一. DQL
DQL:Data Query Language(数据查询语言),用来查询数据库表中的记录。
关键字:SELETE
sql
-- DQL 完整语法
select
字段列表
from
表名列表
where
条件列表
group by
分组字段列表
having
分组后条件列表
order by
排序字段列表
limit
分页参数二. DQL基本查询
sql
-- DQL-基本查询
-- 查询多个字段 -- 建议使用
select 字段1, 字段2, 字段3 from 表名;
-- 查询所有字段(通配符)
select * from 表名;
-- 为查询字段设置别名,as可以省略
select 字段1 [as 别名1], 字段2 [as 别名2] from 表名;
-- 查询去除重复记录
select distinct 字段列表 from 表名;注意:* 代表查询所有字段,在实际开发中尽量少用(不直观,影响效率)
sql
-- 查询多个字段
select name, password from emp;
-- 查询所有字段(通配符)
select * from emp;
-- 为查询字段设置别名,as可以省略
select name as n, password p from emp;
-- 查询去除重复记录
select distinct job from emp;三. DQL条件查询
sql
-- DQL-条件查询
select 字段列表 from 表名 where 条件列表;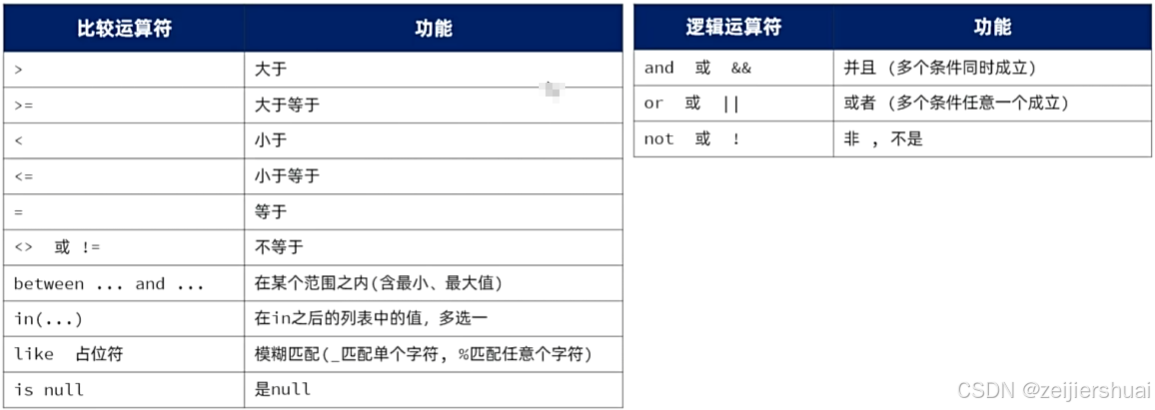
sql
-- 等于 =
select * from emp where name = '泰坦';
-- 小于等于 <=
select * from emp where salary <= 6000;
-- is null为空 is not null不为空
select * from emp where job is null ;
select * from emp where job is not null ;
-- 不等于 != 或 <>
select * from emp where password != '12344';
select * from emp where password <> '12344';
-- between and --between 最小值 and 最大值
select * from emp where entry_date between '2016-01-01' and '2020-01-01';
-- between and 与 多个条件 and
select * from emp where entry_date between '2016-01-01' and '2020-01-01' and gender = '1';
-- or 或者
select * from emp where job = '1' or job = '2' or job = '3';
-- in
select * from emp where job in('1', '2', '3');
-- like (_:单个字符)
select * from emp where name like '__';
-- like (% 任意个字符)
select * from emp where name like '%飞%';四. DQL分组查询
聚合函数
将一列数据作为一个整体,进行纵向计算
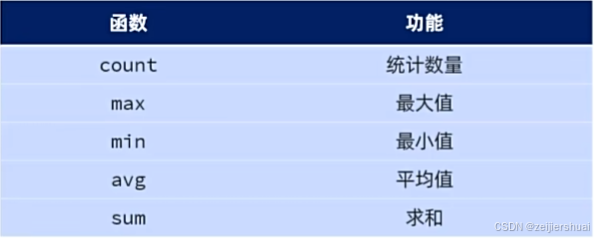
注意:null值不参与所有聚合函数的运算; count(*) 优先推荐使用
sql
-- 聚合函数(所有的聚合函数不参与null的统计)
-- count(字段) 最后推荐使用
select count(id) from emp;
-- count(*) 优先推荐使用
select count(*) from emp;
-- count(常量) 第二推荐使用
select count(1) from emp;
-- avg 平均值
select avg(salary) from emp;
-- max 最高值
select max(salary) from emp;
-- min 最低值
select min(salary) from emp;
-- sum 求和
select sum(salary) from emp;分组查询
sql
-- 分组查询
select 字段列表 from 表名 [where 条件列表] group by 分组字段名 [having 分组后过滤条件]注意:分组之后,select后的字段列表不能随意书写,能写的一般是分组字段+聚合函数
执行顺序:where > 聚合函数 > having
where 与 having的区别:
(1) 执行时机不同:where是在分组之前进行过滤,不满足where条件则不参与分组;having是在分组之后对结果进行过滤;
(1) 判断条件不同:where不能对聚合函数进行判断,而having可以
sql
-- 分组查询
-- select 字段列表 from 表名 [where 条件列表] group by 分组字段名 [having 分组后过滤条件]
-- 注意:分组之后,select后的字段列表不能随意书写,能写的一般是分组字段+聚合函数
select gender, count(*) from emp group by gender;
select job, count(*) from emp where entry_date <= '2020-01-01' group by job having count(*) >= 2;五. DQL排序查询
sql
-- 排序查询
select 字段列表 from 表名 [where 条件列表] [group by 分组字段名 having 分组后过滤条件] order by 排序字段 排序方式;排序方式:升序(asc)、降序(desc);默认是升序asc;
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
sql
-- 升序
select * from emp order by entry_date asc;
select * from emp order by entry_date;
-- 降序
select * from emp order by entry_date desc ;
-- 多字段排序
select * from emp order by entry_date, update_time desc ;六. DQL分页查询
sql
-- 分页查询
select 字段 from 表名 [where 条件列表] [group by 分组字段名 having 分组后过滤条件] [order by 排序字段 排序方式] limit 起始索引, 查询记录数;-
起始索引从0开始。
-
分页查询是数据库的方言,不同数据库有不同的实现,MySQL中是limit。
-
如果起始索引为0,起始索引可以省略,直接简写为 limit 10。
sql
-- 每页展示10条 第一页
select * from emp limit 0,10;
select * from emp limit 10;
-- 每页展示10条 第二页
select * from emp limit 10,10;
-- 每页展示10条 第三页
select * from emp limit 20,10;
-- 页码 起始索引 = (页码-1)*起始索引