主从复制
为什么要主从复制?
由于数据都是存储在一台服务器上,如果出事就完犊子了,比如:
- 如果服务器发生了宕机,由于数据恢复是需要点时间,那么这个期间是无法服务新的请求的;
- 如果这台服务器的硬盘出现了故障,可能数据就都丢失了。
要避免这种单点故障,最好的办法是将数据备份到其他服务器上,让这些服务器也可以对外提供服务,这样即使有一台服务器出现了故障,其他服务器依然可以继续提供服务。
怎么确定主从服务器?
有服务器 A 和 服务器 B,我们在服务器 B 上执行下面这条命令:
# 服务器 B 执行这条命令
replicaof <服务器 A 的 IP 地址> <服务器 A 的 Redis 端口号>服务器 B 就会变成服务器 A 的「从服务器」,然后与主服务器进行第一次同步。
Redis主从复制怎么实现的
如果是第一次同步或者从服务器数据落后太多
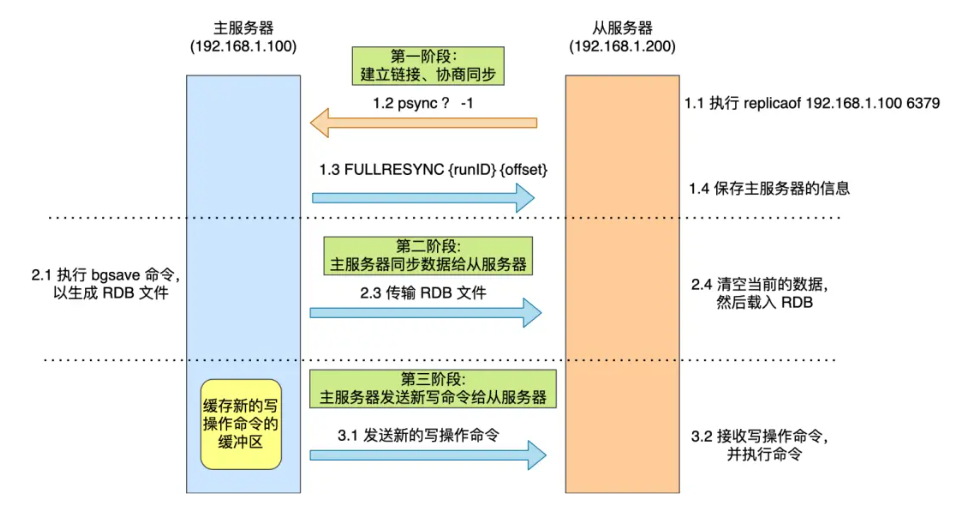
- 首先从服务器执行了 replicaof 命令后,从服务器就会给主服务器发送要进行数据同步的命令。
- 主服务器把自己的信息发送给从服务器。
- 主服务器执行 bgsave 命令会创建一个子进程来生成 RDB 文件,然后把文件发送给从服务器。从服务器收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件。
- 主服务器生成 RDB 这个过程是不会阻塞主线程的,因为是子进程来创建的RDB文件,父进程能够进行新命令的写入。
- 为了保证主从服务器的数据一致性**,父进程把新命** **令写入到 replication buffer 缓冲区里,在从服务器完成了RDB的载入之后,**主服务器将 replication buffer 缓冲区里所记录的写操作命令发送给从服务器,从服务器执行来自主服务器 replication buffer 缓冲区里发来的命令,这时主从服务器的数据就一致了。
什么是命令传播
- 主从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接。
- 后续主服务器可以通过这个连接继续将写操作命令传播给从服务器,然后从服务器执行该命令,使得与主服务器的数据库状态相同。
- 而且这个连接是长连接的,目的是避免频繁的 TCP 连接和断开带来的性能开销。
- 上面的这个过程被称为基于长连接的命令传播
主从复制可能遇到的问题?
- 由于是通过 bgsave 命令来生成 RDB 文件的,那么主服务器就会忙于使用 fork() 创建子进程,如果主服务器的内存数据非大,在执行 fork() 函数时是会阻塞主线程的,从而使得 Redis 无法正常处理请求;
- 传输 RDB 文件会占用主服务器的网络带宽,会对主服务器响应命令请求产生影响。
分担主服务器的压力解决方式
Redis从服务器可以有自己的从服务器,我们可以把拥有从服务器的从服务器当作经理角色,它不仅可以接收主服务器的同步数据,自己也可以同时作为主服务器的形式将数据同步给从服务器。
什么情况下会发生增量复制?
主从服务器在完成第一次同步后,就会基于长连接进行命令传播。网络发送延迟可能造成连接断开。
如果主从服务器间的网络连接断开了,那么就无法进行命令传播了,这时从服务器的数据就没办法和主服务器保持一致了,客户端就可能从「从服务器」读到旧的数据。
网络断开恢复后主从服务器会采用增量复制的方式继续同步,也就是只会把网络断开期间主服务器接收到的写操作命令,同步给从服务器。
什么是环形缓冲区?什么是replicatuon 缓冲区?
1. Replication Buffer(复制缓冲区)
- 定义 :主节点为每个从节点单独分配的缓冲区,用于暂存即将发送给该从节点的数据(包括全量复制和增量复制的数据)。
- 特点 :
- 每个从节点独立拥有一个 Replication Buffer。
- 数据按顺序存储,非环形结构 ,可能因网络延迟或从节点处理慢导致缓冲区溢出(触发
client-output-buffer-limit限制)。
- 作用:用于全量复制期间传输 RDB 文件后的增量数据,以及后续增量复制的实时数据。
2. Replication Backlog Buffer(复制积压缓冲区)
- 定义 :主节点上全局唯一的环形缓冲区(Circular Buffer),记录最近写入的命令,用于支持增量复制。
- 特点 :
- 环形结构:固定大小,新数据覆盖旧数据(当缓冲区写满时)。
- 所有从节点共享同一个 Backlog Buffer。
- 作用 :主节点在全量复制期间和增量复制期间,将新写入的命令写入此缓冲区,确保从节点断线重连后能通过偏移量(
offset)快速同步增量数据。
增量复制过程
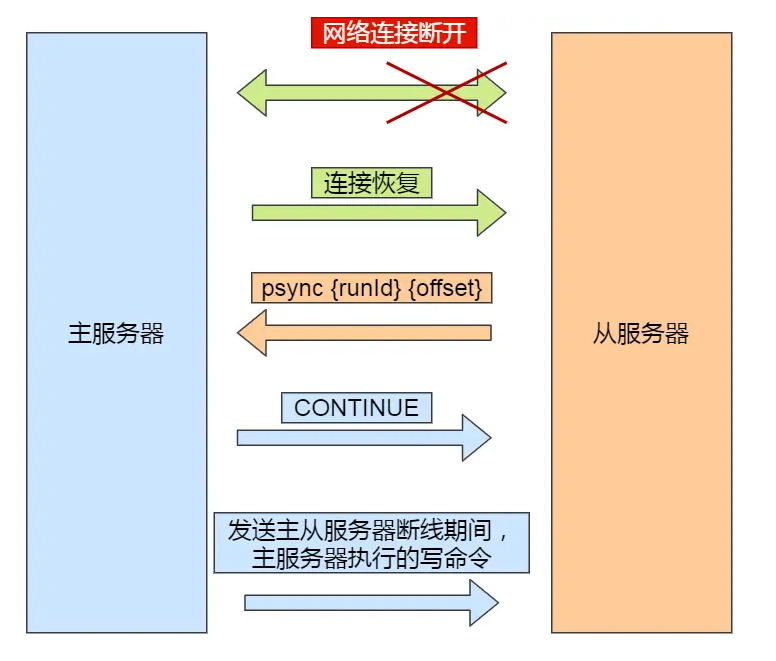
主要有三个步骤:
- 从服务器在恢复网络后,会发送 psync 命令给主服务器,此时的 psync 命令里的 offset 参数不是 -1;
- 主服务器收到该命令后,然后用 CONTINUE 响应命令告诉从服务器接下来采用增量复制的方式同步数据;
- 然后主服务将主从服务器断线期间,所执行的写命令发送给从服务器,然后从服务器执行这些命令。
网络断开后,当从服务器重新连上主服务器时,从服务器会通过 psync 命令将自己的复制偏移量 slave_repl_offset 发送给主服务器,主服务器根据自己的 master_repl_offset偏移量 和 slave_repl_offset 从服务器偏移量之间的差距,然后来决定对从服务器执行哪种同步操作:
- 如果判断出从服务器要读取的数据还在 repl_backlog_buffer 环形缓冲区里,那么主服务器将采用增量同步的方式;
- 相反,如果判断出从服务器要读取的数据已经不存在 repl_backlog_buffer 缓冲区里,那么主服务器将采用全量同步的方式。
当主服务器在 repl_backlog_buffer 中找到主从服务器差异(增量)的数据后,就会将增量的数据写入到 replication buffer 缓冲区,这个缓冲区我们前面也提到过,它是缓存将要传播给从服务器的命令。
哨兵模式
为什么要有哨兵机制?
主从模式是读写分离的,如果主节点(master)挂了,那么将没有主节点来服务客户端的写操作请求,也没有主节点给从节点(slave)进行数据同步了。哨兵模式自动发现主节点挂了,它自动将一个「从节点」切换为「主节点」。
什么是哨兵机制?
哨兵(Sentinel)机制 ,它的作用是实现主从节点故障转移。它会监测主节点是否存活,如果发现主节点挂了,它就会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端。
工作原理?
哨兵节点主要负责三件事情:监控、选主、通知。
主观下线
哨兵会每隔 1 秒给所有主从节点发送命令,当主从节点回复一个响应命令给哨兵,这样就可以判断它们是否在正常运行。
如果主节点或者从节点没有在规定的时间内响应哨兵的 PING 命令,哨兵就会将它们标记为「主观下线」。
客观下线
对于主节点是通过哨兵集群 (最少需要三台机器来部署哨兵集群 )来判断,通过多个哨兵节点一起判断,就可以就可以避免单个哨兵因为自身网络状况不好,而误判主节点下线的情况。
当一个哨兵判断主节点为「主观下线」后,就会向其他哨兵发起命令,其他哨兵收到这个命令后,就会根据自身和主节点的网络状况,做出投票。
一旦投票超过半数那么就认为主节点客观下线了,如果出现客观下线那么就有哨兵集群来进行主从故障转移。
主从故障转移之前
**哨兵是以哨兵集群的方式存在的,**需要在哨兵集群中选出一个 leader,让 leader 来执行主从切换。
判断主节点为「客观下线」的哨兵节点就是候选者。
候选者可以成为leader但是要得到一半以上的票数。
主从故障转移过程
- 第一步:在已下线主节点(旧主节点)属下的所有「从节点」里面,挑选出一个从节点,并将其转换为主节点。
有三轮考察机制。
- 第二步:让旧主节点的所有「从节点」修改主节点对象,修改为「新主节点」;
- 第三步:将新主节点的 IP 地址和信息,通过「发布者/订阅者机制」通知给客户端;
- 第四步:继续监视旧主节点,当这个旧主节点重新上线时,将它设置为新主节点的从节点;
为什么主从切换会导致数据丢失?
在Redis哨兵模式中,主从故障转移可能导致数据丢失的原因主要包括以下几点:
-
异步复制延迟:
原因 :主节点写入数据后,异步复制到从节点存在延迟。若主节点在数据未完全复制时宕机,这部分数据将丢失。影响:新主节点可能缺失未同步的数据,导致客户端写入的数据无法恢复。
-
脑裂(Split-Brain)问题:
原因 :网络分区导致原主节点与集群隔离,哨兵选举新主节点。原主节点在隔离期间仍接受写入,恢复后作为从节点同步新主数据,丢弃自身新数据。影响:隔离期间写入原主节点的数据被覆盖,永久丢失。
解决办法:切片集群