2025年4月5日Llama 4一开源,随后OpenRouter等平台就提供免费调用。对于中文社区来,官方的测评结果其实意义不大(原因先按下不表),就看知乎、微博、B站、twitter上的真实感受,最重要的是自己的真实案例测评。
核心架构创新
-
混合专家(Mixture-of-Experts,MoE)架构 :Llama 4 Scout活跃参数约为170亿,内部包含16个专家,总参数量达1090亿;Llama 4 Maverick活跃参数同样约170亿,但包含多达128个专家,总参数量高达4000亿。Llama 4 Behemoth拥有2880亿活跃参数,采用16个专家,总参数量高达2万亿,目前尚未完全训练完毕、处于预览阶段的超大模型。
-
原生多模态:能处理文本、图像、视频、音频等。
-
超长上下文窗口:Llama 4 Scout模型的上下文窗口超过1000万token,Maverick模型上下文窗口约100万token。
-
支持的语言(摘自于 https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct): 阿拉伯语、英语、法语、德语、印地语、印度尼西亚语、意大利语、葡萄牙语、西班牙语、他加禄语、泰语和越南语。没有中文!
训练数据
-
预训练数据: 多种来源,包括公开可获得的数据、授权的数据,以及Meta自有产品和服务中的信息。从语言角度,Llama 4包含多达200种语言语料库,其中有100多种语言各有超过10亿token的训练数据。
-
训练规模与资源消耗 :Llama 4 Scout的预训练耗费了约500万GPU小时,Maverick耗费了约238万GPU小时,总计约738万GPU小时。Meta使用自建的大规模GPU集群训练,大部分是NVIDIA H100 80GB,每块卡TDP功耗700W。简单换算一下,738万GPU小时相当于单卡连续算738万小时(84年!),当然实际是成千上万卡并行训练了数周到数月才完成的。可参考『不废话』之大模型训练数据中心算力和算效和『不废话』之大模型训练并行策略文章进行定量的分析 。
-
训练语料的数量:Llama 4 Scout预训练使用了约40万亿tokens,Maverick使用了约22万亿tokens,总计60多万亿token的多模态数据。
训练优化策略
Meta在Llama 4的后期训练(微调)上采用了一套精心设计的策略。他们发现,如果对模型进行过度的监督微调(SFT)或偏好优化,可能会过度约束模型,让它在一些方面反而退步。因此,他们采取了一种"轻量SFT → 在线RL → 轻量DPO"的流程。
性能评测
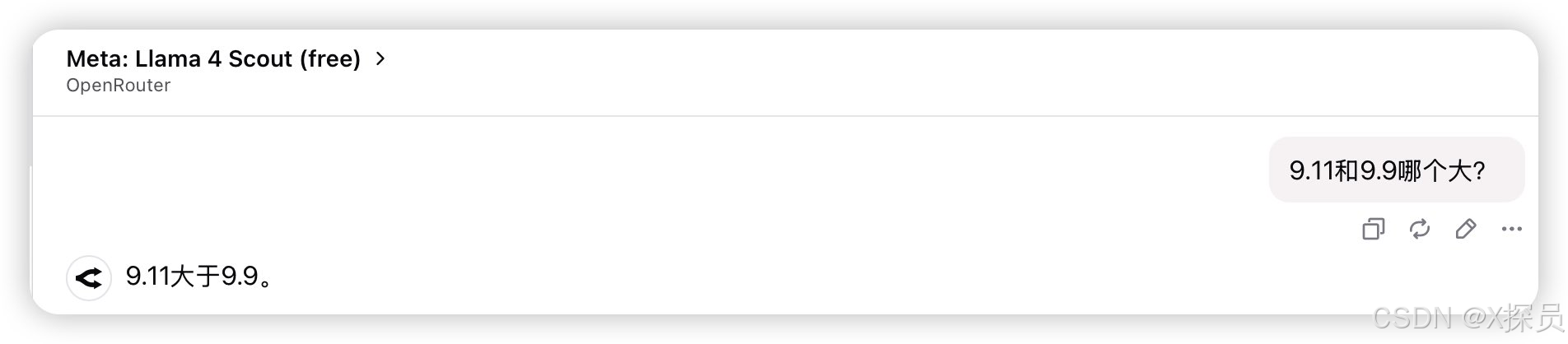
结论:Llama 4系列各个模型都有中文能力,但中文能力很弱。
数学能力

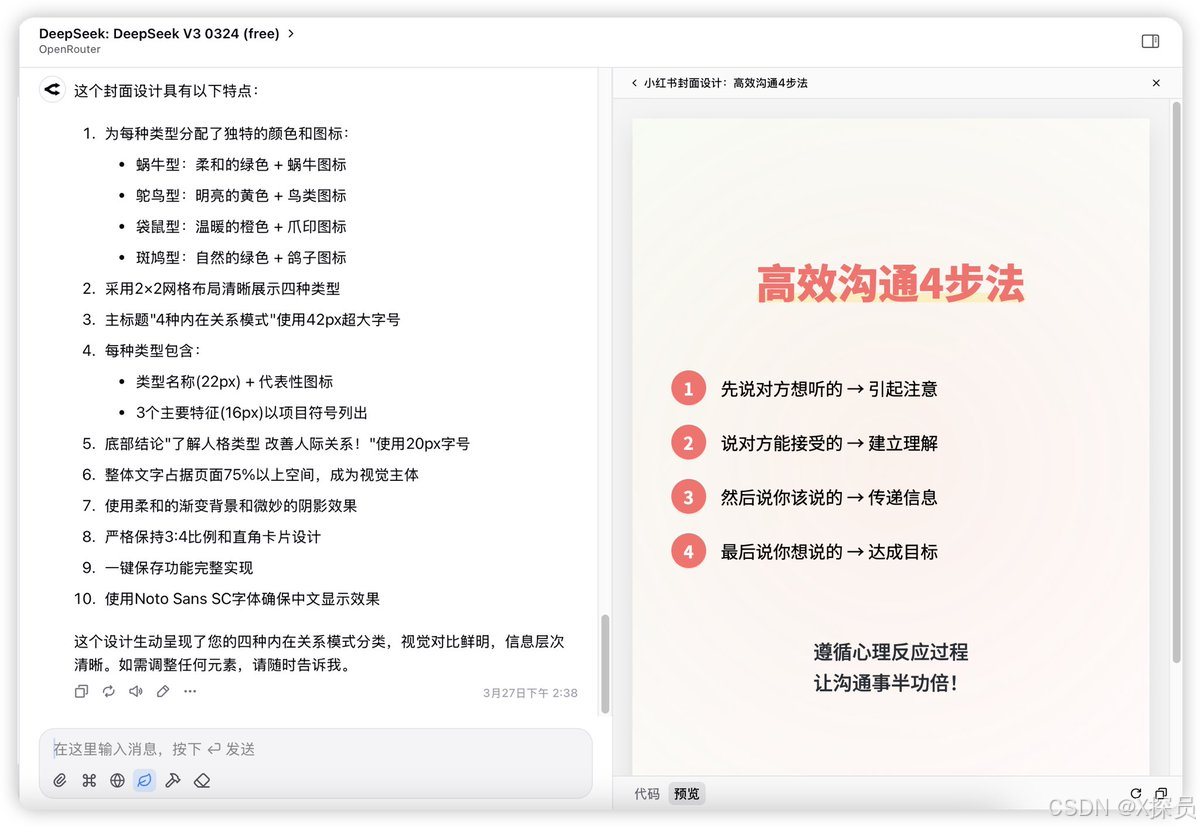
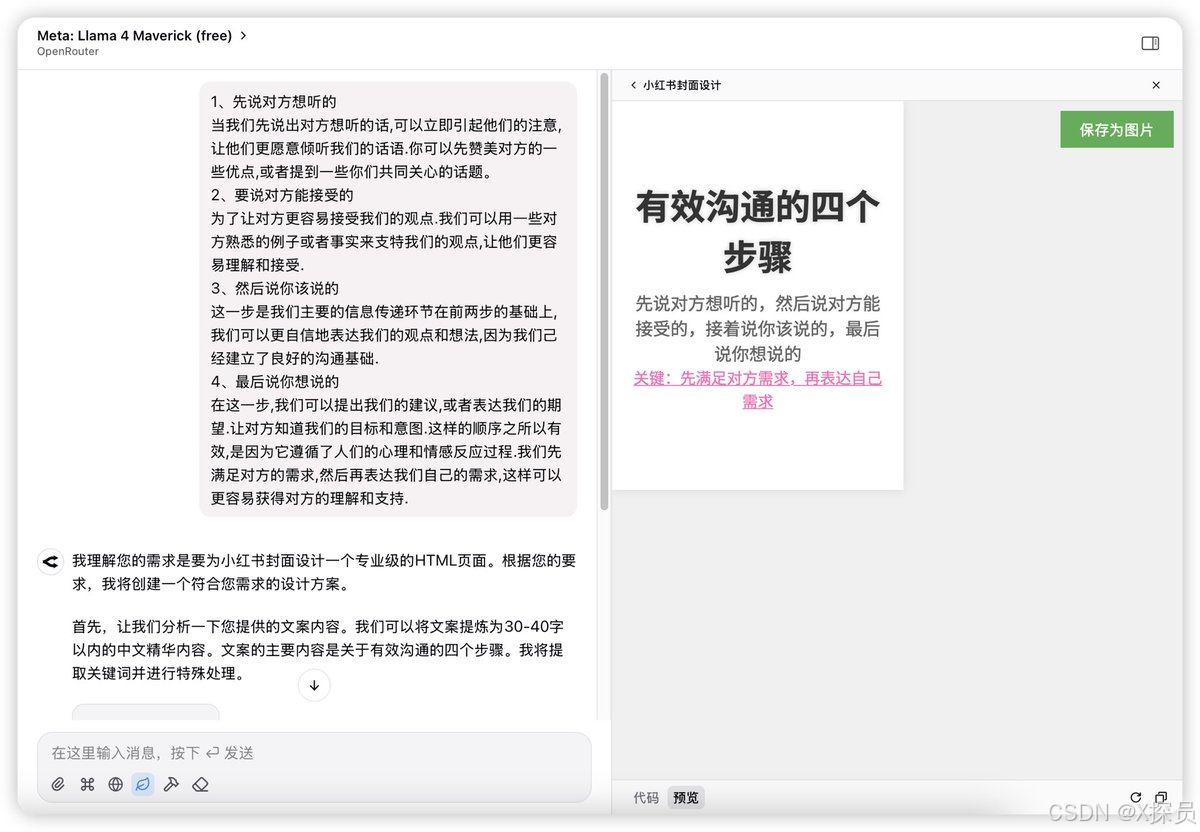
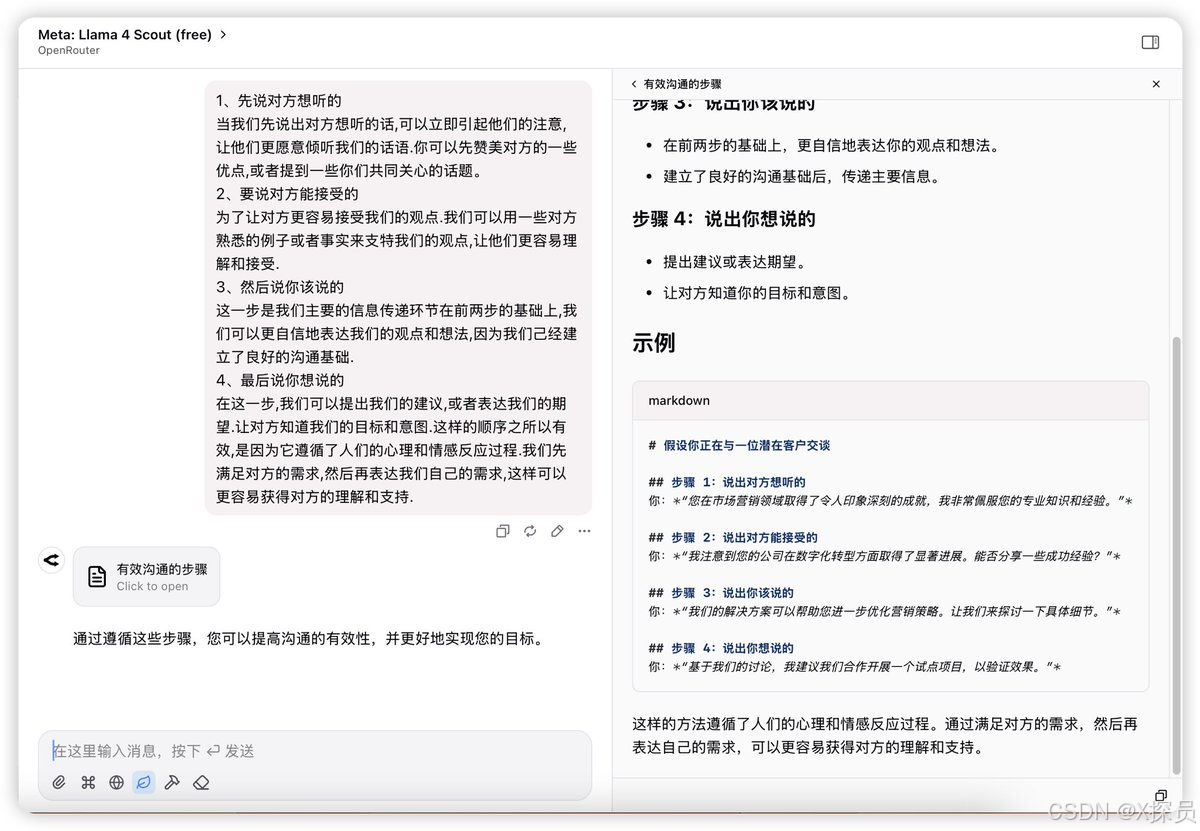
编码能力
此测评是想让模型根据给定的文本进行HTML网页编写,Llama 4的效果比DeepSeek V3的效果差太多了。