新榜中导出数据是收费的,如何免费导出呢
接口分析
切换分类排行,数据是在这个接口中请求的
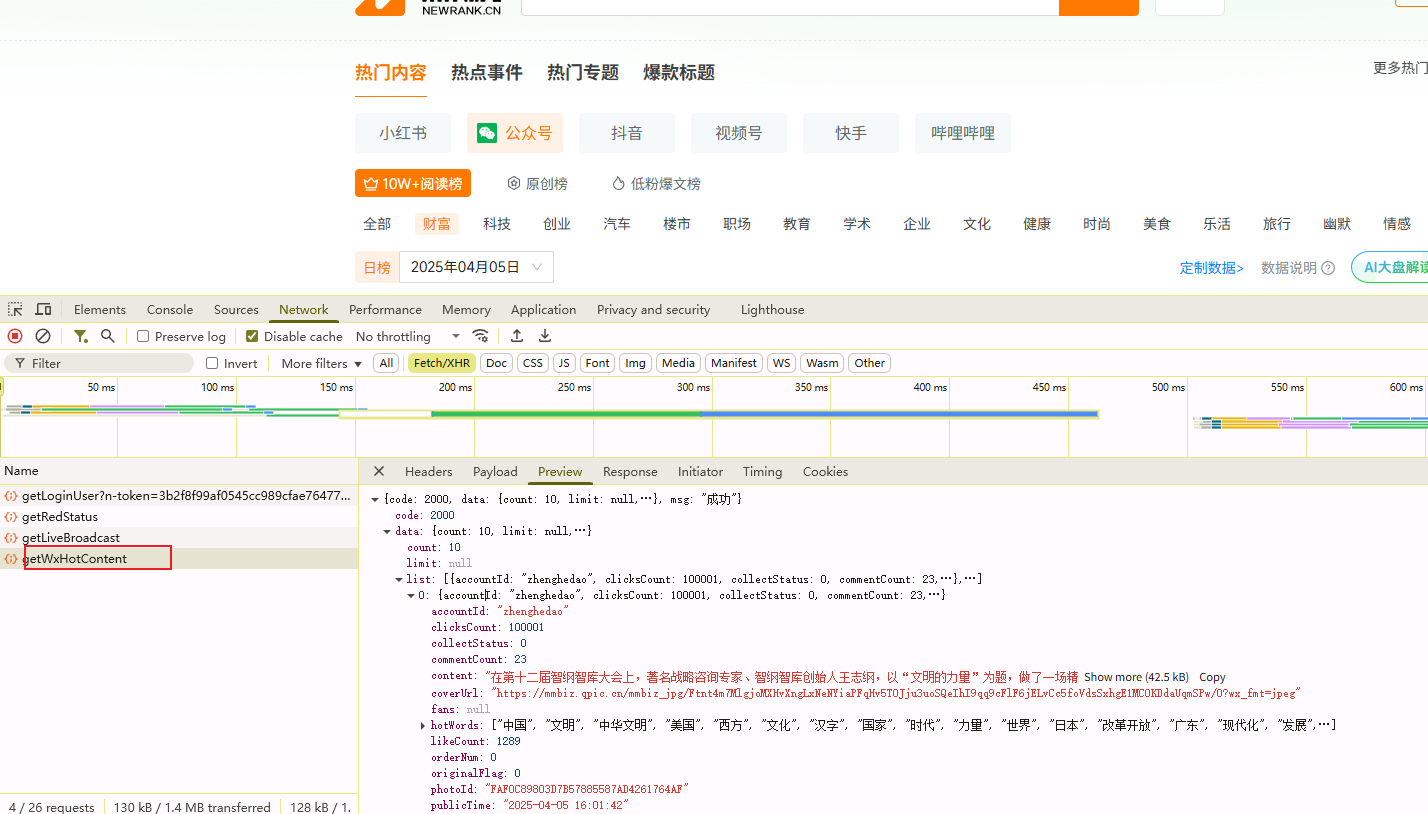
参数:
js
{"rankType":1,"rankDate":"2025-04-05","type":["财富"],"size":25,"start":1,"secondType":""}
{"rankType":1,"rankDate":"2025-04-05","type":["创业","科技","财富"],"size":25,"start":1,"secondType":""}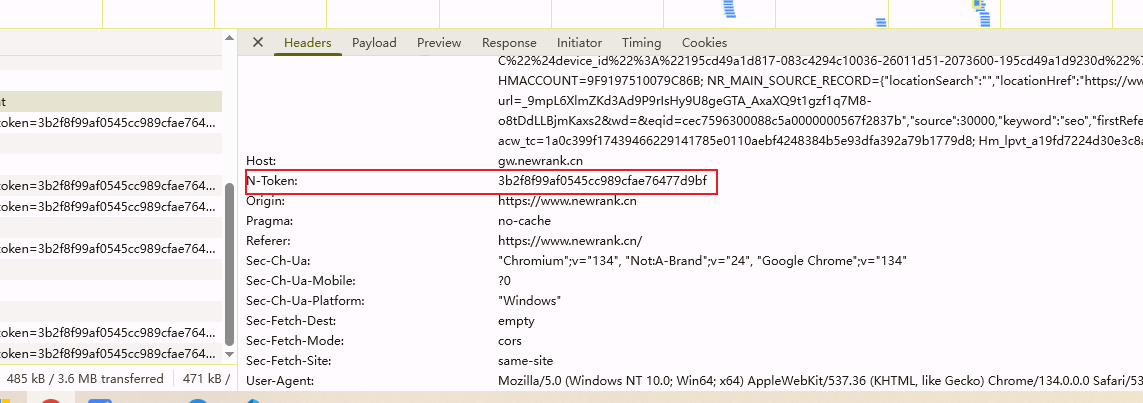
参数分析:
type就是分类数据,rankDate是排行榜日期
header中有个特殊参数n-token
n-token不是每次都变化的,相对比较固定,判断不是根据参数加密,这里就不去分析n-token加密,直接使用
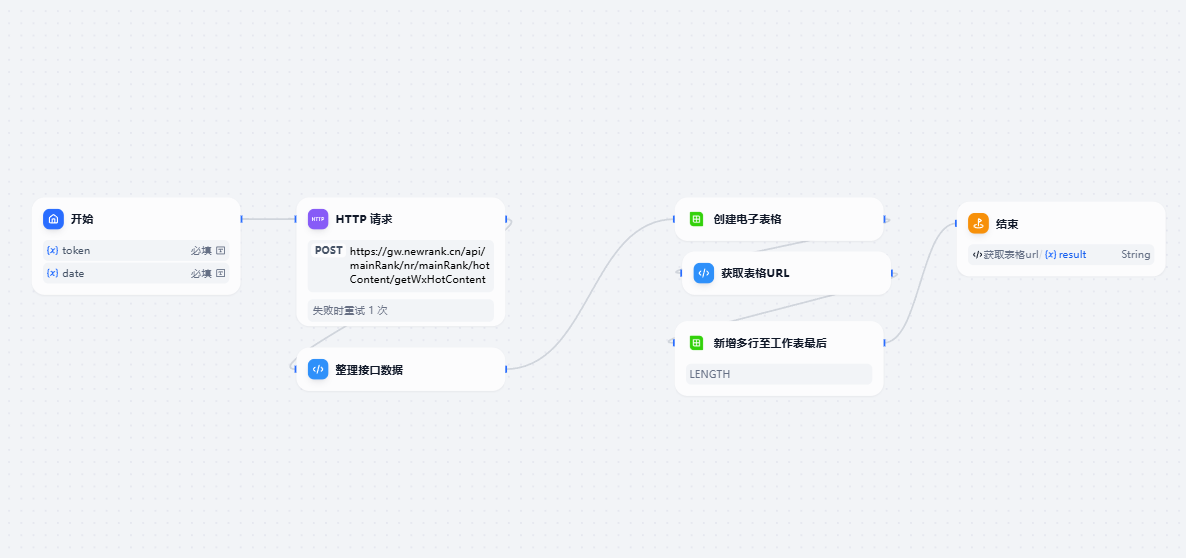
搭建dify工作流
1.开始节点
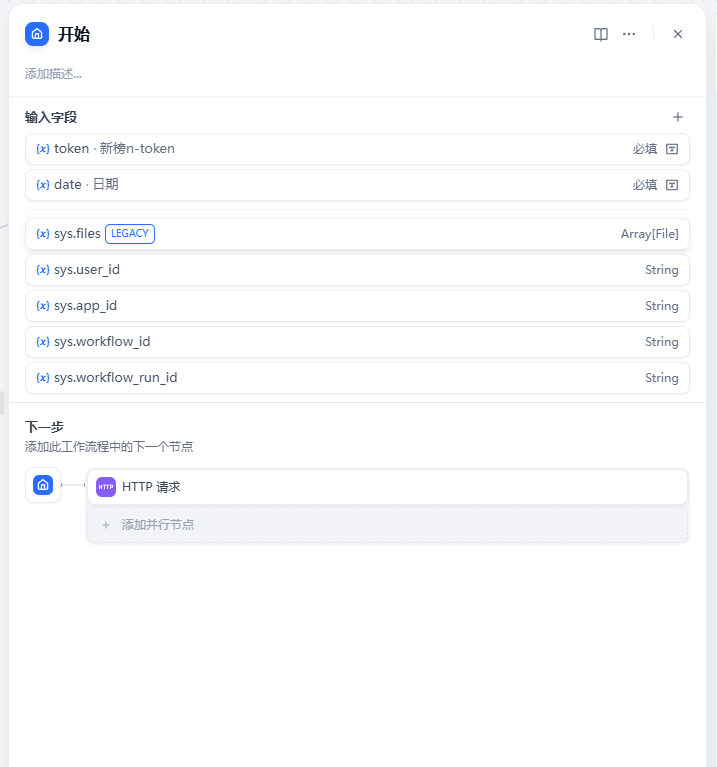
这里需要两个参数: n-token,日期
2. post请求节点
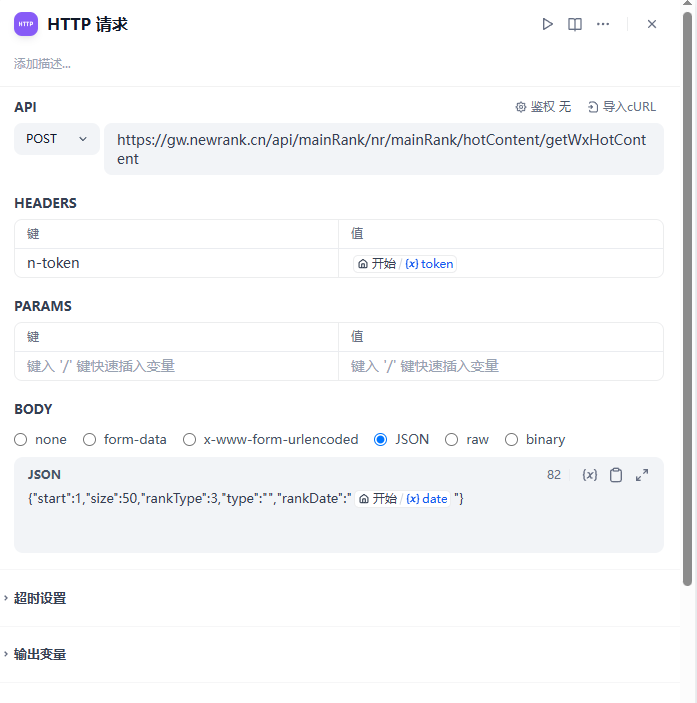
请求地址是固定的,请求头需要设置一下n-token,使用开始节点中传入的token
请求体中日期参数使用开始节点date字段
3. 请求结果整理
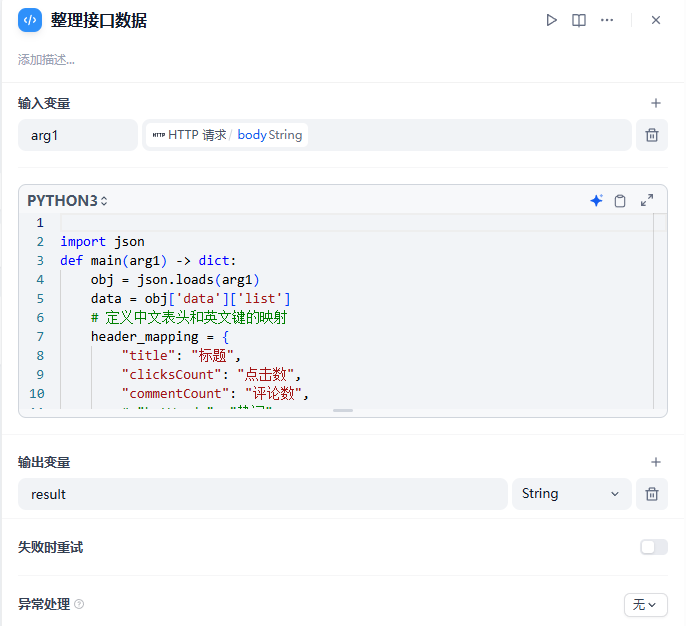
飞书表格格式[["编号","姓名","年龄"],[1,"张三",10],[2,"李四",11]]是二维数组格式的字符串,需要将接口数据整理成这个二维数组的格式,这里我使用代码节点进行转换,也可以使用大模型进行转换
4. 创建飞书表格
创建电子表格时需要现在飞书文档中创建文件夹,
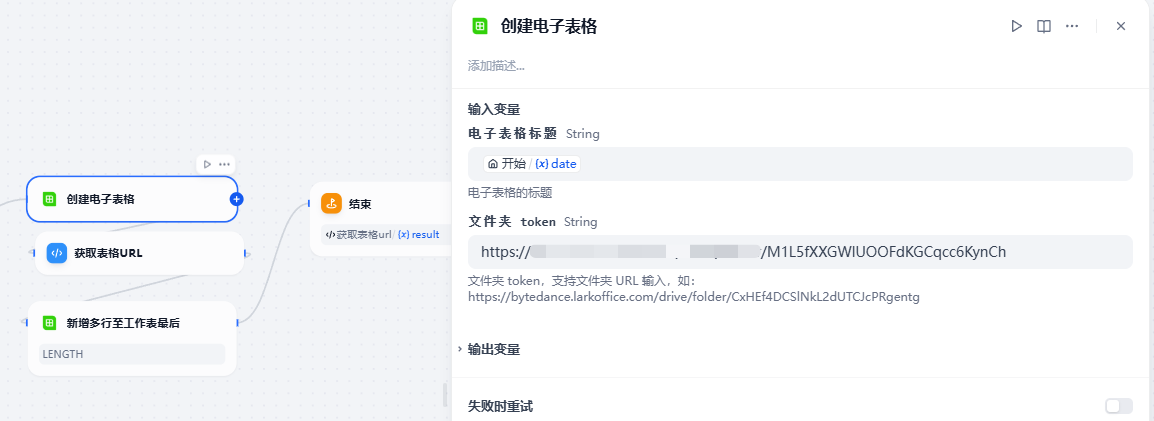
这里使用代码获取了一下飞书表格地址
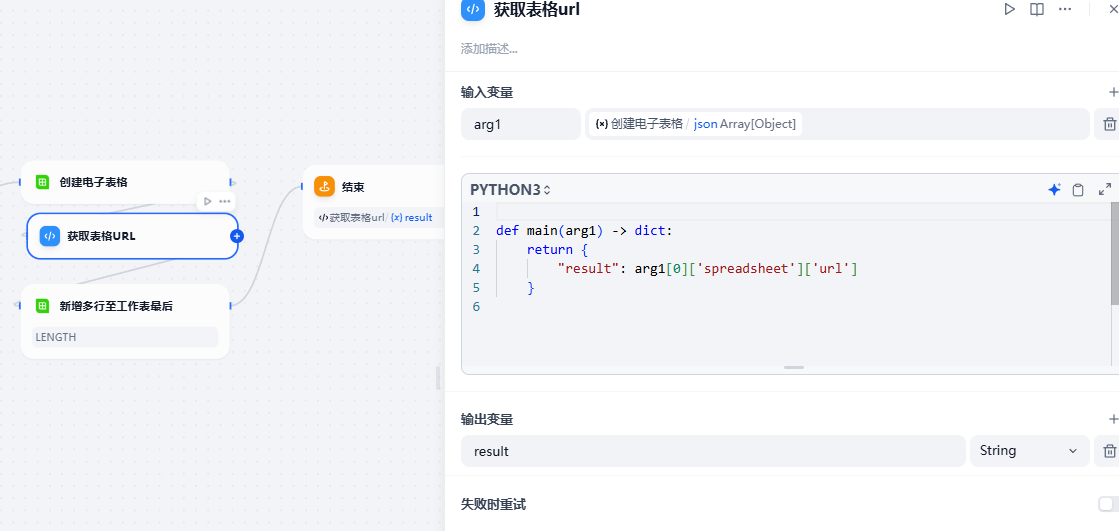
将数据添加到表格
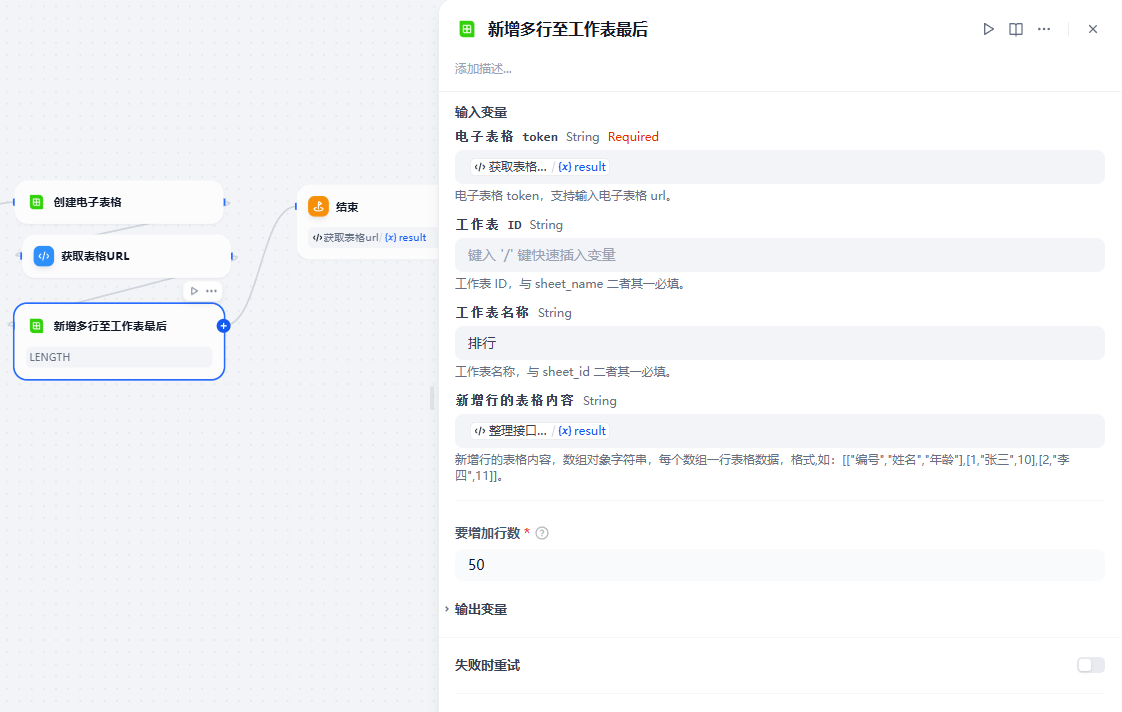
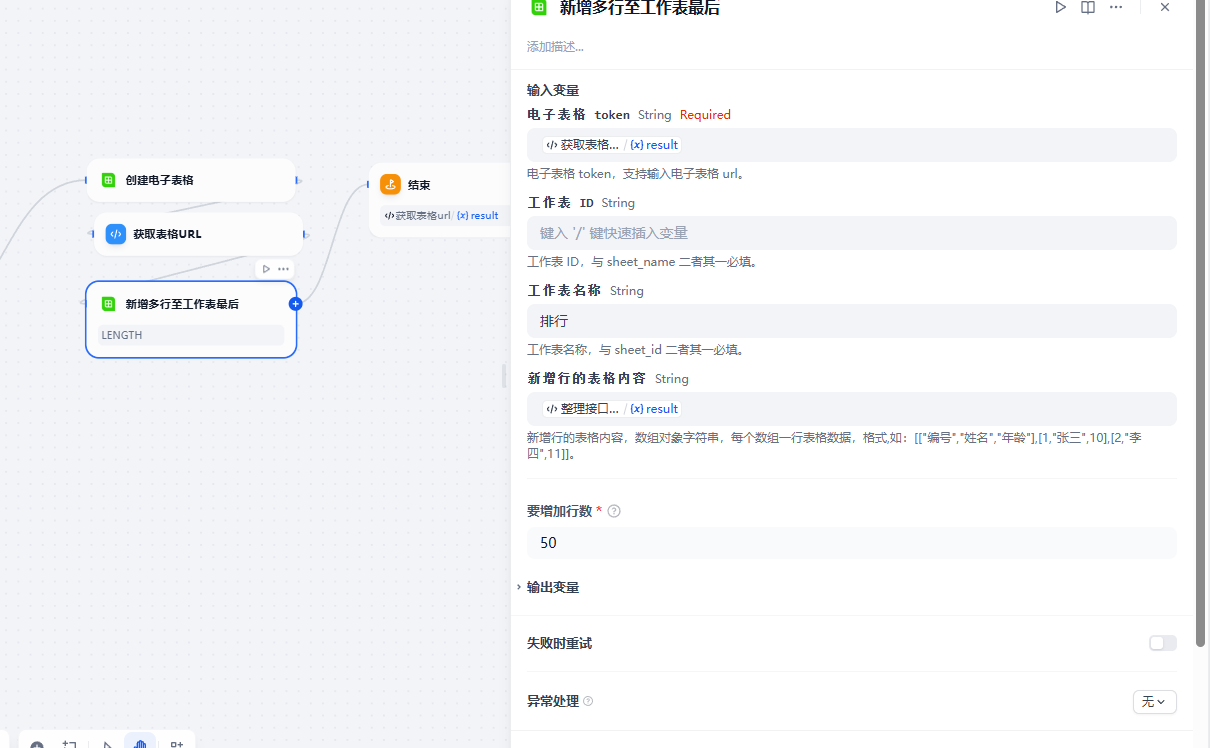
增加行数这里没法使用变量,需要设置一个固定值,可以根据接口参数中的count设置,也可以使用一个较大的值
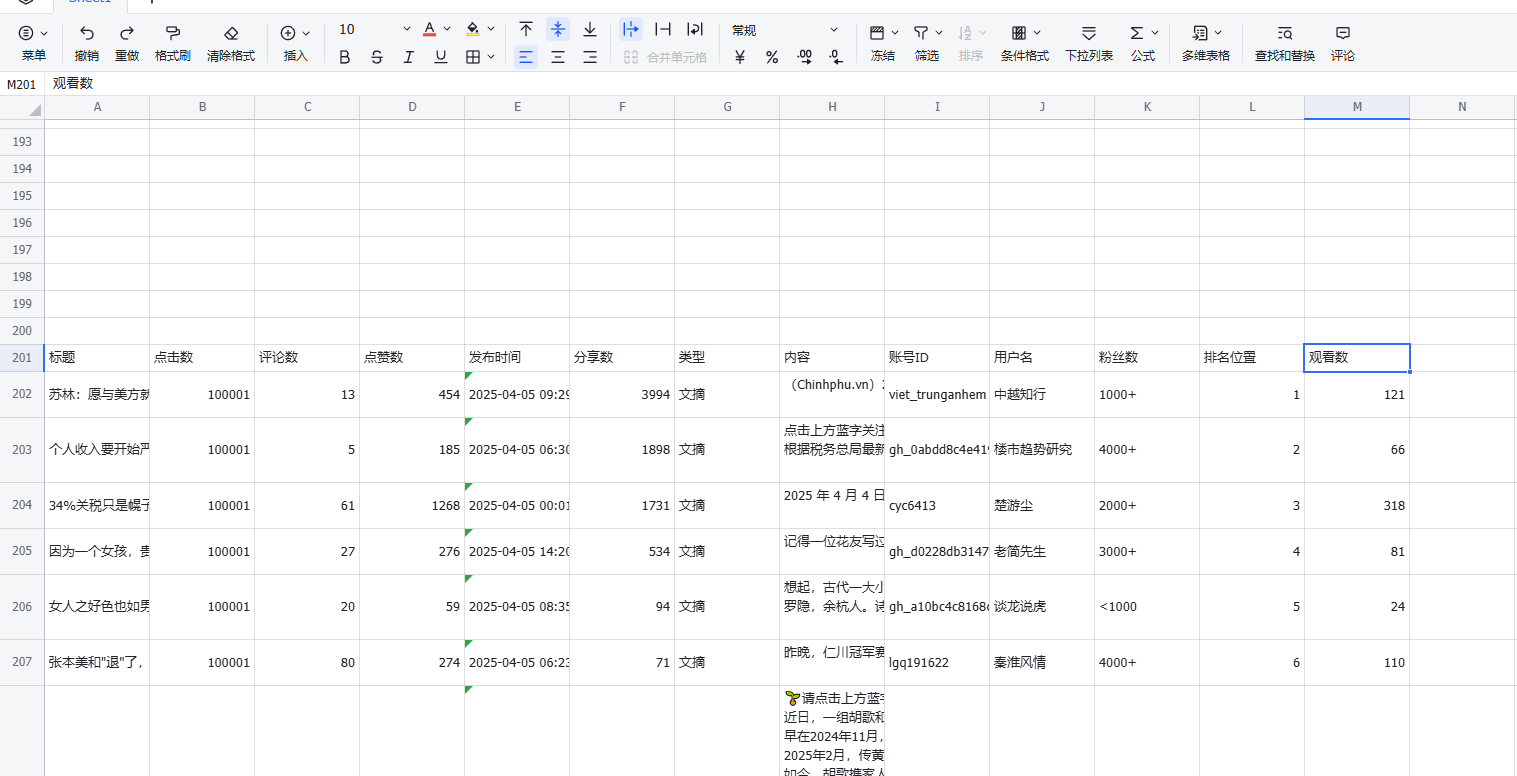
新建的表格默认会添加200空行,所以打开表格时候看到没有数据不要慌,要滚动到200行以后才会看到数据,飞书没有提供删除行的接口,这个没发避免,如果实在看不过去就手动删除一下前面200空行
这样一个简单的工作流就完成了
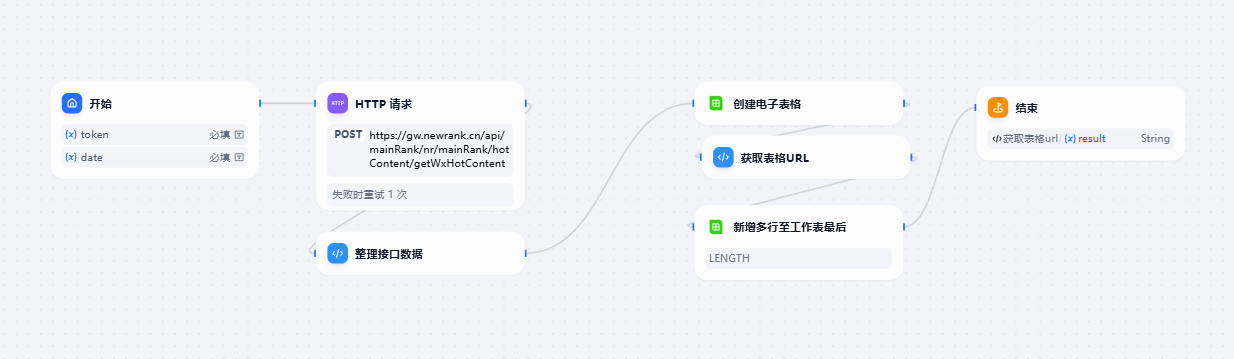
如果需要抖音,小红书,快手的数据可以在开始节点中加一个类型,根据类型请求不同接口的数据