数据存储 hadoop-3.4.1
下载并安装软件

上传安装软件到服务器
解压安装:tar -xzvf hadoop-3.4.1.tar.gz -C /opt/module/
Hadoop配置
-
配置hadoop环境变量:
bashsudo vim /etc/profile.d/myprofile.sh #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.4.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop应用变更: source /etc/profile
-
配置hadoop使用的JAVA环境
bashsudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh # 配置Hadoop使用的JAVA路径 export JAVA_HOME=/opt/module/jdk-17.0.10 -
配置core-site.xml
bashvim $HADOOP_HOME/etc/hadoop/core-site.xmlXML<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mydoris:9000</value> <description>NameNode的地址</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/hadoop/tmp</value> <description>hadoop数据存储目录</description> </property> </configuration> -
配置hdfs-site.xml
bashvim $HADOOP_HOME/etc/hadoop/hdfs-site.xmlXML<configuration> <property> <name>dfs.replication</name> <value>1</value> <!-- 单机只需1副本 --> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property> </configuration> -
配置 yarn-site.xmlbashvim $HADOOP_HOME/etc/hadoop/yarn-site.xmlXML<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 原默认值8030与doris冲突,改为 18030 --> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>0.0.0.0:18030</value> </property> <!-- 原默认值8040与doris冲突,改为 18040 --> <property> <name>yarn.nodemanager.localizer.address</name> <value>0.0.0.0:18040</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration> -
-
配置mapred-site.xml
bashvim $HADOOP_HOME/etc/hadoop/mapred-site.xmlXML<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
-
解决Hadoop 3.4与JDK 17冲突问题
bash# 编辑 Hadoop 环境配置文件 cd /opt/module/hadoop-3.4.1 vim etc/hadoop/hadoop-env.sh # 文件末尾 添加以下内容: # Fix for JDK 17+ module access restrictions export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.lang=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.lang.reflect=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.net=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.util=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/sun.nio.ch=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.nio=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.util.concurrent=ALL-UNNAMED" # 若已经启动过hdfs,需要清理并重启hadoop # 停止 ./sbin/stop-yarn.sh ./sbin/stop-dfs.sh # 删除临时数据(避免 clusterID 冲突) rm -rf /tmp/hadoop-* # 重新格式化(使用 JDK 17) hdfs namenode -format # 启动 ./sbin/start-dfs.sh ./sbin/start-yarn.sh
启动Hadoop服务
格式化 NameNode(首次)
bash
./bin/hdfs namenode -format启动 HDFS + YARN
bash
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
验证服务
bash
jps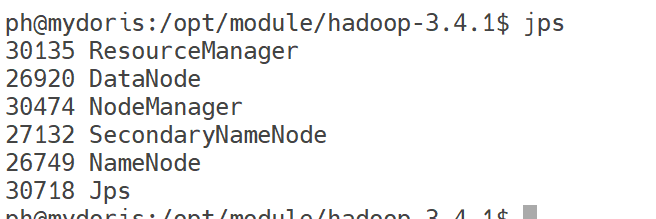
查看启动日志
日志路径:/opt/module/hadoop-3.4.1/logs/
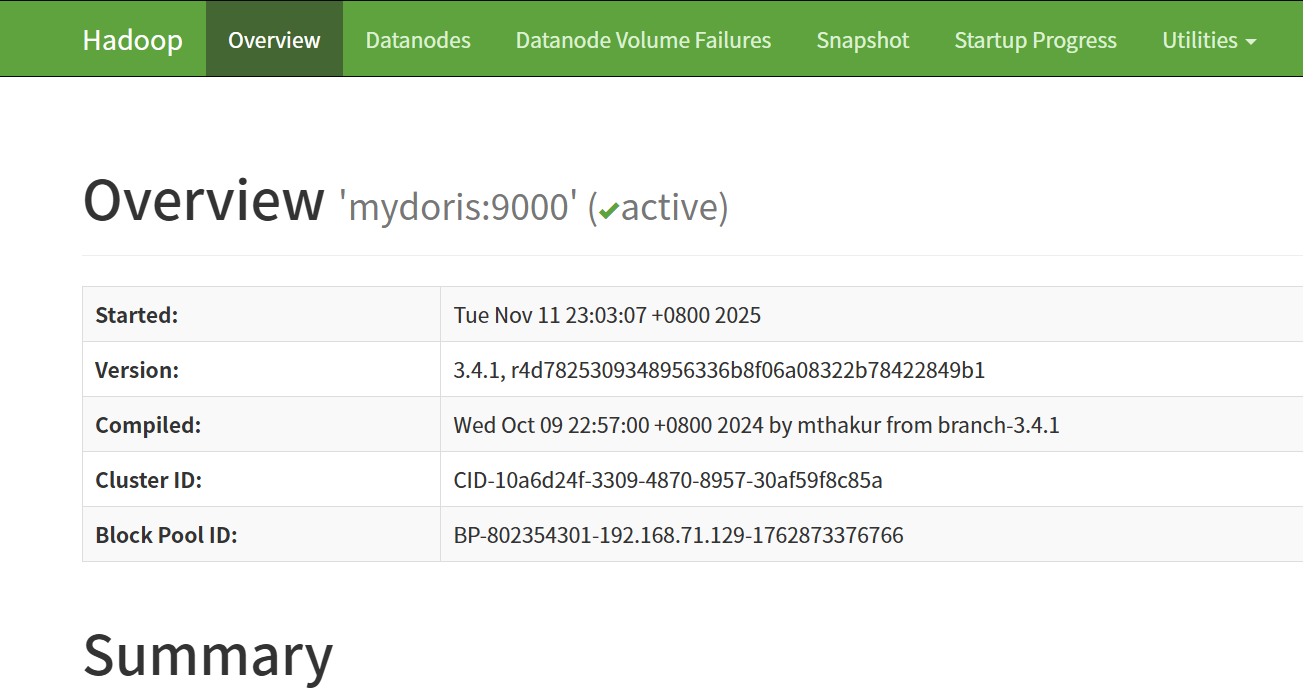
访问 WEB UI
HDFS: http://mydoris:9870
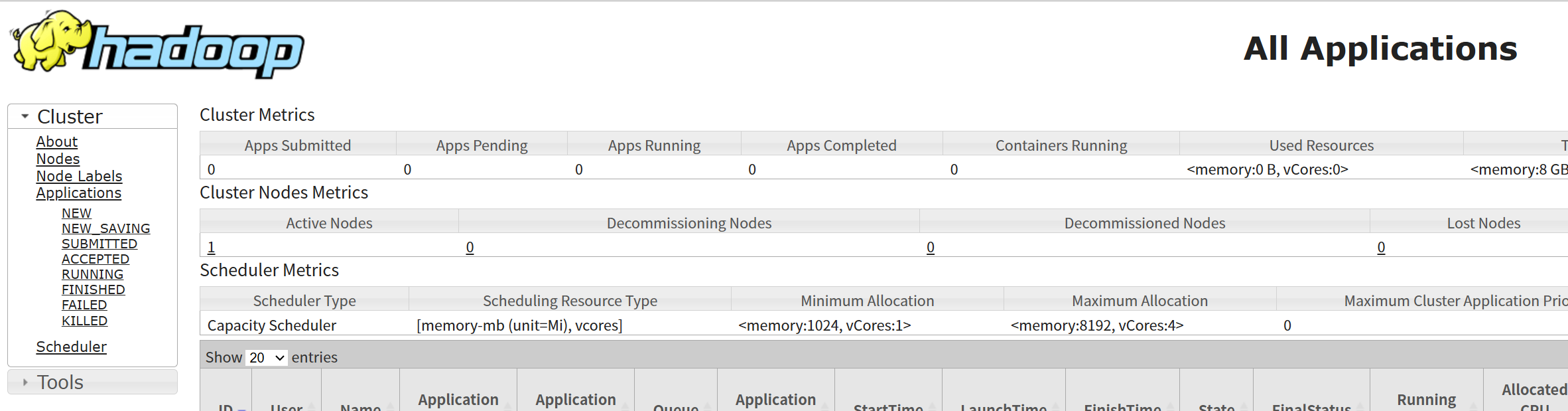
YARN: http://mydoris:8088
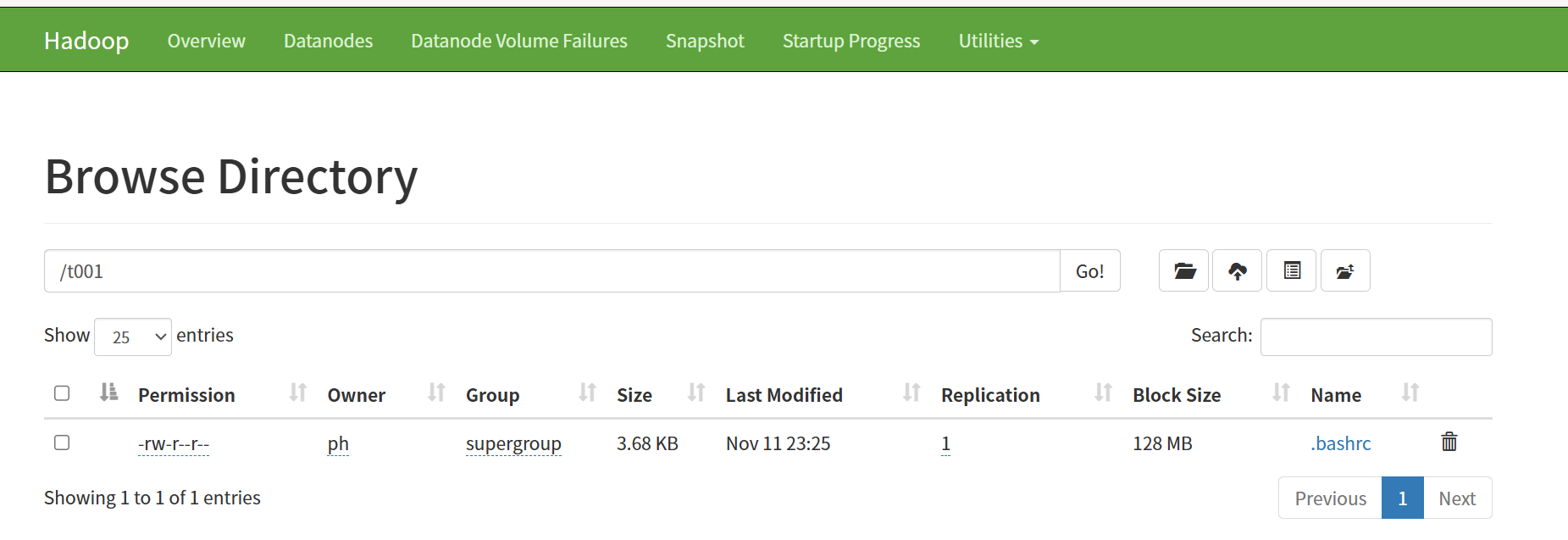
测试 HDFS 读写
bash
./bin/hadoop fs -mkdir /t001
./bin/hadoop fs -put ~/.bashrc /t001/
./bin/hadoop fs -ls /t001
启停脚本
-
创建脚本文件:vim /opt/script/xhadoop
bash#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") ssh mydoris "${HADOOP_HOME}/sbin/start-dfs.sh" ssh mydoris "${HADOOP_HOME}/sbin/start-yarn.sh" ;; "stop") ssh mydoris "${HADOOP_HOME}/sbin/stop-dfs.sh" ssh mydoris "${HADOOP_HOME}/sbin/stop-yarn.sh" ;; *) echo "Input Args Error..." ;; esac -
修改脚本权限 chmod 777 /opt/script/xhadoop
-
添加一个链接 sudo ln -s -f /opt/script/xhadoop /bin/xhadoop
-
使用脚本
xhadoop start
xhadoop stop
数据湖 Iceberg 1.6.1
HIve Catalog
MySQL 8.0.43
-
在线安装MySQL
bash# 更新软件包列表 sudo apt update # 查看可使用的安装包 sudo apt search mysql-server # 安装最新版本 sudo apt install -y mysql-server # 安装指定版本: sudo apt install -y mysql-server-8.0 -
检查MySQL状态
bashsudo systemctl status mysql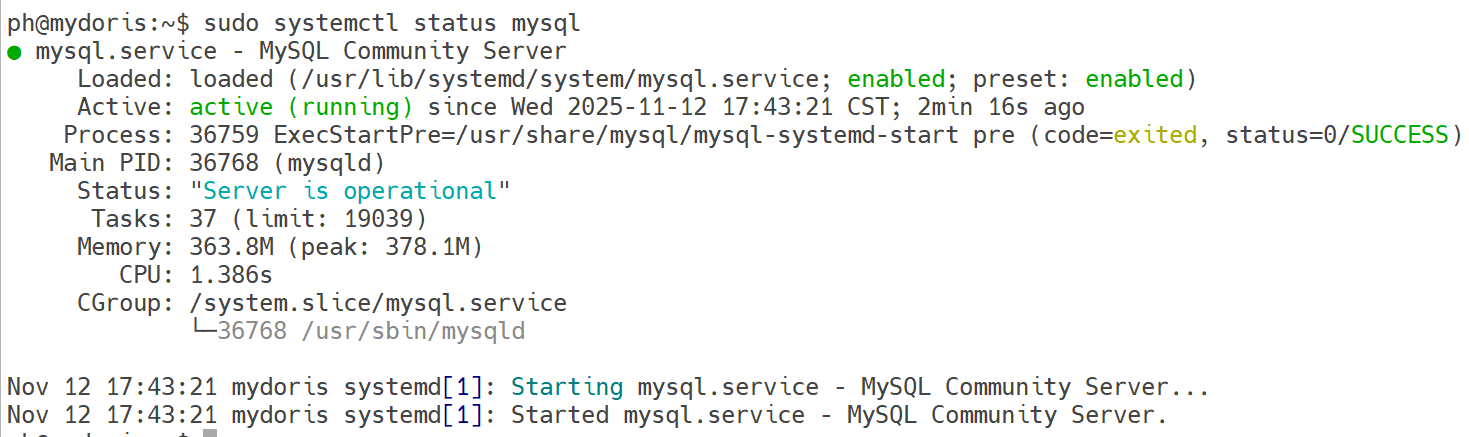 bash
bash# 解压文件 tar -xJf mysql-8.0.43-linux-glibc2.17-x86_64.tar.xz mv mysql-8.0.43-linux-glibc2.17-x86_64 /opt/module/ # 创建软链接 sudo ln -s /opt/module/mysql-8.0.43-linux-glibc2.17-x86_64 /usr/local/mysql -
设置开机启动
bash# 启动MySQL服务(默认安装后会自动启动,不需要再执行) sudo systemctl start mysql # 设置开机自启动: sudo systemctl enable mysql -
修改密码、权限、允许远程访问
-
登录mysql,在默认安装时如果没有让我们设置密码,则直接回车就能登录成功
sudo mysql -u root -p -
设置密码:ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY ' Admin1234 ';
-
刷新缓存:flush privileges;
-
use mysql
-
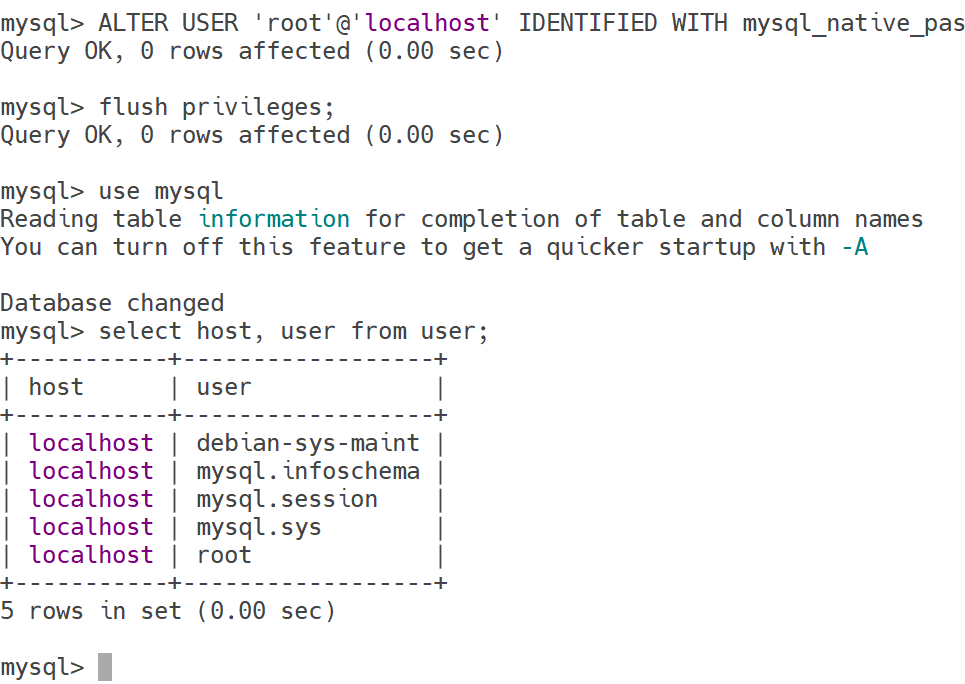
检查用户可在哪台主机访问数据库
select host, user from user;
-
修改root可在任意位置访问:update user set host = '%' where user = 'root';
-
配置mysqld.cnf
bashsudo vim /etc/mysql/mysql.conf.d/mysqld.cnf bind-address = 0.0.0.0 mysqlx-bind-address = 0.0.0.0 -
重启MySQL重新加载一下配置:sudo systemctl restart mysql
-
检查端口:netstat -an | grep 3306
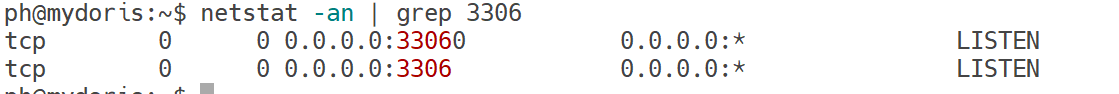
-
创建 Hive Metastore 数据库和用户
sqlmysql -u root -p CREATE DATABASE hive_metastore; CREATE USER 'hive'@'%' IDENTIFIED BY 'Admin1234'; GRANT ALL PRIVILEGES ON hive_metastore.* TO 'hive'@'%'; FLUSH PRIVILEGES; EXIT; SELECT SCHEMA_NAME FROM information_schema.SCHEMATA WHERE SCHEMA_NAME = 'hive_metastore';
-
hive-3.1.3
-
上传 apache-hive-3.1.3-bin.tar.gz 到服务器
-
解压安装
bashtar -xzf apache-hive-3.1.3-bin.tar.gz mv apache-hive-3.1.3-bin /opt/module mv /opt/module/apache-hive-3.1.3-bin/ /opt/modulehive-3.1.3 -
设置hive环境变量
bashsudo vim /etc/profile.d/myprofile.sh #设置 hive 环境变量 export HIVE_HOME=/opt/module/hive-3.1.3 export PATH=$PATH:$HIVE_HOME/bin # 使配置生效 source /etc/profile -
添加依赖JAR
bash# MySQL 驱动(必须) 将 mysql-connector-java-8.0.33.jar 放到 $HIVE_HOME/lib/ # Iceberg Hive Runtime(关键!让 HMS 识别 Iceberg 表) 将 iceberg-hive-runtime-1.6.1.jar 放到 $HIVE_HOME/lib/ -
配置 hive-site.xml
vim $HIVE_HOME/conf/hive-site.xmlXML<?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- Mysql MetaStore --> <property> <name>hive.metastore.db.type</name> <value>mysql</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://mydoris:3306/hive_metastore?useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>Admin1234</value> </property> <!-- Hive Metastore Service --> <property> <name>hive.metastore.uris</name> <value>thrift://mydoris:9083</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!-- Iceberg 支持 --> <property> <name>metastore.storage.schema.reader.impl</name> <value>org.apache.hadoop.hive.metastore.SerDeStorageSchemaReader</value> </property> <!-- 重要:指定 warehouse 基于 HDFS --> <property> <name>hive.metastore.warehouse.dir</name> <value>/iceberg/warehouse</value> <!-- HDFS 路径 --> </property> </configuration> -
初始化 Metastore Schema
bash$HIVE_HOME/bin/schematool -dbType mysql -initSchema \ -userName hive -passWord Admin1234 \ -url "jdbc:mysql://mydoris:3306/hive_metastore?useSSL=false&allowPublicKeyRetrieval=true" -
启动 Hive Metastore
bash$HIVE_HOME/bin/hive --service metastore -
验证
netstat -tuln | grep 9083
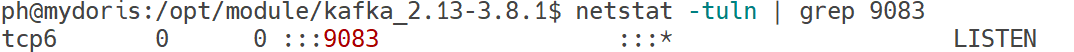
启停脚本
-
创建脚本文件:vim /opt/script/xhive
-
脚本内容
bash#!/bin/bash # Hive Metastore 启停脚本 for Hive 3.1.3 # 支持 start / stop / status export HIVE_HOME=${HIVE_HOME:-/opt/module/hive-3.1.3} export HADOOP_HOME=${HADOOP_HOME:-/opt/module/hadoop-3.4.1} LOG_DIR="$HIVE_HOME/logs" PID_FILE="$LOG_DIR/metastore.pid" PORT=${METASTORE_PORT:-9083} HOST=${METASTORE_HOST:-localhost} mkdir -p "$LOG_DIR" start() { if [ -f "$PID_FILE" ] && kill -0 $(cat "$PID_FILE") 2>/dev/null; then echo "Hive Metastore is already running (PID: $(cat $PID_FILE))" exit 1 fi echo "Starting Hive Metastore on $HOST:$PORT ..." nohup "$HIVE_HOME/bin/hive" --service metastore \ > "$LOG_DIR/metastore.log" 2>&1 & echo $! > "$PID_FILE" sleep 2 if kill -0 $(cat "$PID_FILE") 2>/dev/null; then echo "Hive Metastore started successfully (PID: $(cat $PID_FILE))" else echo "Failed to start Hive Metastore. Check $LOG_DIR/metastore.log" rm -f "$PID_FILE" exit 1 fi } stop() { if [ ! -f "$PID_FILE" ]; then echo "Not running." return 0 fi PID=$(cat "$PID_FILE") if ! kill -0 "$PID" 2>/dev/null; then echo "Stale PID." rm -f "$PID_FILE" return 0 fi echo "Stopping Metastore (PID: $PID)..." kill "$PID" # SIGTERM - 优雅 sleep 8 if kill -0 "$PID" 2>/dev/null; then kill -9 "$PID" # SIGKILL - 强制 fi rm -f "$PID_FILE" echo "Stopped." } status() { if [ -f "$PID_FILE" ]; then PID=$(cat "$PID_FILE") if kill -0 "$PID" 2>/dev/null; then echo "Hive Metastore is running (PID: $PID)" echo "Log: tail -f $LOG_DIR/metastore.log" return 0 else echo "Hive Metastore is NOT running (stale PID file)." rm -f "$PID_FILE" return 1 fi else echo "Hive Metastore is NOT running." return 1 fi } case "$1" in start) start ;; stop) stop ;; restart) stop sleep 2 start ;; status) status ;; *) echo "Usage: $0 {start|stop|restart|status}" exit 1 ;; esac -
修改脚本权限 chmod 777 /opt/script/xhive
-
添加一个链接 : sudo ln -s -f /opt/script/xhive /bin/xhive
-
使用脚本
xhive start
xhive stop
xhive restart
xhive status
消息队列 kafka_2.13-3.8.1
安装配置
-
将压缩包 kafka_2.13-3.8.1.tgz 上传到服务器
-
解压安装:tar -zxvf /opt/software/kafka_2.13-3.8.1.tgz -C /opt/module/
-
添加环境变量
bashsudo vim /etc/profile.d/myprofile.sh # 设置kafka环境变量 export KAFKA_HOME=/opt/module/kafka_2.13-3.8.1 export PATH=$PATH:$KAFKA_HOME/bin # 重新加载配置 source /etc/profile
配置 KRaft 模式
-
创建数据目录 mkdir -p /opt/data/kafka/kraft-logs
-
编辑配置文件
bashcp $KAFKA_HOME/config/kraft/server.properties $KAFKA_HOME/config/kraft/server.properties.bak vim $KAFKA_HOME/config/kraft/server.properties log.dirs=/opt/data/kafka/kraft-logs -
生成 Cluster ID(唯一标识)
bashKAFKA_CLUSTER_ID=$($KAFKA_HOME/bin/kafka-storage.sh random-uuid) echo $KAFKA_CLUSTER_ID # 保存这个值,例如:pHsOvoSPR8-tocrVrTTrQw -
格式化数据目录
bash$KAFKA_HOME/bin/kafka-storage.sh format \ -t $KAFKA_CLUSTER_ID \ -c $KAFKA_HOME/config/kraft/server.properties -
验证 meta.properties 是否生成
bashcat /opt/data/kafka/kraft-logs/meta.properties
-
启动 Kafka
bash$KAFKA_HOME/bin/kafka-server-start.sh \ $KAFKA_HOME/config/kraft/server.properties
功能测试
bash
# 创建主题
./bin/kafka-topics.sh --create --topic user_events --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1
# 查看主题
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
# 查询主题
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic user_events
# 删除主题
./bin/kafka-topics.sh --delete --topic user_events --bootstrap-server localhost:9092启停脚本
bash
#!/bin/bash
CONFIG=$KAFKA_HOME/config/kraft/server.properties
LOG_DIR=/opt/data/kafka/kraft-logs
PID_FILE=$LOG_DIR/kafka.pid
start() {
if [ -f "$PID_FILE" ] && kill -0 $(cat $PID_FILE) 2>/dev/null; then
echo "Kafka already running (PID: $(cat $PID_FILE))"
exit 1
fi
nohup $KAFKA_HOME/bin/kafka-server-start.sh $CONFIG \
> $LOG_DIR/kafka.log 2>&1 &
echo $! > $PID_FILE
echo "Started Kafka (PID: $(cat $PID_FILE))"
}
stop() {
if [ ! -f "$PID_FILE" ]; then
echo "Kafka not running"
return
fi
kill $(cat $PID_FILE)
sleep 5
rm -f $PID_FILE
echo "Kafka stopped"
}
case $1 in
start) start ;;
stop) stop ;;
restart) stop; sleep 2; start ;;
*) echo "Usage: $0 {start|stop|restart}" ;;
esacxkafka start
xkafka stop
xkafka restart
OLAP doris 3.0.8
修改环境变量
-
修改系统最大打开文件句柄数(需重新登录生效)
bashsudo vim /etc/security/limits.conf * soft nofile 1000000 * hard nofile 1000000 -
修改虚拟内存区域
bashsudo vim /etc/sysctl.conf vm.max_map_count=2000000 # 应用更改 sudo sysctl -p # 检查 cat /proc/sys/vm/max_map_count -
检查主机是否支持 AVX2 指令集
bashcat /proc/cpuinfo | grep avx2 # 若有输出表示机器支持 AVX2 指令集,使用apache-doris-2.1.8.1-bin-x64.tar.gz # 否则使用apache-doris-2.1.8.1-bin-x64-noavx2.tar.gz
准备安装介质
从Apache Doris - Download | Easily deploy Doris anywhere - Apache Doris下载doris安装介质
apache-doris-3.0.8-bin-x64.tar
解压安装
-
将压缩包apache-doris-3.0.8-bin-x64.tar.gz上传到服务器
-
解压安装
bashtar -zxvf apache-doris-3.0.8-bin-x64.tar.gz -C /opt/module/ mv /opt/module/apache-doris-3.0.8-bin-x64/ /opt/module/doris-3.0.8
Doris 配置
-
配置环境变量
bashsudo vim /etc/profile.d/myprofile.sh #设置DORIS环境变量 export DORIS_HOME=/opt/module/doris-3.0.8 export PATH=$DORIS_HOME/fe/bin:$DORIS_HOME/be/bin:$PATH # 使配置生效 source /etc/profile -
配置FE元数据目录(仅FE主机)
bash# 选择独立于 BE 数据的硬盘,创建 FE 的元数据目录 mkdir -p /opt/data/doris/meta vim $DORIS_HOME/fe/conf/fe.conf meta_dir = /opt/data/doris/meta
iceberg配置
bash
vim $DORIS_HOME/fe/conf/fe.conf
# iceberg 配置
catalog.iceberg_hive.type=iceberg
catalog.iceberg_hive.hive.metastore.uris=thrift://mydoris:9083
catalog.iceberg_hive.hadoop_conf_path=/opt/module/hadoop-3.4.1/etc/hadoop启停脚本
|------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 后台启停 | $DORIS_HOME/fe/bin/start_fe.sh --daemon $DORIS_HOME/be/bin/start_be.sh --daemon $DORIS_HOME/fe/bin/stop_fe.sh --daemon $DORIS_HOME/be/bin/stop_be.sh --daemon |
| 前台启停 | $DORIS_HOME/fe/bin/start_fe.sh $DORIS_HOME/be/bin/start_be.sh |
| 脚本启停 | xdoris start xdoris stop |
-
创建脚本文件:vim /opt/script/xdoris
bash#!/bin/bash # 定义节点列表和路径 NODES=("mydoris") DORIS_HOME="/opt/module/doris-3.0.8" JAVA_HOME="/opt/module/jdk-17.0.10" # 检查参数是否有效 case $1 in "start"|"stop") ;; *) echo "Invalid Args!" echo "Usage: $(basename $0) start|stop" exit 1 ;; esac # 定义启动和停止函数 start_node() { local NODE=$1 echo "Starting BE on $NODE..." ssh -o ConnectTimeout=5 $NODE "export JAVA_HOME=$JAVA_HOME && cd $DORIS_HOME && ./be/bin/start_be.sh --daemon" if [ $? -ne 0 ]; then echo "Failed to start BE on $NODE." return 1 else echo "Successfully started BE on $NODE." fi } stop_node() { local NODE=$1 echo "Stopping BE on $NODE..." ssh -o ConnectTimeout=5 $NODE "export JAVA_HOME=$JAVA_HOME && cd $DORIS_HOME && ./be/bin/stop_be.sh" if [ $? -ne 0 ]; then echo "Failed to stop BE on $NODE." return 1 else echo "Successfully stopped BE on $NODE." fi } # 主逻辑 case $1 in "start") # 启动 FE echo "Starting FE" ssh -o ConnectTimeout=5 mydoris "export JAVA_HOME=$JAVA_HOME && cd $DORIS_HOME && ./fe/bin/start_fe.sh --daemon" if [ $? -ne 0 ]; then echo "Failed to start FE on mydoris." exit 1 fi # 启动每个 BE 节点 for NODE in "${NODES[@]}"; do start_node $NODE & done wait echo "Cluster started successfully." ;; "stop") # 停止每个 BE 节点 for NODE in "${NODES[@]}"; do stop_node $NODE done # 停止 FE echo "Stopping FE on mydoris..." ssh -o ConnectTimeout=5 mydoris "export JAVA_HOME=$JAVA_HOME && cd $DORIS_HOME && ./fe/bin/stop_fe.sh" if [ $? -ne 0 ]; then echo "Failed to stop FE on mydoris." exit 1 fi echo "Cluster stopped successfully." ;; esac -
修改脚本权限
chmod 777 /opt/script/xdoris -
添加一个链接
sudo ln -s -f /opt/script/xdoris /bin/xdoris -
使用脚本
xdoris start
xdoris stop
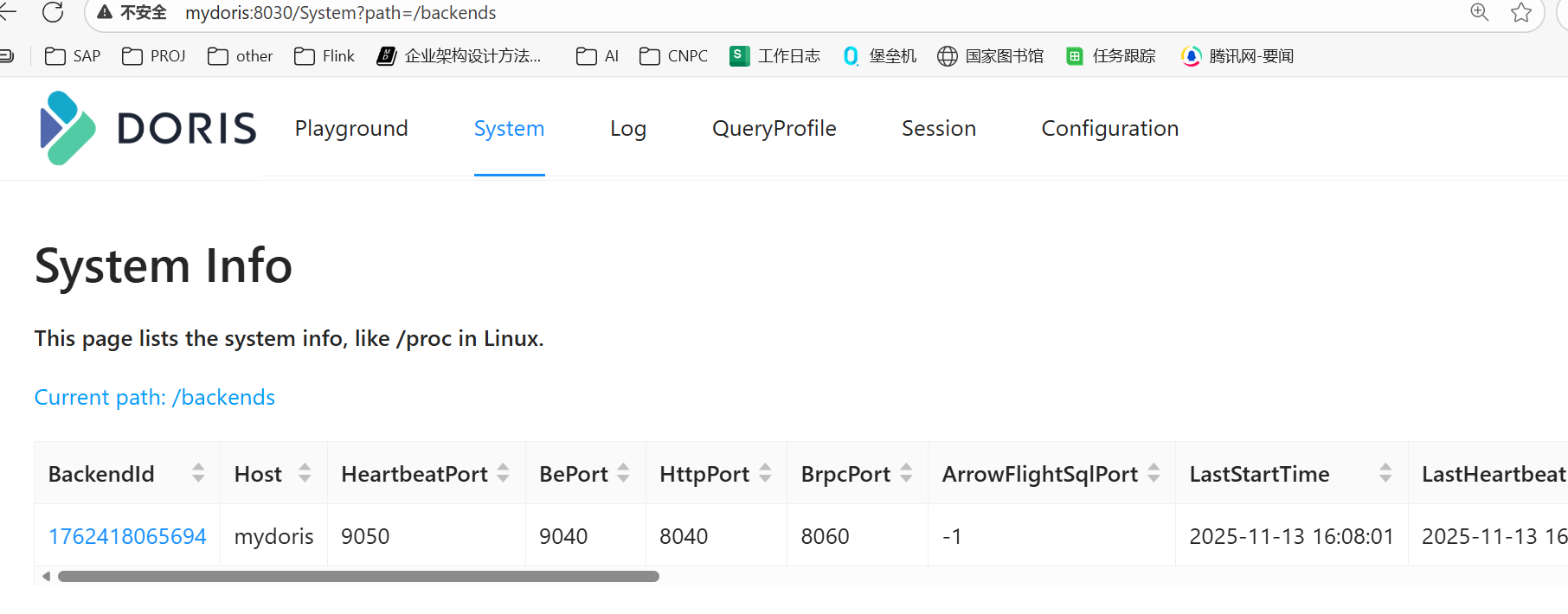
注册 BE 节点(仅一次)
-
配置dbeaver连接
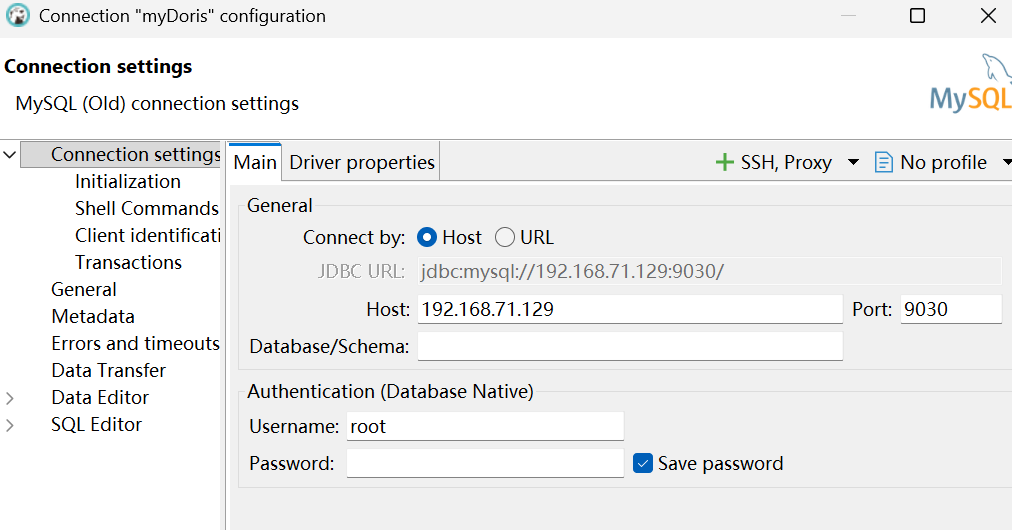
-
使用SQL命令添加BE(仅需执行一次)
sqlALTER SYSTEM ADD BACKEND "mydoris:9050";
登录
-
打开页面:http://mydoris:8030/
-
用户 root 密码 空

-
检查BE注册情况
-
查询iceberg表数据
sql-- 查看 Catalog SHOW CATALOGS; -- 切换 catalog SWITCH iceberg_hive; -- 查看 database SHOW DATABASES; -- 切换 database USE default_db; -- 查看表 show tables; -- 查看数据 SELECT * FROM iceberg_hive.default_db.user_events;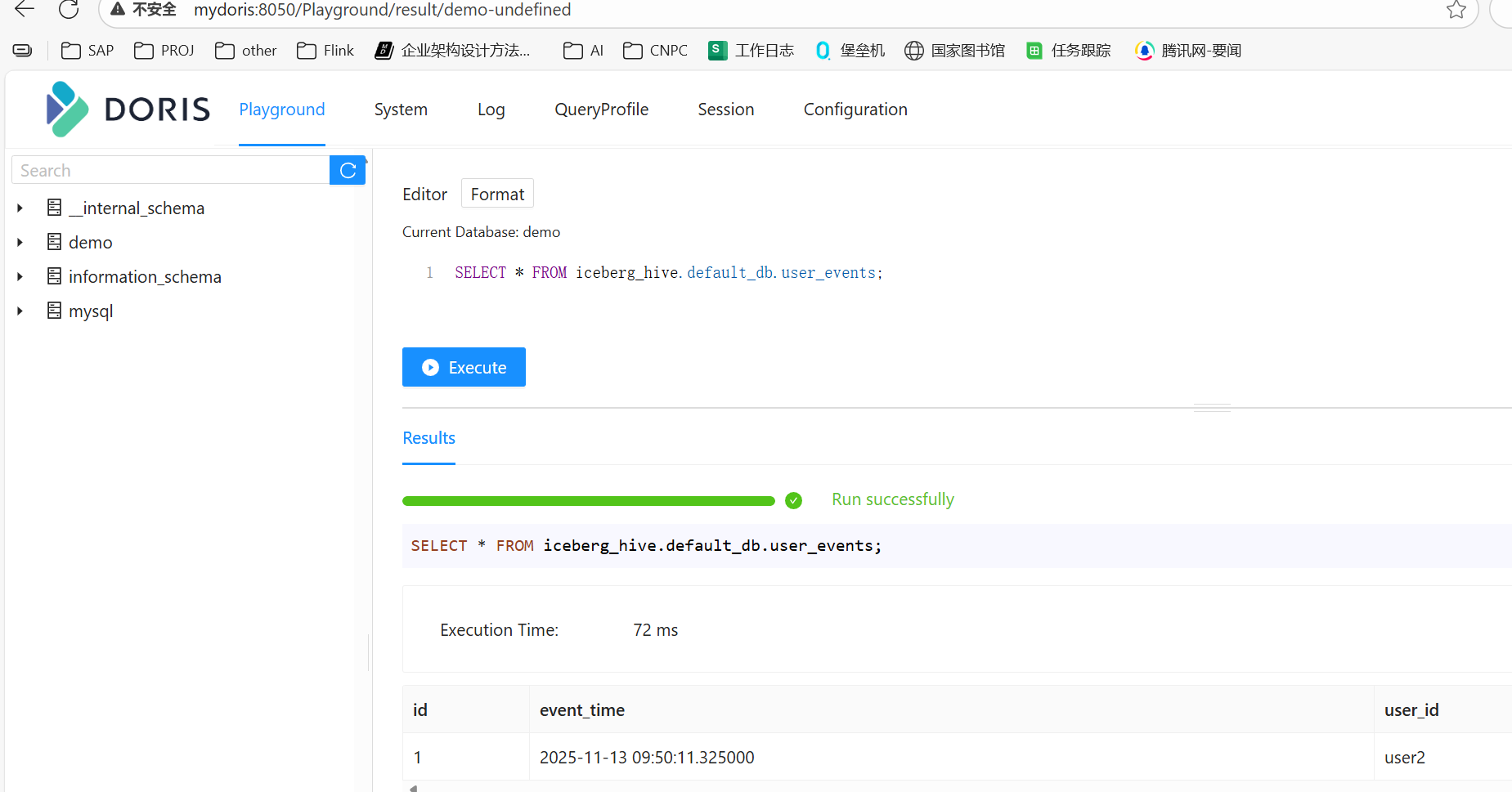
修改root 密码
默认root密码为空,需修改为非空
sql
mysql -h mydoris -P 9030 -uroot
SET PASSWORD FOR 'root' = PASSWORD('Admin1234');计算引擎 Flink 1.18.1
安装配置
-
将压缩包 flink-1.18.1-bin-scala_2.12.gz上传到服务器
-
解压安装
tar -zxvf flink-1.18.1-bin-scala_2.12.tgz -C /opt/module/ -
配置环境变量
bashsudo vim /etc/profile.d/myprofile.sh #设置 flink 环境变量 export FLINK_HOME=/opt/module/flink-1.18.1 export PATH=$FLINK_HOME/bin:$PATH # 配置生效 source /etc/profile -
配置flink-conf
sqlvim $FLINK_HOME/conf/flink-conf.yaml # flink web ui 可在外部访问 rest.bind-address: 0.0.0.0 rest.address: mydoris # 设置taskmanager有4个作业Slot taskmanager.numberOfTaskSlots: 4 -
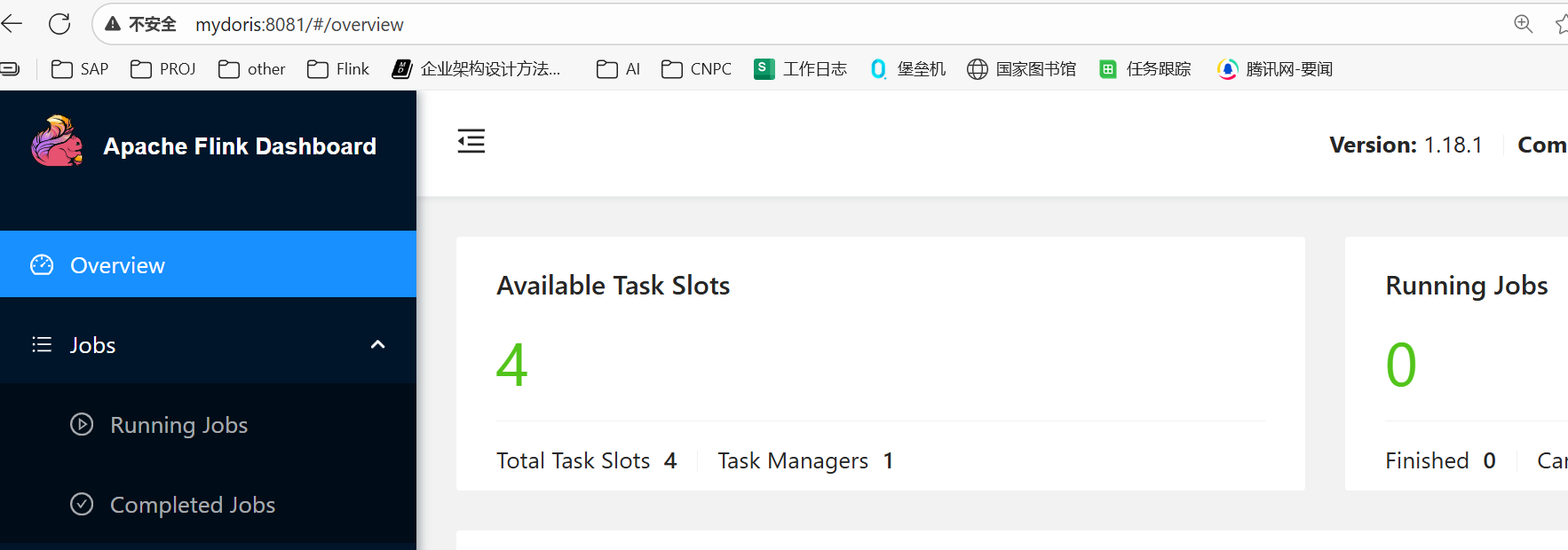
启动集群:$FLINK_HOME/bin/start-cluster.sh
-
访问Flink Web UI
http://mydoris:8081
启停脚本
bash
#!/bin/bash
# 检查是否传入参数
if [ $# -lt 1 ]; then
echo "No Args Input..."
echo "Usage: $0 {start|stop}"
exit 1
fi
# 定义环境变量
JAVA_HOME="/opt/module/jdk-17.0.10"
FLINK_HOME=${FLINK_HOME:-"/opt/module/flink-1.18.1"} # 如果未设置 FLINK_HOME,则使用默认路径
# 获取命令参数
case $1 in
"start")
echo "============== 启动 Flink 集群 ==================="
# 检查 FLINK_HOME 是否有效
if [ ! -d "$FLINK_HOME" ]; then
echo "Error: FLINK_HOME ($FLINK_HOME) 路径不存在,请检查配置。"
exit 1
fi
# 启动 Flink 集群
ssh mydoris "export JAVA_HOME=$JAVA_HOME && ${FLINK_HOME}/bin/start-cluster.sh"
;;
"stop")
echo "============== 关闭 Flink 集群 ==================="
# 检查 FLINK_HOME 是否有效
if [ ! -d "$FLINK_HOME" ]; then
echo "Error: FLINK_HOME ($FLINK_HOME) 路径不存在,请检查配置。"
exit 1
fi
# 停止 Flink 集群
ssh mydoris "export JAVA_HOME=$JAVA_HOME && ${FLINK_HOME}/bin/stop-cluster.sh"
;;
*)
echo "Input Args Error... Usage: $0 {start|stop}"
exit 1
;;
esac场景练习
Iceberg 建表
- 创建 SQL 初始化文件
bash
cat > $FLINK_HOME/conf/init-iceberg.sql <<'EOF'
-- 创建 Iceberg catalog
CREATE CATALOG iceberg_hms WITH (
'type' = 'iceberg',
'catalog-type' = 'hive',
'uri' = 'thrift://mydoris:9083',
'warehouse' = 'hdfs://mydoris:9000/user/hive/warehouse',
'clients' = '5'
);
EOF-
打开客户端
bash$FLINK_HOME/bin/sql-client.sh -i $FLINK_HOME/conf/init-iceberg.sql bash
bash# 客户端启动有问题,可临时使用日志 # 临时开启 SQL Client 的 DEBUG 日志 # 备份原日志配置 cp $FLINK_HOME/conf/log4j-cli.properties $FLINK_HOME/conf/log4j-cli.properties.bak # 添加 DEBUG 配置 cat >> $FLINK_HOME/conf/log4j-cli.properties <<EOF logger.iceberg.name = org.apache.iceberg logger.iceberg.level = DEBUG logger.client.name = org.apache.flink.table.client logger.client.level = DEBUG EOF # 启动 SQL Client 并查看日志 cat /opt/module/flink-1.18.1/log/flink-ph-sql-client-mydoris.log -
操作数据表
sql-- 如果不是 iceberg_hms,则需切换或加前缀 SHOW CATALOGS; SHOW CURRENT CATALOG; USE CATALOG iceberg_hms; -- SHOW DATABASES; -- 创建数据库(如果 default_db 不存在) CREATE DATABASE IF NOT EXISTS default_db; -- 切换到该库 USE default_db; -- 在 Iceberg 中建表 CREATE TABLE default_db.user_events ( id BIGINT, event_time TIMESTAMP(3), user_id STRING, event_type STRING ) PARTITIONED BY (event_time) WITH ( 'write.format.default' = 'parquet', 'write.target-file-size-bytes' = '536870912', -- 512MB 'format-version' = '2' ); -- 看有哪些表 SHOW TABLES; -- 描述表 DESCRIBE user_events; -- 插入数据 INSERT INTO user_events VALUES (1, NOW(), 'user2', 'click'); -- 查询数据 SELECT * FROM user_events; -
在mysql通过查询元数据看iceberg中有哪些表
sqlSELECT t.TBL_NAME FROM TBLS t JOIN TABLE_PARAMS p ON t.TBL_ID = p.TBL_ID WHERE p.PARAM_KEY = 'table_type' AND p.PARAM_VALUE = 'ICEBERG';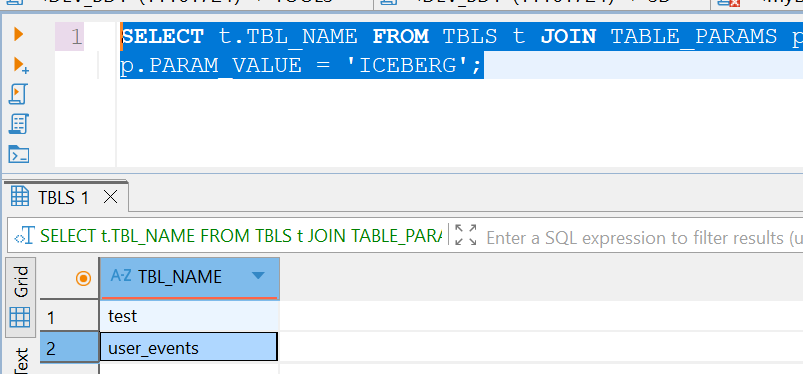
flink CDC
-
解压安装 flink-cdc-3.0.0-bin.tar.gz
tar -xzvf flink-cdc-3.0.0-bin.tar.gz -
将连接器上载到lib
ph@mydoris:/opt/module/flink-cdc-3.0.0/lib$ ls *pip*con* flink-cdc-pipeline-connector-doris-3.0.0.jar flink-cdc-pipeline-connector-mysql-3.0.0.jar -
开启 checkpoint
bashvim $FLINK_HOME/conf/flink-conf.yaml # 每15一次 execution.checkpointing.interval: 15000 # 重启集群 $FLINK_HOME/bin/stop-cluster.sh $FLINK_HOME/bin/start-cluster.sh -
在mysql数据库准备同步数据
sql-- 创建数据库 CREATE DATABASE app_db; USE app_db; -- 创建 orders 表 CREATE TABLE `orders` ( `id` INT NOT NULL, `price` DECIMAL(10,2) NOT NULL, PRIMARY KEY (`id`) ); -- 插入数据 INSERT INTO `orders` (`id`, `price`) VALUES (1, 4.00); INSERT INTO `orders` (`id`, `price`) VALUES (2, 100.00); -- 创建 shipments 表 CREATE TABLE `shipments` ( `id` INT NOT NULL, `city` VARCHAR(255) NOT NULL, PRIMARY KEY (`id`) ); -- 插入数据 INSERT INTO `shipments` (`id`, `city`) VALUES (1, 'beijing'); INSERT INTO `shipments` (`id`, `city`) VALUES (2, 'xian'); -- 创建 products 表 CREATE TABLE `products` ( `id` INT NOT NULL, `product` VARCHAR(255) NOT NULL, PRIMARY KEY (`id`) ); -- 插入数据 INSERT INTO `products` (`id`, `product`) VALUES (1, 'Beer'); INSERT INTO `products` (`id`, `product`) VALUES (2, 'Cap'); INSERT INTO `products` (`id`, `product`) VALUES (3, 'Peanut'); -
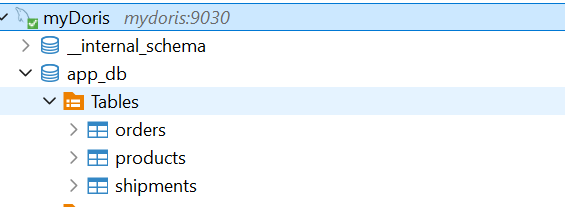
在doris中创建数据库
sqlcreate database app_db; -
创建整库同步任务配置文件
mysql-to-doris.yamlsql################################################################################ # Description: Sync MySQL all tables to Doris ################################################################################ source: type: mysql hostname: mydoris port: 3306 username: root password: Admin1234 tables: app_db.\.* server-id: 5400-5404 server-time-zone: UTC+8 sink: type: doris fenodes: mydoris:8030 username: root password: "Admin1234" table.create.properties.light_schema_change: true table.create.properties.replication_num: 1 pipeline: name: Sync MySQL Database to Doris parallelism: 2 -
通过命令行提交任务到 Flink Standalone cluster
sqlph@mydoris:/opt/module/flink-cdc-3.0.0/yaml$ /opt/module/flink-cdc-3.0.0/bin/flink-cdc.sh mysql-to-doris.yaml Pipeline has been submitted to cluster. Job ID: daf31e7e87299e00dcd398ae217874d8 Job Description: Sync MySQL Database to Doris -
查看作业

-
查看表已经同步