声明:
本文基于哔站博主【Shusenwang】的视频课程【RNN模型及NLP应用】,结合自身的理解所作,旨在帮助大家了解学习NLP自然语言处理基础知识。配合着视频课程学习效果更佳。
材料来源:【Shusenwang】的视频课程【RNN模型及NLP应用】
视频链接:RNN模型与NLP应用(8/9):Attention (注意力机制)_哔哩哔哩_bilibili
一、学习目标
1.掌握Attention注意力机制的基本逻辑
2.清楚Attention注意力机制的实际意义
二、注意力机制
(1)首先我们来回顾一下上节课我们学到的Sequence to Sequence模型:
Sequence to Sequence模型有一个编码器Encoder和一个解码器Decoder。
Encoder将原来的英语文本逐字记录,在最后一个状态向量h和传输带C中记录下整个英语子的信息。而最后一个状态向量h和传输带C,将会作为解码器Decoderde初始化状态向量,使得Decoder获取原英文文本的所有信息,然后Decoder就像是一个文本生成i器一样逐字生成的与文本。详细过程如图:
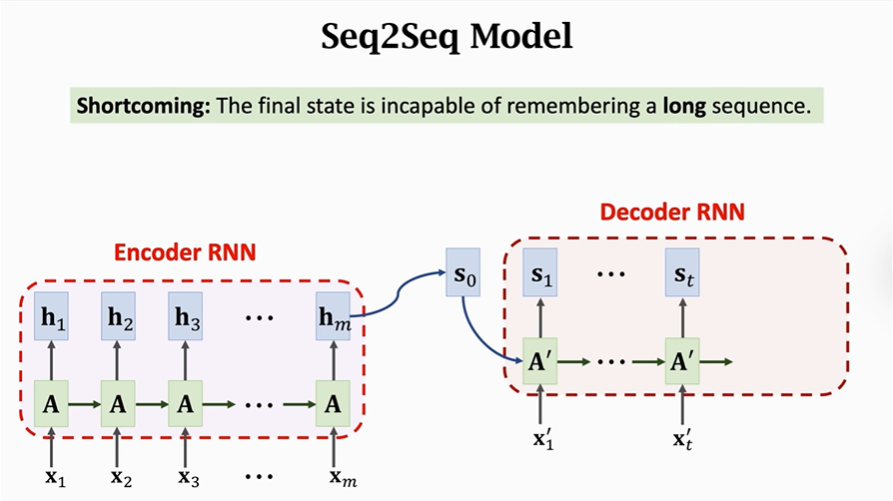
但是:Sequence to Sequence 模型有一个明显的缺陷,要是输入的句子很长,那么Encoder模型就有可能无法将输入的句子全部记忆下来,从而使得Encoder最后一个状态向量漏掉句子中的某些信息,那么Decoder就不能产生争取的翻译。
如果你拿Sequence to Sequence 模型来做机器翻译,那么你就会得到这样的一个图片:
横轴是输入信息长度
纵轴是BLUE score,BLUE score是评价机器翻译好坏的标准。BLUE越高说明机器翻译越准确。
如果**【不用Attention】那么你得到的就是图中++蓝色的线++**,随着翻译句子的长度增加,翻译准确度先升高再降低。
如果**【用Attention】那么你就会得到图中++红色曲线++**,翻译准确度会一直保持很高

(2)用Attention改进Seq2Seq模型
1.前提须知:
①用了Attention,Decoder每次更新状态的时候会再看一遍Encoder的所有状态,这样就不会遗忘。
②Attention还会告诉Decoder应该关注Encoder哪些状态
③Attention可以大幅提升准确率,但是计算量却很大
2.Attention+Seq2Seq
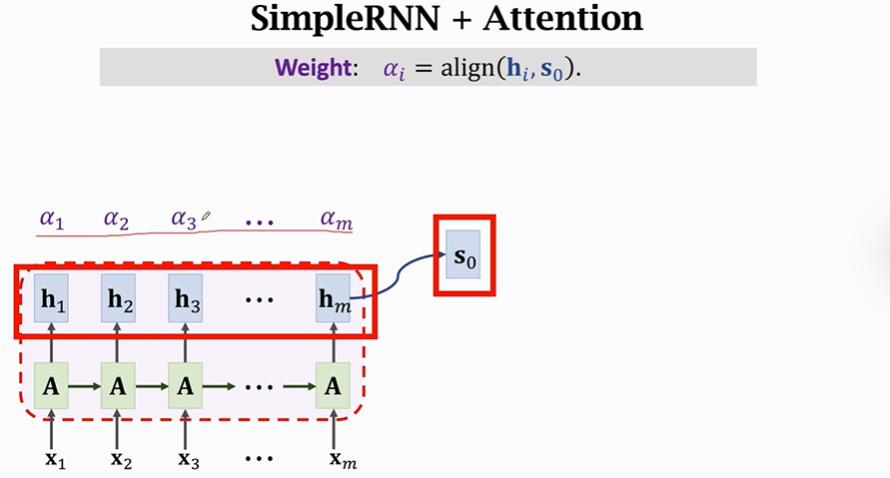
Weight: 𝛼i = align( 𝐡i , 𝐬0 ):
该公式计算Encoder第i个状态和Decoder当前状态的相关性,把结果记为𝛼i(即权重weight),Encoder有m个状态,是一共算出m个𝛼。𝛼i都是介于0到1之间的实数,所有𝛼之和为1。
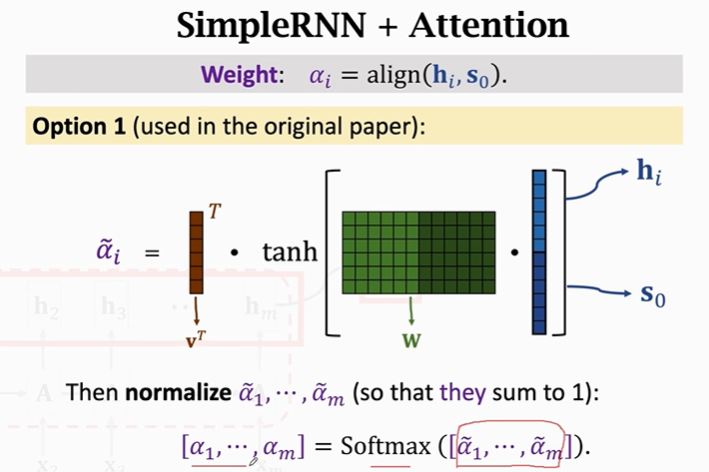
3.如何计算Attention?:
【方法一】:
这里的v和W都是参数矩阵,需要从训练数据中获得。
【方法二】:这种方法更常用

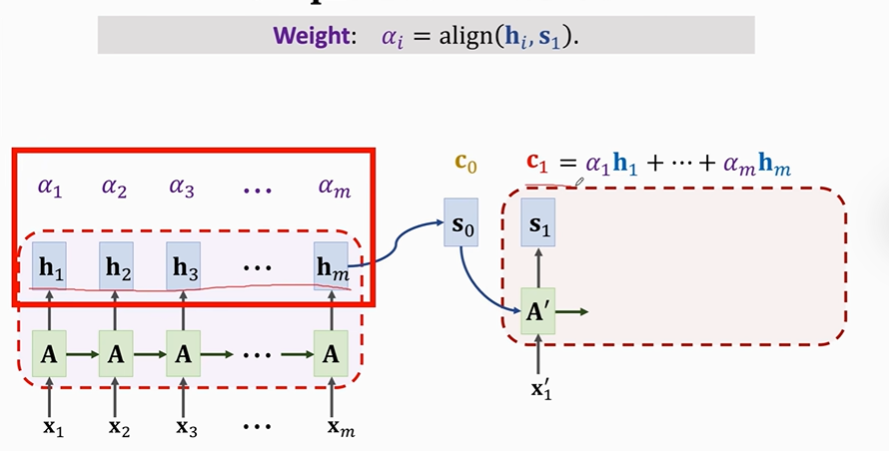
【next】将对应的h与α相乘求加权平均,最终获得C0,我门吧C0称作Contect vector。
每一个C都会对应一个S。C0对应S0
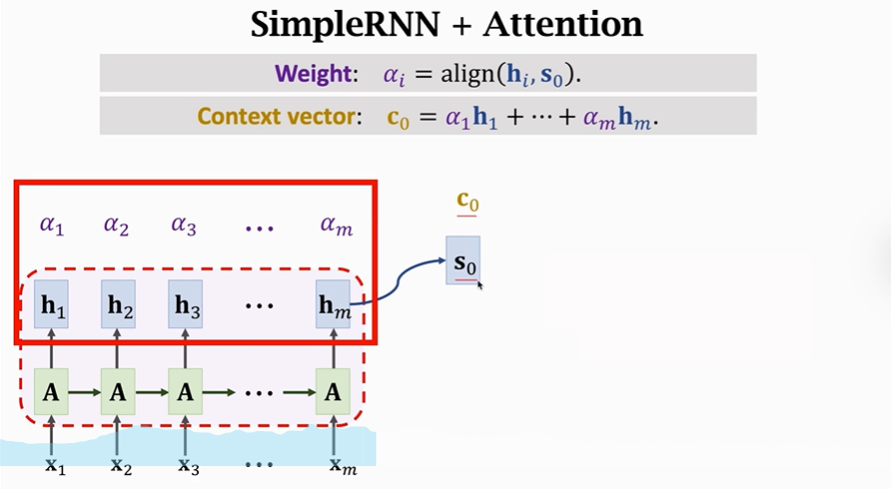
更新状态S和C
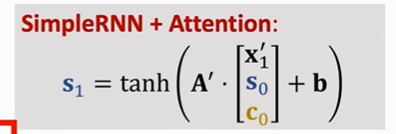
这是S1的更新公式:
计算过程中需要前一个S0和前一个C0。
这是C1的更新公式:
计算过程中的αi与之前的αi不一样。
这里的αi是由所有h和Decoder当前状态S1相乘做加权平均得来的。
以此类推:
C2计算过程:
C3计算过程:
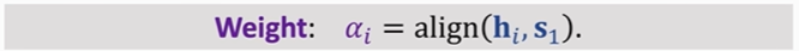
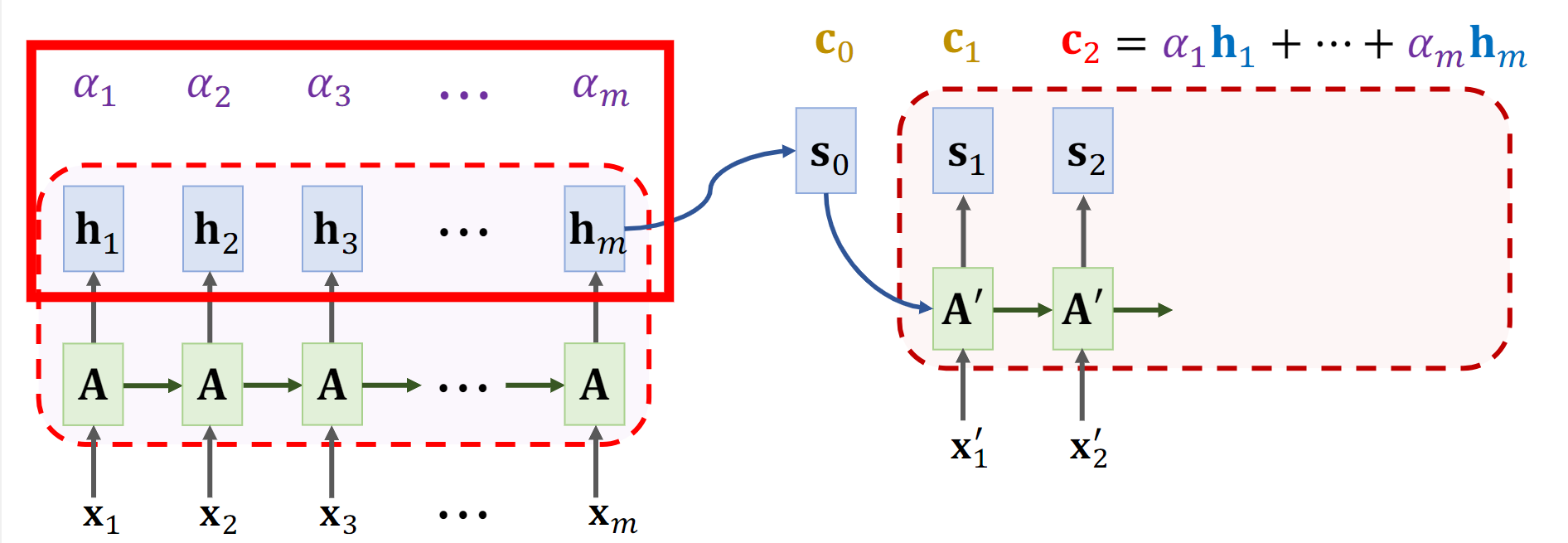
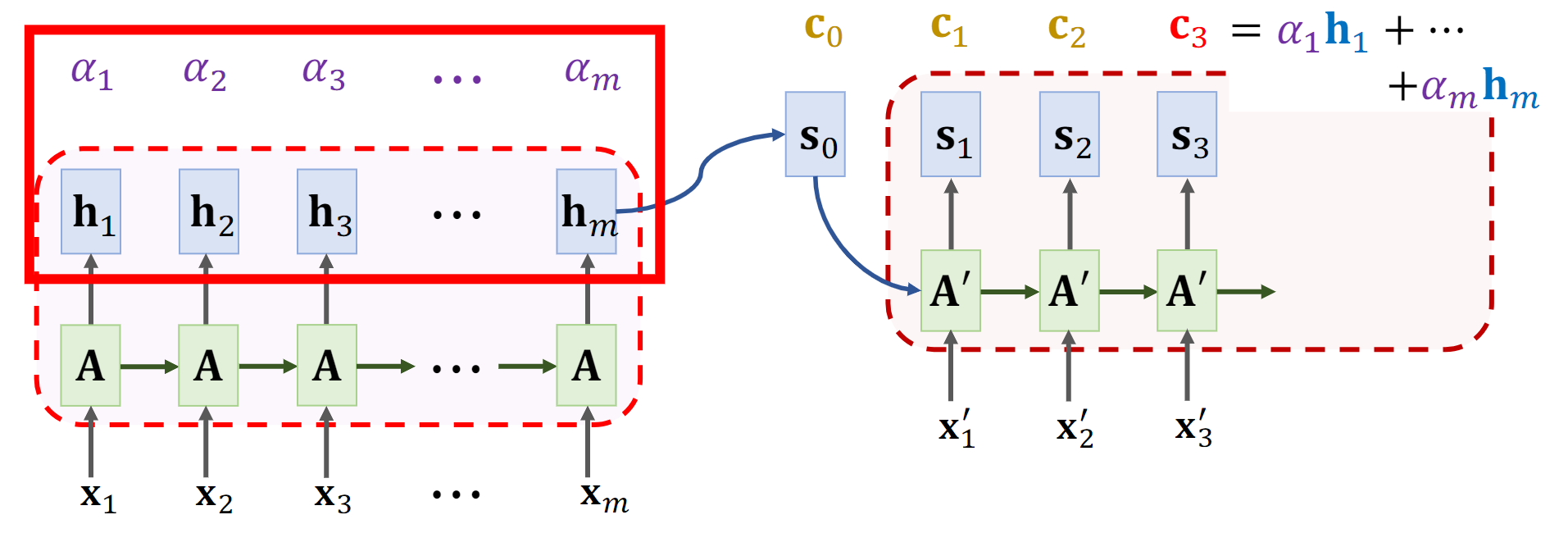
【特别注意】每一次计算过程中的αi与前一步计算的αi都不一样。
【思考】:在这个计算过程中有多少个αi?

假设Encoder计算了m个步骤,Decoder计算了t个步骤。那么全部权重α数量为mt。这个时间复杂度非常高。虽然Attention避免遗忘,大幅提高准确率,但是代价是巨大的计算。
4.Attention的实际意义
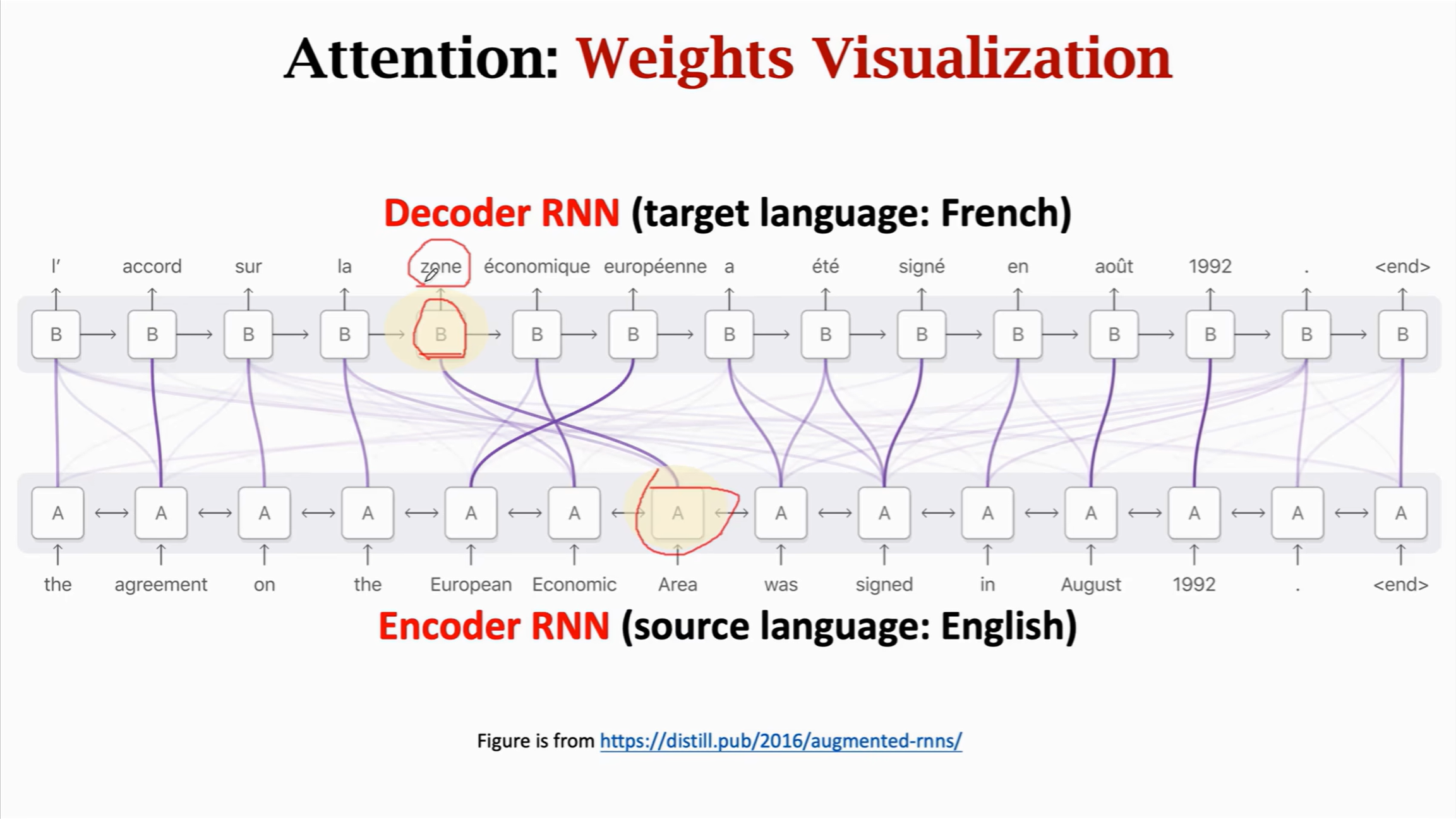
图中
上面一行代表Decoder的每一个状态向量,下面一行代表着Encoder的每一个状态向量
每条线代表着他们的对应相关性即权重α。线越粗代表权重关系很大,线越细代表权重关系很小。
以上图标黄的两个状态为例:法语zone和英语Area之间的线很粗,则说明二者之间相关性很大。这条线有很直观地解释------法语zone就是英语Area,所以这两个状态的相似度很高。
每当Decoder想要生成一个状态的时候都会看一遍Encoder的所有状态,这些权重α会告诉Deocder应该关注哪些地方。
三、总结

1.标准的Seq2Seq模型是根据当前状态来产生下一个状态
2.如果使用Attention,Decoder在产生下一个状态的时候会先看一遍Ecoder里所有的向量。
3.Attention会告诉Decoder应该重点关注Encoder的哪些状态
4.Attention可以大幅提升Seq2Seq模型的表现,但是要耗费大量的计算