用的有限固定长度上下文窗口严重限制了它们在长时间对话或对长文档进行推理方面的适用性。例如,最广泛使用的开源大型语言模型只能支持几十次来回消息,或者在超过最大输入长度之前对短文档进行推理(Touvron等人,2023)。
由于Transformer架构的自注意力机制,直接扩展Transformer的上下文长度会导致计算时间和内存成本呈二次方增长,这使得新的长上下文架构设计成为一项紧迫的研究挑战(Dai等人,2019;Kitaev等人,2020;Beltagy等人,2020)。虽然开发更长上下文的模型是一个活跃的研究领域(Dong等人,2023),但即使我们能够克服上下文扩展的计算挑战,最近的研究表明,长上下文模型难以有效地利用额外的上下文(Liu等人,2023a)。因此,考虑到训练最先进的大型语言模型所需的大量资源以及上下文扩展的收益递减,迫切需要替代技术来支持长上下文。
在本文中,我们研究如何在继续使用固定上下文模型的同时,提供无限上下文的错觉。我们的方法借鉴了虚拟内存分页的思想,该思想旨在通过在主内存和磁盘之间对数据进行分页,使应用程序能够处理远超可用内存的数据集。我们利用大型语言模型代理在函数调用能力方面的最新进展(Schick等人,2023;Liu等人,2023b)来设计MemGPT,这是一个受操作系统启发的用于虚拟上下文管理的大型语言模型系统。通过函数调用,大型语言模型代理可以读写外部数据源,修改自身的上下文,并选择何时向用户返回响应。
这些能力使大型语言模型能够有效地在上下文窗口(类似于操作系统中的"主内存")和外部存储之间"分页"进出信息,类似于传统操作系统中的分层内存。此外,函数调用还可用于管理上下文管理、响应生成和用户交互之间的控制流。这使得代理能够选择为单个任务迭代修改其上下文中的内容,从而更有效地利用其有限的上下文。
在MemGPT中,我们将上下文窗口视为一种受约束的内存资源,并为大型语言模型设计了一个内存层次结构,类似于传统操作系统中使用的内存层级(Patterson等人,1988)。传统操作系统中的应用程序与虚拟内存交互,操作系统通过将溢出数据分页到磁盘,并在
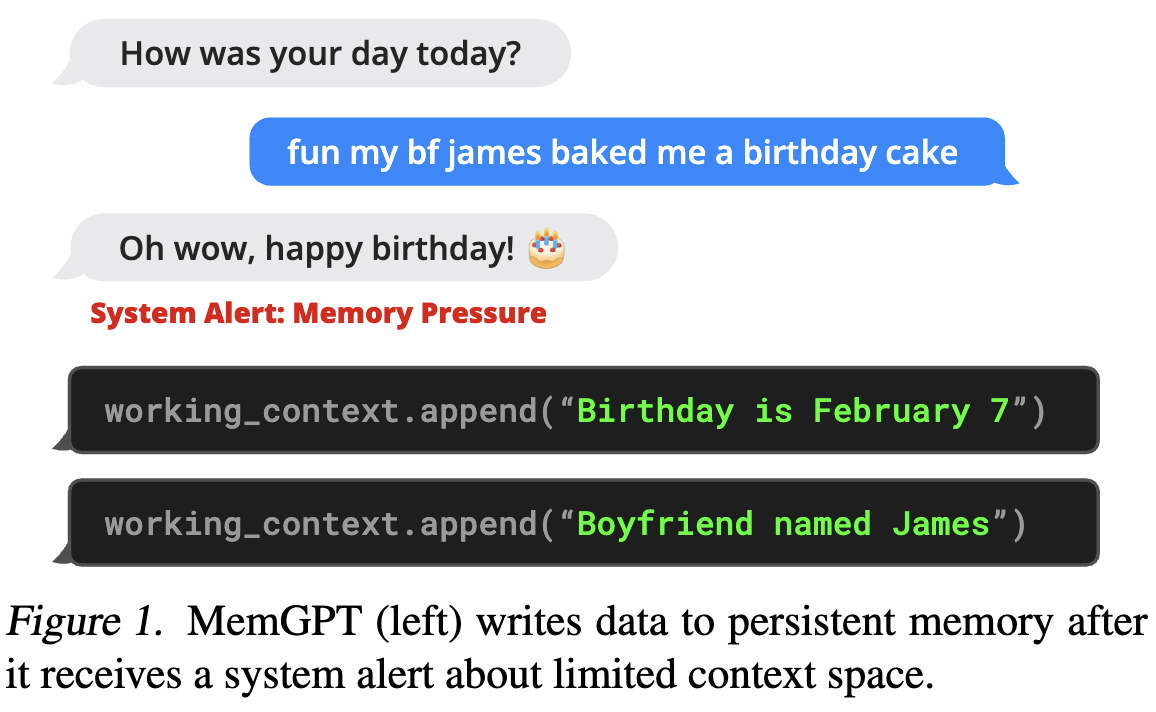
图1. 当MemGPT(左侧)收到关于上下文空间有限的系统警报后,会将数据写入持久性内存。
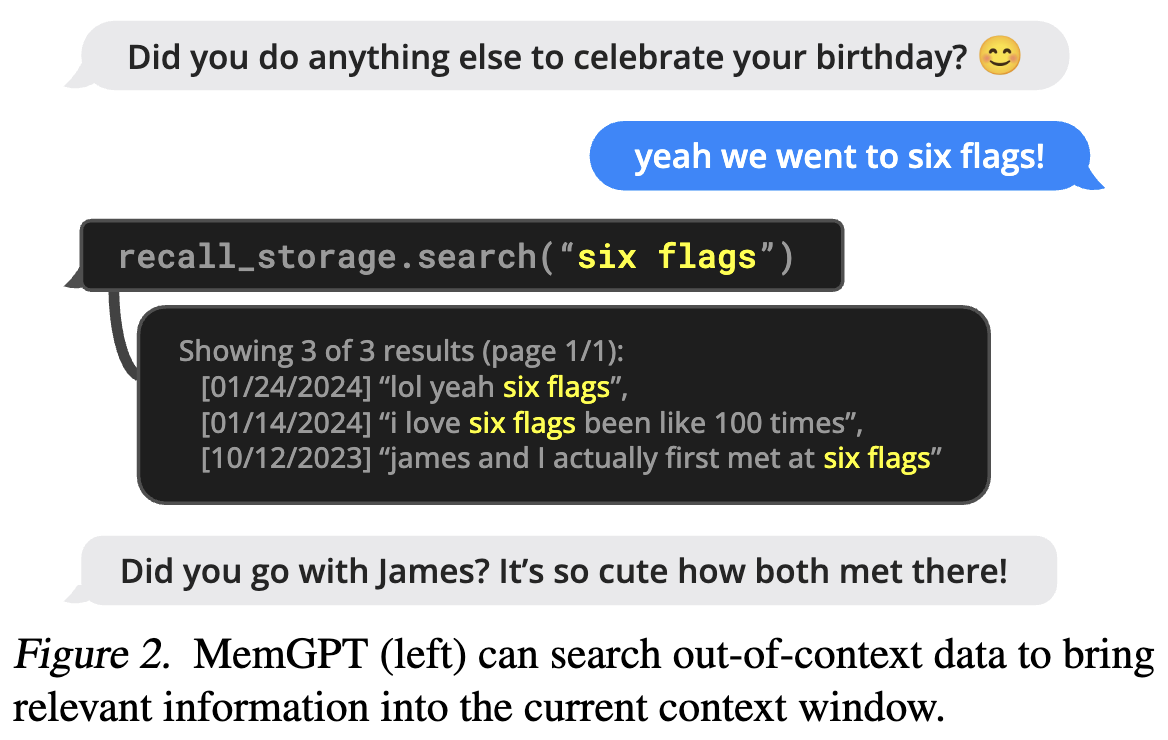
图2. MemGPT(左侧)能够搜索上下文外的数据,将相关信息带入当前上下文窗口。
github
根据提供的代码片段,其中的记忆系统主要通过多层级结构和对应的工具函数实现,具体如下:
1. 记忆系统核心组成
-
核心记忆(Core Memory):
- 有限容量,始终可见于上下文,存储 persona(自身角色)和 human(用户关键信息)等基础信息。
- 包含可编辑的子块,可通过
core_memory_append和core_memory_replace函数修改,确保交互的一致性和个性化。
-
召回记忆(Recall Memory):
- 即对话历史数据库,即使近期消息超出上下文窗口,仍可通过
conversation_search函数检索全部历史交互,实现对过往对话的记忆。
- 即对话历史数据库,即使近期消息超出上下文窗口,仍可通过
-
归档记忆(Archival Memory):
- 无限容量,用于存储不适合核心记忆但重要的反思、洞察等信息,需通过
archival_memory_insert和archival_memory_search函数进行读写和检索。
- 无限容量,用于存储不适合核心记忆但重要的反思、洞察等信息,需通过
-
直觉知识(Intuitive Knowledge):
- 静态但全面的基础知识库,类似 Kahneman 提出的"系统1",为其他记忆系统提供底层支持。
-
工作记忆(Working Memory):
- 有限空间,存储当前对话和任务相关的即时信息,包括身份和共享目标,确保实时响应能力。
2. 记忆操作工具
- 记忆检索 :
conversation_search(检索对话历史)、archival_memory_search(检索归档记忆)。 - 记忆编辑 :
core_memory_append/core_memory_replace(修改核心记忆)、archival_memory_insert(插入归档记忆)。 - 记忆重组 :
rethink_memory/rethink_user_memory用于整合新信息到记忆块,finish_rethinking_memory标记重组完成。 - 记忆存储 :
store_memories用于保存即将超出上下文窗口的对话片段,以语义摘要形式持久化。
3. 实现逻辑
- 不同记忆层级分工明确:核心记忆保证基础上下文,召回记忆覆盖全对话历史,归档记忆扩展长期存储,工作记忆支持即时交互。
- 通过工具函数实现记忆的读写、检索和重组,结合事件驱动(用户消息、定时心跳)触发记忆操作,确保记忆的持续性和一致性。
- 针对不同类型信息(如用户偏好、技术细节、项目进度)采用不同粒度的存储和摘要策略,平衡信息完整性与效率。