目录
Flink的安装模式
(1)Local模式: 所有Flink 组件(JobManager、TaskManager)都会在同一个 JVM 进程中运行,用于本地开发调试。
(2)Standalone Session模式:独立集群部署,需预先启动Flink进程,测试环境或小规模生产场景。
(3)Yarn模式:基于Hadoop YARN资源管理器,支持动态资源分配和自动容错,适合与Hadoop生态整合(如HDFS、YARN)的大规模生产环境。提供三种子模式:
- **会话模式(Session Mode)**:创建并长期保持一个JobManager,当需要有作业提交,则动态创建TaskManager,作业完成回收TaskManager资源,多个作业共享一个JobManager集群资源。
- **单作业模式(Per-Job Mode)**:每个作业单独启动一个集群,按作业隔离资源,避免资源竞争,作业完成后回收集群资源,应用代码在客户端节点运行。
- **应用模式(Application Mode)**:与单作业模式类似,也是一个作业单独启动一个集群,作业完成后回收集群资源,但将应用代码提交至JobManager执行,减少客户端负载。
(4)K8S模式:基于容器化技术,支持自动扩缩容和弹性伸缩,每个JobManager/TaskManager以Pod形式运行,资源隔离性强,适合云原生环境,被认为是未来主流部署方式。
下载Flink
下载Flink,并上传到Linux /opt/software目录
# 国内下载
https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.17.2/flink-1.17.2-bin-scala_2.12.tgz
# 或者官网下载
https://archive.apache.org/dist/flink/flink-1.17.2/flink-1.17.2-bin-scala_2.12.tgz安装Local模式
在node2机器上进行,解压后无需任何配置即可直接使用。
前提条件
- 有1台Linux机器,且安装好jdk,这里是jdk8,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式-安装Java
解压安装包
解压并重命名
[liang@node2 spark-yarn]$ cd /opt/software/
[liang@node2 software]$ ls | grep flink
flink-1.17.2-bin-scala_2.12.tgz
[liang@node2 software]$ tar -zxvf flink-1.17.2-bin-scala_2.12.tgz -C /opt/module
[liang@node2 software]$ cd /opt/module
[liang@node2 software]$ mv flink-1.17.2 flink-local启动集群
[liang@node2 software]$ cd /opt/module/flink-local
[liang@node2 flink-local]$ ls
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt
[liang@node2 flink-local]$ ls bin/
bash-java-utils.jar kubernetes-jobmanager.sh start-zookeeper-quorum.sh
config.sh kubernetes-session.sh stop-cluster.sh
find-flink-home.sh kubernetes-taskmanager.sh stop-zookeeper-quorum.sh
flink pyflink-shell.sh taskmanager.sh
flink-console.sh sql-client.sh yarn-session.sh
flink-daemon.sh sql-gateway.sh zookeeper.sh
historyserver.sh standalone-job.sh
jobmanager.sh start-cluster.sh
[liang@node2 flink-local]$ bin/start-cluster.sh查看进程
[liang@node2 flink-local]$ jps
7717 StandaloneSessionClusterEntrypoint
8006 TaskManagerRunner
8121 Jps提交作业
文件WordCount
$ bin/flink run examples/streaming/WordCount.jar输出过程
[liang@node2 flink-local]$ bin/flink run examples/streaming/WordCount.jar
Executing example with default input data.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID b4f0874e1e377c83fc830baf1767413a
Program execution finished
Job with JobID b4f0874e1e377c83fc830baf1767413a has finished.
Job Runtime: 886 ms查看结果
查看输出的WordCount结果的末尾10行数据
[liang@node2 flink-local]$ ls log/
flink-liang-client-node2.log
flink-liang-standalonesession-0-node2.log
flink-liang-standalonesession-0-node2.log.1
flink-liang-standalonesession-0-node2.out
flink-liang-taskexecutor-0-node2.log
flink-liang-taskexecutor-0-node2.out
[liang@node2 flink-local]$ tail log/flink-*-taskexecutor-*.out执行过程
[liang@node2 flink-local]$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)持续流WordCount
使用 SocketWindowWordCount 示例实时接收 Socket 输入
终端1:发送数据终端
$ nc -lk 9999 终端2:打开新的终端,提交作业
$ cd /opt/module/flink-local
$ bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9999在发送数据终端发送数据

查看结果
打开新的终端,命令行查看结果,每行计算一次结果
[liang@node2 ~]$ cd /opt/module/flink-local
[liang@node2 flink-local]$ tail -f log/flink-liang-taskexecutor-0-node2.out查看Web UI
local模式仅支持命令行查看,不支持浏览器访问。
[liang@node2 flink-local]$ curl localhost:8081
浏览器查看
node2:8081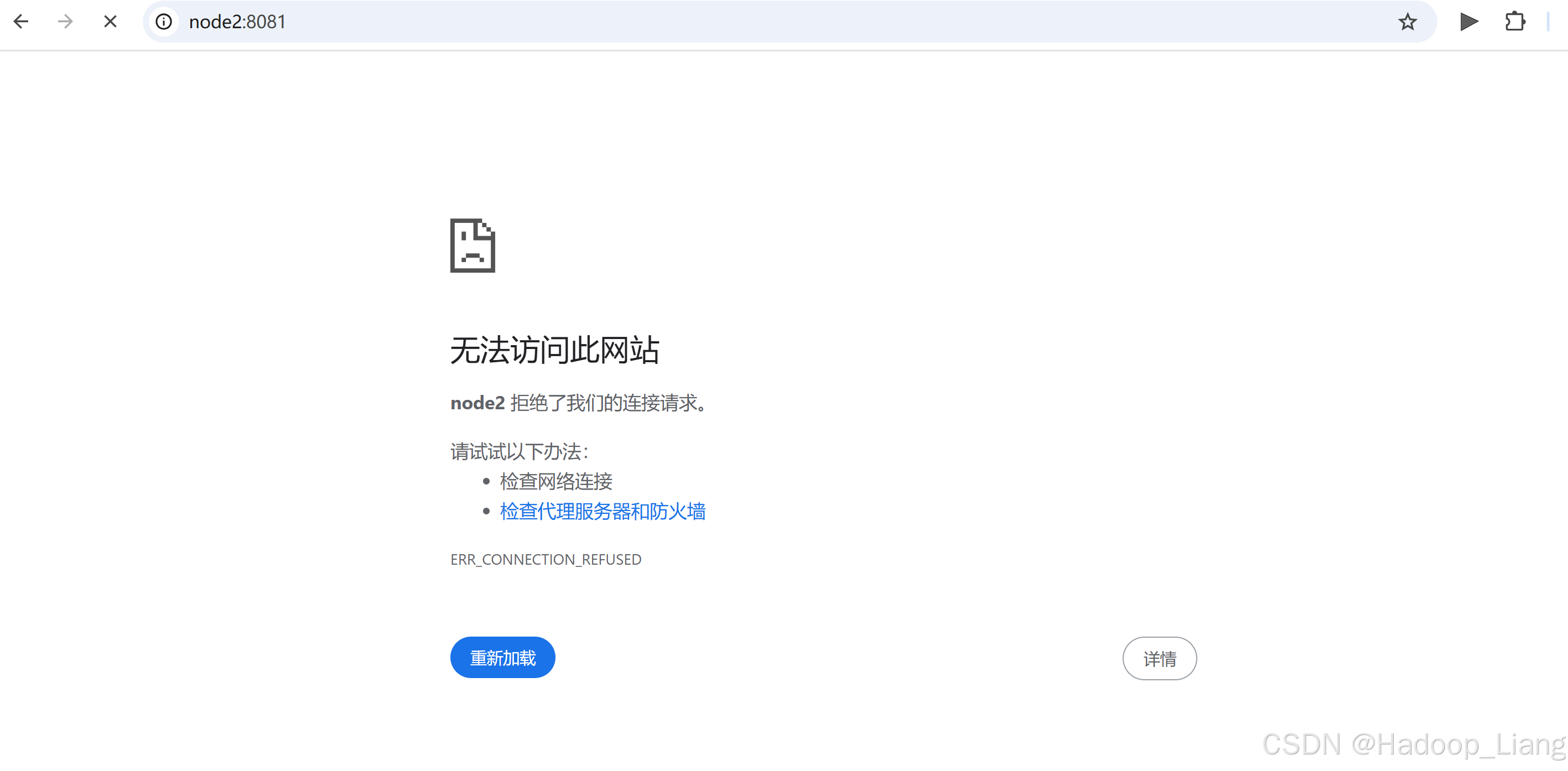
要能查看到Web UI还需要配置Flink。
配置flink-conf.yaml
[liang@node2 flink-local]$ cd conf
[liang@node2 conf]$ vim flink-conf.yaml找到相关配置项并修改,如下
jobmanager.rpc.address: node2
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node2
rest.address: node2
rest.bind-address: 0.0.0.0这样配置支持Web UI访问,也支持远程提交作业。
注意:配置flink-conf.yaml后,local模式就变成Flink伪分布了。
| 特性 | Local模式 | **伪分布模式(Standalone模式)** |
|---|---|---|
| 适用场景 | 单机本地快速测试,验证代码逻辑或简单性能 | 单机模拟集群环境,用于开发调试或学习多组件交互(如JobManager与TaskManager) |
| 资源管理 | 无需启动独立进程,由本地JVM线程模拟所有组件(JobManager + TaskManager) | 需启动独立进程:JobManager(主节点)和至少1个TaskManager(工作节点) |
| Web UI | 默认不启用Web界面 | 提供Web UI(默认端口8081),可监控任务状态、日志和资源配置 |
| 网络配置 | 仅本地回环地址(127.0.0.1),无法远程访问 | 可绑定真实IP地址(如0.0.0.0),支持远程提交作业和访问Web UI |
| 容错性 | 无高可用机制,进程崩溃则任务终止 | 支持高可用配置(需依赖ZooKeeper),但单机伪分布下通常不启用 |
重启集群
bash
[liang@node2 conf]$ cd ..
[liang@node2 flink-local]$ ls bin/
bash-java-utils.jar kubernetes-jobmanager.sh start-zookeeper-quorum.sh
config.sh kubernetes-session.sh stop-cluster.sh
find-flink-home.sh kubernetes-taskmanager.sh stop-zookeeper-quorum.sh
flink pyflink-shell.sh taskmanager.sh
flink-console.sh sql-client.sh yarn-session.sh
flink-daemon.sh sql-gateway.sh zookeeper.sh
historyserver.sh standalone-job.sh
jobmanager.sh start-cluster.sh
[liang@node2 flink-local]$ bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 8006) on host node2.
Stopping standalonesession daemon (pid: 7717) on host node2.
[liang@node2 flink-local]$
[liang@node2 flink-local]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node2.
Starting taskexecutor daemon on host node2.
[liang@node2 flink-local]$ jps
9220 StandaloneSessionClusterEntrypoint
9509 TaskManagerRunner
9595 Jps浏览器访问
node2:8081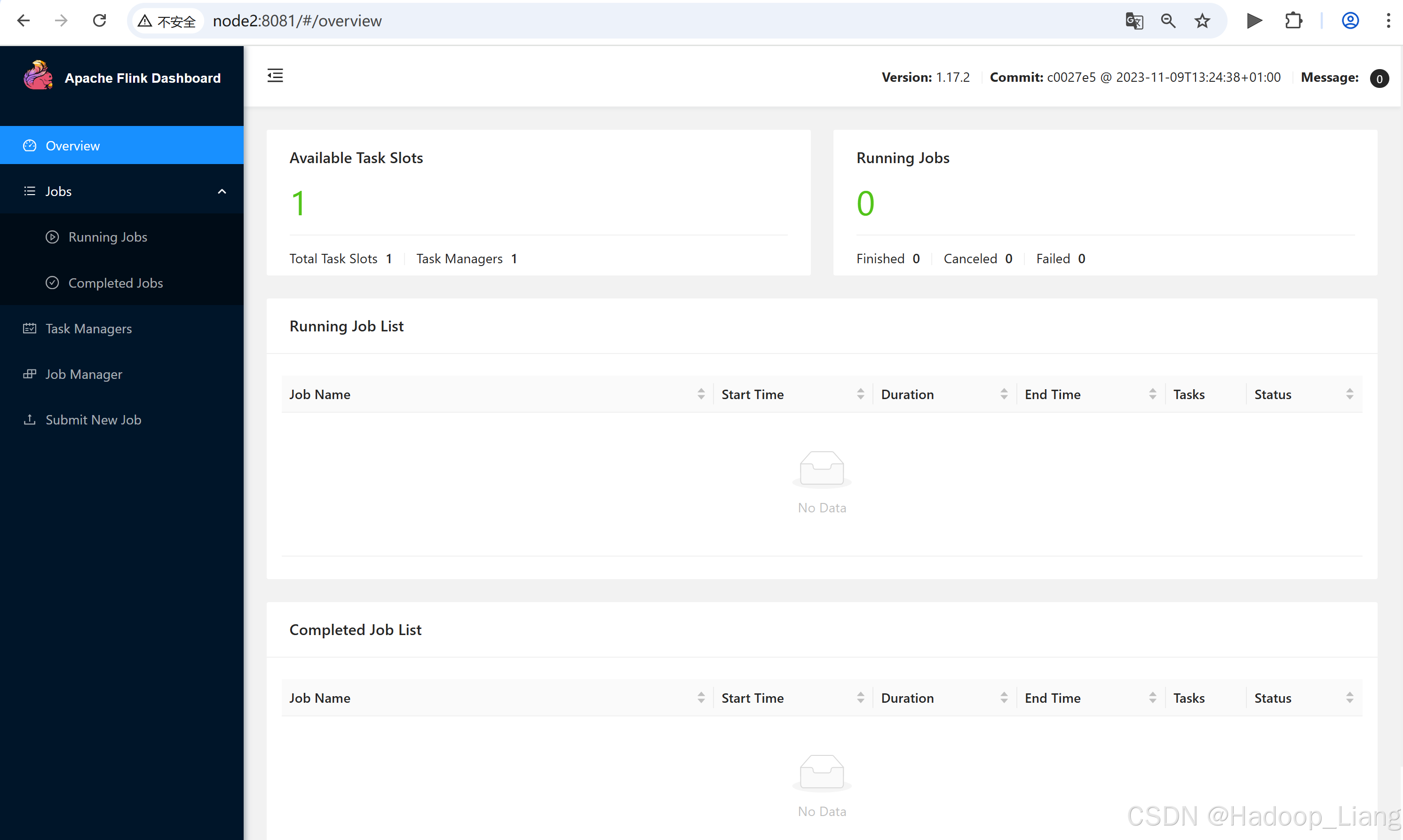
简单使用
文件的WordCount
测试提交WordCount作业
$ bin/flink run examples/streaming/WordCount.jar执行过程
[liang@node2 flink-local]$ bin/flink run examples/streaming/WordCount.jar
Executing example with default input data.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 3f939fb4b8d4c2dab4d47d7b5f4cc389
Program execution finished
Job with JobID 3f939fb4b8d4c2dab4d47d7b5f4cc389 has finished.
Job Runtime: 913 ms查看输出的WordCount结果的末尾10行数据
$ tail log/flink-*-taskexecutor-*.out执行过程
[liang@node2 flink-local]$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)查看Web UI
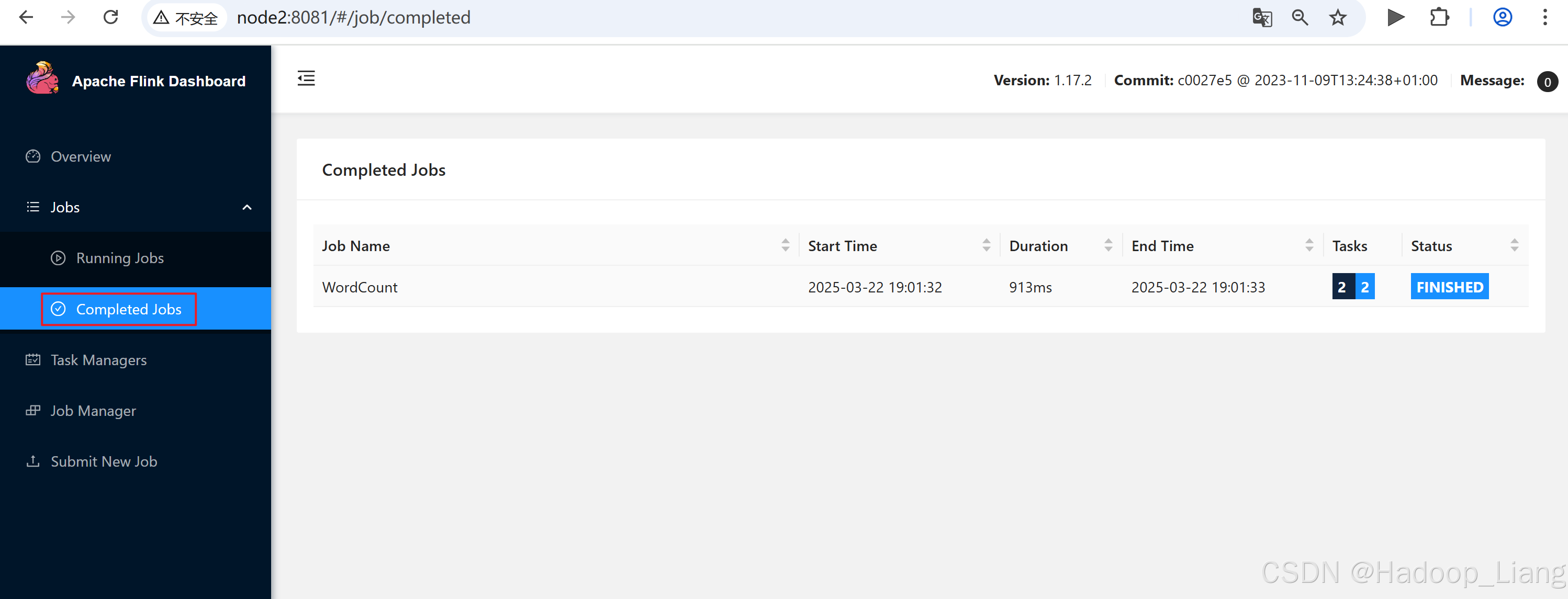
输入数据有限,所以计算会完成。
持续流WordCount
使用 SocketWindowWordCount 示例实时接收 Socket 输入
终端1:发送数据终端
$ nc -lk 9999 终端2:打开新的终端,提交作业
$ cd /opt/module/flink-local
$ bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9999在发送数据终端发送数据

提交作业终端

打开新的终端,命令行查看结果,每行计算一次结果
[liang@node2 ~]$ cd /opt/module/flink-local/
[liang@node2 flink-local]$ ls
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt
[liang@node2 flink-local]$ ls log/
flink-liang-client-node2.log flink-liang-taskexecutor-0-node2.log
flink-liang-standalonesession-0-node2.log flink-liang-taskexecutor-0-node2.log.1
flink-liang-standalonesession-0-node2.log.1 flink-liang-taskexecutor-0-node2.log.2
flink-liang-standalonesession-0-node2.log.2 flink-liang-taskexecutor-0-node2.out
flink-liang-standalonesession-0-node2.out
[liang@node2 flink-local]$ tail -f log/flink-liang-taskexecutor-0-node2.out
hello : 1
flink : 1
hello : 1
hadoop : 1
Web UI查看结果
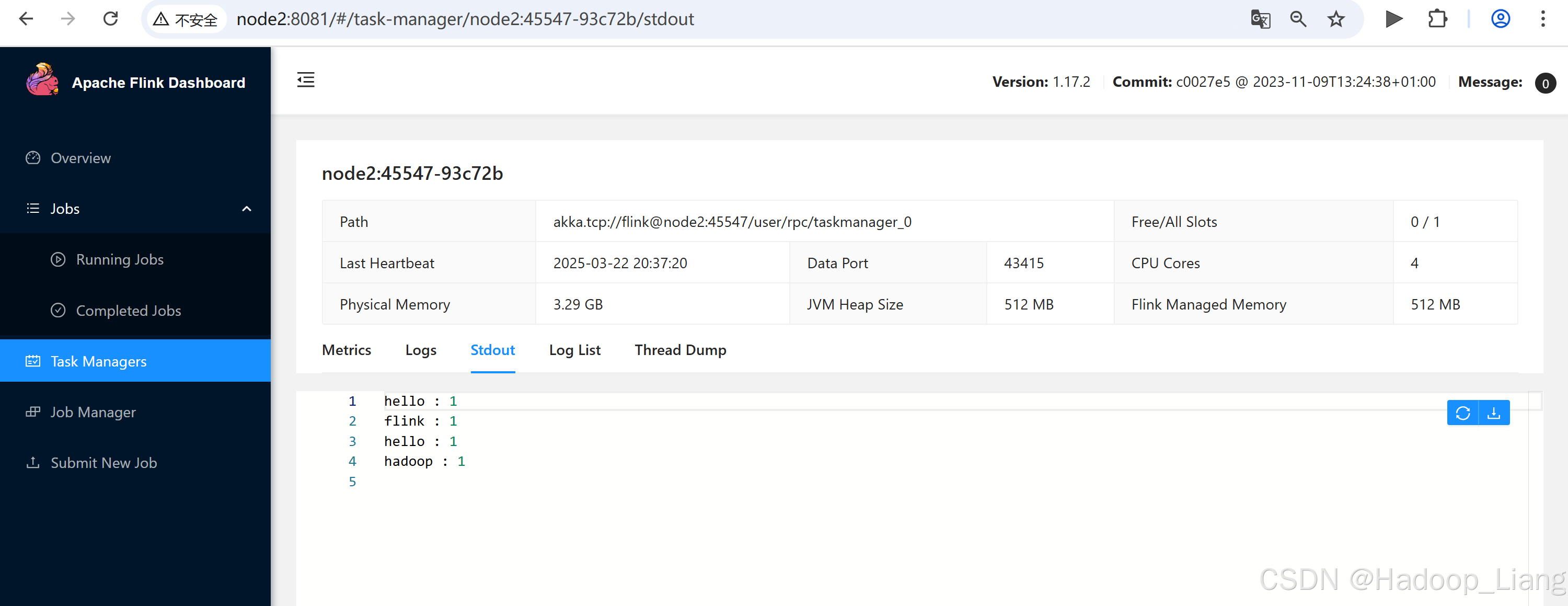
关闭集群
关闭集群
$ bin/stop-cluster.shjps查看进程
$ jps执行过程
[liang@node2 flink-local]$ bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 9509) on host node2.
Stopping standalonesession daemon (pid: 9220) on host node2.
[liang@node2 flink-local]$ jps
10579 JpsStandalone Session模式
安装Flink Standalone 完全分布集群
前提条件
有三台Linux机器
三台机器均安装好jdk,这里使用jdk8,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式-安装Java
Flink集群规划
| node2 | node3 | node4 |
|---|---|---|
| JobManager | ||
| TaskManager | TaskManager | TaskManager |
解压安装包
解压并重命名
[liang@node2 software]$ tar -zxvf flink-1.17.2-bin-scala_2.12.tgz -C /opt/module
[liang@node2 software]$ cd /opt/module
[liang@node2 module]$ mv flink-1.17.2 flink-standalone进入到解压后的目录,查看包含的文件
[liang@node2 module]$ cd flink-standalone
[liang@node2 flink-standalone]$ ls
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt配置flink
进入flink配置目录,查看配置文件
[liang@node2 ~]$ cd conf
[liang@node2 conf]$ ls
flink-conf.yaml log4j.properties logback-session.xml workers
log4j-cli.properties log4j-session.properties logback.xml zoo.cfg
log4j-console.properties logback-console.xml masters配置flink-conf.yaml
[liang@node2 conf]$ vim flink-conf.yaml找到相关配置项并修改,如下
jobmanager.rpc.address: node2
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node2
rest.address: node2
rest.bind-address: 0.0.0.0配置workers
[liang@node2 conf]$ vim workers把原有内容删除,添加内容如下:
node2
node3
node4配置masters
[liang@node2 conf]$ vim masters 修改后内容如下:
node2:8081分发到其他机器
分发安装目录
[liang@node2 conf]$ xsync /opt/module/flink-standalone修改node3和node4的配置
分别修改node3、node4机器的flink-conf.yaml文件,将taskmanager.host的值修改为所在机器的主机名。
node3机器
进入node3机器flink的配置目录
[liang@node3 ~]$ cd /opt/module/flink-standalone/conf/配置flinke-conf.yaml文件
[liang@node3 conf]$ vim flink-conf.yaml将taskmanager.host的值修改为node3
taskmanager.host: node3node4机器
进入node4机器flink的配置目录
[liang@node4 ~]$ cd /opt/module/flink-standalone/conf/配置flinke-conf.yaml文件
[liang@node4 conf]$ vim flink-conf.yaml将taskmanager.host的值修改为node4
taskmanager.host: node4启动flink集群
在node2机器,执行启动集群命令
[liang@node2 conf]$ cd ..
[liang@node2 flink-standalone]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node2.
Starting taskexecutor daemon on host node2.
Starting taskexecutor daemon on host node3.
Starting taskexecutor daemon on host node4.查看进程
jps查看进程
[liang@node2 flink-standalone]$ jpsall
=============== node2 ===============
10116 Jps
9557 StandaloneSessionClusterEntrypoint
9977 TaskManagerRunner
=============== node3 ===============
2342 TaskManagerRunner
2431 Jps
=============== node4 ===============
2340 TaskManagerRunner
2430 Jps注意:如果没有jpsall命令,就分别在node2、node3、node4执行jps命令
node2有StandaloneSessionClusterEntrypoint、TaskManagerRunner进程
node3有TaskManagerRunner进程
node4有TaskManagerRunner进程
看到如上进程,说明Flink Standalone集群配置成功。
Web UI
浏览器主机名:8081访问
node2:8081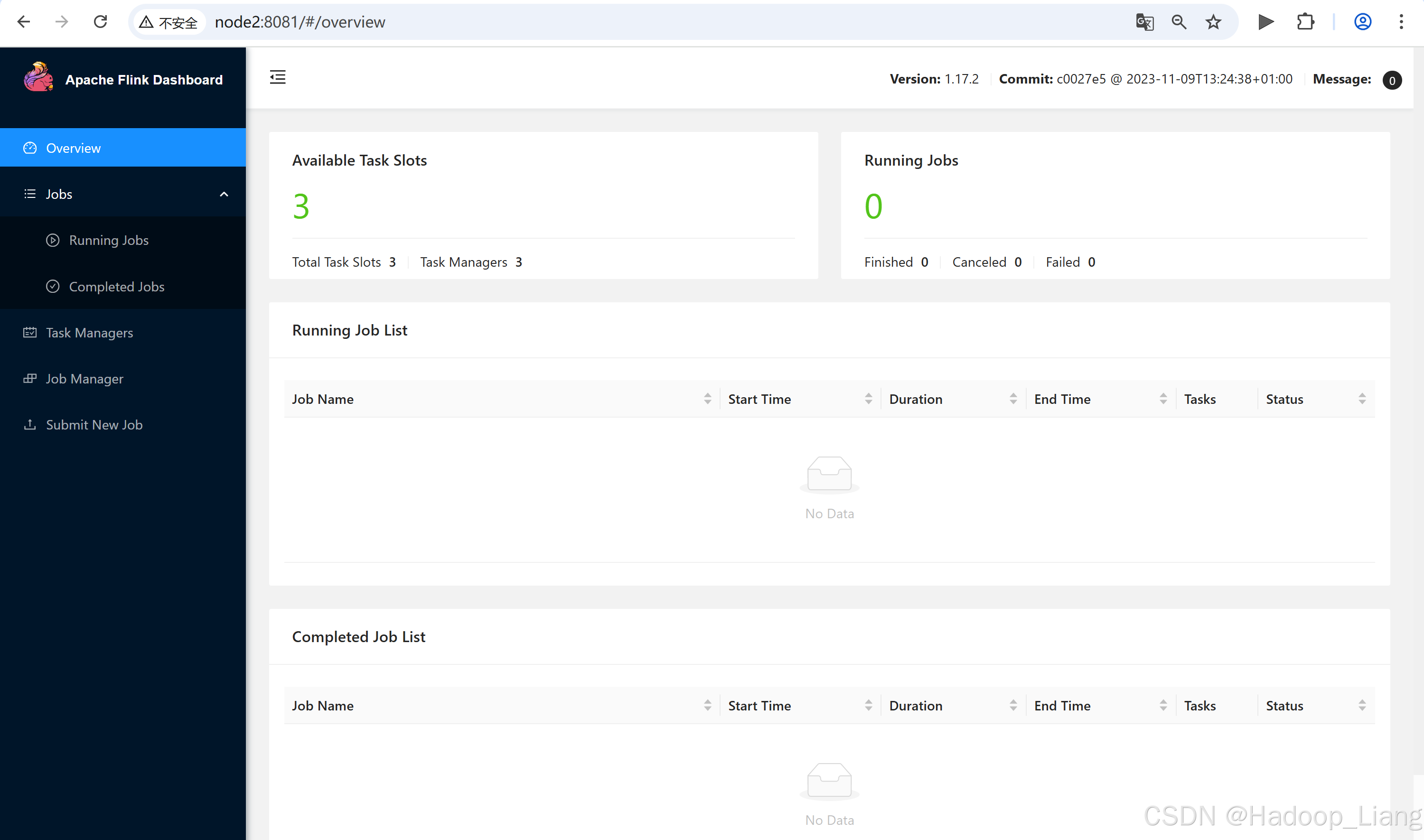
提交应用测试
文件WordCount
[liang@node2 flink-standalone]$ bin/flink run examples/streaming/WordCount.jar
Executing example with default input data.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID ee8f5d8b493be0ad1463a072b11c4586
Program execution finished
Job with JobID ee8f5d8b493be0ad1463a072b11c4586 has finished.
Job Runtime: 1080 ms查看结果有两种方式:
- 命令行查看
- Web UI查看
命令行查看结果
查看输出的wordcount结果的末尾10行数据
[liang@node2 flink-standalone]$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)Web UI查看作业结果
node2:8081查看作业
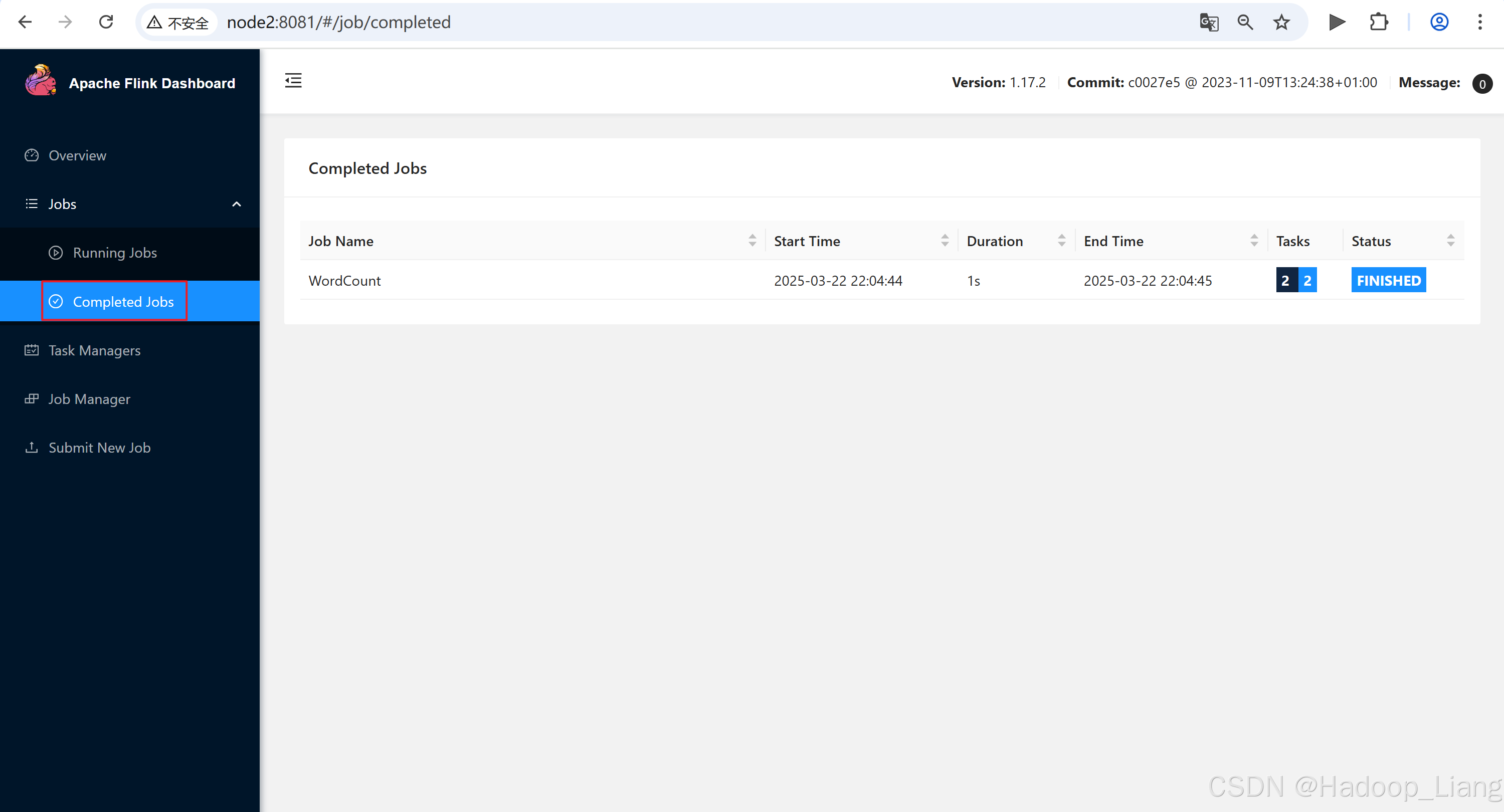
查看作业结果
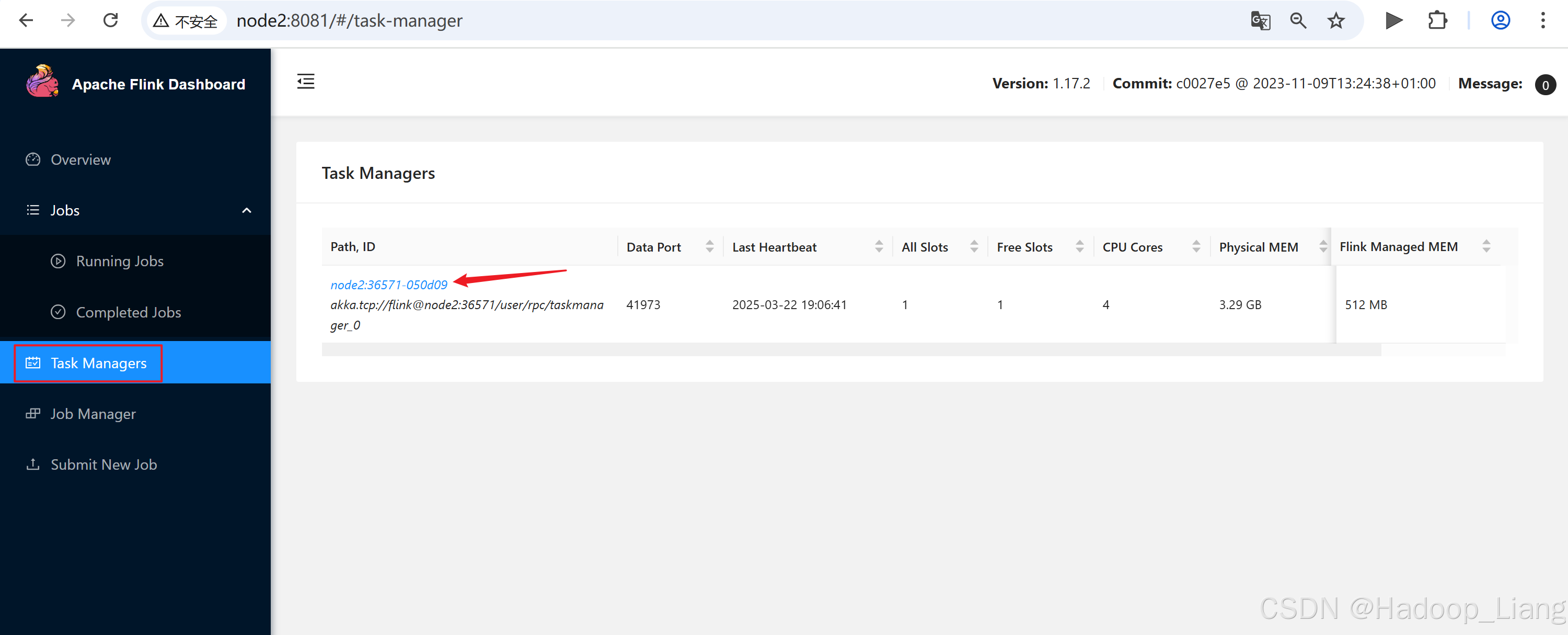
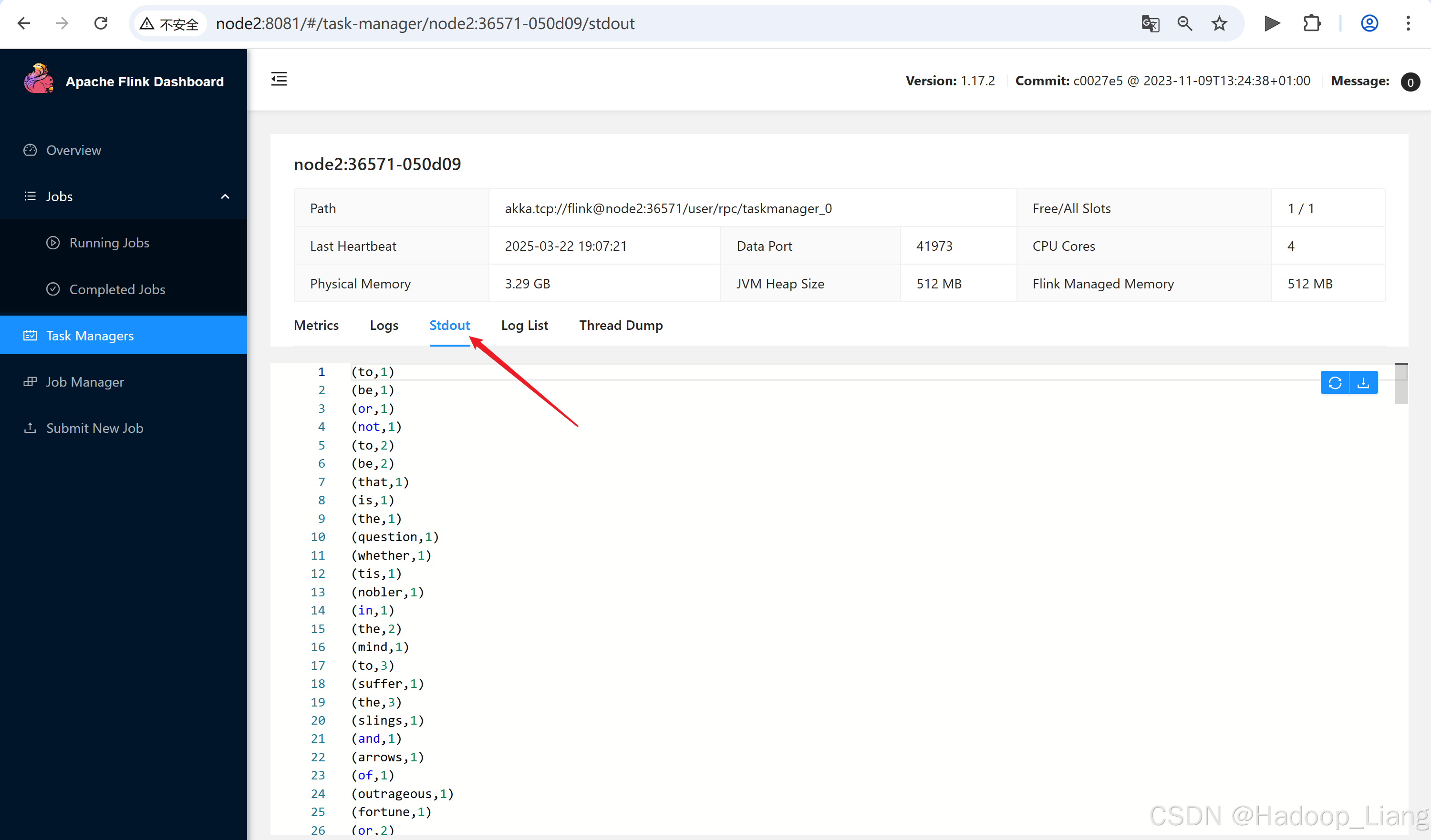
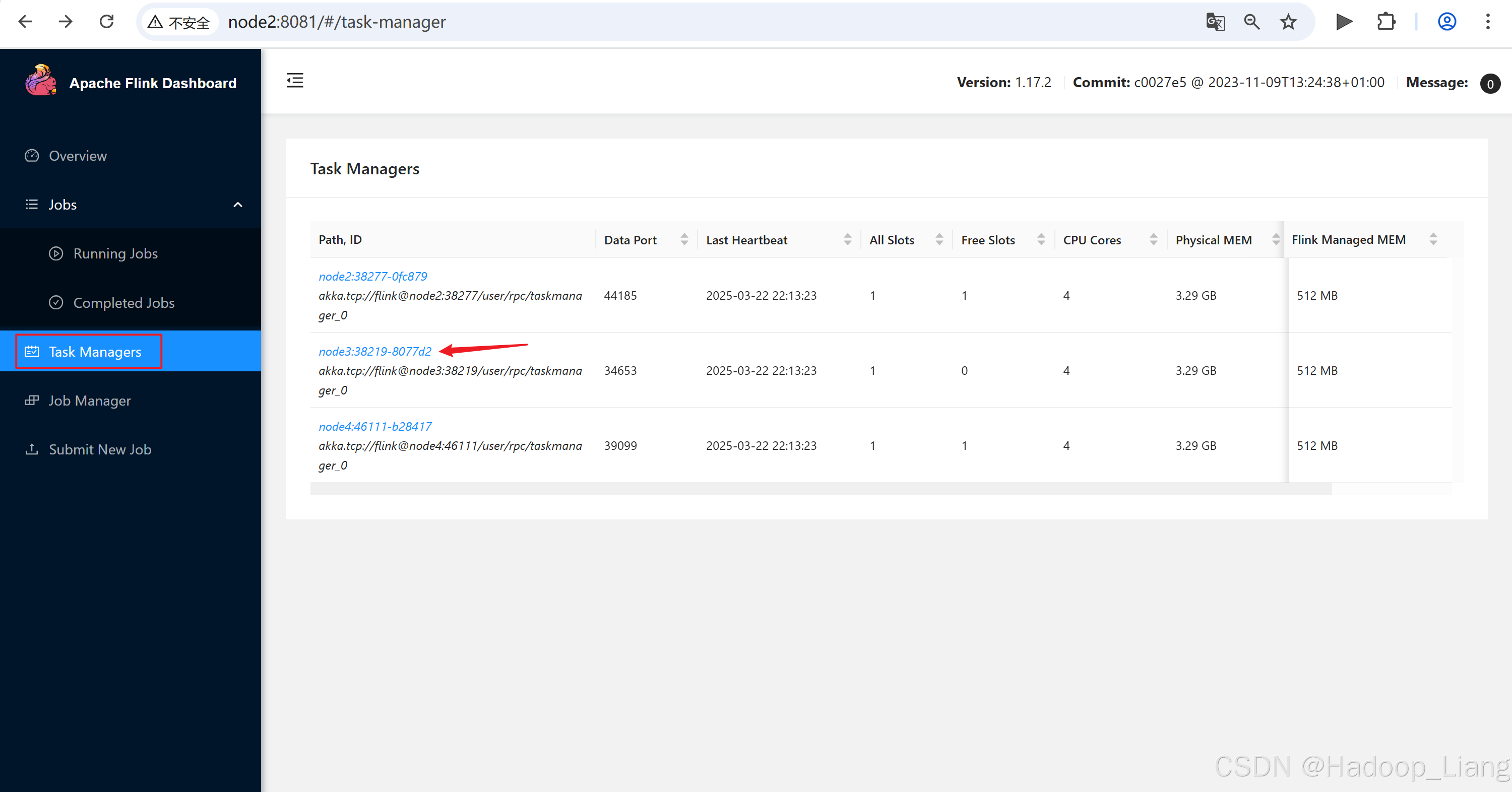
点击查看TaskManagers,点击其中一个TaskManager机器,点击Stdout能查看到作业结果

点击node2:38277-0fc879,点击Stdout
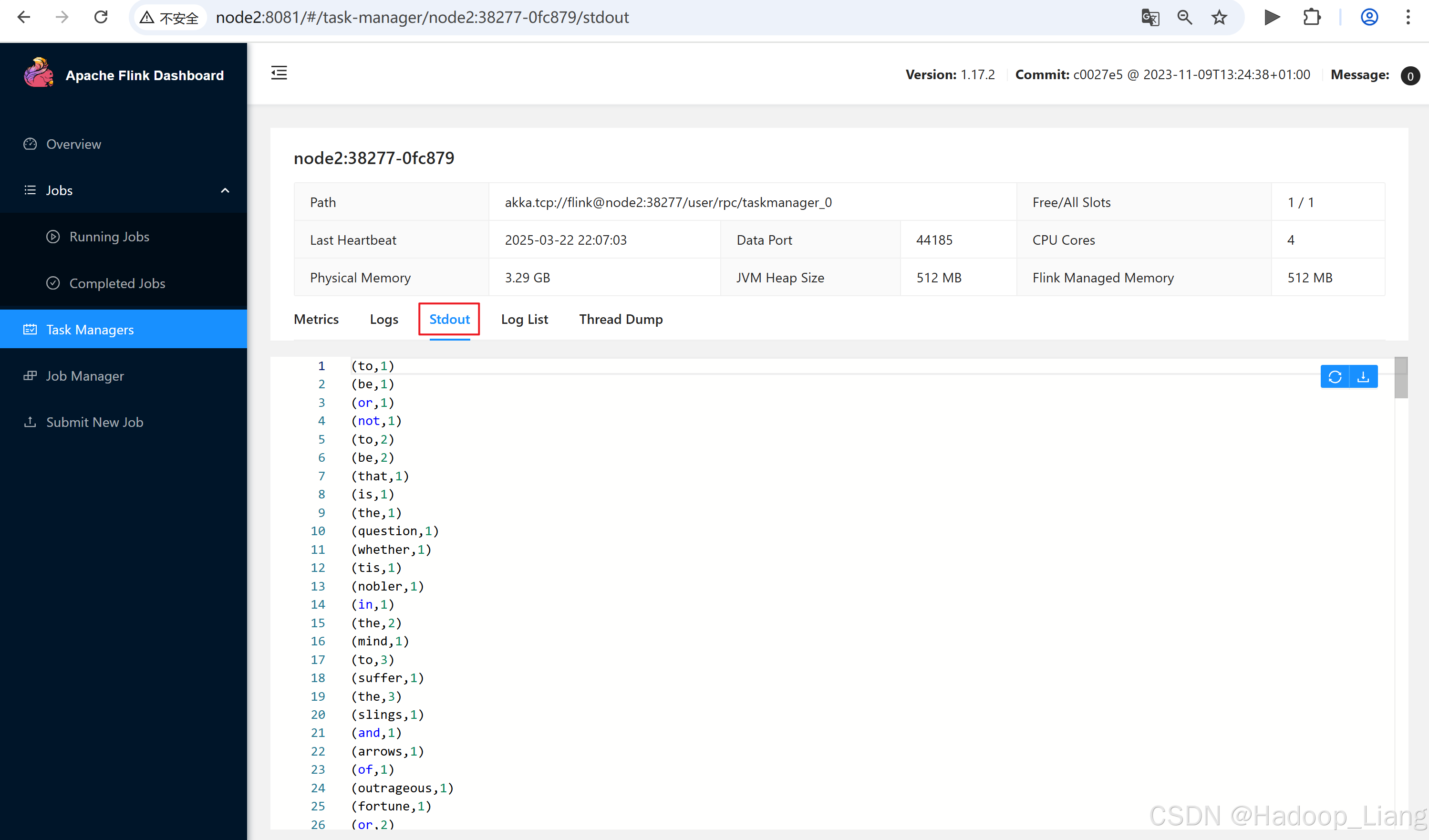
注意:如果node2查看不到,可以返回点击其他机器查看。
持续流WordCount
使用 SocketWindowWordCount 示例实时接收 Socket 输入
发送数据终端
$ nc -lk 9999 打开新的终端,提交作业
$ cd /opt/module/flink-standalone
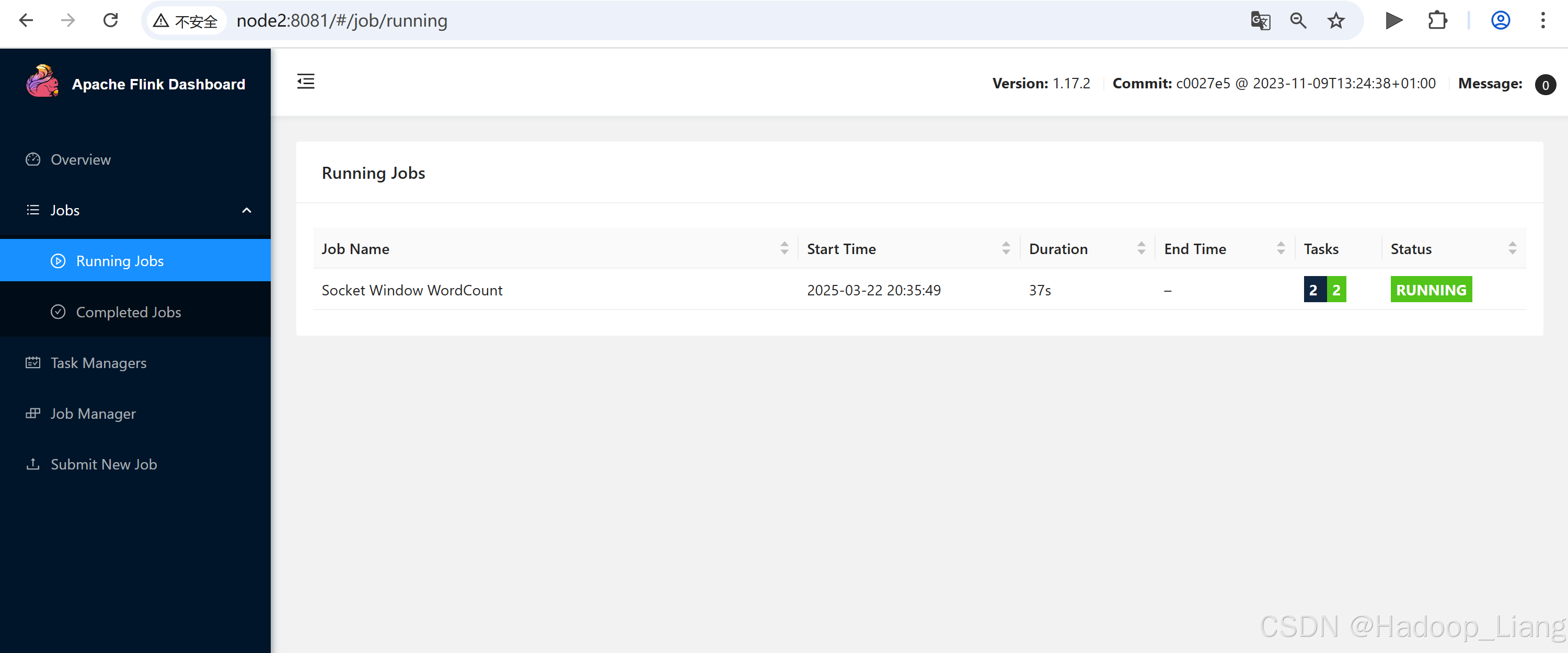
$ bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname node2 --port 9999在发送数据终端发送数据
hello flink standalone mode
hello world
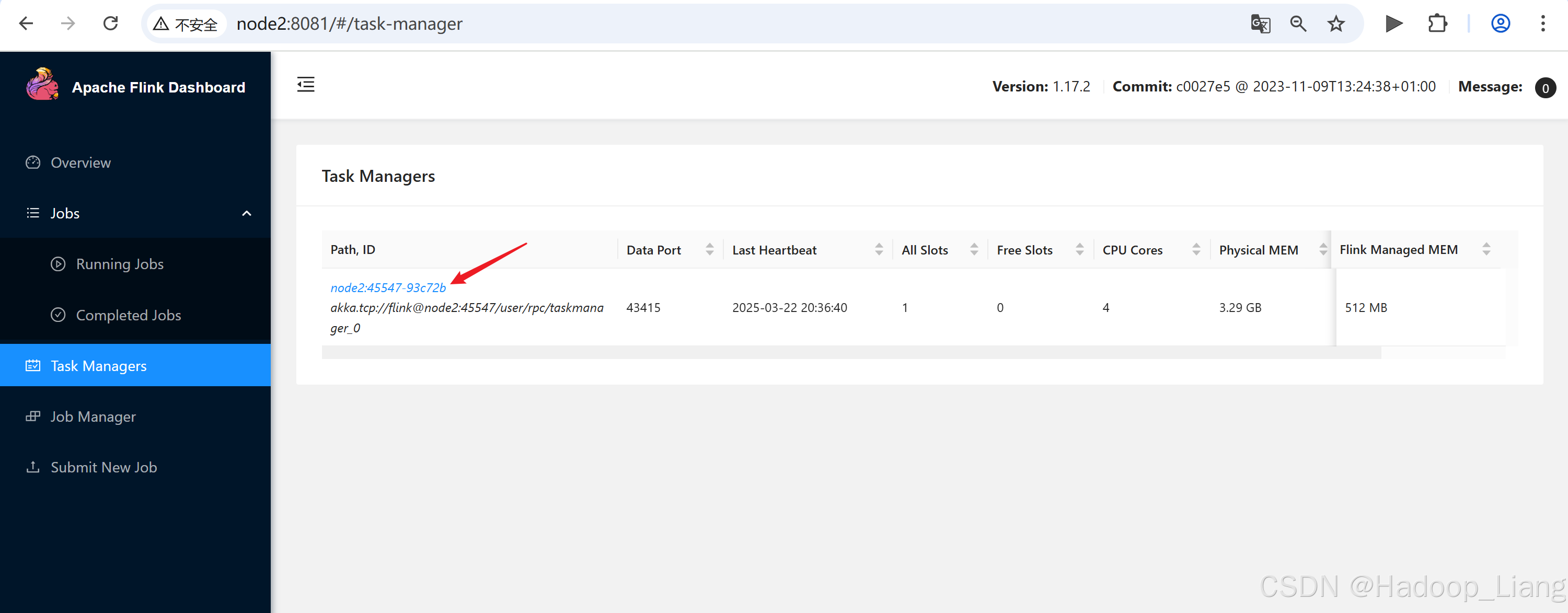
Web UI查看作业结果
查看作业

查看结果
点击node3:38219-8077d2,点击stdout
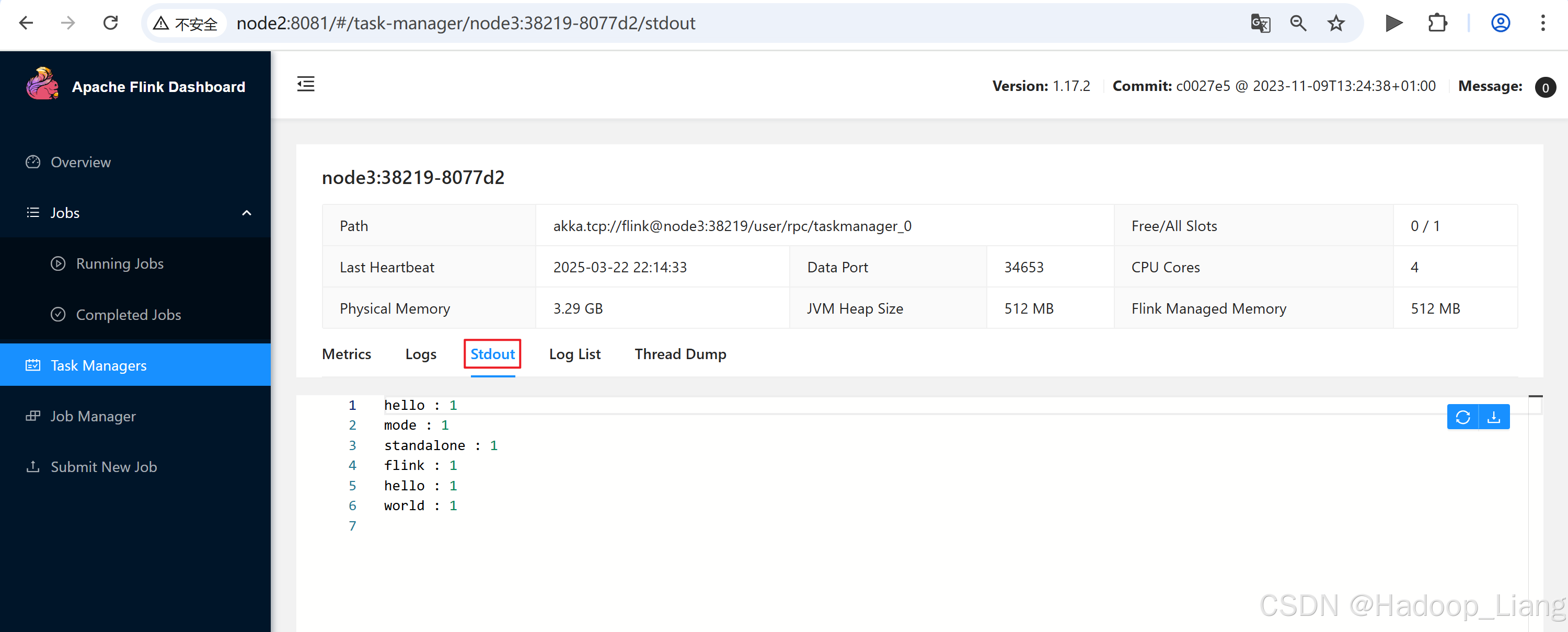
在node3查看到结果,说明是使用node3的Task Manager进行计算的。
关闭flink集群
在node2机器,执行关闭集群命令
[liang@node2 flink-standalone]$ bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 9977) on host node2.
Stopping taskexecutor daemon (pid: 2342) on host node3.
Stopping taskexecutor daemon (pid: 2340) on host node4.
Stopping standalonesession daemon (pid: 9557) on host node2.jps查看进程
[liang@node2 flink-standalone]$ jpsall
=============== node2 ===============
11575 Jps
=============== node3 ===============
2935 Jps
=============== node4 ===============
2914 JpsYARN模式
Flink作为客户端,把作业提交到Yarn中计算
只需在node2机器安装Flink
前提条件
- 安装好Hadoop完全分布式集群,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式
解压安装包
解压并重命名
[liang@node2 ~]$ cd /opt/software
[liang@node2 software]$ tar -zxvf flink-1.17.2-bin-scala_2.12.tgz -C /opt/module
[liang@node2 software]$ cd /opt/module
[liang@node2 module]$ mv flink-1.17.2 flink-yarn配置环境变量
[liang@node2 module]$ sudo vim /etc/profile.d/my_env.sh添加如下环境变量,让Flink能找到Hadoop
#FLINK YARN MODE NEED
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`让环境变量生效
[liang@node2 module]$ source /etc/profile分发环境变量
[liang@node2 module]$ sudo /home/liang/bin/xsync /etc/profile.d/my_env.sh根据提示输入node2机器root账号的密码
分别在node3、node4让环境变量生效
[liang@node3 conf]$ source /etc/profile
[liang@node4 conf]$ source /etc/profile启动Hadoop集群
$ hdp.sh start提交应用测试
会话模式
开启一个YARN会话来启动一个Flink session集群
[liang@node2 module]$ cd flink-yarn
[liang@node2 flink-yarn]$ bin/yarn-session.sh -nm test输入部分日志如下
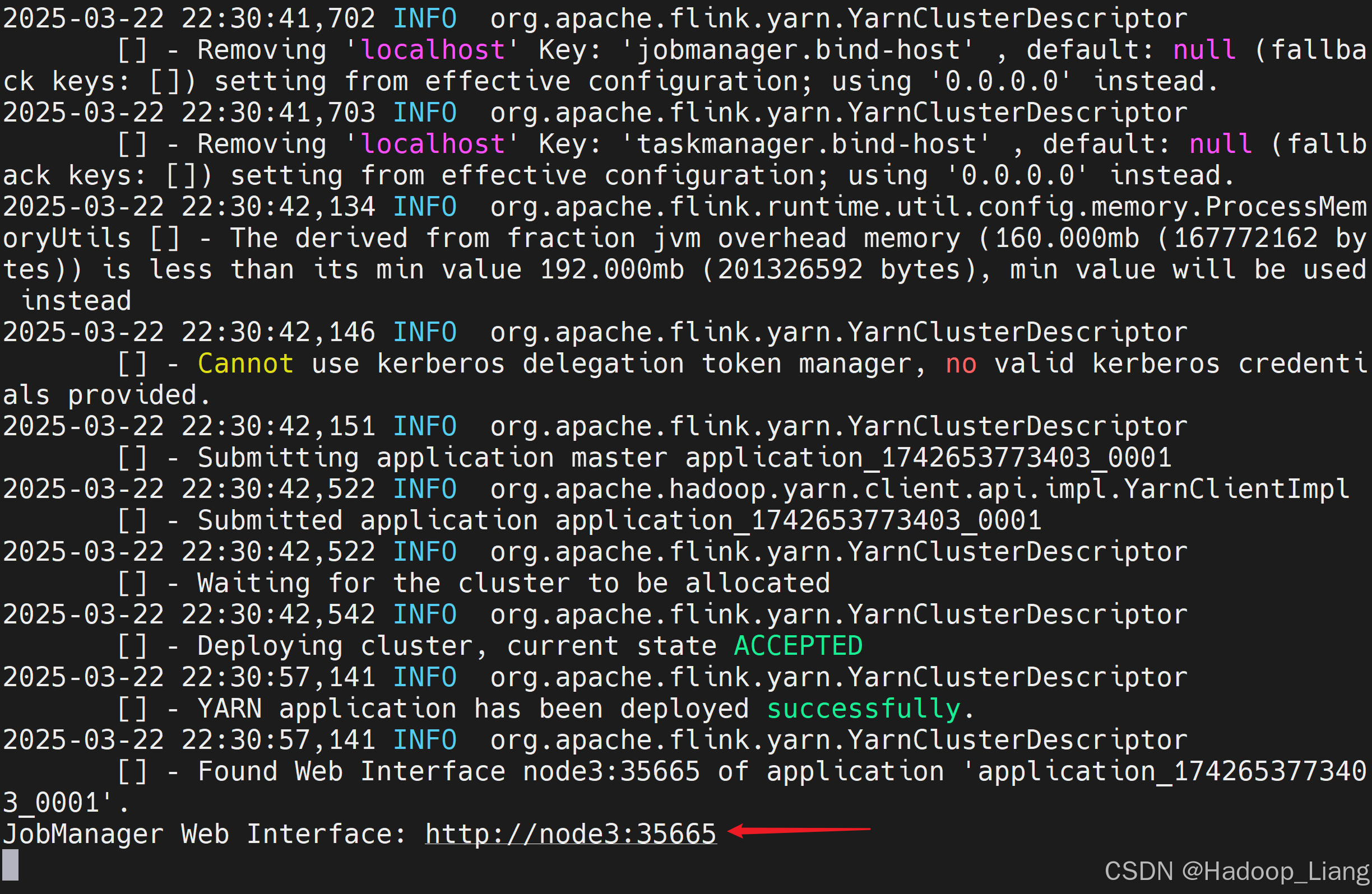
可以看到JobManager的Web UI地址为
http://node3:35665注意:端口号是随机的
浏览器访问看到Web UI地址
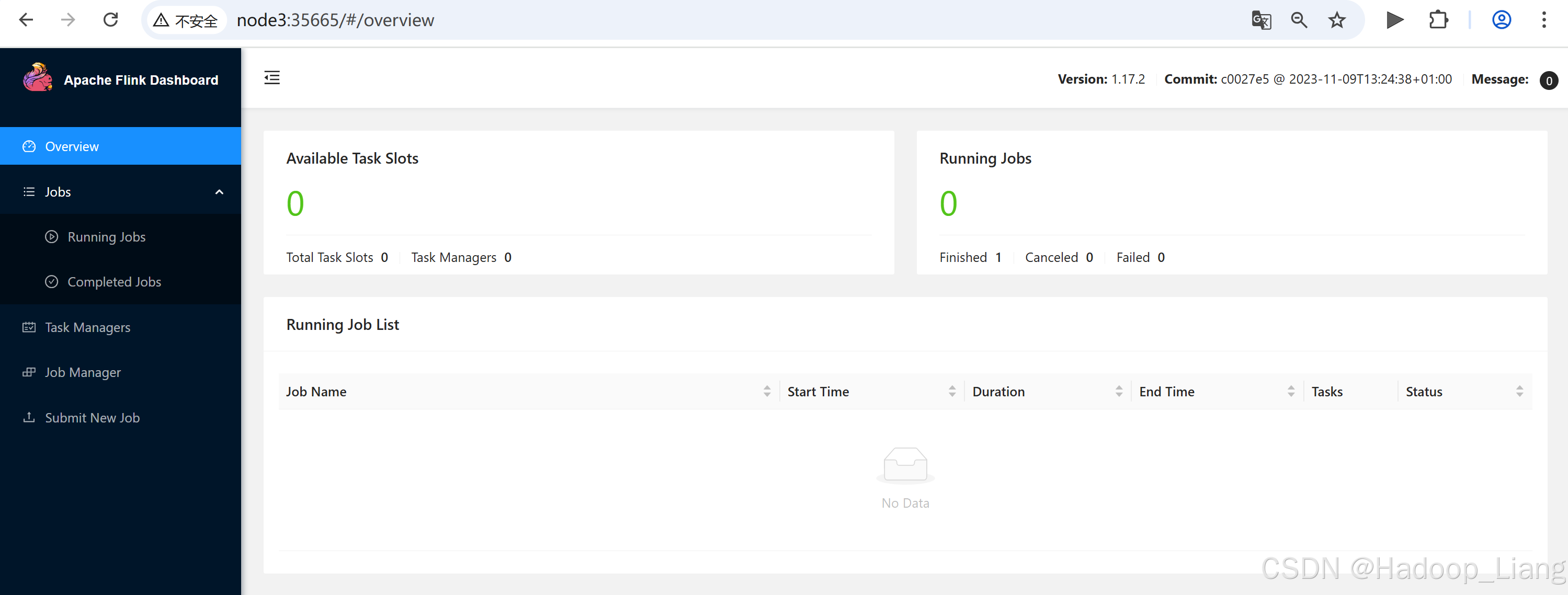
说明在Yarn的Container中创建了一个Flink Session集群
提交应用集群
提交应用有两种方式:
- 命令行方式
- Web UI方式
命令行方式
打开新的终端
$ cd /opt/module/flink-yarn
$ bin/flink run examples/streaming/WordCount.jar客户端可以自行确定JobManager的地址,也可以通过-m或者-jobmanager参数指定JobManager的地址,JobManager地址在YARN Session启动页面中找到。
Web UI查看作业
node3:35665
查看结果

查看Task Managers没有任何信息,原因是因为运行完成后,为了节约资源,释放了Task Manager
要看到结果,重新执行一次作业,快速地查看Web UI 的Task Managers,看到如下结果。

Web UI方式
准备jar包
下载Flink自带的example jar包
打开新的终端,执行nc命令发送数据
[liang@node3 module]$ nc -lk 9999浏览器访问,基于Web UI提交应用jar包
node3:35665
选择SocketWjarindowWordCount.jar后,点击如下界面jar包名称设置作业
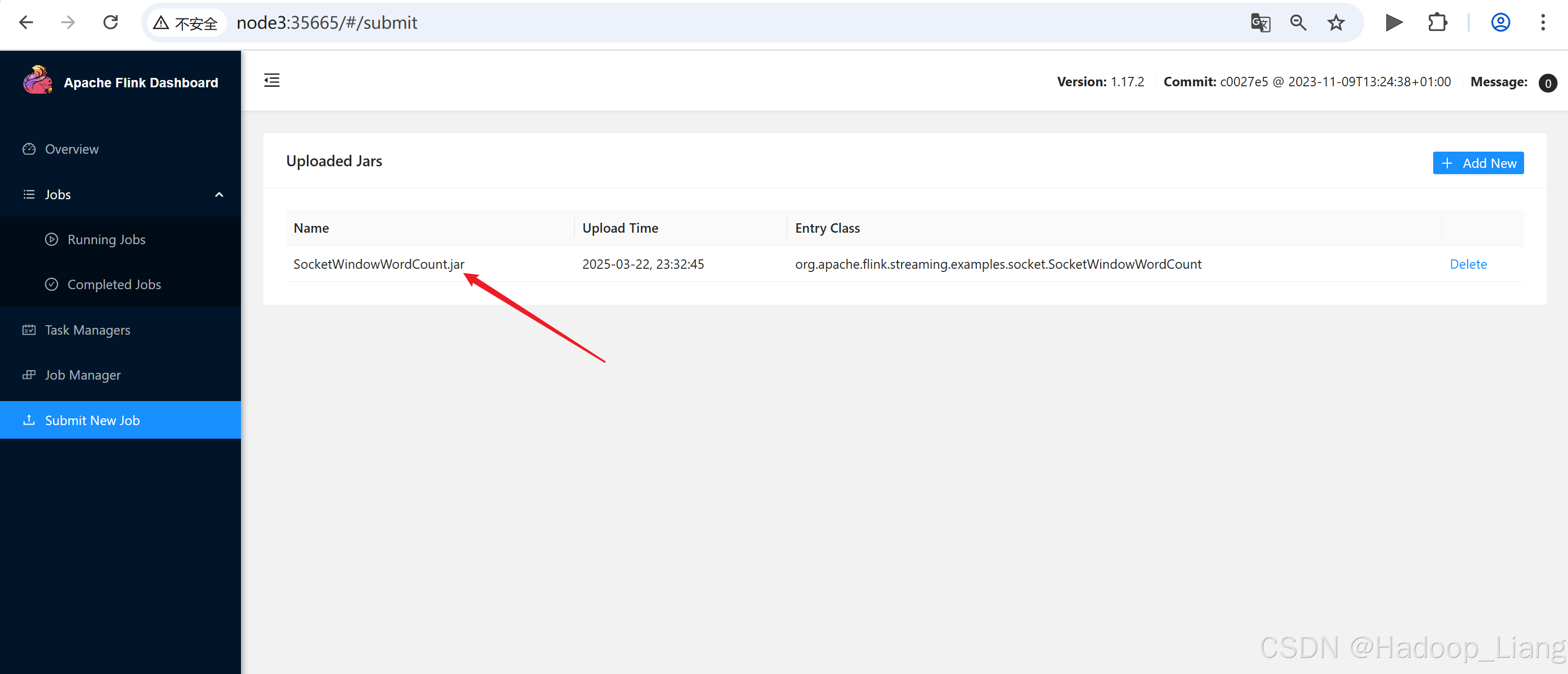
填写如下参数,点击Submit提交
--hostname node3 --port 9999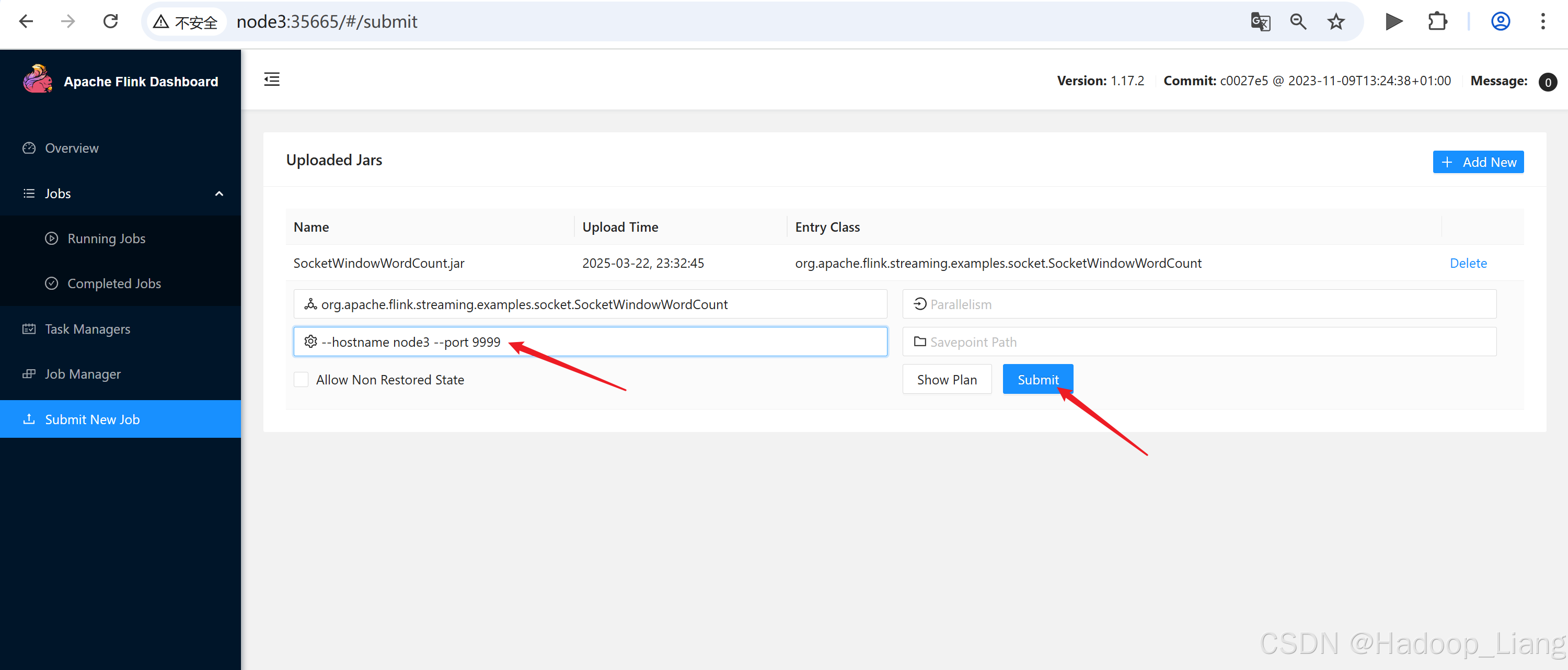
查看到正在运行的作业

在nc终端,发送数据,例如:
hello flink hello world
返回Web UI查看结果
点击Task Managers,点击container_1742653773403_0001_01_000009
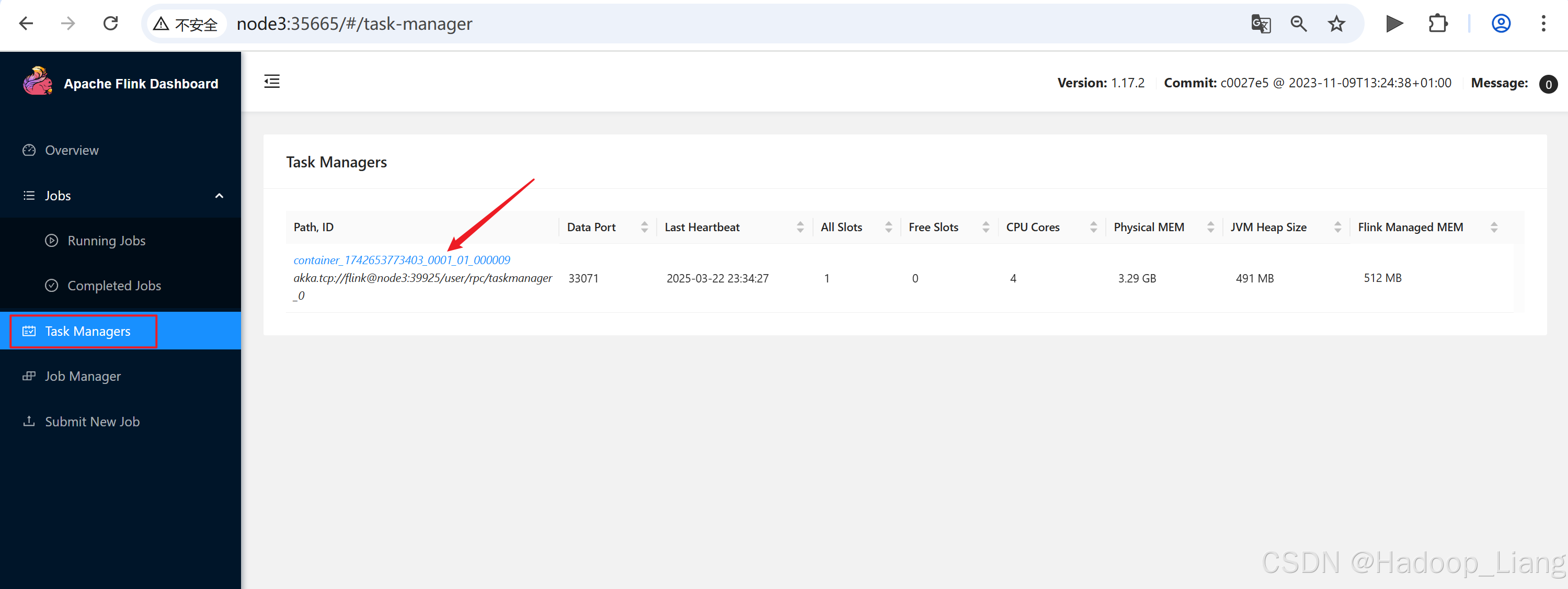
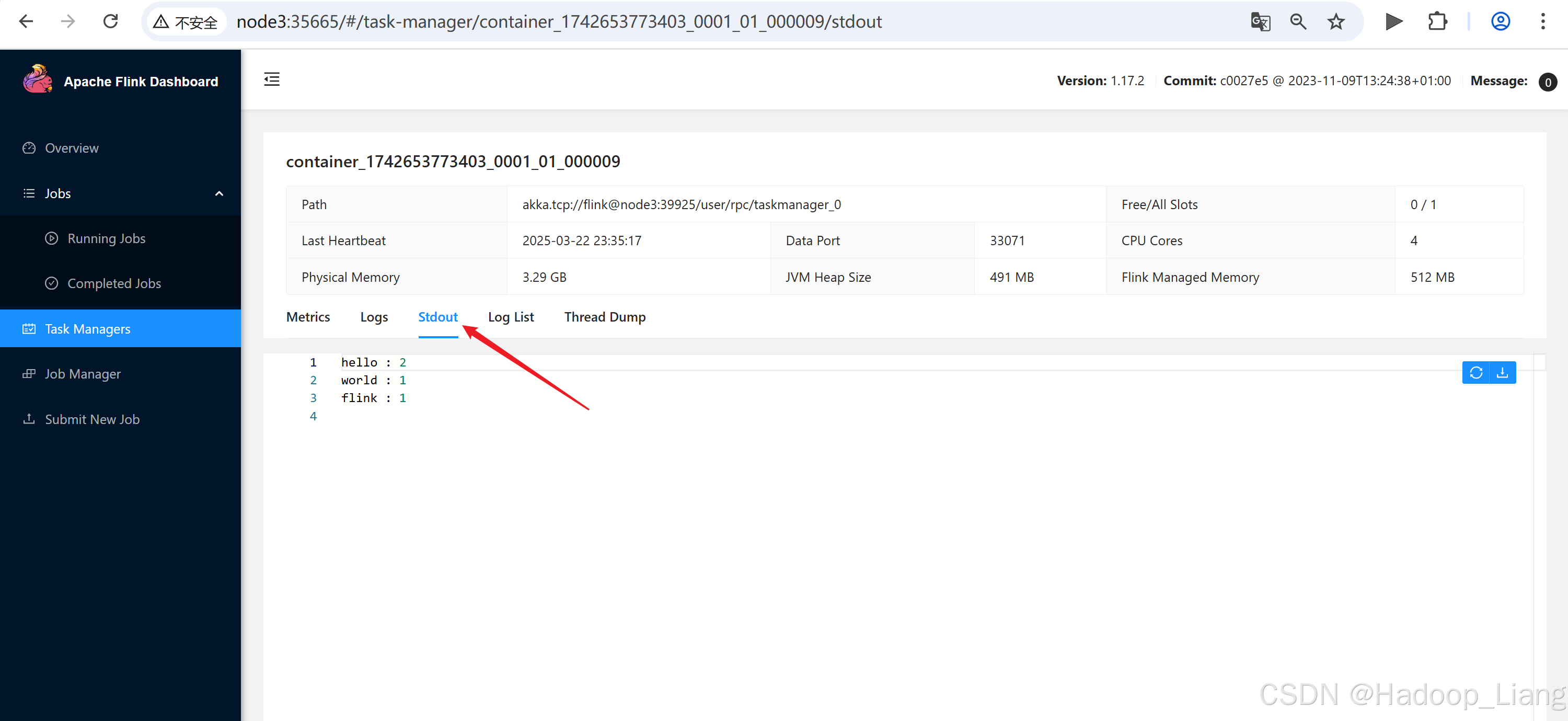
取消作业
点击作业名称
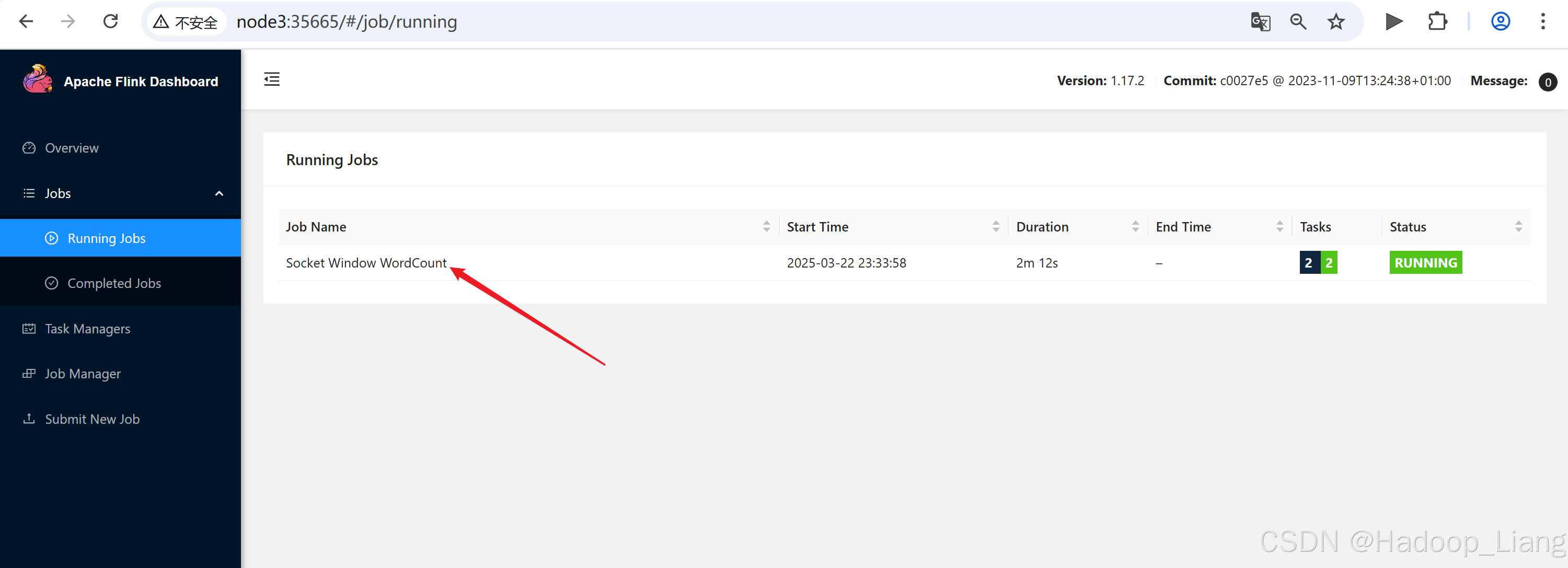
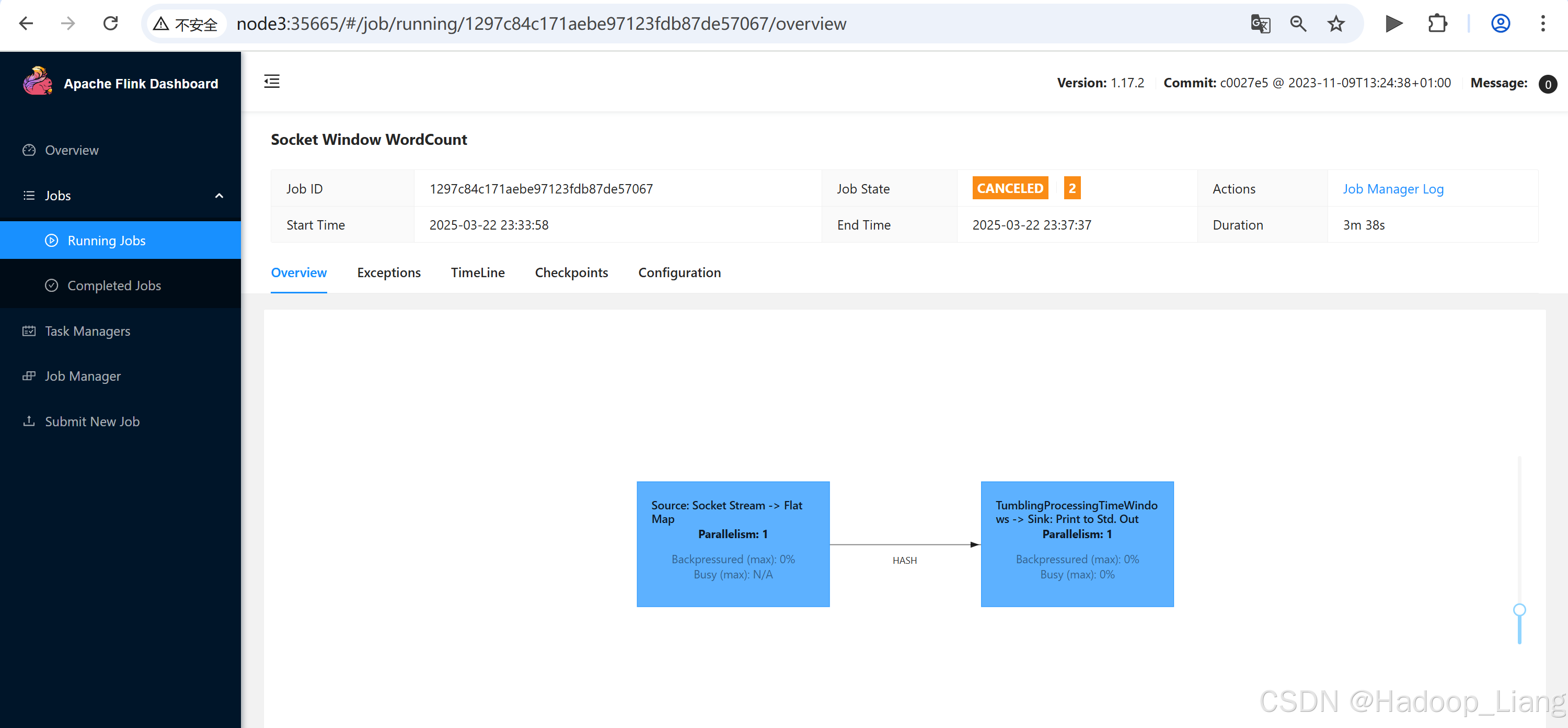
点击Cancel Job,点击Yes

计算文件作业
重新提交另外一个jar:WordCount.jar
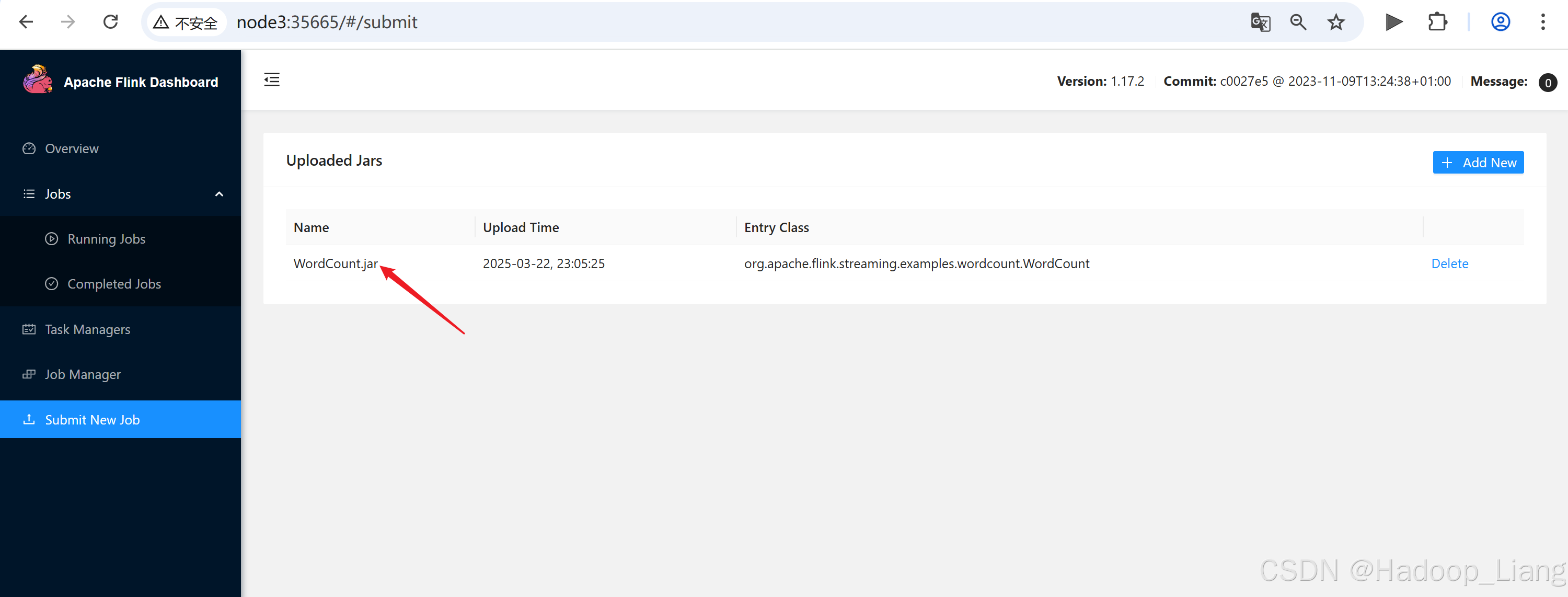
不填写任何参数,直接点击Submit

查看结果
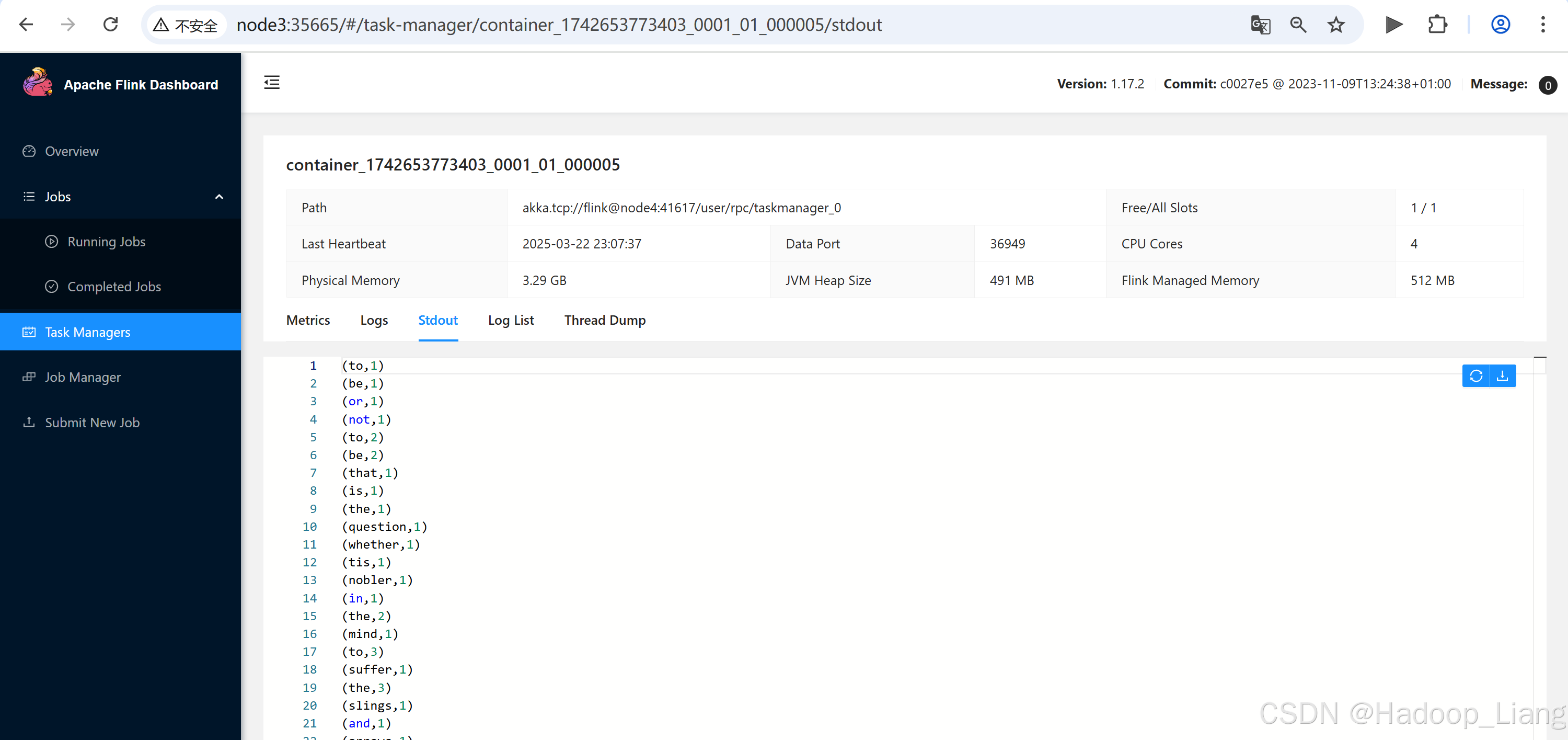
结束Yarn Session会话
返回执行Yarn Session命令的终端,按Ctrl + c 返回命令行
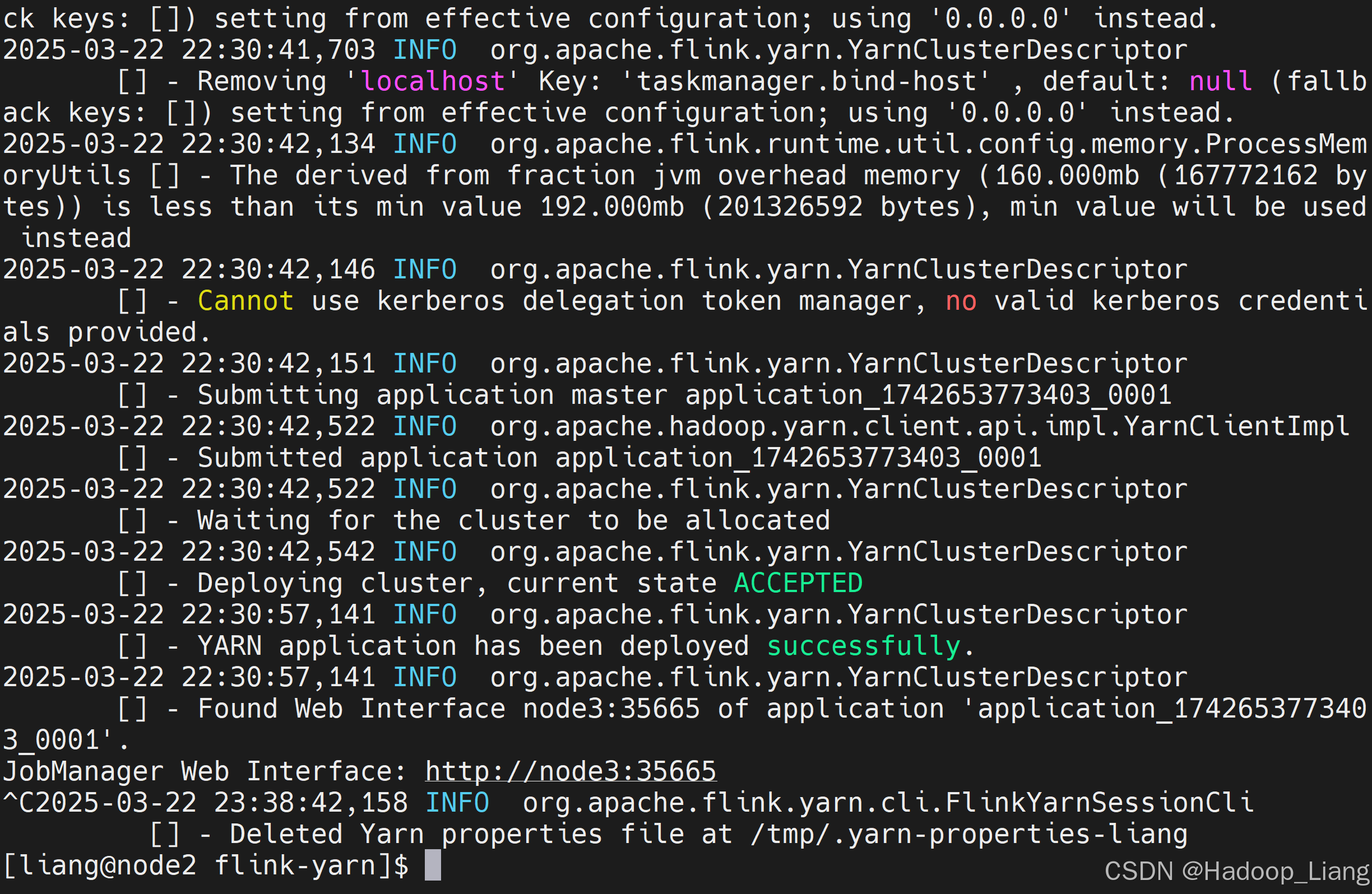
Yarn会话模式总结:
Yarn 会话模式,通过yarn-session.sh命令在Yarn Container创建一个JobManager,并保持这个JobManager。当有作业提交时,会动态创建TaskManager,当作业完后后,会回收TaskManager。
单作业模式
Yarn模式下,需要使用HDFS文件
创建输入测试文件
[liang@node2 flink-yarn]$ ls
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt
[liang@node2 flink-yarn]$ vim input.txt内容如下
hello yarn mode
hello flink
hello hadoop将input.txt上传到HDFS
$ hdfs dfs -put input.txt /提交作业
使用单作业模式提交作业
$ bin/flink run -d -t yarn-per-job -Dclassloader.check-leaked-classloader=false examples/streaming/WordCount.jar \
--input hdfs://node2:8020/input.txt \
--output hdfs://node2:8020/output注意:yarn模式下,输入数据都为HDFS的路径,output是一个输出目录,执行命令之前,输出目录不能存在。
查看结果
执行命令后,等待运行作业结束,查看输出目录
[liang@node2 flink-yarn]$ hdfs dfs -ls /
Found 8 items
-rw-r--r-- 1 liang supergroup 25 2025-03-18 23:17 /1.txt
drwxr-xr-x - liang supergroup 0 2025-03-21 23:21 /hbase
-rw-r--r-- 1 liang supergroup 41 2025-03-22 23:54 /input.txt
drwxr-xr-x - liang supergroup 0 2025-03-18 23:18 /out
drwxr-xr-x - liang supergroup 0 2025-03-23 00:07 /output
drwxr-xr-x - liang supergroup 0 2025-03-22 18:31 /spark-evenlog-directory
drwx------ - liang supergroup 0 2025-03-19 15:16 /tmp
drwxr-xr-x - liang supergroup 0 2025-03-19 15:18 /user
[liang@node2 flink-yarn]$ hdfs dfs -ls /output
Found 1 items
drwxr-xr-x - liang supergroup 0 2025-03-23 00:07 /output/2025-03-23--00
[liang@node2 flink-yarn]$ hdfs dfs -ls /output/2025-03-23--00
Found 1 items
-rw-r--r-- 1 liang supergroup 69 2025-03-23 00:07 /output/2025-03-23--00/part-0d077c9e-7a99-4eca-8c91-7c21ffaa1cec-0
[liang@node2 flink-yarn]$ hdfs dfs -cat /output/2025-03-23--00/part-0d077c9e-7a99-4eca-8c91-7c21ffaa1cec-0
(hello,1)
(yarn,1)
(mode,1)
(hello,2)
(flink,1)
(hello,3)
(hadoop,1)应用模式
文件Wordcount
执行如下命令
$ bin/flink run-application -t yarn-application -d examples/streaming/WordCount.jar \
--input hdfs://node2:8020/input.txt \
--output hdfs://node2:8020/output1 
等待运行结束,查看结果
[liang@node2 flink-yarn]$ hdfs dfs -ls /
Found 9 items
-rw-r--r-- 1 liang supergroup 25 2025-03-18 23:17 /1.txt
drwxr-xr-x - liang supergroup 0 2025-03-21 23:21 /hbase
-rw-r--r-- 1 liang supergroup 41 2025-03-22 23:54 /input.txt
drwxr-xr-x - liang supergroup 0 2025-03-18 23:18 /out
drwxr-xr-x - liang supergroup 0 2025-03-23 00:07 /output
drwxr-xr-x - liang supergroup 0 2025-03-23 00:12 /output1
drwxr-xr-x - liang supergroup 0 2025-03-22 18:31 /spark-evenlog-directory
drwx------ - liang supergroup 0 2025-03-19 15:16 /tmp
drwxr-xr-x - liang supergroup 0 2025-03-19 15:18 /user
[liang@node2 flink-yarn]$ hdfs dfs -ls /output1
Found 1 items
drwxr-xr-x - liang supergroup 0 2025-03-23 00:12 /output1/2025-03-23--00
[liang@node2 flink-yarn]$ hdfs dfs -ls /output1/2025-03-23--00
Found 1 items
-rw-r--r-- 1 liang supergroup 69 2025-03-23 00:12 /output1/2025-03-23--00/part-01662fc4-01e6-45a4-858c-5443fc2b31f0-0
[liang@node2 flink-yarn]$ hdfs dfs -cat /output1/2025-03-23--00/*
(hello,1)
(yarn,1)
(mode,1)
(hello,2)
(flink,1)
(hello,3)
(hadoop,1)持续流WordCount
终端1:在node2 发送数据终端
[liang@node2 flink-yarn]$ nc -lk 9999 终端2:打开新的终端,提交作业
$ cd /opt/module/flink-yarn
$ bin/flink run-application -t yarn-application -d examples/streaming/SocketWindowWordCount.jar --hostname node2 --port 9999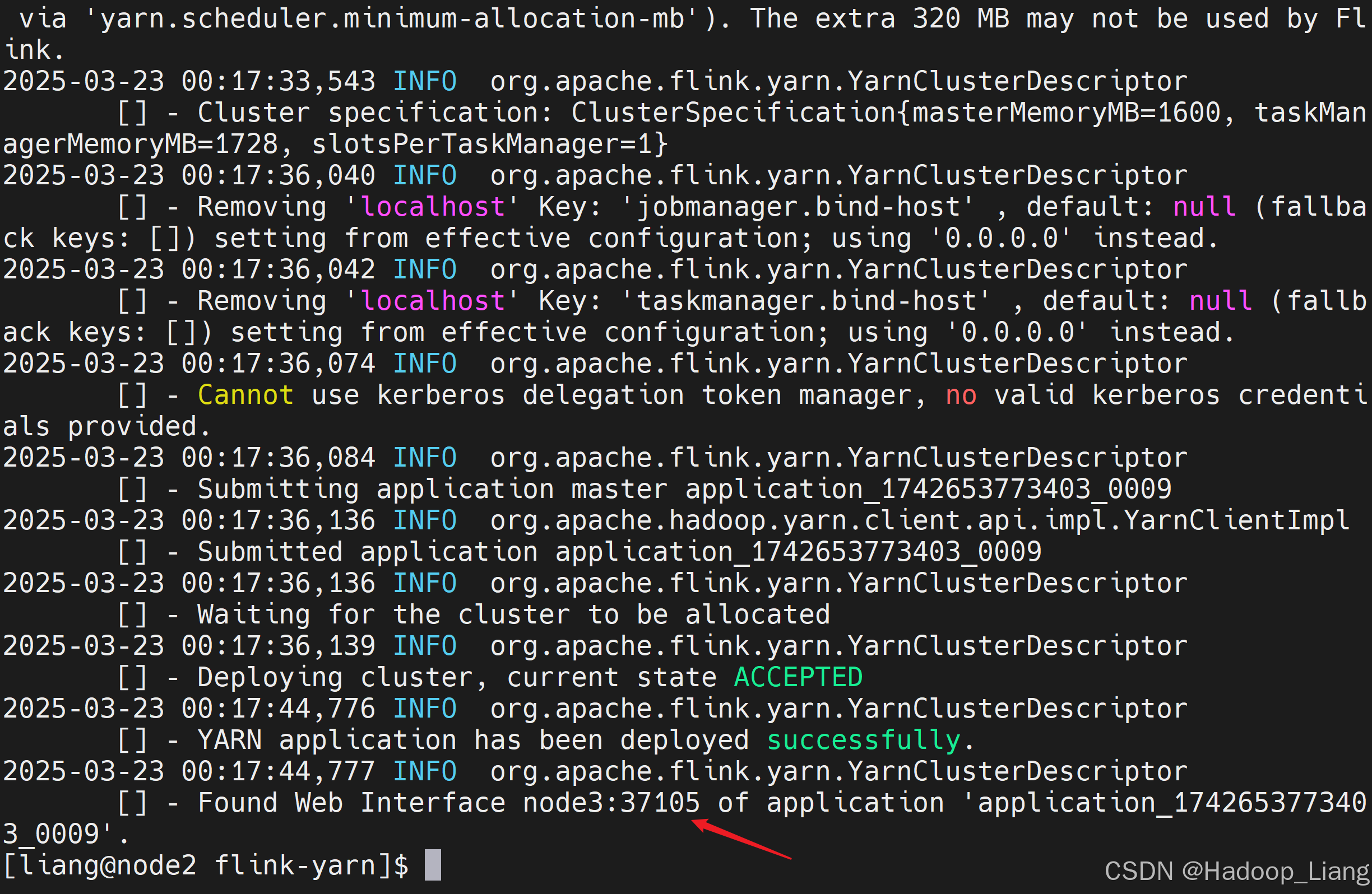
看到Web UI地址为
node3:37105 浏览器访问以上查到的Web UI地址
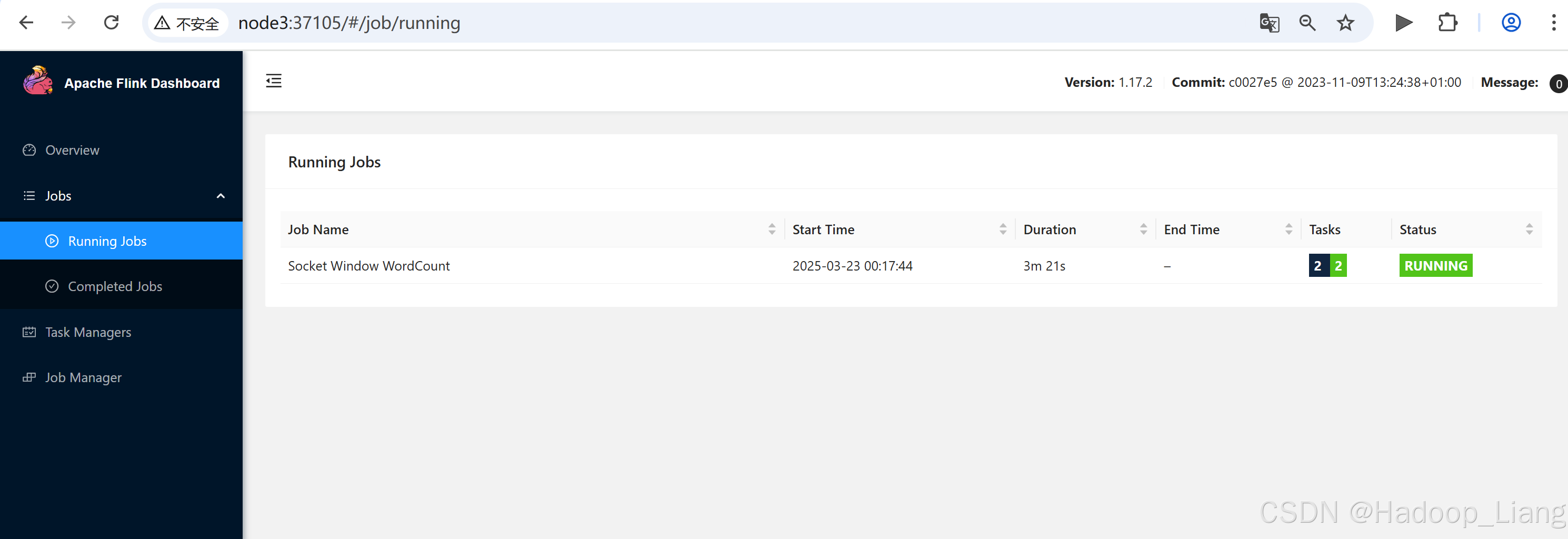
返回nc终端发送数据
hello flink hello yarn
在Web UI查看结果
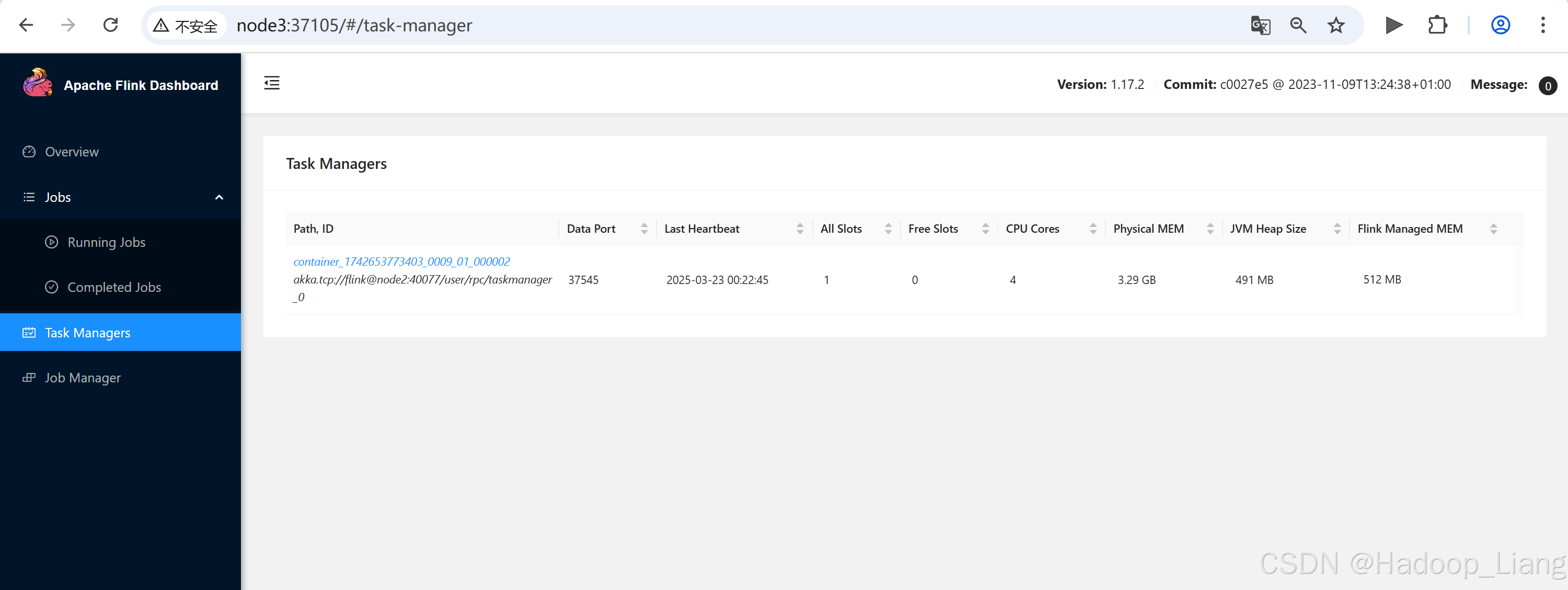
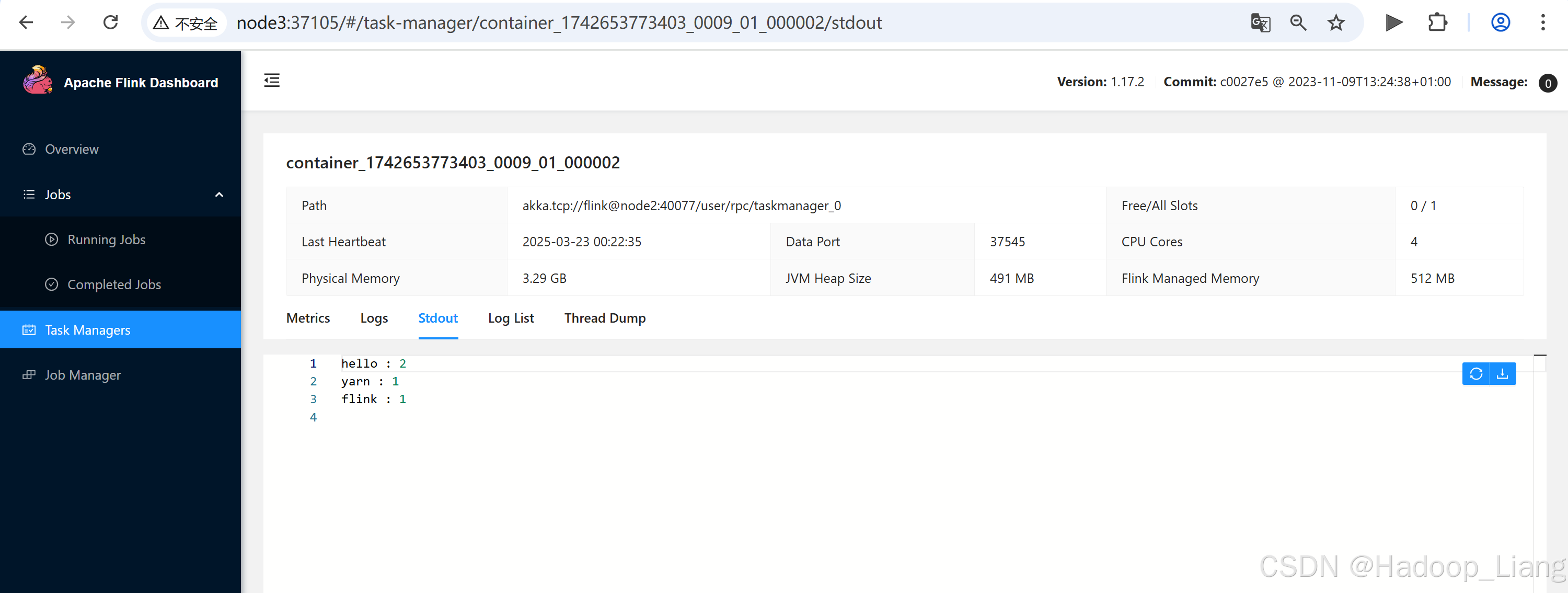
结束任务
在nc终端,按Ctrl + c 结束任务
关闭Hadoop集群
$ hdp.sh stop如有需要,可点击查看:配套视频教程
完成!enjoy it!