目录
- 节点类
- list类
- 迭代器类
-
- 前言(string和vector的区别)
- 迭代器模版参数的说明
- 构造函数
- ++运算符重载
- [- -运算符的重载](#- -运算符的重载)
- ==运算符重载
- !=运算符的重载
- *运算符的重载
- ->运算符的重载
- 迭代器相关函数
- 插入和删除函数
- 其他函数
- [list的sort vs 库的sort](#list的sort vs 库的sort)
- 从迭代器类重新理解封装
- end
节点类
基本框架
cpp
template<class T>
struct list_node
{
T _data;
list_node<T>* _next;
list_node<T>* _prev;
};- 这个框架很简单,具体的我在数据结构模拟实现链表那个章节已经详细讲过,如果需要请去复习一下【手撕数据结构】拿捏双向链表
构造函数
cpp
template<class T>
struct list_node
{
T _data;
list_node<T>* _next;
list_node<T>* _prev;
list_node(const T& x = T()) //别忘了写缺省参数
:_data(x)
,_next(nullptr)
,_prev(nullptr)
{
}
};- 这里我们就用初始化列表对链表节点对象进行初始化,对节点存储的值用匿名对象进行缺省参数赋值。前后节点指针初始化为空指针
- 这里的匿名对象对于自定义类型会去调用他们的默认构造来初始化,内置类型也有构造函数就是int,float,double是0
list类
构造函数
- 我们要清楚,我们现在实现的链表是一个循环双向链表,那么就要求逻辑结构应该如图这样
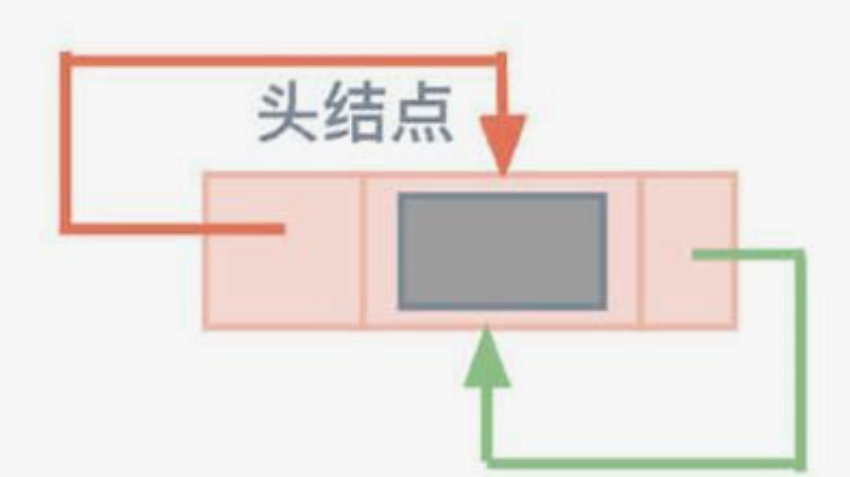
- 那么就需要对链表的头结点的前后节点指针都指向他自己
那么我们的构造函数不妨这样来实现
cpp
void empty_init()
{
_head = new Node(); //调用构造函数,创造节点初始化,链表是一个个节点连接起来
_head->_next = _head;
_head->_prev = _head; //带头双向循环
}- 我们实现一个成员函数来初始化哨兵位节点
这里补充一下_head, 是链表的哨兵位节点
cpp
private:
Node* _head;- 构造函数直接调用这个初始化函数就行了
cpp
list()
{
empty_init();
}- 这里有同学就会有疑问,这里为啥不喝前面的string,vectori两个容器的构造一样在构造函数的初始化列表进行初始化,像下图一样

因为初始化列表他只能用来初始化成员变量,_head的确是成员变量不错,但是_head->_next并不是成员变量,而是成员变量的成员。
- 所以我们就实现一个函数来完成这些操作
拷贝构造函数
cpp
list(const list<T>& lt)
{
empty_init();
for (auto& e : lt)
{
push_back(e);
}
}- 在string和vector两个容器里面我已经详细讲解了拷贝构造的要求,最重要的就是要完成深拷贝。这里我们就用了push_back这个接口来完成深拷贝。
cpp
void push_back(const T& x)
{
Node* new_node = new Node(x); //new 可以开空间,也能调用构造函数初始化
Node* tail = _head->_prev;
tail->_next = new_node;
new_node->_prev = tail;
new_node->_next = _head;
_head->_prev = new_node; //改成_head->_prve就没有问题了
_size++;
}- 可以看到我们的push_back函数用new开了新空间,并且把对应的指针指向了新空间,这就完成了深拷贝。
- 或许有同学疑问,为啥这_head->_prev = new_node;不写成tail = new_node
- 原因就是tail是一个指针变量,我们改变指针变量的值是不能改变指针变量指向的值的。

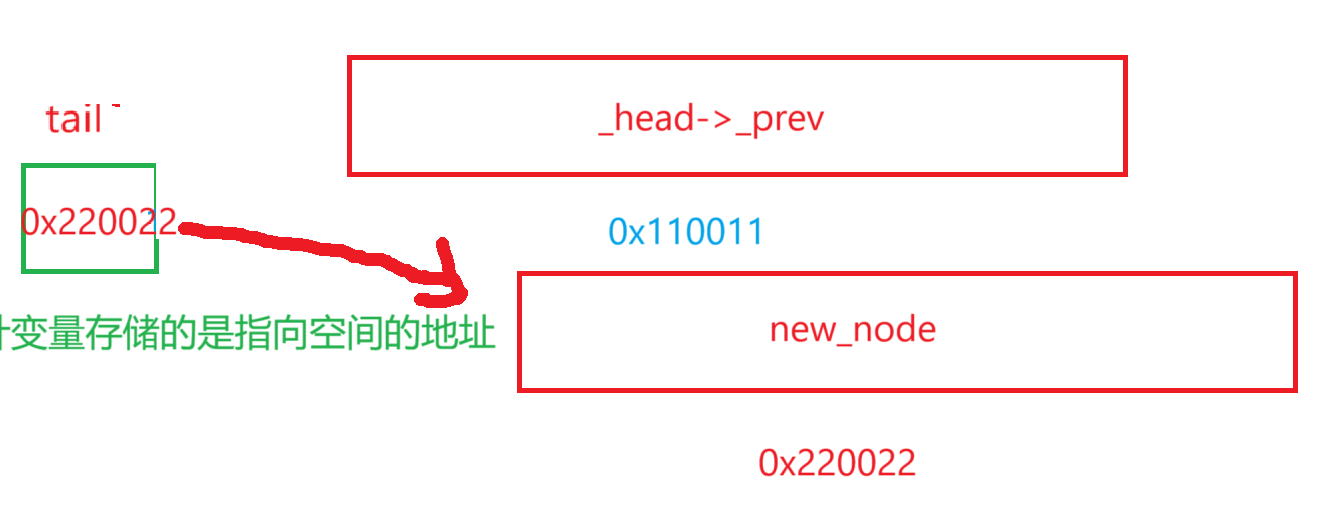
- 所以改变tail并不能改变_head->_prev,这里我面的本意是想把_head->_prev这个指针的指向改变
赋值重载
c
list<T>& operator=(list<T> lt)
{
swap(lt);
return *this;
}- 还记得我在前面两章说vector和string的赋值重载的时候吗,资本家思想。如果我想要得到lt的并且想扔掉原来的资源,只需要把swap一下,lt这个局部变量在调用完这个函数就会销毁。因为我现在已经把原来this的资源交换给了lt, 所以销毁lt就相当于销毁了原来this指向的资源。
析构函数
cpp
~list()
{
clear();
delete _head;
_head = nullptr;
}- 这里我们直接先提前看一下clear的内部实现,来了解析构函数
cpp
void clear()
{
auto it = begin();
while (it != end())
{
it = erase(it);
}
}- 可以看到就是从头结点删除到尾节点,这里的erae方法后面介绍
- 所以析构的时候我们就只需要delete一下哨兵节点就行了
迭代器类
前言(string和vector的区别)
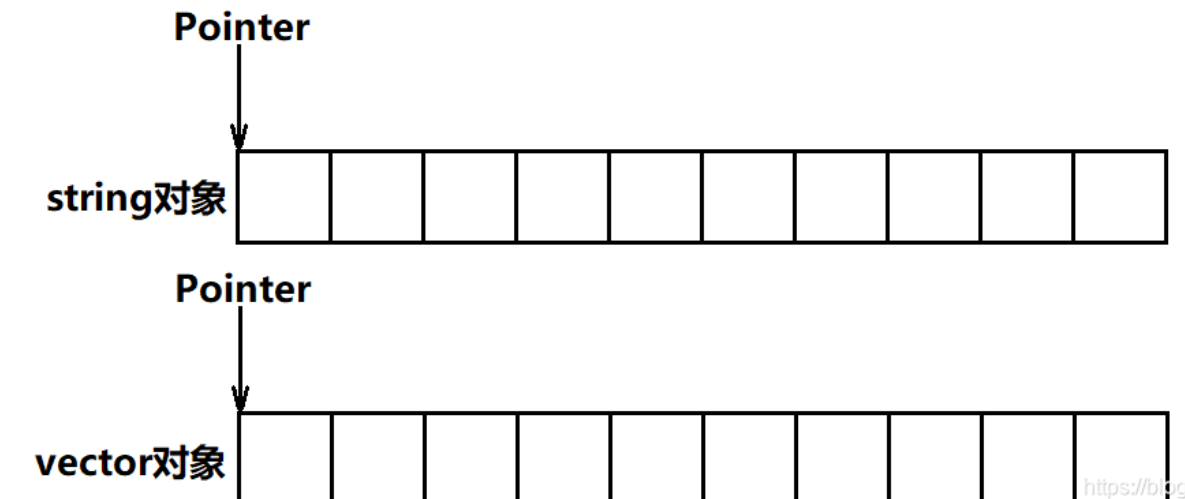
或许很多人有疑问,为啥list迭代器还要单独实现一个类来解决,而vector和string就可以直接写出来。我们先来回顾一下vector的迭代器



- 可以看到我们不管是删除还是插入操作,如果我们想要找到下一个数据的地址,只需要简单的++或者--就行了,这就是原生指针,我们开辟空间的时候是开辟一块连续的空间
- 但是对于链表,我们是一个节点一个节点的开空间,这样开出来的空间位置是随机的是不连续的,这时候我们再想要通过简单的++或者--就找到数据就不可能了。
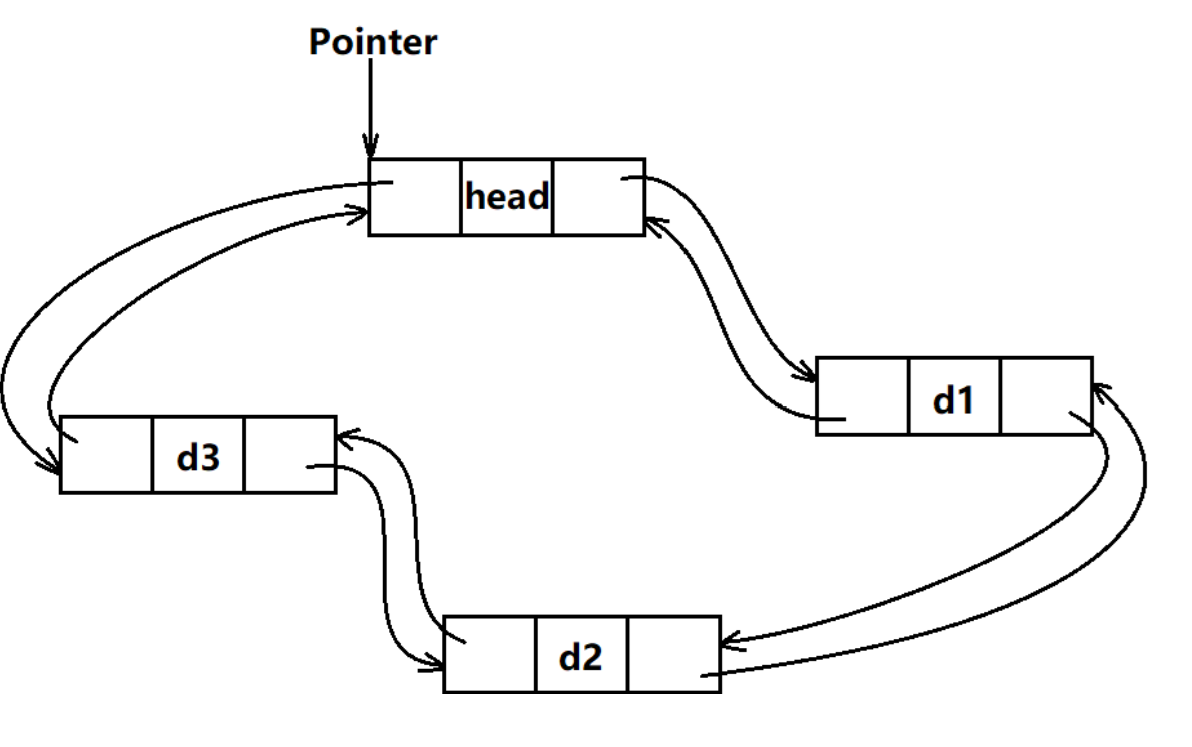
既然原生指针并不能找到链表的下一个节点,那么我们就需要封装一个迭代器类来完成这一系列操作。
- 我们实现这个类的时候要注意,迭代器本质就是把底层细节封装起来,让用户像用string和vector原生指针方便的访问链表的各个节点,用户并不需要关心底层到底是怎么实现的,即他是怎么找到下一个节点,只需要像用+±-这种操作完成这个访问数据即可。
- 总结:迭代器类,实质上就是对list进行+±-和访问运算符*这些和原生指针一样的操作的运算符重载,能够让用户感觉就是在用原生指针一样。
迭代器模版参数的说明
这里我们所实现的迭代器类的模板参数列表当中为什么有三个模板参数?
cpp
template<class T, class Ref, class Ptr>- 为了和库里面保持一致,我们不光要实现普通list对象的迭代器,还要实现const的list对象的迭代器,其实const的list对象的迭代器和普通list迭代器就是返回的类型不一致,实现上是一致的,这时候我们就可以通过模板自动推导类型来解决。

构造函数
cpp
list_iterator(Node* node)
:_node(node)
{
}- 很简单,我们需要知道从node节点开始迭代访问,那么提供node这个节点
++运算符重载
cpp
Self& operator++()
{
_node = _node->_next;
return *this;
}- 从链表节点的类中我们知道节点的下一个节点的位置是用一个_next成员变量指针指向的,所以指向那个位置就行了。
这就是一个后置++的实现,接下来我们实现前置++
cpp
Self operator++(int)
{
Self tmp(*this);
_node = _node->_next;
return tmp;
}- 这里我们就是返回自增之前的那个对象
- 解释下Self的类型,其实就是迭代器对象的类型
cpp
typedef list_iterator<T, Ref, Ptr> Self;- -运算符的重载
cpp
Self& operator--()
{
_node = _node->_prev;
return *this;
}- 和++相反,++是找到后面的那个节点,而--就是找到前面那个节点。
cpp
Self operator--(int)
{
Self tmp(*this);
_node = _node->_prev;
return tmp;
}- 前置- - 同上面前置++
==运算符重载
cpp
bool operagor == (const Self & s)
{
return _node == s._node;
}- 判断两个节点指针指向的地址是否相同即可
!=运算符的重载
- !=运算符刚好和==运算符的作用相反,我们判断这两个迭代器当中的结点指针的指向是否不同即可
cpp
bool operator!=(const Self& s)
{
return _node != s._node;
}*运算符的重载
cpp
Ref operator*()
{
return _node->_data;
}- 返回节点指针的存储数据的成员变量_data就可以了
- 这里的Ref是引用的类型,模板推导出来的引用类型
->运算符的重载
cpp
Ptr operator->()
{
return &_node->_data;
}- 很多同学都不知道重载这个运算符用来干啥,
--
- 可以看到,当我们链表存储的类型是一个类类型的时候,我们的流插入运算符就不能输出类类型的数据了。这时候我们要么重载留插入运算符,要么就另寻其他办法。
这时候我们观察到,链表节点是一个类,想访问里面的成员变量,可以通过对成员变量的地址->来访问类里面的成员变量。这时候我们就需要这个成员变量的地址对他解引用来访问他。
- 这时候有的同学就可能会有疑问,那->获取地址后不应该再次->才能得到数据吗,为什么只需要写一个->,这是因为要提升程序的可读性
例如日期类的成员访问:
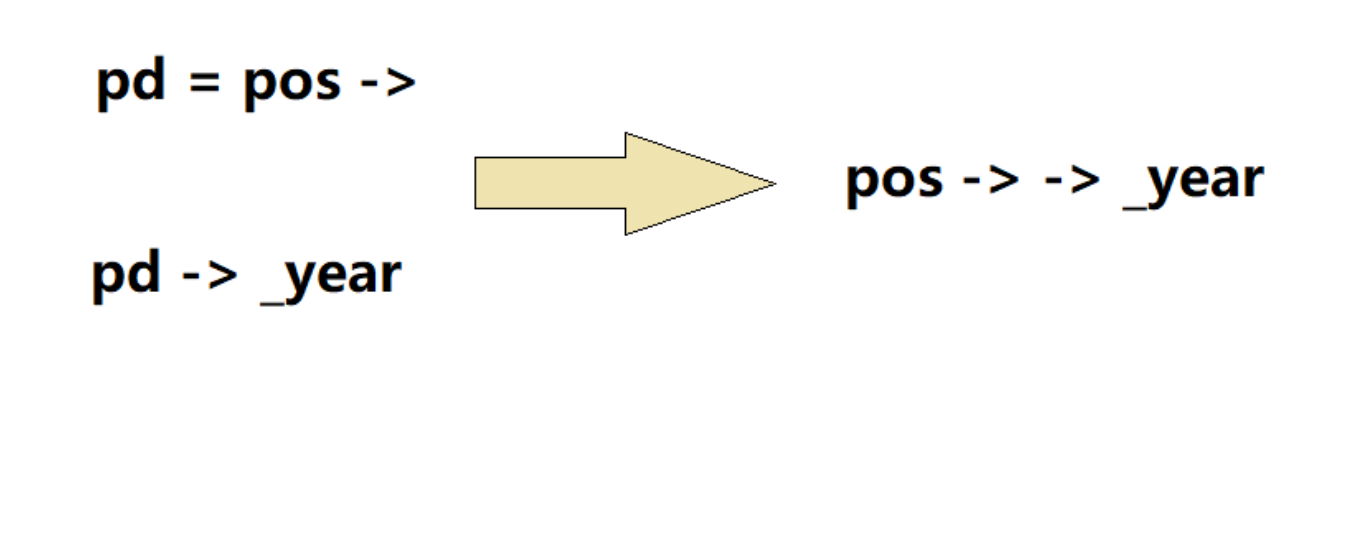
迭代器相关函数
cpp
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}- 这里只需要把节点传给我们的迭代器类构造一个迭代器对象就可以获得头节点和尾部的迭代器。
插入和删除函数
insert
cpp
iterator insert(iterator pos, const T& val)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(val);
newnode->_next = cur;
newnode->_prev = prev;
prev->_next = newnode;
cur->_prev = newnode;
_size++;
return iterator(newnode);
}- 这里插入很easy,只需要把插入的新节点前后指针更新到对应的指针就行了。
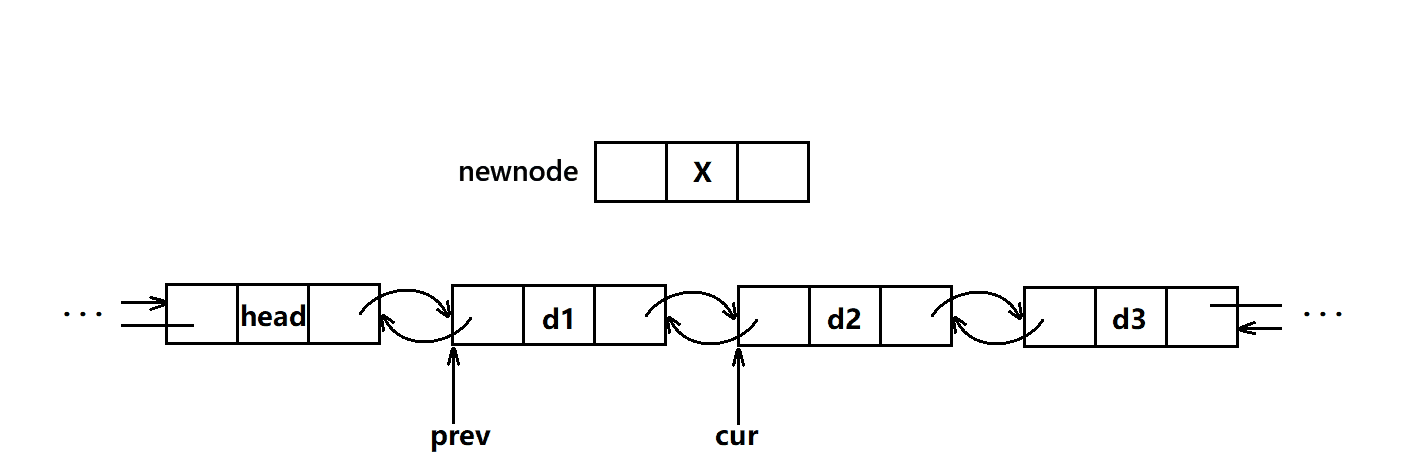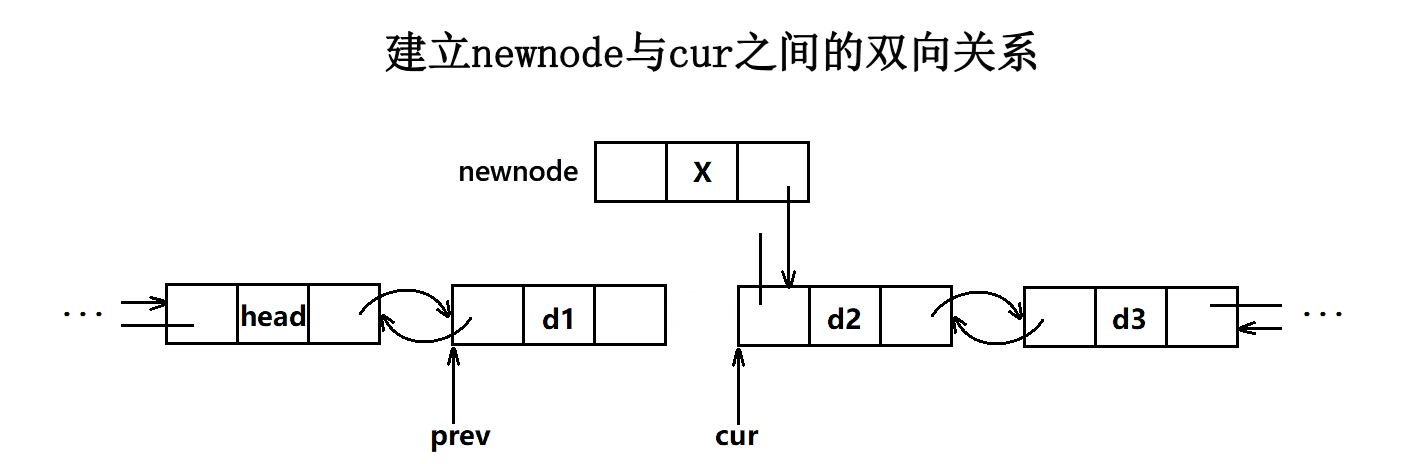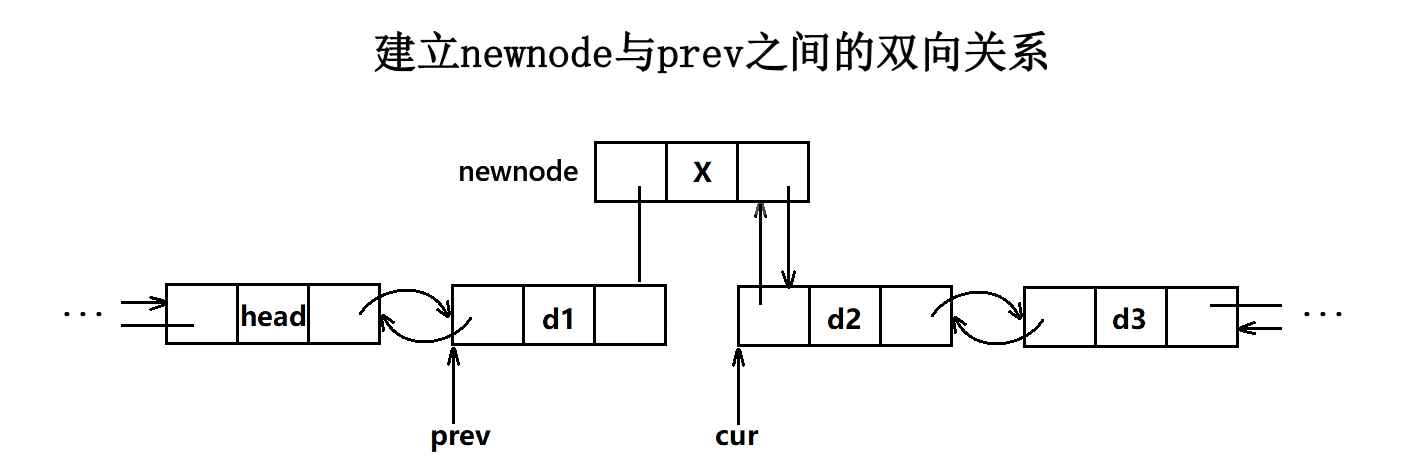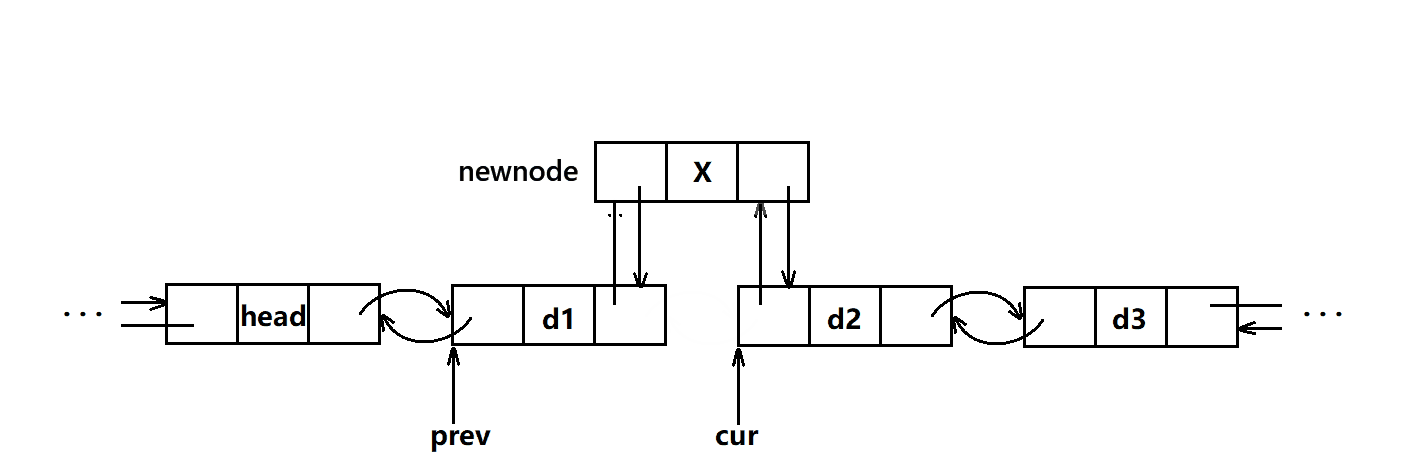
- 注意这里插入不存在迭代器失效的问题,因为我们的扩容都是一个个独立的空间,不存在像vector那样扩容后会导致迭代器无法找到新开的空间,这里的迭代器是通过指针来找到空间的
erase函数
cpp
iterator erase(iterator pos)
{
assert(pos != end()); //注意这里是给end, pos是迭代器的类型对象
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* next = cur->_next;
next->_prev = prev;
prev->_next = next;
delete cur;
_size--;
return iterator(next);
}
- 这里释放节点就要注意迭代器失效的问题了,我们删除后,指向这个节点的迭代器指向的就是一个无效的内存,这时候就需要更新这个迭代器让他指向有效的内存。
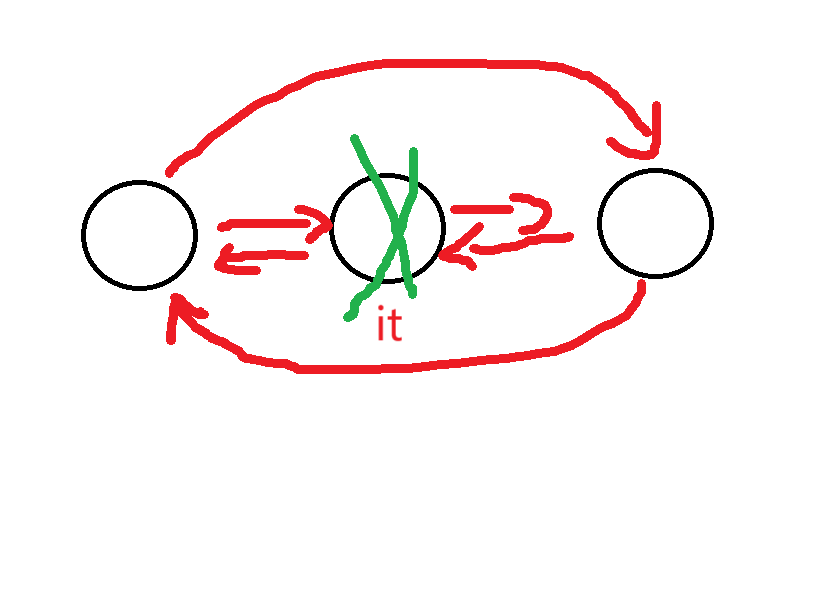
push_fron, pop_back, pop_front
cpp
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_front()
{
erase(begin());
}
void pop_back()
{
erase(--end());
}- 复用insert和erase接口就行,push_front就是insert到头结点位置,pop_front就是删除头结点位置,pop_back则是删除end(end是最后一个节点的下一个节点)前一个位置
其他函数
size函数
cpp
size_t size() const
{
return _size;
}- 我们通过,一个成员变量来实现,如果链表插入节点的时候就自增_size,删除节点的时候就自减_size,可以看看前面的插入和删除函数
clear函数
cpp
void clear()
{
auto it = begin();
while (it != end())
{
it = erase(it);
}
}- 析构函数哪里前面已经解释过
swap函数
cpp
void swap(list<T>& tmp)
{
std::swap(_head, tmp._head);
}- 这里ist容器当中存储的实际上就只有链表的头指针,我们就交换两个变量的头结点就行了,就让他们交换了数据,
- 这里我们还重载了一个全局的swap函数
cpp
template<class T>
void swap(list<T>& a, list<T>& b)
{
a.swap(b);
}- 这一点我在string和vector中也说过
- 为了防止使用算法库中的i那个很多拷贝构造的swap函数,我们重载一个全局函数通过模板有现成吃现成(两个链表类型的变量,相同的类型),会优先匹配我们自己实现的swap函数,然后我们这个全局的函数又调用成员函数swap,这个效率比算法库的那个效率高很多,为啥效率高,请看前面两个容器的讲解很详细。
list的sort vs 库的sort
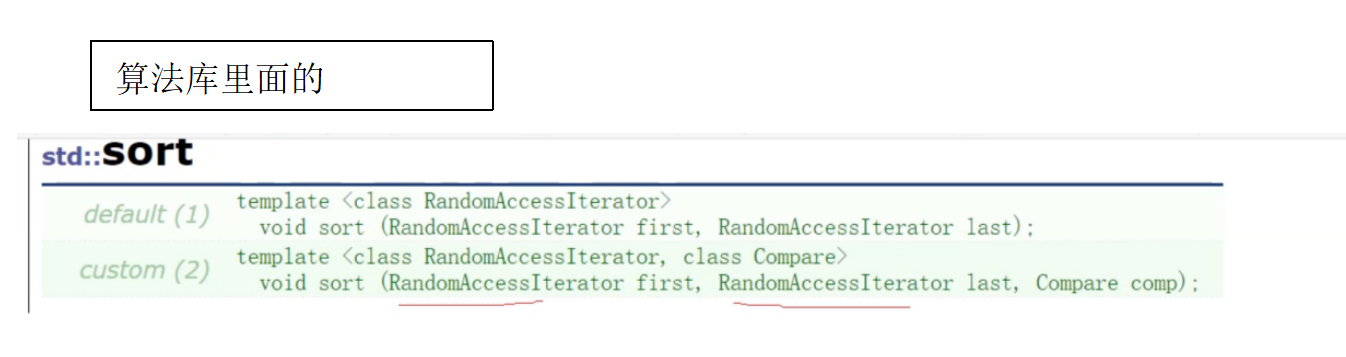
List为啥要自己实现一个sort函数来排序,不能直接用算法库中的sort吗?
1.不能,因为我们的迭代器按功能角度来分类有3种:
(1)单向迭代器(支持++) 例如:foward_list(单链表)
(2)双向迭代器(支持++.--), list
(3)随机迭代器(支持++,--, +, -) string,vector

vector和list的排序效率

- 我们第一组数据是vector用算法库sort和list用他的成员函数sort单独排序,第二组数据是list的数据拷贝到vector给算法库的sort排序和list用他的成员函数sort单独排序
- 可以看到copy到vector给算法库的sort排序都比list的sort快
原因:
1链表这个不连续的结构并不适合大量数据的排序,他的索引访问不能像vector那样连续的索引访问那么高效,需要更多时间来找到索引位置
2.算法库中的sort是快速排序算法,list的sort用的是归并排序,快速排序还是比归并排序要厉害一点的。
- ,想要更高的效率排序,最好拷贝到vector中排序,排完再拷贝回list
从迭代器类重新理解封装
- 大家可以看到我们的迭代器类实际上是一个
cpp
struct list_iterator- 在类外是可以访问的,虽然在类外是可以访问,但是我们通过对迭代器类重命名
cpp
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;- 提供了类外统一用iterator来访问的方式,这样外面并不知道我实际是什么名字,并不能很好的猜出来,可以看到我们stl中容器的迭代器都是统一命名为iterator, 但是每个容器的迭代器的底层细节实现方式可能都有差异,但是用户都可以通过iterator来访问各个容器,只能通过我给的接口访问,这就是一个隐式的封装
- 为啥要写成struct,就是为了方便类里面对他的高频访问的问题。如迭代器函数begin,插入insert

end
感谢大家阅读,希望对大家有帮助,快去实现一下吧