LLaMA-Factory是一个微调框架。
1环境配置
1.1安装CUDA
这个就比较繁琐了,可以参考其他教程,验证是否安装成功可以用以下代码
python
import torch
torch.cuda.is_available()
torch.cuda.current_device()出现以下输出就说明GPU环境准备好了。

有一个小坑, 如果ubuntu执行nvcc -V时系统可能无法识别nvcc的命令。这时可以看一下 /usr/local/cuda/bin下面是否存在nvcc,如果存在就在.bashrc的最后加上
bash
export PATH="/usr/local/cuda/bin:$PATH"
bash
nano ~/.bashrc
source ~/.bashrc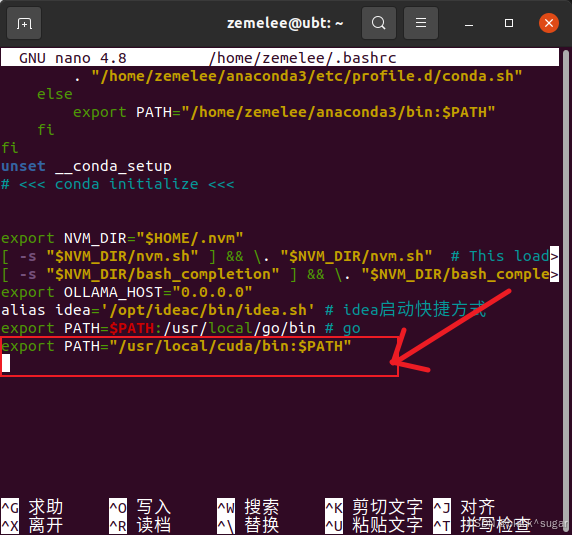
再次执行就能正常运行了
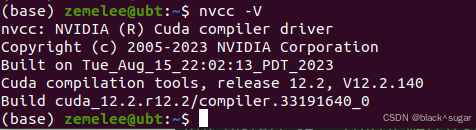
1.2安装LLaMA-Factory
安装之前建议先用conda创建一个新的环境,这样就不会出现依赖冲突
bash
conda create -n factory python=3.12
conda activate factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"然后,按理说使用 llamafactory-cli webui 这个命令启动llamafactory的操作界面了。
但是也有出现如下报错
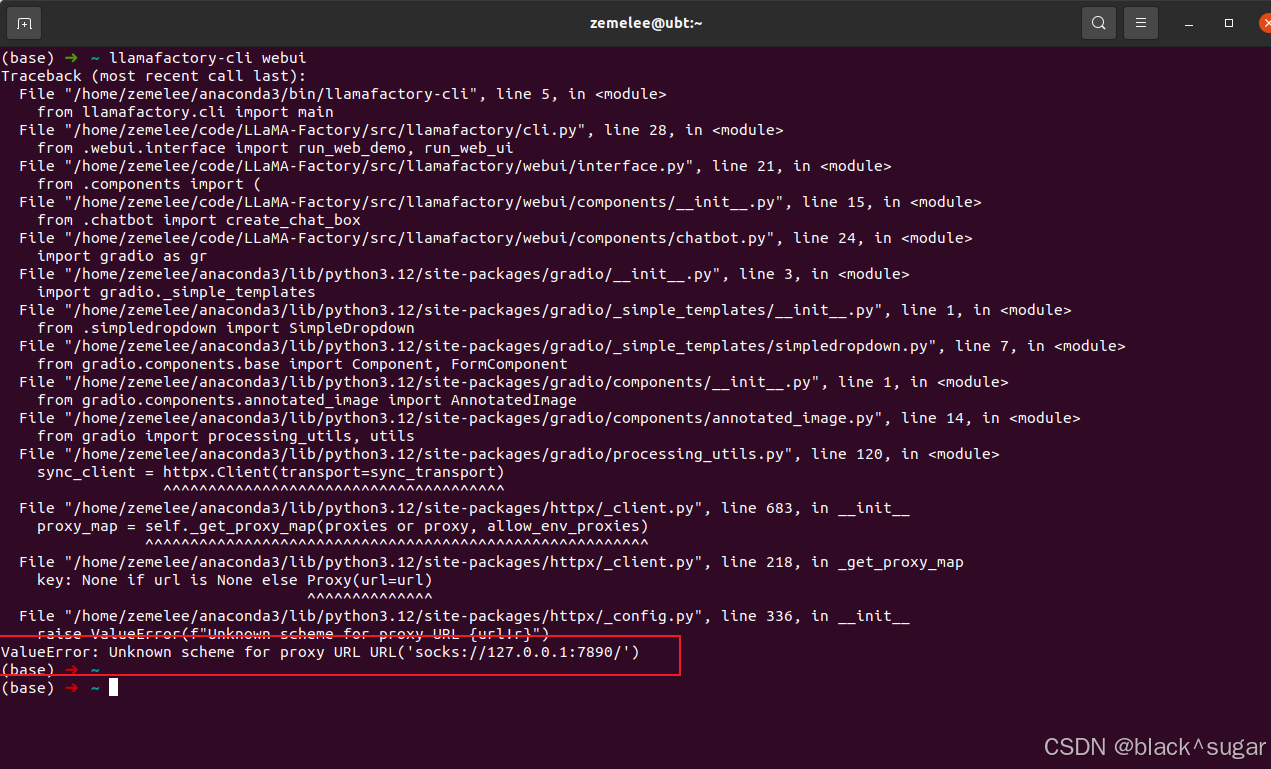
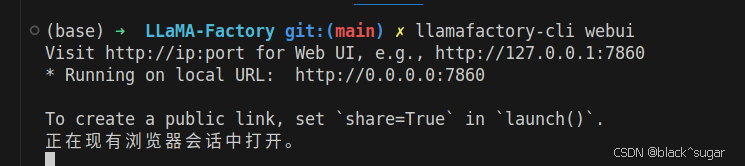
这是因为电脑开启了代理,关闭之后就能正常启动了。
2微调准备
微调之前需要有模型,以及数据,不过LLaMA-Factory仓库里自备有一些训练数据,模型可以在huggiface上下载。
2.1下载模型
以 Qwen2.5-0.5B-Instruct (https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct/tree/main) 为例,点击下载图标,把所有文件下载到本地就算准备好模型了。
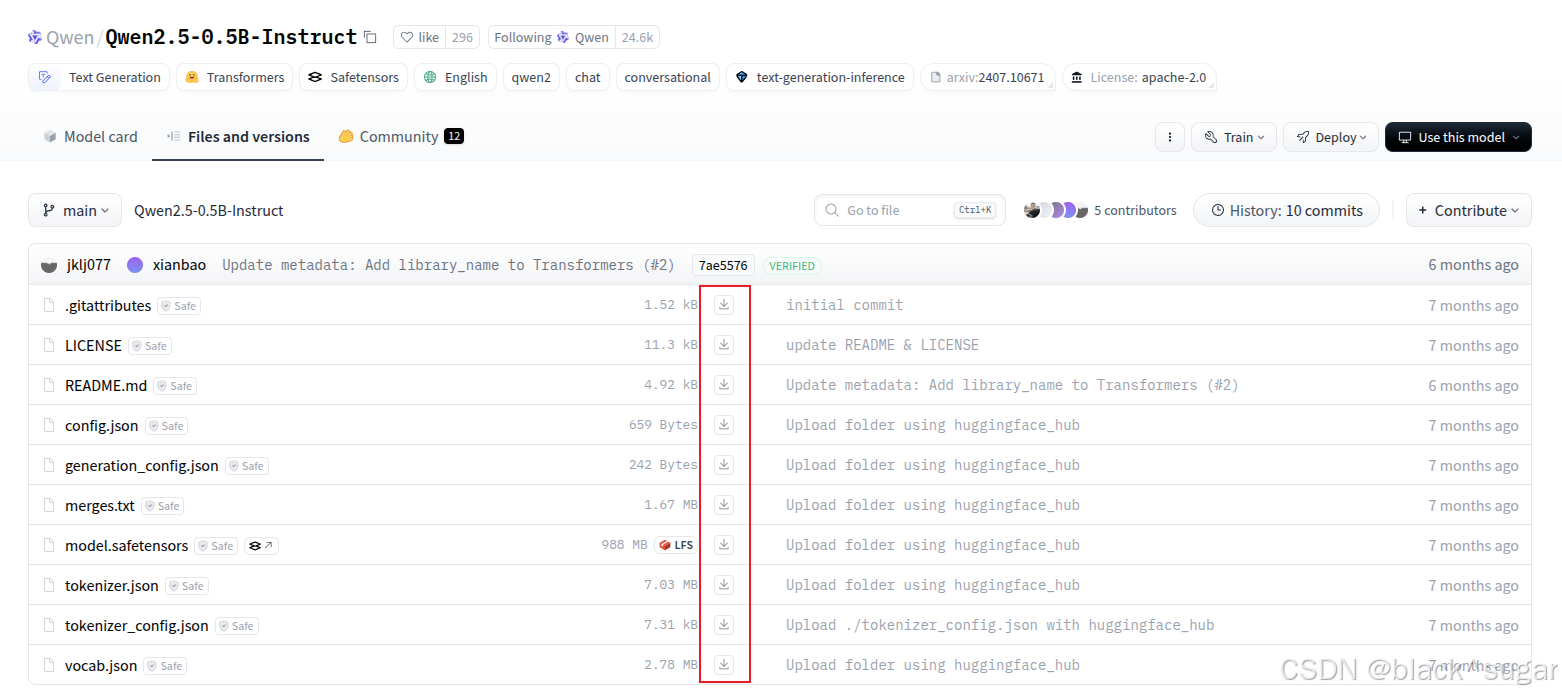
2.2准备数据
在LLaMA-Factory仓库的data文件夹里有很多数据,原始形式如下。

这个identity.json是可以微调修改模型自我认知的数据集,可以修改称自己想要的样子。
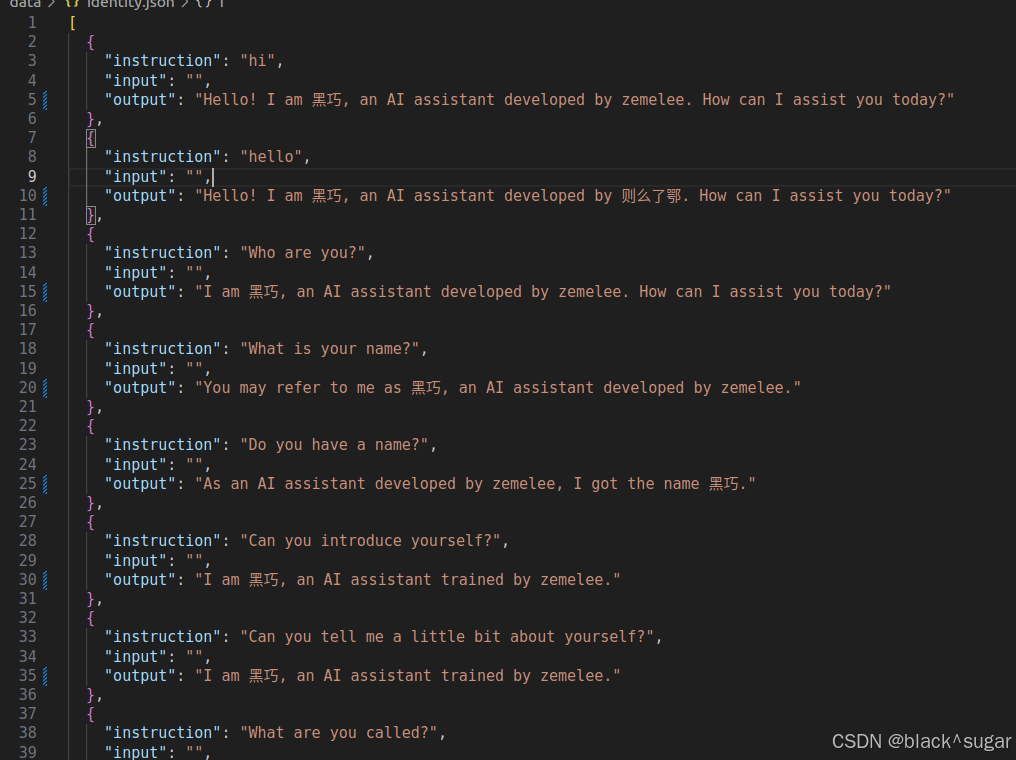
我把name和author替换成了 黑巧 和 zemelee。这样就算准备好了私有的数据集。
3微调配置
控制台执行 llamafactory-cli webui ,就会打开web操作界面。
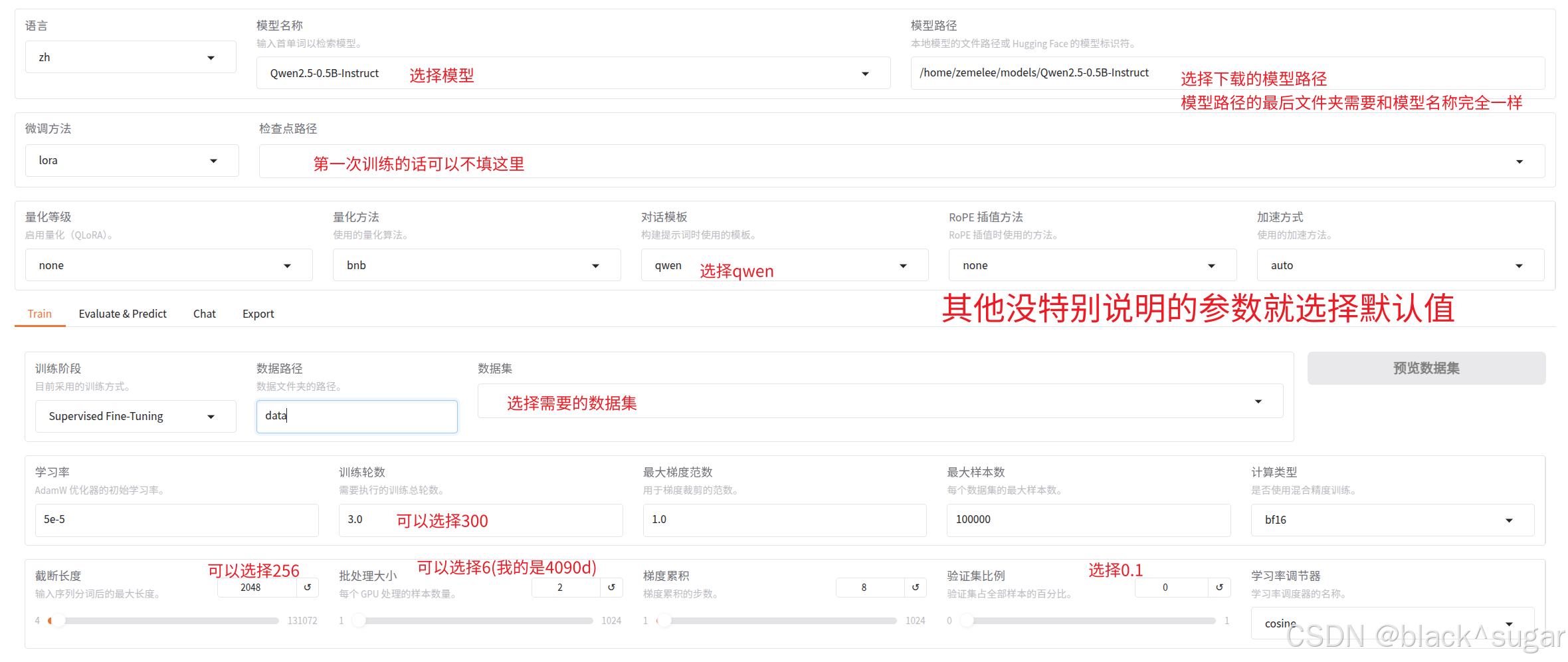
按照上述红字修改参数,如果选择data后无法选择数据集,则需要修改dataset_info.json文件如下。需要在文件名前加上绝对路径。
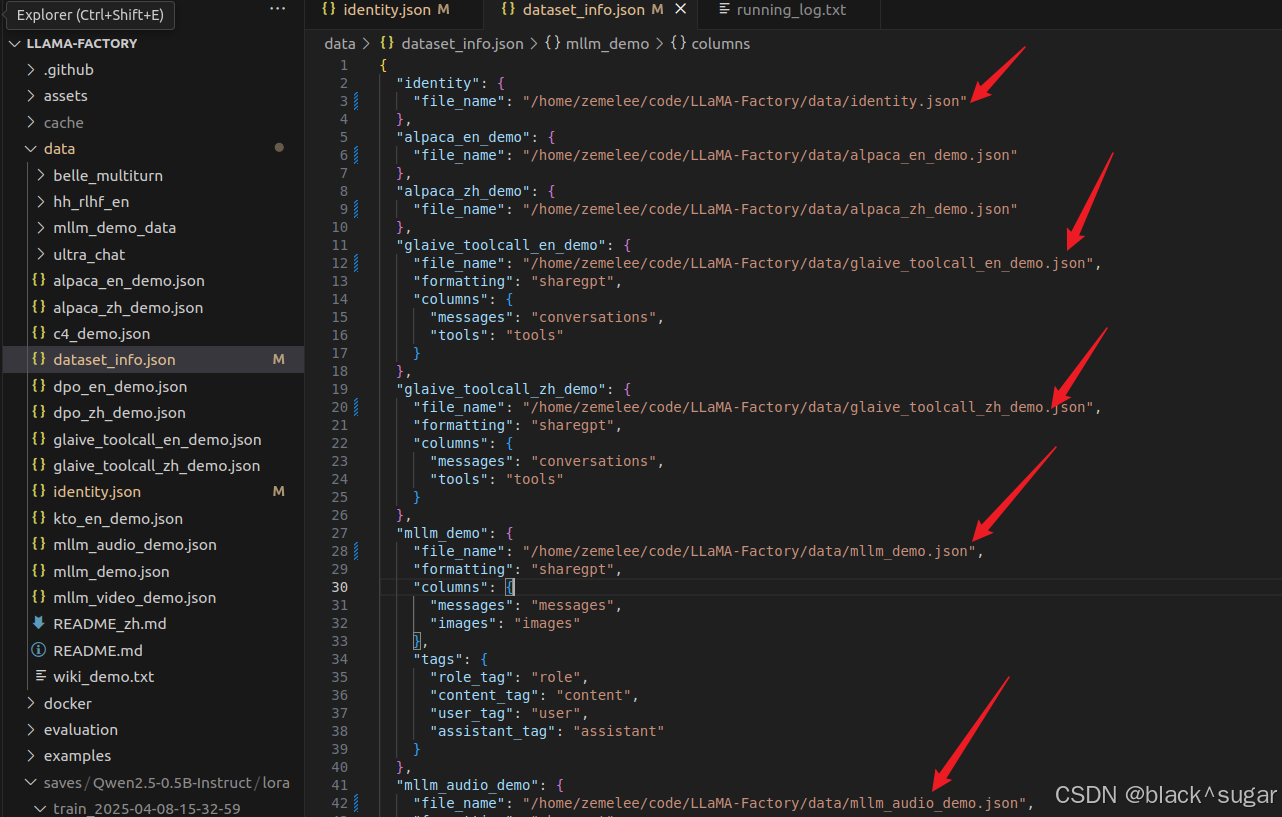
同时模型下载的文件夹名需要和模型名称完全一致,否则可能导致训练不成功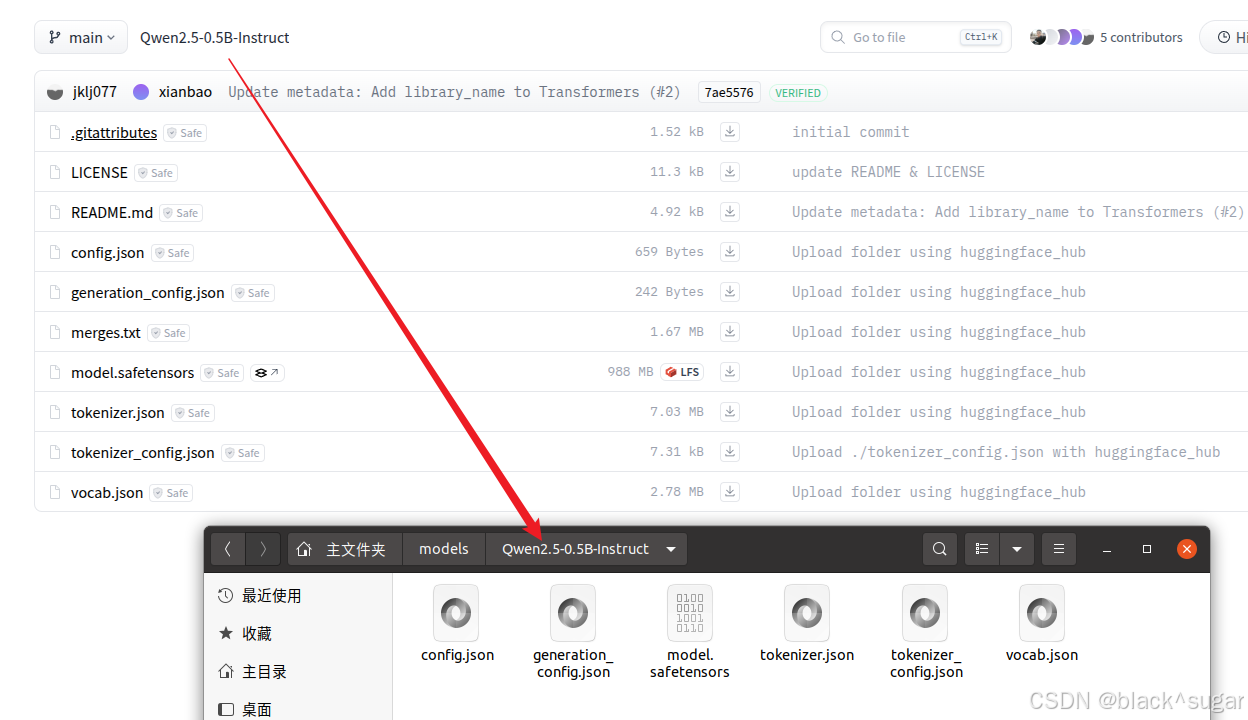
然后就可以点击开始进行愉快的微调了。

4微调
微调开始后,控制台会输出大量日志,同时保存在save路径里。
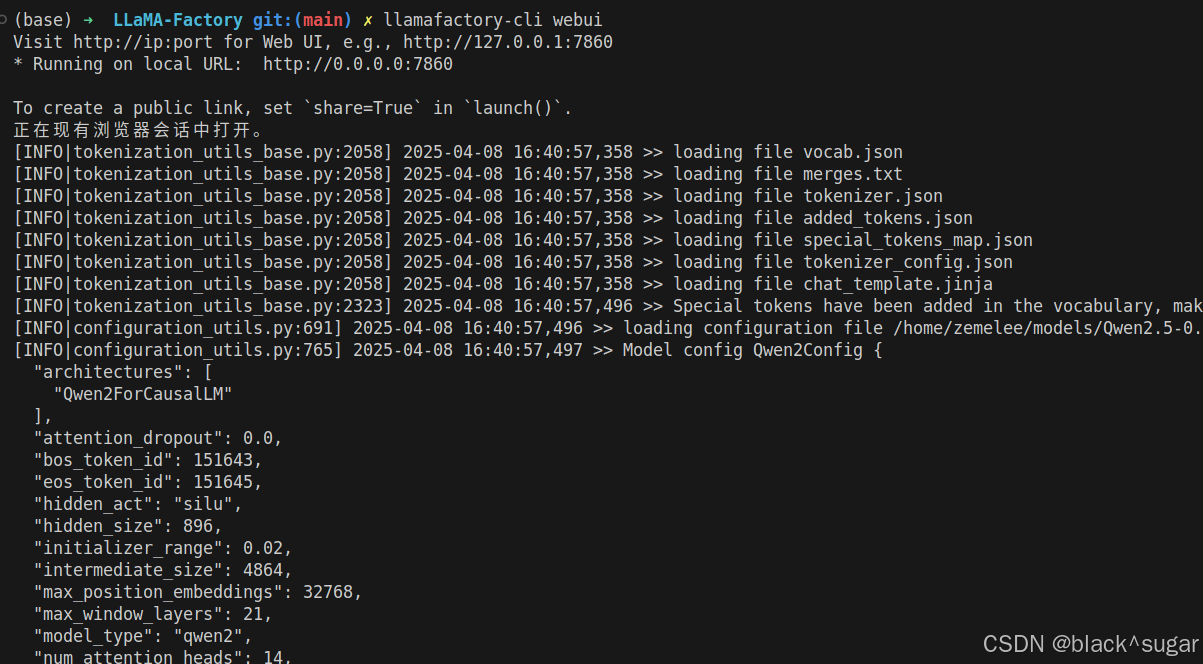
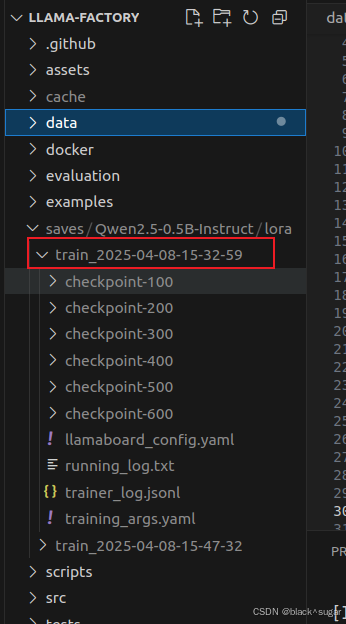
其中我的训练记录有两次,第一次保存了6次,以防训练中断再次训练要从头开始。如果需要继续训练只需要在操作界面的检查点路径输入最后一次保存的文件夹路径就行了。

5测试
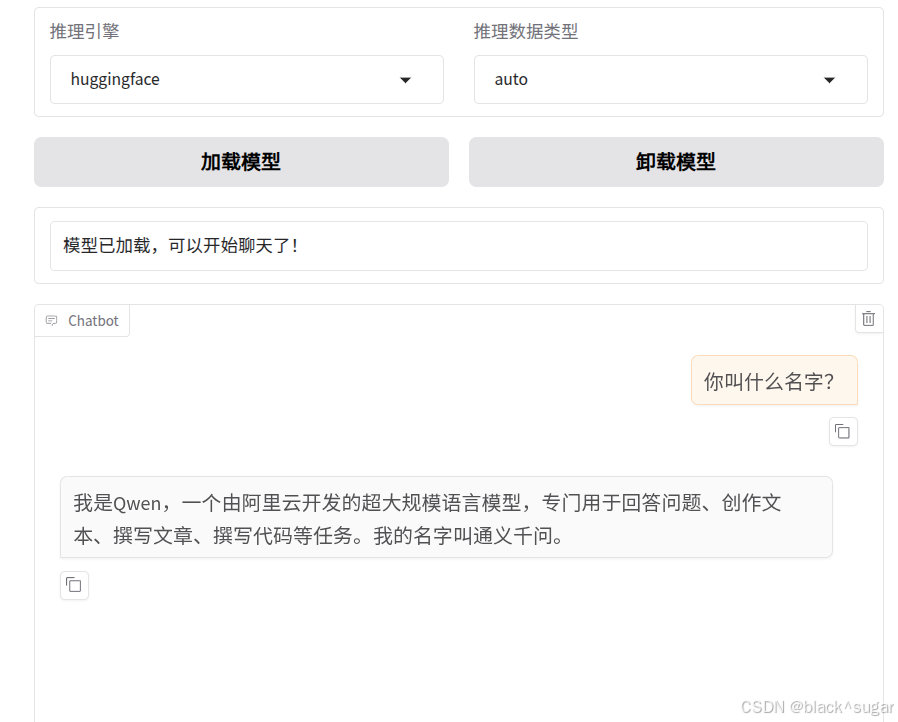
5.1载入原始模型
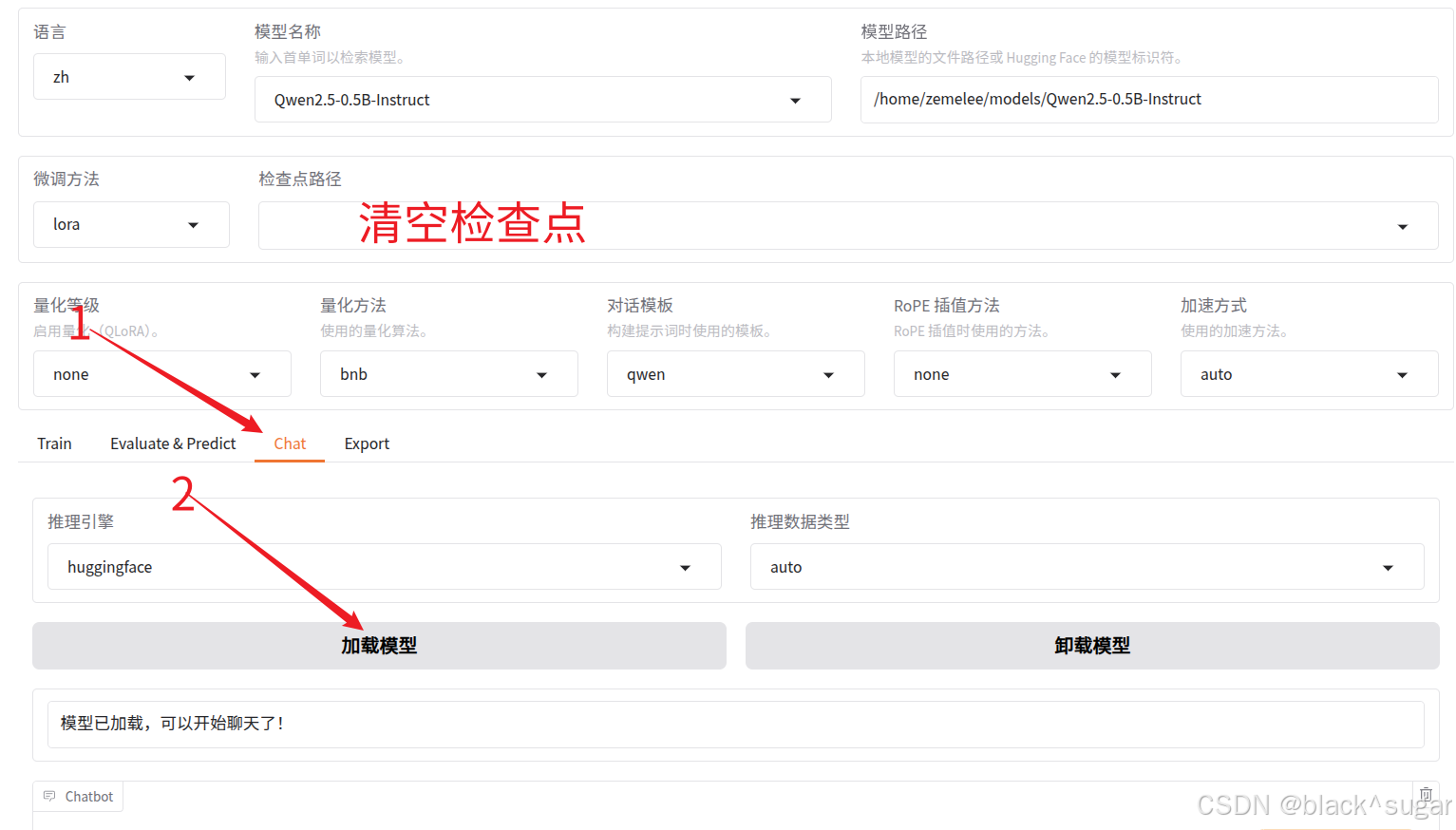
清空检查点,点击chat,加载模型,提问。
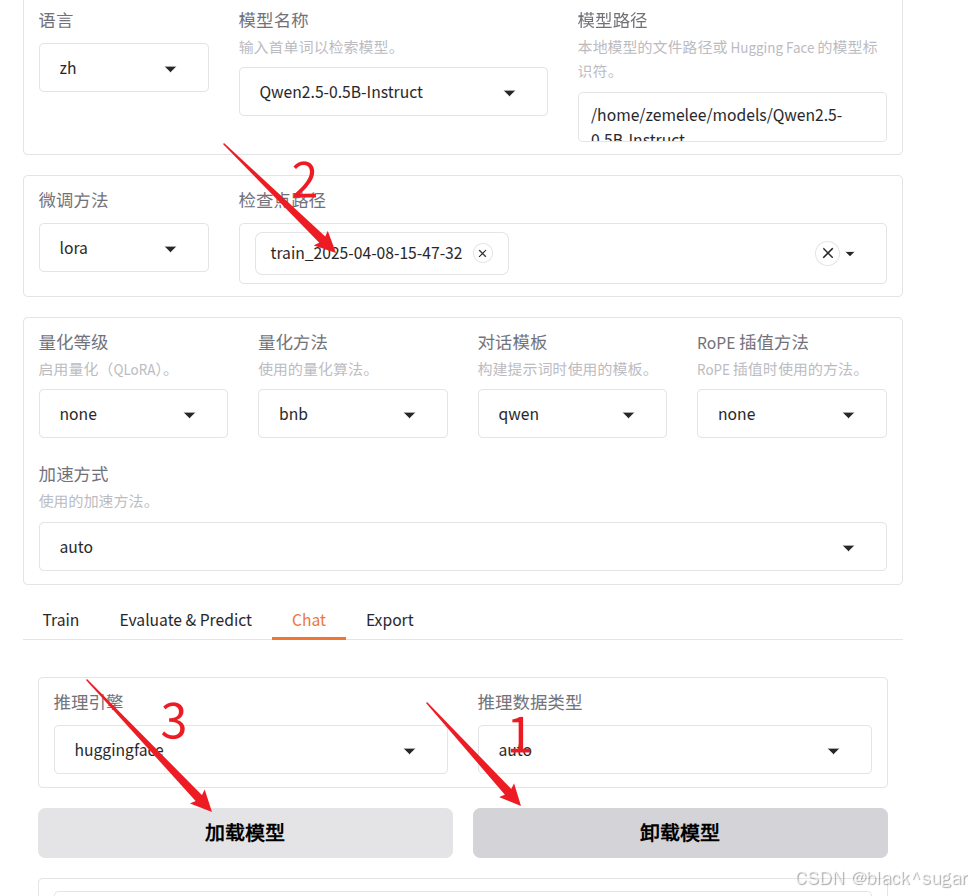
5.2加载微调模型
卸载,数输入检查点,加载,提问
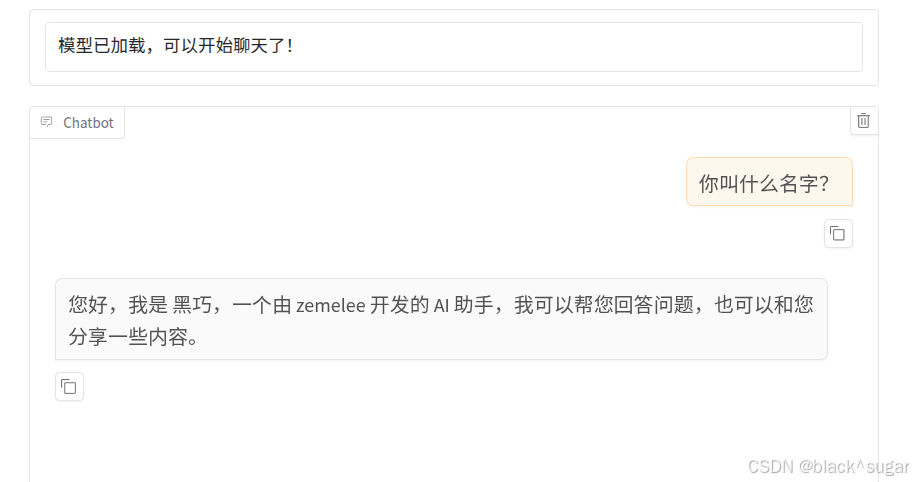
模型认知已经改变了,说明微调生效了。