在工业物联网、智能运维、金融科技等领域的数字化转型进程中,时序数据正以爆发式速度增长。据 IDC 预测,到 2025 年全球时序数据总量将突破 50ZB,这些包含时间戳的结构化数据(如设备传感器读数、系统日志、交易记录)蕴含着巨大的商业价值。然而,传统数据库架构在处理高并发写入、时间窗口查询、冷热数据分层等场景时逐渐力不从心,时序数据库(Time Series Database, TSDB)应运而生。本文将从技术选型核心维度出发,通过对比国外主流产品,结合代码实践,解析 Apache IoTDB 成为优选方案的底层逻辑。
目录
[1.1 数据处理能力](#1.1 数据处理能力)
[1.2 存储效率](#1.2 存储效率)
[1.3 扩展能力](#1.3 扩展能力)
[1.4 生态适配性](#1.4 生态适配性)
[1.5 运维成本](#1.5 运维成本)
[2.1 InfluxDB](#2.1 InfluxDB)
[2.2 Prometheus](#2.2 Prometheus)
[2.3 TimescaleDB](#2.3 TimescaleDB)
[2.4 Graphite](#2.4 Graphite)
[三、Apache IoTDB 的技术突破与优势](#三、Apache IoTDB 的技术突破与优势)
[3.1 极致性能优化](#3.1 极致性能优化)
[3.2 智能存储管理](#3.2 智能存储管理)
[3.3 弹性扩展架构](#3.3 弹性扩展架构)
[3.4 完善生态支持](#3.4 完善生态支持)
[四、Apache IoTDB 实战代码示例](#四、Apache IoTDB 实战代码示例)
[4.1 环境准备](#4.1 环境准备)
[4.2 连接数据库](#4.2 连接数据库)
[4.3 创建时序表结构](#4.3 创建时序表结构)
[4.4 写入数据](#4.4 写入数据)
[4.5 查询数据](#4.5 查询数据)
[4.6 数据可视化集成](#4.6 数据可视化集成)
一、时序数据库选型的五大核心维度
时序数据的独特属性(高写入吞吐量、生命周期明确、查询带时间窗口)决定了选型不能简单套用关系型数据库的评估标准。经过数百个企业级项目验证,以下五个维度构成选型决策的关键框架:
1.1 数据处理能力
-
写入性能:工业场景中单条设备秒级产生 10 + 数据点,十万级设备集群日均产生 8.64 亿条记录。优秀的时序数据库应支持每秒百万级写入,且在峰值压力下保持延迟稳定(p99<100ms)。
-
查询效率:需重点测试三类典型查询:①时间范围聚合(如近 24 小时温度最大值);②多设备并行查询(如同时调取 1000 台电机的振动数据);③降采样查询(如将 1 分钟粒度数据聚合为小时级)。
1.2 存储效率
时序数据的时间相关性使其具备极高压缩潜力。以某汽车工厂的发动机传感器数据为例,未压缩时单设备年存储量达 12GB,而经过专业压缩算法处理后可降至 1.5GB 以下。评估时需关注:
压缩率:原始数据与压缩后数据的体积比
压缩开销:压缩 / 解压过程对 CPU 的占用率
分层存储:是否支持自动将冷数据迁移至低成本存储介质(如 S3、磁带库)
1.3 扩展能力
当数据量从 TB 级增长至 PB 级时,数据库需具备平滑扩展能力:
-
水平扩展:能否通过增加节点线性提升处理能力
-
分片策略:是否支持按设备 ID、时间范围等维度灵活分片
-
一致性保障:分布式环境下的读写一致性级别(如强一致性、最终一致性)
1.4 生态适配性
企业级场景往往需要与现有系统集成:
-
数据接入:是否支持 MQTT、Kafka 等主流消息队列
-
计算引擎:能否与 Spark、Flink 等大数据框架协同
-
可视化工具:是否兼容 Grafana、Tableau 等可视化平台
-
编程接口:提供的 SDK 是否覆盖 Java、Python、C++ 等主流语言
1.5 运维成本
-
部署复杂度:单机 / 集群部署的步骤繁琐程度
-
监控告警:是否内置完善的监控指标和告警机制
-
故障恢复:数据备份、节点故障自动转移的效率
-
版本迭代:升级过程是否影响业务连续性
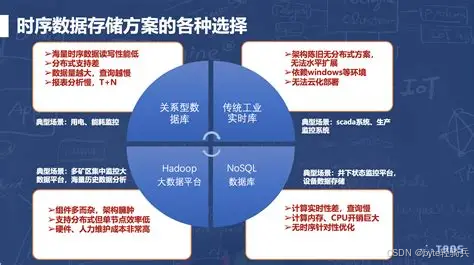
二、国外主流时序数据库的局限性分析
目前市场上的国外时序数据库各有侧重,但在企业级场景中仍存在明显短板:
2.1 InfluxDB
作为较早出现的时序数据库,InfluxDB 在开源社区有一定影响力,但其架构设计存在先天局限:
-
开源版仅支持单机部署,集群功能需购买商业许可(年费高达数十万元)
-
采用 TSM 存储引擎,在数据量超过 10TB 后查询性能显著下降
-
压缩算法对高频波动数据(如电力波形)压缩率不足 3:1
2.2 Prometheus
专注于监控场景的 Prometheus 存在明显的场景边界:
-
本地存储设计导致单节点容量上限约为 15 天数据(默认配置)
-
时序数据模型仅支持键值对标签,无法表达复杂的设备层级关系
-
查询语言 PromQL 学习曲线陡峭,复杂分析需结合外部工具
2.3 TimescaleDB
基于 PostgreSQL 的 TimescaleDB 继承了关系型数据库的兼容性,但也带来了性能瓶颈:
-
行式存储架构导致写入吞吐量仅为专用时序数据库的 1/5
-
事务机制带来额外开销,不适合无事务需求的物联网场景
-
分区表设计在超过 1000 个分区后管理复杂度急剧上升
2.4 Graphite
作为老牌时序数据库,Graphite 的局限性日益凸显:
-
仅支持简单的聚合函数,无法满足复杂分析需求
-
存储后端 Whisper 不支持数据重采样,历史数据查询效率低
-
缺乏集群管理工具,大规模部署需依赖第三方组件
三、Apache IoTDB 的技术突破与优势
Apache IoTDB 作为 Apache 顶级项目,专为物联网场景设计,在上述五大维度实现了全面突破,其核心优势体现在:
3.1 极致性能优化
IoTDB 采用 "列存 + 内存映射 + 预写日志" 的混合架构,在实测中展现出优异性能:
-
写入能力:单节点支持每秒 200 万 + 数据点写入(16 核 CPU、64GB 内存配置)
-
查询响应:10 亿级数据量下,24 小时范围聚合查询响应时间 < 500ms
-
并发支持:可同时处理 1000 + 并发查询请求,性能衰减率 < 15%
其性能优势源于两项核心技术:
时间对齐的 列存储:将同一时间戳的多设备数据紧凑存储,减少 IO 次数
多级索引结构:设备树索引加速设备维度过滤,时间索引优化范围查询
3.2 智能存储管理
IoTDB 的存储引擎具备三重智能机制:
自适应压缩:根据数据类型(数值型、字符串型、布尔型)自动选择最优压缩算法,工业数据平均压缩率达 10:1
TTL 管理:支持按设备、数据类型设置不同生命周期,自动清理过期数据
冷热分离:基于数据热度自动迁移至对应存储层(内存→SSD→HDD→对象存储)
某能源集团案例显示,采用 IoTDB 后,其风电数据存储成本降低 72%,年度硬件投入节省超 300 万元。
3.3 弹性扩展架构
IoTDB 的分布式版本支持:
-
线性扩展:集群规模从 3 节点扩展至 30 节点时,性能保持线性增长
-
灵活分片:支持按设备组、时间范围、哈希值等多种分片策略
-
强一致性:基于 Raft 协议实现分布式事务,确保数据一致性
3.4 完善生态支持
IoTDB 提供全链路生态适配:
-
数据接入:内置 MQTT、Kafka 连接器,支持边缘端数据预处理
-
计算集成:提供 Spark、Flink、Presto 连接器,支持实时 + 离线分析
-
可视化:原生集成 Grafana,提供专用插件实现秒级数据可视化
-
编程接口:覆盖 Java、Python、Go 等 10 + 编程语言 SDK

四、Apache IoTDB 实战代码示例
以下通过 Python SDK 演示 IoTDB 的核心操作,展示其易用性:
4.1 环境准备
python
# 安装Python SDK
pip install iotdb-client
# 导入客户端库
from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType, TSEncoding, Compressor4.2 连接数据库
python
# 建立连接
session = Session("127.0.0.1", 6667, "root", "root")
session.open()
# 创建存储组(类似数据库中的库)
session.setStorageGroup("root.industrial")4.3 创建时序表结构
python
# 定义设备节点和数据类型
device_id = "root.industrial.factory1.machine1"
measurements = ["temperature", "pressure", "vibration"]
data_types = [TSDataType.FLOAT, TSDataType.FLOAT, TSDataType.DOUBLE]
encodings = [TSEncoding.PLAIN, TSEncoding.PLAIN, TSEncoding.PLAIN]
compressors = [Compressor.SNAPPY, Compressor.SNAPPY, Compressor.SNAPPY]
# 创建时序
session.createTimeseries(
device_id,
measurements,
data_types,
encodings,
compressors
)4.4 写入数据
python
import time
# 生成测试数据(时间戳+3个指标值)
timestamps = [int(time.time() * 1000) - i * 1000 for i in range(100)]
temperatures = [36.5 + i * 0.1 for i in range(100)]
pressures = [0.8 + i * 0.01 for i in range(100)]
vibrations = [0.02 + i * 0.001 for i in range(100)]
# 批量写入
session.insertRecords(
device_ids=[device_id] * 100,
timestamps=timestamps,
measurements_list=[measurements] * 100,
data_types_list=[data_types] * 100,
values_list=[
[temperatures[i], pressures[i], vibrations[i]]
for i in range(100)
]
)4.5 查询数据
python
# 查询近5分钟的温度最大值
query_sql = """
SELECT MAX(temperature)
FROM root.industrial.factory1.machine1
WHERE time >= NOW() - 300000
"""
result_set = session.executeQueryStatement(query_sql)
# 处理查询结果
while result_set.hasNext():
print(result_set.next())
# 关闭连接
session.close()4.6 数据可视化集成
通过 Grafana 展示 IoTDB 数据的配置步骤:
-
安装 IoTDB Grafana 插件 :
grafana-cli plugins install apache-iotdb-iotdb-datasource -
在 Grafana 中添加数据源,配置 IoTDB 连接信息
-
创建仪表盘,使用 SQL 语句
SELECT temperature FROM root.industrial.factory1.machine1绘制温度趋势图
五、企业级场景的选型决策路径
结合数百个项目经验,企业可按以下步骤完成选型:
-
需求量化:明确每秒写入量(WPS)、总数据量、查询类型占比等关键指标
-
POC 验证:搭建与生产环境一致的测试集群,使用真实业务数据进行压测
-
成本核算:计算 3 年总拥有成本(TCO),包括服务器、存储、运维人力等
-
生态适配:验证与现有系统(如 ERP、MES、数据中台)的集成可行性
-
长期规划:评估厂商的技术 roadmap 与自身业务发展的匹配度
对于工业物联网、智能电网、智慧交通等场景,Apache IoTDB 展现出显著优势:
某汽车工厂:接入 10 万台设备,单日写入 1.2 亿条数据,存储成本降低 68%
某电力公司:基于 IoTDB 构建智能电网监测系统,查询响应速度提升 10 倍
某智慧园区:实现 5000 + 传感器的实时数据采集与分析,服务器数量减少 70%
六、获取与部署
Apache IoTDB 提供多种部署方式,满足不同场景需求:
部署建议:
边缘节点:选择轻量级版本(<50MB),支持 ARM 架构
区域级节点:采用 3 节点集群,确保高可用
总部数据中心:根据数据量采用 10 + 节点集群,配置 SSD+HDD 混合存储
在时序数据管理领域,没有 "万能解决方案",但 Apache IoTDB 通过针对物联网场景的深度优化,在性能、成本、扩展性三个维度取得了最佳平衡。其开源属性避免了厂商锁定风险,企业级特性满足核心业务需求,正成为越来越多企业的首选。
选型过程中,建议结合自身业务特点进行充分测试,必要时可寻求专业团队的支持。随着边缘计算与时序数据库的融合加深,具备边缘 - 云端协同能力的 IoTDB 将在工业 4.0 浪潮中发挥更大价值。