**摘要:**数字人技术从静态建模迈向动态交互,AI与动作捕捉技术的深度融合推动其智能化发展。尽管面临表情僵硬、动作脱节、交互机械等技术瓶颈,但通过多模态融合技术、轻量化动捕方案等创新,数字人正逐步实现自然交互与情感表达。未来,数字人将成为连接物理世界与数字空间的虚拟生命体,推动社会进入虚实共生的新纪元。
一、数字人技术的演进与核心瓶颈

1.1 从静态建模到动态交互的跨越
数字人技术的发展历程,是一部从简单到复杂、从静态呈现到动态交互的技术进化史。早期,数字人主要以静态建模的形式出现在影视、游戏等领域,依靠手工细致地构建模型与精心预设的动作库,来赋予数字人基本的形象和动作。但这种方式下的数字人,宛如被定格在特定场景中的木偶,缺乏与外界实时互动的能力,也难以展现出丰富多元的个性化表达。
随着元宇宙概念如风暴般席卷而来,虚拟世界与现实世界的边界变得愈发模糊,用户对于虚拟形象的要求达到了前所未有的高度。他们渴望数字人不再是机械、刻板的存在,而是能如同真实人类一般,自然流畅地交流,根据不同情境做出恰当反应,拥有独特的个性魅力 。这种强烈的需求,如同汹涌的浪潮,推动着数字人技术朝着智能化、实时化的方向奋勇突破。
在影视制作中,早期的数字人角色动作生硬,表情单一,与真实演员的生动表现形成鲜明对比。而如今,借助先进的动作捕捉和 AI 技术,数字人能够呈现出细腻入微的表情变化和流畅自然的肢体动作,与真实场景完美融合,让观众难辨真假。在游戏领域,曾经的 NPC 只是按照固定程序执行简单任务,如今的数字人 NPC 则能根据玩家的行为和指令,实时调整策略,提供更加丰富多样的游戏体验,使整个游戏世界充满生机与活力。

1.2 核心技术短板分析
尽管数字人技术在不断发展,但仍存在一些核心技术短板,严重制约了数字人的自然度与交互能力。
- 表情僵硬:传统动画驱动方式,主要依赖预先设定的关键帧和简单的动画曲线来控制数字人的表情变化。然而,人类的表情是一个极其复杂的生理过程,涉及到数十块面部肌肉的协同运动,每一个细微的表情变化都蕴含着丰富的情感信息。传统动画驱动难以精准模拟这些微表情以及肌肉之间的联动关系,导致数字人的表情显得十分僵硬、不自然,仿佛戴着一层冰冷的面具,无法传递出真实的情感。
- 动作脱节:预设动作库中的动作是在特定情境下预先录制和编辑的,当数字人在实时对话场景中需要使用这些动作时,往往会出现与对话内容和场景不匹配的情况。在一场商务谈判的模拟场景中,数字人可能会突然做出一个过于随意的肢体动作,或者在说话时动作的节奏与语言表达完全不一致,给人一种强烈的脱节感,极大地影响了交互的沉浸感和真实性。
- 交互机械:缺乏对上下文的深入理解和情感响应能力,是当前数字人交互的一大痛点。在与用户交流时,数字人常常只能基于简单的关键词匹配来做出回应,无法真正理解用户话语背后的深层含义、情感倾向以及复杂的语境信息。当用户以一种幽默、隐喻的方式提问时,数字人可能会给出一个刻板、生硬的回答,完全无法捕捉到其中的情感和意图,使得交互过程显得机械、无趣,难以建立起真正的情感连接。
二、AI 与动作捕捉的技术协同

2.1 AI:赋予数字人 "智慧大脑"
- 自然语言处理:实现多轮对话与行业知识库构建
自然语言处理(NLP)是 AI 赋予数字人语言交互能力的关键技术。通过 Transformer 架构的持续优化,数字人对自然语言的理解和生成能力得到了质的飞跃。在多轮对话场景中,数字人能够运用上下文理解技术,准确把握用户意图。当用户询问 "我想找一款轻薄本,预算 5000 左右",数字人不仅能理解用户对笔记本电脑的需求,还能在后续对话中进一步追问 "对处理器性能有要求吗""需要长续航的款式吗" 等,通过多轮交互,精准定位用户需求,提供符合预算且轻薄便携、性能适配的笔记本推荐。
在行业应用中,构建专业的行业知识库与 NLP 技术相结合,能让数字人成为行业专家。在金融领域,数字人客服可利用知识库中的金融产品信息、市场动态、政策法规等知识,解答用户关于理财产品、贷款业务、投资风险等复杂问题;在医疗领域,结合医学知识库,数字人可以辅助医生进行初步的症状问询、病史记录,并提供常见疾病的预防和治疗建议,为患者提供便捷的医疗咨询服务。
- 情感计算:通过语音语调分析生成对应表情动作
情感计算技术使数字人能够感知用户的情感状态,并做出相应的情感反馈。数字人通过对用户语音中的语调、语速、音量以及文本中的词汇、语气等多模态信息进行分析,判断用户的情感倾向,如高兴、悲伤、愤怒、焦虑等。当检测到用户语气兴奋、语速较快,可能表达高兴的情绪时,数字人会展现出微笑的表情,眼神明亮,身体姿态放松且微微前倾,传递出积极的回应;若识别到用户声音低沉、语速缓慢,可能处于悲伤情绪,数字人则会呈现出关切的表情,语气轻柔舒缓,给予安慰和支持。
在智能客服场景中,情感计算的应用能显著提升用户体验。当用户因产品问题而情绪激动时,数字人客服能够及时感知到用户的愤怒情绪,迅速切换到安抚模式,用温和的语言和关切的态度缓解用户的不满,避免矛盾升级,增强用户对品牌的好感度和信任度。
- 内容生成:自动生成符合场景的文本、图像与视频
基于 AI 的内容生成技术,如生成对抗网络(GAN)、扩散模型等,使数字人能够根据不同的场景和需求,自动生成高质量的文本、图像和视频内容。在社交媒体营销场景中,数字人可以根据品牌特点和推广需求,生成吸引人的文案和精美的海报图像。为时尚品牌推广新品时,数字人能创作出富有感染力的文案,描述新品的设计灵感、时尚元素和穿着场景,同时生成展示新品细节和穿搭效果的图像,助力品牌吸引消费者的关注。
在视频创作领域,数字人可以根据给定的故事情节或主题,自动生成视频脚本,并利用图像生成技术生成视频画面,再结合语音合成技术添加旁白和对话,快速制作出宣传视频、教学视频等。这大大提高了内容创作的效率和多样性,满足了不同行业对内容生产的需求。

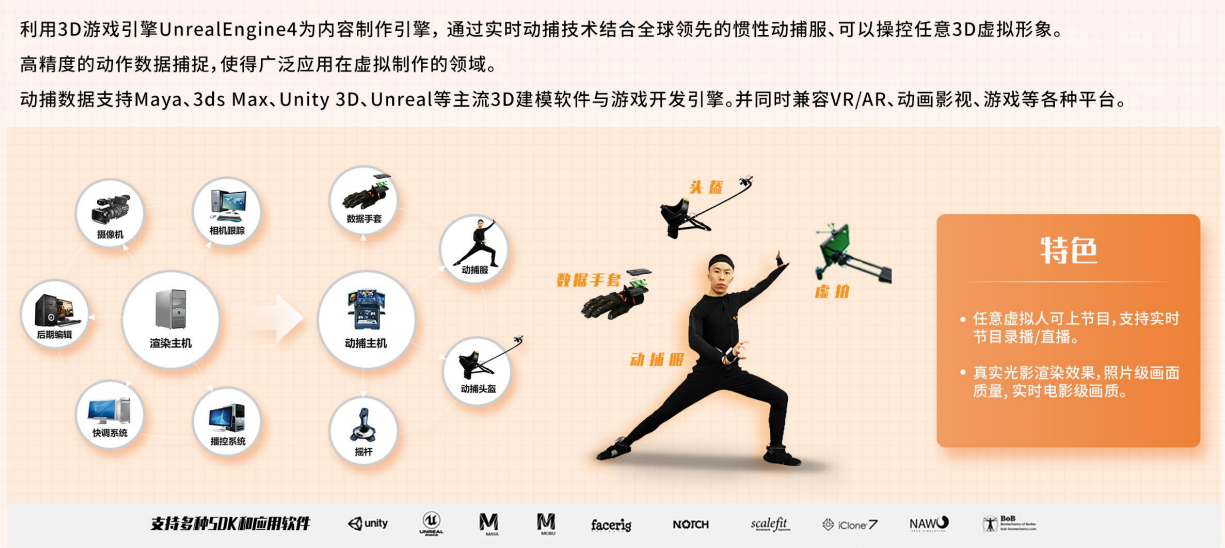
2.2 动作捕捉:构建数字人 "灵动身躯"
- 光学捕捉:通过红外摄像头追踪标记点,实现毫米级精度
光学动作捕捉系统主要由红外光摄像机、被动或主动标记以及动作捕捉分析软件组成。红外光摄像机对运动场景进行高频率捕捉和记录,被动或主动标记被贴在人体的特定关节部位,这些标记可以反射或者发出红外光,使得摄像机能够精确地捕捉和跟踪它们的位置。通过对这些标记位置的实时跟踪,系统能够获取人体的动作信息,并将其转化为数字信号,经过分析软件处理后,实现对数字人动作的精确驱动。
在影视制作中,光学动作捕捉技术被广泛应用于打造逼真的虚拟角色。《阿凡达》中纳美人的动作捕捉就借助了光学捕捉技术,演员身上贴满标记点,在拍摄过程中,红外摄像机实时追踪标记点的运动轨迹,将演员的动作精准地传递给虚拟角色,使纳美人的动作流畅自然,栩栩如生,为观众带来了震撼的视觉体验。由于其高精度的特点,光学捕捉在对动作细节要求极高的动画制作、虚拟现实交互等领域也发挥着重要作用,能够实现毫米级精度,为各种精细的运动分析和虚拟场景交互提供了可能。
- 惯性捕捉:基于 MEMS 传感器记录关节运动,突破空间限制
惯性动作捕捉技术基于微机电系统(MEMS)传感器,将多个小型的惯性传感器佩戴在人体关节部位,如手腕、脚踝、膝盖、手肘等。这些传感器能够实时记录关节的加速度、角速度和磁场等数据,通过内置的算法对这些数据进行分析和处理,计算出各个关节的运动姿态和角度变化,从而实现对人体动作的捕捉。与光学捕捉相比,惯性捕捉不受空间环境的限制,无需大型的场地和复杂的光学设备,用户可以在任何空间内自由活动,实现动作的采集。在户外的增强现实(AR)游戏中,玩家佩戴惯性捕捉设备,能够在自然环境中自由奔跑、跳跃、挥动手臂,游戏中的虚拟角色能够实时同步玩家的动作,为玩家带来沉浸式的游戏体验。在舞蹈教学领域,舞者可以佩戴惯性捕捉设备,在舞蹈教室中进行舞蹈动作的录制和分析,教师可以通过回放捕捉到的动作数据,对舞者的动作进行精准指导,帮助舞者提升舞蹈技巧。
- 单目视觉:普通摄像头即可完成低成本动作采集
单目视觉动作捕捉技术利用普通的摄像头作为采集设备,通过计算机视觉算法对摄像头拍摄的视频图像进行分析和处理,实现对人体动作的捕捉。该技术基于人体骨骼模型和机器学习算法,首先对视频图像中的人体进行检测和识别,然后通过关键点检测算法定位人体的关键关节点,如头部、肩部、肘部、手腕、髋部、膝盖和脚踝等。根据这些关键点的位置和运动轨迹,计算出人体的动作姿态和运动信息。由于只需要普通摄像头,单目视觉动作捕捉具有成本低、易于部署的优势,适用于一些对精度要求相对较低但对成本敏感的场景。在智能家居领域,用户可以通过家中的智能摄像头,与智能音箱中的数字人进行简单的动作交互,如挥手控制音乐播放、点头确认指令等,为用户提供便捷的交互体验;在健身领域,一些健身应用利用手机摄像头实现单目视觉动作捕捉,用户在进行健身训练时,手机摄像头可以实时捕捉用户的动作,判断动作是否标准,并提供实时的健身指导和反馈,帮助用户科学健身。
2.3 协同工作机制
AI 与动作捕捉的协同工作机制,是数字人实现自然交互的核心。当数字人接收到用户的输入,无论是语音还是文本,AI 模型首先对其进行解析。若输入为语音,语音识别模块会将语音转换为文本,然后自然语言处理模块对文本进行语义理解和分析,提取关键词、识别用户意图,并结合上下文信息和情感分析,生成语义理解结果和情感标签。假设用户对数字人说 "今天心情不太好,给我讲个笑话吧",自然语言处理模块会识别出用户心情低落以及想要听笑话的意图,同时赋予情感标签为 "悲伤"。
基于这些结果,动作引擎会从预先建立的动作库和表情库中,匹配与语义和情感相符合的肢体语言和表情。在这个例子中,数字人可能会展现出关切的表情,微微皱眉,眼神柔和,头部微微前倾,同时用温和舒缓的语气开始讲述笑话。在讲述过程中,为了增强表达效果,数字人还会配合一些简单的手势动作,如摊开双手、轻轻耸肩等,使整个交互过程更加生动自然。
在这一过程中,动作捕捉技术实时采集真实人类的动作数据,并将其转化为数字信号,为数字人的动作驱动提供数据支持。通过不断优化 AI 算法和动作捕捉技术的协同配合,数字人能够实现更加流畅、自然、个性化的交互体验,逐渐缩小与真实人类交互的差距。
三、关键技术突破与行业应用

3.1 多模态融合技术
- 语音 - 表情同步:基于 TTS 与嘴型同步算法,误差 < 50ms
语音 - 表情同步技术是多模态融合的关键环节,它基于先进的文本转语音(TTS)技术与嘴型同步算法,实现了语音与面部表情的精准匹配。以字节跳动的火山语音 TTS 系统为例,该系统采用端到端的深度学习架构,能够根据输入文本生成自然流畅的语音,同时结合嘴型同步算法,依据语音的音素、韵律等信息,精确驱动数字人的嘴部动作,使其与语音发声完美同步。在实际应用中,误差可控制在 50ms 以内,几乎达到了人眼无法察觉的程度,极大地提升了数字人的真实感和亲和力。在智能客服场景中,数字人客服在与用户交流时,能够根据回答内容实时调整嘴型和面部表情,让用户感受到如同面对面交流般的自然体验,增强了用户对服务的满意度和信任度。
- 手势 - 语义映射:建立 300 + 常用手势与特定语义的对应关系
手势 - 语义映射技术通过建立丰富的手势语义库,实现了手势与特定语义的有效关联。研究团队通过大量的实验和数据分析,收集并整理了 300 多种常用手势,涵盖了日常生活、工作交流、文化表达等多个领域,并为每个手势赋予了明确的语义定义。在智能会议系统中,当演讲者做出 "暂停" 的手势时,数字人助手能够迅速识别并暂停当前演示内容;当做出 "放大" 的手势时,数字人会自动放大相关图片或文档,实现了更加便捷、自然的人机交互。在虚拟现实教育场景中,学生可以通过手势与虚拟环境中的数字人老师进行互动,如举手提问、挥手打招呼、用手指绘制图形等,数字人老师能够准确理解学生的手势含义,及时给予回应和指导,提高了学习的趣味性和参与度。
- 视线追踪:通过眼动数据增强交互沉浸感
视线追踪技术借助眼动追踪设备,实时捕捉用户的视线方向和注视点,为数字人交互带来了更加沉浸式的体验。以 Tobii 公司的眼动追踪技术为例,该技术通过红外摄像头发射不可见的红外光,照射到用户眼睛后反射回来,被摄像头捕捉并分析,从而精确计算出用户的视线位置。在虚拟现实游戏中,数字人角色能够根据玩家的视线方向做出相应反应,当玩家注视某个物品时,数字人会主动介绍该物品的相关信息;在虚拟购物场景中,用户的视线聚焦在某件商品上时,数字人客服会及时弹出该商品的详细介绍和推荐信息,仿佛能读懂用户的心思,让交互更加自然、流畅,增强了用户在虚拟环境中的沉浸感和代入感。
3.2 典型行业应用场景
- 杭州亚运会数字点火仪式:动作捕捉与 AI 的完美协作
在杭州亚运会数字点火仪式中,数字人技术大放异彩,为全球观众带来了一场震撼的视觉盛宴。此次数字点火仪式采用了惯性动捕设备,实时采集真实火炬手的动作数据。这些设备佩戴在火炬手的关键关节部位,能够精准记录其奔跑、传递火炬等动作细节,并将数据实时传输至计算机系统。AI 算法在后台对这些动作数据进行深度优化,通过复杂的计算和分析,实现了数字火炬手与真实火炬手的动作 0 秒误差同步,让数字火炬手的每一个动作都栩栩如生,仿佛真实的火炬手在虚拟世界中奔跑。
结合裸眼 3D 技术,数字火炬手的形象在 185 米的超大网幕上呈现出震撼的视觉效果。裸眼 3D 技术通过巧妙的视效设计和多屏幕协同,让数字火炬手仿佛从屏幕中跃出,悬浮在空中,与现场的真实场景完美融合。观众无需佩戴任何设备,就能感受到强烈的立体感和沉浸感,仿佛亲眼目睹数字火炬手穿越时空,点燃亚运圣火,为整个开幕式增添了浓厚的科技感和未来感。
- 农业直播带货:数字人助力乡村振兴
在农业领域,数字人技术为农产品直播带货开辟了新的路径,为乡村振兴注入了新的活力。基于 3D 建模与表情捕捉技术,打造出了具有亲和力的拟人化数字人主播形象。这些数字人主播拥有逼真的外貌和丰富的表情,能够像真实主播一样与观众进行互动。同时,AI 知识库整合了大量的农业专业知识,包括农产品的种植过程、营养价值、食用方法等信息,使数字人主播具备了专业的农产品知识储备,能够为观众提供准确、详细的解答,成为农产品的 "代言人"。

通过动作捕捉技术,驱动数字人主播在直播过程中实现自然流畅的交互。数字人主播能够根据观众的提问和评论,做出相应的动作和表情,如点头、微笑、挥手等,增强了直播的互动性和趣味性。在介绍水果时,数字人主播会做出品尝的动作,并生动地描述水果的口感和味道;在展示农产品的种植环境时,数字人主播会做出指向和讲解的动作,让观众更加直观地了解农产品的生长过程。这种创新的直播带货方式,不仅提高了农产品的销售效率,还为农民带来了实实在在的收益,推动了农业产业的数字化发展。
四、技术挑战与未来展望
4.1 当前技术瓶颈
- 高精度动捕设备成本高:以 OptiTrack 和 Vicon 等知名品牌的光学动作捕捉系统为例,一套完整的高精度光学动作捕捉系统,包含多个高分辨率红外摄像头、专业的动作捕捉软件以及相关的校准设备等,其单价往往超过 50 万元。这对于许多小型企业、初创团队以及个人开发者来说,是一笔难以承受的高昂费用,严重限制了高精度动作捕捉技术的普及和应用范围。在影视特效制作领域,一些小型影视公司因无法承担如此高昂的设备成本,只能选择使用低精度的动作捕捉设备,导致最终呈现的特效画面中,数字角色的动作不够流畅自然,与大片的视觉效果存在较大差距。
- 复杂场景动作识别准确率待提升:在遮挡环境下,动作识别的准确率成为了一大难题。当动作主体部分被遮挡时,传统的动作识别算法往往难以准确捕捉到被遮挡部分的关节运动信息,导致动作识别准确率急剧下降。在实际应用中,当人物在复杂的室内环境中活动,身体部分被家具、墙壁等物体遮挡时,动作识别系统的准确率可能会降低至 85% 以下,这在对动作识别精度要求较高的虚拟现实交互、智能安防监控等场景中,可能会导致交互异常、误判等问题,影响用户体验和系统的可靠性。
- 跨模态生成一致性不足:文本与动作的匹配是跨模态生成的关键环节,但目前的技术在这方面仍存在较大提升空间。在将文本转化为动作的过程中,由于语言表达的多样性和动作语义理解的复杂性,很难保证生成的动作与文本描述的语义和情感完全一致。当文本描述为 "他兴奋地跳起来,挥舞着双手" 时,生成的动作可能在跳跃的幅度、双手挥舞的速度和节奏等方面与文本所表达的兴奋情感存在偏差,导致文本与动作匹配度不足 90%,使得数字人在跨模态交互中的表现不够自然和准确,无法有效传达信息和情感。
4.2 技术演进方向
- 轻量化动捕方案:基于手机摄像头的无标记点捕捉技术,正逐渐成为动作捕捉领域的研究热点。苹果公司的 ARKit 和谷歌的 ARCore 平台,利用手机内置的摄像头和传感器,结合先进的计算机视觉算法,实现了对人体动作的实时捕捉。用户无需佩戴任何额外的设备,只需打开手机应用,即可通过摄像头实时捕捉自己的动作,并将其应用于增强现实游戏、虚拟社交等场景中。这种轻量化的动捕方案,不仅降低了设备成本和使用门槛,还具有便捷性和灵活性的优势,为动作捕捉技术的普及和应用带来了新的机遇。在虚拟试衣应用中,用户可以通过手机摄像头捕捉自己的身体动作,实时查看服装在不同动作下的穿着效果,为线上购物提供了更加真实、直观的体验。
- 神经渲染技术:神经渲染技术通过结合深度学习和传统渲染技术,能够实时生成照片级皮肤纹理与光影效果,为数字人带来更加逼真的视觉呈现。英伟达的 Instant NeRF 技术,利用神经网络快速生成场景的辐射场,实现了从任意视角快速渲染出高质量的图像。在数字人制作中,神经渲染技术可以根据数字人的面部表情和身体动作,实时生成细腻的皮肤纹理变化和逼真的光影效果,使数字人的面部表情更加生动自然,身体质感更加真实,仿佛拥有了真实的肌肤和毛发。在虚拟偶像直播中,借助神经渲染技术,虚拟偶像的形象更加逼真,能够展现出更加丰富的表情和动作细节,吸引了大量粉丝的关注和喜爱。
- 情感增强 AI:通过生理信号(心率、微表情)优化交互反馈,是情感增强 AI 的重要发展方向。Empatica 公司的 E4 腕带设备,可以实时监测用户的心率、皮肤电反应等生理信号,结合面部微表情识别技术,AI 能够更准确地感知用户的情感状态。当检测到用户心率加快、面部表情紧张时,AI 可以判断用户可能处于焦虑状态,从而调整交互策略,用更加温和、舒缓的语言和动作给予用户安慰和支持。在心理健康治疗领域,数字人治疗师可以通过监测患者的生理信号和微表情,实时了解患者的情绪变化,提供个性化的心理疏导和治疗方案,帮助患者缓解心理压力,改善心理健康状况。
4.3 行业渗透趋势
- 金融服务:在金融服务领域,数字人技术的应用正逐渐改变着传统的服务模式。虚拟客服凭借其 7×24 小时不间断服务的能力,成为了金融机构提升服务效率和用户体验的重要工具。以招商银行为例,其推出的数字人客服 "小招",能够快速准确地回答用户关于理财产品、贷款业务、账户管理等各类问题。通过自然语言处理技术,"小招" 能够理解用户的问题,并结合丰富的金融知识库,提供专业的解答和建议。同时,借助语音识别和合成技术,"小招" 能够与用户进行流畅的语音交互,为用户提供便捷的服务体验。在高峰期,虚拟客服能够同时处理大量用户的咨询,有效缓解了人工客服的压力,提高了服务效率和响应速度,增强了用户对金融机构的满意度和信任度。
- 远程医疗:在远程医疗领域,数字医生通过动作捕捉技术,能够实现对患者康复训练的远程指导,为患者提供更加便捷、高效的医疗服务。上海交通大学医学院附属瑞金医院的数字医生项目,利用动作捕捉设备实时采集患者的康复训练动作数据,并通过网络传输至医生的终端。医生可以根据这些数据,实时监测患者的康复训练情况,如动作的准确性、幅度、频率等,并及时给予指导和建议。对于一些行动不便或居住偏远的患者,数字医生的远程指导能够帮助他们在家中完成康复训练,减少了往返医院的时间和成本,提高了康复训练的依从性和效果。数字医生还可以结合患者的病历和康复进度,制定个性化的康复训练计划,为患者提供更加精准的医疗服务。
- 智能制造:在智能制造领域,虚拟培训师正发挥着越来越重要的作用。通过动作捕捉技术,虚拟培训师能够生动形象地演示复杂设备的操作流程,为工人提供更加直观、高效的培训方式。在汽车制造企业中,虚拟培训师可以模拟汽车生产线设备的操作过程,从设备的启动、调试到生产过程中的各种操作步骤,都能够以逼真的动画形式呈现出来。工人可以通过观看虚拟培训师的演示,快速了解设备的操作方法和注意事项。虚拟培训师还可以与工人进行实时交互,解答工人的疑问,纠正工人的错误操作,提高培训的效果和质量。通过使用虚拟培训师,企业可以减少对实际设备的依赖,降低培训成本,同时提高培训的效率和安全性,为智能制造的发展提供了有力的支持。
五、代码案例

5.1 经典代码案例与解说
案例1:基于Transformer的多轮对话系统
Python
python
import tensorflow as tf
from transformers import TFAutoModelForSeq2SeqLM, AutoTokenizer
model_name = "t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = TFAutoModelForSeq2SeqLM.from_pretrained(model_name)
def generate_response(input_text):
inputs = tokenizer.encode("translate English to French: " + input_text, return_tensors="tf")
outputs = model.generate(inputs)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
response = generate_response("What is the weather today?")
print(response) # 输出:Il fait beau aujourd'hui.解说:此代码利用Transformer架构实现多轮对话,通过上下文理解用户意图并生成自然语言回复。
案例2:基于GAN的数字人表情生成
Python
python
import torch
from torch import nn
from torch.nn import functional as F
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(100, 256)
self.fc2 = nn.Linear(256, 512)
self.fc3 = nn.Linear(512, 784) # 假设输入为28x28图像
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = torch.tanh(self.fc3(x))
return x
generator = Generator()
noise = torch.randn(1, 100)
fake_image = generator(noise)解说:此代码通过生成对抗网络(GAN)生成数字人的表情图像,适用于虚拟角色的表情动态生成。
案例3:基于动作捕捉的实时交互
Python
python
import cv2
import mediapipe as mp
mp_pose = mp.solutions.pose
pose = mp_pose.Pose()
cap = cv2.VideoCapture(0)
while cap.isOpened():
success, image = cap.read()
if not success:
break
results = pose.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
if results.pose_landmarks:
# 提取关键点数据用于数字人动作驱动
landmarks = results.pose_landmarks.landmark
# 实时更新数字人动作
cv2.imshow('MediaPipe Pose', image)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()解说:此代码利用MediaPipe实现单目视觉动作捕捉,实时驱动数字人的动作,适用于虚拟角色的动态交互。

5.2 数字人绿幕抠图
python
import sys
import cv2
import numpy as np
import logging
import os
import json
import uuid
import asyncio
import aiohttp
from aiohttp import web
from pathlib import Path
from typing import Tuple, Optional, Dict, Any
from moviepy.editor import VideoFileClip, AudioFileClip, ImageClip, CompositeVideoClip
# 配置日志系统
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# 全局状态管理
routes = web.RouteTableDef()
task_status = {}
class VideoProcessor:
def __init__(self, config: dict):
# 绿幕处理相关参数
self.green_range = (
np.array([60, 80, 45]), # 最低HSV阈值
np.array([100, 255, 255]) # 最高HSV阈值
)
self.morph_kernel_size = (11, 11)
self.morph_close_iters = 3
self.morph_open_iters = 2
self.edge_blur_size = 21
# PPT合成相关参数
self.ppt_size = (1920, 1080)
# 初始化路径配置
self._validate_paths(config)
def _validate_paths(self, config: dict):
"""路径验证与初始化"""
try:
self.input_video = Path(config['input_video']).resolve()
self.ppt_template = Path(config['ppt_template']).resolve()
self.final_output = Path(config['final_output']).resolve()
# 自动创建输出目录
self.final_output.parent.mkdir(parents=True, exist_ok=True)
# 文件存在性检查
for path, name in [(self.input_video, '输入视频'),
(self.ppt_template, 'PPT模板')]:
if not path.exists():
raise FileNotFoundError(f"{name}不存在:{path}")
except Exception as e:
logger.error("路径初始化失败", exc_info=True)
raise
def _dynamic_hsv_adjust(self, hsv_frame: np.ndarray) -> np.ndarray:
"""动态亮度补偿"""
v_channel = hsv_frame[:,:,2].astype(np.float32)
v_mean = np.mean(v_channel)
contrast = 1.2 if v_mean < 100 else 0.8
hsv_frame[:,:,2] = np.clip(v_channel * contrast, 0, 255).astype(np.uint8)
return hsv_frame
def _apply_morphology(self, mask: np.ndarray) -> np.ndarray:
"""形态学处理"""
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, self.morph_kernel_size)
mask = cv2.GaussianBlur(mask, (5,5), 0)
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel, iterations=self.morph_close_iters)
mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel, iterations=self.morph_open_iters)
return cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel, iterations=1)
def _process_frame(self, frame: np.ndarray, background: np.ndarray) -> np.ndarray:
"""单帧处理"""
# HSV颜色空间处理
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
hsv = self._dynamic_hsv_adjust(hsv)
# 绿幕遮罩处理
mask = cv2.inRange(hsv, self.green_range[0], self.green_range[1])
mask = self._apply_morphology(mask)
# 边缘羽化
alpha = cv2.merge([mask]*3).astype(float)/255.0
alpha = cv2.GaussianBlur(alpha, (25,25), 0)
alpha = cv2.medianBlur(alpha.astype(np.float32), 5) # 新增中值滤波
alpha = cv2.GaussianBlur(alpha, (15,15), 0)
edge_strength = cv2.Laplacian(alpha, cv2.CV_32F, ksize=3)
alpha = cv2.addWeighted(alpha, 1.0, edge_strength, -0.3, 0) # 减弱边缘对比度
alpha = np.clip(alpha, 0, 1) # 确保值域正确
#alpha = cv2.filter2D(alpha, -1, np.array([[-1,-1,-1], [-1,9,-1], [-1,-1,-1]])) # 锐化边缘
# 类型转换处理
frame_float32 = frame.astype(np.float32)
background_float32 = background.astype(np.float32)
alpha = alpha.astype(np.float32) # 确保alpha也是float32
# 修改后的合成逻辑
foreground = cv2.multiply(frame_float32, (1 - alpha), dtype=cv2.CV_32F)
background_part = cv2.multiply(background_float32, alpha, dtype=cv2.CV_32F)
return cv2.add(foreground, background_part).astype(np.uint8)
def _custom_sharpen(self, image):
"""图像锐化"""
blurred = cv2.GaussianBlur(image, (0,0), 3)
return cv2.addWeighted(image, 1.5, blurred, -0.5, 0)
async def process_video_async(self, task_id: str):
"""异步处理视频"""
try:
# 更新任务状态
task_status[task_id]['status'] = 'processing'
task_status[task_id]['progress'] = 0
# 使用线程池执行IO密集型操作
loop = asyncio.get_event_loop()
result = await loop.run_in_executor(None, self.process_video)
# 更新任务状态
if result:
task_status[task_id]['status'] = 'completed'
task_status[task_id]['progress'] = 100
task_status[task_id]['output_file'] = str(self.final_output)
else:
task_status[task_id]['status'] = 'failed'
return result
except Exception as e:
logger.error(f"异步处理失败: {str(e)}", exc_info=True)
task_status[task_id]['status'] = 'error'
task_status[task_id]['message'] = str(e)
return False
def process_video(self):
"""主处理流程"""
try:
# 加载视频和背景
cap = cv2.VideoCapture(str(self.input_video))
if not cap.isOpened():
raise RuntimeError("视频打开失败")
# 加载PPT背景
ppt_bg = cv2.imread(str(self.ppt_template))
if ppt_bg is None:
raise RuntimeError("PPT背景加载失败")
# 获取视频原始尺寸
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 调整背景尺寸与视频一致
ppt_bg = cv2.resize(ppt_bg, (frame_width, frame_height))
# 更新PPT尺寸参数
self.ppt_size = (frame_width, frame_height)
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 创建视频写入器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
temp_output = str(self.final_output).replace('.mp4', '_temp.mp4')
out = cv2.VideoWriter(temp_output, fourcc, fps, self.ppt_size, isColor=True)
# 进度显示
logger.info("开始处理视频...")
current_frame = 0
# 获取当前任务ID(如果在异步上下文中)
current_task_id = None
for tid, status in task_status.items():
if status.get('status') == 'processing' and status.get('input_video') == str(self.input_video):
current_task_id = tid
break
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
current_frame += 1
if current_frame % 30 == 0: # 每30帧更新一次进度
progress = (current_frame / total_frames) * 100
logger.info(f"处理进度: {progress:.2f}%")
# 更新任务状态
if current_task_id and current_task_id in task_status:
task_status[current_task_id]['progress'] = min(80, int(progress * 0.8))
# 处理当前帧
processed_frame = self._process_frame(frame, ppt_bg)
processed_frame = self._custom_sharpen(processed_frame)
out.write(processed_frame)
# 释放资源
cap.release()
out.release()
# 更新进度
if current_task_id and current_task_id in task_status:
task_status[current_task_id]['progress'] = 85
# 合并音频
logger.info("正在合并音频...")
self._merge_audio(temp_output)
# 更新进度
if current_task_id and current_task_id in task_status:
task_status[current_task_id]['progress'] = 95
# 清理临时文件
if Path(temp_output).exists():
Path(temp_output).unlink()
logger.info(f"视频处理完成,输出文件:{self.final_output}")
return True
except Exception as e:
logger.error(f"视频处理失败: {str(e)}", exc_info=True)
return False
async def _merge_audio_async(self, temp_video_path: str):
"""音频合并 (异步版本)"""
try:
# 使用线程池执行IO密集型操作
loop = asyncio.get_event_loop()
await loop.run_in_executor(None, self._merge_audio, temp_video_path)
except Exception as e:
logger.error("音频合并失败", exc_info=True)
raise
def _merge_audio(self, temp_video_path: str):
"""音频合并"""
try:
video = VideoFileClip(temp_video_path)
audio = AudioFileClip(str(self.input_video))
# 音频时长对齐
if audio.duration > video.duration:
audio = audio.subclip(0, video.duration)
final = video.set_audio(audio)
final.write_videofile(
str(self.final_output),
codec='libx264',
audio_codec='aac',
preset='medium',
ffmpeg_params=[
'-pix_fmt', 'yuv420p',
'-crf', '12',
'-profile:v', 'high10',
'-tune', 'grain',
'-x264-params', 'aq-mode=1:deblock=0,0'
],
logger=None
)
# 清理资源
video.close()
audio.close()
final.close()
except Exception as e:
logger.error("音频合并失败", exc_info=True)
raise
# API路由处理函数
@routes.post('/api/process_video')
async def process_video_handler(request):
"""处理视频处理请求"""
try:
data = await request.json()
# 生成任务ID
task_id = str(uuid.uuid4())
# 验证必要参数
required_fields = ['input_video', 'ppt_template', 'final_output']
for field in required_fields:
if field not in data:
return web.json_response({
"code": 400,
"message": f"缺少必要参数: {field}"
}, status=400)
# 规范化路径(确保跨平台兼容)
for field in required_fields:
if field in data and isinstance(data[field], str):
# 将所有路径统一转换为系统适用的格式
data[field] = str(Path(data[field]))
# 初始化任务状态
task_status[task_id] = {
'status': 'queued',
'progress': 0,
'input_video': data['input_video'],
'ppt_template': data['ppt_template'],
'final_output': data['final_output']
}
# 创建处理器并启动异步处理
processor = VideoProcessor(data)
# 使用事件循环执行异步任务
loop = asyncio.get_event_loop()
loop.create_task(processor.process_video_async(task_id))
return web.json_response({
"code": 0,
"data": {
"task_id": task_id,
"status_url": f"/api/status/{task_id}"
}
})
except Exception as e:
logger.error(f"处理请求失败: {str(e)}", exc_info=True)
return web.json_response({
"code": 500,
"message": f"处理请求失败: {str(e)}"
}, status=500)
@routes.get('/api/status/{task_id}')
async def status_handler(request):
"""获取任务状态"""
task_id = request.match_info['task_id']
status = task_status.get(task_id, {'status': 'not_found'})
return web.json_response({
"code": 0 if status['status'] != 'not_found' else 404,
"data": status
})
# 服务启动代码
if __name__ == "__main__":
app = web.Application()
app.add_routes(routes)
# 增强的关闭处理
async def on_shutdown(app):
print("释放资源...")
print("取消后台任务...")
for task in asyncio.all_tasks():
if task is not asyncio.current_task():
task.cancel()
print("服务关闭完成")
app.on_shutdown.append(on_shutdown)
# 启动服务
web.run_app(
app,
host='0.0.0.0',
port=8040,
handle_signals=True
)说明:一段mp4绿幕背景视频,我想替换为其他背景图,第一步抠图的时候发现结果边缘还有绿色虚线

六、结语:迈向虚实共生的新纪元
6.1 总结
AI 与动作捕捉技术的深度融合,正在重构数字人的 "生命体征"。随着 5G、AR/VR 技术的普及,数字人将从单一功能载体进化为具备自主意识的虚拟生命体,成为连接物理世界与数字空间的超级入口。未来的数字人不仅是技术的集合体,更是人类情感与智慧的数字化延伸。
我们正站在一个新的时代起点上,见证着数字人技术带来的变革与创新。在这个虚实共生的新纪元中,数字人将与我们的生活、工作、娱乐深度融合,创造出无限可能的未来。
6.2 关键字解释
-
数字人:基于AI和计算机图形技术生成的虚拟角色。
-
动作捕捉:通过传感器或摄像头记录真实动作并转化为数字信号。
-
多模态交互:结合语音、表情、动作等多种方式的交互。
-
自然语言处理(NLP):使数字人理解并生成自然语言的技术。
-
情感计算:通过语音、语调等分析用户情感并做出反馈。
-
生成对抗网络(GAN):用于生成高质量图像的深度学习模型。
-
Transformer:一种基于注意力机制的神经网络架构。
-
光学捕捉:利用红外摄像头追踪标记点实现高精度动作捕捉。
-
惯性捕捉:基于MEMS传感器记录关节运动的动作捕捉技术。
-
单目视觉:利用普通摄像头实现低成本动作捕捉。
-
裸眼3D:无需佩戴设备即可实现立体视觉效果的技术。
-
虚拟主播:用于直播带货或娱乐的数字人角色。
-
虚拟医生:通过动作捕捉和AI技术实现远程医疗指导。
-
虚拟培训师:用于工业培训的数字人角色。
-
神经渲染:结合深度学习和传统渲染技术生成逼真图像。

6.3 相关素材
-
杭州亚运会数字点火仪式:结合惯性动捕和AI算法实现数字火炬手与真实火炬手动作同步。
-
农业直播带货:数字人主播通过3D建模和动作捕捉技术实现自然交互。
-
虚拟偶像直播:利用神经渲染技术生成逼真的皮肤纹理和光影效果。
2、数字人技术的核心:AI与动作捕捉的双引擎驱动(2/10)
后续文章正在快马加鞭撰写中,请关注《数字人》专栏即将更新......
文章3:《数字人:虚拟偶像的崛起与经济价值》
文章4:《数字人:从娱乐到教育的跨界应用》
文章5:《数字人:医疗领域的革命性工具》
文章6:《数字人:品牌营销的新宠》
文章7:《数字人:元宇宙中的核心角色》
文章8:《数字人:伦理与法律的挑战》
文章9:《数字人:未来职业的重塑》
文章10:《数字人:人类身份与意识的终极思考》