常见数据包含以下格式
1,明文字符串
字符传格式
明文字符串:hello world
json字符串:{"key":"value"}
编码库
常见格式有UTF-8 ISO-8859-1 US-ASCII UTF-16BE gbk
字符串编码和解码常识
当一个字符,数字或者一个中文,在一个编码库里面能够找到,就能够被编码成对应的字节,否则会出错,也没办法在该编码库解码回来
2,字节数组
就是一个数组,里面的每个元素代表一个字节,每个字节的范围是【0,255】或者【-128,127】
范围在【128-255】有符号位会转为负数
也就是有符号和无符号,可以相互转换的
转换方式有两种,结果都一样
1:取反+1
| 比如说-1用2进制表示就是 1 0000 0001 取反+1就是 0 1111 1110 加上1就是 0 1111 1111 也就是255了 |
|---|
| 比如说-128用2进制表示就是 1 1000 0000 取反+1就是 0 0111 1111 加上1就是 0 1000 0000 也就是128了 |
注
| 红色位为字节的符号位 |
|---|
| 因为一个字节是8个位计算方式就是一个符号位+8个数值位 |
| 短整型是2个字节也是一个符号位+16个数值位 |
| 整型是4个字节也是一个符号位+32个数值位 |
2:负数+256就是正数
| 比如说-1加上256就是255 |
|---|
| -128+256就是128 |
注
| 这个256是2的8次方 |
|---|
| 如果是短整型这个就是2的16次方了也就是256的2次方了 |
| 整型这个就是2的32次方了也就是256的4次方了 |
3,二进制,16进制
二进制就是 0b01010101 这种,一个字节有8个位
0b代表后续的数值是二进制格式
十六进制就是 0xFFFF这种,一个字节用两个16进制字符表示
0x代表后续的数值是16进制的
8个二进制位和两个16进制字符就是一个字节,可以互相转换完全等价
字节数组转换成16进制和2进制格式更容易被读懂
比如说0xFF就是一个字节的字节的最大值
0b1111 1111就是一个字节的所有位都是true
4,base64
Base64,就是包括小写字母a-z、大写字母A-Z、数字0-9、符号"+"、"/"一共64个字符的字符集
个数计算: 26+26+10+2 = 64
可以参考表
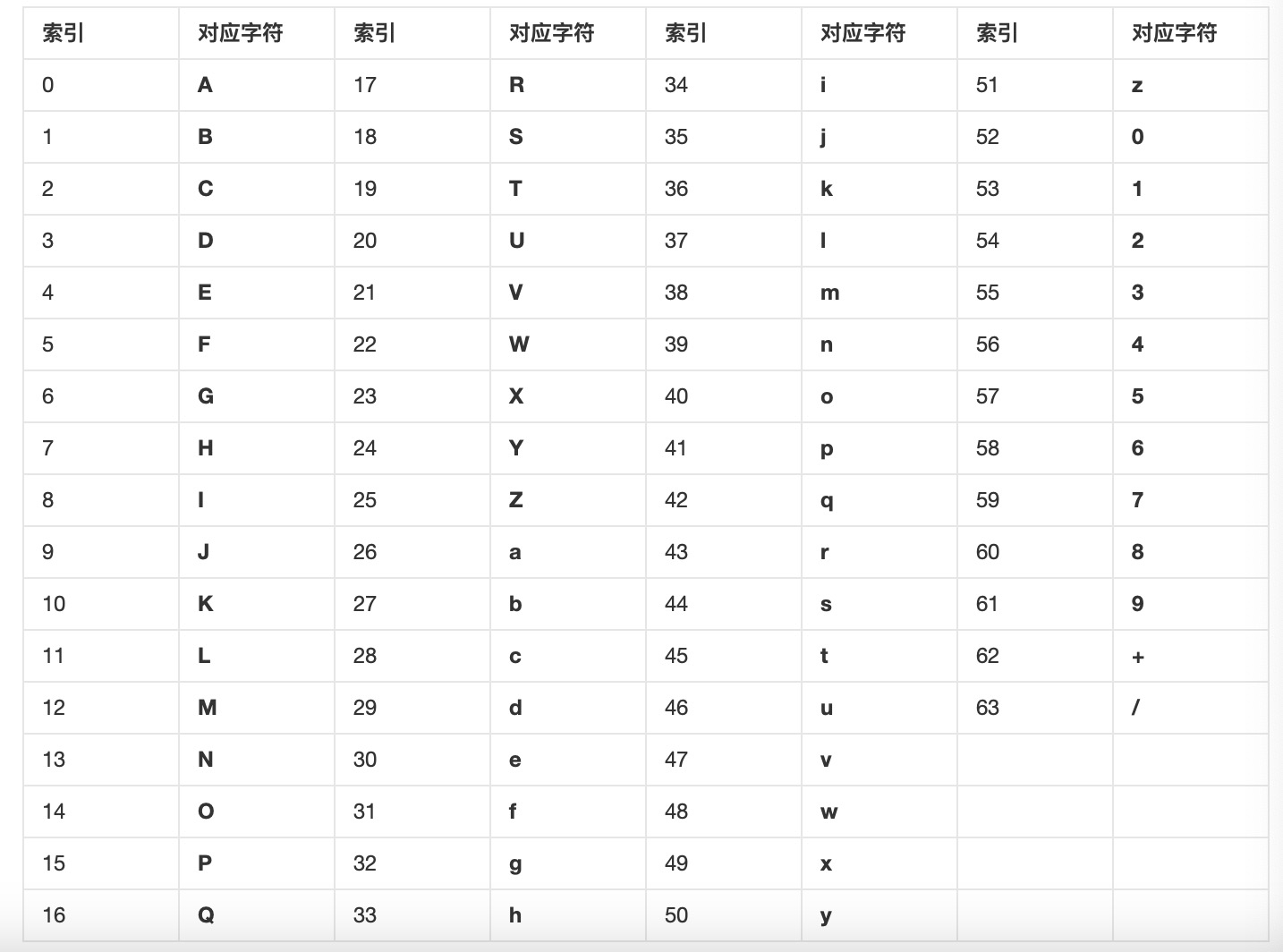
分别代表0-63二进制表示就是0b00 0000到0b11 1111,6个位就够了
6个二进制位代表一个base64字符,所以字节数组可以和base64互相转换完全等价
字节数组转换成base64的原理
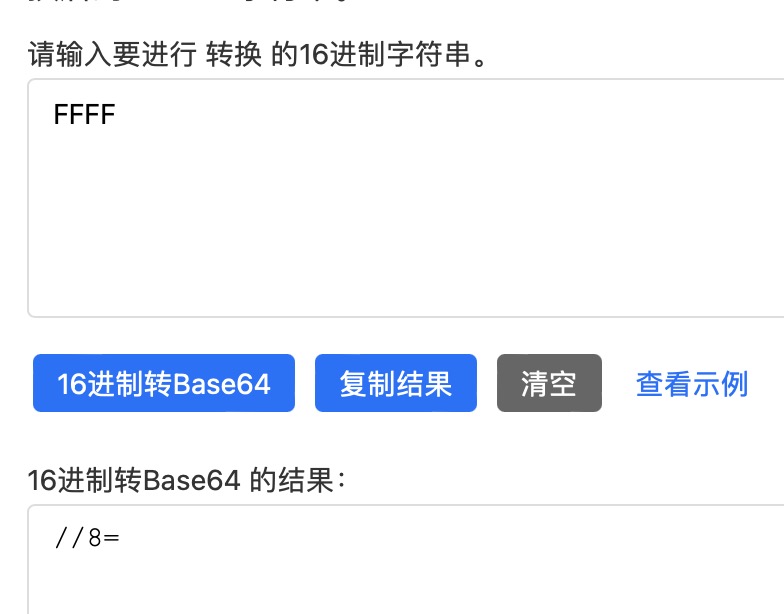
比如说一个字节数组【255,255】长度是2,也就是有两个字节,那么就是16个位
也就是 0b1111 1111 1111 1111 这种
拆分成 0b111111 111111 1111 三部分也就是三个字符
0b111111 0b111111 0b111100
转成base64就是"//8"
因为最后一部分只有四个位需要末尾补充2个0,每补充两个位base64的末尾要加上一个 "="号
最终结果base64就是"//8="
下面是用在线工具转的结果
常见数据格式的转换(以java为例)
1,字符串转字节数组
java
/**
* 字符串编码位字节数组
* @param string 传入的字符串
* @param charset 编码格式 默认utf-8
* 常见格式有UTF-8 ISO-8859-1 US-ASCII UTF-16BE gbk
* @return
*/
public static byte[] stringToBytes(String string, String charset){
try {
byte[] bytes = string.getBytes(charset);
return bytes;
}catch (Exception e){
e.getStackTrace();
}
return null;
}2,字节数组解码成字符串
java
/**
* 字节数组解码成字符串
* @param bytes
* @param charset
* @return
*/
public static String bytesToString(byte[] bytes, String charset){
try {
String string = new String(bytes,charset);
return string;
}catch (Exception e){
e.getStackTrace();
}
return null;
}3,字节数组编码成base64
java
/**
* 字节数组编码成base64
* @param bytes
* @param flags
* DEFAULT = 0 有填充字符=,有换行符
* NO_PADDING = 1 没有填充字符=,有换行符号
* NO_WRAP = 2 有填充自字符=,没换行符号
* CRLF = 4 有填充自字符=,有回车+换行符号
* URL_SAFE = 8 有填充字符=,有换行符,将+和/替换为-和_。
* NO_CLOSE = 16 有填充字符=,有换行符,不关闭输出流
* @return
*/
public static String bytesToBase64(byte[] bytes,int flags){
String base64 = Base64.encodeToString(bytes,flags);
return base64;
}4,base64解码成字节流
java
/**
* base64解码成字节流
* @param base64
* @param flags
* @return
*/
public static byte[] base64ToBytes(String base64,int flags){
byte[] bytes = Base64.decode(base64,flags);
return bytes;
}5,16进制字符串转成字节数组
java
/**
* 16进制字符串转成字节数组
* @param hexStr
* @return
*/
public static byte[] hexStrToBytes(String hexStr) {
hexStr = hexStr.replaceAll(" ", "");
hexStr = hexStr.replaceAll("\n", "");
byte[] arrB = hexStr.getBytes();
int iLen = arrB.length;
// 两个字符表示一个字节,所以字节数组长度是字符串长度除以2
byte[] arrOut = new byte[iLen / 2];
for (int i = 0; i < iLen; i = i + 2) {
String strTmp = new String(arrB, i, 2);
arrOut[i / 2] = (byte) Integer.parseInt(strTmp, 16);
}
return arrOut;
}6,字节数组转16进制字符串
java
/**
* 字节数组转16进制字符串
* @param bytes
* @return
*/
public static String bytesToHexStr(byte[] bytes) {
if (bytes == null) {
return null;
}
StringBuilder builder = new StringBuilder();
// 遍历byte[]数组,将每个byte数字转换成16进制字符,再拼接起来成字符串
for (int i = 0; i < bytes.length; i++) {
// 每个byte转换成16进制字符时,bytes[i] & 0xff如果高位是0,输出将会去掉,所以+0x100(在更高位加1),再截取后两位字符
builder.append(Integer.toString((bytes[i] & 0xff) + 0x100, 16).substring(1));
}
return builder.toString().toUpperCase();
}数据处理会遇到哪些问题
1,字符串和字节数组之间转换中文乱码问题
字符串和字节数组之间转换的核心在于编码库
乱码原因1:选用的编码库不包含该字符,编码肯定会出问题
乱码原因2:用a编码库编码用b编码库解码,肯定也会出问题
所以保证两个条件就一定不会出现乱码
1,所选编码库包含该字符
2,编码和解码用的同一个编码库
2,为什么只有中文乱码问题,英文和数字不会乱码
英文和数字是最基础的,每个编码库都支持
英文和数字在每个编码库里面编码成的字节数组都是一样的
3,怎样去识别一个字节数组
长度:字节数组有固定长度以字节为单位
转换成2进制:以2进制0101 0101的格式或者16进制FF这种,后者看起来更方便
4,数据传输选择什么格式好
权威首选:字节数组格式
最官方不会出错,但是明文和复制粘贴起来比较麻烦
方便首选:json字符串
易读,用起来方便,但是会存在编码出错风险
其他方式1:base64
等价于字节数组,同一个flags编码不会出错,不易读,明文和复制粘贴起来比较简单,长度为字节数组长度的三分之4
其他方式2:16进制
等价于字节数组,不需要编码,不会出错,易读,明文和复制粘贴起来比较简单,长度为字节数组长度的的二倍
5,两段数据怎么拼接或者分包比较好
权威首选:字节数组格式
最官方,不会出错
方便首选:json字符串
统一编码不会出错
其他方式1:base64
会出错,不建议
其他方式2:16进制
不会出错,很好用
6,数据过大怎么处理
压缩
平均压缩前和压缩后的比例叫做平均压缩率,这个比例越小平均压缩率越高
分包
数据过大一次发不完全可以分包发送,保证顺序不错乱不丢包即可
7,更多疑问
请留言或加V:Xzw421771880