更多干货抢先看: 大数据干货合集
在AI技术快速渗透企业场景的当下,如何让AI Agent稳定处理实时海量数据、实现高容错与低时延运行,成为企业数字化转型的关键需求。Apache Flink Agents作为Apache Flink的全新子项目,恰好填补了这一空白,将流处理能力与AI Agent功能深度融合,为企业级Agent应用提供了全新解决方案。以下从项目概览、核心价值、技术特性包括Java/Python/SQL code示例、版本与roadmap等方面,梳理其核心要点。

项目概览 - 项目架构、定位与基础信息
Apache Flink Agents是基于Apache Flink构建的智能体AI框架,用于在Flink的流处理运行时之上直接构建事件驱动的AI智能体,属于Apache Flink的全新子项目。它在同一框架内统一了流处理与自主智能体能力,将Flink在分布式、大规模、容错的结构化数据处理能力以及成熟的状态管理机制等方面的成熟优势,与构建Agent所需的能力(LLM、工具、记忆与动态编排)相结合。
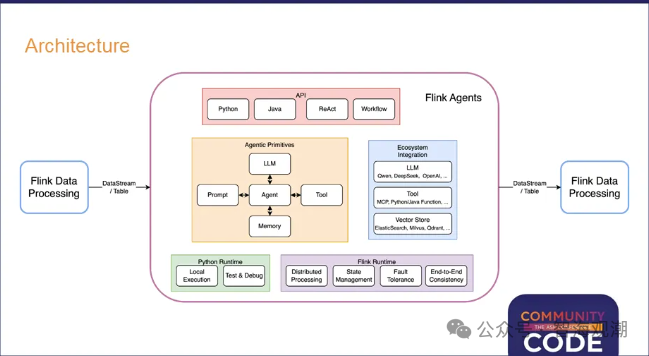
图片来自Apache Flink PMC成员宋辛童在Community Over Code Asia 2025 Streaming分享
从基础配置来看,其构建依赖特定环境与工具,需运行在类Unix环境(如Linux、Mac OS X、Cygwin、WSL),同时需要Git、Maven、Java 11以及Python3.10或3.11版本。开发者可通过git clone https://github.com/apache/flink-agents.git克隆项目,再借助./tools/build.sh脚本构建Java和Python部分,并将Flink Agents的dist jar安装到Python wheel包中,为后续开发与使用奠定基础。
核心价值 - 解决行业痛点与独特优势、应用场景
当前企业构建AI Agent存在很多痛点。比如,现有多以同步、一次性交互为主,难以处理实时事件;传统方式需整合多系统(如流处理、模型推理、编排),导致运营复杂、迭代慢。Apache Flink Agents依托Flink优势,能处理实时高吞吐事件流,支持智能体自主运行,保障安全性与故障恢复,还降低开发门槛,推动其企业规模化落地。
实时直播分析智能助手和智能运维系统应用场景示例架构图。
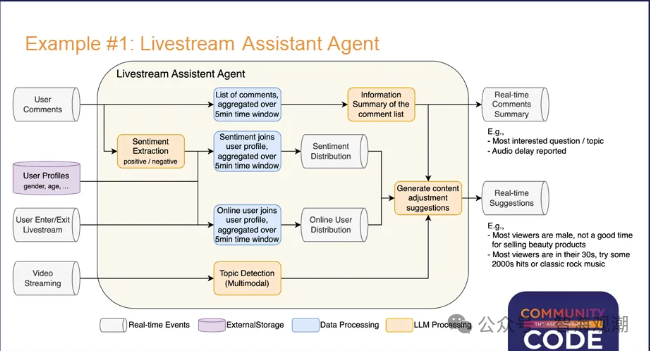
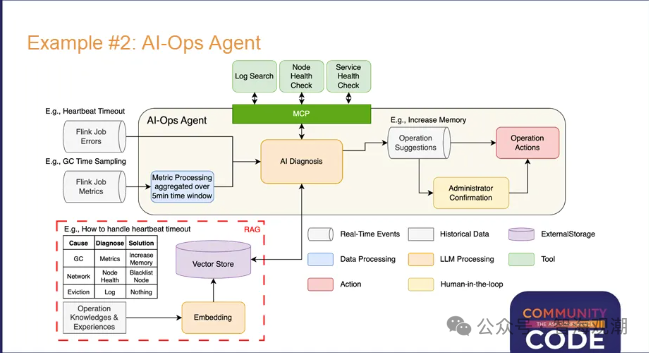
图片来自Apache Flink PMC成员宋辛童在Community Over Code Asia 2025 Streaming分享
技术特性 - 功能与接口设计
核心功能
Apache Flink Agents的核心功能围绕智能体构建、运行与优化全流程展开,覆盖模型、工具、数据处理、容错等多个关键环节。
- 模型与工具支持。支持定义和调用模型进行推理,可对接主流大语言模型,开发者能通过指定模型地址、参数等配置,快速集成所需模型;同时,智能体可调用各类工具,包括SaaS应用、内部服务、自定义函数等,支持通过MCP调用工具,还能纳入本地Flink UDF作为工具,满足多样化业务需求。
- 数据处理与集成。实现了数据处理与智能体工作流的无缝融合,智能体可消费任意数据流作为输入,输出新的数据流,且借助Flink的checkpoint机制,确保数据处理与决策逻辑的端到端一致性,无需额外协调。此外,支持上下文搜索功能,能通过向量搜索、JDBC、REST等方式获取外部上下文,丰富智能体的决策依据。
- 生命周期与状态管理。提供智能体的初始化、运行、销毁全生命周期支持,同时具备状态管理能力,智能体可持久化和查询上下文,无需依赖外部存储,能在不同调用间共享状态,保证决策的连贯性与准确性。
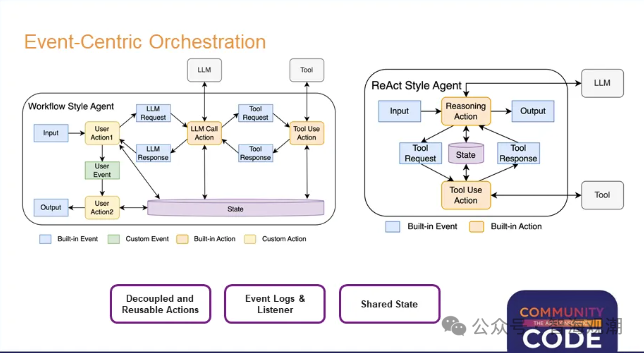
- 可观测性与可复现性。采用以事件为中心的编排方式,智能体的所有操作都通过事件连接与控制,开发者可通过事件日志观察和理解智能体行为,便于问题排查与优化;原生支持利用Kafka等流存储重放历史事件流,支持回归测试、智能体调试、模型漂移分析和事后决策追溯,提升开发与运维效率。
- 多智能体通信。内置异步多智能体通信支持,基于Kafka等流存储实现智能体间消息传递,消息可重放、路由和持久化,为构建复杂的多智能体协作系统提供基础。
编程接口
为适配不同开发者的习惯与需求,Apache Flink Agents提供了多种编程接口,且与Flink现有API深度融合,降低学习与使用成本。
-
Java API(Flink Table API)。开发者可通过该接口连接外部资源(如MCP服务器、OpenAI端点),利用CREATE MODEL语法注册模型,定义包含模型、工具、提示词的智能体工作流,再将智能体应用于Table输入并生成Table输出,充分利用Flink Table API的声明式数据转换能力。

-
Python API(PyFlink Table和DataStream API)。支持通过AgentWorkflow 类定义智能体,可同时在PyFlink Table 和 DataStream API中使用,开发者能自定义工作流类,定义工具、MCP服务器、模型以及工作流步骤,灵活实现智能体的业务逻辑,适配Python生态下的开发需求。

-
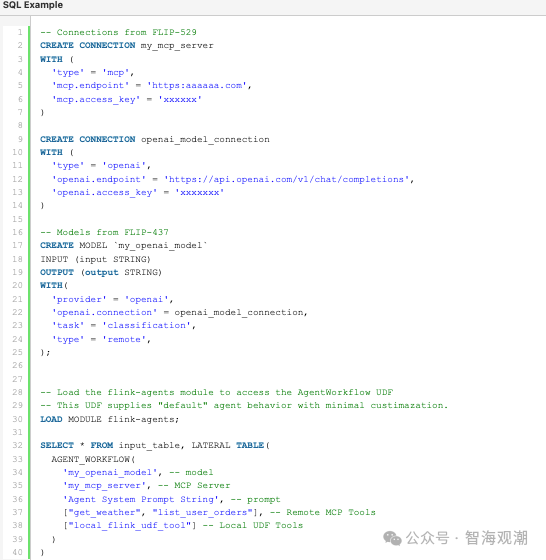
Flink SQL。通过加载Flink - agents模块,开发者可使用AGENT_WORKFLOW UDF实现智能体功能,支持创建连接、注册模型,并通过SQL语句调用智能体工作流,让熟悉SQL的开发者也能快速构建智能体应用,进一步扩大了项目的适用人群范围。
版本与Roadmap - 当前状态与未来规划
现有版本情况
2025年10月份,Apache Flink社区发布了Apache Flink Agents的首个预览版本0.1.0,开发者可从https://flink.apache.org/downloads/#apache-flink-agents下载该版本。需要注意的是,此版本为预览版,可能存在部分已知或未知问题,已知问题列表及解决状态可在GitHub Issues(https://github.com/apache/flink-agents/issues)查看;同时,当前的API与配置选项处于实验阶段,后续版本可能会有不向后兼容的变更,因此不建议在对稳定性要求高的生产环境中使用。不过,该版本的发布标志着项目进入实际应用验证阶段,为后续版本优化提供了重要的实践依据。
未来Roadmap
Apache Flink Agents项目遵循分阶段的roadmap,以快速交付可用MVP(最小可行产品)为目标,再根据用户反馈与实际需求扩展功能。
- MVP 设计阶段(2025年5 - 6月)
此阶段主要完成核心组件、架构、接口以及功能范围的定义,为后续开发明确方向与框架,确保项目从一开始就具备清晰的技术路线与目标。 - MVP 开发阶段(2025年 7 - 8月)
重点实现模型支持、工具调用、上下文搜索、生命周期与上下文管理、可复现性等核心功能,搭建起项目的基本功能框架,让项目具备初步的使用价值。 - 多智能体与示例阶段(2025年9月)
开发多智能体通信功能,同时构建示例应用,展示项目在实际场景中的应用方式,帮助开发者更好地理解与使用项目,推动项目的推广与落地。 - MVP 发布阶段(2025年10月)
完成MVP版本的发布与公告,正式将项目推向市场,收集用户反馈,为后续版本优化提供依据。 - MVP 后扩展阶段(2025年第四季度及以后)
在MVP版本基础上,正式引入FLIP流程,规范项目设计与开发流程;同时,增加多智能体协调、可观测性增强等新功能,持续提升项目的性能与功能丰富度,满足企业日益复杂的业务需求。
更多详情请查阅:
https://github.com/apache/flink-agents
https://nightlies.apache.org/flink/flink-agents-docs-main/
更多干货抢先看: 大数据干货合集