"人工智能的未来不在于更大的模型,而在于更智能的推理与行动。" ------ 当我们谈论AI Agent时,ReAct框架无疑是这场智能革命的先锋。
🎯 引言:从被动响应到主动思考的跨越
想象一下,如果你的AI助手不再是一个只会回答问题的"聊天机器人",而是一个能够像人类一样思考、规划、行动的智能伙伴,那会是怎样的体验?这不是科幻小说的情节,而是ReAct(Reasoning and Acting)框架正在实现的现实。
在大语言模型(LLM)席卷全球的今天,我们见证了ChatGPT、GPT-4等模型在文本生成和理解方面的惊人能力。然而,这些模型本质上仍然是"被动"的------它们只能根据输入生成输出,缺乏主动探索和与环境交互的能力。ReAct框架的出现,彻底改变了这一现状,它让AI真正具备了"思考"和"行动"的能力。
🧠 ReAct的核心理念:模拟人类认知过程
人类智能的独特之处
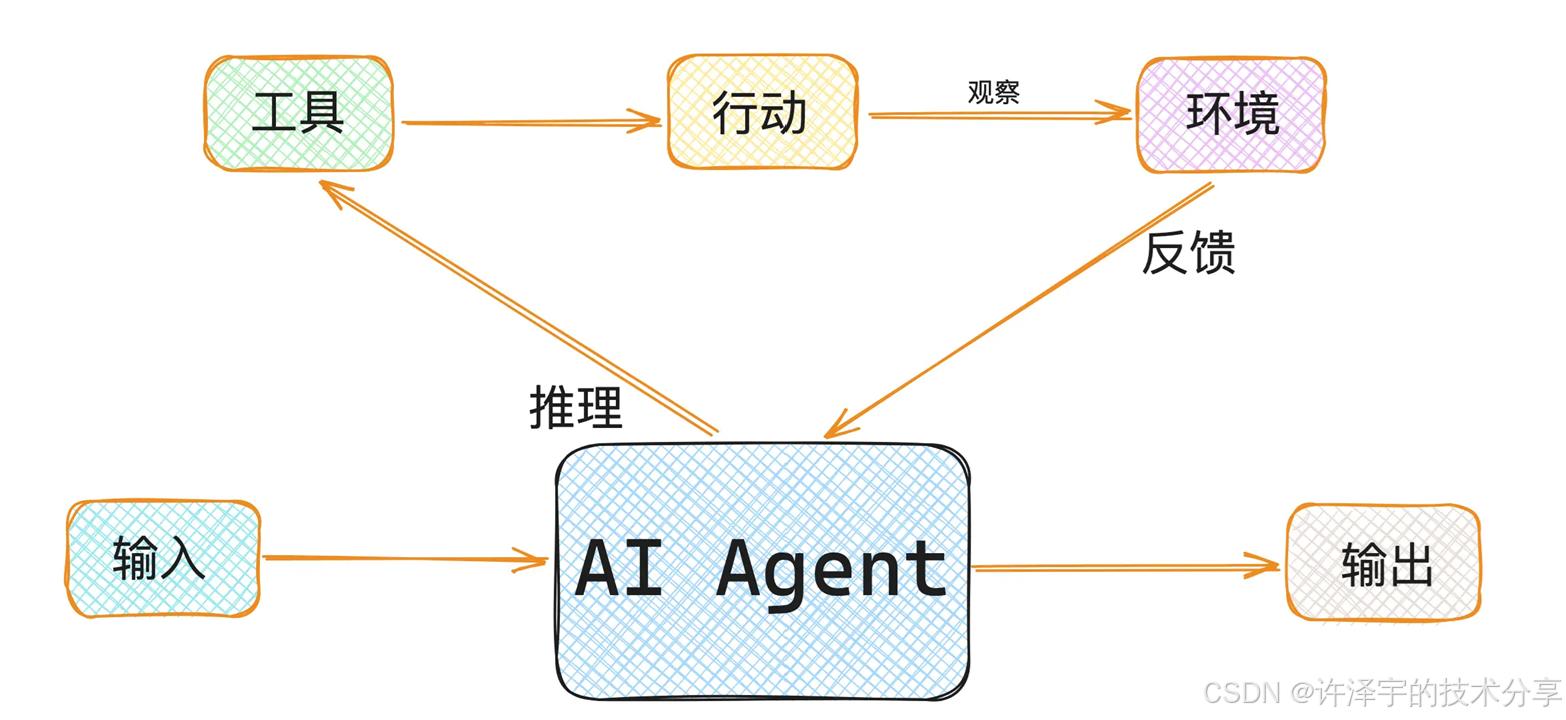
人类智能的一个独特特征是能够将任务导向的行为与言语推理无缝结合。当我们面对复杂问题时,大脑会自然地进行以下过程:
-
感知环境:通过感官系统收集信息
-
分析思考:在大脑中进行推理和规划
-
采取行动:基于分析结果执行具体操作
-
观察反馈:评估行动结果,调整后续策略
这种"思考-行动-观察"的循环模式,正是ReAct框架的核心灵感来源。
ReAct的革命性创新
ReAct(Reasoning and Acting)框架由来自普林斯顿大学和谷歌的研究团队在2022年提出,其核心思想是让大语言模型能够交替生成推理轨迹(Thought)和特定任务的行动(Action),从而实现两者之间更大的协同作用。
ReAct的核心公式可以表示为:
Thought → Action → Observation → Thought → Action → ... → Final Answer这个看似简单的循环,却蕴含着深刻的智能原理:
-
Thought(思考):模型分析当前情况,制定下一步计划
-
Action(行动):执行具体操作,如搜索、计算、调用工具等
-
Observation(观察):获取行动结果,为下一轮思考提供依据
🔧 ReAct的技术架构:四大核心组件
1. 思维链(Chain of Thought)
思维链是ReAct框架的"大脑",负责将复杂任务分解为多个可执行的步骤。与传统的CoT(Chain-of-Thought)不同,ReAct的思维链不仅包含推理过程,还能指导具体的行动决策。
示例:
用户问题:"2024年周杰伦最新演唱会的时间和地点是什么?"
Thought 1: 用户想了解周杰伦2024年的最新演唱会信息,我需要搜索最新的相关资料。
Action 1: search["周杰伦 2024 演唱会 最新"]
Observation 1: 搜索结果显示多个关于周杰伦2024年演唱会的网页...
Thought 2: 搜索结果较多,我需要查看具体的演唱会信息页面。
Action 2: lookup["演唱会时间地点"]
Observation 2: 找到具体信息:2024年12月在台北小巨蛋举办...
Thought 3: 现在我有了准确的信息,可以回答用户的问题了。
Final Answer: 根据最新信息,周杰伦2024年最新演唱会将于12月在台北小巨蛋举行。2. 推理模块(Reasoning)
推理模块是ReAct的"智慧中枢",负责分析输入数据、理解上下文、制定策略。它不仅要理解用户的意图,还要根据当前状态决定最优的行动方案。
推理模块的关键能力:
-
上下文理解:准确把握问题的核心需求
-
策略规划:制定多步骤的解决方案
-
动态调整:根据反馈信息调整策略
-
错误处理:识别并纠正执行过程中的错误
3. 行动模块(Action)
行动模块是ReAct的"执行引擎",负责将推理结果转化为具体的操作。这些操作可能包括:
-
信息检索:搜索网络、查询数据库
-
工具调用:使用计算器、代码执行器等
-
API交互:调用第三方服务接口
-
文件操作:读写文件、处理数据
行动模块的设计原则:
class ActionModule:
def __init__(self):
self.available_tools = {
'search': self.web_search,
'calculate': self.calculator,
'code_execute': self.code_runner,
'file_read': self.file_reader
}
def execute_action(self, action_type, parameters):
if action_type in self.available_tools:
return self.available_tools[action_type](parameters)
else:
return "Unknown action type"4. 观察模块(Observation)
观察模块是ReAct的"感知系统",负责收集和处理行动执行后的反馈信息。它不仅要获取结果数据,还要评估行动的成功程度,为下一轮推理提供准确的输入。
观察模块的核心功能:
-
结果收集:获取行动执行的直接结果
-
状态评估:判断当前任务的完成程度
-
异常检测:识别执行过程中的错误或异常
-
信息过滤:提取对后续推理有用的关键信息
💻 ReAct的实现:从理论到实践
LangChain中的ReAct实现
LangChain作为最流行的LLM应用开发框架,提供了完整的ReAct Agent实现。让我们通过一个完整的代码示例来理解ReAct的工作原理:
from langchain import hub
from langchain.agents import create_react_agent, AgentExecutor
from langchain.tools import BaseTool
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
# 1. 初始化大语言模型
llm = ChatOpenAI(
model="gpt-4",
temperature=0,
openai_api_key="your-api-key"
)
# 2. 定义自定义工具
class CalculatorTool(BaseTool):
name = "calculator"
description = "用于执行数学计算的工具"
def _run(self, expression: str) -> str:
try:
result = eval(expression)
return f"计算结果:{result}"
except Exception as e:
return f"计算错误:{str(e)}"
class WebSearchTool(BaseTool):
name = "web_search"
description = "用于搜索网络信息的工具"
def _run(self, query: str) -> str:
# 这里可以集成真实的搜索API
return f"搜索'{query}'的结果:[模拟搜索结果]"
# 3. 创建工具列表
tools = [CalculatorTool(), WebSearchTool()]
# 4. 创建ReAct Agent
react_prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, react_prompt)
# 5. 创建Agent执行器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
# 6. 执行任务
result = agent_executor.invoke({
"input": "请帮我计算 (25 * 4) + (100 / 5) 的结果,然后搜索这个数字的数学意义"
})
print(result["output"])ReAct的执行流程解析
当我们运行上述代码时,ReAct Agent会按照以下流程执行:
输入:"请帮我计算 (25 * 4) + (100 / 5) 的结果,然后搜索这个数字的数学意义"
Thought: 我需要先计算这个数学表达式,然后搜索结果的数学意义。
Action: calculator
Action Input: (25 * 4) + (100 / 5)
Observation: 计算结果:120
Thought: 现在我得到了结果120,接下来需要搜索这个数字的数学意义。
Action: web_search
Action Input: 120 数学意义 数学性质
Observation: 搜索'120 数学意义 数学性质'的结果:[关于120的数学性质信息]
Thought: 现在我有了完整的信息,可以给出最终答案。
Final Answer: 计算结果是120。120是一个高度合成数,具有丰富的数学性质...🌟 ReAct的核心优势:为什么它如此重要?
1. 突破传统LLM的局限性
传统的大语言模型存在几个关键问题:
-
知识截止:训练数据有时间限制,无法获取最新信息
-
幻觉问题:可能生成看似合理但实际错误的内容
-
计算能力有限:在精确计算方面表现不佳
-
缺乏实时交互:无法与外部环境进行动态交互
ReAct框架通过引入外部工具和实时交互能力,有效解决了这些问题。
2. 增强可解释性和可控性
ReAct的"思考-行动-观察"模式使得AI的决策过程变得透明可见:
传统LLM:
输入 → [黑盒处理] → 输出
ReAct框架:
输入 → 思考1 → 行动1 → 观察1 → 思考2 → 行动2 → 观察2 → ... → 输出这种透明性带来了巨大的价值:
-
调试友好:可以清楚地看到每一步的推理过程
-
错误定位:容易识别问题出现在哪个环节
-
人工干预:可以在任何步骤进行人工调整
-
信任建立:用户能够理解AI的决策依据
3. 灵活的工具集成能力
ReAct框架的模块化设计使得集成各种外部工具变得极其简单:
# 数学计算工具
class MathTool(BaseTool):
name = "math_calculator"
description = "执行复杂数学计算"
# 代码执行工具
class CodeExecutor(BaseTool):
name = "code_runner"
description = "执行Python代码"
# 数据库查询工具
class DatabaseTool(BaseTool):
name = "db_query"
description = "查询数据库信息"
# 图像生成工具
class ImageGenerator(BaseTool):
name = "image_gen"
description = "生成图像内容"4. 自适应学习能力
ReAct框架具备强大的自适应能力,能够根据任务需求动态调整策略:
-
任务识别:自动识别任务类型,选择合适的工具
-
策略优化:根据执行结果调整后续行动
-
错误恢复:当某个行动失败时,能够尝试替代方案
-
经验积累:通过多次执行积累经验,提高效率
🎯 ReAct的实际应用场景
1. 智能客服系统
在客服场景中,ReAct Agent能够:
# 客服场景示例
user_query = "我的订单什么时候能到?订单号是12345"
# ReAct处理流程:
# Thought: 用户询问订单状态,我需要查询订单信息
# Action: query_order_status
# Action Input: order_id=12345
# Observation: 订单状态:已发货,预计明天到达
#
# Thought: 我已经获得了订单信息,可以回答用户问题
# Final Answer: 您的订单12345已经发货,预计明天就能到达。2. 数据分析助手
在数据分析场景中,ReAct能够自动化完成复杂的分析任务:
# 数据分析场景
analysis_request = "分析最近一个月的销售数据,找出增长最快的产品类别"
# ReAct处理流程:
# Thought: 需要获取最近一个月的销售数据并进行分析
# Action: fetch_sales_data
# Action Input: period="last_month"
# Observation: 获得销售数据...
#
# Thought: 现在需要按产品类别分组并计算增长率
# Action: analyze_growth_rate
# Action Input: data=sales_data, group_by="category"
# Observation: 分析结果显示电子产品类别增长最快...3. 教育辅导系统
ReAct在教育领域的应用展现了其强大的个性化能力:
# 教育场景示例
student_question = "我不理解二次函数的图像特征"
# ReAct处理流程:
# Thought: 学生对二次函数图像有疑问,我需要提供详细解释和可视化
# Action: generate_function_graph
# Action Input: function="y = x^2"
# Observation: 生成了二次函数图像...
#
# Thought: 现在我需要解释图像的关键特征
# Action: explain_graph_features
# Action Input: graph_type="quadratic"
# Observation: 获得了详细的特征解释...4. 代码开发助手
ReAct在软件开发中的应用正在改变程序员的工作方式:
# 开发场景示例
development_task = "帮我写一个Python函数来计算斐波那契数列"
# ReAct处理流程:
# Thought: 用户需要一个计算斐波那契数列的Python函数
# Action: generate_code
# Action Input: task="fibonacci function", language="python"
# Observation: 生成了函数代码...
#
# Thought: 我需要测试这个函数是否正确工作
# Action: test_code
# Action Input: code=generated_code, test_cases=[1,5,10]
# Observation: 测试通过,函数工作正常...📊 ReAct与其他AI框架的对比分析
ReAct vs 传统CoT(Chain of Thought)
| 特性 | 传统CoT | ReAct |
|---|---|---|
| 推理方式 | 纯文本推理 | 推理+行动结合 |
| 信息来源 | 模型内部知识 | 外部工具+实时数据 |
| 可验证性 | 难以验证 | 每步可验证 |
| 错误处理 | 错误传播 | 动态纠错 |
| 适用场景 | 逻辑推理题 | 复杂实际任务 |
ReAct vs Function Calling
| 特性 | Function Calling | ReAct |
|---|---|---|
| 调用方式 | 一次性调用 | 多轮交互调用 |
| 推理能力 | 有限 | 强大的多步推理 |
| 灵活性 | 相对固定 | 高度灵活 |
| 复杂度 | 简单 | 复杂但功能强大 |
ReAct vs Planning-based Agents
| 特性 | Planning-based | ReAct |
|---|---|---|
| 规划方式 | 预先制定完整计划 | 动态规划调整 |
| 适应性 | 较差 | 优秀 |
| 执行效率 | 高(计划明确时) | 中等(需要多轮交互) |
| 错误恢复 | 困难 | 容易 |
🚧 ReAct的局限性与挑战
1. 计算成本较高
ReAct的多轮交互特性导致了更高的计算成本:
传统LLM调用:1次API调用
ReAct Agent:平均3-5次API调用
成本增加:3-5倍
延迟增加:2-3倍优化策略:
-
使用更小但高效的模型进行初步推理
-
实现智能缓存机制
-
优化工具调用的并行性
2. 工具依赖性
ReAct的能力很大程度上取决于可用工具的质量和数量:
挑战:
-
工具接口的标准化
-
工具可靠性保证
-
工具安全性控制
-
工具版本管理
解决方案:
class ToolManager:
def __init__(self):
self.tools = {}
self.tool_validators = {}
self.fallback_tools = {}
def register_tool(self, tool, validator=None, fallback=None):
self.tools[tool.name] = tool
if validator:
self.tool_validators[tool.name] = validator
if fallback:
self.fallback_tools[tool.name] = fallback
def execute_with_fallback(self, tool_name, params):
try:
return self.tools[tool_name].run(params)
except Exception as e:
if tool_name in self.fallback_tools:
return self.fallback_tools[tool_name].run(params)
raise e3. 推理链的复杂性管理
随着任务复杂度增加,ReAct的推理链可能变得过于冗长:
问题表现:
-
推理步骤过多,效率降低
-
中间步骤出错,影响最终结果
-
推理逻辑难以跟踪和调试
改进方向:
-
实现推理链的自动优化
-
引入推理步骤的重要性评估
-
开发可视化调试工具
4. 安全性和可控性
ReAct Agent的自主性带来了新的安全挑战:
安全风险:
-
恶意工具调用
-
敏感信息泄露
-
无限循环执行
-
资源滥用
安全措施:
class SecureReActAgent:
def __init__(self, max_iterations=10, allowed_tools=None):
self.max_iterations = max_iterations
self.allowed_tools = allowed_tools or []
self.execution_log = []
def execute_with_safety(self, task):
iteration_count = 0
while iteration_count < self.max_iterations:
# 执行安全检查
if not self.is_safe_action(next_action):
raise SecurityError("Unsafe action detected")
# 记录执行日志
self.execution_log.append({
'iteration': iteration_count,
'action': next_action,
'timestamp': datetime.now()
})
iteration_count += 1🔮 ReAct的未来发展趋势
1. 多模态ReAct Agent
未来的ReAct Agent将不仅仅处理文本,还将整合视觉、听觉等多种模态:
class MultiModalReActAgent:
def __init__(self):
self.text_processor = TextLLM()
self.vision_processor = VisionLLM()
self.audio_processor = AudioLLM()
self.multimodal_fusion = FusionModule()
def process_multimodal_input(self, text, image, audio):
# 多模态信息融合处理
text_features = self.text_processor.encode(text)
vision_features = self.vision_processor.encode(image)
audio_features = self.audio_processor.encode(audio)
fused_representation = self.multimodal_fusion.fuse(
text_features, vision_features, audio_features
)
return self.generate_multimodal_response(fused_representation)2. 自适应工具学习
未来的ReAct Agent将具备自主学习新工具的能力:
技术特点:
-
自动发现可用工具
-
学习工具使用方法
-
评估工具效果
-
优化工具组合
class AdaptiveToolLearner:
def discover_new_tools(self, environment):
# 自动发现环境中的可用工具
available_tools = environment.scan_tools()for tool in available_tools: # 学习工具的使用方法 usage_pattern = self.learn_tool_usage(tool) # 评估工具的有效性 effectiveness = self.evaluate_tool(tool, usage_pattern) if effectiveness > self.threshold: self.register_tool(tool, usage_pattern)
3. 协作式多Agent系统
多个ReAct Agent之间的协作将成为解决复杂任务的关键:
class CollaborativeReActSystem:
def __init__(self):
self.agents = {
'researcher': ResearchAgent(),
'analyst': AnalysisAgent(),
'writer': WritingAgent(),
'reviewer': ReviewAgent()
}
self.coordinator = TaskCoordinator()
def solve_complex_task(self, task):
# 任务分解
subtasks = self.coordinator.decompose_task(task)
# 分配给不同的专业Agent
results = {}
for subtask in subtasks:
agent_type = self.coordinator.select_agent(subtask)
results[subtask.id] = self.agents[agent_type].execute(subtask)
# 结果整合
final_result = self.coordinator.integrate_results(results)
return final_result4. 边缘计算优化
为了降低延迟和成本,ReAct Agent将向边缘计算方向发展:
优化方向:
-
模型压缩和量化
-
本地工具集成
-
智能缓存策略
-
混合云-边缘架构
5. 领域专业化
不同领域将出现专门优化的ReAct Agent:
-
医疗ReAct Agent:集成医学知识库和诊断工具
-
金融ReAct Agent:整合市场数据和分析工具
-
教育ReAct Agent:结合个性化学习和评估工具
-
科研ReAct Agent:连接学术数据库和实验工具
🛠️ 实战项目:构建一个完整的ReAct Agent
让我们通过一个完整的项目来展示如何构建一个实用的ReAct Agent:
项目目标:智能数据分析助手
我们将构建一个能够自动分析数据、生成报告的ReAct Agent。
import pandas as pd
import matplotlib.pyplot as plt
from langchain.agents import create_react_agent, AgentExecutor
from langchain.tools import BaseTool
from langchain_openai import ChatOpenAI
from typing import Optional
import json
class DataAnalysisReActAgent:
def __init__(self, api_key: str):
self.llm = ChatOpenAI(
model="gpt-4",
temperature=0,
openai_api_key=api_key
)
self.tools = self._create_tools()
self.agent = self._create_agent()
def _create_tools(self):
"""创建数据分析工具集"""
class DataLoaderTool(BaseTool):
name = "data_loader"
description = "加载CSV数据文件"
def _run(self, file_path: str) -> str:
try:
df = pd.read_csv(file_path)
return f"数据加载成功,形状:{df.shape},列名:{list(df.columns)}"
except Exception as e:
return f"数据加载失败:{str(e)}"
class StatisticsCalculator(BaseTool):
name = "statistics_calculator"
description = "计算数据的基本统计信息"
def _run(self, column_name: str) -> str:
try:
if hasattr(self, 'current_data'):
stats = self.current_data[column_name].describe()
return f"{column_name}的统计信息:\n{stats.to_string()}"
else:
return "请先加载数据"
except Exception as e:
return f"统计计算失败:{str(e)}"
class VisualizationTool(BaseTool):
name = "visualization_tool"
description = "创建数据可视化图表"
def _run(self, chart_config: str) -> str:
try:
config = json.loads(chart_config)
chart_type = config.get('type', 'line')
x_column = config.get('x')
y_column = config.get('y')
if hasattr(self, 'current_data'):
plt.figure(figsize=(10, 6))
if chart_type == 'scatter':
plt.scatter(self.current_data[x_column],
self.current_data[y_column])
elif chart_type == 'line':
plt.plot(self.current_data[x_column],
self.current_data[y_column])
elif chart_type == 'histogram':
plt.hist(self.current_data[x_column], bins=20)
plt.xlabel(x_column)
plt.ylabel(y_column)
plt.title(f'{chart_type.title()} Chart')
plt.savefig('analysis_chart.png')
plt.close()
return "图表已生成并保存为 analysis_chart.png"
else:
return "请先加载数据"
except Exception as e:
return f"可视化失败:{str(e)}"
class CorrelationAnalyzer(BaseTool):
name = "correlation_analyzer"
description = "分析数据列之间的相关性"
def _run(self, columns: str) -> str:
try:
column_list = json.loads(columns)
if hasattr(self, 'current_data'):
correlation_matrix = self.current_data[column_list].corr()
return f"相关性分析结果:\n{correlation_matrix.to_string()}"
else:
return "请先加载数据"
except Exception as e:
return f"相关性分析失败:{str(e)}"
return [
DataLoaderTool(),
StatisticsCalculator(),
VisualizationTool(),
CorrelationAnalyzer()
]
def _create_agent(self):
"""创建ReAct Agent"""
prompt_template = """
你是一个专业的数据分析助手,能够使用各种工具来分析数据并生成洞察。
可用工具:
{tools}
使用以下格式:
Question: 用户的问题
Thought: 你应该思考要做什么
Action: 要采取的行动,应该是 [{tool_names}] 中的一个
Action Input: 行动的输入
Observation: 行动的结果
... (这个 Thought/Action/Action Input/Observation 可以重复N次)
Thought: 我现在知道最终答案了
Final Answer: 对原始输入问题的最终答案
开始!
Question: {input}
Thought: {agent_scratchpad}
"""
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(prompt_template)
agent = create_react_agent(self.llm, self.tools, prompt)
return AgentExecutor(
agent=agent,
tools=self.tools,
verbose=True,
handle_parsing_errors=True,
max_iterations=10
)
def analyze(self, query: str, data_path: Optional[str] = None):
"""执行数据分析任务"""
if data_path:
# 首先加载数据
load_query = f"请加载数据文件:{data_path}"
self.agent.invoke({"input": load_query})
# 执行分析查询
result = self.agent.invoke({"input": query})
return result["output"]
# 使用示例
if __name__ == "__main__":
# 初始化分析助手
analyzer = DataAnalysisReActAgent(api_key="your-openai-api-key")
# 执行分析任务
analysis_queries = [
"请分析sales_data.csv文件中的销售趋势",
"计算各产品类别的平均销售额",
"创建销售额与时间的散点图",
"分析价格和销量之间的相关性"
]
for query in analysis_queries:
print(f"\n查询:{query}")
print("="*50)
result = analyzer.analyze(query, "sales_data.csv")
print(f"结果:{result}")
print("="*50)项目扩展:添加报告生成功能
class ReportGeneratorTool(BaseTool):
name = "report_generator"
description = "生成数据分析报告"
def _run(self, analysis_results: str) -> str:
"""根据分析结果生成格式化报告"""
try:
results = json.loads(analysis_results)
report = f"""
# 数据分析报告
## 执行摘要
本报告基于提供的数据集进行了全面分析,主要发现如下:
## 数据概览
- 数据集大小:{results.get('data_shape', 'N/A')}
- 分析时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
## 关键发现
{self._format_findings(results.get('findings', []))}
## 统计摘要
{self._format_statistics(results.get('statistics', {}))}
## 建议
{self._generate_recommendations(results)}
## 附录
- 生成的图表:analysis_chart.png
- 原始数据文件:{results.get('data_source', 'N/A')}
"""
# 保存报告
with open('analysis_report.md', 'w', encoding='utf-8') as f:
f.write(report)
return "分析报告已生成并保存为 analysis_report.md"
except Exception as e:
return f"报告生成失败:{str(e)}"
def _format_findings(self, findings):
if not findings:
return "暂无关键发现"
formatted = ""
for i, finding in enumerate(findings, 1):
formatted += f"{i}. {finding}\n"
return formatted
def _format_statistics(self, stats):
if not stats:
return "暂无统计信息"
formatted = ""
for key, value in stats.items():
formatted += f"- {key}: {value}\n"
return formatted
def _generate_recommendations(self, results):
# 基于分析结果生成建议
recommendations = [
"建议进一步收集更多历史数据以提高分析准确性",
"考虑引入外部因素进行更全面的分析",
"定期更新数据以保持分析结果的时效性"
]
formatted = ""
for i, rec in enumerate(recommendations, 1):
formatted += f"{i}. {rec}\n"
return formatted🎓 学习ReAct的最佳实践
1. 从简单开始
初学者应该从简单的单工具ReAct Agent开始:
# 简单的计算器Agent
class SimpleCalculatorAgent:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-3.5-turbo")
self.calculator = CalculatorTool()
def solve_math_problem(self, problem):
# 简单的ReAct循环
thought = f"我需要计算:{problem}"
action = "calculator"
action_input = problem
observation = self.calculator.run(action_input)
final_answer = f"计算结果是:{observation}"
return final_answer2. 逐步增加复杂性
随着经验积累,逐步添加更多工具和复杂逻辑:
# 中等复杂度的研究助手
class ResearchAssistant:
def __init__(self):
self.tools = [
WebSearchTool(),
DocumentReaderTool(),
SummarizerTool(),
CitationGeneratorTool()
]
def research_topic(self, topic):
# 多步骤研究流程
search_results = self.search_web(topic)
documents = self.read_documents(search_results)
summary = self.summarize_findings(documents)
citations = self.generate_citations(documents)
return {
'summary': summary,
'citations': citations,
'sources': documents
}3. 重视错误处理
在实际应用中,错误处理至关重要:
class RobustReActAgent:
def __init__(self):
self.max_retries = 3
self.fallback_strategies = {
'tool_failure': self.handle_tool_failure,
'parsing_error': self.handle_parsing_error,
'timeout': self.handle_timeout
}
def execute_with_error_handling(self, task):
for attempt in range(self.max_retries):
try:
return self.execute_task(task)
except ToolFailureError as e:
if attempt < self.max_retries - 1:
self.fallback_strategies['tool_failure'](e)
else:
raise e
except Exception as e:
self.log_error(e, attempt)
if attempt == self.max_retries - 1:
return self.generate_fallback_response(task)4. 性能优化技巧
class OptimizedReActAgent:
def __init__(self):
self.cache = {}
self.tool_usage_stats = {}
self.optimization_enabled = True
def execute_optimized(self, task):
# 检查缓存
cache_key = self.generate_cache_key(task)
if cache_key in self.cache:
return self.cache[cache_key]
# 选择最优工具
optimal_tool = self.select_optimal_tool(task)
# 执行并缓存结果
result = self.execute_with_tool(task, optimal_tool)
self.cache[cache_key] = result
# 更新使用统计
self.update_tool_stats(optimal_tool, result)
return result🌍 ReAct的社区生态与资源
开源项目和框架
-
LangChain:最流行的ReAct实现框架
-
AutoGPT:基于ReAct的自主AI Agent
-
特点:完全自主的任务执行
-
LangGraph:用于构建复杂Agent工作流
-
特点:图形化Agent设计
-
CrewAI:多Agent协作框架
-
特点:专业化Agent团队协作
学习资源
-
论文资源
-
原始ReAct论文:"ReAct: Synergizing Reasoning and Acting in Language Models"
-
相关研究:Chain-of-Thought, Tree of Thoughts等
-
-
在线课程
-
DeepLearning.AI的LangChain课程
-
Coursera的AI Agent专项课程
-
YouTube上的实战教程
-
-
技术博客
-
Lilian Weng的AI Agent综述
-
OpenAI的技术博客
-
各大科技公司的AI研究博客
-
社区和论坛
-
GitHub Discussions:各个开源项目的讨论区
-
Reddit:r/MachineLearning, r/artificial等社区
-
Discord:LangChain官方Discord服务器
-
Stack Overflow:技术问题解答
🎯 结语:ReAct的未来展望
技术发展趋势
ReAct框架作为AI Agent领域的重要突破,正在推动整个人工智能行业向更加智能、自主的方向发展。我们可以预见以下几个重要趋势:
-
更强的推理能力:随着大语言模型的不断进步,ReAct Agent的推理能力将更加接近人类水平
-
更丰富的工具生态:越来越多的专业工具将被集成到ReAct框架中,形成强大的工具生态系统
-
更好的用户体验:通过优化交互设计和响应速度,ReAct Agent将提供更加流畅的用户体验
-
更广泛的应用场景:从简单的问答到复杂的决策支持,ReAct将在更多领域发挥重要作用
对行业的影响
ReAct框架的普及将对多个行业产生深远影响:
-
软件开发:AI编程助手将成为开发者的标配工具
-
数据分析:自动化数据分析将大大提高分析效率
-
客户服务:智能客服将提供更加个性化的服务体验
-
教育培训:个性化AI导师将改变传统教学模式
-
科学研究:AI研究助手将加速科学发现的进程
面临的挑战与机遇
挑战:
-
计算成本的控制
-
安全性和可靠性的保证
-
伦理和法律问题的解决
-
技术标准的统一
机遇:
-
巨大的市场需求
-
技术快速发展
-
生态系统日趋完善
-
投资热情高涨
给开发者的建议
-
持续学习:AI技术发展迅速,保持学习的热情和能力
-
实践为主:通过实际项目来掌握ReAct的精髓
-
关注安全:在追求功能的同时,不忘安全性考虑
-
开放合作:积极参与开源社区,共同推动技术发展
-
用户导向:始终以解决实际问题为目标
💬 互动讨论:让我们一起探索ReAct的无限可能
读到这里,相信你对ReAct框架已经有了深入的理解。但学习的旅程永远不会结束,技术的探索需要我们共同参与。
🤔 思考题
-
你认为ReAct框架最适合解决哪类问题?为什么?
-
在你的工作或学习中,有哪些场景可以应用ReAct Agent?
-
ReAct框架还有哪些可以改进的地方?
-
你对多Agent协作有什么看法和想法?
💡 分享你的经验
如果你已经尝试过ReAct框架,欢迎在评论区分享:
-
你的实践经验和心得
-
遇到的问题和解决方案
-
有趣的应用案例
-
对未来发展的预测
🚀 一起行动
让我们一起:
-
关注本账号,获取更多AI技术干货
-
点赞支持,让更多人了解ReAct的魅力
-
转发分享,与朋友一起探讨AI的未来
-
评论互动,在交流中碰撞出思维的火花
📚 延伸阅读
想要深入学习ReAct和AI Agent?推荐以下资源:
-
技术论文:搜索"ReAct Synergizing Reasoning Acting Language Models"
-
开源项目:访问LangChain GitHub仓库
-
实战教程:关注我的后续文章,将分享更多实战案例
-
社区讨论:加入相关技术社群,与同行交流
最后的话
ReAct框架不仅仅是一项技术创新,更是人工智能发展史上的一个重要里程碑。它让我们看到了AI从"工具"向"伙伴"转变的可能性,也为我们描绘了一个更加智能、更加美好的未来。
在这个AI快速发展的时代,让我们保持好奇心,拥抱变化,用技术的力量创造更多价值。无论你是AI研究者、开发者,还是对AI感兴趣的爱好者,都欢迎加入这场智能革命的浪潮。
记住:未来属于那些能够让AI真正"思考"和"行动"的人。而ReAct,正是通往这个未来的钥匙。
如果这篇文章对你有帮助,请不要忘记点赞、收藏和分享。你的支持是我持续创作的动力!
有任何问题或建议,欢迎在评论区留言,我会认真回复每一条评论。让我们一起在AI的道路上越走越远!
#ReAct #AI Agent #人工智能 #LangChain #机器学习 #深度学习 #技术分享