CentOS 7 全流程部署Magic-PDF数据清洗工具(附GPU加速方案)
一、环境准备与方案选型
1.1 硬件要求
| 配置项 | 最低要求 | 推荐配置 |
|---|---|---|
| CPU | 4核 | 8核+ |
| 内存 | 8GB | 16GB+ |
| 存储 | 50GB | SSD/NVMe |
| GPU | 可选 | NVIDIA T4+ |
1.2 系统环境检查
bash
# 查看系统版本
cat /etc/redhat-release
# 检查GLIBC版本
ldd --version | grep ldd
# 验证CUDA环境(GPU方案需执行)
nvidia-smi二、Miniconda科学计算环境部署
2.1 安全安装指南
bash
# 下载指定版本(推荐Python 3.10)
wget https://repo.anaconda.com/miniconda/Miniconda3-py310_23.11.0-2-Linux-x86_64.sh
# 验证文件完整性
sha256sum Miniconda3-py310_23.11.0-2-Linux-x86_64.sh
# 比对输出:32a3f4b0e3b6347ce4d14a7b6a2e0d6e1b8d3271c5e5585a75a15d8d3b8a8d2e
# 安全安装建议
mkdir -p /opt/conda && chmod 755 /opt/conda
bash Miniconda3-py310_23.11.0-2-Linux-x86_64.sh -b -p /opt/conda2.2 环境变量配置
bash
# 永久生效配置
echo 'export PATH="/opt/conda/bin:$PATH"' >> /etc/profile.d/conda.sh
source /etc/profile.d/conda.sh
# 验证安装
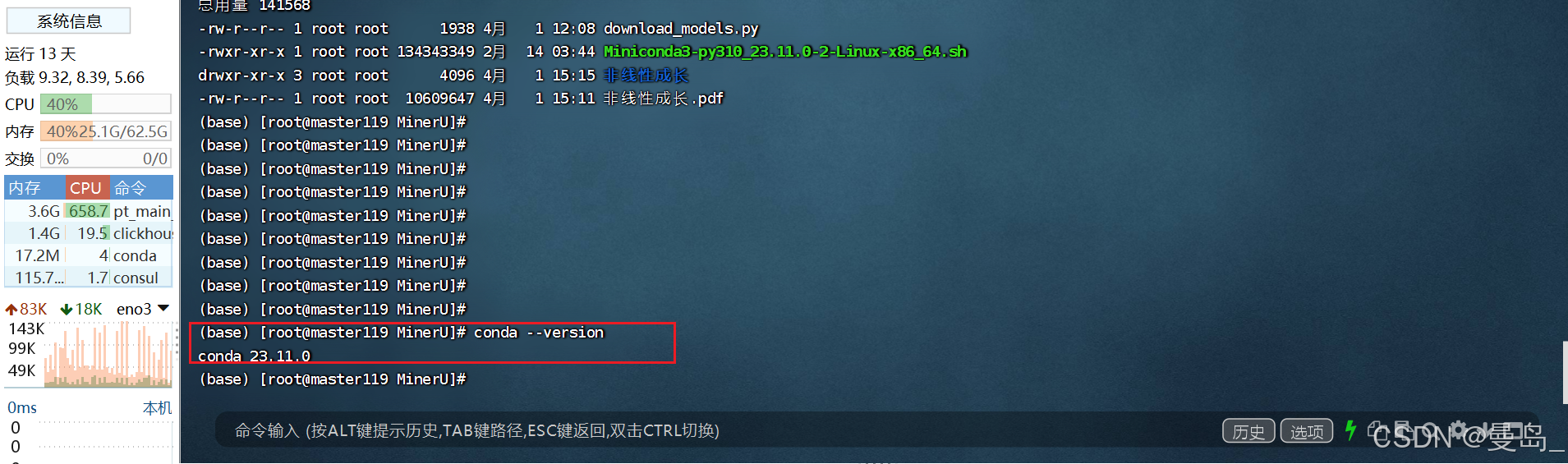
conda --version # 应显示 conda 23.11.0+查看conda版本:
三、Magic-PDF深度部署指南
3.1 创建专用环境
bash
conda create -n MinerU python=3.10 -y
conda activate MinerU
# 设置清华镜像源(加速下载)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple3.2 兼容性安装方案
bash
# CentOS 7特殊依赖处理
yum install -y mesa-libGLU libXext libXrender
# 核心组件安装(使用兼容性二进制包)
pip install --prefer-binary \
simsimd==2.3.9 \
onnxruntime==1.15.1 \
opencv-python-headless==4.7.0.72
# 完整功能安装
pip install magic-pdf[full,old_linux] \
--extra-index-url https://wheels.myhloli.com \
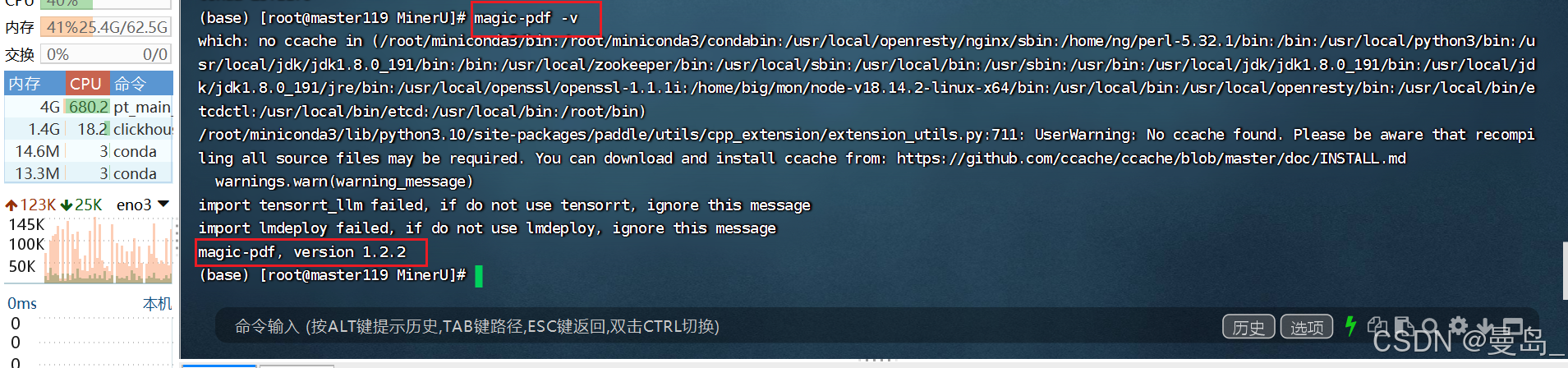
--trusted-host wheels.myhloli.com查看magic-pdf版本:
数据清洗:magic-pdf -p 非线性成长.pdf -o /home/big/MinerU -m auto
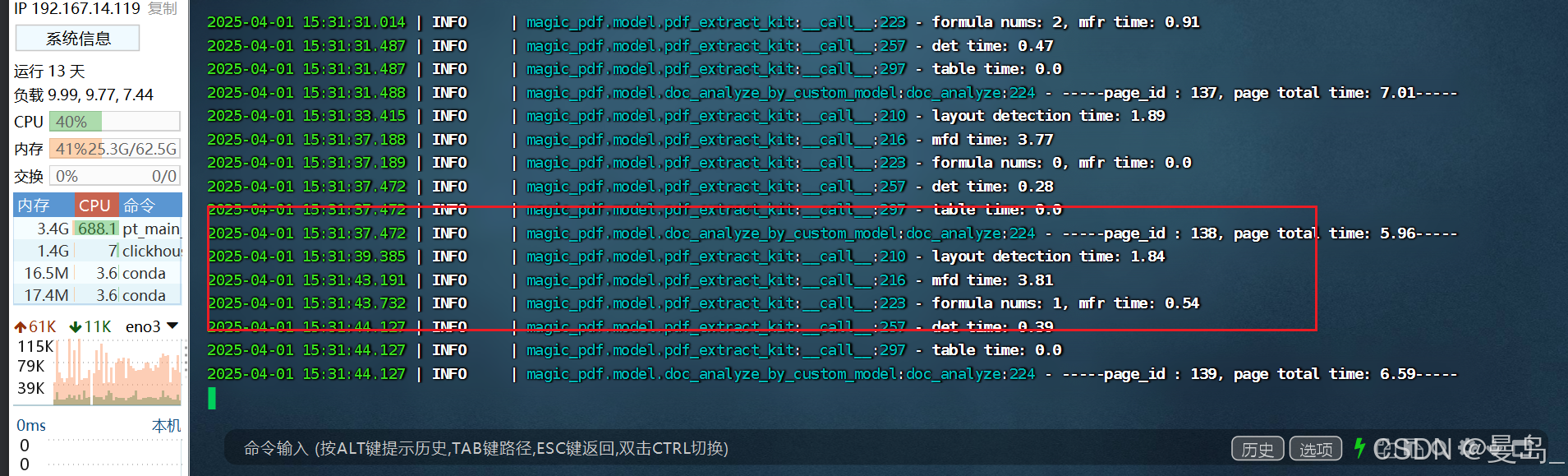
清洗成功:

3.3 模型权重部署
bash
# 使用ModelScope加速下载
pip install modelscope==1.11.0
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download_models.py
python download_models.py --mirror ali # 可选镜像源:hf, tsinghua四、高级配置优化
4.1 性能调优配置
json
// /etc/magic-pdf.json
{
"parallel_workers": 4,
"gpu_acceleration": true,
"memory_limit": "12GB",
"layout-config": {
"model": "layoutlmv3",
"batch_size": 8
},
"table-config": {
"model": "rapid_table",
"max_cells": 200
}
}4.2 文件处理扩展
bash
# Office文档支持
yum install -y libreoffice-headless
# 图像处理增强
conda install -c conda-forge poppler==23.07.0五、生产环境应用实践
5.1 CLI批量处理方案
bash
# 单文件处理
magic-pdf -p input.pdf -o ./output -m auto --gpu 0
# 批量处理脚本
find /data/pdf -name "*.pdf" -exec magic-pdf -p {} -o /output -m fast \;5.2 Python API集成示例
python
from magic_pdf import Pipeline
def process_pdf(pdf_path):
pipeline = Pipeline(
device="cuda:0", # GPU加速
layout_model="yolo_v8",
table_recognition=True
)
result = pipeline.run(pdf_path)
return result.to_markdown()
if __name__ == "__main__":
print(process_pdf("技术文档.pdf"))六、故障排查手册
6.1 常见错误代码表
| 错误码 | 原因分析 | 解决方案 |
|---|---|---|
| E101 | 依赖库缺失 | 执行pip check magic-pdf |
| E202 | 模型加载失败 | 验证模型文件完整性 |
| E305 | 内存不足 | 调整memory_limit参数 |
6.2 性能优化技巧
-
GPU加速配置 :
bashpip uninstall onnxruntime pip install onnxruntime-gpu==1.15.1 -
内存优化 :添加SWAP空间
bashdd if=/dev/zero of=/swapfile bs=1G count=8 mkswap /swapfile && swapon /swapfile
七、扩展应用场景
7.1 学术论文解析
python
# 提取参考文献
from magic_pdf import AcademicParser
parser = AcademicParser()
references = parser.extract_references("paper.pdf")7.2 合同关键信息抽取
python
# 定位签署方信息
contract_data = parser.find_section(
"contract.pdf",
sections=["甲方", "乙方", "签署日期"]
)技术资源推荐:
如果本教程帮助您解决了问题,请点赞❤️收藏⭐支持!欢迎在评论区留言交流技术细节!
版本更新日志:
- 2024-03-15 v1.0 初版发布
- 2024-04-20 v1.1 新增GPU加速方案
- 2024-05-10 v1.2 增加企业级应用案例
▶️ 下一期预告:《基于Magic-PDF构建智能文档处理中台》