本文详细介绍了SQL语言的四大组成部分:DDL(数据定义语言)、DML(数据操纵语言)、DQL(数据查询语言)和DCL(数据控制语言)之一的DML(数据操纵语言)。
数据库使用时,大多数情况下,开发者只会操作数据,核心是就增删改查(CRUD), 增删改查四条语句,最重要的是查询(DQL) 。
增加语句
增加语言,就是给某张表进行数据插入。
语法:
sql
insert INTO table_name[(field1 [, field2 ......]) values(value1 [, vaule2 ......]) [,()]];案例演示:
sql
insert into t_user(name, password) values("zxy", "hehhehe");
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO t_user value(null, "xixi", 16, "123456");
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_user(password, name) values("abcd", "haha");
Query OK, 1 row affected (0.01 sec)
--插入多表数据
mysql> insert into t_user(name, password) value("yuyu1", "afaf"), ("ouou", "hfvha");
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0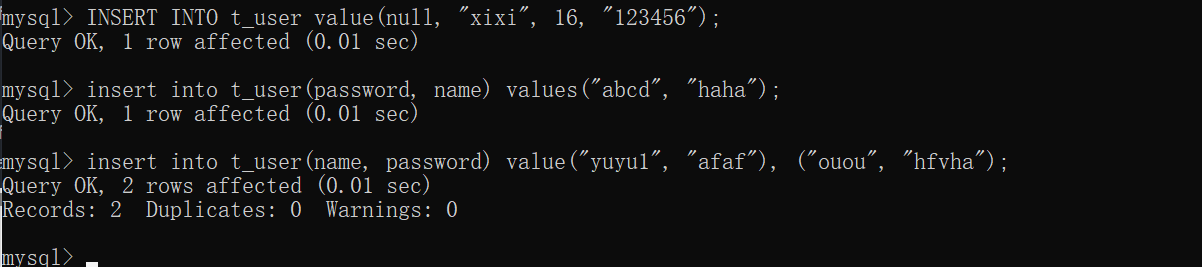
删除语句和TRUNCATE
删除语言,请注意删除的条件!!!如果不带条件,则删除全表。
语法结构:
sql
delete from table_name [where 条件];
truncate table table_name;区别
-
性能 :TRUNCATE TABLE 比 DELETE FROM 快,因为 DELETE FROM 是逐行删除,并在事务日志中记录每行的删除,而 TRUNCATE TABLE 只记录页的释放。
-
事务处理 :DELETE FROM 可以回滚(ROLLBACK),而 TRUNCATE TABLE 不能回滚。
-
触发器 :TRUNCATE TABLE 不会触发 DELETE 触发器,而 DELETE FROM 会触发。
-
外键约束 :对于由外键约束引用的表,不能使用 TRUNCATE TABLE ,而应使用不带 WHERE 子句的 DELETE FROM。
-
标识列 :TRUNCATE TABLE 会重置标识列的计数值,而 DELETE FROM 不会。
案例演示:
sql
delete from t_user where id=4;
-- 如果没有条件,则清空全表数据【慎重!!】
delete from user;
-- truncate清空全表[注意:truncate删除数据是不经过数据字典]
truncate table students;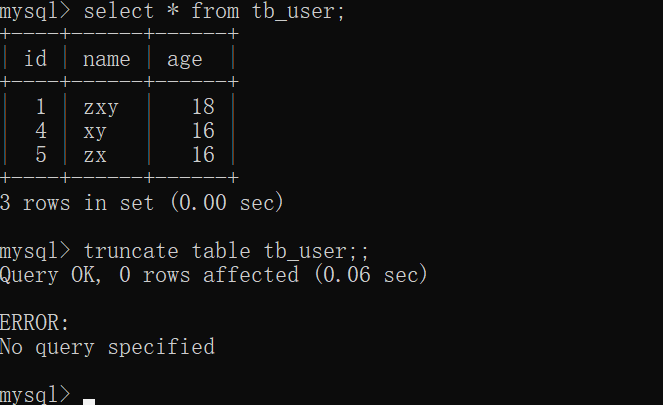
更新语句
更新就是修改表中的数据。
语法结构:
sql
update table_name set 字段1=新值 [, 字段2=新值, 字段3=字段3 + 1] [where 条件];案例演示:
sql
update t_user set age = 30 where id = 7;
update t_user set age = 20, password="root" where id = 28;
update t_user set age = age + 1 ;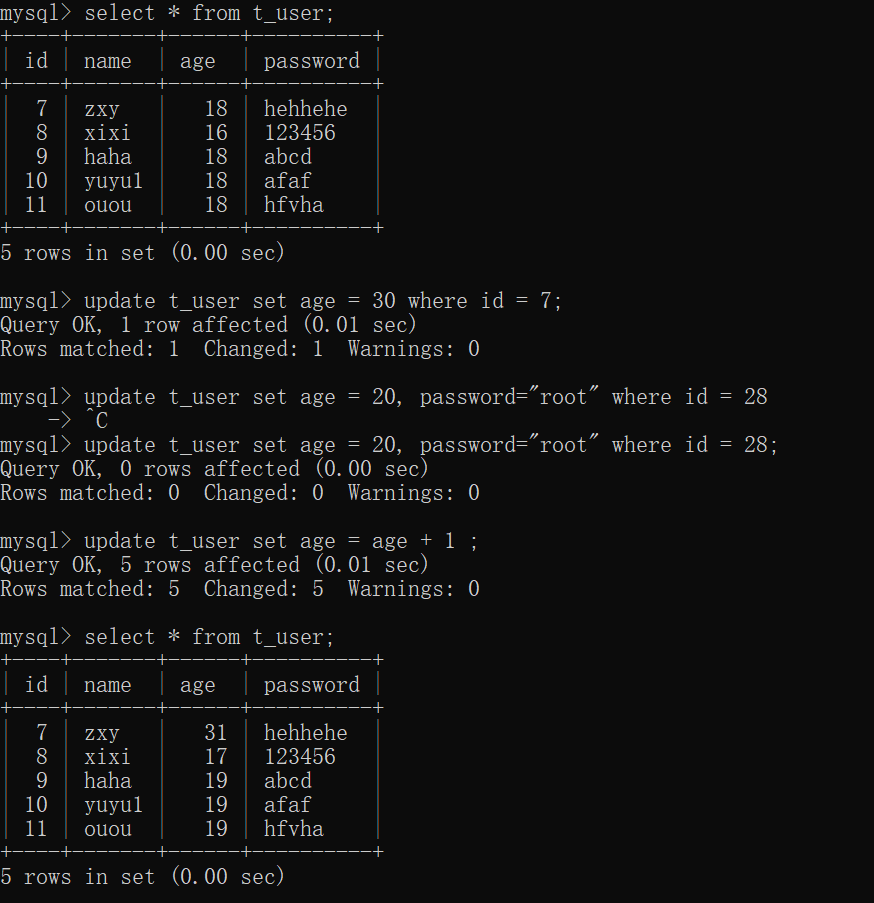
replace语句
该语句是集更新和插入为一体的一个语句。
如果表中没有这条数据,则执行插入,否则执行更新。
注意:replace的更新,本质是先删除,再插入。
sql
replace into t_user(id, name, password) values(100, "test", "test");
replace into t_user(id, name, password) values(100, "testtest", "testtest");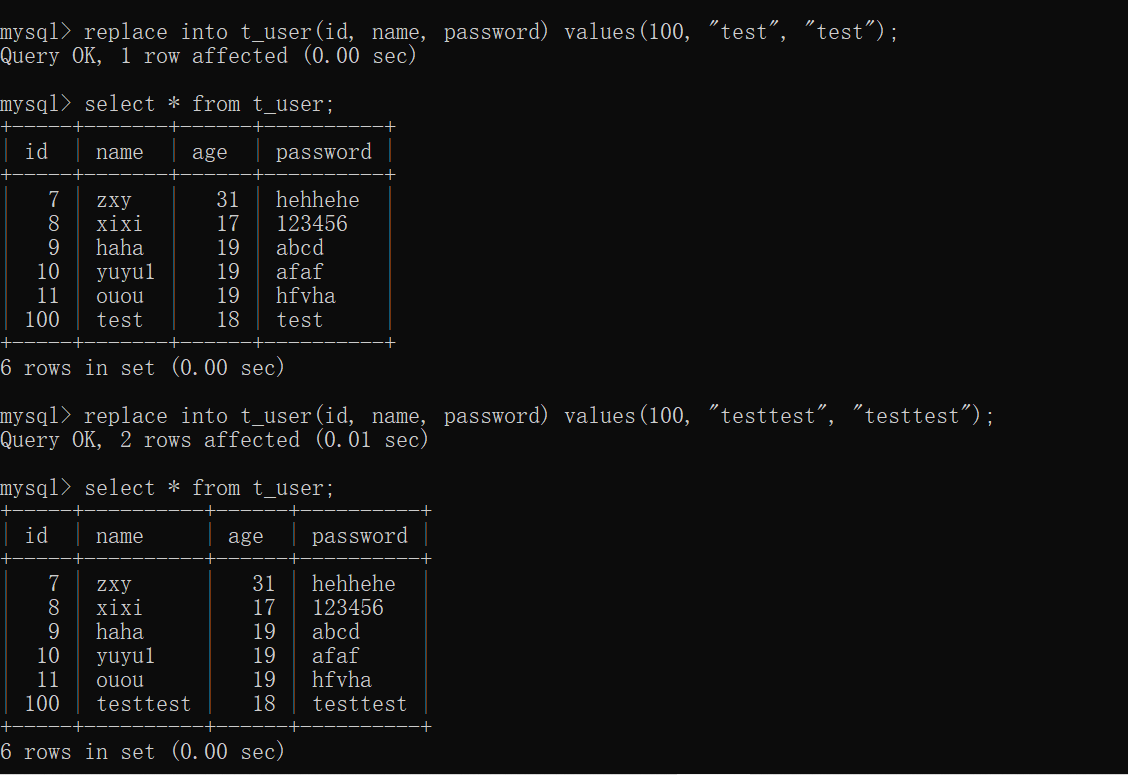
select查询语句
在开发中,查询语句是使用最多,也是CRUD中,复杂度最高的sql语句。
查询的语法结构
select *|字段1 , 字段2 ...... from 表名称 , 表名称2...... where 条件 group by 字段 \[having 分组后的筛选] order by 字段 \[desc\|asc 字段2 \[desc\|asc ......]] limit 分页
简单的sql查询,案例演示:
sql
-- 查询所有数据
select * from t_user;
-- 查询需要的字段信息
select id, name, password from t_user;
-- 查询一个字段,一个等值条件
select name from t_user where id = 1;
select 字段列表 from 表名称 where 条件
/*
等值查询
*/
select password from t_user where name="zxy";
select * from t_user where age = 19;
alter table t_user add birthday datetime default now();
select * from t_user where birthday='2025-03-13 20:52:12';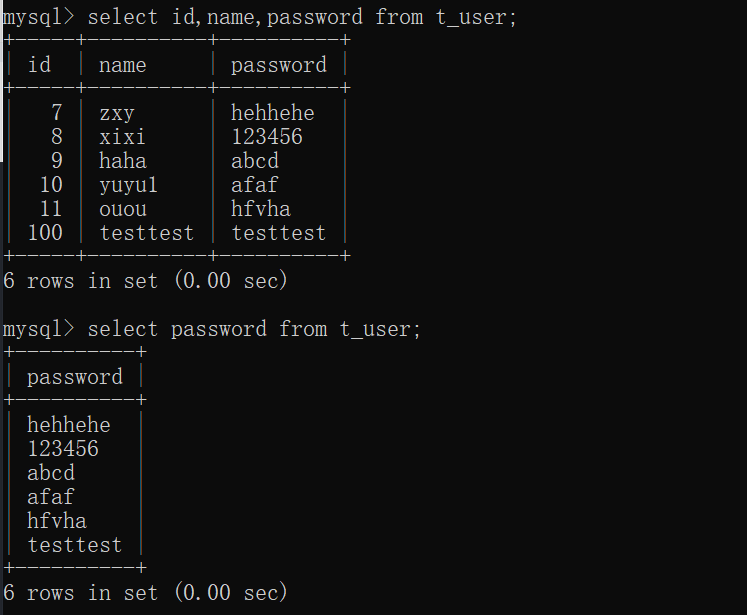

由于案列表里没有birthday字段,我们在这里添加一个dirthday字段,并更新一些数据
sql
-- 修改表结构,添加字段名为birthday的列
mysql> alter table t_user add birthday datetime default now();
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0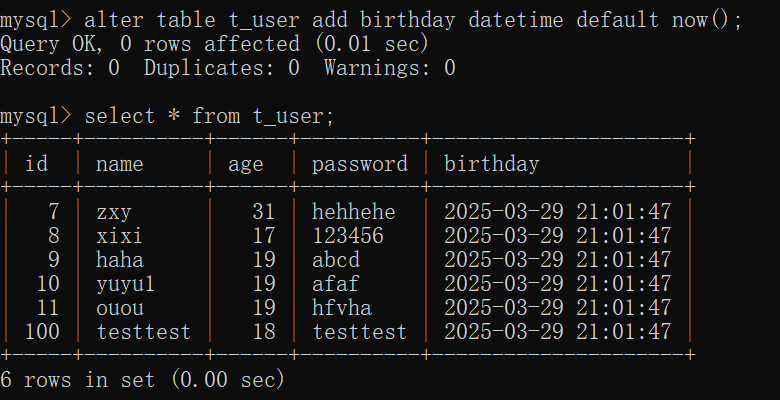
sql
-- 更新表数据
UPDATE t_user SET birthday = '1990-01-01' WHERE id = 7;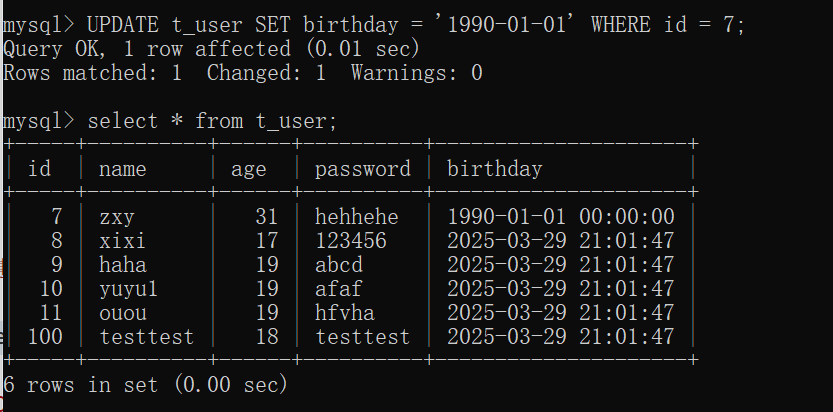
select语句中的特殊情况:
sql
对数值型数据列、变量、常量可以使用算数操作符创建表达式(+ - * /)
对日期型数据列、变量、常量可以使用部分算数操作符创建表达式(+ -)
运算符不仅可以在列和常量之间进行运算,也可以在多列之间进行运算。
SELECT last_name, salary, salary*12
FROM employees;
补充:+ 说明
-- MySQL的+默认只有一个功能:运算符
SELECT 100+80; # 结果为180
SELECT '123'+80; # 只要其中一个为数值,则试图将字符型转换成数值,转换成功做预算,结果为203
SELECT 'abc'+80; # 转换不成功,则字符型数值为0,结果为80
SELECT 'This'+'is'; # 转换不成功,结果为0
SELECT 'This'+'30is'; # ?猜测下这个结果是多少?
SELECT NULL+80; # 只要其中一个为NULL,则结果为NULL等值判断
-
=判断两次的值是否相等 -
is判断空null -
is not null来判断不为空 -
<=>可以判断null或者普通值
不等判断
-
!=不等于 -
<>也是不等于
逻辑运算符
逻辑运算符是多条件关联的一种方式。
与或非
-
and
-
or
-
not
注意:在sql中,如果要提升条件的运行顺序,或者提高条件的优先级别 ,则需要使用括号来提升
查询时的别名使用(用as指定别名)
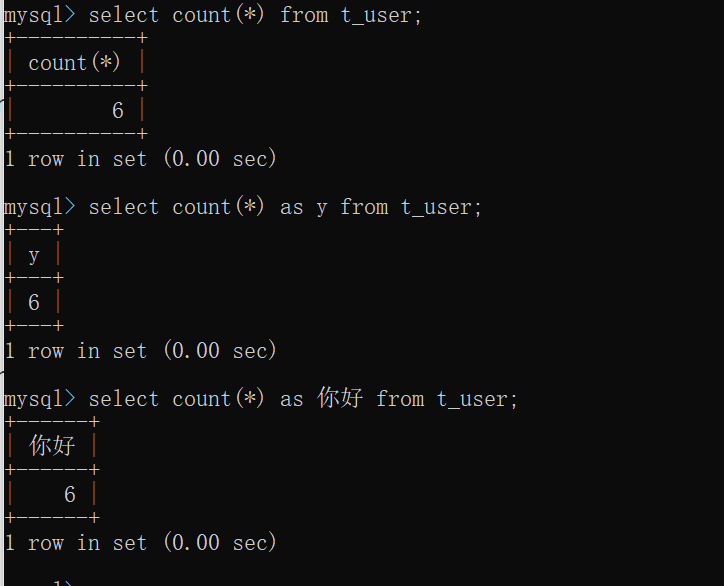
查询时,将结果的显示字段,使用一个其他名称来代替,就是别名。
常见的条件查询
sql
使用IN运算符获得匹配列表值的记录
SELECTemployee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (7902, 7566, 7788);
使用LIKE运算符
使用LIKE运算符执行模糊查询
查询条件可包含文字字符或数字
(%) 可表示零或多个字符
( _ ) 可表示一个字符
SELECT last_name
FROM employees
WHERE last_name LIKE '_A%';
使用IS NULL运算符
查询包含空值的记录
SELECT last_name, manager_id
FROM employees
WHERE manager_id IS NULL;
逻辑运算符
使用AND运算符
AND需要所有条件都是满足T.
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary>=1100--4 AND job_id='CLERK';
使用OR运算符
OR只要两个条件满足一个就可以
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary>=1100 OR job_id='CLERK';
使用NOT运算符
NOT是取反的意思
SELECT last_name, job_id
FROM employees
WHERE job_id NOT IN ('CLERK','MANAGER','ANALYST');
使用正则表达式:REGEXP
<列名> regexp '正则表达式'
select * from product where product_name regexp '^2018';分组
sql中,分组是一种统计概念。查询的数据,进行数据分析时,可能需要将相同的数据分成一组。
条件后面,当然是存在条件时,不过不存在,则是表名称后面
注意:分组查询时,查询字段必须是分组的字段,或者是聚合函数。
group by 字段
案例演示:
sql
mysql> select gender from t_hero group by gender;
+--------+
| gender |
+--------+
| 男 |
| 女 |
+--------+
2 rows in set (0.00 sec)
mysql> select gender,count(gender) from t_hero group by gender;
+--------+---------------+
| gender | count(gender) |
+--------+---------------+
| 男 | 14 |
| 女 | 2 |
+--------+---------------+
2 rows in set (0.00 sec)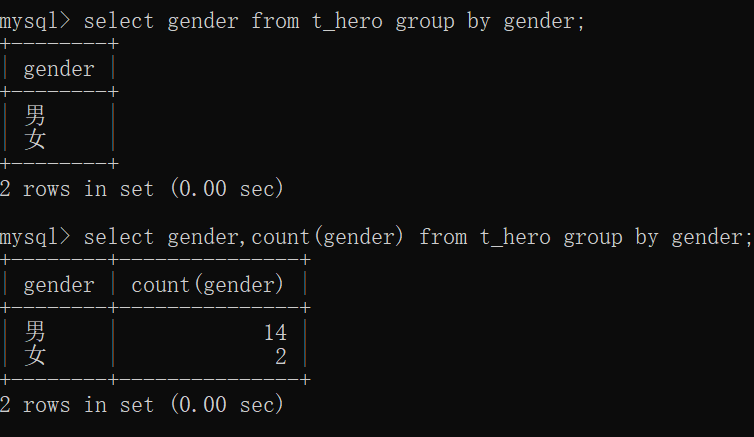
分组后的筛选
发现,如果直接在分组后的结果集上进行条件判断,将条件写在where中,会报错,因为:结果集是分组后才能做的判断,而where实在查询前的条件判断。
所以不能使用where,必须使用having。
再次强调,having必须写在group by之后!!!没有分组,就不能写having,但是分组可以没有having。
案例演示:
sql
mysql> select gender ,count(gender) from t_hero group by gender having count(gender) > 5;
+--------+---------------+
| gender | count(gender) |
+--------+---------------+
| 男 | 14 |
+--------+---------------+
1 row in set (0.00 sec)
结果排序
将查询结果,以特定的顺序展示(升序或者降序
语法结构:
sql
order by 字段
order by 字段 asc|desc;
order by 字段 asc|desc, 字段2 ;案例演示:
sql
-- 升序排序
select * from t_user order by age asc;
-- 降序排序
select * from t_user order by age desc;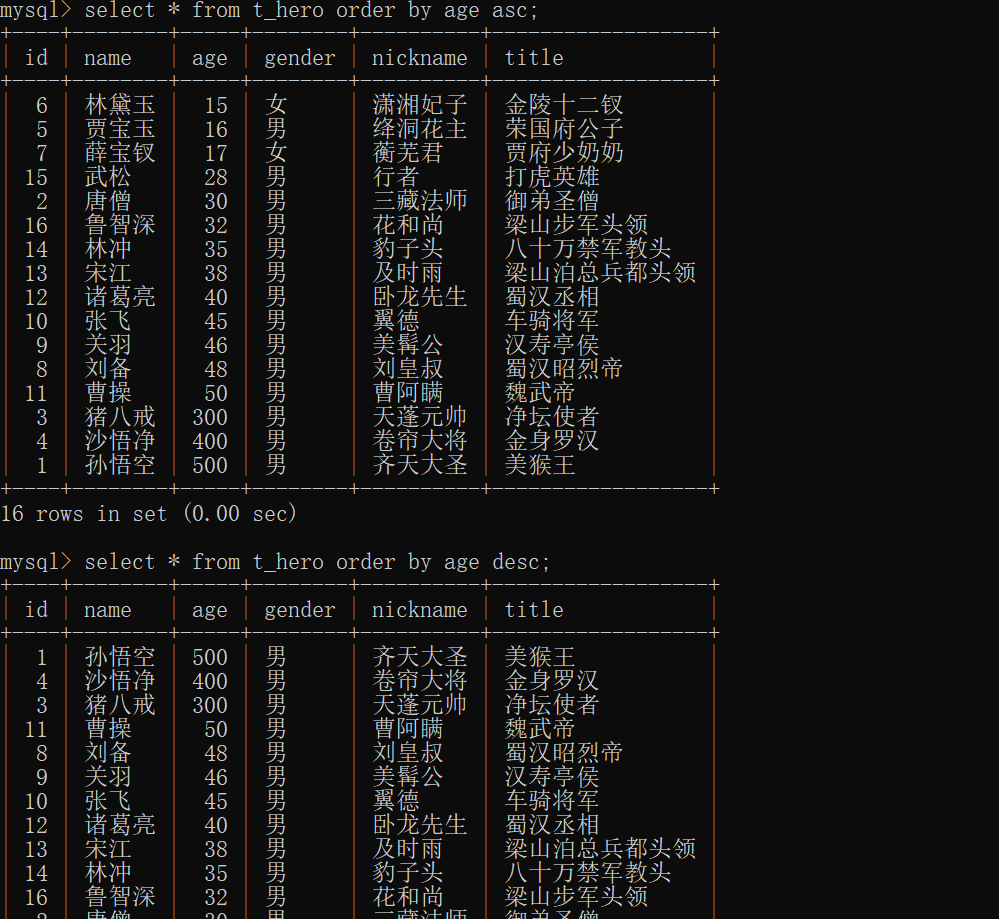
分页查询
select语句,查询数据时,可能结果会非常多,此时就不能直接展示,分页展示。
总数量(all_data):查询 select count(*)
每页展示的数量(page_size):程序员定
当前页(cur_page):默认第一页,用户自己点击选择
总页数(all_page):总数量 % 每页的数量 == 0 整除后的商 : 商 + 1
sql
limit num # 查询多少条
limit num1, num2; # num1: 偏移量, num2 : 每页的数量
limit cur_page * (page_size - 1), page_size;分表查询
数据直接都存储在一张表中:
-
如果数据很大,性能会出现问题
-
将不同的数据,如果放在同一个表中,可能数据冗余
-
数据冗余,会导致数据可能出错
将不同的类型,采用不同的数据表进行存储,如果两张表或者多张表之间存在关联关系,则可以采用外键来描述这种关联关系。
外键作为主表的一个字段,这个外键一般是从表的主键,因为从表的主键一般不会轻易更改
案例:
sql
--主表
create table grade(
id int auto_increment,
name varchar(50) unique,
primary key(id) -- 主键
)
insert into grade(name) value("Java精品班"), ("python数据分析班"), ("网络安全班"), ("云原生高级班");
--从表
create table student(
id int primary key auto_increment,
name varchar(50) unique,
gender enum("F", "M"),
age int default 18,
adddress varchar(255),
class_id int -- 外键
);
Query OK, 0 rows affected (0.06 sec)
mysql> desc student;
+----------+---------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+---------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(50) | YES | UNI | NULL | |
| gender | enum('F','M') | YES | | NULL | |
| age | int | YES | | 18 | |
| adddress | varchar(255) | YES | | NULL | |
| class_id | int | YES | | NULL | |
+----------+---------------+------+-----+---------+----------------+
6 rows in set (0.00 sec)
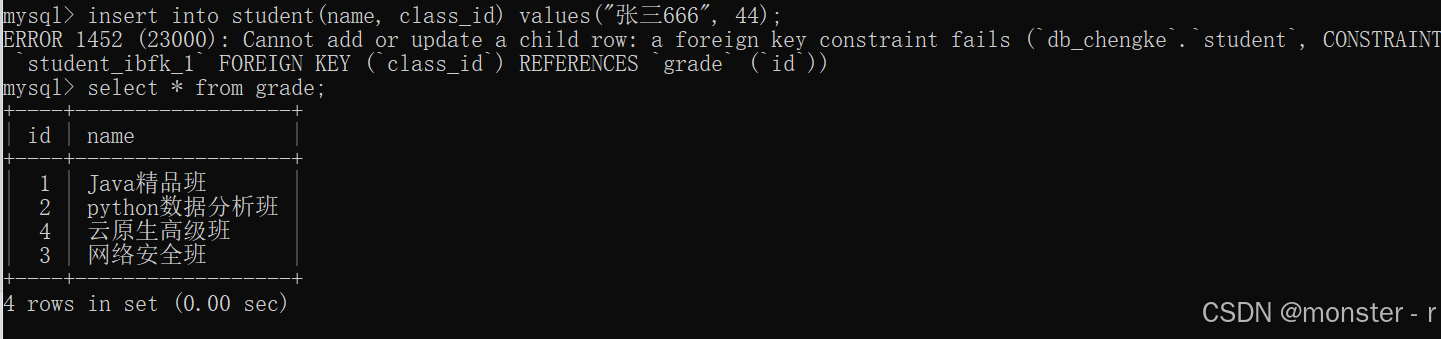
insert into student(name, class_id) values("张三", 1);
insert into student(name, class_id) values("张三2", 2);
insert into student(name, class_id) values("张三3", 1);
insert into student(name, class_id) values("张三4", 3);
insert into student(name, class_id) values("张三5", 1);
insert into student(name, class_id) values("张三6", 4);
-- 此时,插入了一条错误数据,该数据描述的外键不存在,是一条错误数据!!!
insert into student(name, class_id) values("张三666", 44);
# 如果要避免出现这种情况,必须加入外键约束!!外键和多表关联
外键:指的是两张或者多张表之间关联关系的字段。
外键约束:是表的约束,是约束表在插入外键数据时能够正确的插入。
如何添加约束:
在创建表的同时,将外键约束添加上去
首先保证班级表创建成功
插入正确的数据
create table grade(
id int auto_increment,
name varchar(50) unique,
primary key(id)
)
insert into grade(name) value("Java精品班"), ("python数据分析班"), ("网络安全班"), ("云原生高级班");
外键约束
外键是构建于一个表的两个字段或者两个表的两个字段之间的关系
外键确保了相关的两个字段的两个关系:
子(从)表外键列的值必须在主表参照列值的范围内,或者为空(也可以加非空约束,强制不允许为空)。
当主表的记录被子表参照时,主表记录不允许被删除。
外键参照的只能是主表主键或者唯一键,保证子表记录可以准确定位到被参照的记录。
外键约束创建的两种方式
方法一:通过在已经创建好的表中修改的方式来添加外键约束
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY(外键字段名)
方法二:在创建表的同时创建外键约束
FOREIGN KEY (外键列名)REFERENCES 主表(参照列)
sql
create table student(
id int primary key auto_increment,
name varchar(50) unique,
gender enum("F", "M"),
age int default 18,
adddress varchar(255),
class_id int,
foreign key(class_id) references grade(id) --外键约束
);案例:这里想插入class_id=44,因为外键约束关联了grade表,而grade表主键最大为4,所有这里报错了

ON DELETE {RESTRICT \| CASCADE \| SET NULL \| NO ACTION \| SET DEFAULT}
该子句用于定义当父表中的记录被删除时,子表中相关记录的处理方式
ON UPDATE {RESTRICT \| CASCADE \| SET NULL \| NO ACTION \| SET DEFAULT}
该子句用于定义当父表中的记录被更新时,子表中相关记录的处理方式
子表中相关记录的处理方式,有以下几种选项:
1.
RESTRICT当父表中的记录的主键值被更新时,如果子表中存在与之关联的记录,数据库会拒绝更新操作,并抛出一个错误。
2.
CASCADE当父表中的记录的主键值被更新时,数据库会自动更新子表中所有与之关联的记录的外键值。
3.
SET NULL当父表中的记录的主键值被更新时,子表中与之关联的记录的外键列会被设置为
NULL。前提是外键列允许为NULL。4.
NO ACTION在 SQL 标准中,
NO ACTION与RESTRICT类似。在大多数数据库系统中,当执行更新操作时,数据库会检查子表中的关联记录,但不会立即采取行动。如果在事务结束时仍然存在关联记录,更新操作将被拒绝。5.
SET DEFAULT当父表中的记录的主键值被更新时,子表中与之关联的记录的外键列会被设置为其默认值。前提是外键列有默认值。
表与表之间的关联关系
当表与表之间存在了外键,这就意味着,这两张表之间存在某种关联关系。
一旦表存在了关联关系,则会进行外键设计,如果设计外键,将外键设计在哪张表中?
-
一对一 :外键可以设计在任意一张表中
-
一对多 :外键必须设计在多方
-
多对多 :创建第三张表,来专门描述两张表的关联关系
多表关联查询
当两张或者多张表之间存在了关联关系,往往多表查询,如果查询。
-
交叉连接
-
内连接
-
外链接
-
左外连接
-
右外连接
-
-
自连接
-
全连接
-
自然连接 【不建议使用,直到就行】数据库自动使用相同字段名称完成外键关联
sql
-- 交叉连接(cross join),
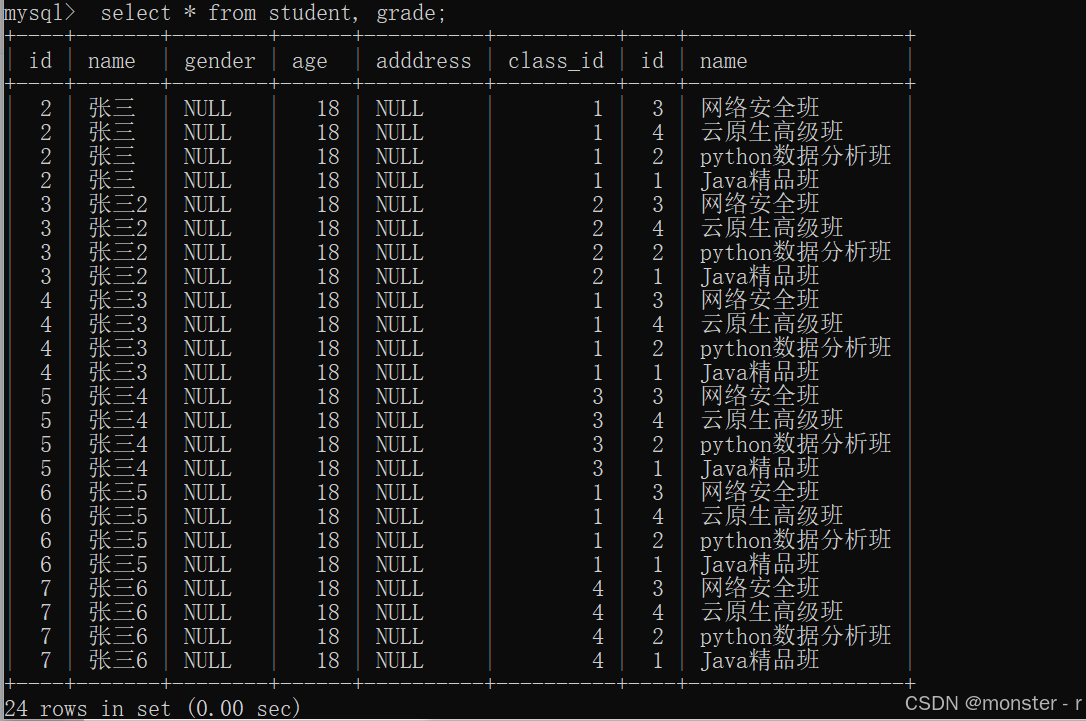
-- 在查询多表时,不指定表的关联关系,数据只能全部匹配,引发笛卡尔积现象
select * from student, grade;
-- sql98的标准写法
select * from student cross join grade;
# 内连接(一般情况下使用)
select * from student, grade where student.class_id = grade.id;
select * from student, grade where student.class_id = grade.id and student.name = '张三';
# 注意:sql98的内连接方式时,如果不指定关联条件,不管怎么写,都是交叉连接
select * from student inner join grade;
select * from student join grade;
# 正确写法,必须写清楚关联条件
select * from student inner join grade on (student.class_id=grade.id);
select * from student join grade on (student.class_id=grade.id) where student.name = "张三3";
# 内连接,只能查询出,存在关联关系的数据,如果不存在关联关系,如目前没有班级的学生,目前没有学生的班级
select * from student cross join grade on (student.class_id=grade.id) where student.name = "张三3";
# 如果要将这些没关联关系的数据查询出来,则需要使用外连接
select * from student left join grade on (student.class_id=grade.id);
select * from student right join grade on (student.class_id=grade.id);
# 注意:mysql不支持全连接查询 full join
# 但是SQL存在联合查询 union 、union all
# 注意:联合查询,必须保证查询的多条SQL返回的结果 结构必须一致,所以联合查询常见于查询一张表
(select * from student where class_id = "1") union (select id, name from student where id > 3);
(select * from student where class_id = "1") union all (select * from student where id > 3);
# 自连接查询
# 表的外键指向自身
create table board (
id int primary key auto_increment,
name varchar(50) unique not null,
intro text,
parent_id int,
foreign key(parent_id) references board(id)
);
insert into board(name, parent_id) values("前端板块", null);
insert into board(name, parent_id) values("后端板块", null);
insert into board(name, parent_id) values("硬件板块", null);
insert into board(name, parent_id) values("html", 1);
insert into board(name, parent_id) values("css", 1);
insert into board(name, parent_id) values("java", 2);
insert into board(name, parent_id) values("python", 2);
insert into board(name, parent_id) values("嵌入式", 3);
insert into board(name, parent_id) values("python基础", 7);
insert into board(name, parent_id) values("django", 7);
insert into board(name, parent_id) values("python GUI开发", 7);
insert into board(name, parent_id) values("css2", 5);
insert into board(name, parent_id) values("css3", 5);
select name from board where parent_id is null;
select name from board where parent_id = (select id from board where name = "前端板块");
select * from board as b, (select id from board where name = "前端板块") as t where b.parent_id = t.id;
select name from (select * from board where parent_id is not null) as t where t.parent_id in (1, 2, 3);
笛卡尔积现象:当进行多张表联合查询的时候,在没有任何条件进行限制情况下,最终查询结果条数是多张表记录条数的乘积
例如:
select *|字段 ,...... from 表名称 ,表名称 ......
SQL中函数
聚合函数
聚合函数对一组值进行运算,并返回单个值。也叫组合函数。
COUNT(*|列名) 统计行数
AVG(数值类型列名) 平均值
SUM (数值类型列名) 求和
MAX(列名) 最大值
MIN(列名) 最小值
除了COUNT()以外,聚合函数都会忽略NULL值。
| 函数名称 | 作用 |
|---|---|
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和,返回指定列的总和 |
| AVG | 求平均值,返回指定列数据的平均值 |
count(*) 和 count(1)和count(列名)区别
count(1) and count(*)
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count()用时多了! 从执行计划来看,count(1)和count()的效果是一样的。 但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。 因为count(),自动会优化指定到那一个字段。所以没必要去count(1),用count(),sql会帮你完成优化的 因此:count(1)和count(*)基本没有差别!
count(1) and count(字段) 两者的主要区别是 (1) count(1) 会统计表中的所有的记录数,包含字段为null 的记录。 (2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
count(*) 和 count(1)和count(列名)区别
执行效果上: count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上: 列名为主键,count(列名)会比count(1)快 列名不为主键,count(1)会比count(列名)快 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*) 如果有主键,则 select count(主键)的执行效率是最优的 如果表只有一个字段,则 select count(*)最优。
数值型函数
| 函数名称 | 作用 |
|---|---|
| ABS | 求绝对值 |
| SQRT | 求平方根 |
| POW 和 POWER | 两个函数的功能相同,返回参数的幂次方 |
| MOD | 求余数 |
| CEIL 和 CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
字符型函数
| 函数名称 | 作用 |
|---|---|
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CHAR_LENGTH | 计算字符串长度函数,返回字符串的字节长度,注意两者的区别 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 |
| INSERT(str,pos,len,newstr) | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| LEFT(str,len) | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE(s,s1,s2) | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING(s,n,len) | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
| STRCMP(expr1,expr2) | 比较两个表达式的顺序。若expr1 小于 expr2 ,则返回 -1,0相等,1则相反 |
| LOCATE(substr,str ,pos) | 返回第一次出现子串的位置 |
| INSTR(str,substr) | 返回第一次出现子串的位置 |
日期和时间函数
| 函数名称 | 作用 |
|---|---|
| CURDATE() CURRENT_DATE() CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME() CURRENT_TIME() CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW | 返回当前系统的日期和时间值 |
| SYSDATE | 返回当前系统的日期和时间值 |
| DATE | 获取指定日期时间的日期部分 |
| TIME | 获取指定日期时间的时间部分 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定曰期对应的月份的英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值,也就是星期数,注意周日是开始日,为1 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1 〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH 和 DAY | 两个函数作用相同,获取指定日期是一个月中是第几天,返回值范围是1~31 |
| DATEDIFF(expr1,expr2) | 返回两个日期之间的相差天数,如 SELECT DATEDIFF('2007-12-31 23:59:59','2007-12-30'); |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| TIME_TO_SEC | 将时间参数转换为秒数,是指将传入的时间转换成距离当天00:00:00的秒数,00:00:00为基数,等于 0 秒 |
流程控制函数
| 函数名称 | 作用 |
|---|---|
| IF(expr,v1,v2) | 判断,流程控制,当expr = true时返回 v1,当expr = false、null 、 0时返回v2 |
| IFNULL(v1,v2) | 判断是否为空,如果 v1 不为 NULL,则 IFNULL 函数返回 v1,否则返回 v2 |
| CASE | 搜索语句 |