背景
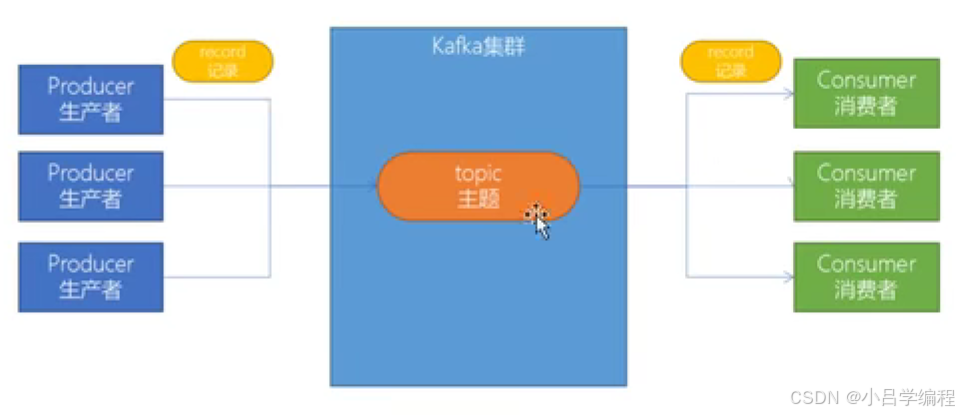
依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.1</version>
</dependency>
发送消息
java
//示例:
private final KafkaTemplate<String, String> kafkaTemplate;
//参数很多可参考官网文档
kafkaTemplate.send(topic, message);接收消息
java
//示例:
@KafkaListener(topics = PositionAnalyseMessage.TOPIC, groupId = "wetool-position-analyse")
public void consume0(PositionAnalyseMessage message) {
this.doConsume(message);
}参数解释
1.在同一个消费组中,同一条消息之后被一个消费者消费
java
// 同组的消费者A
@KafkaListener(topics = "test-topic", groupId = "same-group")
public void consumeA(String message) { }
// 同组的消费者B
@KafkaListener(topics = "test-topic", groupId = "same-group")
public void consumeB(String message) { }2.在不同消费组中,同一条消息会被不同组的消费者都会消费(类似发布订阅)
java
// 订单消息处理
@KafkaListener(topics = "order-topic", groupId = "order-process")
public void processOrder(Order order) {
// 处理订单逻辑
}
// 订单统计
@KafkaListener(topics = "order-topic", groupId = "order-statistics")
public void statisticsOrder(Order order) {
// 统计订单数据
}
// 订单通知
@KafkaListener(topics = "order-topic", groupId = "order-notification")
public void notifyOrder(Order order) {
// 发送订单通知
}3.containerFactory参数的作用
在 Spring Boot 中,
containerFactory是用于自定义 Kafka 消费者监听器行为 的核心配置机制。通过定义不同的containerFactory,可以灵活控制消费者的参数、提交策略、消息处理方式等,以满足不同场景的需求。
一、containerFactory 的核心作用
-
覆盖默认配置
-
修改消费者参数(如自动提交、拉取超时、并发线程数)。
-
指定序列化/反序列化方式(如 JSON、Avro)。
-
配置事务支持、拦截器、错误处理器等。
-
-
区分不同消费场景
- 为不同监听器分配独立的配置(如手动提交 vs 自动提交、单条消费 vs 批量消费)。
-
实现高级功能
-
批量消费(
batchListener=true)。 -
手动提交偏移量(
AckMode.MANUAL)。 -
记录消息投递次数(
deliveryAttemptHeader=true)。 -
添加全局拦截器(日志、监控、消息过滤)。
-
二、containerFactory 的使用示例
示例 1:手动提交偏移量的工厂
场景 :处理支付订单,需确保业务逻辑成功后再提交偏移量,避免数据不一致。
配置:
java
@Bean
public KafkaListenerContainerFactory<?> manualCommitFactory(
ConsumerFactory<Object, Object> consumerFactory) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory =
new ConcurrentKafkaListenerContainerFactory<>();
// 关闭自动提交
Map<String, Object> props = new HashMap<>(consumerFactory.getConfigurationProperties());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(props));
// 手动立即提交模式
factory.getContainerProperties().setAckMode(AckMode.MANUAL_IMMEDIATE);
return factory;
}使用:
java
@KafkaListener(
topics = "payment-orders",
groupId = "payment-service",
containerFactory = "manualCommitFactory" // 指定手动提交工厂
)
public void handlePayment(Order order, Acknowledgment ack) {
paymentService.process(order);
ack.acknowledge(); // 业务成功后提交
}示例 2:批量消费的工厂
场景 :日志聚合服务,需批量消费消息后写入 Elasticsearch。
配置:
java
@Bean
public KafkaListenerContainerFactory<?> batchListenerFactory(
ConcurrentKafkaListenerContainerFactoryConfigurer configurer,
ConsumerFactory<Object, Object> consumerFactory) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory =
new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, consumerFactory);
factory.setBatchListener(true); // 启用批量模式
factory.setMessageConverter(new BatchMessagingMessageConverter()); // 批量消息转换
return factory;
}使用:
java
@KafkaListener(
topics = "app-logs",
containerFactory = "batchListenerFactory" // 指定批量消费工厂
)
public void processLogs(List<LogEntry> logs) {
elasticsearchService.bulkIndex(logs); // 批量写入ES
}示例 3:带拦截器的工厂(记录消息处理耗时)
场景 :监控消息处理性能,统计平均耗时。
配置:
java
@Bean
public KafkaListenerContainerFactory<?> monitoredFactory(
ConsumerFactory<Object, Object> consumerFactory) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
// 添加耗时记录拦截器
factory.setRecordInterceptor(new RecordInterceptor<>() {
@Override
public ConsumerRecord<?, ?> intercept(ConsumerRecord<?, ?> record) {
long startTime = System.currentTimeMillis();
// 处理前记录时间
return record;
}
@Override
public void success(ConsumerRecord<?, ?> record, Object result) {
long duration = System.currentTimeMillis() - startTime;
log.info("消息处理耗时: {}ms", duration);
}
});
return factory;
}使用:
java
@KafkaListener(
topics = "user-events",
containerFactory = "monitoredFactory" // 使用带拦截器的工厂
)
public void handleUserEvent(UserEvent event) {
// 处理用户事件
}| 场景 | 关键配置 | 适用工厂 |
|---|---|---|
| 手动提交偏移量 | enable.auto.commit=false + AckMode.MANUAL_IMMEDIATE |
manualCommitFactory |
| 批量消费 | batchListener=true + max.poll.records=1000 |
batchListenerFactory |
| 事务消息 | producer.transaction-id-prefix=tx- + @Transactional |
需事务支持的工厂 |
| 消息重试与死信队列 | RetryTemplate + DeadLetterPublishingRecoverer |
配置重试策略的工厂 |
| 安全认证(SSL/SASL) | security.protocol=SSL + sasl.jaas.config |
带安全配置的工厂 |
4.concurrency的作用
java
@KafkaListener(topics = "mysql-binlog-content", groupId = "marketing-mysql-binlog-content", concurrency = "1")
public void consumeContentBinlog(@Header("tableName") String table, Binlog binlog) {
BinlogHandleExecutors.handleBinlog(CONTENT,table, binlog);
}concurrency 参数用于控制 Kafka 消费者的并发度,即同时处理消息的线程数量
在这个例子中 concurrency = "1" 表示:
- 只使用一个线程来消费 Kafka 消息
- 消息会按顺序被处理,不会出现并发处理的情况
- 保证了消息处理的顺序性
具体来说:
- 当 concurrency = "1" 时,消息会严格按照 Kafka 分区中的顺序被处理
- 如果设置 concurrency > 1,则会创建多个消费者线程并行处理消息,这可能会提高吞吐量,但会失去消息处理的顺序性
- 对于需要保证消息处理顺序的场景(比如数据库 binlog 处理),通常建议使用 concurrency = "1"
在这个代码中,由于处理的是数据库 binlog 数据,需要保证数据变更的顺序性,所以设置为 1 是合理的。这样可以确保 binlog 事件按照发生的顺序被处理,避免数据不一致的问题。
例如:想象你有一个快餐店,concurrency 就相当于收银台的数量:
- concurrency = "1" 的情况:
- 就像只有一个收银台
- 顾客必须排成一队,一个接一个地结账
- 虽然处理速度可能较慢,但能保证每个顾客都按顺序被服务
- 不会出现顾客 A 比顾客 B 先来,但顾客 B 却先结完账的情况
- concurrency > 1 的情况:
- 就像有多个收银台同时工作
- 顾客可以分散到不同的收银台结账
- 处理速度更快,但可能会打乱顾客的排队顺序
- 可能出现顾客 A 比顾客 B 先来,但顾客 B 先结完账的情况
回到代码中的场景:
- 这个代码处理的是数据库的 binlog(数据库变更记录)
- 就像快餐店的顾客一样,这些变更记录是有顺序的
- 比如:先修改了用户 A 的余额,再修改了用户 B 的余额
- 如果使用 concurrency > 1,可能会先处理用户 B 的修改,再处理用户 A 的修改
- 这就会导致数据不一致,所以这里使用 concurrency = "1" 来确保变更按顺序处理
这就是为什么在处理数据库变更记录时,通常要使用 concurrency = "1" 来保证数据的一致性。