作者:劳贵泓(泓逸)
引言
日志服务的 SPL 作为一种强大的数据处理语言,自发布以来,持续保持迭代创新,不断打磨新版数据加工的能力,现新增了 pack-fields、log-to-metric、metric-to-metric 算子,增强了数据规整的能力,优化了从日志格式到时序指标的转化链路,显著拓展了业务场景在可观测性和时序预测领域的应用空间。在开发过程中,梳理了一些大家口口相传的开发范式,期望能够由浅入深的对 SPL 的开发过程进行一个全方位的介绍。

- pack-fields:对应旧版加工的算子 e_pack_fields,将多个字段打包成一个结构化的 Json 对象
- log-to-metric: 对应旧版加工的算子 e_to_metric,将日志格式转化为时序存储的格式
- metric-to-metric:新增算子,给 Metric 时序数据提供新的处理方式,主要包括 add、del、rename
新算子功能详解

2.1 pack-fields 算子
2.1.1 场景与问题
在实际业务中,多字段分散存储常导致处理效率低下。新版 pack-fields 算子通过字段打包功能极大降低了数据传输成本,同时新增了字段修剪功能,能够高效提取符合正则表达式的 KV 结构,进一步增强数据规整的灵活性。
2.1.2 核心改进
对比旧版 e_pack_fields:新增字段修剪功能(ltrim='mdc_'),可以提取出字段值中满足正则表达式的所有 KV 结果,并打包赋值给指定字段。
python
# 输入数据
content: 'k1=v1&k2=v2?k3:v3'
# 输出数据
mdc : {"k1":"v1", "k2":"v2"}
# 旧版加工
e_regex("content", r"(\w+)=(\w+)", {r"\1": r"\2"}, pack_json="mdc")
# 等价于
* | parse-kv -prefix="mdc_" -regexp content, '(\w+)=(\w+)' | pack-fields -include='mdc_.*' -ltrim = 'mdc_' as mdc2.1.3 示例
makefile
# 输入数据
__time__: 1614739608
rt: 123
qps: 10
host: myhost
# SPL语句
* | log-to-metric -names='["rt", "qps"]' -labels='["host"]'
# 输出两条Metric日志
__labels__:host#$#myhost
__name__:rt
__time_nano__:1614739608
__value__:123
__labels__:host#$#myhost
__name__:qps
__time_nano__:1614739608
__value__:102.2 log-to-metric
2.2.1 场景与问题
解决非结构化日志转时序数据的链路场景,并提高转化性能。相较于旧版算子,默认使用 Hash 写入,保证了写入端的 shard 均衡,提高查询性能。

2.2.2 核心改进
将非结构化的日志数据转换为结构化的指标数据。
- 新增通配符批量匹配(request*)
- 自动类型推断(数值型自动转为 metric 值)
- 一键 format(对 key 和 value 进行数据规范)
2.2.3 示例
makefile
# 输入数据
__time__: 1614739608
rt: 123
qps: 10
host: myhost
# SPL语句
* | log-to-metric -names='["rt", "qps"]' -labels='["host"]'
# 输出两条Metric日志
__labels__:host#$#myhost
__name__:rt
__time_nano__:1614739608
__value__:123
__labels__:host#$#myhost
__name__:qps
__time_nano__:1614739608
__value__:102.3 metric-to-metric**
2.3.1 场景与问题
时序数据的来源可能来自于不同端,可能是 ilogtail、openTelemetry 亦或者是其他 SDK,在数据采集的过程中,不可避免的会出现脏数据的情况,影响 Metric 时序数据库的查询能力,出现查询不准确或者查询失败的情景。新增 metric-to-metric 算子可以对已有时序数据进行二次加工,支持添加、删除和修改标签,同时直击数据结构问题,统一提供修复能力。
2.3.2 创新功能
对已有时序数据进一步加工(如添加/修改/删除标签),并提供了一键 format 非法数据的能力。
2.3.3 示例
makefile
# 输入数据
__labels__:host#$#myhost|qps#$#10|asda$cc#$#j|ob|schema#$#|#$#|#$#xxxx
__name__:rt
__time_nano__:1614739608
__value__:123
# SPL语句
*|metric-to-metric -format
# 输出数据
__labels__:asda_cc#$#j|host#$#myhost|qps#$#10
__name__:rt
__time_nano__:1614739608
__value__:123
makefile
# 输入数据
__labels__:host#$#myhost|qps#$#10
__name__:rt
__time_nano__:1614739608
__value__:123
# SPL语句
* | metric-to-metric -del_labels='["qps"]'
# 输出数据
__labels__:host#$#myhost
__name__:rt
__time_nano__:1614739608
__value__:123性能优化范式
本章主要探索在 SPL 新算子开发过程中的优化范式,和旧版加工的 DSL 不同,新版加工的 SPL 算子更加注重性能的极致编程。新算子的开发不是一个简单的从行计算转变为列计算的过程 ,涉及到了更加复杂的技术栈,如内存管理,高效 C++ 开发等,是具有一定挑战性的技术课题。本章旨在给大家提供了一个从实战角度出发,基于需求的场景为切入点的一个 SPL 新算子的研发手册。
3.1 基线问题
对于常见的需求开发,以第一章所提出的三个算子为例,在开发过程中,可能会遇到如下几个问题:
- 内存拷贝过多(单条日志处理产生 3 次拷贝以上)
- 数据结构低效 (不必要的 set 和 map)
3.2 优化范式
本节对以上的常见问题进行逐一的拆解,每个场景都是本人在开发过程中所遇到的问题,每个真实案例都会提供研究范式示例,以供参考。
3.2.1 内存使用问题
3.2.1.1 使用 SplStringPiece 避免字符串拷贝

在 velox 中,字符串类型通常通过 StringView 表示,而不是直接使用 std::string。StringView 是一个轻量级的对象,包含指向原始数据的指针和长度信息,避免了字符串的深拷贝。SPL 提供了 SplStringPiece 的类封装了 StringView 的实现,如果你的 UDF 涉及字符串操作,尽量使用 SplStringPiece 而不是创建新的 std::string。
arduino
#include "spl/util/SplStringPiece.h"
void processString(const SplStringPiece& input, SplStringPiece& output) {
// 直接操作 StringView,无需拷贝
output = input.substr(0, input.size() / 2);
}3.2.1.2 避免临时对象
在新算子的实现中,尽量避免创建临时对象(如 std::vector 或 std::string),因为这些对象会在堆上分配内存。如果必须使用临时对象,可以考虑通过栈分配或对象池来管理。
尽量使用引用(const 引用或非常量引用)作为函数参数,以避免数据的拷贝。通过传递引用,可以直接操作原始数据而不需要创建副本。
c
bool call(std::string result, std::string input); // 大量字符串拷贝
bool call(SplStringPiece& result, const SplStringPiece& input);在使用 std::emplace_back()不需要构建临时对象,会自动调用构造函数。
c
std::vector<std::pair<SplStringPiece, SplStringPieceVector>> spsVec;
spsVec.emplace_back(std::make_pair(SplStringPiece(field), makeStringPiece(input)));
#等价于
spsVec.emplace_back(SplStringPiece(field), makeStringPiece(input));3.2.1.3 使用 std::move 进行转移
当需要将对象的所有权转移给另一个对象时,可以使用 std::move 来避免不必要的拷贝。通过使用 std::move,可以将对象转换为右值引用,从而触发移动语义。
css
for (vector_size_t i = 0; i < taskData.data_->size(); i++) {
std::string label;
process(label);
output.push_back(std::move(label));//改变临时对象的所有权
}3.2.1.4 可以用 thread_local 避免频繁需要使用的临时变量,避免内存的重新分配
css
for (vector_size_t i = 0; i < taskData.data_->size(); i++) {
// thread_local
std::string label;
process(label);
output.push_back(label);
}如果每次需要使用某个变量时都通过 new 或其他方式动态分配内存,会导致以下问题:
- 性能开销:动态内存分配涉及堆管理,可能会触发系统调用,增加延迟。
- 内存碎片:频繁分配和释放小块内存可能导致内存碎片化,影响程序的整体性能。
- 使用 thread_local,变量的内存是在线程创建时一次性分配的,并在线程销毁时自动释放,避免了动态分配的开销。
3.2.1.5 如何处理 std::string 和 SplStringPiece 的关系
在 SPL 项目中,SplStringPiece 因为不持有内存, 使用起来其实没有 std::string 方便, 大型项目要把 std::string 全部改成 SplStringPiece 是不太现实的, 而 SplStringPiece/std::string 混用则很容易产生临时对象。实践中可以这么处理:
- 流量相关的数据结构使用 SplStringPiece 来提升处理请求的性能
- 用户配置相关的数据结构仍然使用 std::string 更方便和安全
3.2.2 数据结构
3.2.2.1 更高效的数据结构
思考:unordered_set 是否可以换成 Bitmap
如果你需要存储的是整数集合,并且这些整数在一个固定范围内,bitmap 是一个非常高效的选择,尤其是在内存敏感的应用中。
c
//一些简单的检查实现
bool TaskData::delCols(const VectorBuilderPtr& vbPtr, const std::unordered_set<SplStringPiece>& fieldSet) {
const auto& fields = data_->type()->asRow().names();
for (uint32_t c = 0; c < fields.size(); ++c) {
if (fieldSet.count(SplStringPiece(fields[c])) > 0 && canFieldDoDelRuntime(SplStringPiece(fields[c]) , parserMode)) {
continue;
}
}
}
//可以选择更加高效的bitmap
bool TaskData::delCols(const VectorBuilderPtr& vbPtr, const std::vector<bool>& fieldMarked) {
const auto& fields = data_->type()->asRow().names();
for (uint32_t c = 0; c < fields.size(); ++c) {
if (fieldMarked[c] && canFieldDoDelRuntime(SplStringPiece(fields[c]) , parserMode)) {
continue;
}
}
}
}3.3 优化效果
经过以上的一套组合拳,我们已经实现了基本的需求,到了交付环节,本节分析一下具体效果,看一下是否符合预期,所使用的测试数据集为线上生产日志。
3.3.1 log-to-metric性能提升
此处简单介绍一下测试脚本:case1 作为 benchmark;case1、case2、case3 是对于参数 -names 复杂度的递增;case1、case4、case5 是对于参数 -labels 负责度的递增;case7 为综合场景,并加入了 -format 参数

结论:参数 -names 受优化影响较大,考虑到 -names 的参数复杂度决定了数据富化的膨胀程度,在性能优化上存在指数级的放大,因此实际上符合预期。
3.3.2 metric-to-metric性能提升
此处简单介绍一下测试脚本:case1、case2、case3 分别是增加/修改/删除标签的场景;case4 为综合场景,并加入了 -format 参数
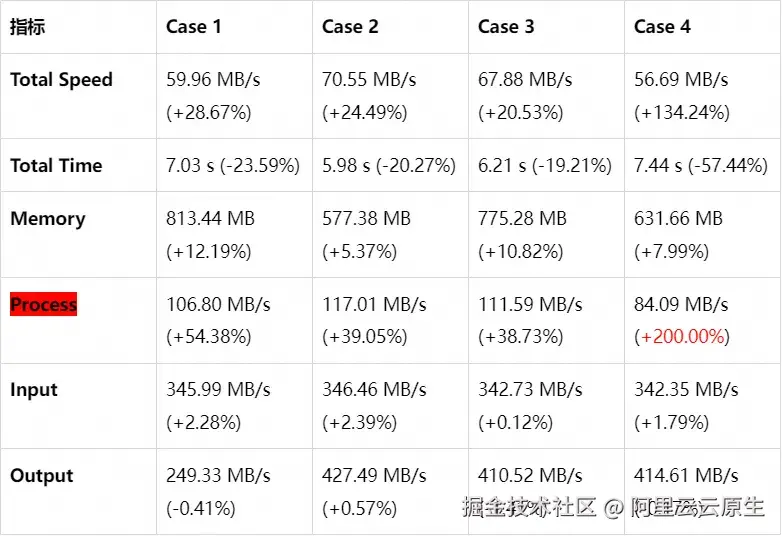
结论:参数 -format 受优化影响较大,format 的操作比较复杂,包含了数据的拆分、过滤和重组,也是符合预期的。
3.4. 相较于旧版加工的能力提升
3.4.1 测试说明
由于旧版加工和新版加工在工程实现上存在较大差异(如内存中的数据格式不一致),因此无法完全模拟出一致的 benchmark 场景。为了尽可能保证测试结果的公平性,我们通过 mock 一批内存大小差异不大的数据,针对端到端场景的关键指标进行了测试。以下为详细的测试结果与分析。
3.4.2 关键性能指标对比

新版的加工能力针对 log-to-metric 和 pack-fields 两种模块进行了全面的性能优化。从测试结果可以得出以下结论:
- 端到端性能显著提升:新版框架优化了输入、处理和输出的全流程,尤其是数据处理阶段的性能优化显著。log-to-metric 模块性能整体提升 7.17 倍,而 pack-fields 模块提升更为显著,达到 37.23 倍。
- 处理速度的突破:两种模块的处理速度分别提升了 27.8 倍 和 51.52 倍,解决了旧版中处理阶段效率不足的问题。
新版在工程实现上的优化方向非常明确且效果显著,通过性能改进全面解决了旧版的瓶颈问题,为数据加工任务提供了更强的处理能力和更高的吞吐量。
结语
此次 SPL 加工能力的迭代更新,以"性能提升"、"场景支持多样化"和"易用性优化"为核心目标,在以下几个方面取得了显著突破:
- 极致性能与稳定性:基于灵活的加工框架、先进的编码模式及 C++ 实现的存储与计算引擎,新算子在资源复用与性能优化方面全面领先,尤其在高负载或复杂数据场景下,仍能保持稳定的写入与读取性能。新版加工算子性能较旧版普遍提升 10 倍以上,为处理海量数据和加速分析效率提供了坚实保障。
- 使用体验升级:SPL 采用类 SQL 的语法设计,支持多级管道化操作的灵活组合,显著降低用户的使用门槛。新增的一键格式化、字段通配符匹配等功能,大幅简化了复杂加工任务的操作步骤,为用户带来更加便捷高效的开发体验。
- 业务可观测性与扩展能力:完美支持从日志到指标的链路打通,帮助用户构建端到端的可观测体系。满足日志聚合、时序预测及异常检测等多种场景需求,为业务的日志分析、可观测性打造了一体化解决方案。
SPL 算子不仅完成了旧版 DSL 加工向更强大语法和算子形式的过渡,更将性能调优和场景适配做到了极致,解锁了时序预测和日志分析的更多可能性。作为重要的基础设施模块,SPL 加工能力将持续优化演进。未来的规划将继续聚焦通用性、性能与产品能力,为用户提供更加强大、灵活的技术支持。