二叉搜索树 ,它或者是一棵空树 ,或者是具有下列性质的二叉树: 若它的左子树不为空,则左子树上所有结点的值均小于它的根结点的值 ; 若它的右子树不为空,则右子树上所有结点的值均大于它的根结点的值 ; 它的左、右子树也分别为二叉排序树。
文章目录
- 一、初识二叉搜索树
-
- [1. 概念](#1. 概念)
- [2. 性能分析](#2. 性能分析)
- 二、二叉搜索树的基本操作
-
- [1. 插入操作](#1. 插入操作)
- [2. 查找操作](#2. 查找操作)
- [3. 删除操作](#3. 删除操作)
- 三、二叉搜索树的实现
- [四、二叉搜索树的 key 和 key/value 搜索](#四、二叉搜索树的 key 和 key/value 搜索)
-
- [1. key 搜索](#1. key 搜索)
- [2. key/value 搜索](#2. key/value 搜索)
- [3. key/value 二叉搜索树的实现](#3. key/value 二叉搜索树的实现)
- 总结
一、初识二叉搜索树
1. 概念
二叉搜索树 又称二叉排序树 ,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空 ,则左子树 上所有结点的值都小于等于根结点的值。
- 若它的右子树不为空 ,则右子树 上所有结点的值都大于等于根结点的值。
- 它的左右子树也分别为二叉搜索树。
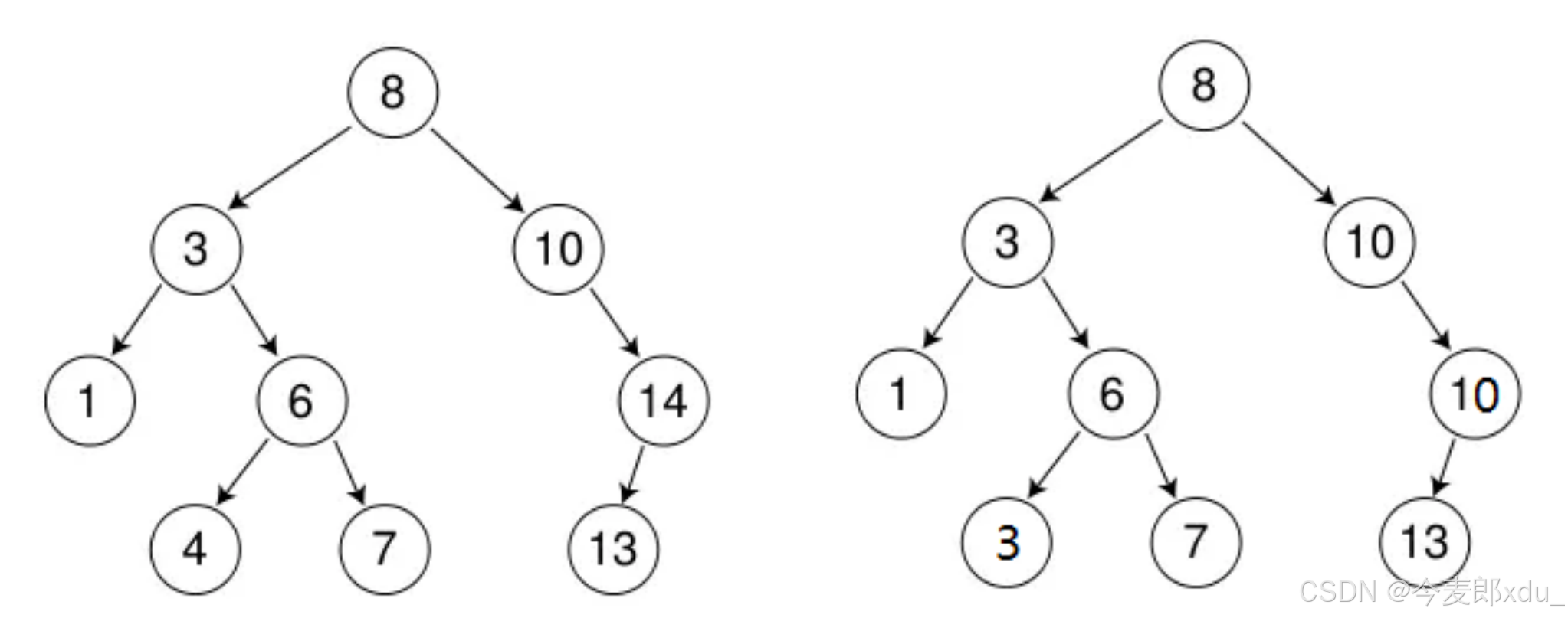
二叉搜索树中可以支持插入相等的值 ,也可以不支持插入相等的值,具体看使用场景定义:
在 C C C++ S T L STL STL 标准库中, m a p / s e t / m u l t i m a p / m u l t i s e t map/set/multimap/multiset map/set/multimap/multiset 系列容器底层就是二叉搜索树 ,其中 m a p / s e t map/set map/set 不支持插入相等值, m u l t i m a p / m u l t i s e t multimap/multiset multimap/multiset 支持插入相等值。
2. 性能分析
最优情况 下,二叉搜索树为完全二叉树 (或者接近完全二叉树),其高度为: log 2 N \log_2N log2N;
最差情况 下,二叉搜索树退化为单支树 (或者类似单支),其高度为: N N N;
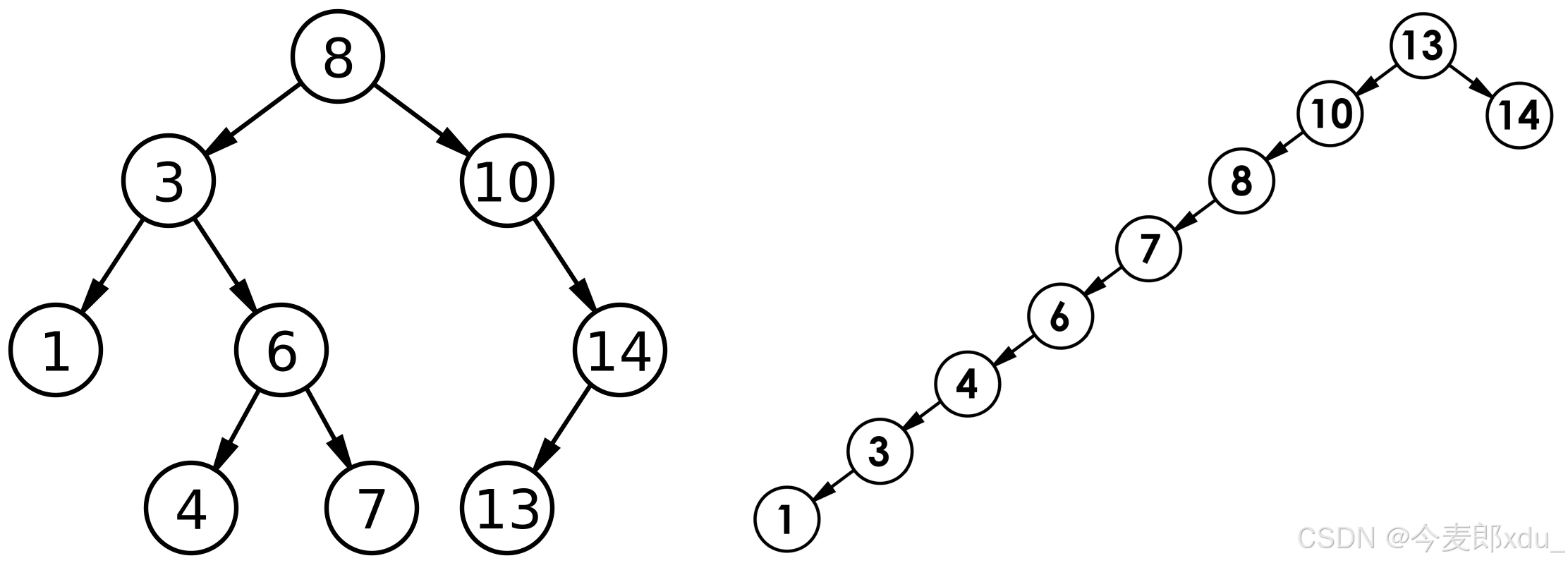
所以综合而言,二叉搜索树增删查改时间复杂度为: O ( N ) O(N) O(N)。
因此,这样的效率显然是无法满足我们需求的,所以后面又引申出了二叉搜索树的变形:平衡二叉搜索树 ( A V L AVL AVL 树、红黑树 和 B B B 树系列),才能适用于我们在内存中存储和搜索数据。
【注意】为什么已经有二分查找了,还需要二叉搜索树呢?
虽然二分查找 也可以实现 O ( log 2 N ) O(\log_2N) O(log2N) 级别的查找效率,但是二分查找有两大缺陷:
-
需要存储在支持下标随机访问 的结构中,并且有序。
-
插入和删除数据效率很低 ,因为存储在下标随机访问的结构中,插入和删除数据一般需要挪动数据。
这里也就体现出了平衡二叉搜索树的价值。
二、二叉搜索树的基本操作
1. 插入操作
二叉搜索树的插入操作 的最坏时间复杂度 为 O ( N ) O(N) O(N)。(有序数组)
插入的具体过程如下:
- 树为空 ,则直接新增结点 ,赋值给 r o o t root root 指针:
cpp
if (_root == nullptr)
{
_root = new node(key);
return true;
}- 树不空 ,按二叉搜索树性质,插入值比当前结点大往右 走,插入值比当前结点小往左走:
cpp
node* parent = nullptr;
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}- 找到空位置,插入新结点:
cpp
cur = new node(key);
if (key < parent->_key)
{
parent->_left = cur;
}
else
{
parent->_right = cur;
}
return true;注意:如果支持插入相等的值,插入值跟当前结点相等的值可以往右走,也可以往左走,找到空位置,插入新结点。(这里我选择的是不支持相等的值插入)
原数组:
cpp
int a[] = {8, 3, 1, 10, 6, 4, 7, 14, 13};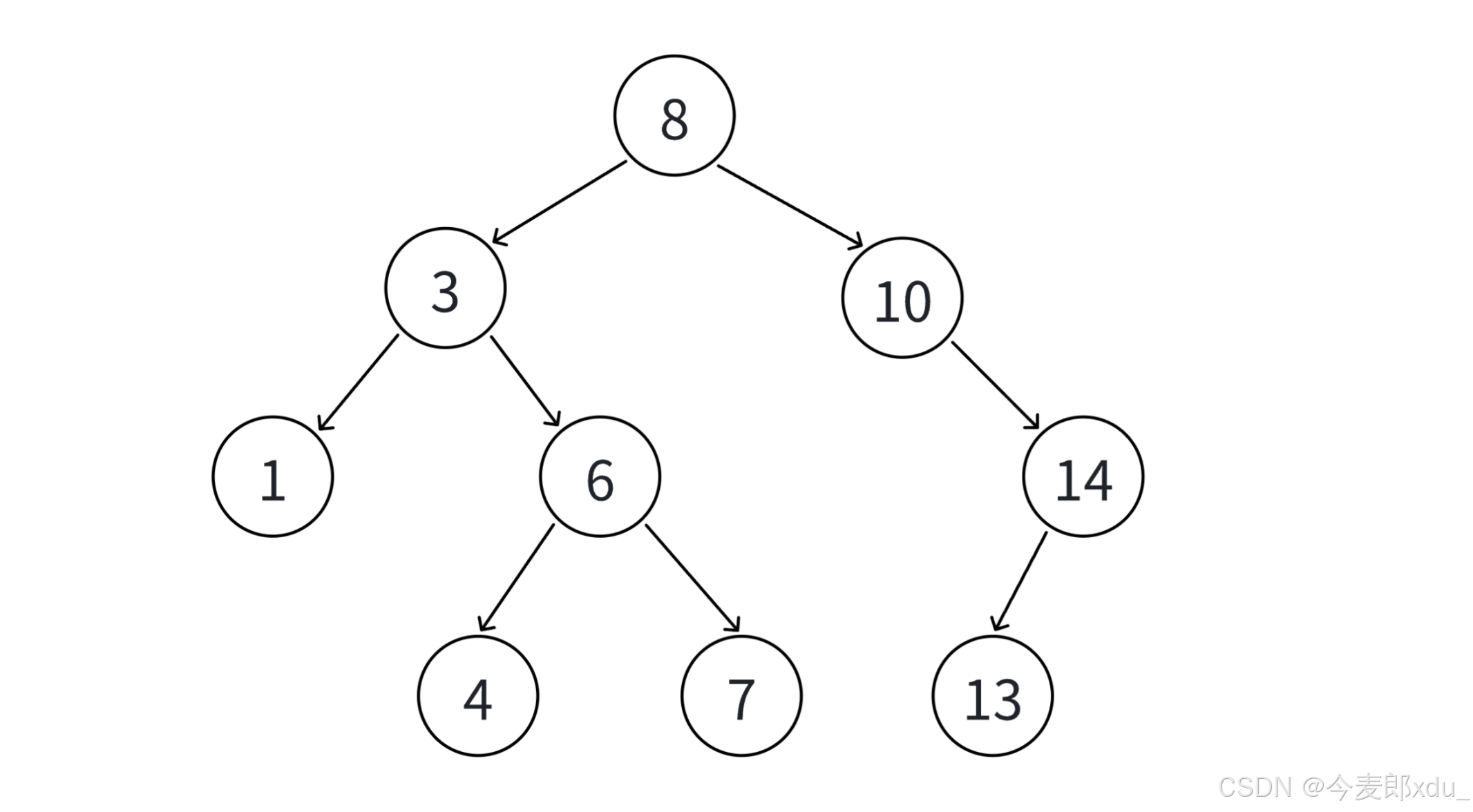
插入一个元素 16 16 16:
cpp
int a[] = {8, 3, 1, 10, 6, 4, 7, 14, 13, 16};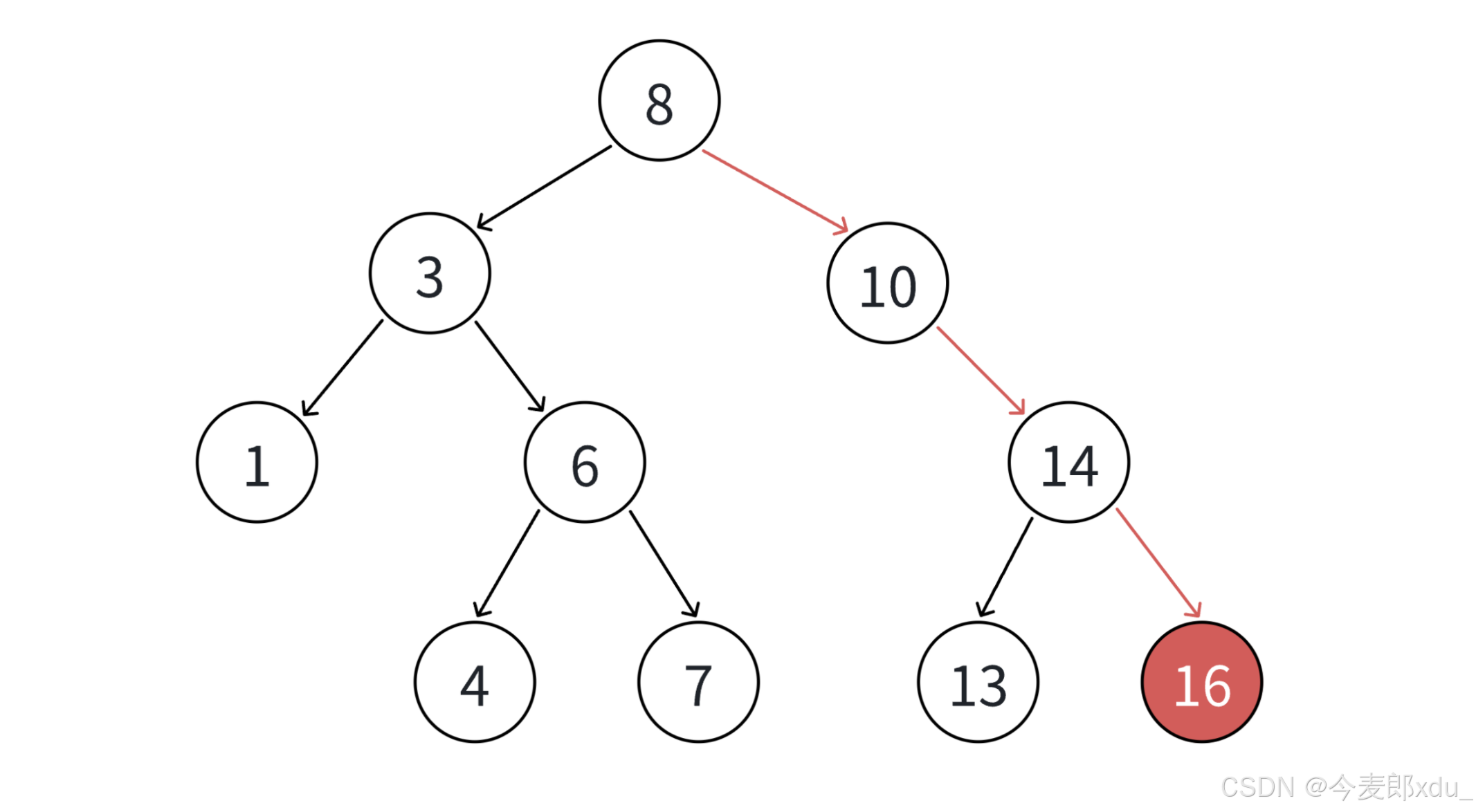
完整代码示例:
cpp
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new node(key);
return true;
}
node* parent = nullptr;
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}
cur = new node(key);
if (key < parent->_key)
{
parent->_left = cur;
}
else
{
parent->_right = cur;
}
return true;
}2. 查找操作
二叉搜索树的查找操作 和插入操作一样,最坏时间复杂度 为 O ( N ) O(N) O(N)。(有序数组)
-
从根开始比较,查找 x x x, x x x 比根的值大则往右边走查找, x x x 比根值小则往左边走查找。
-
最多查找高度次,走到空,还没找到,则说明这个值不存在。
-
如果不支持插入相等 的值,找到 x x x 即可返回。
代码示例:
cpp
bool find(const K& key)
{
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
cur = cur->_left;
}
else if (key > cur->_key)
{
cur = cur->_right;
}
else
{
return true;
}
}
return false;
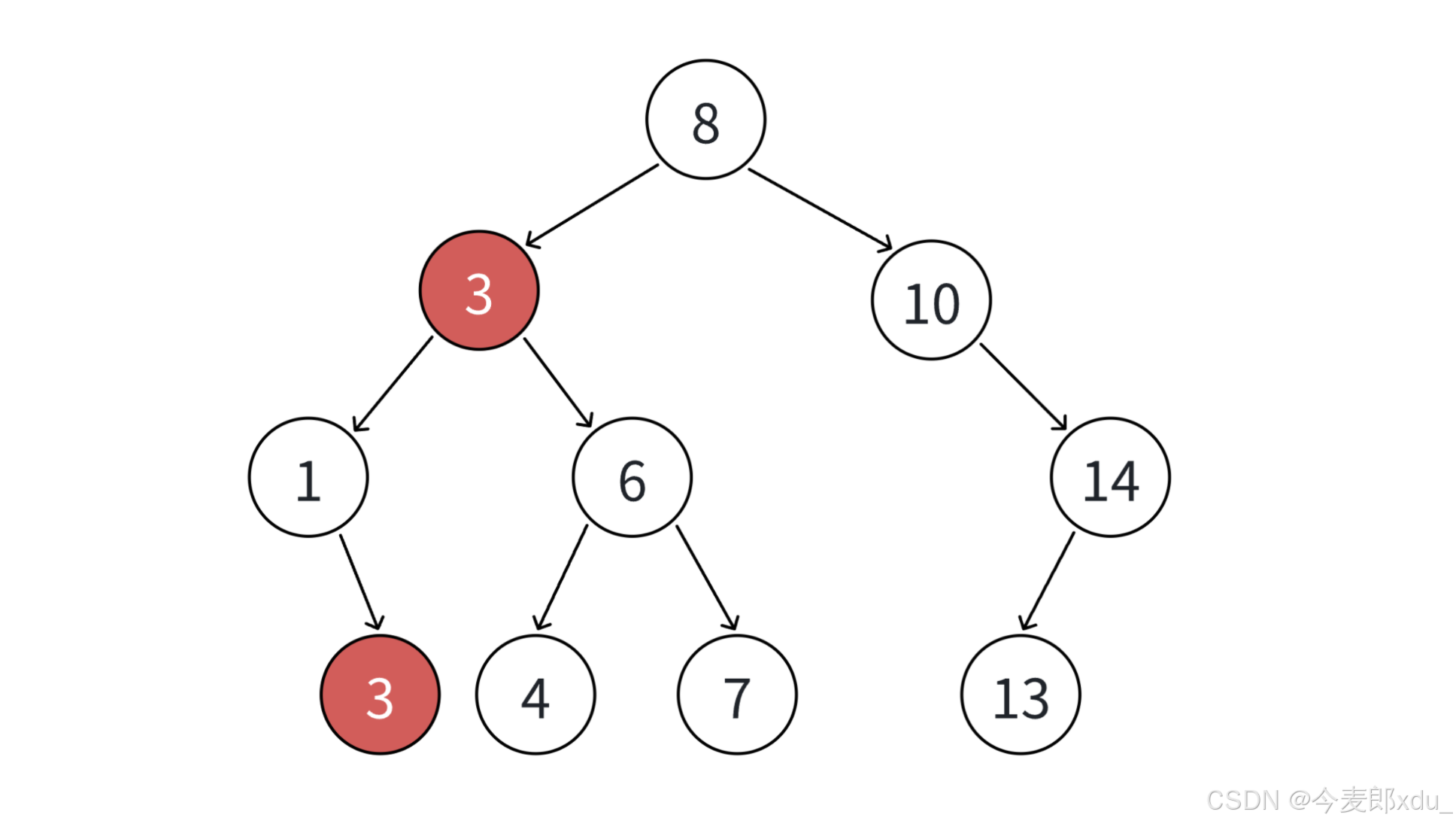
}- 若支持插入相等 的值,意味着如果有多个 x x x 存在时,一般要求查找中序的第一个 x x x。如下图,查找 3 3 3,要找到 1 1 1 的右孩子的那个 3 3 3 返回。
3. 删除操作
由于二叉搜索树的删除操作 需要先进行查找操作,因此最坏时间复杂度 也为 O ( N ) O(N) O(N)。(有序数组)
首先查找元素是否在二叉搜索树中 ,如果不存在,则返回 f a l s e false false。
cpp
node* parent = nullptr;
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
// 找到了,删除cur结点
return true;
}
}
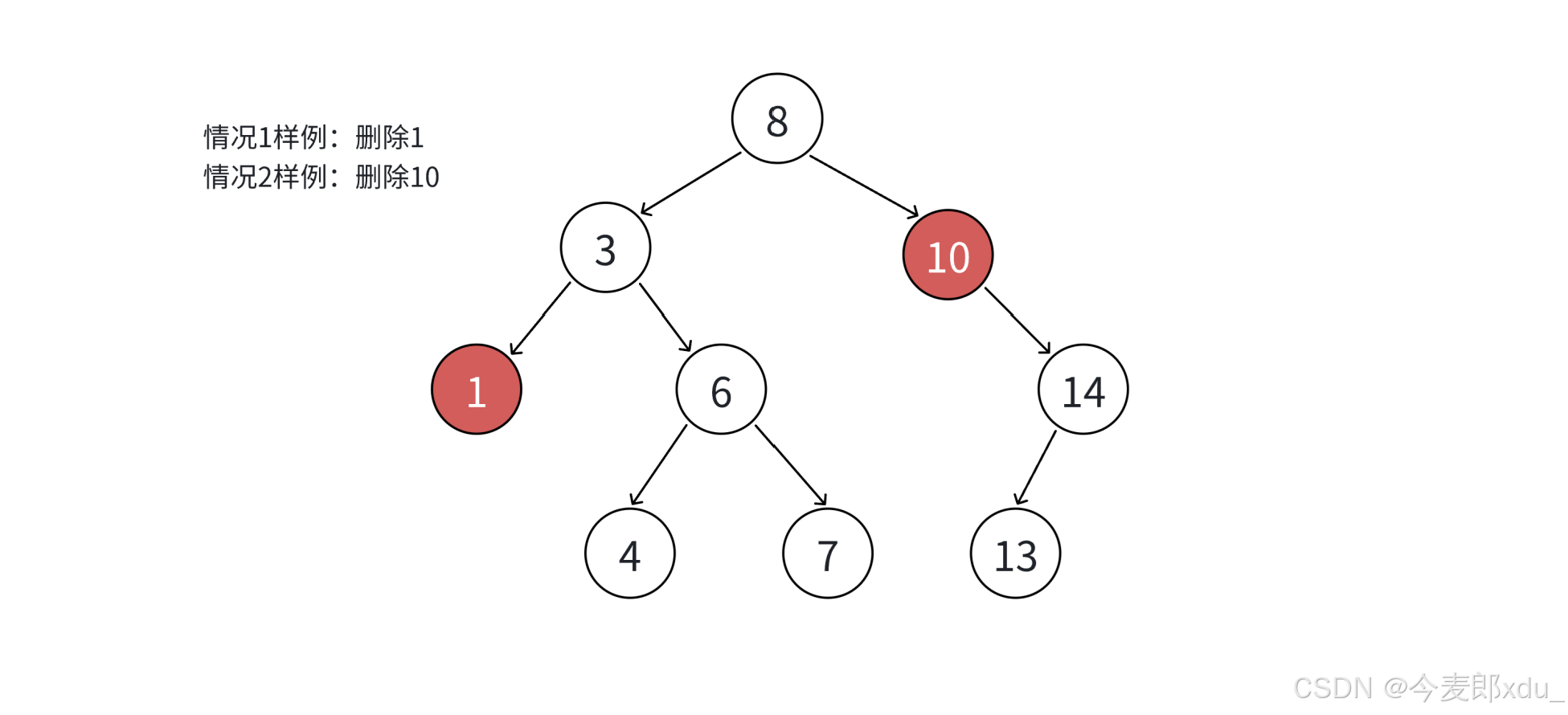
return false;如果查找元素存在 则分以下四种情况分别处理:(假设要删除的结点为 N N N)
-
要删除结点 N N N 左右孩子均为空 (0 0 0 个孩子);
-
要删除的结点 N N N 左孩子为空 ,右孩子结点不为空(1 1 1 个孩子):
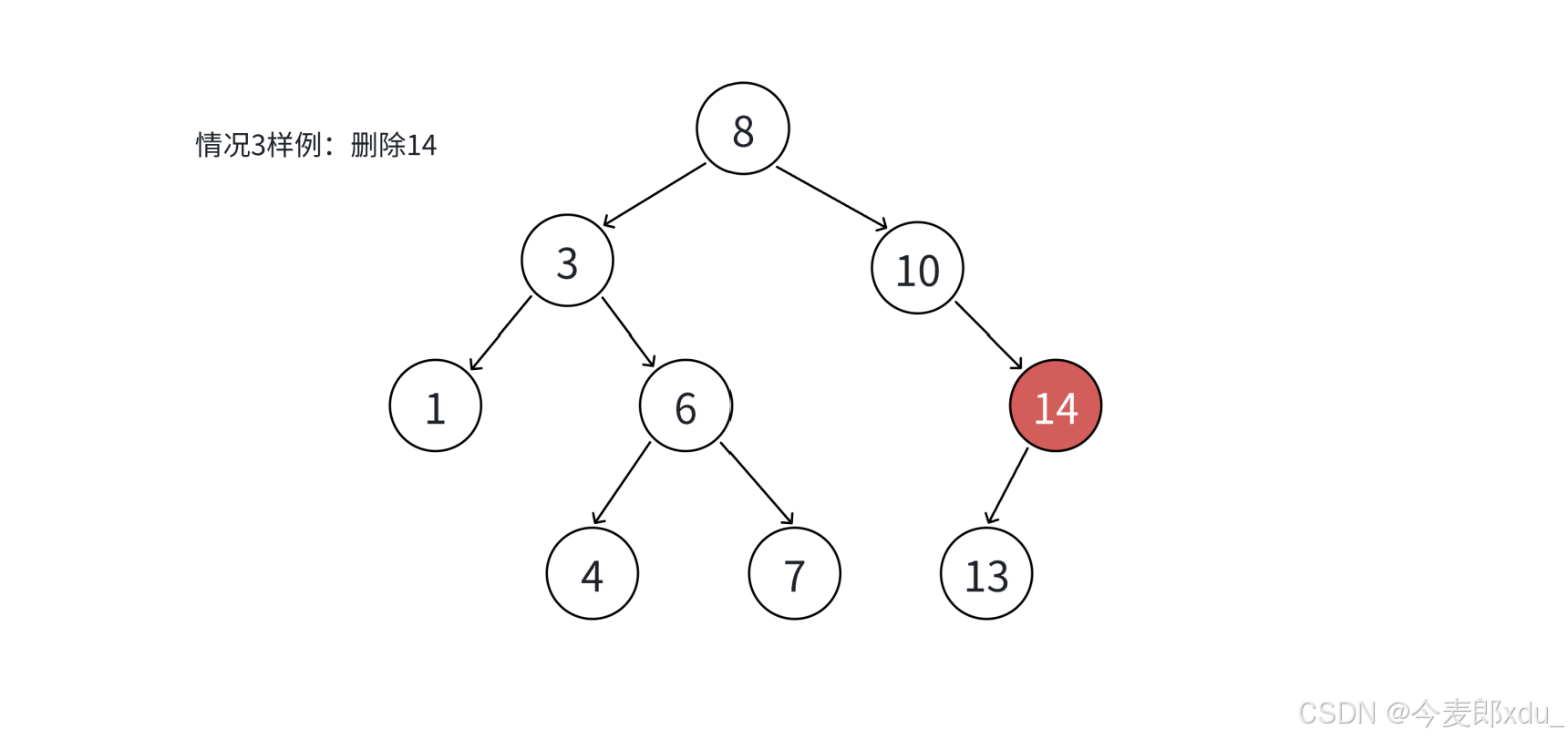
- 要删除的结点 N N N 右孩子为空 ,左孩子结点不为空(1 1 1 个孩子):
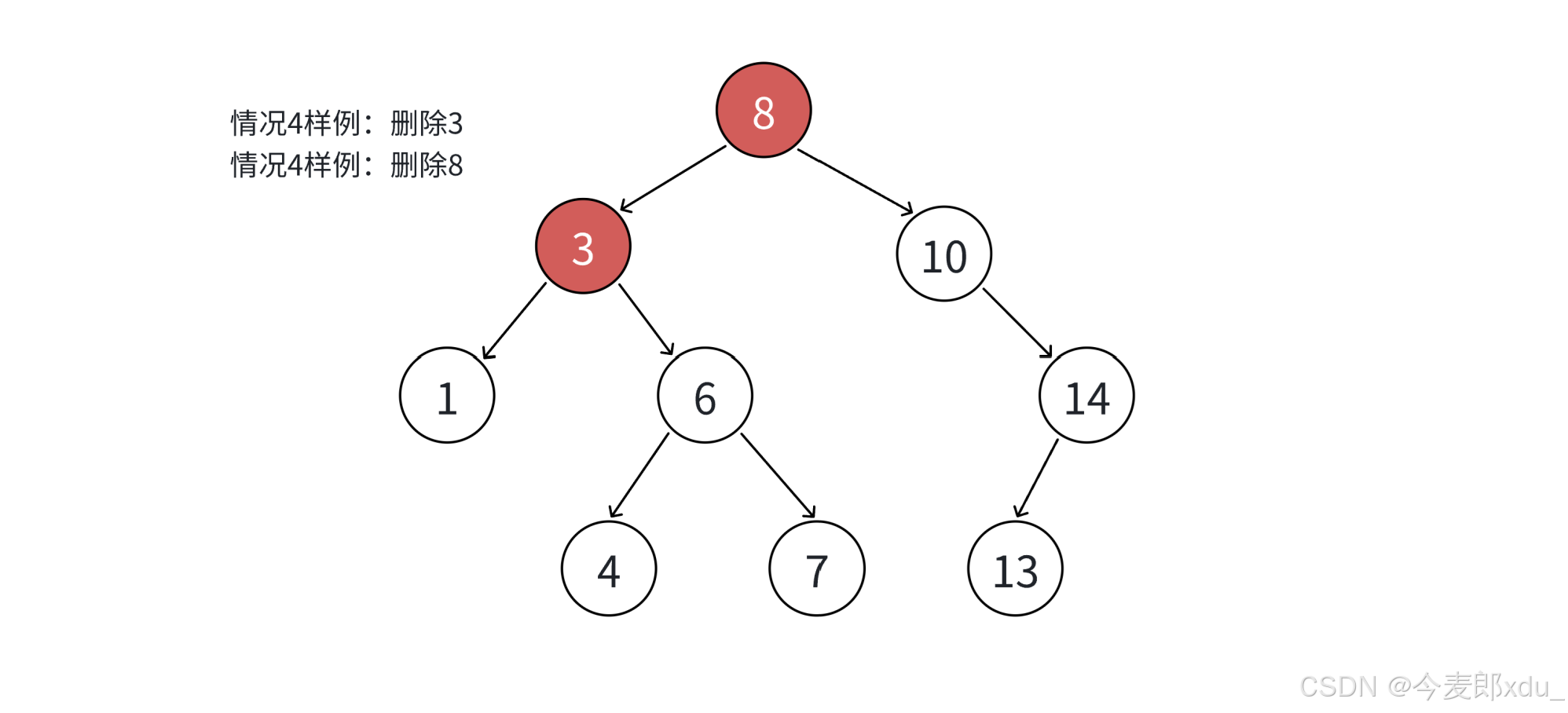
- 要删除的结点 N N N 左右孩子结点均不为空 (2 2 2 个孩子):
对应以上四种情况的解决方案:
-
把 N N N 结点的父亲对应孩子指针指向空,直接删除 N N N 结点。(情况 1 1 1 可以当成 2 2 2 或者 3 3 3 处理,效果是一样的,这里当作情况 2 2 2 来处理)
-
把 N N N 结点的父亲对应孩子指针指向 N N N 的右孩子,直接删除 N N N 结点。
cpp
// 1.左为空(都为空也被包含在内)
if (cur->_left == nullptr)
{
if (cur == _root) // parent == nullptr
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}- 把 N N N 结点的父亲对应孩子指针指向 N N N 的左孩子,直接删除 N N N 结点。
cpp
// 2.右为空
else if (cur->_right == nullptr)
{
if (cur == _root) // parent == nullptr
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}- 无法直接删除 N N N 结点,因为 N N N 的两个孩子无处安放,只能用替换法 删除。找 N N N 左子树的值最大结点 R R R(最右结点)或者 N N N 右子树的值最小结点 R R R(最左结点)替代 N N N,因为这两个结点中任意一个,放到 N N N 的位置,都满足二叉搜索树的规则。替代 N N N 的意思就是 N N N 和 R R R 的两个结点的值交换,转而变成删除 R R R 结点, R R R 结点符合情况 2 2 2 或情况 3 3 3,可以直接删除。
注意 :二叉搜索树有一个性质,最小结点就是最左结点,最大结点就是最右结点。
cpp
// 3.左右都不为空
else
{
node* replaceParent = cur;
node* replace = cur->_left; // 左子树的最大结点(最右结点)
while (replace->_right)
{
replaceParent = replace;
replace = replace->_right;
}
cur->_key = replace->_key;
if (replaceParent->_right == replace) // 进了循环
{
replaceParent->_right = replace->_left;
}
else // 没进循环
{
replaceParent->_left = replace->_left;
}
delete replace;
}三、二叉搜索树的实现
由于这个数据结构是用 C C C++ 代码来模拟实现的,因此采用了模板来定义的二叉搜索树类,所以不能将声明和定义分离,因此这里分为了两个文件: B i n a r y S e a r c h T r e e . h BinarySearchTree.h BinarySearchTree.h 来模拟实现并封装一个二叉搜索树的模板类 , t e s t . c p p test.cpp test.cpp 用来测试。
原理部分上一章已经交代清楚了,这里给出完整代码:
- B i n a r y S e a r c h T r e e . h BinarySearchTree.h BinarySearchTree.h:
cpp
#pragma once
#include<iostream>
using namespace std;
namespace key
{
template<class K>
struct BSTNode
{
K _key;
BSTNode<K>* _left;
BSTNode<K>* _right;
BSTNode(const K& key)
: _key(key)
, _left(nullptr)
, _right(nullptr)
{}
};
template<class K>
class BSTree
{
using node = BSTNode<K>;
public:
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new node(key);
return true;
}
node* parent = nullptr;
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}
cur = new node(key);
if (key < parent->_key)
{
parent->_left = cur;
}
else
{
parent->_right = cur;
}
return true;
}
bool find(const K& key)
{
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
cur = cur->_left;
}
else if (key > cur->_key)
{
cur = cur->_right;
}
else
{
return true;
}
}
return false;
}
bool erase(const K& key)
{
node* parent = nullptr;
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
// 1.左为空(都为空也被包含在内)
if (cur->_left == nullptr)
{
if (cur == _root) // parent == nullptr
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
// 2.右为空
else if (cur->_right == nullptr)
{
if (cur == _root) // parent == nullptr
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
// 3.左右都不为空
else
{
node* replaceParent = cur;
node* replace = cur->_left; // 左子树的最大结点(最右结点)
while (replace->_right)
{
replaceParent = replace;
replace = replace->_right;
}
cur->_key = replace->_key;
if (replaceParent->_right == replace) // 进了循环
{
replaceParent->_right = replace->_left;
}
else // 没进循环
{
replaceParent->_left = replace->_left;
}
delete replace;
}
return true;
}
}
return false;
}
void inorder()
{
_inorder(_root);
cout << endl;
}
private:
void _inorder(node* _root)
{
if (_root == nullptr)
{
return;
}
_inorder(_root->_left);
cout << _root->_key << " ";
_inorder(_root->_right);
}
node* _root = nullptr;
};
}- t e s t . c p p test.cpp test.cpp:
cpp
#include"BinarySearchTree.h"
namespace key
{
void test()
{
int a[] = { 8, 9, 5, 4, 1, 3, 2, 7, 6 };
BSTree<int> bst;
for (int i = 0; i < 9; i++)
{
bst.insert(a[i]);
bst.inorder();
}
for (int i = 8; i >=0 ; i--)
{
bst.erase(a[i]);
bst.inorder();
}
for (int i = 0; i <= 9; i++)
{
bst.find(i) == true ? cout << i << " find" << endl : cout << i << " no find" << endl;
}
}
}
int main()
{
key::test();
return 0;
}四、二叉搜索树的 key 和 key/value 搜索
1. key 搜索
只有 k e y key key 作为关键码,结构中只需要存储 k e y key key 即可,关键码即为需要搜索到的值 ,搜索场景只需要判断 k e y key key 在不在。 k e y key key 的搜索场景实现的二叉树搜索树支持增 / / /删 / / /查,但是不支持修改,修改 k e y key key 就破坏搜索树的结构了。
2. key/value 搜索
每一个关键码 k e y key key,都有与之对应的值 v a l u e value value , v a l u e value value 可以任意类型对象。树的结构中(结点)除了需要存储 k e y key key 还要存储对应的 v a l u e value value,增 / / /删 / / /查还是以 k e y key key 为关键字走二叉搜索树的规则进行比较,可以快速查找到 k e y key key 对应的 v a l u e value value。 k e y / v a l u e key/value key/value 的搜索场景实现的二叉树搜索树支持修改,但是不支持修改 k e y key key,修改 k e y key key 就破坏搜索树的性质了,可以修改 v a l u e value value。
3. key/value 二叉搜索树的实现
k e y / v a l u e key/value key/value 二叉搜索树本质上还是通过关键码 k e y key key 来进行增 / / /删 / / /查等操作,只是需要多记录每一个 k e y key key 所对应的值 v a l u e value value,形成一种映射关系,所以只需要在之前的 k e y key key 搜索树上稍作修改即可。
cpp
namespace key_value
{
template<class K, class V>
struct BSTNode
{
K _key;
V _value;
BSTNode<K, V>* _left;
BSTNode<K, V>* _right;
BSTNode(const K& key, const V& value)
: _key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{}
};
template<class K, class V>
class BSTree
{
using node = BSTNode<K, V>;
public:
bool insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new node(key, value);
return true;
}
node* parent = nullptr;
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}
cur = new node(key, value);
if (key < parent->_key)
{
parent->_left = cur;
}
else
{
parent->_right = cur;
}
return true;
}
node* find(const K& key)
{
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
cur = cur->_left;
}
else if (key > cur->_key)
{
cur = cur->_right;
}
else
{
return cur;
}
}
return nullptr;
}
bool erase(const K& key)
{
node* parent = nullptr;
node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
// 1.左为空(都为空也被包含在内)
if (cur->_left == nullptr)
{
if (cur == _root) // parent == nullptr
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
// 2.右为空
else if (cur->_right == nullptr)
{
if (cur == _root) // parent == nullptr
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
// 3.左右都不为空
else
{
node* replaceParent = cur;
node* replace = cur->_left; // 左子树的最大结点(最右结点)
while (replace->_right)
{
replaceParent = replace;
replace = replace->_right;
}
cur->_key = replace->_key;
if (replaceParent->_right == replace) // 进了循环
{
replaceParent->_right = replace->_left;
}
else // 没进循环
{
replaceParent->_left = replace->_left;
}
delete replace;
}
return true;
}
}
return false;
}
void inorder()
{
_inorder(_root);
cout << endl;
}
private:
void _inorder(node* _root)
{
if (_root == nullptr)
{
return;
}
_inorder(_root->_left);
cout << _root->_key << ":" << _root->_value << " ";
_inorder(_root->_right);
}
node* _root = nullptr;
};
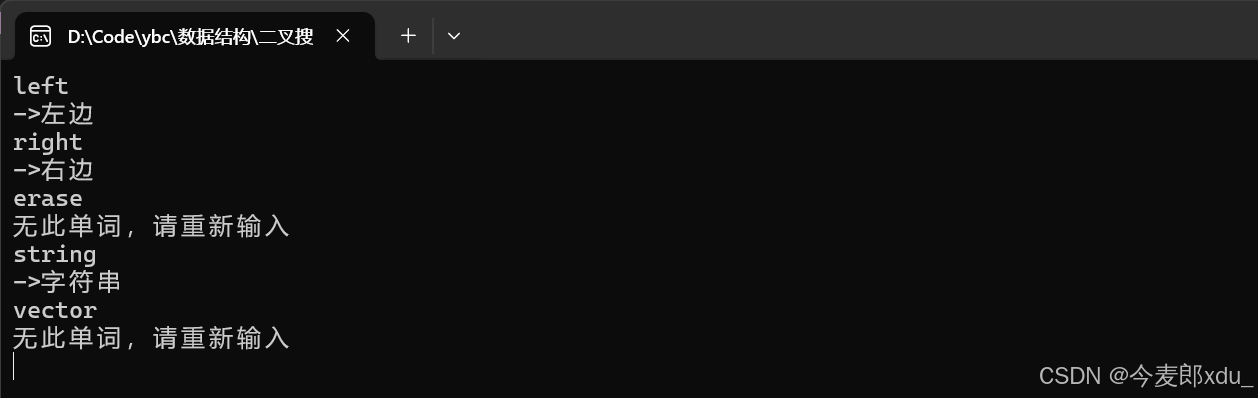
}测试应用 1 1 1(简易中英字典):
输入(英文,中文 )的映射关系,以英文为依据( k e y key key),来查找对应中文( v a l u e value value)的值:
cpp
void test1()
{
BSTree<string, string> dict;
dict.insert("left", "左边");
dict.insert("right", "右边");
dict.insert("insert", "插入");
dict.insert("string", "字符串");
string str;
while (cin >> str)
{
auto ret = dict.find(str);
if (ret)
{
cout << "->" << ret->_value << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
}
测试应用 2 2 2(统计字符出现次数):
先查找水果在不在搜索树中:
-
不在 :说明水果第一次出现,则插入 < < < 水果 , 1 > 1> 1>
-
在 :则查找到的结点中水果对应的次数 + 1 +1 +1
cpp
void test2()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
BSTree<string, int> countTree;
for (const auto& str : arr)
{
auto ret = countTree.find(str);
if (ret == nullptr)
{
countTree.insert(str, 1);
}
else
{
ret->_value++;
}
}
countTree.inorder();
}
总结
本文先是对二叉搜索树进行了一个基本介绍:其作为一种经典的数据结构,既有链表的快速插入与删除操作的特点,又有数组快速查找的优势,所以应用十分广泛,例如在文件系统 和数据库系统 一般会采用这种数据结构进行高效率的排序与检索操作;
然后,介绍并实现了二叉搜索树的三大基本操作:增删查( k e y key key 不能修改,修改就无意义了);
最后,又提到了二叉搜索树的两个应用场景,其中,在 C C C++ S T L STL STL 标准库中, s e t set set 的容器的底层结构就是 k e y key key 值查找 ,而 m a p map map 容器的底层结构是 k e y / v a l u e key/value key/value 键值对查找。