@TOC
如有侵权,联系删除
一、环境说明
使用前必须检查以下环境
(1)python编译环境
(2)python脚本执行所需要的库,具体看代码(main.py)import导入的部分库
(3)确保电脑可以正常连接网络,可以正常访问淘宝链接
(4)anconda环境(可选)
备注:博主测试的python环境是3.8.8,尽量用python3版本
二、数据爬虫
资源下载后,首先是爬虫爬取数据代码和使用说明,可以查看同级目录下的spider目录
进入spider目录里面有相关说明文档,一定要先看"使用说明(使用前必看).docx "文件,该文档详细写了运行的步骤,小白也能看得懂的傻瓜式教程
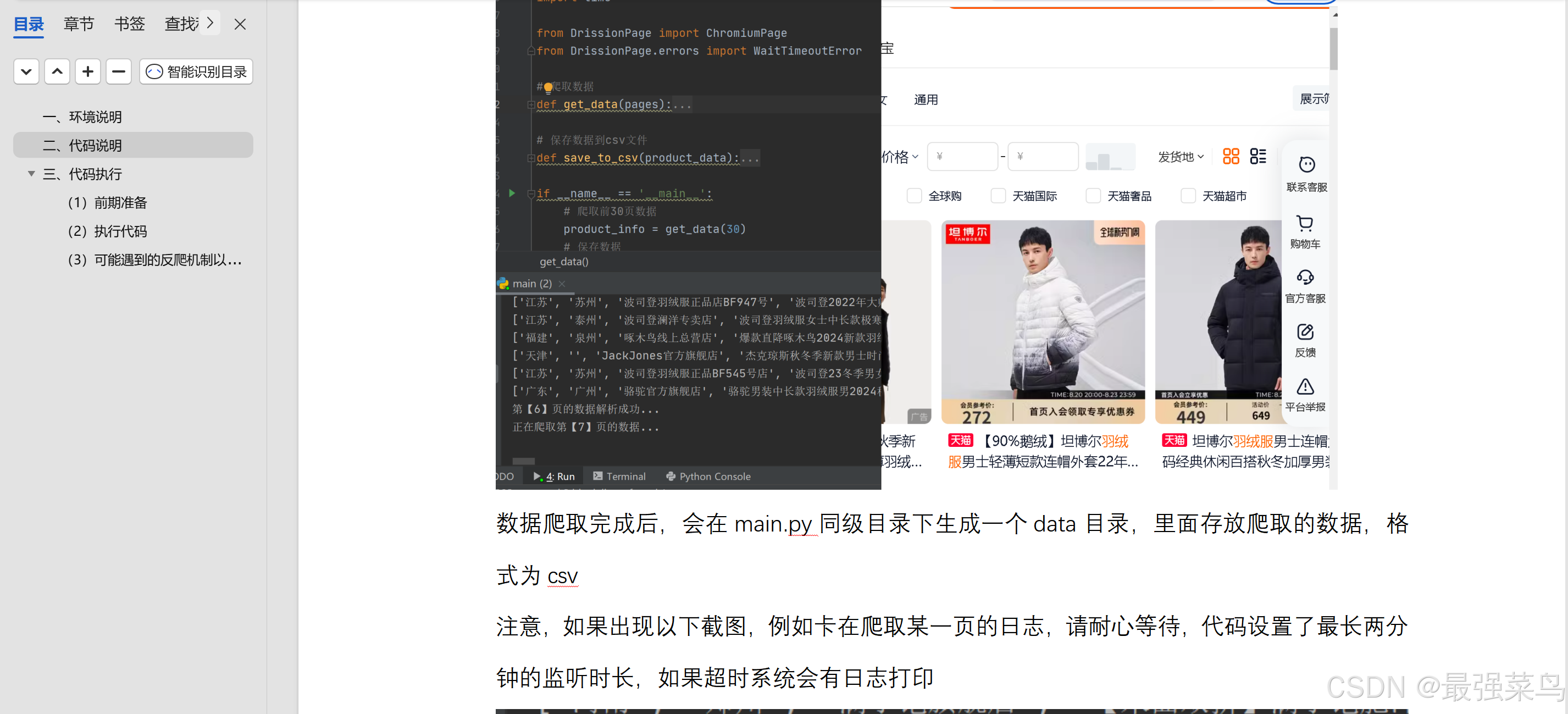
然后看main.py,这个是代码文件,共分为两个主要方法,一个是get_data方法,用于爬取数据,另一个是save_to_csv方法,用于保存数据

_main_是主函数入口,这里默认爬取30页的数据,可以根据实际情况修改要爬取的页数,运行后自动在同级目录生成data文件夹,里面保存爬取后的数据
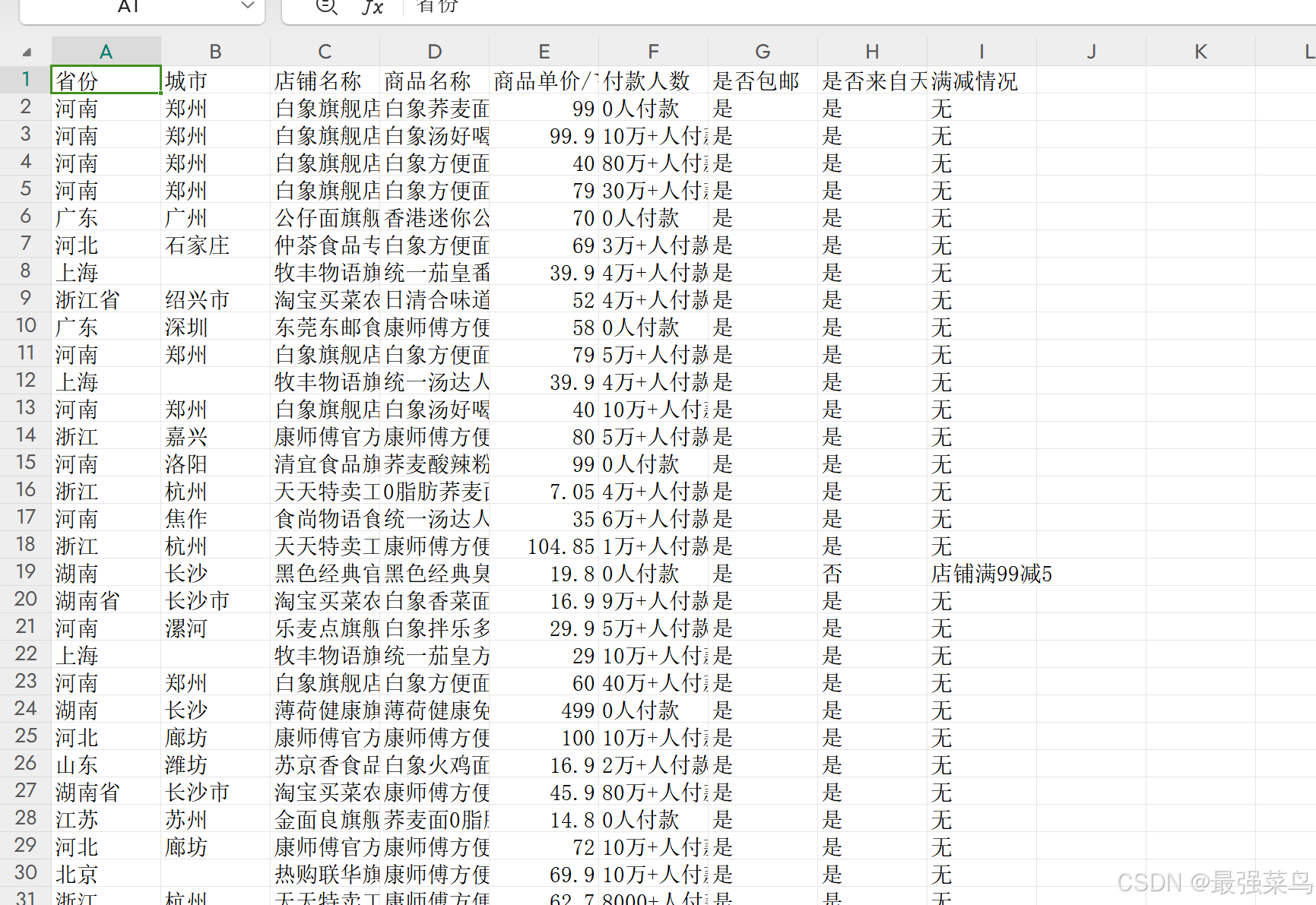
至此数据爬取部分已完成
三、数据清洗与分析
因为考虑到了有用户用的jupyter,所以这里提供了两个版本
注意:这里提供了两个版本,analysis.ipynb和analysis.py,任意一个跑起来都可以
注意:这里提供了两个版本,analysis.ipynb和analysis.py,任意一个跑起来都可以
注意:这里提供了两个版本,analysis.ipynb和analysis.py,任意一个跑起来都可以
下载资源后,最外层资源有一个"使用说明(使用前必看).docx "文件,一定要先看这个文件,这个是整理的详细的傻瓜式的运行教程,小白绝对能看得懂
(1)jupyter版本
先简单说一下analysis.ipynb的使用,首先确保安装了jupyter编辑器,然后按住win + R,输入cmd,进入黑窗口
输入jupyter notebook,启动编辑器

启动后浏览器会打开一个窗口,jupyter会打开默认的路径(这个路径可以自行百度怎么修改),然后把analysis.ipynb拷贝到jupyter路径下打开即可,以博主的截图为例如下
打开如下,就可以按照每一节的代码运行实时看到效果
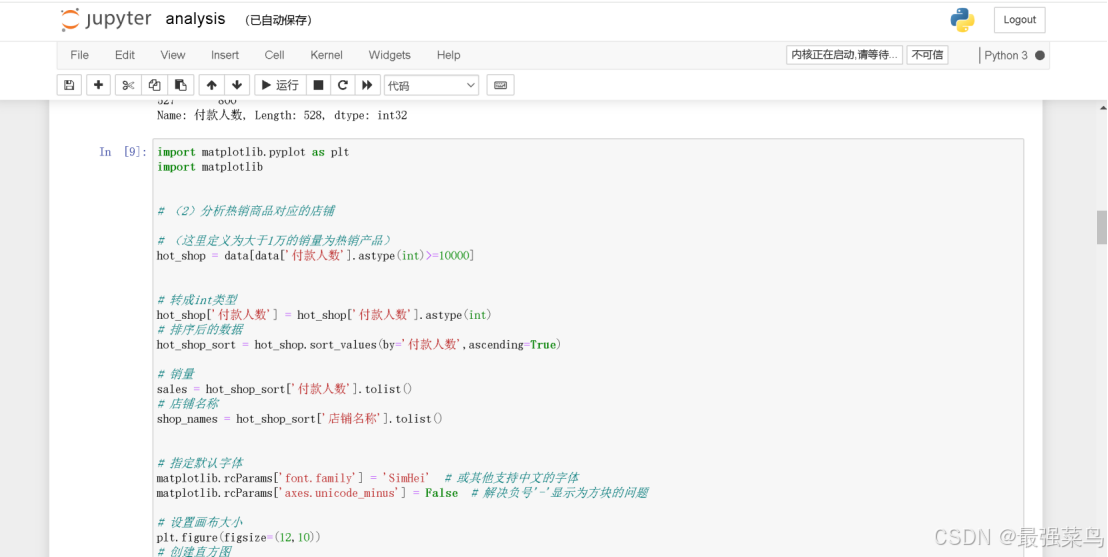
已最简单的销量分析柱状图为例
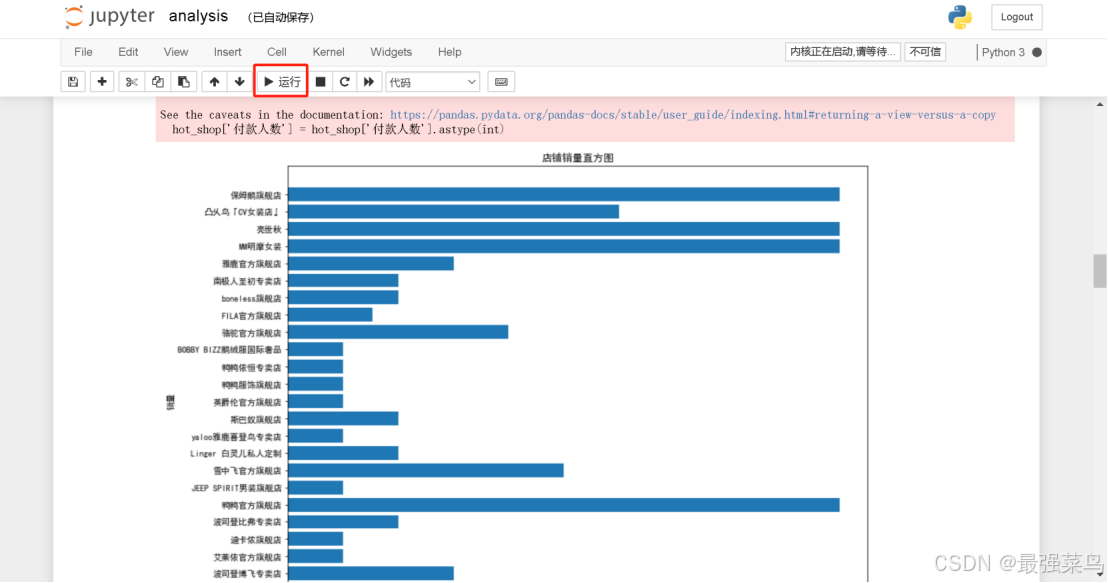
其他的例如词云分析等可自行运行
(2)原始python版本
这个文件用python默认编辑器打开都可以,这里博主用pycharm打开
执行后会打开对应的日志信息和分析的数据图表
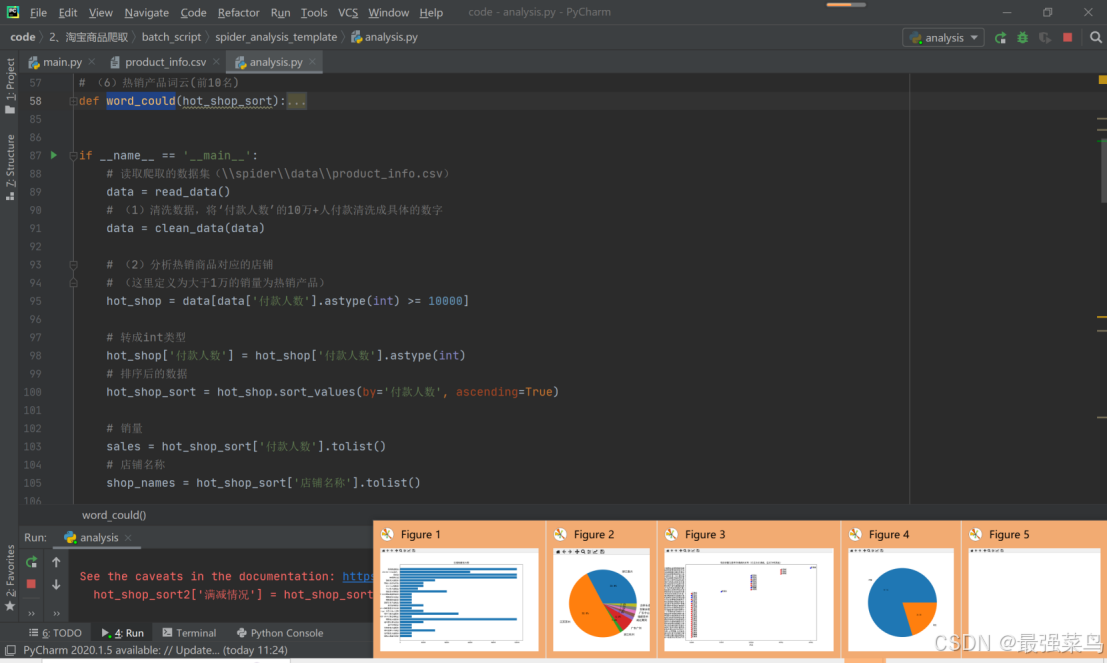
数据可视化,包括销量分析、分布、词云分析等等可以自行运行起来看看,自此数据的清洗分析完成
四、总结
可用于个人学习、课程设计、课程大作业、毕设等