解密 Kubernetes Device Plugin:让容器轻松驾驭特殊硬件
在容器化技术飞速发展的今天,容器凭借轻量、隔离、可移植的特性成为应用部署的主流选择。但在实际应用中,当容器需要访问 GPU、FPGA 等特殊硬件资源时,事情就变得不那么简单了。Kubernetes 中的 Device Plugin(设备插件)正是为解决这一难题而生,它如同一位"桥梁工程师",让容器与宿主机的特殊硬件之间搭建起稳定、高效的沟通通道。
一、容器访问硬件的"天然障碍":为什么需要 Device Plugin?
容器的核心优势之一是"隔离性"------它通过 Linux 命名空间(Namespaces)和控制组(cgroups)等技术,为应用打造独立的运行环境,同时限制其对宿主机资源的无序占用。这种隔离性在处理 CPU、内存等"标准化资源"时表现出色:
- CPU :容器通过 cgroups 共享宿主机的 CPU 时间片,管理员可通过
--cpus等参数限制使用量; - 内存 :同样依托 cgroups 进行配额管理,
--memory等参数能精准控制内存占用。
然而,当面对 GPU、FPGA、高性能网卡等"特殊硬件"时,容器的隔离性反而成了"绊脚石"。以最常用的 GPU 为例:
- GPU 的设备文件(如
/dev/nvidia0)和驱动库(如/usr/local/nvidia/lib64)默认不会暴露给容器,否则可能破坏容器的隔离性,甚至导致硬件资源被滥用; - 不同型号的 GPU 驱动依赖不同,容器若想正常调用 GPU,必须匹配宿主机的驱动环境,这与容器"一次打包、到处运行"的理念相悖;
- 集群中 GPU 数量有限,若缺乏统一的调度机制,可能出现多个容器争抢同一 GPU 的情况,导致资源浪费或应用崩溃。
显然,CPU、内存等标准化资源的管理方式无法直接套用到特殊硬件上。为了让容器安全、高效地使用这些"特殊资源",Kubernetes 引入了 Device Plugin 机制------它既是特殊硬件的"管理员",也是容器与硬件之间的"翻译官"。
二、Device Plugin 的核心使命:连接容器与特殊硬件
Device Plugin 的核心作用可以概括为一句话:让 Kubernetes 集群"感知"特殊硬件的存在,并协调容器对硬件的有序使用。具体来说,它承担着三大关键任务:
1. 设备发现与注册:让集群"看见"硬件
宿主机上的特殊硬件(如 GPU 的型号、数量,FPGA 的设备路径)对 Kubernetes 而言是"隐形"的。Device Plugin 首先要做的,就是让集群"感知"到这些硬件的存在:
- 自动探测 :启动后,Device Plugin 会扫描宿主机,识别出所有可用的特殊设备(例如检测到 2 块 NVIDIA Tesla T4 GPU,设备文件分别为
/dev/nvidia0和/dev/nvidia1); - 资源注册 :将探测到的设备以"标准化名称"(格式为
vendor-domain/resourcetype,如nvidia.com/gpu)注册到节点的 kubelet 中。此后,Kubernetes 集群就能通过节点状态感知到这些资源(例如"该节点有 2 块nvidia.com/gpu")。
2. 设备分配与调度:让容器"按需取用"
当用户的 Pod 声明需要特殊硬件(例如在 resources.limits 中指定 nvidia.com/gpu: 1)时,Device Plugin 会配合 Kubernetes 调度器完成资源分配:
- 可用性检查:检查节点上的特殊设备是否空闲,避免重复分配(例如确保同一块 GPU 不会被两个 Pod 同时占用);
- 精准分配 :确定可用设备后,告知 kubelet 具体的设备 ID(如
GPU-abc123),确保 Pod 能"一对一"绑定到硬件。
3. 容器资源注入:让硬件"为容器所用"
即使设备已分配,容器若无法访问硬件的驱动和配置,仍无法正常工作。Device Plugin 会通过 Allocate 等方法,将硬件相关的资源"注入"容器:
- 环境变量 :例如注入
NVIDIA_VISIBLE_DEVICES=GPU-abc123,告诉容器"使用这块 GPU"; - 设备文件映射 :将宿主机的
/dev/nvidia0等设备文件映射到容器内,让容器直接与硬件交互; - 驱动挂载 :将宿主机的 GPU 驱动库(如
/usr/local/nvidia/lib64)挂载到容器,解决容器内驱动缺失问题。
通过这三步操作,原本"隔绝"的容器与特殊硬件被紧密连接起来,应用无需修改代码就能像使用本地硬件一样调用宿主机的 GPU 等资源。
三、Device Plugin 的工作原理:从注册到调用的全流程
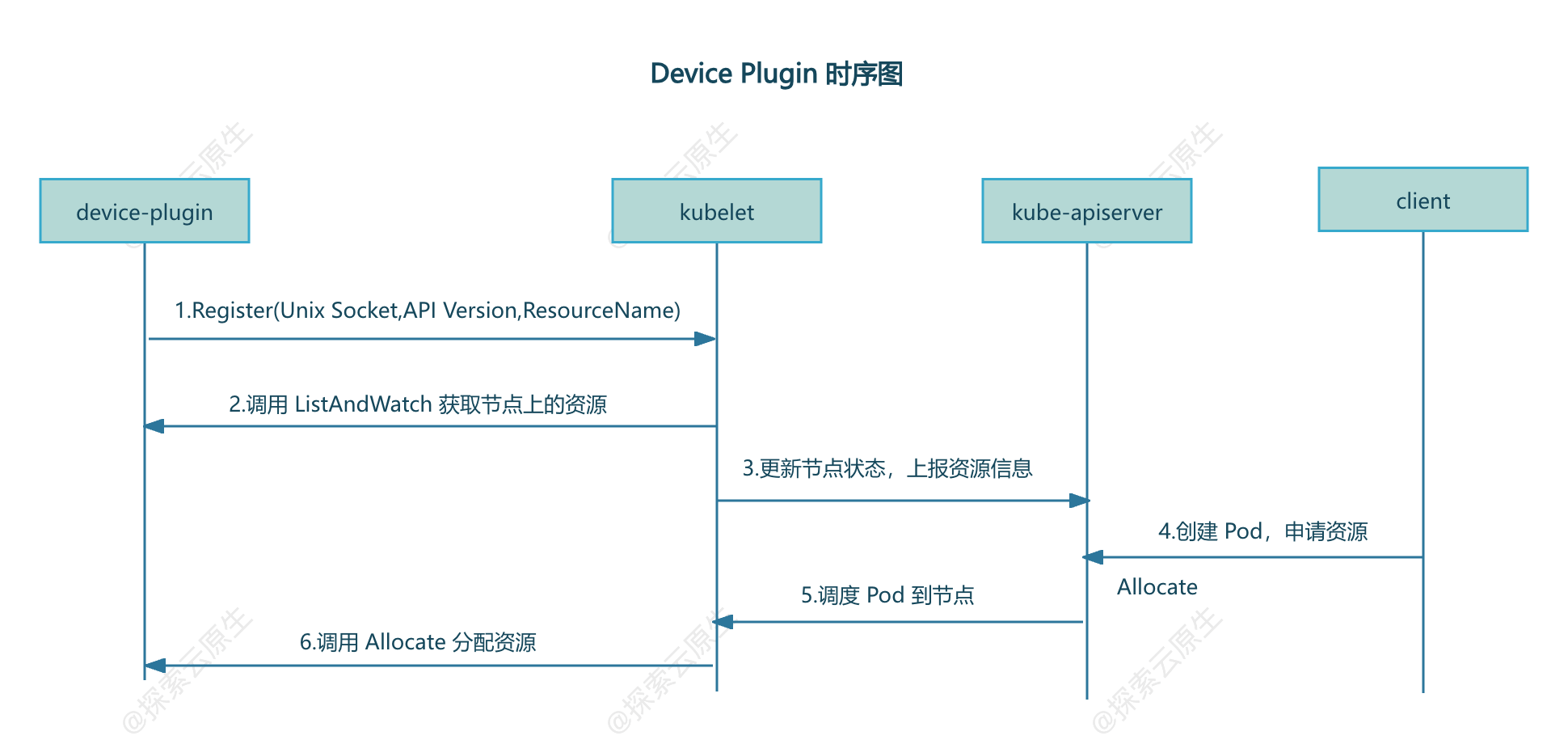
Device Plugin 的工作流程并不复杂,核心是"插件注册"与"kubelet 调用"的协作,具体可分为以下步骤:
1. 准备阶段:kubelet 启动注册服务
Kubernetes 节点上的 kubelet 会启动一个 Registration gRPC 服务(通过宿主机的 kubelet.sock 套接字实现),专门用于接收 Device Plugin 的注册请求。
2. 注册阶段:插件"自我介绍"
Device Plugin 通常以 DaemonSet 形式部署(确保每个节点都运行一份),启动后会做一件关键事:向 kubelet"报到"。它通过挂载到容器内的 kubelet.sock,调用注册接口并提供三个核心信息:
- 自身的 unix socket 名称(方便 kubelet 后续调用);
- 插件的 API 版本(用于版本兼容);
- 管理的资源名称(如
nvidia.com/gpu,让 kubelet 知道它能处理哪种资源请求)。
3. 资源发现:kubelet 获知硬件状态
注册成功后,kubelet 会通过 Device Plugin 提供的 socket 调用 ListAndWatch 接口:
List:获取当前节点上所有可用的特殊设备(如"2 块 GPU,ID 分别为 GPU-abc123、GPU-def456");Watch:持续监控设备状态(如设备故障时及时上报)。
随后,kubelet 会将这些资源信息更新到节点的状态中,管理员通过 kubectl get node -o yaml 就能在节点的 Capacity 字段看到 nvidia.com/gpu: 2 这样的记录。
4. 资源分配:响应 Pod 的硬件请求
当用户创建一个申请特殊硬件的 Pod(例如 resources.limits: {nvidia.com/gpu: 1})时:
- Kubernetes 调度器(kube-scheduler)会根据节点上的资源状态,将 Pod 调度到有可用资源的节点;
- 目标节点的 kubelet 会调用该节点上 Device Plugin 的
Allocate接口,请求分配 1 块 GPU; - Device Plugin 检查并锁定一块空闲 GPU(如 GPU-abc123),返回设备文件、环境变量等配置信息;
- kubelet 根据返回的配置,在启动容器时注入设备映射和驱动挂载,确保容器能正常使用 GPU。
四、总结:Device Plugin 是容器拥抱特殊硬件的"关键钥匙"
在云计算和 AI 时代,GPU 等特殊硬件已成为许多应用的"刚需"。Device Plugin 通过标准化的接口和流程,解决了容器访问特殊硬件时的隔离性、兼容性和调度难题,让 Kubernetes 集群能够像管理 CPU、内存一样管理 GPU、FPGA 等资源。
无论是 AI 训练任务调用 GPU,还是边缘计算场景使用 FPGA 加速,Device Plugin 都在默默扮演"桥梁"的角色------它让容器技术突破了"只能用标准化资源"的局限,为更广泛的硬件加速场景打开了大门。