省流: 实现了一个 uptime-kuma 监控系统 open api 的 uptime-kuma-mcp-server , 用以对话实现批量增删改查页面监控。这个方法也能快速判断某个域名被 GFW 的情况。
粘贴网页全部内容, 并口语化描述: 把所有二级域名加入监控  添加成功
添加成功 
口语化:删除所有形如 *.v.mytest.cc 的监控。 
json
"mcpServers": {
"uptime-kuma-mcp-server": {
"command": "uvx",
"args": ["uptime-kuma-mcp-server"],
"env": {
"KUMA_URL": "https://yourdomain.xyz",
"KUMA_USERNAME": "username",
"KUMA_PASSWORD": "passwd"
}
},
}Function calling tool
如果你不知道什么是 LLM function calling tool,看这一个 80 行的文件 github.com/Camusama/al... 就能快速理解。
- 客户端 定义一个函数,把函数说明 Schema 当 prompt 和用户提问一起发给大模型
- 客户端 For 循环响应 LLM 回复,大模型通过 Schema 知道有这个 Tool ,按 Schema 内函数描述和参数的描述 提取出参数,告诉你要调这个函数,给你提取出的参数
- 客户端响应大模型的 function calling 请求,拿参数调函数,返回值发给大模型。大模型再次回复,重复循环。
这里客户端指的是直接和 LLM 交互的端,可以是 后端服务器 / FaaS Worker / SSR 网页 。 但有价值的 Tool 比如打开浏览器 Playwright 这种只能在用户终端实现。
原始情况下 Tool Schema 要手写,大部分情况下它明显是对 Tool 函数的描述文件。则在 LlamaIndex 这种框架里定义 Tool 就相对简单,由函数注释直接生成 Schema。
很明显 Tool 过多会导致 Prompt 过大,但相比 Rag workflow 模式累加起来的上下文则也不多。
而上述情况复杂化就是 Compute Use 了, 打开用户浏览器或 Docker terminal 哐哐截图,哐哐点击输入的,就是在客户端把用户交互(截图,双击,输入,移动鼠标,执行等)都定义成 Tool 来在客户端 哐哐调 github.com/openai/open... 。
ReAct 的过程主要靠 LLM 多模态 VL 理解当前用户页面截图来输出下一步行动,token 消耗较大。可以说点一杯咖啡这个行为消耗的 Token 价格够买两杯了。这一点在后面 MCP 的使用中也会体现,轻松突破大模型上下文限制导致 Block 。
MCP
从开发一个 MCP server 的角度来说,它比较类似之前的 Function calling tool,只是更有通用性,不再局限于某个 workflow 框架或代码仓库。
- Dify ,Fastgpt 这种 Rag Workflow 里 tool 都是现成的,和 Workflow 对应的客户端集成。
- LangGraph 这种框架实践可以看 LangManus 项目 的实现,其实核心逻辑: workflow 编排 和 Prompt 代码很少也很好理解,大部分代码量其实在实现 Tool 。比如 Crawl 抓网页工具。但更复杂的浏览器控制工具就拿browser use 包一层即可。
- 执行 Tool 的总是客户端而不是 LLM 自己 ,对 MCP 也一样。在 Tool 的实施过程中大部分工程工作量集中在具体的客户端。实践场景下,我们几乎都是使用现成客户端。而 Manu , Devin 这种就是把客户端前端界面做的很酷炫,核心仍然是 Surpervisor 的 workflow 编排模式,更多的 Tool 和 Prompt 工程。
需求背景
想实践一下 MCP ,冥思苦想创造了一个需求来用它实现。
本人有很多服务,一般聚合在 marquez.cc 的二级域名下。这些二级域名分散在 Cloudflare ,Vercel 等的 DNS 中,难以统计。 而且随着一些服务的批量调用,一些二级域名会出现被墙的情况。 之前只使用 哪吒监控 监控主机,没有主动监控服务。
 于是探索发现了一个工具 uptime-kuma 监控系统 用来监控服务,新增页面 URL get 就行,界面美观操作简单耗能少。
于是探索发现了一个工具 uptime-kuma 监控系统 用来监控服务,新增页面 URL get 就行,界面美观操作简单耗能少。
在上图中两个机器上用 Docker 搭建了三份,其中一份用来实验本 MCP 。

开发
uptime kuma 有 open api,但没有官方文档,搜索第一个是 uptime-kuma-api.readthedocs.io/en/latest/ 为一个 Python wrapper。那么把它包一层就是能用的 MCP 了,所以使用 MCP Python SDK 来实现。
FastMCP
Github 上搜索写法,现成的 Python MCP 都是手写 Schema 和 list_tool 的模式,比如Cognee MCP
官方文档的qucik start 已更新到 FastMCP 写法,即通过函数注解,通过函数描述自动生成 Schema ,和 LlamaIndex 类似 。
python
# server.py
from mcp.server.fastmcp import FastMCP
# Create an MCP server
mcp = FastMCP("Demo")
# Add an addition tool
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
if __name__ == "__main__":
mcp.run(transport="sse")直接 python server.py 就有 localhost:8000 , 输入到 Client 内即可测试。

把 kuma-api-wrapper 包在上述注解中即可。有价值的只有 Monitor 的增删改查。
- 增删 API 只有单个没有批量,通过 python 的 asyncio 并行处理,并修复类型
- 查的数据 Item 字段量过大容易超 token ,适当裁剪。
Prompt Engineering
对于LLM 的 RL 阶段而言,对于优化算法的关注远大于对于prompts的关注,但实际上prompts决定了模型学习和探索的范围,重要性丝毫不低于算法本身。
LLM = 99%的数据 + 1% 的算法。当下 LLM 的 AI Engineer 主要的工作和反复迭代优化的主要就是 Prompt 。 开发 MCP 的过程适合对单个 Tool 的 Prompt 精耕细作。
当前需求是优化 Tool 函数本身和函数参数的 Prompt。
踩坑点
这里有个坑点在于 MCP 目前是早期阶段,github 上 python 写法搜到的都是手写 inputSchema 的模式比如 Cognee MCP, 但文档qucik start 只有 FastMCP 写法,tools 示例里函数注释 Args 标注函数参数的 Prompt 描述这种写法是无效的,也搜不到修改 inputSchema 的示例。
比如对于 add_monitors 这个 Tool 函数 urls 的参数描述 Prompt 『监控URL列表,需要去重,且必须包含完整协议(如bing.com)』%25E3%2580%258F "https://bing.com)%E3%80%8F") 如果不生效,大模型调用过程中提取的参数就会是 "bing.com" 而不会补全为 "bing.com", 也不去重,导致功能异常。
这里用 AI 写代码倒腾了几次也写不明白,可见 LLM 很难处理自己不知道的知识。最后研究发现是用 python validate 的 pydantic 里添加对 Filed 的描述来实现的,这样生成的 inputSchema 包含对 function parameter 的描述。
python
from pydantic import Field
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Parameter Descriptions Server")
@mcp.tool()
def add_monitors(
urls: list[str] = Field(description="监控URL列表,需要去重,且必须包含完整协议(如https://bing.com)"),
) -> str:
"""批量添加多个监控器到Uptime Kuma,添加完成后返回 Uptime Kuma 的页面地址,显示出来"""
// rest code生成的 inputSchema 符合预期

Prompt 优化体验
- 对函数参数的精确描述直接决定 LLM 调用时能否正常运行 ,比如 『监控URL列表,需要去重,且必须包含完整协议(如bing.com)』%25E3%2580%258F "https://bing.com)%E3%80%8F") , 这样 LLM 能从大量文本中提取 URL ,并正确去重并转为完整的格式如 bing.com 转化为 bing.com

- tool 的描述中指示展示监控面板链接,让 LLM 在回答时直接给出链接跳转。

场景实践
一般网站都有 Bot.txt 反爬虫, fetch 模式的 tool 会报错,最稳的还是使用 playwright 开网页操作。而这就需要 LLM 多模态能理解截图,同时消耗大量 Token。
现阶段能调明白 MCP 的 LLM 也没几个,如果使用 Claude 去操作 playwright 就有亿点贵了,开个网页点两下几刀乐没了。目前性价比科学之选是 Deepseek-v3。
工作流程
这里需求是发现 mytest.cc 域名的所有二级域名并添加监控,但 DNS 本身是被动查询的,无法主动发现记录,并且也不是所有记录都有监控价值。
这里使用 crt.sh 网站搜索 mytest.cc 域名,能查到证书记录。我所有真正用到的服务都使用 Let's Encrypt 为二级域名部署了 Https ,则用 crt.sh 查到的证书记录都是部署过的,有网站的服务。
json
"mcpServers": {
"uptime-kuma-mcp-server": {
"command": "uvx",
"args": ["uptime-kuma-mcp-server"],
"env": {
"KUMA_URL": "https://yourdomain.xyz",
"KUMA_USERNAME": "username",
"KUMA_PASSWORD": "passwd"
}
},
}打开 Playwright 和这个,总共两个 MCP ,输入 『去crt.sh 搜索所有 marquez.cc 的二级域名,全部添加到监控』

的确成功打开了网页并执行了搜索,但之后直接爆上下文了 exceed context length,可见只要和截图沾边就 token 消耗量巨大。 
那我们手动一下,去 crt.sh 搜索 mytest.cc 记录,复制整个网页内容到输入框。
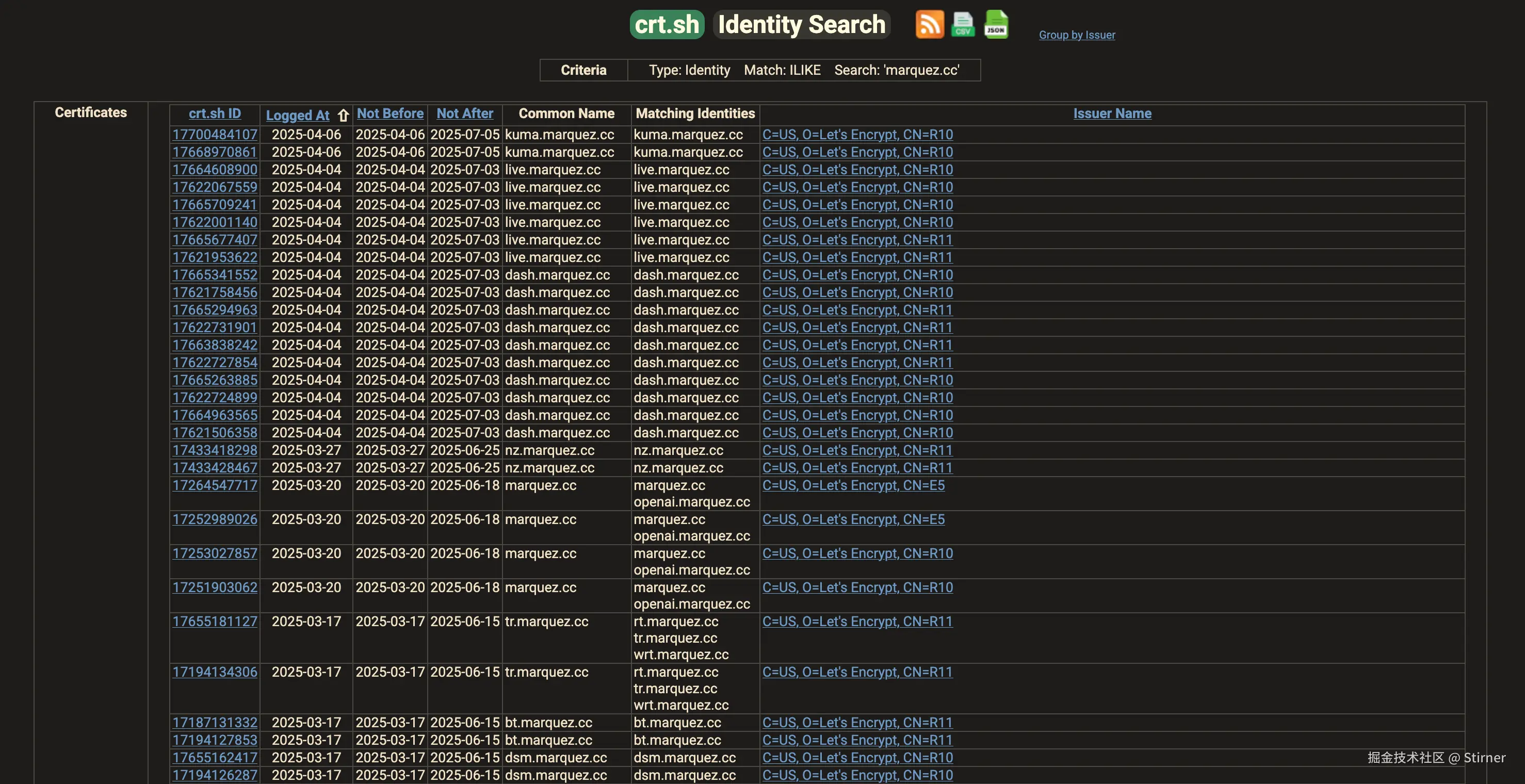 并口语化描述: 把所有二级域名加入监控
并口语化描述: 把所有二级域名加入监控
去 kuma 监控页面看效果,域名的情况就一目了然了。域名都正确去重, 并补充了 https:// 协议部分。
也能精细化运维,比如说:删除所有形如 *.v.mytest.cc 的监控。
LLM 可以自行判断先 get 获取ID再删,这依赖于对于 Tool 和 函数参数 的 inputSchema描述精确性。
总结
开发了一个 MCP 工具,实现了个人的一个具体需求。归纳串联了 AI engineer 相关的知识点,同步自身相关认知到预期水平。
个人还有一个使用 FastGPT RAG 生成问答对数据集 SFT 小模型的实践,有兴趣可以留言。
总体上就是先使用一个文档当知识库,用一个简单 Rag workflow 跑通业务。然后使用 LLM 分析这个文档,归纳总结分析出十几个领域,每个领域产生十几个问题,总计 360 多个问题,然后调用之前的 workflow API 批量操作问题生成答案,并反复多次数据标注,重新生成一些答案,反复多次的过程中提升数据质量和 workflow 的 Prompt 。最后处理成 jsonl 的格式去 SFT qwen-7b , 从而把这个文档内容刷到 LLM 里。 qwen-7b 可以秒回,非常快,节约了 Rag Retrival 十几秒的单次问答时间。
写文章本身也是一个学习的过程,也请读者能指出文章中的疏忽错漏之处。如果本文对你有所帮助,欢迎点赞收藏。