在现代数据架构中,分布式数据湖(Distributed Data Lake) 结合 实时计算(Real-time Computing) 已成为大数据处理的核心模式。数据湖用于存储海量的结构化和非结构化数据,而实时计算则确保数据能够被迅速处理和分析,以支持业务决策、流式数据分析和机器学习应用。
1. 分布式数据湖概述
1.1 数据湖的定义
数据湖(Data Lake)是一种能够存储 原始格式数据 (结构化、半结构化和非结构化数据)的存储架构,支持 大规模数据管理 和 灵活的数据分析。
与传统数据仓库(Data Warehouse)相比,数据湖的特点是:
-
存储更灵活:数据不需要预定义模式(Schema-on-Read)。
-
支持多种数据格式:如 JSON、Parquet、ORC、CSV、Avro 等。
-
大规模存储和计算分离:适用于现代云计算和分布式存储架构。
1.2 分布式数据湖架构
分布式数据湖一般由以下关键组件构成:
-
存储层(Storage Layer)
-
采用 分布式文件系统,如:
-
HDFS(Hadoop Distributed File System)
-
Amazon S3(AWS对象存储)
-
Google Cloud Storage(GCS)
-
Azure Data Lake Storage(ADLS)
-
-
存储数据采用 列式格式(Parquet/ORC) 以优化查询性能。
-
-
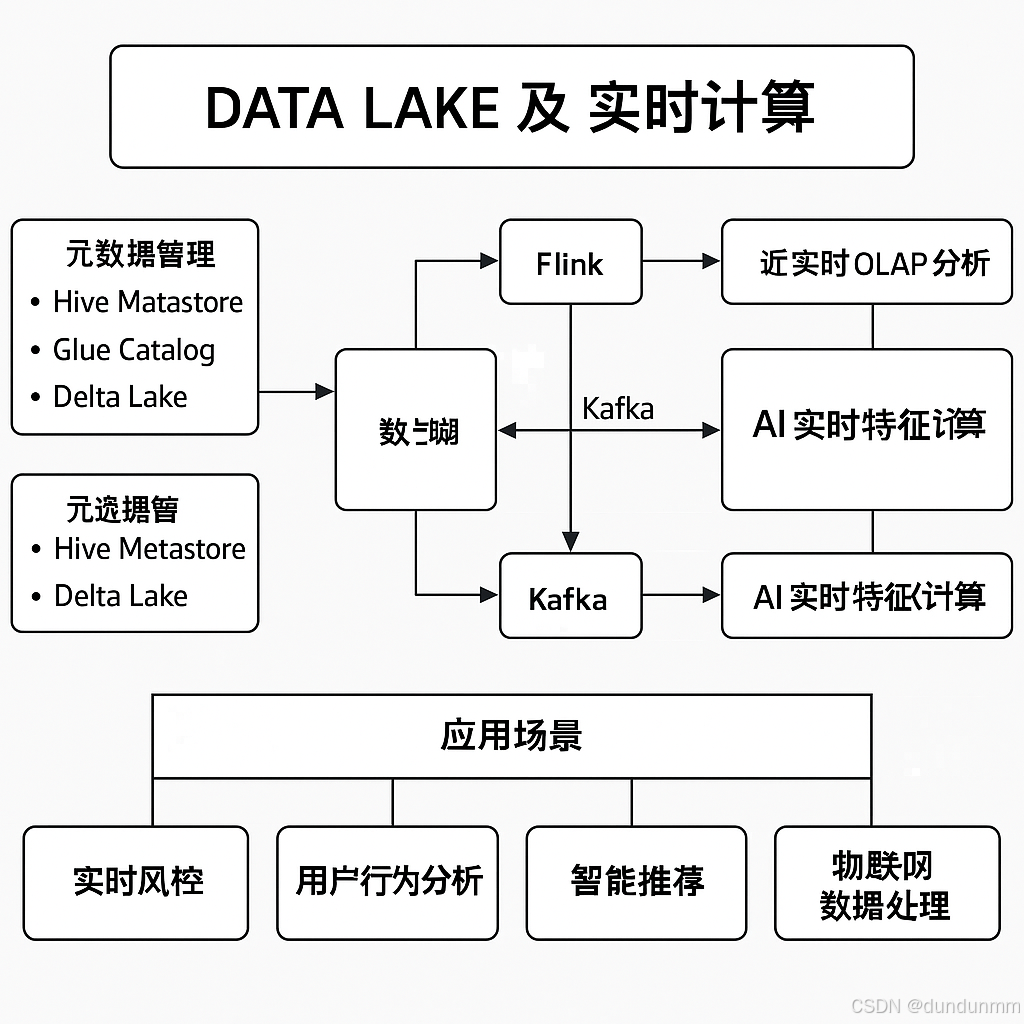
元数据管理(Metadata Management)
-
维护数据表结构、Schema 及索引,如:
-
Apache Hive Metastore
-
AWS Glue Catalog
-
Databricks Delta Lake
-
-
通过 ACID 事务(如 Delta Lake)增强数据一致性。
-
-
计算层(Compute Layer)
-
计算框架:Apache Spark、Apache Flink、Presto、Trino
-
执行 批处理(Batch Processing) 和 流计算(Stream Processing)。
-
-
数据访问接口(Data Access Layer)
-
通过 SQL、API、BI 工具 访问数据,如:
-
Presto、Trino(查询)
-
Apache Spark SQL
-
Apache Arrow(高性能数据传输)
-
-
-
数据治理(Data Governance)
-
提供 权限管理、数据质量控制,常见工具:
-
Apache Ranger(权限管理)
-
Apache Atlas(数据血缘分析)
-
-
2. 实时计算技术
2.1 实时计算的需求
随着 物联网、金融交易、智能推荐、网络安全监控 等场景的兴起,实时计算需求不断增长:
-
低延迟(Low Latency):秒级甚至毫秒级响应数据变化。
-
高吞吐(High Throughput):每秒处理数百万条数据流。
-
流式计算(Stream Processing):对数据流进行增量计算。
2.2 实时计算架构
现代实时计算架构通常采用 Lambda 或 Kappa 架构:
-
Lambda 架构
-
由 批处理(Batch)+ 流处理(Streaming) 结合:
-
批处理:Hadoop、Spark
-
流处理:Flink、Kafka Streams
-
-
优点:可提供数据准确性保障(数据回溯)。
-
缺点:代码维护复杂,数据同步成本高。
-
-
Kappa 架构
-
仅使用 流计算(Streaming Processing) 处理所有数据。
-
主要组件:
-
Kafka/Pulsar(数据流传输)
-
Flink/Kafka Streams/Spark Streaming(流处理)
-
-
优点:架构简单,适用于 事件驱动应用(如欺诈检测、实时推荐)。
-
2.3 主要实时计算框架
| 框架 | 计算模式 | 适用场景 |
|---|---|---|
| Apache Flink | 实时流处理(Stream Processing) | 高吞吐、低延迟应用 |
| Apache Kafka Streams | 轻量级流处理 | 事件驱动架构 |
| Apache Spark Streaming | 微批(Micro-batch)流计算 | 实时分析 + 兼容 Spark 批处理 |
| Apache Storm | 低延迟流处理 | 高速数据流(金融风控) |
| Apache Druid | 实时 OLAP 分析 | BI、数据可视化 |
3. 分布式数据湖与实时计算的结合
3.1 为什么要结合数据湖与实时计算?
在实际业务中,数据湖的存储能力与实时计算结合,可以实现:
-
实时分析:基于数据湖的流数据分析,如用户行为分析。
-
实时 ETL(Extract-Transform-Load):流式数据清洗、转换、存入数据湖。
-
增量数据处理 :结合 Delta Lake、Iceberg 进行 Change Data Capture(CDC),只处理新增数据。
3.2 结合方式
-
数据湖 + 实时流计算
-
数据流入(Streaming Ingestion):
- Kafka → Flink → Delta Lake / Iceberg
-
实时查询(Streaming Query):
- Flink SQL 直接查询数据湖。
-
-
数据湖 + 近实时 OLAP
-
数据湖存储历史数据,Druid 进行实时聚合分析:
- Flink → Kafka → Druid
-
-
数据湖 + AI 实时特征计算
-
实时机器学习(Online Machine Learning):
-
Flink 计算特征 → 存入 Feature Store(如 Feast)
-
AI 模型使用最新数据训练 / 推理
-
-
4. 典型应用场景
| 应用场景 | 解决方案 | 主要技术 |
|---|---|---|
| 实时风控 | 监测交易数据,检测欺诈行为 | Flink + Kafka + 数据湖 |
| 用户行为分析 | 统计 PV/UV,用户路径分析 | Flink SQL + Delta Lake |
| 智能推荐 | 结合用户实时行为调整推荐策略 | Flink + ML 模型 |
| IoT 数据处理 | 处理海量物联网设备数据 | Kafka + Flink + Iceberg |
| 日志分析 | 监控系统日志,检测异常 | Flink + Druid + Elasticsearch |
5. 未来发展趋势
-
数据湖 + Lakehouse 模式 :采用 Delta Lake、Apache Iceberg 统一批流处理能力,支持 ACID 事务。
-
流批一体化(Stream-Batch Unification):Flink/Spark 逐步统一批处理和流处理,提高一致性。
-
自动化数据治理(Automated Data Governance):引入 AI 进行元数据管理和数据质量检测。
-
云原生架构(Cloud-Native Data Lake):无服务器(Serverless)计算框架,如 AWS Athena、Google BigQuery。
6. 结论
分布式数据湖与实时计算的结合,能够高效存储、管理和分析大规模数据 ,是未来数据架构发展的核心方向。通过采用 Flink、Kafka、Delta Lake 等技术,可以实现 高效实时分析、流式数据处理和 AI 应用,满足企业级大数据需求。