文章目录
文件引用分析
每次生成的checkpoint 里都会有所有文件的引用信息
- 问题,引用分析里如何把f1,f2去掉了,可以参考下面的代码,每次生成引用分析时,会先list 本地的文件目录,因为f1,f2已经合并了,所以不会出现在后续里了
bash
//保存引用的是个map,每个checkpoint 是一个
SortedMap<Long, Collection<HandleAndLocalPath>> uploadedSstFiles
uploadedSstFiles.put(checkpointId, Collections.unmodifiableList(sstFiles));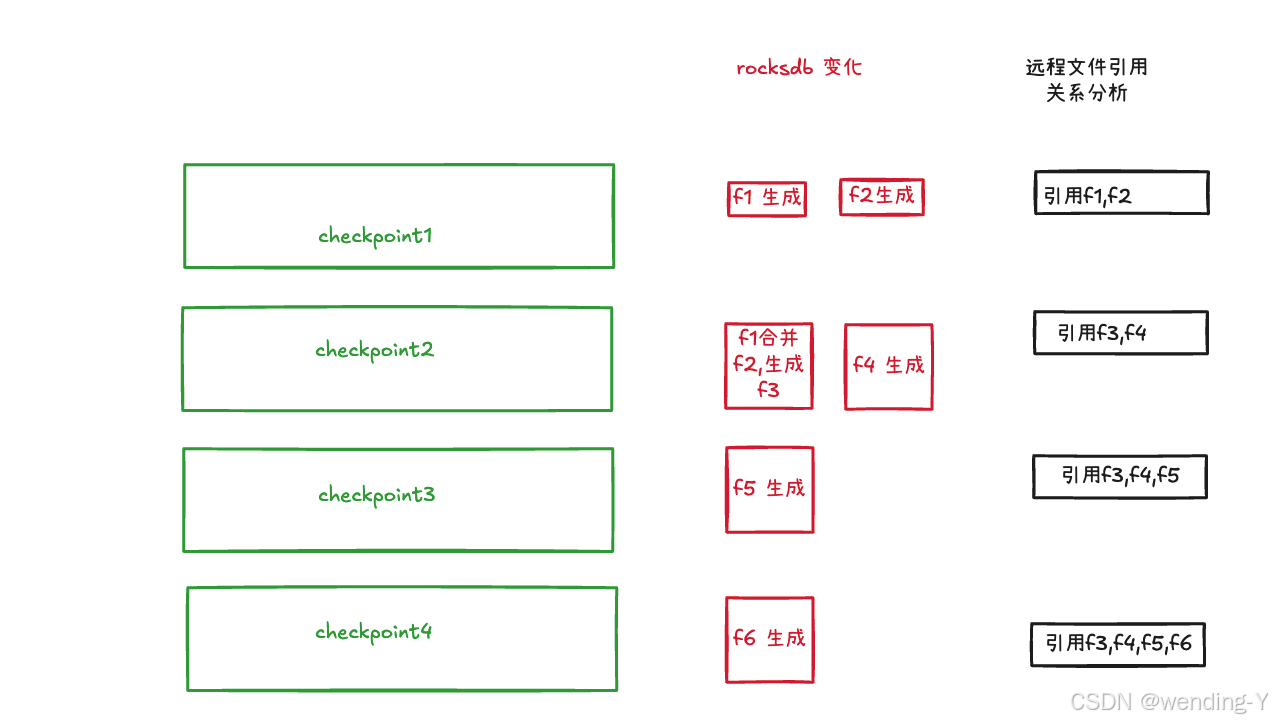
相关代码分析
bash
List<HandleAndLocalPath> sstFilesUploadResult =
stateUploader.uploadFilesToCheckpointFs(
sstFilePaths,
checkpointStreamFactory,
stateScope,
snapshotCloseableRegistry,
tmpResourcesRegistry);
uploadedSize +=
sstFilesUploadResult.stream().mapToLong(e -> e.getStateSize()).sum();
//这里加上本次上传的
sstFiles.addAll(sstFilesUploadResult);
private void createUploadFilePaths(
Path[] files,
List<HandleAndLocalPath> sstFiles,
List<Path> sstFilePaths,
List<Path> miscFilePaths) {
for (Path filePath : files) {
final String fileName = filePath.getFileName().toString();
if (fileName.endsWith(SST_FILE_SUFFIX)) {
Optional<StreamStateHandle> uploaded = previousSnapshot.getUploaded(fileName);
if (uploaded.isPresent()) {
//这里加上已经上传的
sstFiles.add(HandleAndLocalPath.of(uploaded.get(), fileName));
} else {
sstFilePaths.add(filePath); // re-upload
}
} else {
miscFilePaths.add(filePath);
}
}
}
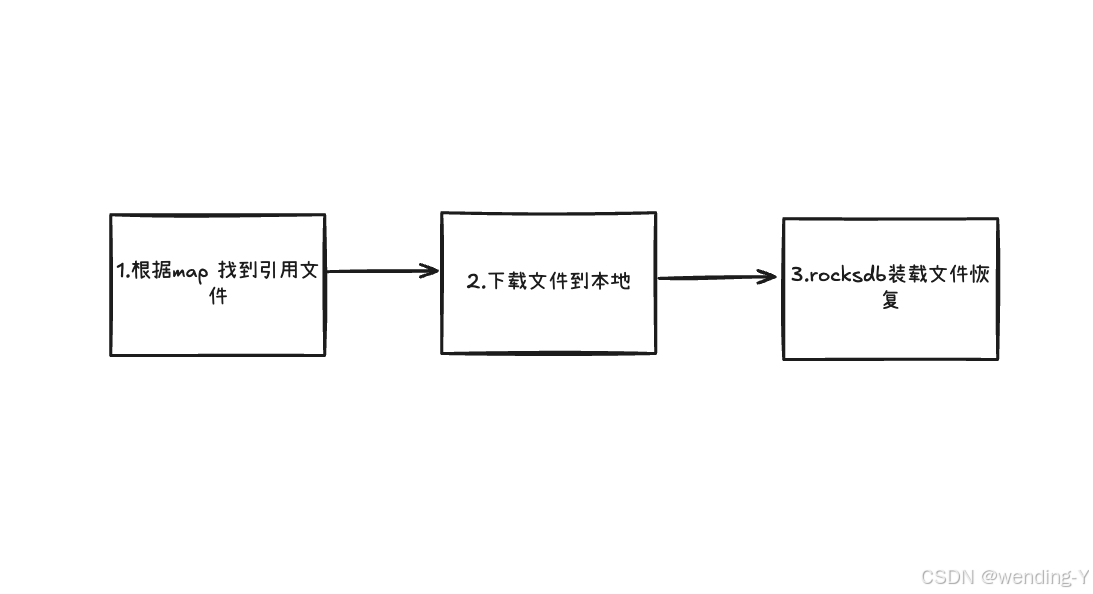
}从state 恢复,以rocksdb为例
不修改并行度
大致是这三步
bash
@SuppressWarnings("unchecked")
private void restoreWithoutRescaling(KeyedStateHandle keyedStateHandle) throws Exception {
logger.info(
"Starting to restore from state handle: {} without rescaling.", keyedStateHandle);
if (keyedStateHandle instanceof IncrementalRemoteKeyedStateHandle) {
IncrementalRemoteKeyedStateHandle incrementalRemoteKeyedStateHandle =
(IncrementalRemoteKeyedStateHandle) keyedStateHandle;
restorePreviousIncrementalFilesStatus(incrementalRemoteKeyedStateHandle);
restoreBaseDBFromRemoteState(incrementalRemoteKeyedStateHandle);
} else if (keyedStateHandle instanceof IncrementalLocalKeyedStateHandle) {
IncrementalLocalKeyedStateHandle incrementalLocalKeyedStateHandle =
(IncrementalLocalKeyedStateHandle) keyedStateHandle;
restorePreviousIncrementalFilesStatus(incrementalLocalKeyedStateHandle);
restoreBaseDBFromLocalState(incrementalLocalKeyedStateHandle);
} else {
throw unexpectedStateHandleException(
new Class[] {
IncrementalRemoteKeyedStateHandle.class,
IncrementalLocalKeyedStateHandle.class
},
keyedStateHandle.getClass());
}
logger.info(
"Finished restoring from state handle: {} without rescaling.", keyedStateHandle);
}修改并行度
keyGroupRange
先理解keyGroupRange
定义 :
KeyGroupRange 是一组连续的 KeyGroup 的集合。它表示某个任务实例(subtask)负责处理哪些 KeyGroup。
作用 :
KeyGroupRange 用于定义每个并行子任务(Task)需要处理的 KeyGroup 范围。
每个 Task 都会分配到一个或多个 KeyGroupRange,从而明确该 Task 应该处理哪些 KeyGroup 的数据和状态。
特点 :
KeyGroupRange 是一个范围的概念,可以包含多个 KeyGroup。
当任务的并行度发生变化时,KeyGroupRange 的分配也会相应调整
假设:
总共有 16 个 KeyGroup(编号从 0 到 15)。
并行度为 2。
分配方式
Task 1 负责 KeyGroupRange [0, 8),即 KeyGroup 0 到 7。
Task 2 负责 KeyGroupRange [8, 16),即 KeyGroup 8 到 15。
如果并行度增加到 4:
Task 1 负责 KeyGroupRange [0, 4),即 KeyGroup 0 到 3。
Task 2 负责 KeyGroupRange [4, 8),即 KeyGroup 4 到 7。
Task 3 负责 KeyGroupRange [8, 12),即 KeyGroup 8 到 11。
Task 4 负责 KeyGroupRange [12, 16),即 KeyGroup 12 到 15。
过程
- 核心挑战
当并行度变化时,每个子任务负责的 数据分片(KeyGroup) 范围会发生变化。例如:
旧并行度 :2 个子任务,每个子任务负责 KeyGroup 0-1 和 KeyGroup 2-3。
新并行度 :4 个子任务,每个子任务负责更小的 KeyGroup 范围(如 0-0, 1-1, 2-2, 3-3)。
此时,需要将旧子任务的 状态数据 按新分片规则重新分配到新子任务中,同时避免数据丢失或重复。
- 恢复流程步骤
步骤 1:选择"最佳"检查点
目标 :找到一个与新子任务的 KeyGroup 范围 重叠最多的检查点增量句柄,作为恢复的基础。
原因 :减少需要迁移的数据量,提高效率。
示例 :
如果新子任务的 KeyGroup 范围是 0-0,则优先选择旧检查点中覆盖 KeyGroup 0 的数据。
步骤 2:下载所有相关状态数据
操作 :将所有相关检查点的数据(如 SST 文件)从远程存储(如 HDFS/S3)下载到本地临时目录。
原因 :确保所有可能需要的数据都可用,以便后续合并。
步骤 3:初始化基础数据库
操作 :
加载"最佳"检查点的数据 :将选中的检查点数据加载到一个新的 RocksDB 实例中。
裁剪数据 :仅保留属于新子任务 KeyGroup 范围 的键(通过键的前缀过滤)。
示例 :
新子任务负责 KeyGroup 0-0,则删除所有不属于该范围的键。
步骤 4:合并其他检查点数据
操作 :
逐个处理其他检查点 :对剩余的检查点,逐个加载到临时 RocksDB 实例。
遍历键值对 :逐条检查键是否属于新子任务的 KeyGroup 范围 。
复制有效数据 :将符合条件的键值对写入主 RocksDB 实例。
示例 :
检查点 A 包含 KeyGroup 0-3 的数据,新子任务只保留 KeyGroup 0 的部分。
步骤 5:清理临时数据
操作 :删除临时文件和资源,释放存储空间。
问题
为什么选择重叠最多的增量检查点句柄?
减少数据合并工作量 :
初始检查点覆盖的 KeyGroup 越多,后续需要从其他检查点合并的数据越少。
提高恢复效率 :
减少临时 RocksDB 实例的数量和迭代次数,从而加速恢复过程。
降低资源消耗 :
减少网络传输和磁盘 I/O 开销。