摘要
为了防御后门攻击,以往的研究主要集中在使用干净数据在模型部署前去除后门攻击。在本文中,我们研究了利用测试时部分被污染的数据来去除模型中的后门的可能性。为了解决这个问题,我们提出了一种两阶段方法 TTBD。在第一阶段,我们提出了一种后门样本检测方法 DDP,用于从一批混合的、部分被污染的样本中识别出被污染的样本。一旦检测出被污染的样本,我们利用Shapley 估计来计算神经元的重要性贡献,定位受污染的神经元,并对其进行剪枝,以去除模型中的后门。实验表明,TTBD 仅凭一批部分被污染的数据,就能在不同的模型架构和数据集上成功去除后门,并能防御不同类型的后门攻击。
在我们的设定中,防御者可以访问一组混合数据,其中包含干净样本和后门污染样本,即部分被污染的数据。这些污染样本可能有助于去除后门,但准确检测它们是一个重大挑战。此外,由于后门污染样本的检测可能无法做到完全准确,检测出的污染样本中可能会混入一些干净样本,这给后门去除带来了额外的困难。
在后门样本检测方面,TeCo 26 是一种最先进的后门样本检测方法,它利用样本的腐蚀鲁棒性一致性来区分污染样本和干净样本。然而,TeCo 对不同的模型架构非常敏感,在 VGG 32 等架构上无法成功区分污染数据和干净数据,这导致后门去除失败。为了解决这个问题,我们提出了一种新的后门检测方法,称为"剪枝过程中检测"(DDP),该方法可以在不同的模型架构上准确检测污染样本。
在检测出污染数据后,我们提出了一种基于 Shapley 估计的后门清除方法,该方法能够容忍不精确的后门检测。实验表明,我们提出的两阶段后门防御框架 TTBD(Test-Time Backdoor Defense) 仅使用一小批测试时的部分污染样本(100 张图片),就能够成功去除后门,并且在 3 种常见的模型架构和 3 种常见数据集上防御 7 种不同类型的后门攻击,同时仅带来少量的精度下降。
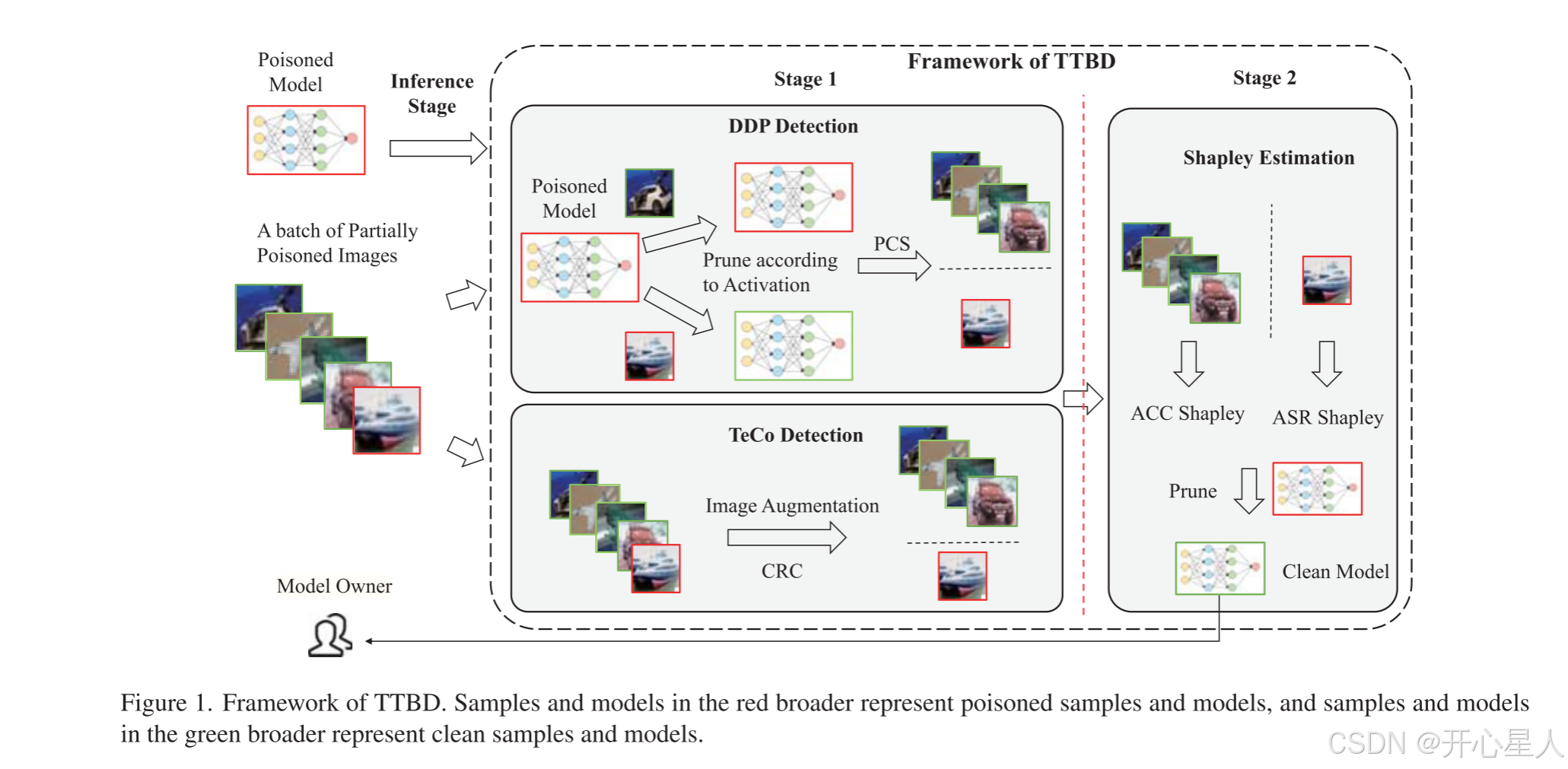
"剪枝过程中检测"(DDP)
之前的后门检测方法TeCo利用了投毒样本和干净样本对图像变换的敏感性差异作为区分它们的手段。根据之前的研究 25,投毒样本和干净样本之间的另一个区别是投毒样本会激活后门神经元,而干净样本则不会。因此,防御者可以利用后门激活的差异来区分投毒样本和干净样本。修剪投毒样本中激活值最高的神经元将有助于去除模型中的后门,并且当防御者获得一批部分投毒样本时,他们可以利用该批次中每个样本的激活值来指导修剪过程,从而去除模型中的后门攻击。对于投毒样本,修剪激活值最高的神经元会导致模型的攻击成功率(ASR)急剧下降,从而导致正常样本和投毒样本的预测发生变化。然而,对于干净样本,修剪激活值最高的神经元只会导致正常样本发生变化。 因此,我们使用预测变化分数(PCS)作为投毒样本检测的指标。投毒样本通常比干净样本表现出更高的PCS

为了防止模型的准确性影响PCS,当模型的准确性下降到某个阈值以下时,修剪会提前停止。基于样本激活值的修剪是去除模型中后门和检测投毒样本的直观方法。然而,在我们的设置中,每次只使用一个样本进行激活估计和投毒神经元定位,这降低了使用投毒样本激活进行后门去除的性能。为了解决这一限制,我们计算了使用整个部分投毒样本批次的神经元的Shapley值,作为对干净样本和后门样本都重要的神经元的指标,并修剪具有最高激活值和最低Shapley值的神经元。这种方法提供了更准确的神经元重要性度量,并能有效地定位投毒神经元。Shapley值的计算及其有效性将在下一节中讨论。
如何在极低投毒率下进行检测?在某些情况下,攻击者可能在推理阶段稀疏地提供后门样本(某些批次完全干净),或者以极低的投毒率进行攻击,以避免防御者的检测。在这些情况下,防御者有能力聚合来自多个批次的图像,然后去除后门。当面对如此少量的投毒实例时,防御者利用TeCo和DDP的组合作为双重检测方法来提高检测的准确性。然后,防御者利用TTBD框架去除模型中的后门。表6中的TTBD-SPARSE表明,当攻击者以极低的投毒率(1%)和稀疏的方式(某些批次完全干净)进行攻击时,防御者通过聚合来自20个批次的图像成功地去除了后门。
使用Shapley值进行后门去除
通常,模型中只有很小一部分神经元作为后门神经元,这些神经元仅在提供投毒样本时被激活。修剪这些投毒神经元后,后门行为将被去除 25。神经元的激活值是在定位投毒神经元时最常用的方法,防御者可以根据神经元的激活值修剪神经元以去除后门 25, 37。然而,神经元的激活值并不准确,一些正常神经元也具有较大的激活值,当样本数量较少时情况会变得更糟。因此,准确地定位投毒神经元至关重要。在本小节中,我们利用Shapley值来定位投毒神经元,并根据它去除后门。
Shapley值。在深度神经网络中,存在成千上万的神经元以及它们之间复杂的相互作用,这使得量化它们对模型输出的贡献变得具有挑战性。Shapley值作为博弈论中的一个重要概念,可以分配每个参与者对结果的贡献 7。Shapley值是通过计算每个参与者的边际值的平均值得到的,玩家 i 的Shapley值表达式如下 2:

估计Shapley值。由于深度神经网络中有成千上万的神经元,直接计算Shapley值是耗时的。为了加快Shapley值的计算,提出了两种Shapley估计加速方法 7, 11。首先是蒙特卡洛估计。从方程3可以看出,Shapley值也可以表示为所有可能顺序中神经元的边际值的平均值,表达式如下 2:

后门去除。上述估计的Shapley值表明了神经元对模型性能的相对重要性,防御者可以利用它来指导神经元修剪。直观上,面对部分投毒样本的情况,防御者利用检测到的投毒样本和原始模型预测的标签来估计模型的ASR Shapley值。尽管Shapley值比模型激活值更准确,但直接修剪具有最高ASR Shapley值的神经元会导致准确率急剧下降 。这是由于检测到的投毒样本可能包含正常样本,并且投毒样本的数量通常较少。为了解决这个问题,我们使用整个样本批次来估计ACC的Shapley值,并选择具有最高ASR Shapley值和最低ACC Shapley值的神经元 。此外,为了防止神经元由于同时具有较大的正边际值和负边际值而导致Shapley值较小,我们改进了方程4,并使用边际值的绝对值的平均值作为绝对Shapley值,表达式如下:
