在计算技术快速迭代的今天,传统通用处理器(CPU)正逐步被专用硬件加速器补充或替代,尤其在特定计算领域。这些加速器通过针对性设计,在功耗效率、计算吞吐量(FLOPS)和内存带宽方面实现了显著优化。截至2025年4月,加速器市场需求呈指数级增长,主要驱动因素来自人工智能(AI)、机器学习(ML)、高性能计算(HPC)及边缘计算应用的广泛部署。本文将深入剖析五类主要计算加速器------GPU、FPGA、ASIC、TPU和NPU,从技术架构、性能特点、应用领域到产业生态进行系统化比较,并分析在不同应用场景下各类加速器的适用性。
硬件加速器的基本原理与关键指标
硬件加速器是专门设计用于从通用CPU卸载特定计算任务的专用处理设备,通过架构优化实现高效执行。与追求通用性的CPU不同,加速器聚焦于针对特定计算模式的并行处理能力、低延迟响应和能源效率优化。这些设备通过定制化微架构,特别适合处理具有重复性和计算密集特性的操作,如深度学习中的矩阵乘法运算或电信领域的信号处理。
评估加速器性能的关键技术指标包括:
- 计算能力(FLOPS):每秒浮点运算次数,直接反映处理器在科学计算和AI训练等场景的原始计算能力。
- 内存带宽:数据在存储单元与处理单元间的传输速率,通常构成高吞吐量应用的主要瓶颈。
- 能源效率:单位能耗下的计算性能,通常以每瓦特FLOPS或每焦耳操作数量衡量,对移动设备和边缘计算尤为重要。
下文将详细探讨各类加速器的技术架构、性能特性及其在实际应用中的优势。

1、图形处理单元(GPUs)
技术架构与演进
图形处理单元最初设计用于图形渲染加速,但由于其高度并行的处理架构,已发展成为通用计算加速的主导平台。现代GPU集成了数千个针对单指令多数据(SIMD)操作优化的处理核心,形成了高度并行的计算矩阵,特别适合处理需要同时执行相同指令的大规模数据集。
技术规格与性能参数
- 计算性能:以NVIDIA Ampere架构A100 GPU为例,在双精度(FP64)计算中可达19.5 TFLOPS,而在使用Tensor Cores进行AI工作负载处理时,性能可提升至312 TFLOPS。
- 内存带宽:A100采用HBM3(高带宽内存)技术,提供高达1.6 TB/s的内存带宽,远超传统CPU使用的DDR内存系统。
- 功耗特性:全负载运行时功耗约400W,反映了高性能计算处理器的能源需求特征。
技术优势
GPU架构的核心优势在于其大规模并行处理能力,数千个计算核心可同时执行多线程任务,极大加速矩阵运算和向量处理。高带宽内存技术有效缓解了数据传输瓶颈,确保计算核心能够持续获得数据供给。通过CUDA、OpenCL等并行计算框架,GPU实现了从专用图形处理向通用计算的扩展,支持多样化应用场景。
应用领域
- AI模型训练与推理:GPU在深度学习领域占据主导地位,为TensorFlow、PyTorch等框架提供基础计算能力,支持大规模神经网络的训练和部署。
- 科学计算模拟:凭借强大的浮点运算能力,GPU广泛应用于物理、化学和气候模拟等计算密集型科学研究领域。
- 区块链与加密计算:GPU的并行计算架构适合处理加密货币挖矿所需的重复性哈希运算。
主要厂商与产品线
- NVIDIA:作为GPU市场领导者,提供从数据中心级A100、H100、H200、GB2000到消费级GeForce RTX系列产品。其CUDA生态系统显著增强了GPU的可编程性和应用扩展性。
- AMD:通过Instinct MI系列(如具备141 TFLOPS FP32性能的MI300X)与NVIDIA形成市场竞争,在性价比方面具有一定优势。
- Intel:近年通过Gaudi、Arc和Data Center GPU Max系列产品积极拓展GPU市场,专注于AI加速和高性能计算领域。
与其他加速器的比较
GPU在并行计算能力和原始FLOPS性能上通常优于CPU,但在特定任务的能效比上可能不及FPGA或ASIC。其通用计算架构使其比ASIC和TPU更具灵活性,但在固定计算任务上效率相对较低。
2. 可程序化逻辑门阵列(FPGAs)
技术架构与特性
FPGA是一种可在制造后重新配置的集成电路,由可编程逻辑块、可配置互连和I/O单元组成。与固定架构的GPU不同,FPGA允许开发者根据特定算法需求定制硬件电路,提供了灵活性与性能之间的优化平衡。
技术规格与性能参数
- 计算性能:Xilinx Versal ACAP系列根据具体配置可提供约10-20 TFLOPS的浮点性能,但这一参数会随着逻辑资源配置而显著变化。
- 内存带宽:中端FPGA通常采用DDR4/DDR5接口实现100-200 GB/s带宽,高端型号如Intel Stratix 10集成HBM2可达1 TB/s。
- 功耗特性:功耗范围较广,中端FPGA如Xilinx Zynq UltraScale+系列在典型工作负载下消耗约10-50W,取决于逻辑资源利用率和时钟频率。
技术优势
FPGA的关键优势在于其可重配置性,允许在部署后针对新算法或工作负载进行硬件架构优化。由于可以构建定制化数据通路,FPGA在实时处理应用中表现出极低的处理延迟。同时针对特定任务优化的FPGA设计通常比通用GPU具有更高的能源效率。
应用领域
- 边缘计算:凭借低功耗和低延迟特性,FPGA适合在智能摄像头和传感器等物联网设备中进行AI推理加速。
- 电信基础设施:广泛应用于5G基站的信号处理和网络数据包路由。
- 金融交易系统:定制逻辑设计有效降低高频交易系统的处理延迟。
主要厂商与产品线
- Xilinx (AMD):以Versal和Zynq系列闻名,提供集成ARM处理器核心的异构FPGA解决方案。
- Intel:生产Stratix和Agilex系列FPGA,部分高端型号集成HBM以满足高带宽应用需求。
- Lattice Semiconductor:专注于低功耗FPGA产品线,如面向边缘计算的CrossLink-NX系列。
与其他加速器的比较
FPGA在原始计算性能(FLOPS)方面通常低于GPU,但在延迟敏感和功率受限的应用环境中表现优异。与ASIC相比,FPGA对固定功能任务的能效较低但灵活性显著提高。在未集成HBM的情况下,FPGA的内存带宽通常低于高端GPU。

3、特定应用集成电路(ASICs)
技术架构与设计理念
ASICs是为执行特定功能而定制设计的微处理器,其电路结构针对固定工作负载进行了优化,提供了无可比拟的执行效率。ASIC设计通过牺牲灵活性换取极致性能和能效,一旦制造完成,其功能就被固定。
技术规格与性能参数
- 计算性能:Google的Edge TPU针对整数运算优化,提供约4 TOPS(每秒万亿次操作)的推理性能。
- 内存带宽:性能差异显著;高端ASIC如Cerebras WSE-2采用创新内存架构,实现高达20 PB/s(每秒拍字节)的片上带宽。
- 功耗特性:Edge TPU设计功耗仅2W适合边缘设备,而WSE-2因其庞大规模和高性能需求,总功耗约23kW。
技术优势
ASIC的最大优势在于针对特定计算任务的极致优化,实现最佳的性能功耗比。集成片上内存架构减少了芯片外数据传输,显著提升了处理效率。如WSE-2等新型大规模ASIC架构可处理规模超出传统GPU能力范围的复杂工作负载。
应用领域
- AI边缘推理:如Google Edge TPU为移动设备中的轻量级机器学习模型提供高效推理能力。
- 深度学习训练:Cerebras WSE-2等大型ASIC加速数据中心中的大规模神经网络训练。
- 加密货币处理:Bitmain等公司的专用ASIC凭借高度优化的哈希算法实现在比特币挖矿中的主导地位。
主要厂商与产品线
- Google:自主开发TPU和Edge TPU系列,专为AI工作负载优化。
- Cerebras Systems:开创性地研发晶圆级ASIC架构,如WSE-2等面向深度学习的超大规模处理器。
- Bitmain:在加密货币挖矿ASIC领域处于领先地位,以Antminer系列产品著称。
与其他加速器的比较
ASIC在其特定设计任务上的效率和带宽表现通常远优于GPU和FPGA,但缺乏应对算法变化的灵活性。对于通用计算任务,其原始计算性能可能低于高端GPU,而高昂的设计和生产成本限制了其应用范围,主要集中于大规模部署或特定领域应用。
4、张量处理单元(TPUs)
技术架构与设计哲学
张量处理单元是Google开发的一类特殊ASIC,专为加速神经网络中的张量运算而设计。TPU在通用计算架构的GPU和高度专用化的ASIC之间找到了平衡点,通过对机器学习核心计算模式的优化实现高效处理。
技术规格与性能参数
- 计算性能:TPU v4每芯片提供约275 TOPS(INT8精度),在大规模集群配置中可实现艾级(ExaFLOPS)计算能力。
- 内存带宽:TPU v5架构采用HBM3技术,单芯片实现高达1.2 TB/s的内存带宽。
- 功耗特性:完整的TPU v4 pod集群总功耗约500kW,但单个芯片能效较高,功耗约100W。
技术优势
TPU的核心优势在于其专为机器学习优化的矩阵乘法单元(MXU),能高效处理神经网络中的关键张量运算。TPU pod架构支持数千个处理单元的互连,实现大规模并行计算。此外,TPU与TensorFlow等框架的深度集成确保了软硬件协同优化。
应用领域
- 云端AI服务:Google Cloud TPU为大规模机器学习模型提供训练和推理基础设施。
- 前沿研究:支持AlphaGo和大型语言模型等前沿AI研究项目。
- 大规模数据分析:加速结构化数据集的处理与分析。
主要厂商
Google作为TPU的唯一研发和生产厂商,通过Cloud TPU服务和Edge TPU产品线向市场提供TPU计算能力。
5、神经处理单元(NPUs)
技术架构与设计思路
神经处理单元是为神经网络推理优化的新型专用加速器,通常集成在移动设备和边缘计算平台的系统级芯片(SoC)中。NPU设计优先考虑低功耗运行和实时推理能力,以适应资源受限环境。
技术规格与性能参数
- 计算性能:Apple M2芯片中的Neural Engine提供约15.8 TOPS的推理性能。
- 内存带宽:通常在50-100 GB/s范围,主要利用片上SRAM缓存优化数据访问。
- 功耗特性:极低功耗设计,典型工作状态下仅消耗1-5W,为电池供电设备专门优化。
技术优势
NPU的突出优势在于其超低功耗设计,特别适合移动设备和物联网应用。其架构针对实时处理进行优化,在语音识别和图像处理等场景中表现出极低延迟。紧凑型设计允许NPU作为SoC的组成部分,有效节省空间和系统成本。
应用领域
- 移动计算平台:Apple Neural Engine为Face ID和Siri等功能提供本地AI处理能力。
- 智能驾驶系统:处理自动驾驶汽车中的传感器数据流。
- 消费电子产品:增强AR/VR头显和智能家居设备的交互体验。
主要厂商与产品线
- Apple:在A系列和M系列处理器中集成Neural Engine。
- Qualcomm:在Snapdragon SoC中集成Hexagon NPU。
- 华为:在麒麟处理器中集成自研达芬奇架构NPU。
与其他加速器的比较
NPU在功耗效率和处理延迟方面优于传统GPU和TPU,但计算能力(FLOPS)相对较低,主要针对轻量级推理而非训练任务。相比FPGA,NPU灵活性较低但针对特定神经网络运算的专业化程度更高。
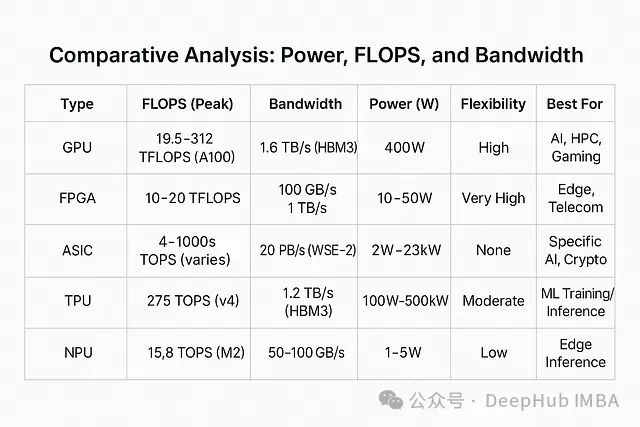
加速器性能对比与选型指南
能效比较
在能效方面,NPU和低功耗ASIC(如Edge TPU)以每芯片不足5W的功耗领先,这使它们成为电池供电设备和边缘计算的理想选择。相比之下,高性能GPU和大型ASIC(如WSE-2)虽然功耗较高,但针对需要极高计算密度的数据中心环境进行了优化。
计算性能比较
在原始计算能力方面,TPU和高端GPU凭借数百TFLOPS/TOPS的性能指标在大规模训练任务中占据主导地位。而FPGA和NPU虽然在绝对计算能力上相对较弱,但在特定任务的效率和延迟优化方面具有独特优势。
内存带宽比较
内存带宽方面,Cerebras WSE-2等新型ASIC架构通过创新片上内存设计实现了拍字节级数据传输能力,重新定义了处理器内存系统的性能极限。而FPGA和NPU则依赖于相对较低带宽的内存系统,更适合数据规模较小的任务处理。
加速器选型建议
- GPU:当需要计算灵活性和原始计算能力时的首选。推荐NVIDIA H100用于大规模AI训练,AMD MI300X适合追求性价比的高性能计算应用。
- FPGA:当应用需要硬件级定制化和低延迟处理时的理想选择。Xilinx Versal系列在边缘计算和电信领域表现尤为出色。
- ASIC:对于固定算法且需要极高吞吐量的工作负载,ASIC提供无与伦比的效率。Cerebras WSE-2在大规模AI研究中具有显著优势。
- TPU:特别适合于深度集成Google生态系统且需要高度可扩展性的机器学习应用场景。
- NPU:当功耗和尺寸约束成为首要考虑因素时,NPU是边缘设备AI推理的最佳选择。
https://avoid.overfit.cn/post/629c2c7bc15a45d98e55f2378f5bed49
作者:Neil Dave