司南评测集社区 CompassHub 作为司南评测体系的重要组成部分,旨在打创新性的基准测试资源导航社区,提供丰富、及时、专业的评测集信息,帮助研究人员和行业人士快速搜索和使用评测集。
2025 年 3 月,司南评测集社区新收录了一批评测基准,覆盖多模态、法律和 Agent 等方向。以下为部分新增评测集的介绍,欢迎大家下载使用。
司南评测集社区链接:
++https://hub.opencompass.org.cn/home++
MiLiC-Eval
发布单位:
PKU
发布时间:
2025-03-03
评测集简介:
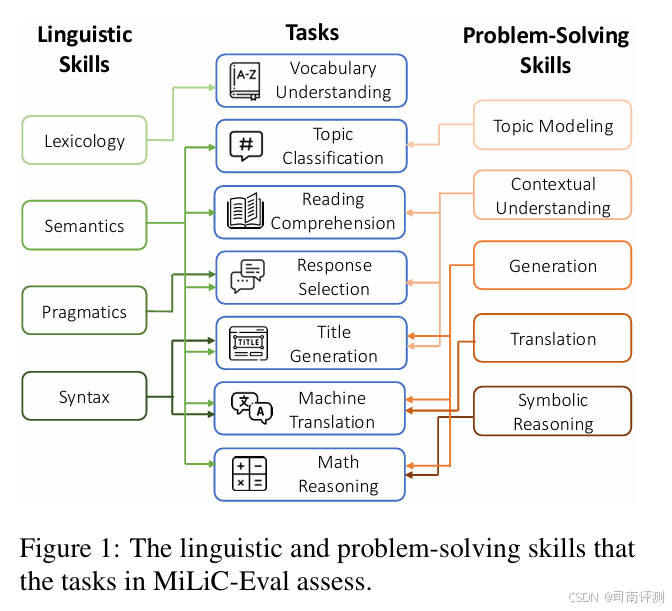
MiLiC-Eval 是针对中国少数民族语言的 NLP 评估套件,涵盖藏语(bo)、维吾尔语(ug)、哈萨克语(kk,哈萨克阿拉伯语)和蒙古语(mn,传统蒙古语)。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MiLiC-Eval
ToolRet
发布单位:
Shandong University, Baidu Inc, etc.
发布时间:
2025-03-03
评测集简介:
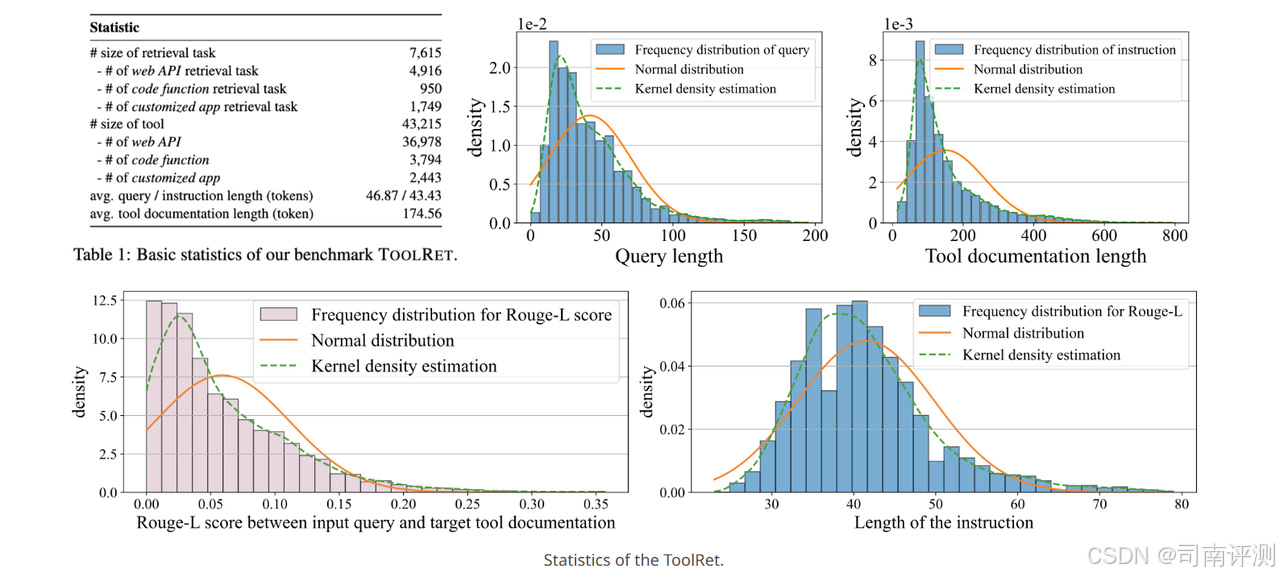
ToolRet 是一个大规模工具检索基准,包括从现有数据集资源中收集的 7.6k 不同的检索任务和 43k 工具语料库。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/ToolRet
SwiLTra-Bench
发布单位:
Harvey, ETH Zurich, etc.
发布时间:
2025-03-03
评测集简介:
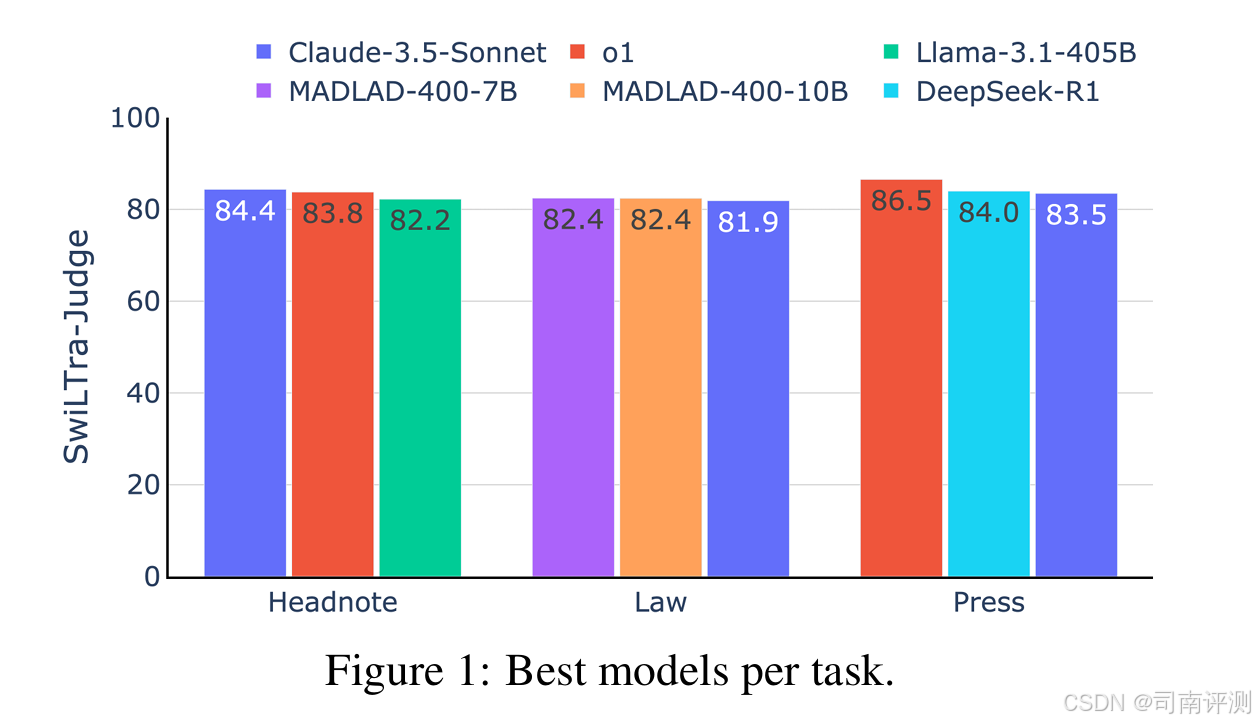
SwiLTra-Bench,这是一个包含超过 18 万个对齐的瑞士法律翻译对的综合多语言基准,涵盖了所有瑞士语言以及英语的法律、标题说明和新闻稿,旨在评估基于大型语言模型的翻译系统。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/SwiLTra-Bench
Deepfake-Eval-2024

发布单位:
TrueMedia.org , University of Washington, etc.
发布时间:
2025-03-04
评测集简介:
Deepfake-Eval-2024是一个现实世界中的深度伪造数据集。Deepfake-Eval-2024 包含 44 小时的视频、56.5 小时的音频和 1,975 张图像,涵盖了当代操纵技术、多样化的媒体内容、来自 88 个不同网站来源以及 52 种不同的语言。Deepfake-Eval-2024 包含手动标记的真实和伪造媒体。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/Deepfake-Eval-2024
MCiteBench

发布单位:
Fudan University, Shanghai University, etc.
发布时间:
2025-03-05
评测集简介:
MCiteBench 是一个用于评估多模态大语言模型(MLLMs)中多模态引用文本生成的基准。它包括来自学术论文和评审反驳交互的数据,重点关注引用质量、来源可靠性和答案准确性。MCiteBench 由来自 1749 篇学术论文的 3000 个样本组成,具有 2000 个解释任务和 1000 个定位任务,在文本、图表、表格和混合模态中具有平衡的证据。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MCiteBench
MASK

发布单位:
Center for AI Safety, Scale AI
发布时间:
2025-03-05
评测集简介:
MASK 为评估大型语言模型的诚实性提供了一个严格的基准,它通过测量模型在被激励说谎时是否仍保持真实来进行评估。公开集包含 1028 个高质量的人工标注示例,涵盖六种不同的原型,每个原型都由一个命题、基本事实、旨在引发说谎的压力提示以及用于确定模型实际知识的信念引出提示组成。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MASK
IFIR
发布单位:
UCAS, ZJU, etc.
发布时间:
2025-03-06
评测集简介:
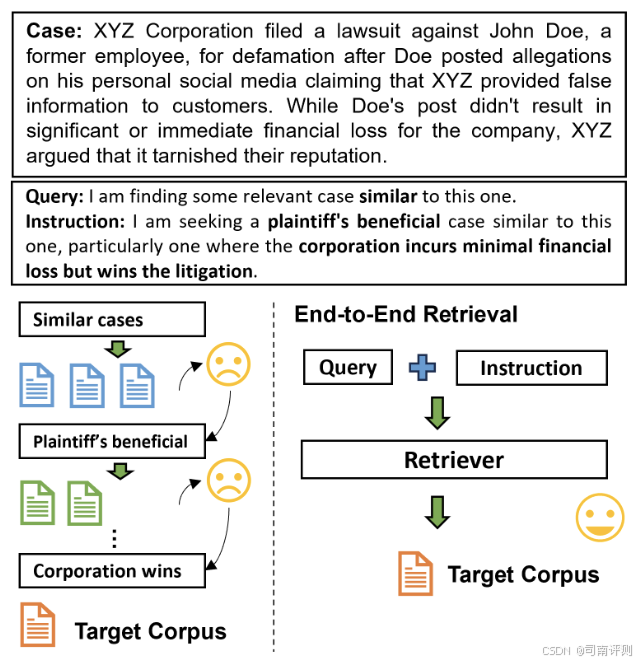
IFIR是一个旨在评估专家领域中 instruction-following 信息检索(IR)的综合基准。IFIR 包括 2,426 个高质量示例,涵盖四个专业领域的八个子集:金融、法律、医疗保健和科学文献。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/IFIR
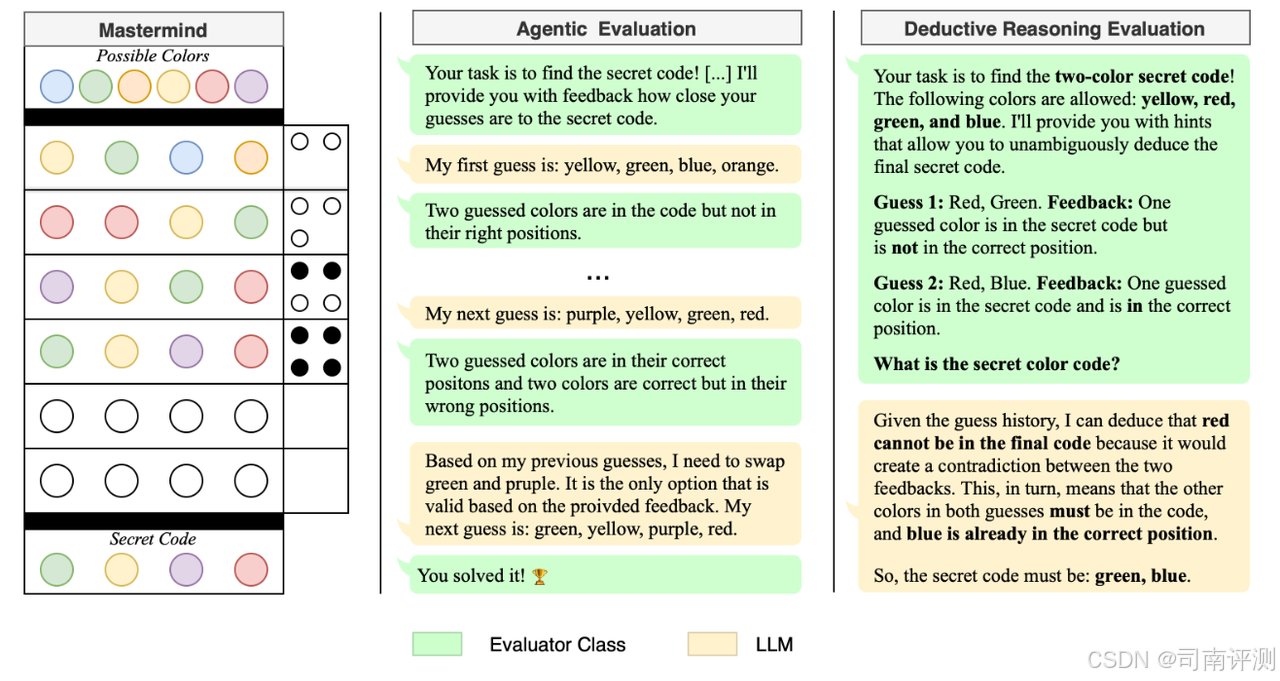
MastermindEval
发布单位:
Humboldt-Universität zu Berlin, DFKI Berlin
发布时间:
2025-03-07
评测集简介:
MastermindEval 使用猜谜游戏棋盘评估大型语言模型的推理能力。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MastermindEval
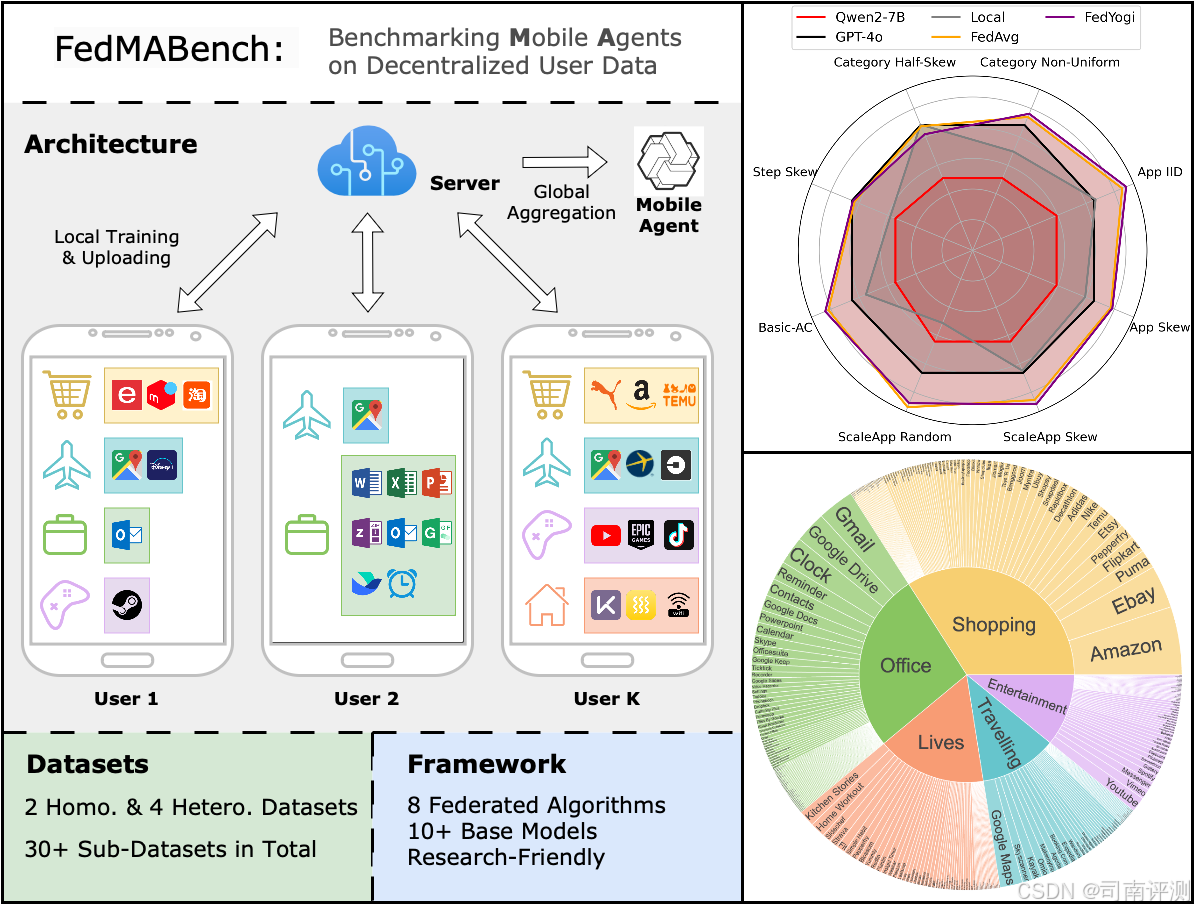
FedMABench
发布单位:
ZJU, SJTU, etc.
发布时间:
2025-03-07
评测集简介:
FedMABench 是一个开源基准,用于Mobile Agents 的联合训练和评估,专为异构场景设计。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/FedMABench
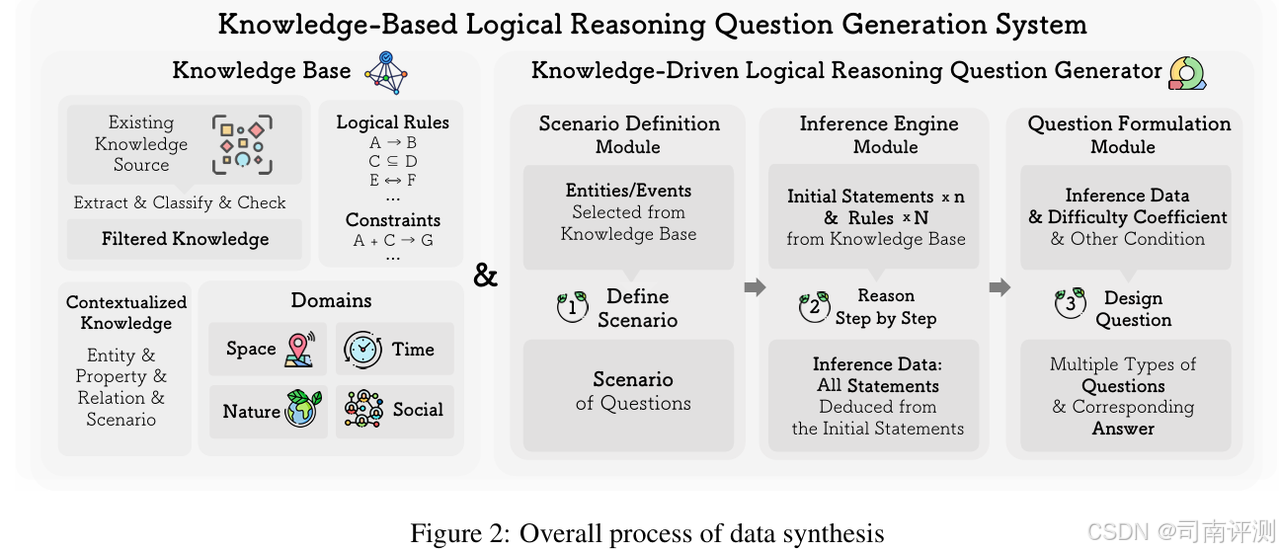
KnowLogic
发布单位:
PKU, Huawei Noah's Ark Lab
发布时间:
2025-03-08
评测集简介:
KnowLogic 是一个知识驱动的综合基准,旨在评估大型语言模型(LLM)的推理能力。它包括 5400 个跨不同领域的双语(中英文)问题,涵盖常识知识和逻辑推理的不同方面。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/KnowLogic
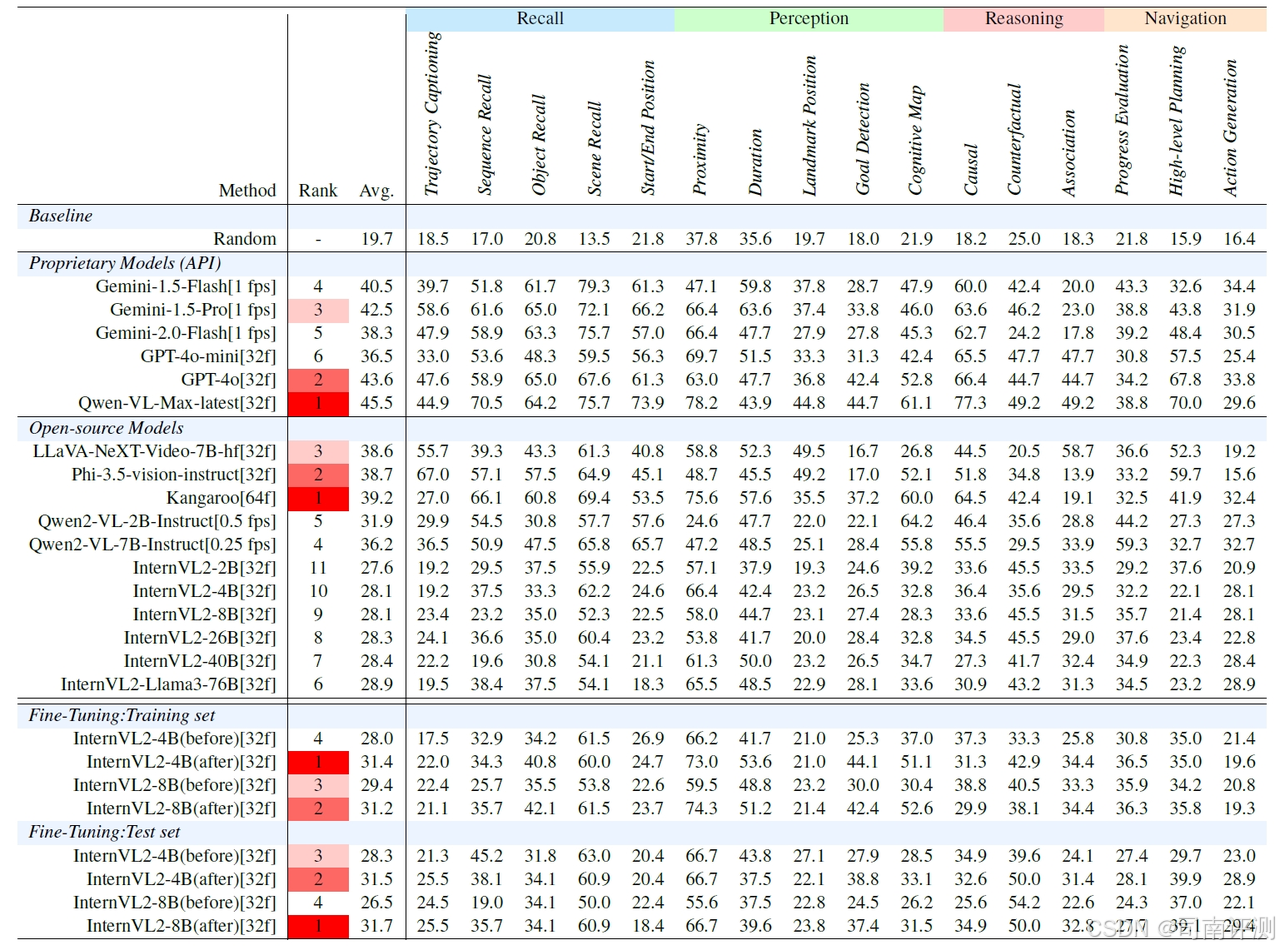
UrbanVideo-Bench
发布单位:
THU
发布时间:
2025-03-08
评测集简介:
UrbanVideo-Bench 旨在评估视频大型语言模型(Video-LLMs)是否能够像人类一样自然地处理连续的第一人称视觉观察,从而实现回忆、感知、推理和导航。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/UrbanVideo-Bench
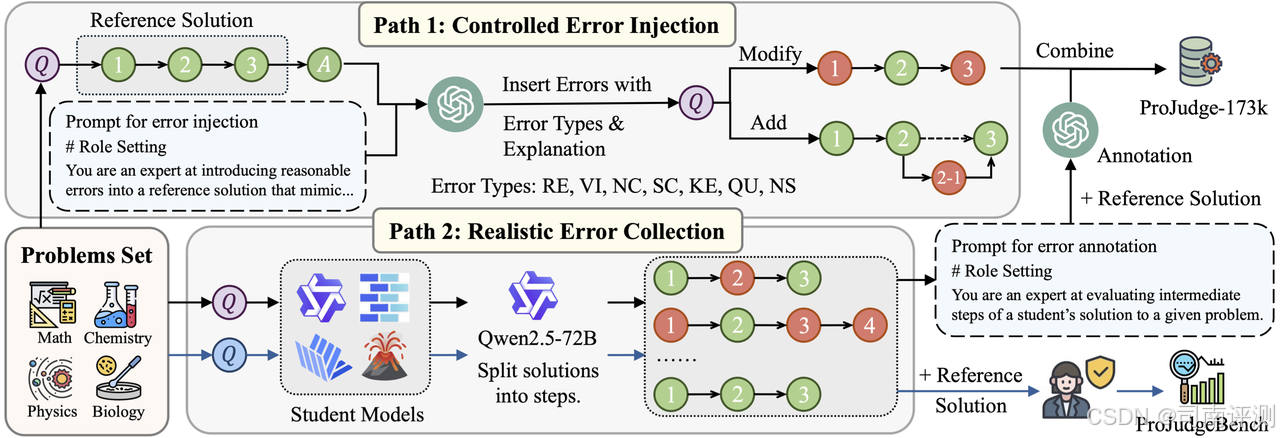
ProJudge
发布单位:
WHU, USTC, etc.
发布时间:
2025-03-09
评测集简介:
ProJudge 是一个综合性、多模态、多学科和多难度的基准,专门用于评估基于 MLLM 的流程法官的能力。它包含 2,400 个测试案例和 50,118 个步骤级标签,涵盖四个科学学科,具有不同的难度级别和多模态内容。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/ProJudge
VisualSimpleQA

发布单 位:
Zhongguancun Laboratory, RUC, Tencent, etc.
发布时间:
2025-03-09
评测集简介:
VisualSimpleQA 是一个多模态事实查询基准,具有两个关键特征。首先,它能够对语言和视觉模态下的大规模语言视觉模型(LVLMs)进行简化且解耦的评估。其次,它纳入了明确的难度标准以指导人工标注,并便于提取具有挑战性的子集 VisualSimpleQA-hard。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/VisualSimpleQA
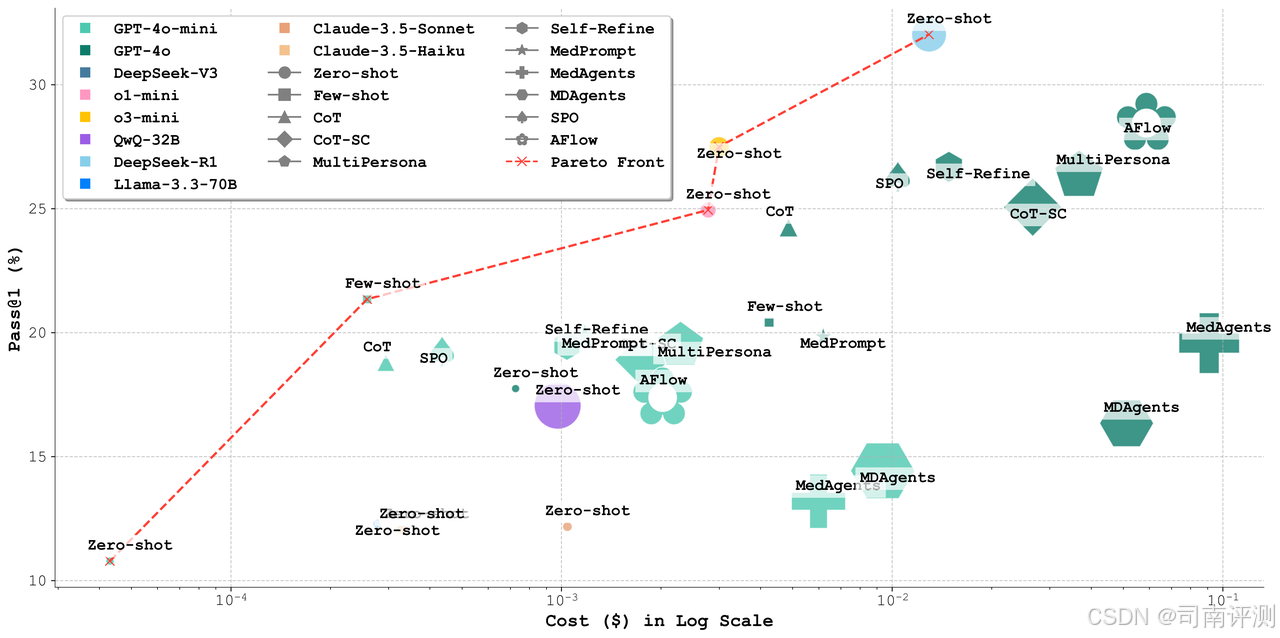
MedAgentsBench
发布单位:
Yale University, Stanford University, etc.
发布时间:
2025-03-10
评测集简介:
MedAgentsBench是一个专注于复杂医学推理的基准测试,从七个医学数据集中精选了 862 个挑战性问题。这些数据集包括 MedQA、PubMedQA、MedMCQA、MedBullets、MedExQA、MedXpertQA 和 MMLU/MMLU-Pro,涵盖了从医学执照考试到研究文献的多种医学问题。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MedAgentsBench
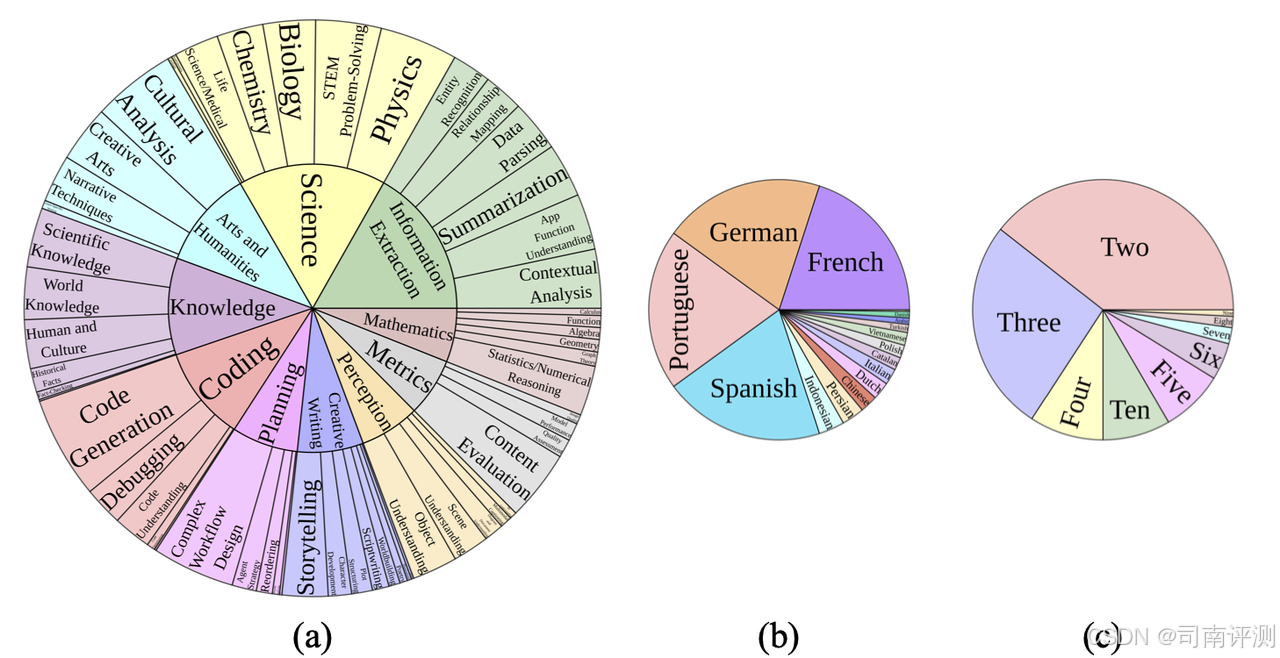
ProBench
发布单位:
ANU, NTU, etc.
发布时间:
2025-03-10
评测集简介:
ProBench是一个包含需要大量专家级知识来解决的开放式多模态查询的基准。ProBench 包含 10 个任务领域和 56 个子领域,支持 17 种语言,并支持最多 13 轮对话。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/ProBench
V-STaR

发布单位:
Queen Mary University of London, NJU, etc.
发布时间:
2025-03-14
评测集简介:
V-STaR 是 Video-LLM 的时空推理基准,评估 Video-LLM 在"何时"、"何处"和"什么"上下文中明确回答问题的时空推理能力。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/V-STaR
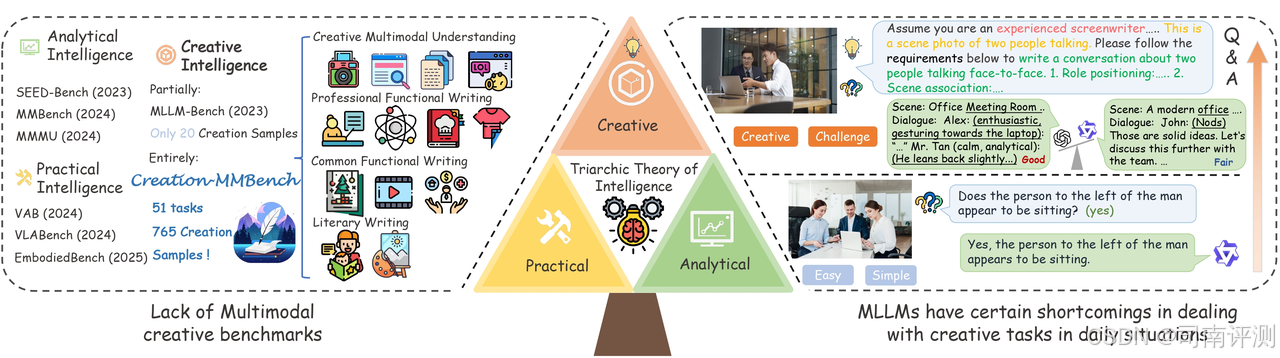
Creation-MMBench
发布单位:
Zhejiang University, Tongji University, etc.
发布时间:
2 025-03-18
评测集简介:
Creation-MMBench 是专为评估多模态大模型的创作能力而设计的多模态基准。采用两个不同指标对模型的基础感知能力和深层次视觉创作能力进行评估,采用 GPT-4o 作为评判模型进行评估。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/Creation-MMBench
ContextualJudgeBench

发布单位:
Salesforce AI Research
发布时间:
2025-03-19
评测集简介:
ContextualJudgeBench 是一个具有 2000 个样本的成对基准测试,用于在两个上下文设置(上下文问答和摘要)中评估作为评判者的大语言模型。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/ContextualJudgeBench
BigOBench
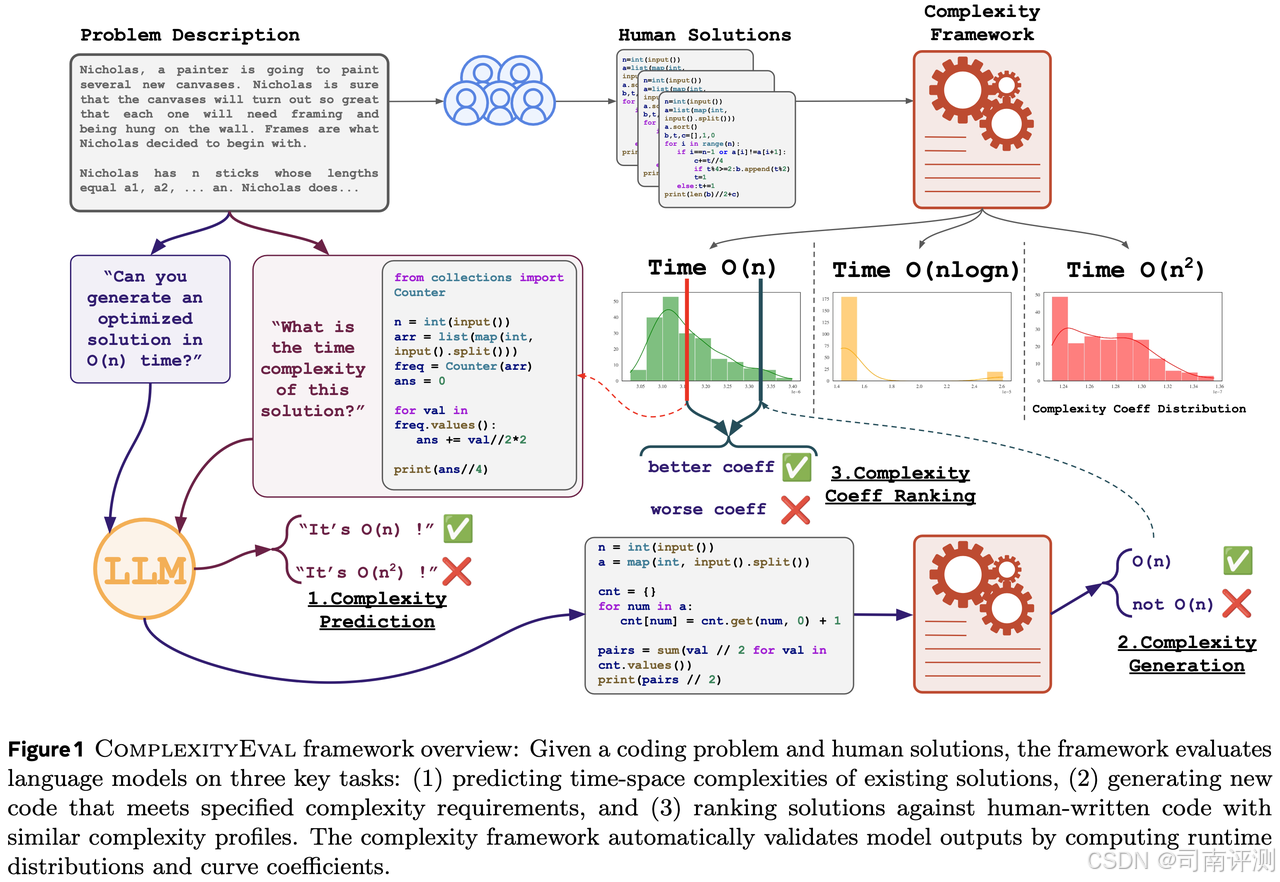
发布单位:
Meta, Inria, etc.
发布时间:
2025-03-19
评测集简介:BigO(Bench)是一个包含约 300 个需要用 Python 解决的代码问题的基准测试,以及 3,105 个编码问题和 1,190,250 个解决方案用于训练,以评估 LLMs 能否找到代码解决方案的时间-空间复杂度,或者生成符合时间-空间复杂度要求的代码解决方案。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/BigOBench
·