文章目录
1、前言
- 学习参考书籍以及本文涉及的示例程序:李山文的《Linux驱动开发进阶》
- 本文属于个人学习后的总结,不太具备教学功能。
2、内存管理机制
对于没有MMU的计算机而言,有如下两种常见的方式:位图和链表。
2.1、基于位图的内存管理
即使用bitmap来管理一个内存池。核心思想就是用1bit表示1个内存块的状态,0表示空闲,1表示已占用。假设系统有16个内存块,用两个字节的bitmap来表示就是:0010 1100 0001 1111,即第3、5、6、10、12~16 块已占用,其余空闲。使用bitmap管理小内存块时,其bitmap占用率就会比较高,导致内存利用率变低。
bitmap自身占用计算:


2.2、基于链表的内存管理
使用链表节点来记录内存块信息,如起始地址、大小、使用状态。每分配一个内存块就会产生一个节点,相邻的空闲节点会被合并成一块空闲节点。基于链表的内存一样有缺陷,当频繁分配/释放不同的大小块时,导致空闲内存分散。
2.3、伙伴算法(buddy)
buddy算法可以有效解决上面两种方法的缺点,即不易产生外部碎片,分配和释放内存的速度快,但容易产生内部碎片。可自行查阅了解。
3、MMU
MMU(Memory Management Unit)即内存管理单元。核心功能就是负责虚拟地址和物理地址之间的转换。
首先我们得明确一个结论,无论在用户态使用malloc()还是内核态使用kmalloc(),所返回的地址都是虚拟的,我们是不可能直接通过物理地址操作物理内存的,必须要通过虚拟地址访问物理内存,也就是必须经过MMU。
在32位处理器架构中,每个应用程序(进程)可以访问的虚拟内存空间为 4GB(即 232232 字节),但这并不意味着物理内存真有4GB,而是通过虚拟内存技术实现的抽象。
MMU如何通过虚拟地址找到物理地址?回答是通过页表的方式。
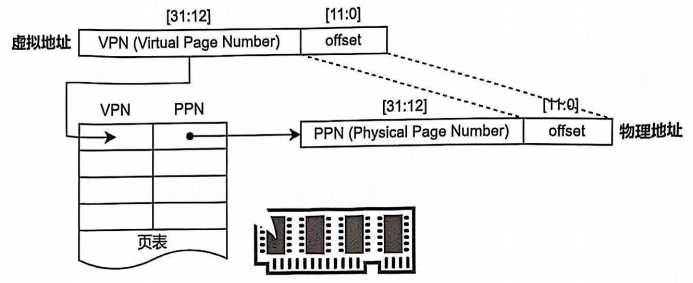
3.1、一级页表
低12位为页内偏移,高20位为虚拟页号。(图片来自李山文的《Linux驱动开发进阶》)
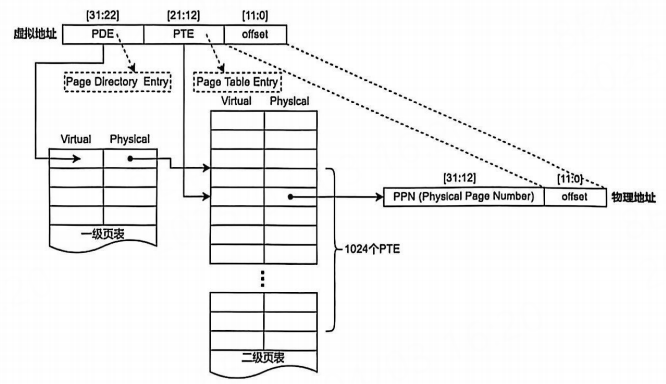
3.1、二级页表
二级页表中,将VPN拆分成了PDE和PTE。(图片来自李山文的《Linux驱动开发进阶》)
PDE(Page Directory Entry):页目录项,用来定位页表(PTE数组)。
PTE(Page Table Entry):页表项,定位物理页帧。
只有一个页目录(Page Directory),一个页目录包含1024个PDE。
每个有效的PDE指向一个页表(Page Table),一个页表包含1024个PTE。
所以理论上有:1024个PDE * 1024个PTE = 1M个PTE。实际上系统会按需分配页表,未使用的虚拟地址区域不分配PTE。
4、内存布局
4.1、内存地址映射
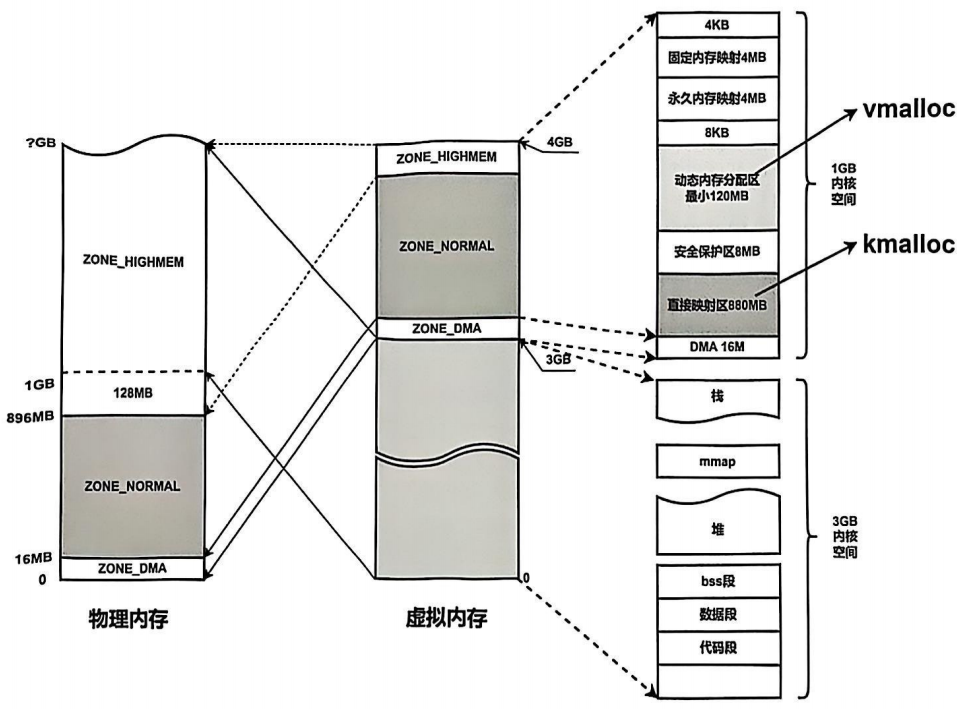
下图是x86架构32位系统中物理地址与虚拟地址映射图。4G的用户空间被划分为1GB内核空间+3GB用户空间。(图片来自李山文的《Linux驱动开发进阶》)
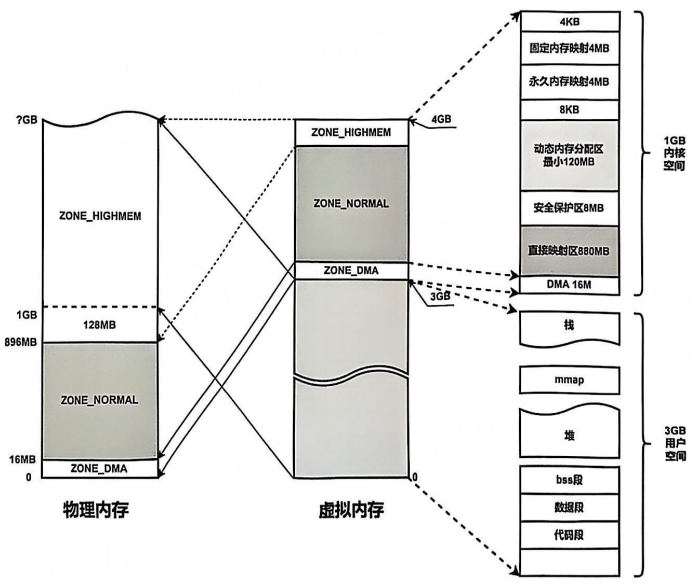
我们先来理解一下这3GB的用户空间和1GB的内核空间到底是干嘛的。首先它们都是虚拟地址。
用户空间的3GB:用于存放应用程序的代码和数据,如代码段,数据段,堆,栈,内存映射(mmap)。
内核空间的1GB:内核代码和数据,设备寄存器(ioremap)和DMA缓冲区,物理内存的直接映射。
而对于1GB的内核空间来说,其被分为三种不同的区域,分别是ZONE_DMA(16MB)、ZONE_NORMAL(880M)和ZONE_HIGHMEM(128MB),其中ZONE_DMA又被称为ZONE_LOWMEM。

我们重点来看看ZONE_HIGHMEM。该区域是一个特殊的内存管理区域,专门用于处理物理内存超过896MB的部分。它的存在是32位架构地址空间限制下的妥协方案,核心目的是让内核能够访问所有物理内存,尽管虚拟地址空间不足。

假设物理内存内有2GB,内核空间如何访问物理内存的2GB-896M=1152MB?答案是,将超出896M的内存划为ZONE_HIGHMEM,动态按需映射。
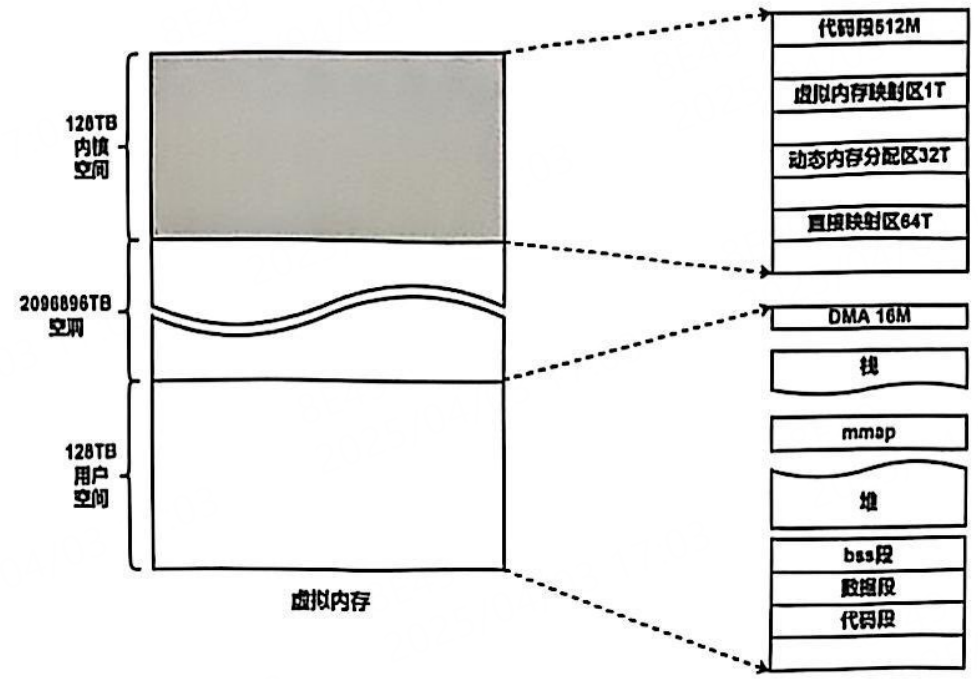
而64位系统取消了ZONE_HIGHMEM,原因是64位系统可表示的虚拟地址空间极大,其内核空间和用户空间都是128TB,内核可以直接线性映射所有物理内存。下图是64位系统虚拟内存映射:(图片来自李山文的《Linux驱动开发进阶》)
5、内存分配
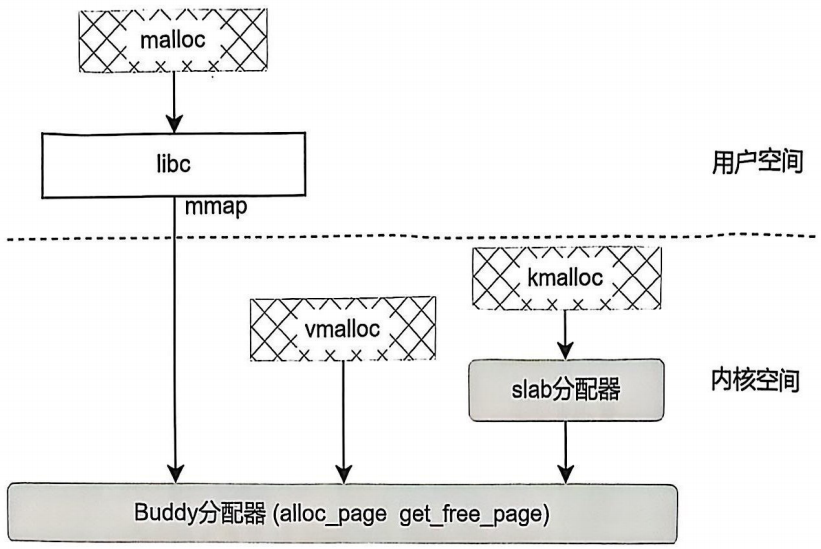
在内核中,主要使用kmalloc和vmalloc分配内存。这两种内存分配方式所使用的内存分配器是不同的。kmalloc使用slab分配器,vmalloc使用buddy分配器(伙伴算法)。
kmalloc:
- 分配物理地址连续的内存块(虚拟内存自然也是连续的)
- 适用于小内存分配(几字节到几MB)
vmalloc:
- 分配虚拟内存连续但物理内存不一定连续的内存块
- 适用于大内存分配
下图展示了malloc、kmalloc、vmalloc分配内存函数的比较:(图片来自李山文的《Linux驱动开发进阶》)
5.1、页分配器
在 Linux 内核中,__alloc_pages 是最底层的页框分配函数,直接由 Buddy System(伙伴系统) 实现,用于分配连续的物理页框。它是内核内存分配的核心,kmalloc、vmalloc 等高层接口最终都会调用它。
函数原型:
c
struct page *__alloc_pages(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask);参数:
gfp_mask:分配标志(如GFP_KERNEL、GFP_ATOMIC),控制分配行为(是否可睡眠、内存区域等)。order:请求的页数(2^order页),如order=0表示 1 页(4KB),order=3表示 8 页(32KB)。zonelist:允许分配的内存区域列表(如ZONE_NORMAL、ZONE_DMA)。nodemask:NUMA 节点掩码(指定从哪个物理节点分配)。
返回值:成功时返回指向第一个 struct page 的指针,失败返回 NULL。
5.2、slab分配器
页分配器每次分配一个页框,默认为4K。slab分配器原理是在页分配器的基础上再细分,将4K的页划分为4个1K的chunk内存块,然后再将1K大小的chunk内存再次划分为更小的slab内存块。
5.3、kmalloc和vmalloc
在 Linux 内核中,kmalloc 和 vmalloc 是两种不同的内存分配机制,它们的主要区别在于:
- 内存来源:
kmalloc使用直接映射区(线性映射区),而vmalloc使用动态映射区(非连续内存区)。 - 物理地址连续性:
kmalloc保证物理地址连续,vmalloc不保证。 - 适用场景:
kmalloc适合小内存、高频分配,vmalloc适合大内存、非频繁操作。 - 在x86架构上,kmalloc函数可以分配最大连续内存块大小默认为128KB(可以通过内核配置修改)。vmalloc默认的最大连续内存块大小是通常的体系结构的页大小,一般为4KB(可以通过内核配置修改)。
(下图来自李山文的《Linux驱动开发进阶》)
5.4、mmap机制
5.4.1、共享文件映射
略,自主查阅。
共享文件映射用的最多。主要目的是将文件映射到内存中,不适合用read/write操作,如控制lcd设备节点/dev/fb0。
5.4.2、共享匿名映射
略,自主查阅。
主要用于进程间共享内存。操作/dev/zero设备节点,并对其mmap。另一个线程也是如此。但是要注意临界资源的访问。
5.4.3、私有文件映射
略,自主查阅。
5.4.4、私有匿名映射
略,自主查阅。
5.4.5、内核中的mmap
下面示例程序来自李山文的《Linux驱动进阶开发》,展示了在内核中如何实现mmap驱动。
c
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <asm/io.h>
#include <asm/uaccess.h>
#include <linux/device.h>
#include <linux/cdev.h>
#include <linux/mm.h>
#include <linux/slab.h>
struct dummy_test {
struct device *dev;
void *buffer_addr;
dev_t dummy_dev_num;
struct cdev dummy_cdev;
struct class *dummy_class;
struct device *dummy_dev;
//...
};
static void dev_test_release(struct device *dev)
{
}
//作者这里增加一个设备仅仅是为了方便管理结构体
static struct device dev_mmap_test = {
.init_name = "mmap_test",
.release = dev_test_release,
};
static int dummy_open(struct inode *inode, struct file *filep)
{
filep->private_data = container_of(inode->i_cdev, struct dummy_test, dummy_cdev);
return 0;
}
static int dummy_mmap(struct file *file, struct vm_area_struct *vma)
{
struct dummy_test *demo = file->private_data;
unsigned long start = vma->vm_start;
unsigned long size = vma->vm_end - vma->vm_start;
unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;
unsigned long phy;
dev_dbg(demo->dev, "create mmap region\n");
//合法性检查
if ((size != PAGE_SIZE) || (offset & ~PAGE_MASK)) {
dev_err(demo->dev, "invalid params for mmap region\n");
return -EINVAL;
}
/* 获得物理地址 */
phy = virt_to_phys(demo->buffer_addr);
/* 是否使用 cache, buffer */
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
/* 开始创建映射内存区域 */
if (remap_pfn_range(vma, start, phy >> PAGE_SHIFT, size, vma->vm_page_prot)) {
printk(KERN_ERR "mmap: remap_pfn_range failed\n");
return -ENOBUFS;
}
return 0;
}
static ssize_t dummy_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
int ret;
struct dummy_test *demo = file->private_data;
ret = copy_to_user(buf, demo->buffer_addr, count&(PAGE_SIZE-1));
if( ret != 0) {
return -EFAULT;
}
return count&(PAGE_SIZE-1);
}
static ssize_t dummy_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
int ret;
struct dummy_test *demo = file->private_data;
ret = copy_from_user(demo->buffer_addr, buf, count&(PAGE_SIZE-1));
if( ret != 0) {
return -EFAULT;
}
return count&(PAGE_SIZE-1);
}
static int dummy_close(struct inode *inode, struct file *filep)
{
filep->private_data = NULL;
return 0;
}
static const struct file_operations dummy_fops = {
.owner = THIS_MODULE,
.open = dummy_open,
.read = dummy_read,
.write = dummy_write,
.mmap = dummy_mmap,
.release = dummy_close,
};
static ssize_t mmap_data_read(struct device *dev,
struct device_attribute *attr, char *buf)
{
struct dummy_test *demo = dev_get_drvdata(dev);
return sprintf(buf, "%s", (char*)demo->buffer_addr);
}
static ssize_t mmap_data_write(struct device *dev,
struct device_attribute *attr, const char *buf, size_t size)
{
struct dummy_test *demo = dev_get_drvdata(dev);
sprintf(demo->buffer_addr, "%s", buf);
return size;
}
static DEVICE_ATTR(data, 0644, mmap_data_read, mmap_data_write);
static int __init dymmy_mmap_init(void)
{
int ret;
struct device *dev = &dev_mmap_test;
struct dummy_test *demo = NULL;
ret = device_register(&dev_mmap_test);
if(ret)
{
printk(KERN_ERR "dev_mmap_test register error!\n");
return ret;
}
demo = kmalloc(sizeof(struct dummy_test), GFP_KERNEL);
if (demo == NULL) {
dev_err(dev, "alloc buffer failed!\n");
return -1;
}
ret = alloc_chrdev_region(&demo->dummy_dev_num ,0, 1, "dummy"); //动态申请一个设备号
if(ret !=0) {
dev_err(dev, "alloc_chrdev_region failed!\n");
return -1;
}
demo->dummy_cdev.owner = THIS_MODULE;
cdev_init(&demo->dummy_cdev, &dummy_fops);
cdev_add(&demo->dummy_cdev, demo->dummy_dev_num, 1);
demo->dummy_class = class_create(THIS_MODULE, "dummy_class");
if(demo->dummy_class == NULL) {
dev_err(dev, "dummy_class failed!\n");
return -1;
}
demo->dummy_dev = device_create(demo->dummy_class, NULL, demo->dummy_dev_num, NULL, "dummy");
if(IS_ERR(demo->dummy_dev)) {
dev_err(dev, "device_create failed!\n");
return -1;
}
demo->buffer_addr = kmalloc(PAGE_SIZE, GFP_KERNEL);
if(demo->buffer_addr == NULL) {
dev_err(dev, "alloc file buffer failed!\n");
return -1;
}
dev_set_drvdata(dev, demo);
demo->dev = dev;
device_create_file(dev, &dev_attr_data);
return 0;
}
static void __exit dymmy_mmap_exit(void)
{
struct dummy_test *demo = dev_get_drvdata(&dev_mmap_test);
cdev_del(&demo->dummy_cdev);
unregister_chrdev_region(demo->dummy_dev_num, 1);
device_destroy(demo->dummy_class, demo->dummy_dev_num);
class_destroy(demo->dummy_class);
kfree(demo);
device_unregister(&dev_mmap_test);
}
module_init(dymmy_mmap_init);
module_exit(dymmy_mmap_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("1477153217@qq.com");
MODULE_VERSION("0.1");
MODULE_DESCRIPTION("mmap test"); 重点的东西有两个,都集中在dummy_mmap()函数中,一个是形参struct vm_area_struct结构体,用来描述用户进程虚拟内存区域的结构体。一个是remap_pfn_range()函数,该函数将物理地址映射到用户虚拟地址空间:
c
static int dummy_mmap(struct file *file, struct vm_area_struct *vma)
{
...
/* 开始创建映射内存区域 */
if (remap_pfn_range(vma, start, phy >> PAGE_SHIFT, size, vma->vm_page_prot)) {
printk(KERN_ERR "mmap: remap_pfn_range failed\n");
return -ENOBUFS;
}
return 0;
}下面是对应的应用程序:
c
#include <stdio.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
int fd;
char *map;
// 打开文件
fd = open(argv[1], O_RDWR);
if (fd == -1) {
perror("open failed\n");
return 1;
}
// 创建内存映射, 注意:这里映射一个内核PAGE内存,即4096字节
map = mmap(NULL, 4096, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (map == MAP_FAILED) {
perror("mmap failed\n");
return 1;
}
// 对映射的文件进行操作
printf("data: %s\n", map);
// 修改映射的文件内容
map[0] = 'H';
map[1] = 'e';
map[2] = 'l';
map[3] = 'l';
map[4] = 'o';
// 解除内存映射
if (munmap(map, 4096) == -1) {
perror("munmap failed\n");
return 1;
}
// 关闭文件
if (close(fd) == -1) {
perror("close failed\n");
return 1;
}
return 0;
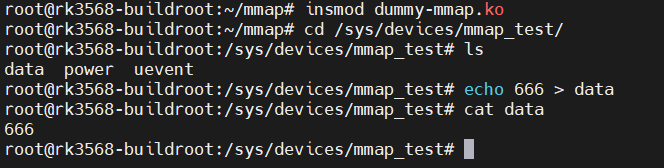
}加载ko文件,首先使用属性文件进行读写测试:
使用应用程序对设备节点进行读写测试:

6、DMA
- 申请dma通道
c
/**
* dma_request_chan - try to allocate an exclusive slave channel
* @dev: pointer to client device structure
* @name: slave channel name
*
* Returns pointer to appropriate DMA channel on success or an error pointer.
*/
struct dma_chan *dma_request_chan(struct device *dev, const char *name)- 申请用于DMA传输的内存。在上面我们了解过内核空间中有一块ZONE_DMA区域,我们需要使用专门的函数来申请DMA内存。
申请内存一致性DMA映射:
c
static inline void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp)
{
return dma_alloc_attrs(dev, size, dma_handle, gfp,
(gfp & __GFP_NOWARN) ? DMA_ATTR_NO_WARN : 0);
}申请流式DMA映射:
c
dma_addr_t dma_map_single(struct device *dev, void *ptr,
size_t size, enum dma_data_direction dir)申请分散聚合DMA映射:
c
// struct scatterlist 用来描述内核中的分散聚合表
dma_addr_t dma_map_sg(struct device *dev, struct scatterlist *sg, int nents,
enum dma_data_direction dir)- 配置DMA
c
static inline int dmaengine_slave_config(struct dma_chan *chan,
struct dma_slave_config *config)
{
if (chan->device->device_config)
return chan->device->device_config(chan, config);
return -ENOSYS;
}- 获取DMA描述符
获取流式DMA映射传输描述符:
c
static inline struct dma_async_tx_descriptor *dmaengine_prep_slave_single(
struct dma_chan *chan, dma_addr_t buf, size_t len,
enum dma_transfer_direction dir, unsigned long flags)
{
struct scatterlist sg;
sg_init_table(&sg, 1);
sg_dma_address(&sg) = buf;
sg_dma_len(&sg) = len;
if (!chan || !chan->device || !chan->device->device_prep_slave_sg)
return NULL;
return chan->device->device_prep_slave_sg(chan, &sg, 1,
dir, flags, NULL);
}获取分散聚合DMA映射传输描述符:
c
static inline struct dma_async_tx_descriptor *dmaengine_prep_slave_sg(
struct dma_chan *chan, struct scatterlist *sgl, unsigned int sg_len,
enum dma_transfer_direction dir, unsigned long flags)
{
if (!chan || !chan->device || !chan->device->device_prep_slave_sg)
return NULL;
return chan->device->device_prep_slave_sg(chan, sgl, sg_len,
dir, flags, NULL);
}获取内存一致性DMA映射传输描述符:
c
static inline struct dma_async_tx_descriptor *dmaengine_prep_dma_cyclic(
struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,
size_t period_len, enum dma_transfer_direction dir,
unsigned long flags)
{
if (!chan || !chan->device || !chan->device->device_prep_dma_cyclic)
return NULL;
return chan->device->device_prep_dma_cyclic(chan, buf_addr, buf_len,
period_len, dir, flags);
}- 提交DMA描述符
c
static inline dma_cookie_t dmaengine_submit(struct dma_async_tx_descriptor *desc)
{
return desc->tx_submit(desc);
}- 开启数据传输
c
/**
* dma_async_issue_pending - flush pending transactions to HW
* @chan: target DMA channel
*
* This allows drivers to push copies to HW in batches,
* reducing MMIO writes where possible.
*/
static inline void dma_async_issue_pending(struct dma_chan *chan)
{
chan->device->device_issue_pending(chan);
}6.1、示例
书籍的DMA示例程序可以参考李山文的《Linux驱动进阶开发》。
后续我会基于这篇《在ARM Linux应用层下使用SPI驱动WS2812》文章,实现在Linux应用层下使用SPI + DMA的方式驱动WS2812。